
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
[一、 别再停留 "只会用不会讲",深挖 string 底层让你真正懂字符串!](#一、 别再停留 “只会用不会讲”,深挖 string 底层让你真正懂字符串!)
[二、0基础手撕:从0搭建 string 核心底层逻辑(附实现代码)](#二、0基础手撕:从0搭建 string 核心底层逻辑(附实现代码))
[1.1 string 类的构造逻辑](#1.1 string 类的构造逻辑)
[1.1.1 无参构造及优化](#1.1.1 无参构造及优化)
[1.1.2 带参构造及优化](#1.1.2 带参构造及优化)
[1.1.3 全缺省构造(上面两者的结合)](#1.1.3 全缺省构造(上面两者的结合))
[1.1.4 拷贝构造和赋值运算符重载](#1.1.4 拷贝构造和赋值运算符重载)
[1.2 string 类的成员变量访问](#1.2 string 类的成员变量访问)
2、下标\[\]与迭代器:string遍历的"两大高效工具"
[2.1 operator\[\] 的底层逻辑与实现](#2.1 operator[] 的底层逻辑与实现)
[2.2 迭代器的基本框架与实现](#2.2 迭代器的基本框架与实现)
[3、字符串修改:push_back,append,insert,erase 与 += 的实现](#3、字符串修改:push_back,append,insert,erase 与 += 的实现)
[3.1 尾插单个字符:push_back 的实现](#3.1 尾插单个字符:push_back 的实现)
[3.2 追加字符串:append 的实现](#3.2 追加字符串:append 的实现)
[3.3 运算符重载:+= 的实现(字符 / 字符串追加)](#3.3 运算符重载:+= 的实现(字符 / 字符串追加))
[3.3.1 实现字符追加](#3.3.1 实现字符追加)
[3.3.2 实现字符串追加](#3.3.2 实现字符串追加)
[3.4 任意位置插入:insert 的实现(插入字符/字符串)](#3.4 任意位置插入:insert 的实现(插入字符/字符串))
[3.4.1 实现插入字符](#3.4.1 实现插入字符)
[3.4.2 实现插入字符串](#3.4.2 实现插入字符串)
[3.5 任意位置删除任意数量字符:erase 的实现](#3.5 任意位置删除任意数量字符:erase 的实现)
一、 别再停留 "只会用不会讲",深挖 string 底层让你真正懂字符串!
在我们日常写代码时,多数人对 string 的认知只停留在 "调用接口",但是面试官在面试时有时会让你手动实现 string 类部分功能,很多人却只能说出具体作用而不能模拟实现而傻掉了。
搞懂 string 的底层,远远不止应对面试那么简单,更是在日常开发中提高效率的关键,了解了 reserve 预分配容量的原理,就能降低扩容的次数;理解深拷贝的逻辑,就能避免传参,赋值时的内存错误。吃透它,再学 vector, list 等后续容器会轻松很多。
二、0基础手撕:从0搭建 string 核心底层逻辑(附实现代码)
1、底层构造逻辑:string类的成员变量与构造逻辑
string 的底层本质上就是靠三个成员变量支撑,先搭建好基本类框架,再逐步实现功能,新手也能一步步自己手撕出一个基本的 string 类。
1.1 string 类的构造逻辑
1.1.1 无参构造及优化
cpp
//string.h
#include<iostream>
#include<assert.h>
#include<string.h>
using namespace std;
namespace Mystring
{
class string
{
public:
string() //无参的构造函数,构造空串
:_str(nullptr)
,_size(0)
,_capacity(0)
{}
//访问_str
char* c_str()
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
void Test_string1(); //声明
}无参构造其实就是构造一个空串,这里我们直接用初始化列表进行初始化,用空指针传给 _str 感觉没什么问题,但是当我们打印时就会发现问题:
cpp
//string.cpp
#include"string.h"
namespace Mystring
{
void Test_string1()
{
string s1;
string s2("Hello world");
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
}
}
//Test.cpp
int main()
{
Mystring::Test_string1();
return 0;
}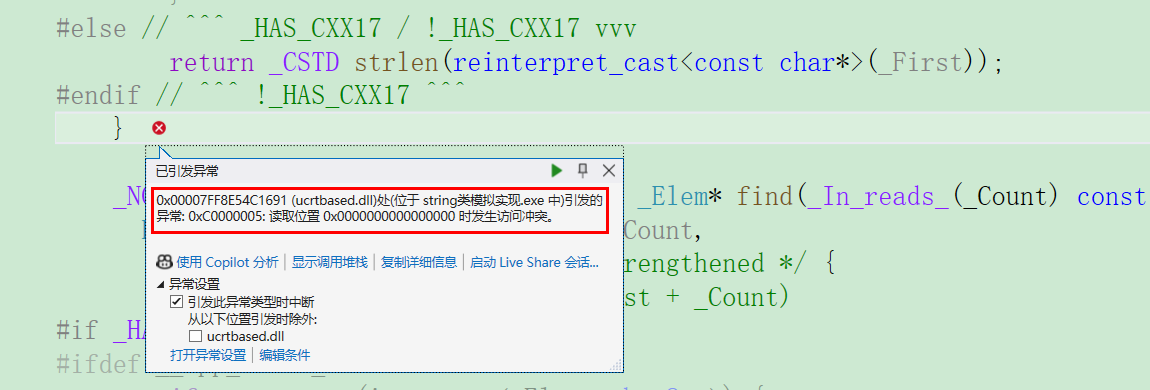
为什么会出现这样的报错?就是因为_str 被初始化成空指针 nullptr,当 cout << s1.c_str() << endl; 时,cout 会尝试访问 _str 指向的内存来打印字符串 ,但nullptr 是无效地址 ,直接访问就会导致程序崩溃,也就是我们常说的空指针解引用。那怎么去解决呢?
我们说过,即使是空字符串,也需要指向一个有效的、以 '\0' 结尾的内存(否则 cout 无法处理),但又因为内容为空,所以我们只需要写一个 '\0' 即可,相当于就是内容为空但有 '\0' 作为结尾的字符串:
cpp
string() //无参的构造函数,构造空串
//正确写法:
:_str(new char[1]{ '\0' }) //此时_str就是一个空串且以\0结尾
, _size(0)
, _capacity(0)
{
}1.1.2 带参构造及优化
如果是带参构造,我们在初始化列表中初始化时就需要利用 strlen 来计算长度,而且每个成员变量都需要如此比较麻烦。
这里就会有人说了,先用 strlen 初始化 _size,再用 _size 初始化其他的不就行了,这就需要回顾前面所讲的知识:我们在讲解初始化列表的时候就说过,初始化成员变量的顺序并不是由初始化列表的顺序来决定的,而是由下面的 private 的成员变量顺序来决定的。所以即使是先写 _size 再初始化 _str,执行顺序也是先初始化 _str,但此时 _size 还是未知数也就会导致出现随机值。
这也就说明了并不是所有情况初始化列表都是刚需的,在一些特定情况是可以不用写初始化列表直接在函数体内进行初始化:
cpp
//string.h
#include<iostream>
#include<assert.h>
#include<string.h>
using namespace std;
namespace Mystring
{
class string
{
public:
string(const char* str) //带参的构造函数
/*:_size(strlen(str))
,_str(new char[_size + 1])
,_capacity(_size)*/
//这种写法是不对的,由于之前讲过成员变量的访问顺序是由下面的private成员变量的顺序来决定的
//并不是初始化列表的顺序,所以是先访问_str,此时由于_size大小还未知则会出现随机值
//这就说明了初始化列表并不是刚需实现,还是要看具体场景
{
//对于有参的构造函数而言在函数体内部初始化会更加方便,因为顺序可以自己定
_size = strlen(str);
_str = new char[_size + 1]; //由于strlen计算不包含结尾的\0,所以new开辟空间要额外加1
_capacity = _size;
strcpy(_str, str);
}
//访问_str
char* c_str()
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
void Test_string1(); //声明
}
//string.cpp
#include"string.h"
namespace Mystring
{
void Test_string1()
{
string s1;
string s2("Hello world");
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
}
}
//Test.cpp
int main()
{
Mystring::Test_string1();
return 0;
}
1.1.3 全缺省构造(上面两者的结合)
cpp
string(const char* str = "") //全缺省构造函数(上面两者的结合)
//由于常量字符串默认结尾有\0,所以不需要再在字符串中加上\0
{
_size = strlen(str); //如果不传参则传缺省值"",则strlen计算长度为0
_str = new char[_size + 1];
_capacity = _size;
strcpy(_str, str);
}1.1.4 拷贝构造和赋值运算符重载
拷贝构造和赋值重载要实现深拷贝,确保多个对象间内存的独立,这个在之前类和对象中拷贝构造函数的深度解析和赋值运算符重载的深度解析已经详细讲过,大家如果不理解这里深浅拷贝区别的可以去回顾一下。
cpp
//拷贝构造(深拷贝)
string(const string& rstr)
{
_str = new char[rstr._size + 1];
_size = rstr._size;
_capacity = rstr._capacity;
memcpy(_str, rstr._str, rstr._size + 1);
}
//赋值运算符重载(深拷贝):先释放被赋值对象的旧内存,再深拷贝新内容
string& operator=(const string& rstr)
{
if (this != &rstr)
{
char* tmp = new char[rstr._size + 1];
memcpy(tmp, rstr._str, rstr._size + 1);
delete[] _str;//释放被赋值对象的旧内存
_str = tmp;
_size = rstr._size;
_capacity = rstr._capacity;
}
return *this;
}1.2 string 类的成员变量访问
在上面其实我们已经实现了对成员变量 _str 的访问,但其实是有一些缺陷的,如果按照上面的方法实现,别人是可以在函数体内对成员变量进行修改的,安全性上是有问题 的。所以我们可以用 const 来修饰成员函数 ,在前面的类和对象中const成员函数与取地址运算符重载深度解析我们也已经详细讲解了。
cpp
//访问_str
const char* c_str() const
{
return _str;
}
//访问_size
const size_t size() const
{
return _size;
}
//访问_capacity
const size_t capacity() const
{
return _capacity;
}我们将上面的所有函数都直接放在类中不进行声明与定义分离的操作 ,原因就是上面的函数均为短小函数,直接定义在类中可看成是内联函数(inline) ,内联函数当调用时不会进行展开,可以提高代码效率。
2、下标\[\]与迭代器:string遍历的"两大高效工具"
2.1 operator\[\] 的底层逻辑与实现
下标访问是 string 类最常用的操作之一,通过重载 operator ,可以像访问数组一样操作 string 的字符,底层本质是对 _str 指针的索引访问,同时前提也需要确保访问不会越界(这个可以加断言)
cpp
//string.h
public:
//访问下标operator[](普通对象)
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
//访问下标operator[](const对象)
const char& operator[](size_t pos)const
{
assert(pos < _size);
return _str[pos];
}
//string.cpp
namespace Mystring
{
void Test_string1()
{
string s2("Hello world");
cout << s2.c_str() << endl;
for (int i = 0; i < s2.size(); i++)
{
cout << s2[i] << " ";
}
}
}
2.2 迭代器的基本框架与实现
迭代器是遍历容器元素的抽象机制,对于 string 可以通过封装指针 来实现简单迭代器,结合下标访问可以覆盖不同遍历场景。
对于上面的遍历没有问题,但当我们用范围for遍历呢?
cpp
//string.cpp
void Test_string1()
{
string s2("Hello world");
cout << s2.c_str() << endl;
//范围for遍历(底层实际就是替换为迭代器)
for (auto e : s2)
{
cout << s2 << " ";
}
}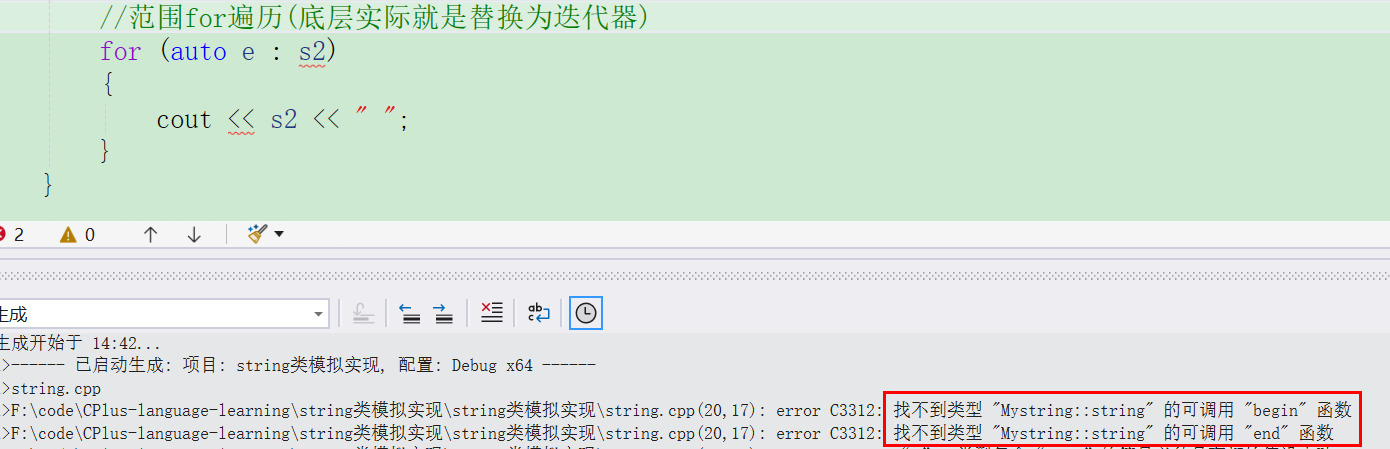
我们会发现并不能进行遍历,而且报错的原因是找不到可调用的 begin 和 end 函数,所以这可以说明范围for遍历的底层实际就是替换为迭代器。下面是对于简单迭代器的实现:
cpp
//string.h
public:
//简单迭代器的实现:
typedef char* interator; //相当于就是把 char* 类型用别名 interator 进行替换
interator begin() //迭代器模拟的就是指针的行为
{
return _str;//返回指向字符串起始位置的指针
}
interator end()
{
return _str + _size;//返回指向字符串有效字符结尾的下一个位置('\0'所在的位置)的指针
}
//string.cpp
namespace Mystring
{
void Test_string1()
{
string s2("Hello world");
cout << s2.c_str() << endl;
//范围for遍历(底层实际就是替换为迭代器)
for (auto e : s2)
{
cout << e << " ";
}
cout << endl;
//迭代器遍历
string::interator it = s2.begin();
while (it != s2.end())
{
cout << *it << " ";
it++;
}
}
而且通过上面的代码我们会发现虽然迭代器我们不能直接和指针划等号 ,但是迭代器在使用上和指针并没有很大的区别 ,并且简单迭代器的实现其实就是利用原生指针,因为这里interator 就是 char* 的别名 ,看 interator 可能有人会懵,那看成 char* 我觉得大家应该就能更好理解了;而且当我们实现了 begin 和 end 函数后,范围for遍历也能够实现了,就说明范围for的底层就是替换为迭代器来实现。
其实所有类中的 interator 都是 typedef 重命名来的 ,我们之所以说迭代器虽然在用法上和指针非常类似但是不能就单纯理解为指针,原因就是对于后面要学习的 list 类中 interator 并不是用 char* 指针进行重命名,而是用一种自定义类型(具体等后面讲到list时再详细讲解),但是不管是什么类型,迭代器 的强大之处就在于它将所有不管有多复杂的类类型都用同一个别名 interator 进行统一命名,将其全部封装起来 。
这样有一个非常大的好处:屏蔽了底层的实现细节,提供了统一的类似访问容器的方式,不再需要去关心容器底层是什么结构以及实现细节。这也就是对接口进行了统一,不管是什么数据结构我们都能用这种类似的方式去进行访问。
关键说明:
两个版本的重载 :非 const 版本返回 char&,支持修改字符;const 版本返回 const char&,仅允许读取(用于 const 对象)。
与迭代器的对比:operator 更适合已知索引的场景(如随机访问第i个字符),迭代器更适合范围遍历,两者底层都是通过指针访问内存,效率一致。
3、字符串修改:push_back,append,insert,erase 与 += 的实现
3.1 尾插单个字符:push_back 的实现
由于字符串修改的函数实现代码较多就可以将声明与定义进行分离:
cpp
//string.h
public:
//字符串修改函数声明
void reserve(size_t n); //扩容
void push_back(char ch); //尾插单个字符
//string.cpp
namespace Mystring
{
//扩容
void string::reserve(size_t n)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
//尾插单个字符
void string::push_back(char ch)
{
if (_size == _capacity) //需要扩容
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
//这里尤其需要注意_capacity为0的情况,为0时乘2不会起作用
}
_str[_size] = ch; //_size的位置就是原字符串结尾字符的下一个位置
_size++;
_str[_size] = '\0';
//由于_capacity是二倍扩容,\0是在_capacity这个大小字符串的结尾
//而一般_size都是小于_capacity,这就会导致在打印时会打印出超过_size部分的内容也就是随机值
//所以我们需要手动将\0提前
}
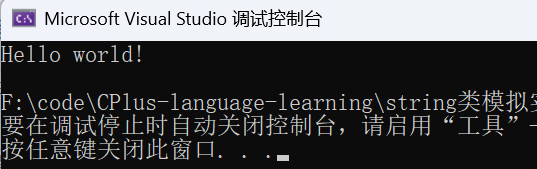
void Test_string2()
{
string s1("Hello world");
s1.push_back('!');
cout << s1.c_str() << endl;
}
}
关键逻辑:
- 扩容策略采用 "2 倍增长"(空串特殊处理为 1),平衡内存利用率和扩容次数;
- 每次插入后强制补'\0',确保C_str()返回的字符串始终有效
3.2 追加字符串:append 的实现
cpp
//string.h
public:
//字符串修改函数声明
void append(const char* str); //追加字符串
//string.cpp
namespace Mystring
{
//扩容
void string::reserve(size_t n)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
//追加字符串
void string::append(const char* str)
{
//追加字符串与字符不同的是,追加的字符串可能非常长,单扩容一次可能都无法满足
//所以我们需要用三目操作符先判断,如果过大则按需扩容
size_t len = strlen(str);
if (_size + len > _capacity) //需要扩容
{
reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity);
}
//直接用strcpy从原字符串的结尾开始往后拷贝追加字符串的内容即可
//由于追加字符串结尾有\0,所以不需要手动将\0提前
strcpy(_str + _size, str);
_size += len;
}
void Test_string2()
{
string s2("Hello");
s2.append(" world");
cout << s2.c_str() << endl;
}
}
关键逻辑:
- 直接复用reserve和strcpy,减少代码冗余;
- 批量追加比循环调用push_back更高效(避免多次扩容)。
- 扩容方案合理,避免频繁扩容。
3.3 运算符重载:+= 的实现(字符 / 字符串追加)
3.3.1 实现字符追加
cpp
//string.h
public:
//字符串修改函数声明
string& operator+=(char ch); //运算符重载:+=(实现字符追加)
//string.cpp
namespace Mystring
{
//扩容
void string::reserve(size_t n)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
//运算符重载:+=(实现字符追加)
string& string::operator+=(char ch)
{
//由于上面已经实现了push_back,两者区别只是+=需要返回值,所以可以直接使用
push_back(ch);
return *this;
}
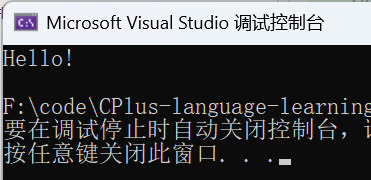
void Test_string2()
{
string s2("Hello");
s2 += '!';
cout << s2.c_str() << endl;
}
}
3.3.2 实现字符串追加
cpp
//string.h
public:
//字符串修改函数声明
string& operator+=(const char* str); //运算符重载:+=(实现字符串追加)
//string.cpp
namespace Mystring
{
//扩容
void string::reserve(size_t n)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
//运算符重载:+=(实现字符串追加)
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
void Test_string2()
{
string s2("Hello");
s2 += '!';
cout << s2.c_str() << endl;
s2 += "haha";
cout << s2.c_str() << endl;
}
}
优势:
- += 本质是对 push_back 和 append 的封装,避免重复编写扩容和字符拷贝逻辑;
- 返回 *this(对象引用)是实现链式操作的核心,确保每次调用后仍能继续操作当前对象;
- 与 append 相比,+= 更适合简单场景,代码可读性更高,两者底层效率一致。
3.4 任意位置插入:insert 的实现(插入字符/字符串)
insert 支持在指定位置插入单个字符或者字符串,核心是"先挪到原有字符,再插入新内容 ",需要特别处理扩容和内存重叠问题。
3.4.1 实现插入字符
cpp
//string.h
public:
//字符串修改函数声明
void insert(size_t pos, char ch); //任意位置插入:insert(实现字符插入)
//string.cpp
namespace Mystring
{
//扩容
void string::reserve(size_t n)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
//任意位置插入:insert(实现字符插入)
void string::insert(size_t pos, char ch)
{
assert(pos <= _size); //pos == _size相当于就是尾插
if (_size == _capacity)
{
reserve(2 * _capacity);
}
memmove(_str + pos + 1, _str + pos, _size + 1 - pos);
//memcpy不能对重叠部分进行拷贝,memmove可以
//_size + 1的作用是将字符串结尾的\0也包含在内,当进行拷贝时则会保留插入后字符串的结尾\0
//就不需要再手动将\0提前了
_str[pos] = ch;
_size++;
_str[_size] = '\0';
}
void Test_string2()
{
string s3("Hello world");
s3.insert(6, 'a');
cout << s3.c_str() << endl;
s3.insert(12, 'a');
cout << s3.c_str() << endl;
}
}
3.4.2 实现插入字符串
cpp
//string.h
public:
//字符串修改函数声明
void insert(size_t pos, const char* str); //任意位置插入:insert(实现字符串插入)
//string.cpp
namespace Mystring
{
//扩容
void string::reserve(size_t n)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
//任意位置插入:insert(实现字符串插入)
void string::insert(size_t pos, const char* str)
{
assert(pos <= _size); //pos == _size相当于就是尾插
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity);
}
memmove(_str + pos + len, _str + pos, _size + 1 - pos);
//还是需要注意在memmove时,拷贝的大小必须是 _size + 1 - pos 保证移动后字符串结尾\0的更新
memcpy(_str + pos, str, len);
//memcpy拷贝的长度为len,避免将str结尾的\0拷贝进去打印时出现问题
_size += len;
}
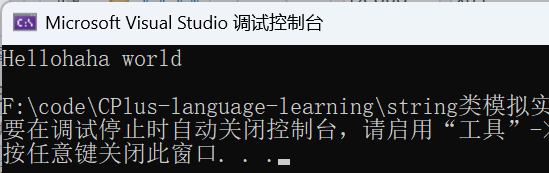
void Test_string2()
{
string s3("Hello world");
s3.insert(5, "haha");
cout << s3.c_str() << endl;
}
}
3.5 任意位置删除任意数量字符:erase 的实现
erase 支持两种场景:删除指定位置的不超过字符串大小的字符个数,或删除从指定位置开始后面的所有字符。核心逻辑就是"挪动后续的字符覆盖掉待删除内容 ",无需释放内存(容量不变,仅修改有效长度)
cpp
//string.h
public:
//字符串修改函数声明
void erase(size_t pos, size_t len = npos); //任意位置删除任意数量字符:erase
private:
static const size_t npos;
//string.cpp
namespace Mystring
{
const size_t string::npos = -1;
//之所以npos的定义放到.cpp文件而不是直接放到.h文件,
//是因为当.h被多个文件包含时,.h文件被展开时npos就被多次定义而导致报错
//任意位置删除任意数量字符:erase
void string::erase(size_t pos, size_t len) //注意声明定义分离时只能在声明出写缺省值
{
assert(pos < _size);
if (len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
//当删除对应位置后面的所有字符,此时则无需真实删除或者用memmove进行覆盖
//直接将字符串结尾的\0提前到对应位置,再将string的_size进行修改即可(模拟实现删除操作)
}
else
{
memmove(_str + pos, _str + pos + len, _size + 1 - pos - len);
_size -= len;
}
}
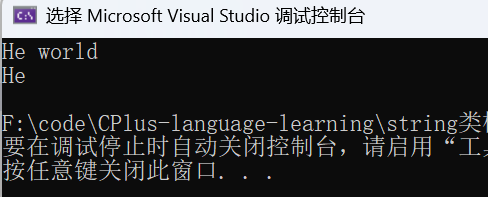
void Test_string2()
{
string s4("Hello world");
s4.erase(2, 3);
cout << s4.c_str() << endl;
s4.erase(2); //不给第二个实参就是删除pos位置后面的所有字符
cout << s4.c_str() << endl;
}
}
结束语
到此,string的构造、遍历以及修改的模拟实现就讲解完了,后面还有一些操作的模拟实现我们就放到下次再进行讲解。希望这篇文章对大家学习C++能有所帮助!
C++参考文档:
https://legacy.cplusplus.com/reference/
https://zh.cppreference.com/w/cpp
https://en.cppreference.com/w/