🔥个人主页: Milestone-里程碑
❄️个人专栏: <<力扣hot100>> <<C++>><<Linux>>
🌟心向往之行必能至
目录
[二 先简写大致框架,快速认识 http请求](#二 先简写大致框架,快速认识 http请求)
[2.1 解码 Decode](#2.1 解码 Decode)
[3.1 重定向状态码](#3.1 重定向状态码)
[3.2 永久重定向和临时重定向](#3.2 永久重定向和临时重定向)
[4.1 GET](#4.1 GET)
[4.2 POST](#4.2 POST)
[4.3 HEAD⽅法](#4.3 HEAD⽅法)
[4.4 DELETE⽅法(不常⽤)被禁用](#4.4 DELETE⽅法(不常⽤)被禁用)
[4.5 OPTIONS⽅法 被禁用](#4.5 OPTIONS⽅法 被禁用)
[五. 常见Header](#五. 常见Header)
[5.2 http是一个无连接,无状态的协议](#5.2 http是一个无连接,无状态的协议)
[无状态 = 服务器 "记不住你",每次请求都是 "陌生人对话"](#无状态 = 服务器 “记不住你”,每次请求都是 “陌生人对话”)
[5.3 解决http无状态带来的烦恼-Cookie](#5.3 解决http无状态带来的烦恼-Cookie)
[5.5 解决Cookie导致的问题 session](#5.5 解决Cookie导致的问题 session)
[六 源码](#六 源码)
在前面我们已经讲过了http的基本概念,接下来我们再看两张图,通过这两张图实现基本的http的请求和响应报头的组成
一.网络传输:拷贝
我们前面的学习学过,write 这些系统接口是写入内核级缓存区,而read这些系统接口是从内核级的缓存区读取数据
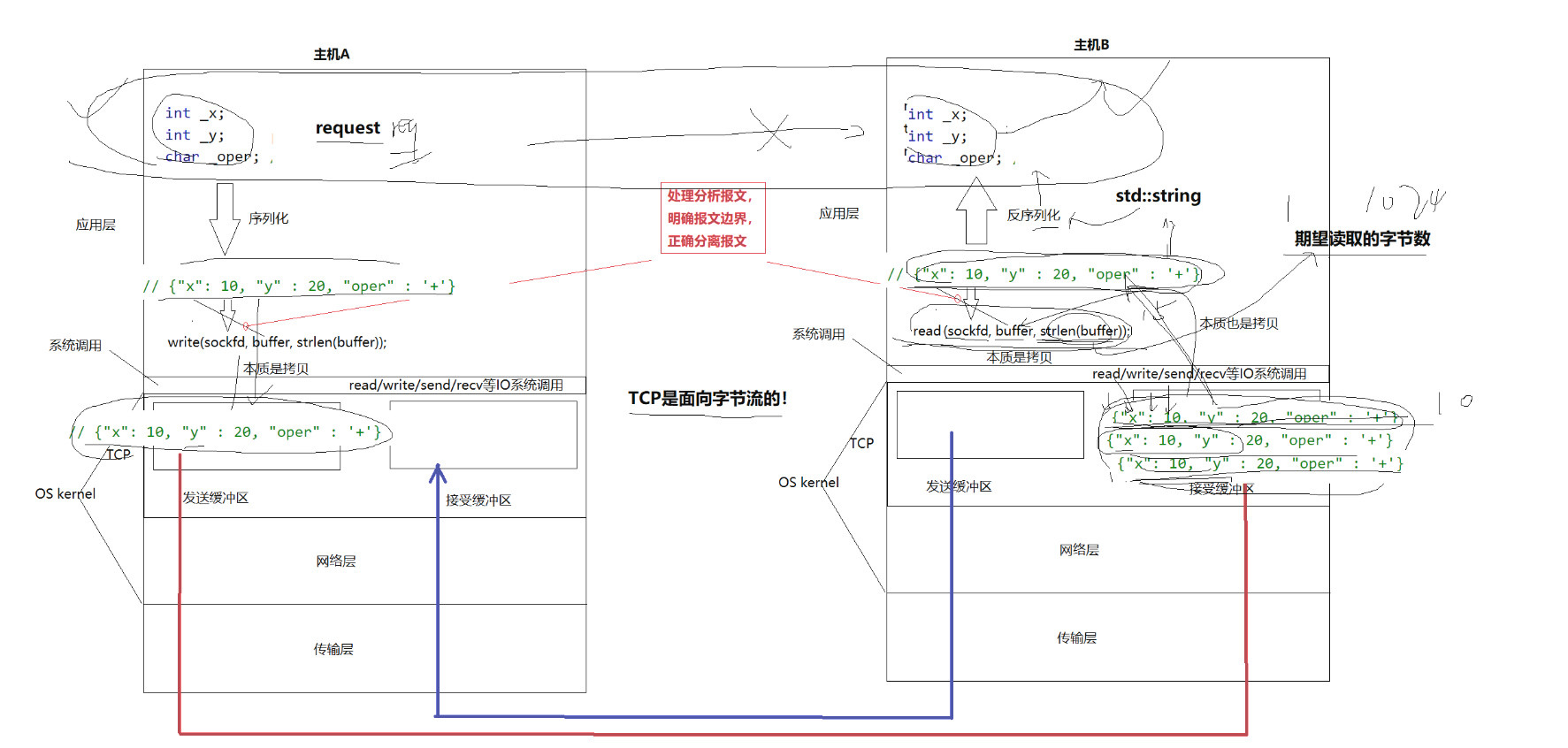
其实TCP和UDP都有缓存区,UDP无需发送缓存区(不可靠),而TCP则有,可靠
每次读取或者发送,其实都是把缓存区的内容拷贝出去,典型的生产者消费者模型
这也就是满了或者空了为什么会堵塞的原因了
二 先简写大致框架,快速认识 http请求
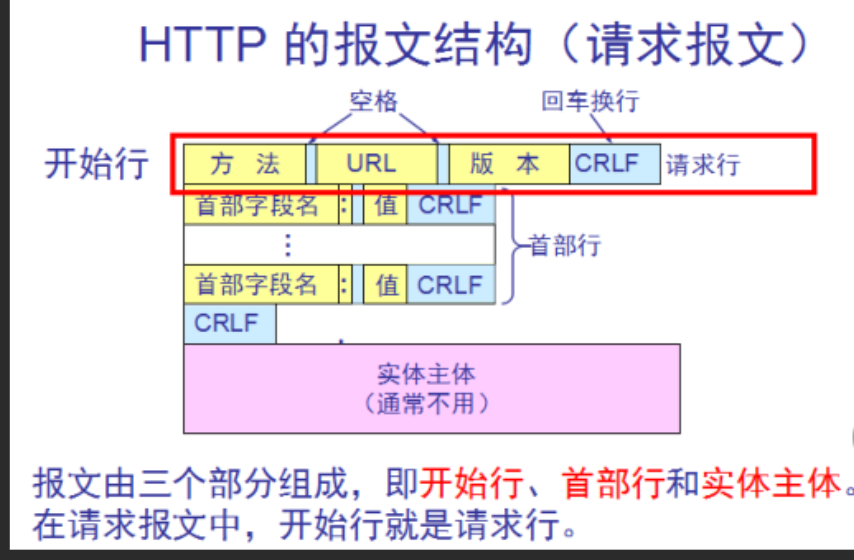
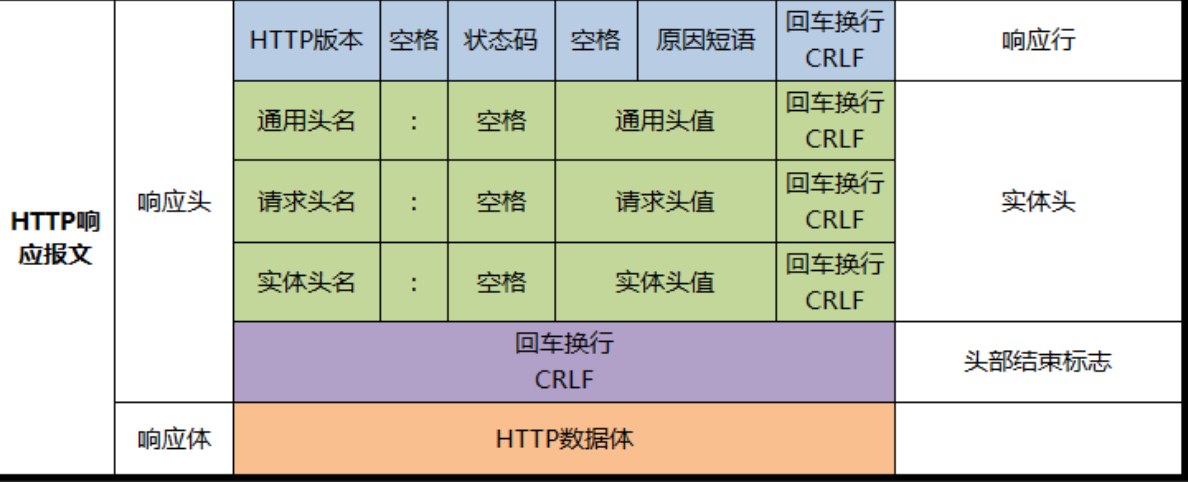
hhtp基本应答格式
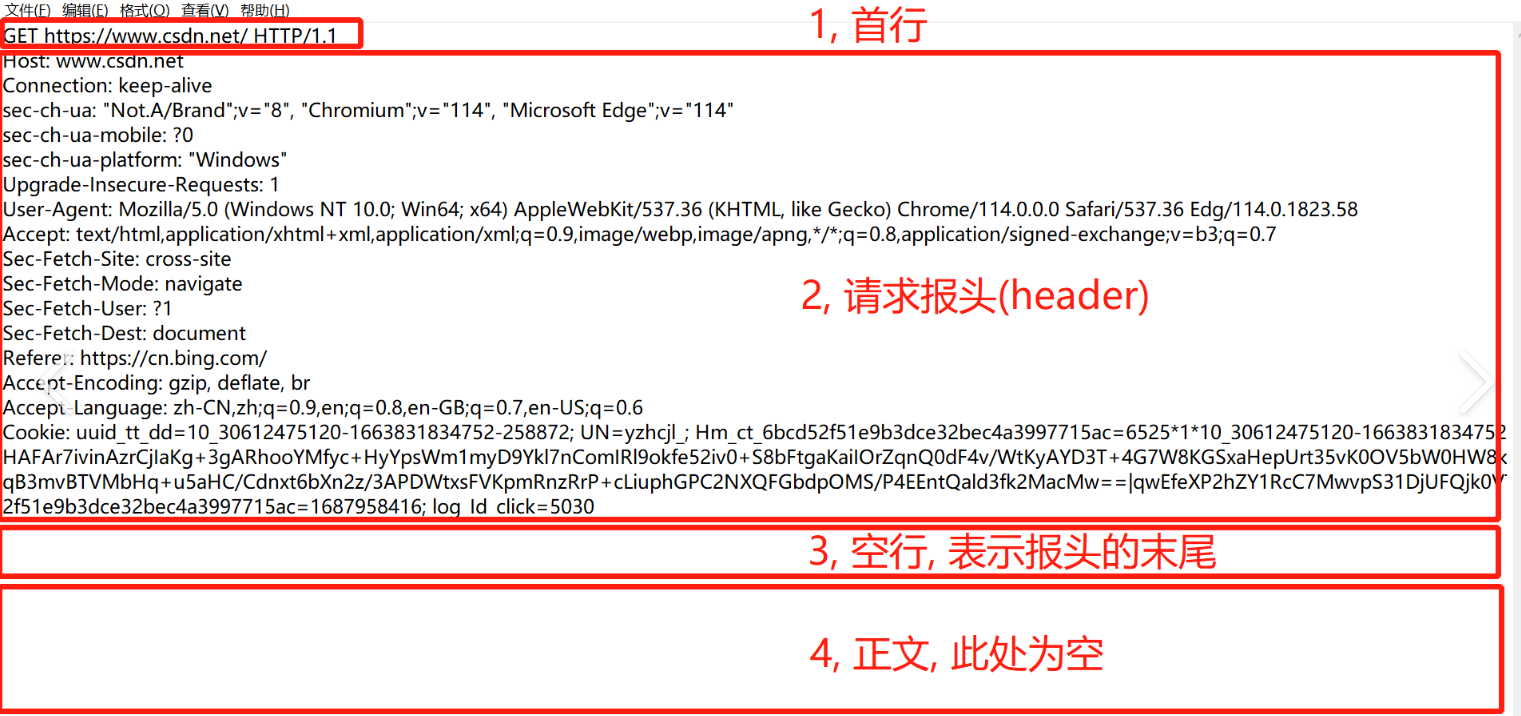
Http.hpp
bash#pragma once #include "Socket.hpp" #include "TcpServer.hpp" #include <iostream> #include <string> #include <memory> #include <unordered_map> using namespace SocketModule; const std::string gspace = " "; const std::string glinespace = "\r\n"; class HttpRequest { public: HttpRequest() { } std::string Serialize() { return std::string(); } bool Deserialize(std::string &reqstr) { return true; } ~HttpRequest() { } private: std::string _method; std::string _url; std::string _version; std::unordered_map<std::string, std::string> _headers; std::string _blankline; std::string _text; }; class HttpResponse { public: HttpResponse() {} ~HttpResponse() {} std::string Serialization(){ std::string hrsp_str; hrsp_str+=_version+gspace+std::to_string(_code)+gspace+_decp+glinespace; for(auto &e:_handler) { hrsp_str+=e.first+e.second+glinespace; } _blankline=glinespace; hrsp_str+=_blankline+_text; return hrsp_str; } bool Deserialization(){ return true; } std::string _version; int _code; // eg:404 std::string _decp; // Nofoune std::unordered_map<std::string, std::string> _handler; std::string _blankline; std::string _text; }; class Http { public: Http(uint16_t port) : tsvrp(std::make_unique<TcpServer>(port)) { } void HandlerHttpRquest(std::shared_ptr<SocketModule::Socket> &sock, InetAddr &client) { #ifndef DEBUG #define DEBUG std::string httpreqstr; int n = sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串 if (n > 0) { HttpResponse resp; resp._version = "HTTP/1.1"; resp._code = 200; // is success resp._decp = "OK"; // 方法1:每行末尾加 \ (注意\后不能有空格) resp._text = "<!DOCTYPE html>\ <html lang=\"en\">\ <head>\ <meta charset=\"UTF-8\">\ <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\ <title>Hello World</title>\ </head>\ <body>\ <h1>Hello World</h1>\ </body>\ </html>"; //再将resp进行序列化 std::string resp_str=resp.Serialization(); sock->Send(resp_str); } std::cout << httpreqstr; #endif // 对请求字符串,进行反序列化 } void Start() { tsvrp->Start([this](std::shared_ptr<SocketModule::Socket> &sock, InetAddr &client) { this->HandlerHttpRquest(sock, client); }); } ~Http() { } private: std::unique_ptr<TcpServer> tsvrp; };此时我们再启动服务器,再通过浏览器搜索,可以得到hello world,但我们发现会有两种情况
- 端口号未接路径,得到的是/
2.端口号带路径,会带上路径
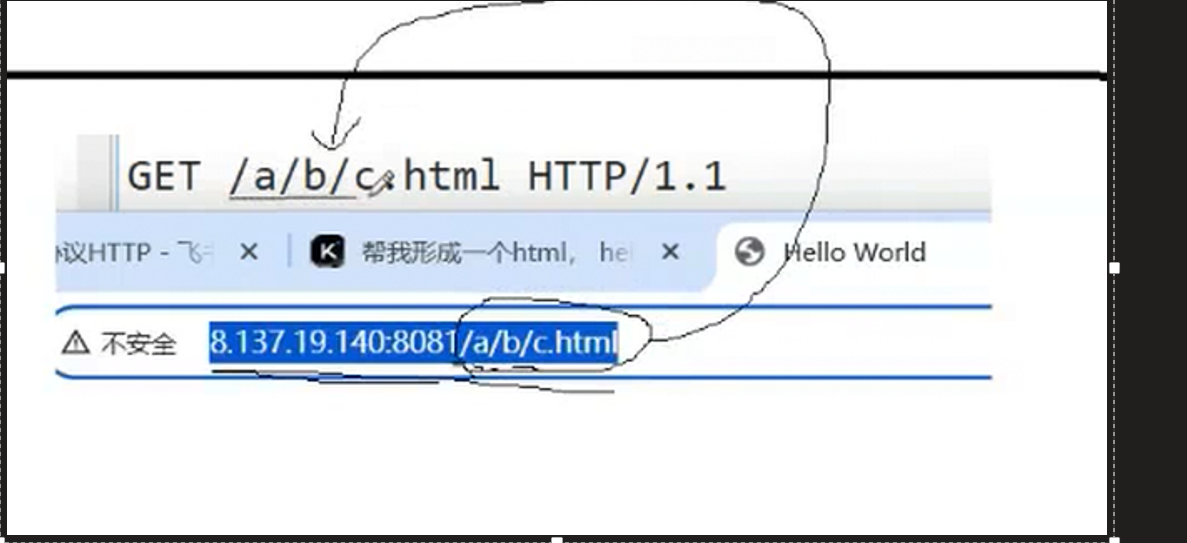
但其实这些目录都是Linux根目录,而是web根目录,当没有带路径时,会自动去先拼接index.html下查找
所以http申请的本质就是请求我们路径下的./wwwroot,目录下的特定资源,而url中的路径,就是我们要找的
因此修改
bash
class Http
{
public:
Http(uint16_t port) : tsvrp(std::make_unique<TcpServer>(port))
{
}
void HandlerHttpRquest(std::shared_ptr<SocketModule::Socket> &sock, InetAddr &client)
{
#ifndef DEBUG
#define DEBUG
std::string httpreqstr;
int n = sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串
if (n > 0)
{
HttpResponse resp;
resp._version = "HTTP/1.1";
resp._code = 200; // is success
resp._decp = "OK";
// 方法1:每行末尾加 \ (注意\后不能有空格)
//再将resp进行序列化
std::string filename=webroot+homepage;
bool res = Util::ReadFileContent(filename, &(resp._text)); // 浏览器请求的资源,一定会存在吗?出错呢?
(void)res;
std::string resp_str=resp.Serialization();
sock->Send(resp_str);
}
std::cout << httpreqstr;
#endif
// 对请求字符串,进行反序列化
}
void Start()
{
tsvrp->Start([this](std::shared_ptr<SocketModule::Socket> &sock, InetAddr &client)
{ this->HandlerHttpRquest(sock, client); });
}
~Http()
{
}
private:
std::unique_ptr<TcpServer> tsvrp;
};二.对请求进行解码,反序列化
对字符串进行反序列化分3步
1.读取并找到完整报头空行
2.对报头进行反序列化,提取一个属性:Content-length的长度
3.再从剩下的字符串内容中,提取content-length个字符

2.1 解码 Decode
解码操作与上一篇协议的解码操作类似
bash
bool Decode(std::string &buffer,std::string *package,std::string & blankline)
{
size_t pos=buffer.find(blankline);
if(pos==std::string ::npos)
return false;
size_t lenpos=buffer.find("Content-length");
int x=std::stoi(buffer.substr(lenpos,lenpos+2));
//再去换行符后面找
if(buffer.size()<pos+x)
return false;
//完整
*package=buffer.substr(pos,pos+x);
return true;
}2.2反序列化
bash
bool Deserialize(std::string &reqstr)
{
std::string line;
if(Util::ReadOneline(reqstr,&line,gliespace))
return true;
return false;
}
bash
bool Deserialize(std::string &reqstr)
{
// 1. 提取请求行
std::string reqline;
bool res = Util::ReadOneLine(reqstr, &reqline, glinespace);
LOG(LogLevel::DEBUG) << reqline;
// 2. 对请求行进行反序列化
ParseReqLine(reqline);
LOG(LogLevel::DEBUG) << "_method: " << _method;
LOG(LogLevel::DEBUG) << "_uri: " << _url;
LOG(LogLevel::DEBUG) << "_version: " << _version;
if(_url == "/")
_url = webroot + _url + homepage; // ./wwwroot/index.html
else
_url = webroot + _url;// ./wwwroot/a/b/c.html
return true;
}三.状态码
1开头:如网盘上传
4开头是客户端出错
5开头是服务器出错
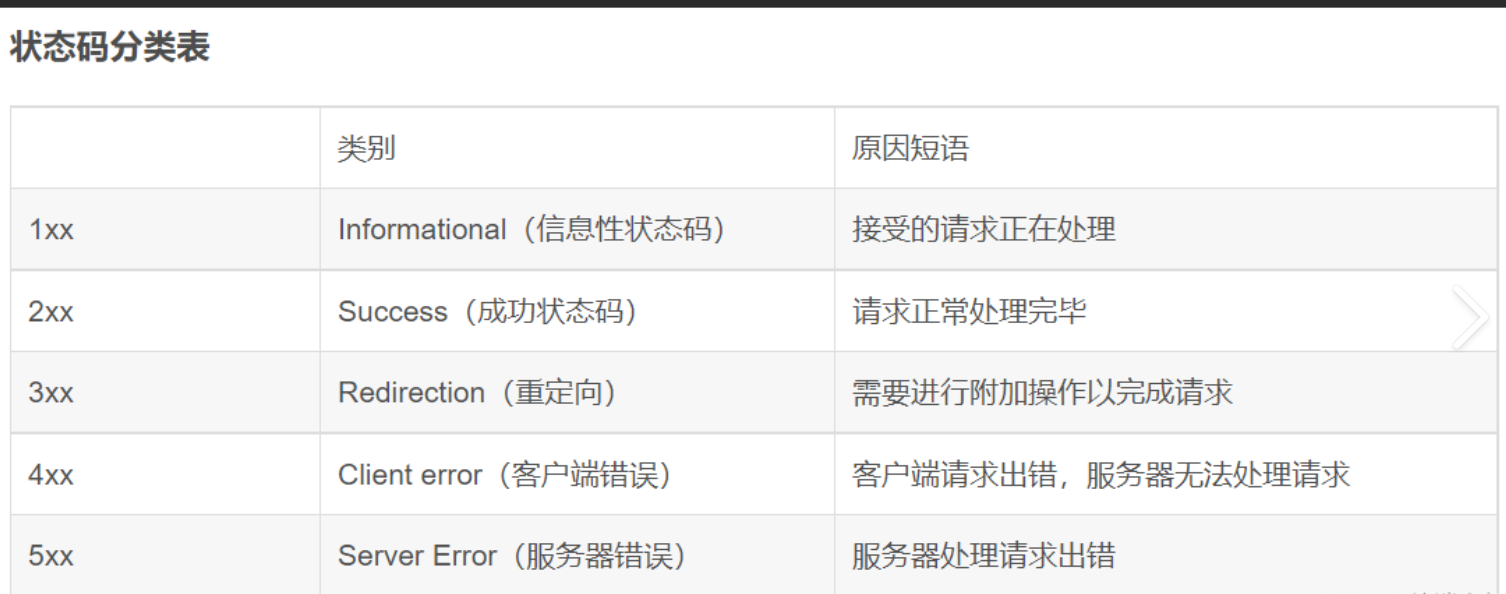
3.1 重定向状态码
| 状态码 | 类型 | 方法是否保留 | 典型场景 |
|---|---|---|---|
| 301 | 永久重定向 | 可能改为 GET | 域名更换 |
| 308 | 永久重定向 | 是 | POST 请求永久迁移 |
| 302 | 临时重定向 | 可能改为 GET | 临时跳转 |
| 307 | 临时重定向 | 是 | POST 请求临时跳转 |
| 303 | 临时重定向 | 强制 GET | POST 提交后跳转 |
| 304 | 缓存协商 | - | 资源未更新,使用缓存 |
其中我们重点讲一下永久重定向和临时重定向
3.2 永久重定向和临时重定向
| 维度 | 永久重定向 | 临时重定向 |
|---|---|---|
| 核心定义 | 资源永久迁移到新 URI,原地址不再使用 | 资源临时驻留在新 URI,原地址仍有效 |
| 核心状态码 | 301 Moved Permanently、308 Permanent Redirect | 302 Found、307 Temporary Redirect、303 See Other |
| 请求方法保留 | 301:可能被客户端转为 GET;308:严格保留(POST/PUT 等) | 302:可能转为 GET;307:严格保留;303:强制转为 GET |
| 搜索引擎行为 | 更新索引(将原地址权重转移到新地址) | 不更新索引(原地址权重不变) |
| 客户端行为 | 缓存重定向规则,后续直接请求新地址 | 不缓存(每次请求原地址后再跳转) |
| 典型使用场景 | 域名更换、页面永久下线 / 迁移、HTTPS 强制跳转(永久) | 临时维护、活动页面跳转、POST 提交后防重复提交、服务器负载均衡 |
临时重定向常 用于网页跳转,登录等,之后还会跳转回来的
永久重定向常用于企业的域名更改等
重定向有两种:
1.重定向到新的网站
2.重定向到自己的内部资源
四.HTTP常见方法
| 方法 | 幂等性 | 是否有请求体 | 核心用途 |
|---|---|---|---|
| GET | 是 | 通常无 | 获取资源 |
| POST | 否 | 是 | 创建 / 提交资源 |
| PUT | 是 | 是 | 全量更新 / 创建资源 |
| DELETE | 是 | 可选 | 删除资源 |
| PATCH | 否 | 是 | 部分更新资源 |
| HEAD | 是 | 无 | 获取资源头信息 |
| OPTIONS | 是 | 可选 | 查询资源支持的方法 / 预检 |
常用的有两种.其中一个为GET,另一个为POST
GET通常用来获得资源,但也可用来提交资源
POST则是用来提交资源
4.1 GET
⽤途:⽤于请求URL指定的资源。
⽰例: GET /index.html HTTP/1.1
特性:指定资源经服务器端解析后返回响应内容。
form表单: https://www.runoob.com/html/html-forms.html
4.2 POST
⽤途:⽤于传输实体的主体,通常⽤于提交表单数据。
⽰例: POST /submit.cgi HTTP/1.1
特性:可以发送⼤量的数据给服务器,并且数据包含在请求体中。
form表单: https://www.runoob.com/html/html-forms.html
GET如果进行参数的提交, 是通过url进行提交
POST:提交参数通过http request正文提交
GET会回显,POST不会,更加私密,但都不安全,可以被抓取,因为明文传送
为了安全,必须对报文进行加密,http协议
4.3 HEAD⽅法
⽤途:与GET⽅法类似,但不返回报⽂主体部分,仅返回响应头。
⽰例: HEAD /index.html HTTP/1.1 查看报头
特性:⽤于确认URL的有效性及资源更新的⽇期时间等
4.4 DELETE⽅法(不常⽤)被禁用
⽤途:⽤于删除⽂件,是PUT的相反⽅法。
⽰例: DELETE /example.html HTTP/1.1
特性:按请求URL删除指定的资源。
4.5 OPTIONS⽅法 被禁用
⽤途:⽤于查询针对请求URL指定的资源⽀持的⽅法。 ⽰例: OPTIONS * HTTP/1.1
特性:返回允许的⽅法,如GET、POST等。
五. 常见Header
Content-Type: 数据类型(text/html等)
Content-Length: Body的⻓度
Host: 客⼾端告知服务器, 所请求的资源是在哪个主机的哪个端⼝上;
User-Agent: 声明⽤⼾的操作系统和浏览器版本信息;
Referer: 当前⻚⾯是从哪个⻚⾯跳转过来的;
Location: 搭配3xx状态码使⽤, 告诉客⼾端接下来要去哪⾥访问;
Cookie: ⽤于在客⼾端存储少量信息. 通常⽤于实现会话(session)的功能
其中,除了最后一个,前面的 ,我们在源码都有使用和讲解,接下来注重讲解Cookie,在讲解之前,我们先讲解报头,谈谈连接问题
5.1connection报头
HTTP中的 Connection 字段是HTTP报⽂头的⼀部分,它主要⽤于控制和管理客⼾端与服务器之间
的连接状态
核心作用
管理持久连接: Connection 字段还⽤于管理持久连接(也称为⻓连接)。持久连接允许客⼾端
和服务器在请求/响应完成后不⽴即关闭TCP连接,以便在同⼀个连接上发送多个请求和接收多个响应。
5.1.2两种连接方式
短链接:HTTP/1.0:在HTTP/1.0协议中,默认连接是⾮持久的
一次请求对应一次 TCP 连接"。客户端发起请求,服务器建立连接并返回响应后,立刻关闭 TCP 连接,适用于早期互联网,加载资源较小时
如果1.0如要使用长连接,需要在报头加入
Connection: keep-alive
长连接:
- HTTP 1.1 的改进 :引入了
Connection: keep-alive机制,允许 TCP 连接被复用,处理多个连续的请求。但这只是对 "无连接" 的优化,而非改变协议本质 :
- 这个长连接是可选且有超时限制的,不是协议强制要求的;
- 连接的复用是为了提升性能(减少 TCP 三次握手的开销),但协议层面依旧不要求连接长期保持;
- 当没有新请求时,连接最终还是会被关闭,不会一直存在。
5.2 http是一个无连接,无状态的协议
http1.0和1.1有连接,为何http无连接
把 HTTP 协议 想象成 "打电话问问题" ,把 TCP 连接 想象成 "接通电话的这根线"。
如1.0
你给客服打电话(发起请求),客服接起(建立 TCP 连接),你问一个问题,客服答完,立刻挂电话(关闭 TCP 连接)
1.1
你给客服打电话,问完第一个问题,客服没挂,说 "你还有别的问题吗?我等你 30 秒"(TCP 连接复用)。你接着问第二个、第三个问题,都不用重新拨号。但如果 30 秒内你没再说话,客服还是会挂电话 ;而且这个 "不挂线等你",是额外的优化选项,不是客服的,但本质都是立刻挂断
无状态:服务器不会保存任何客户端的上下文信息,每个请求之间没有关联,都是独立的个体。
无状态 = 服务器 "记不住你",每次请求都是 "陌生人对话"
第一次请求 :你打电话说 "麻烦查下我尾号 1234 的银行卡余额"。客服(服务器)需要你提供身份证号、银行卡号(请求参数),核实后告诉你 "余额 5000 元",然后结束对话(响应完成)。这个过程里,客服不会在本子上记下 "这个人叫 xx,尾号 1234,余额 5000"。
第二次请求 :你紧接着又打电话说 "那我再查下这张卡的最近交易记录"。对 HTTP 协议来说,这是一个全新的、独立的请求------ 客服完全不知道你就是上一个查余额的人,会再次要求你提供身份证号、银行卡号,才能帮你查询。
5.3 解决http无状态带来的烦恼-Cookie
如果没有Cookie,你在视频软件刷完一个视频,都要登陆一次,
有了Cookie后,你第一次请求登录时,输入账号与密码,浏览器会进行保存
(Set-Cookie:name=XXX&&passward=XXXXXXX)
保存位置:
文件保存(可长期保存,关机一样)
内存里面(浏览器 也是一个进程,保存到自己的内存了)
5.4验证浏览器使用Cookie进行记录
我们可以发现我们登录b站的网页版后,之后无论是关掉当前页面,还是关掉浏览器,甚至是关机,下次打开时,都无需再进行登录,其实就是B站进行了保存,而且是保存在文件中
也确实如此
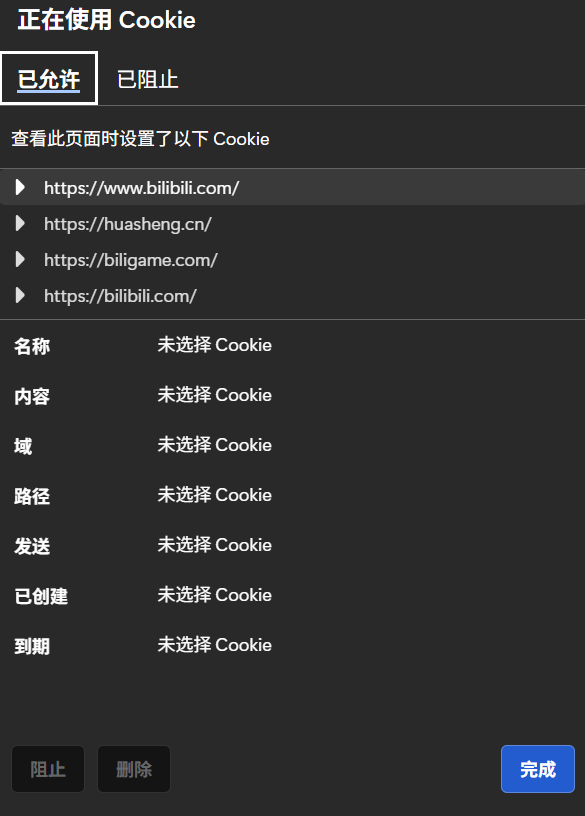
而如果不想浏览器记录,我们只需将文件删除即可
打开上面的Cookie,进行删除
5.5 解决Cookie导致的问题 session
但有了Cookie后,如果我们电脑中了木马病毒,当我们向服务端使用Cookie,存储的个人隐私信息向服务端发送请求时,黑客那边也可以拿到我们的Cookie文件,拿到我们的隐私信息, 并向服务器发送请求
解决办法:
以后我们进行登录等操作时,创建的Cookie文件放在服务器那边(比放本地更安全),而我们请求则创建一个session id,每个对应的服务器那边的一个数据,每次访问,都拿id进行访问
但看上面似乎还是无法解决黑客拿我们的信息访问啊
其实我们说的Cookie是有两个问题:1.被他人拿去访问 2.个人隐私信息泄漏
但有了session id后,我们的个人隐私信息存在了企业的服务器中,解决了该问题
而预防被他人非法登录
eg:微信 qq,当你登录时,上一秒ip还在北京,下一秒就在国外了,ip跨度太大了,一般企业都会进行检测
或者你的社交软件,一日内找了上百位许久未联系的人,也太过异常
等等
六 源码
bash
#pragma once
#include "Socket.hpp"
#include "TcpServer.hpp"
#include "Util.hpp"
#include "Log.hpp"
#include <iostream>
#include <string>
#include <memory>
#include <sstream>
#include <unordered_map>
#include <functional>
using namespace SocketModule;
using namespace LogModule;
const std::string gspace = " ";
const std::string glinespace = "\r\n";
const std::string glinesep = ": ";
const std::string webroot = "./wwwroot";
const std::string homepage = "index.html";
const std::string page_404 = "/404.html";
class HttpRequest
{
public:
HttpRequest()
{
}
std::string Serialize()
{
return std::string();
}
void ParseReqLine(std::string &reqline)
{
// GET / HTTP/1.1
std::stringstream ss(reqline);
ss >> _method >> _uri >> _version;
}
// 实现, 我们今天认为,reqstr是一个完整的http request string
bool Deserialize(std::string &reqstr)
{
// 1. 提取请求行
std::string reqline;
bool res = Util::ReadOneLine(reqstr, &reqline, glinespace);
LOG(LogLevel::DEBUG) << reqline;
// 2. 对请求行进行反序列化
ParseReqLine(reqline);
LOG(LogLevel::DEBUG) << "_method: " << _method;
LOG(LogLevel::DEBUG) << "_uri: " << _uri;
LOG(LogLevel::DEBUG) << "_version: " << _version;
const std::string temp = "?";
auto pos = _uri.find(temp);
if (pos == std::string::npos)
{
return true;
}
if (_uri == "/")
_uri = webroot + _uri + homepage; // ./wwwroot/index.html
else
_uri = webroot + _uri; // ./wwwroot/a/b/c.html
return true;
}
std::string Uri() { return _uri; }
~HttpRequest()
{
}
private:
std::string _method;
std::string _uri;
std::string _version;
std::unordered_map<std::string, std::string> _headers;
std::string _blankline;
std::string _text;
};
class HttpResponse
{
public:
HttpResponse() : _blankline(glinespace)
{
}
// 实现: 成熟的http,应答做序列化,不要依赖任何第三方库!
std::string Serialize()
{
std::string status_line = _version + gspace + std::to_string(_code) + gspace + _desc + glinespace;
std::string resp_header;
for (auto &header : _headers)
{
std::string line = header.first + glinesep + header.second + glinespace;
resp_header += line;
}
return status_line + resp_header + _blankline + _text;
}
void SetTargetFile(const std::string &target)
{
_targetfile = target;
}
void Setcode(int code)
{
_code = code;
switch (_code)
{
case 200:
_desc = "OK";
break;
case 301:
_desc = "Move Temp";
break;
case 302:
_desc = "Set Other";
break;
case 404:
_desc = "Not Found";
break;
default:
break;
}
}
void SetHeader(std::string key, std::string value)
{
auto iter = _headers.find(key);
if (iter != _headers.end())
return;
_headers.insert(make_pair(key, value));
}
std::string UriTo(std::string x)
{
auto pos = x.rfind(".");
if (pos != std::string ::npos)
{
return "text/html";
}
std::string suffix = x.substr(pos);
if (suffix == ".html" || suffix == ".htm")
return "text/html";
else if (suffix == ".jpg")
return "image/jpeg";
else if (suffix == "png")
return "image/png";
else
return "";
}
bool MakeResponse()
{
if (_targetfile == "./wwwroot/favicon.ico")
{
LOG(LogLevel::DEBUG) << "用户请求: " << _targetfile << "忽略它";
return false;
}
if (_targetfile == "./wwwroot/redir_test")
{
Setcode(301);
SetHeader("Location", "https://www.qq.com/");
return true;
}
int filesize = 0;
bool res = Util::ReadFileContent(_targetfile, &_text); // 浏览器请求的资源,一定会存在吗?出错呢?
if (!res)
{
Setcode(404);
_targetfile = webroot + page_404;
filesize = Util::FileSize(_targetfile);
SetHeader("Content-Length", std::to_string(filesize));
bool res = Util::ReadFileContent(_targetfile, &_text); // 浏览器请求的资源,一定会存在吗?出错呢?
}
else
{
Setcode(200);
filesize = Util::FileSize(_targetfile);
SetHeader("Content-Type: ", UriTo(_targetfile));
SetHeader("Content-Length: ", std::to_string(filesize));
SetHeader("Set-Cookie:","username:lisi passwardz=123456;");
}
return true;
}
bool Deserialize(std::string &reqstr)
{
return true;
}
~HttpResponse() {}
// private:
public:
std::string _version;
int _code; // 404
std::string _desc; // "Not Found"
std::unordered_map<std::string, std::string> _headers;
std::string _blankline;
std::string _text;
// 其他属性
std::string _targetfile;
};
using http_func_t = std::function<void(HttpRequest &req, HttpResponse &resp)>;
// 1. 返回静态资源
// 2. 提供动态交互的能力
class Http
{
public:
Http(uint16_t port) : tsvrp(std::make_unique<TcpServer>(port))
{
}
void HandlerHttpRquest(std::shared_ptr<Socket> &sock, InetAddr &client)
{
// 收到请求
std::string httpreqstr;
// 假设:概率大,读到了完整的请求
// bug!
int n = sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.
if (n > 0)
{
// 对报文完整性进行审核 -- 缺
HttpRequest req;
req.Deserialize(httpreqstr);
HttpResponse resp;
resp.SetTargetFile(req.Uri());
resp.MakeResponse();
// HttpResponse resp;
// resp._version = "HTTP/1.1";
// resp._code = 200; // success
// resp._desc = "OK";
// //./wwwroot/a/b/c.html
// LOG(LogLevel::DEBUG) << "用户请求: " << filename;
// bool res = Util::ReadFileContent(filename, &(resp._text)); // 浏览器请求的资源,一定会存在吗?出错呢?
// (void)res;
std::string response_str = resp.Serialize();
sock->Send(response_str);
}
// #ifndef DEBUG
// #define DEBUG
#ifdef DEBUG
// 收到请求
std::string httpreqstr;
// 假设:概率大,读到了完整的请求
sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.
std::cout << httpreqstr;
// 直接构建http应答. 内存级别+固定
HttpResponse resp;
resp._version = "HTTP/1.1";
resp._code = 200; // success
resp._desc = "OK";
std::string filename = webroot + homepage; // "./wwwroot/index.html";
bool res = Util::ReadFileContent(filename, &(resp._text));
(void)res;
std::string response_str = resp.Serialize();
sock->Send(response_str);
#endif
// 对请求字符串,进行反序列化
}
void Start()
{
tsvrp->Start([this](std::shared_ptr<Socket> &sock, InetAddr &client)
{ this->HandlerHttpRquest(sock, client); });
}
void RegisterService(const std::string name, http_func_t h)
{
std::string key = webroot + name; // ./wwwroot/login
auto iter = _route.find(key);
if (iter == _route.end())
{
_route.insert(std::make_pair(key, h));
}
}
~Http()
{
}
private:
std::unique_ptr<TcpServer> tsvrp;
std::unordered_map<std::string, http_func_t> _route;
};