上篇文章:滑动窗口算法精解:水果成篮与字母异位词
目录
1.串联所有单词的子串
https://leetcode.cn/problems/substring-with-concatenation-of-all-words/

理解题意
本题与上篇文章中的题目有异曲同工之处:
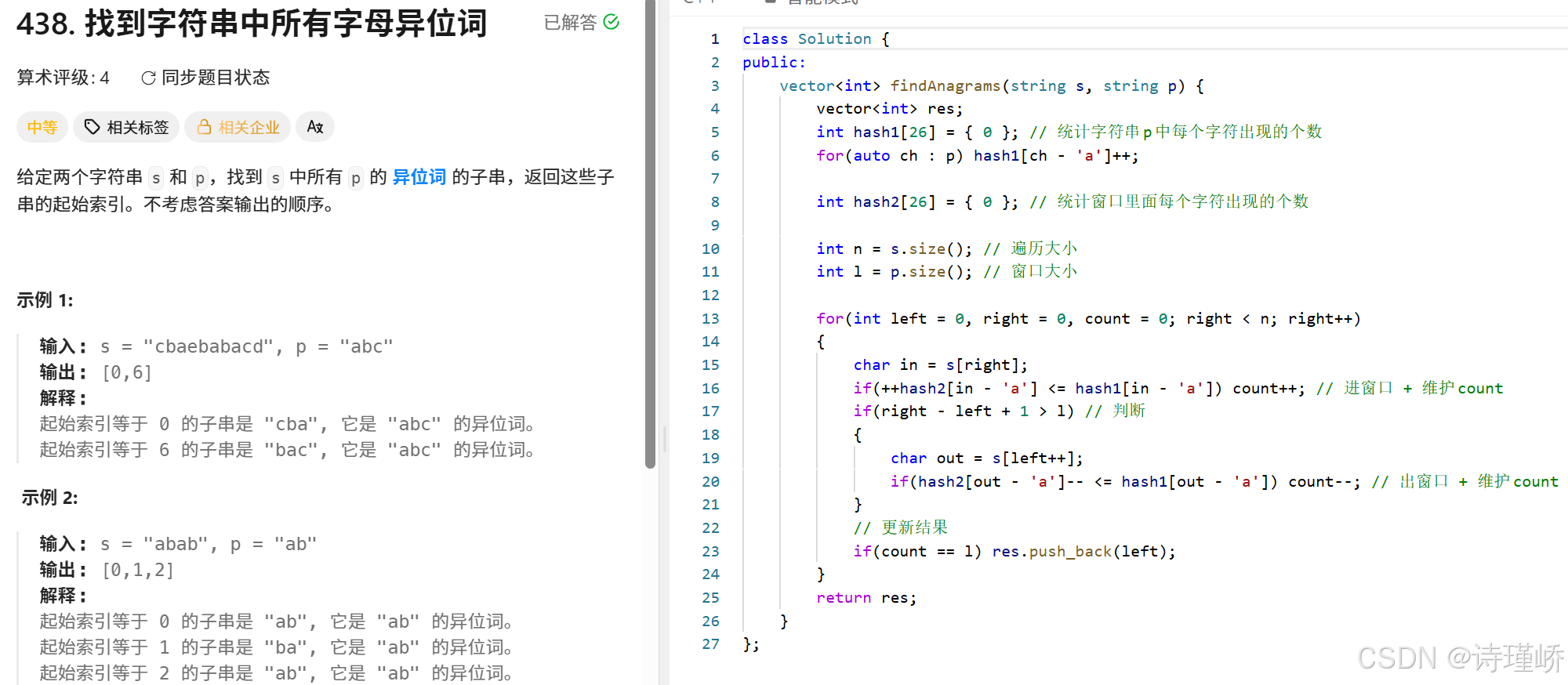
不同点在于:本题需要使用hash<string, int>进行字符串的存储,并且words中每个字符串长度相同,所以每次left与right移动距离都为单个字符串的长度。并且滑动窗口总共执行len次。
算法原理
核心思想是多起点的固定大小滑动窗口结合哈希表。
1.构建目标哈希表:首先遍历 words 数组,将所有单词及其频次记录在 hash~words 中。获取单词长度 len 和单词总数m
2.多起点遍历:由于单词长度为 len,以 s 中不同索引开始的划分方式共有len 种(即从 0,1,...,len- 1 开始)。因此外层循环执行 len 次。
3.维护窗口哈希表与count:在每次内层滑动窗口中:
维护一个当前窗口的哈希表hash,以及一个记录"有效单词数量"的变量count。
进窗口:每次截取 right 处长度为 len 的单词 in 加入 hash。如果加入后该单词的频次仍然<=hash~words [in],说明这是一个"有效"单词,count++。
判断与出窗口:当窗口的跨度 right-left + 1 〉len *m 时,说明窗口内包含了超过 m 个单词,需要将左端点的单词 out 移出窗口。出窗口时,如果移出前该单词是"有效"的(hashout] 〈= hash\~words\[out ),则count--,随后更新 hash left 右移 len 步。
更新结果:如果在某一时刻,窗口内有效单词数 count == m,说明刚好凑齐了所有单词,将此时的 left 加入结果数组ret。
优化点解析:代码中通过引l入count变量来记录当前窗口内的"有效单词数"。这样每次窗口滑动时,只需O(1)的时间去更新和判断count是否等于m,而不需要每次都去遍历对比两个哈希表是否完全相等,大大降低了时间复杂度。
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> ret;
unordered_map<string, int> hash_words; // 保存words中所有单词的频次
int len = words[0].size(),
m = words.size(); // words中一个单词的长度和words中字符串个数
for (auto& str_word : words)
hash_words[str_word]++; // 遍历words所有字符并放入hash表
for (int i = 0; i < len; i++) // 执行len次
{
unordered_map<string, int> hash; // 维护窗口内字符串的频次
for (int left = i, right = i, count = 0; right + len <= s.size(); right += len)
// 细节:每次right+len,最后一个单词剩下的位数会遗漏,所以为right + len
{
// 进窗口 + 维护count
string in = s.substr(right, len);
if(++hash[in] <= hash_words[in])
count++;
// 判断
if (right - left + 1 > (len * m)) {
// 出窗口 + 维护count
string out = s.substr(left, len);
if (hash[out]-- <= hash_words[out])
count--;
left += len;
}
// 更新结果
if (count == m)
ret.push_back(left);
}
}
return ret;
}
};优化:
2.最小覆盖子串
https://leetcode.cn/problems/minimum-window-substring/
理解题意

1.子串中的字符顺序无所谓,只要字符的种类和对应的数量都不小于(t)中的要求即可(即"覆盖")。
2.我们要找的是满足条件的最短子串。
算法原理
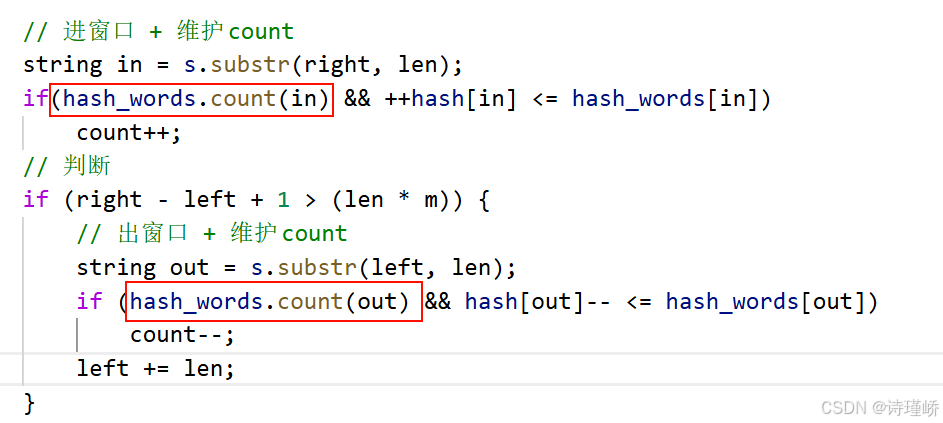
核心思想是变长滑动窗口结合数组模拟哈希。
1.数组模拟哈希表:因为题目说明是由英文字母构成(或包含ASCII字符),直接使用两个大小为128的数组 hasht 和 hash 分别代替哈希表来统计字符频次,这比使用unordered_map 会极大提升访问速度。
- 统计目标信息:遍历目标串t,填充 hasht。同时用 kinds 变量记录 t 中有效字符的种类总数。
3.进窗口:利用双指针 left 和 right 划定窗口。right 指针主动向右遍历,将新字符 in 放入当前窗口哈希表 hash 中。
- 维护有效字符种类count :当且仅当加入字符后 hashin] == hasht\[in 时,说明某个字符的数量刚好达到了t)中的要求,此时当前窗口满足条件的字符种类数count 增加 1。
5.判断与出窗口(核心收缩逻辑):
当count == kinds 时,说明当前窗口已经包含了t 的所有字符,是一个"覆盖子串"。
此时,首先更新结果(比较并记录最小长度minLen 和起点 begin )。
然后尝试优化(缩小)窗口:将left 指向的字符out 移出窗口。如果移出后hash[out]<hasht[out],说明移除了不可或缺的字符,此时count--,窗口不再合法,退出循环继续移动right;否则说明移出的是冗余字符,left 继续向右收缩寻找更短的有效子串。
6.返回结果:遍历完成后,如果begin 未被修改过说明没找到合法子串,返回空字符串;否则使用substr 截取并返回。
class Solution {
public:
string minWindow(string s, string t)
{
int hasht[128] = { 0 }; // 统计字符串t中字符出现的频次
int kinds = 0; // 统计有效字符种类
for(auto str : t)
if(hasht[str]++ == 0) kinds++;
int hash[128] = { 0 }; // 统计窗口内字符出现的频次
int minLen = INT_MAX, begin = -1;
for(int right = 0, left = 0, count = 0; right < s.size(); right++)
{
// 进窗口 + 维护count
char in = s[right];
if(++hash[in] == hasht[in]) count++;
// 判断
while(count == kinds)
{
// 更新结果
if(right - left + 1 < minLen)
{
minLen = right - left + 1;
begin = left;
}
// 出窗口
char out = s[left++];
if(hash[out]-- == hasht[out]) count--;
}
}
if(begin == -1) return "";
else return s.substr(begin, minLen);
}
};本章完。