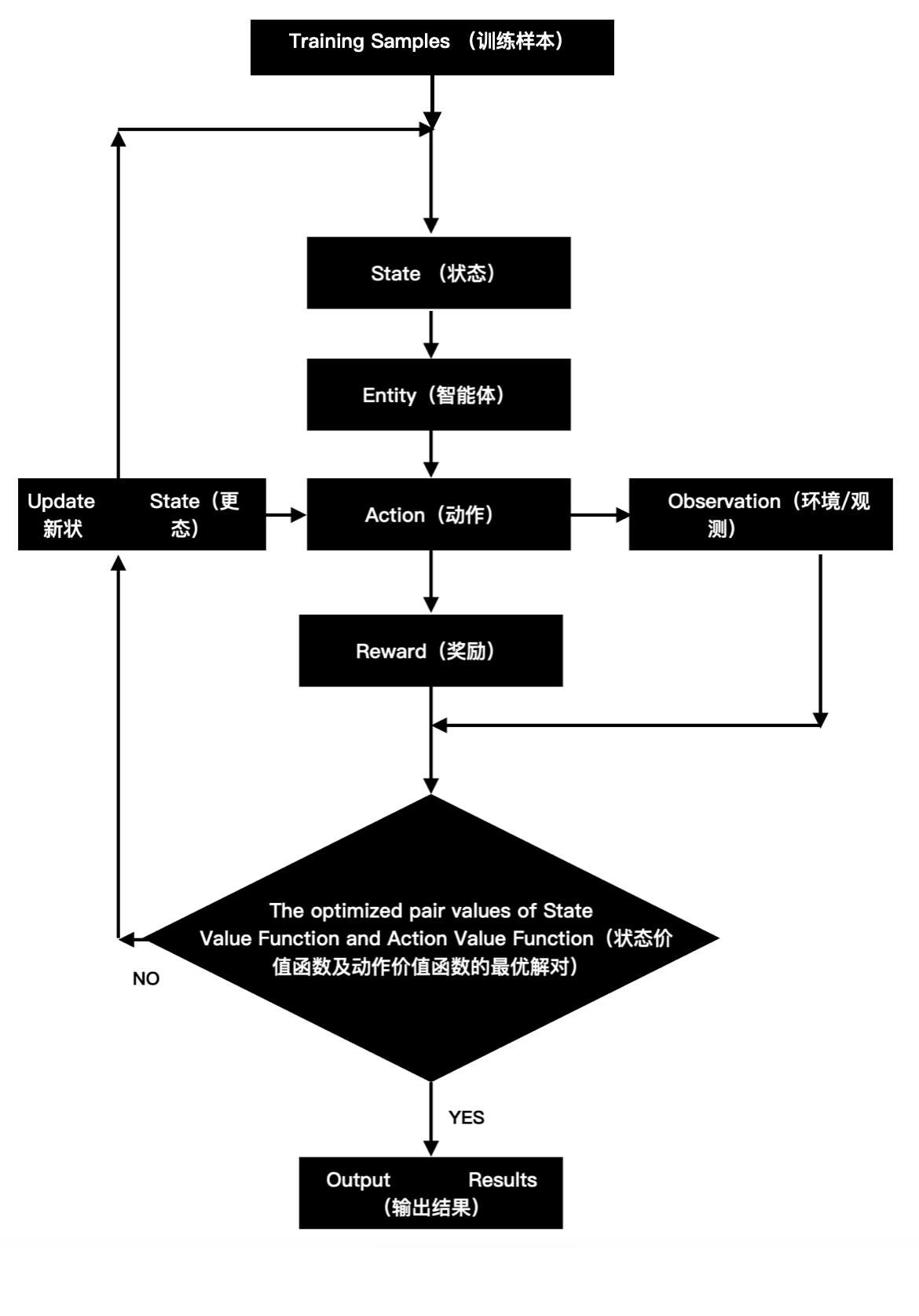
在强化学习中,智能体(agent)在一系列的事件步骤上与环境交互。在每个特定时间点,智能体从环境结构一些观测(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中得到奖励(reward)。注意,强化学习的目标是产生一个好的策略(policy)。强化学习智能体选择的"动作"受策略控制,即从一个环境观测映射到动作的功能。
当环境可被完全观测到时,强化学习问题被称为马尔可夫决策过程(Markov Decision Process)。它的核心是无后效性(Memorylessness),未来的状态仅依赖于当前状态和动作,与"过去的状态/动作序列"无关。这种性质让MDP的计算变得可行,它无需存储历史信息。当状态不依赖之前的动作时,我们称该问题为上下文老虎机(contextual bandit problem)。当没有状态,只有一组最初未知奖励的可用动作时,这个问题就是经典的多臂老虎机(multi-armed bandit problem)。
如下图所示:
参考文献:
1 《动手学深度学习PyTorch版》