FineInstructions: Scaling Synthetic Instructions to Pre-Training Scale
Authors: Ajay Patel, Colin Raffel, Chris Callison-Burch
Deep-Dive Summary:
FineInstructions: 将合成指令扩展至预训练规模
摘要
由于监督训练数据有限,大语言模型(LLMs)通常通过自监督的"预测下一个词"目标在大量非结构化文本数据上进行预训练。为了使得到的模型对用户有用,通常需要在一个规模小得多的"指令微调"数据集上进行进一步训练。为了克服监督数据有限的问题,我们提出了一种程序,可以将互联网规模的预训练文档转化为数十亿个合成指令和回答训练对。生成的名为 FineInstructions 的数据集使用了约 18 M 18\mathrm{M} 18M 个根据真实用户查询和提示创建的指令模板。这些指令模板与来自非结构化预训练语料库的人类编写源文档进行匹配并实例化。通过这种规模生成的"监督"合成训练数据,LLM 可以完全通过指令微调目标从头开始预训练,这与 LLM 的预期下游用途(响应用户提示)更加一致。我们进行了受控的等量 Token 训练实验,发现 FineInstructions 的预训练效果在衡量自由形式响应质量的标准基准测试中优于标准预训练和其他提出的合成预训练技术。
1. 引言
在自监督预训练期间,LLM 使用语言建模任务(如对大量文本数据进行下一个 Token 预测)进行训练。这个阶段是模型获取绝大部分知识的地方,也是消耗绝大部分计算、资源和时间的地方。
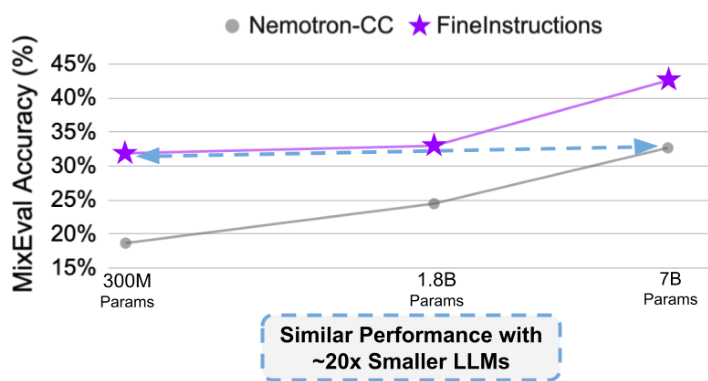
图 1. 在 FineInstructions 数据上进行预训练的效率。
预训练后的 LLM 可以通过在相对较少量的监督指令-回答示例上进行进一步训练(即指令微调),从而获得更好的指令遵循能力。现有的指令微调数据集存在各种问题:规模小、任务单一或过于依赖前沿模型生成的蒸馏数据,这导致预训练阶段仍需承担编码绝大部分知识的重任。
除了编码知识外,预训练语料库还可以通过间接监督帮助模型执行任务。然而,目前尚不清楚预测下一个 Token 是否是模型吸收这些能力的最优方式。最近提出的合成改写和转换流程表明,将原始预训练文档转换为其他格式可以提高预训练期间知识吸收的效率。
本文介绍了 FineInstructions 程序(如图 2 所示),它将预训练语料库转换为大型、多样化且现实的指令-响应对集合。我们将文档与用户可能提出的查询进行匹配,并提取基于文档的回答。
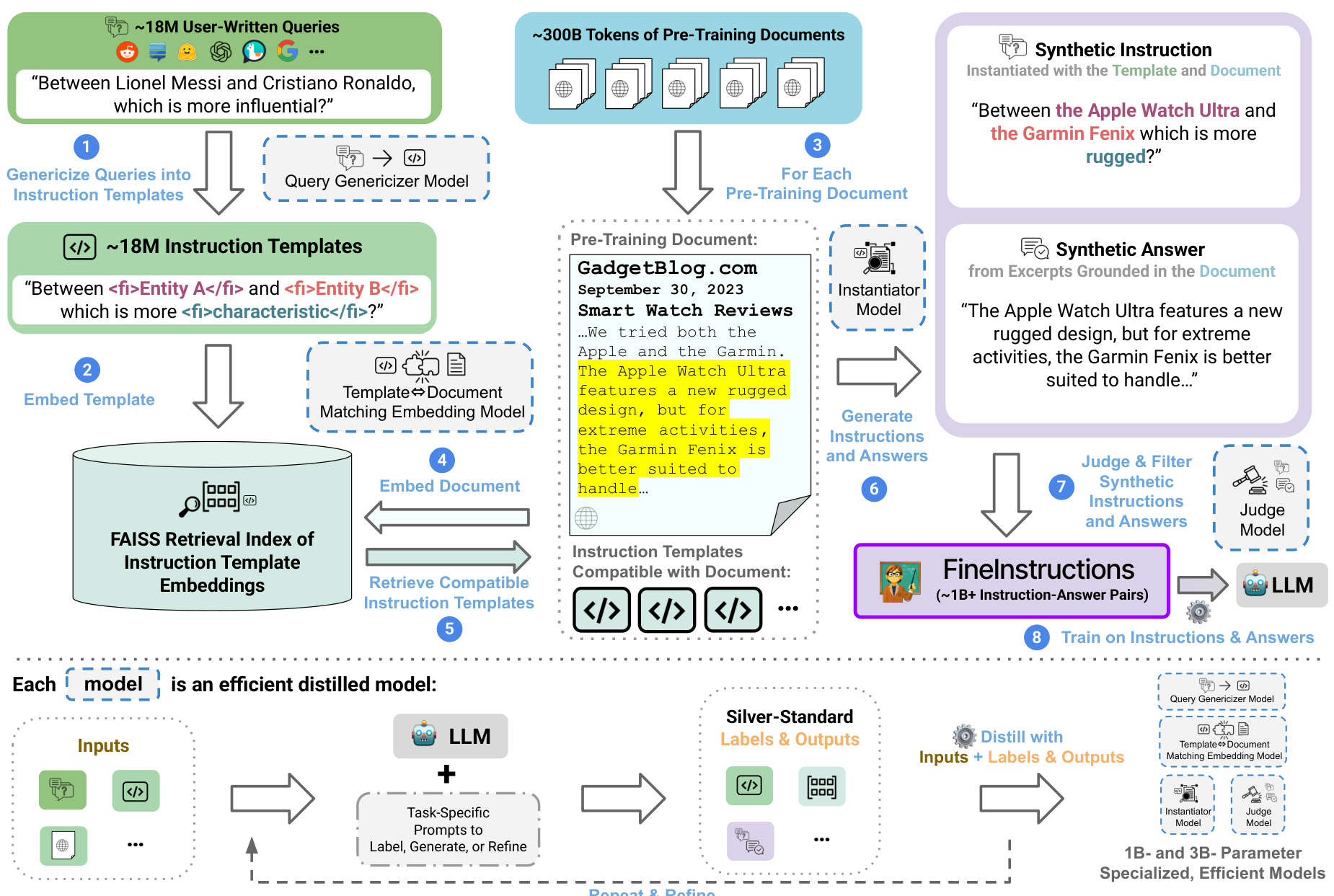
图 2. FineInstructions 流程:高效生成多样化、预训练规模的合成指令-回答对。
这种重构有助于知识吸收,防止计算预算浪费在文档中的低质量噪声(如页眉页脚)上。本文的贡献包括:
- 创建了 18 M 18\mathrm{M} 18M 个基于真实用户查询的指令模板。
- 引入了 FineInstructions 转换程序。
- 证明了仅在 FineInstructions 上训练的效果优于标准预训练和其它合成转换流水线。
- 发布了代码、模型和包含 1 B + 1\mathrm{B}+ 1B+ 指令-回答对的数据集。
2. 相关工作
先前的研究探索了在预训练中加入合成数据、过滤文档、重新加权文档混合比例或将原始文档转换为指令格式。与之前使用数百到数千个手工或众包模板的方法相比,我们的方法在模板数量(达千万级)、多样性和训练实例规模上都具有显著优势。
3. FineInstructions
FineInstructions 流程将用户编写的查询转换为通用的指令模板,并将其与预训练文档匹配。该流程类似于弱监督程序,利用大量指令模板和现有模型从非结构化文本中提取监督数据。我们使用 DataDreamer 框架生成银标准数据,并使用 Llama-3.3 70B Instruct 辅助生成。
3.1 生成指令模板
我们从 WildChat、LMSys Chat、Reddit QA 等多个数据源收集真实的用户查询,并过滤有害内容。通过将查询中的特定实体替换为标签 < f i > < / f i > < \mathrm{fi} > < / \mathrm{fi} > <fi></fi>(内含描述),将其转化为通用模板。我们训练了一个 Llama-3.2 1B 的"查询泛化模型"来执行此任务,最终生成了 18 M 18\mathrm{M} 18M 个模板及其对应的兼容文档描述。
3.2 文档与指令模板匹配
我们使用 BGE-M3 嵌入模型构建检索索引。为了处理长文档并确保覆盖范围,我们引入了**高斯池化(Gaussian Pooling)**层。
针对文档覆盖的高斯池化:
除了全局平均池化外,我们还生成多个"局部"嵌入。假设 H = h 1 , ... , h T H = h_1, \\ldots , h_T H=h1,...,hT 为 Token 嵌入序列, K K K 为高斯核数量(本文取 K = 5 K=5 K=5), ρ k = k K + 1 \rho_k = \frac{k}{K + 1} ρk=K+1k 为归一化位置, σ \sigma σ 为宽度参数。高斯加权池化允许我们检索与长文档中不同章节相关的模板。我们在 FineInstructions 数据集中发现,检索到的回答片段位置与高斯块索引之间存在 0.99 的皮尔逊相关性。
在检索时,我们设定余弦相似度阈值为 0.865,并根据真实世界查询的复杂度分布进行加权随机采样,以保证模板的多样性。
3.3 生成指令和回答
对于每个匹配对,我们使用 LLM 实例化模板并提取文档中的相关片段作为答案。为了保证真实性,我们要求生成答案中引用的文本比例 ≥ 0.80 \geq 0.80 ≥0.80。为了降低计算成本,模型通过生成包含省略号的专用标签(如 <excerpt>...</excerpt>)来指示直接复制的文本,随后再通过程序展开。
3.4 评审与过滤
我们使用 3.8B 参数的 Flow Judge 模型作为评审员,根据 5 分制李克特量表对合成对进行评分,仅保留得分 ≥ 4 \geq 4 ≥4 的高质量指令-回答对。
4. 实验设置
我们评估了从头开始在 FineInstructions 上训练是否能提高模型性能。
4.1 基准方法
- 标准预训练: 在原始非结构化文档上训练。
- IPT (Instruction Pre-Training): 使用指令合成器将文档转换为 Q&A 对。
- Nematron-CC: 包含改写(WRAP)、生成 Q&A 以及提取核心知识等任务的混合数据。
4.2 预训练
我们在控制 Token 数量一致的前提下,在 23 B 23\mathrm{B} 23B 和 300 B 300\mathrm{B} 300B 规模的语料库上分别训练了 1.8B 参数的模型,使用了 Llama-3 分词器。
4.3 评测基准
- MixEval: 衡量知识吸收情况,与人类判断高度相关。
- MT-Bench-101: 衡量模型响应真实用户查询(建议、写作等)的能力。
- AlpacaEval: 衡量真实任务下的胜率,并修正长度偏见。
5. 结果
结果如表 1 所示。FineInstructions 在所有基准测试中均优于标准预训练和其他合成基准。
表 1. 1.8B 参数模型在 FineInstructions 及各基准方法上的性能。
| 方法 | MixEval Acc (%) (标准/困难) | MT-Bench-101 分数 | AlpacaEval FI 胜率 % |
|---|---|---|---|
| IPT 语料库 (23B) | |||
| 标准预训练 | 17.8 / 14.0 | 1.9 | 73.6% |
| IPT | 19.8 / 16.7 | 2.4 | 68.2% |
| FineInstructions | 31.7 / 19.2 | 2.8 | - |
| Nemotron-CC 语料库 (300B) | |||
| 标准预训练 | 24.0 / 17.1 | 3.5 | 63.6% |
| WRAP | 22.8 / 18.4 | 3.6 | 65.1% |
| Q&A | 27.1 / 18.9 | 3.4 | 76.1% |
| Nemotron-CC | 24.5 / 16.7 | 3.6 | 65.9% |
| FineInstructions | 33.0 / 21.8 | 3.9 | - |
在 IPT 数据集上,相比标准预训练,MixEval 的相对提升达 ∼ 69 % \sim 69\% ∼69%。此外,在 AlpacaEval 上,FineInstructions 始终被优先选择。这表明 FineInstructions 在知识类任务和开放式任务中都能产生更好的一致泛化能力。我们还在不同参数规模(300M, 1.8B, 7B)下验证了这种优势,证明其是生产高效小型语言模型的理想技术。
6. 讨论
本节对指令的多样性进行了分析,讨论了评审阶段的消融实验,并概述了未来的研究方向。
以下是该学术论文相关章节的详细中文摘要:
6.1 指令的多样性(Diversity of Instructions)
研究团队对生成的指令进行了分析,以确保其具有足够的多样性,避免某些指令模板过度代表。研究旨在平衡通用性强的简单指令(如"请简述某个主题")和针对特定文档的长尾指令(如"请提供将文件从格式#1转换为格式#2的免费应用")。
在对 Nemotron 预训练基础数据集进行处理时,研究者使用了 430 万个唯一的指令模板来实例化约 1.08 B 1.08\mathrm{B} 1.08B(10.8 亿)条总指令。分析发现:
- 没有任何单一指令模板占比超过生成指令总数的 0.09 % 0.09\% 0.09%。
- 大多数指令模板实例化的指令数量少于 1,000 条,这表明数据在任务和格式上具有高度多样性。
- 预训练文档数量( x x x)与至少被使用一次的唯一指令模板数量( y y y)之间存在幂律关系,近似公式为: y = 16 , 891 ∗ x 0.24 y = 16,891 * x^{0.24} y=16,891∗x0.24 且 r 2 = 0.96 r^2 = 0.96 r2=0.96。
- 指令来源分布:约 50 % 50\% 50% 源自 GooAQ,Reddit QA 约占 27 % 27\% 27%,LMSys Chat 约占 9 % 9\% 9%,WildChat 约占 6 % 6\% 6%,其他来源均 ≤ 1 % \leq 1\% ≤1%。
研究者还使用 Llama-3.3 70B Instruct 模型通过零样本(zero-shot)提示词将指令模板分类到不同的领域(如科学、数学、代码、医学等)。
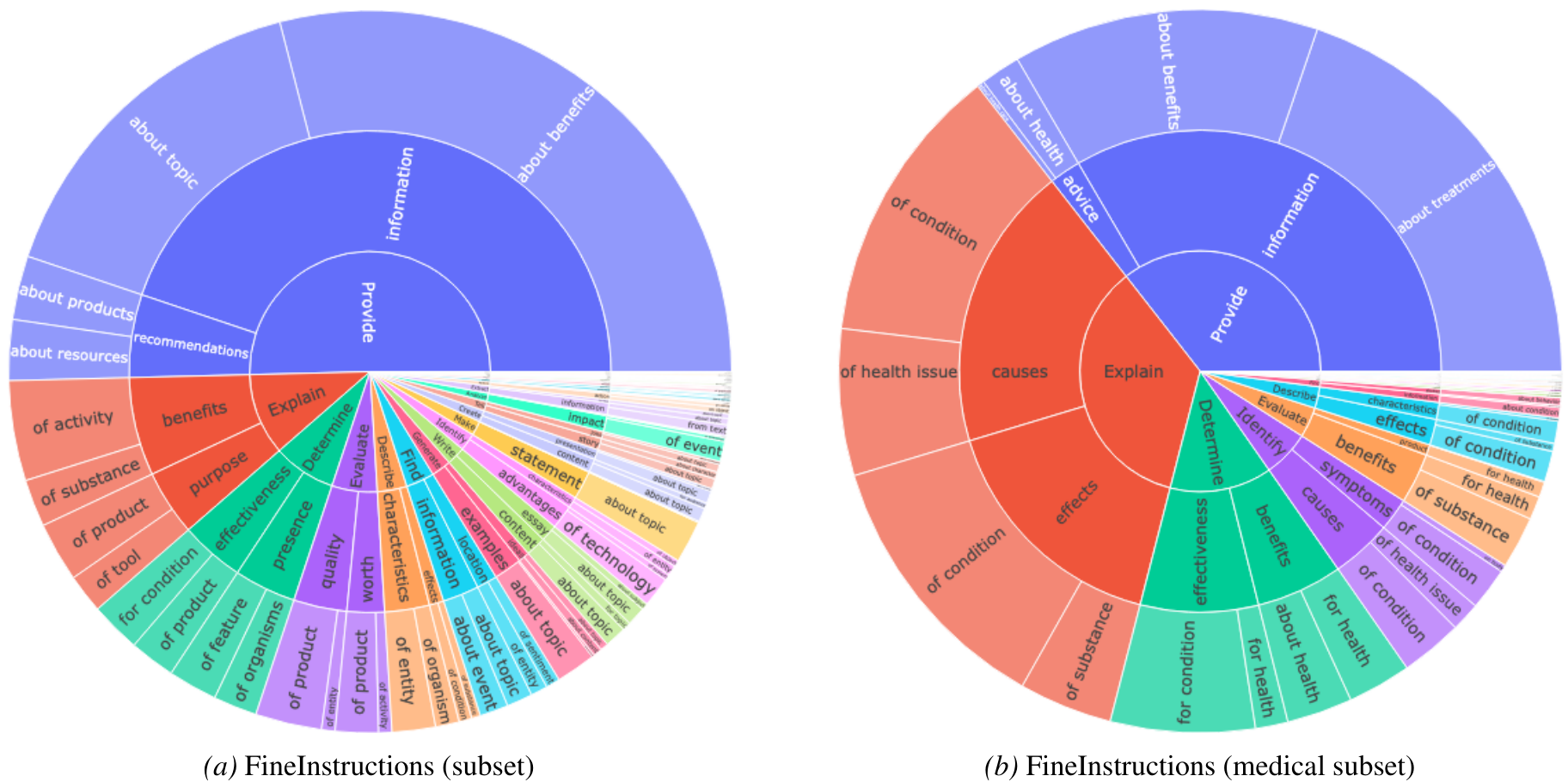
图 3:FineInstructions 中任务多样性的可视化。图中还展示了领域特定的多样性(以医学相关模板为例)。图表可从内环向外环读取每个"切片"的信息。
此外,研究还定义了分类标准来衡量指令是否需要知识推理(如对比两个实体),以及指令是否具有"趣味性"(如写一篇媒体评论)而非简单的知识召回问答。最后,利用 LLM 为每个指令模板生成简短的任务描述,并以旭日图形式展示(见图 3)。
6.2 评判与过滤的效果(Effect of Judging and Filtering)
研究者通过消融实验验证了最终阶段"评判与过滤"的作用。通过对比有无该阶段的预训练结果,发现这一阶段能进一步提升模型性能,尤其是在 AlpacaEval 基准测试上表现显著。
6.3 局限性与未来方向(Limitations and Future Directions)
FineInstructions 流程仍有优化空间,例如源查询分布、嵌入匹配的校准以及采样权重都会影响生成指令的组成和复杂度。研究观察到一个常见的失败模式:复杂的模板难以准确匹配和实例化。将模型规模扩展到 3B 以上可能会在处理复杂模板和长文档时表现更强。
此外,研究发现目前缺乏针对真实长尾任务(如建议、忠告等)的基准测试,现有的多侧重于事实检索。由于该方法生成的模型倾向于生成长答案,因此基于对数概率(log probability)的分类评估方法不再适用,建议使用抽取式评估或 LLM-as-judge 的评分方式。
7 结论(Conclusion)
FineInstructions 提供了一个有效的流水线,将真实的用户查询转化为模板,从而大规模生成分布内(in-distribution)的合成数据。实验证明,该数据可有效地以"指令对齐"格式训练 LLM,而非传统的"预测下一个 token"的自监督方式。通过改变学习目标和预训练数据结构,该方法使模型能更好地反映下游使用模式,并提高知识吸收效率。
致谢与影响声明(Acknowledgements & Impact Statement)
研究得到了 Hugging Face 提供的计算和存储资源支持,以及 DARPA 的资金支持。
在影响声明中,作者指出该工作通过合成数据提高了训练效率。为缓解合成数据可能带来的偏见和幻觉,研究通过从源文档中提取近乎精确的摘录,主要利用模型进行格式转换而非内容生成,从而降低了幻觉风险。
Original Abstract: Due to limited supervised training data, large language models (LLMs) are typically pre-trained via a self-supervised "predict the next word" objective on a vast amount of unstructured text data. To make the resulting model useful to users, it is further trained on a far smaller amount of "instruction-tuning" data comprised of supervised training examples of instructions and responses. To overcome the limited amount of supervised data, we propose a procedure that can transform the knowledge in internet-scale pre-training documents into billions of synthetic instruction and answer training pairs. The resulting dataset, called FineInstructions, uses ~18M instruction templates created from real user-written queries and prompts. These instruction templates are matched to and instantiated with human-written source documents from unstructured pre-training corpora. With "supervised" synthetic training data generated at this scale, an LLM can be pre-trained from scratch solely with the instruction-tuning objective, which is far more in-distribution with the expected downstream usage of LLMs (responding to user prompts). We conduct controlled token-for-token training experiments and find pre-training on FineInstructions outperforms standard pre-training and other proposed synthetic pre-training techniques on standard benchmarks measuring free-form response quality. Our resources can be found at https://huggingface.co/fineinstructions .
PDF Link: 2601.22146v1
部分平台可能图片显示异常,请以我的博客内容为准
