引言
在上一篇文章中,我们通过 Todo List 项目体验了 Claude Code 的强大能力。你可能会好奇:为什么 Claude Code 能如此"聪明"地理解需求、规划任务、执行操作?它是如何在不同文件间穿梭自如,记住上下文,并在出错时自我修复的?
理解这些原理并不是为了"炫技",而是为了更好地使用工具。就像开车,你不需要成为汽车工程师,但了解发动机、变速箱的基本原理,能让你更好地驾驭车辆,出现问题时也能快速判断根因。
本文将深入 Claude Code 的"引擎室",解析其核心架构和工作机制。阅读本文后,你将能够:
- 理解为什么 Claude Code 有时会"忘记"之前的内容(上下文管理)
- 知道如何让 Claude Code 更高效地工作(合理使用工具)
- 掌握 Agent 的协作模式(什么时候自动调用子 Agent)
- 优化开发体验(避免常见陷阱,提升响应速度)
让我们从一个真实场景开始:
场景:你让 Claude Code 重构一个大型项目,它先用 Glob 搜索所有相关文件,然后逐个 Read 文件内容,接着开始修改代码...突然,你发现它"忘记"了最开始分析的架构设计,开始做一些不符合预期的修改。
这不是 Bug,而是上下文管理的必然结果。理解了这一点,你就能调整使用策略,避免这类问题。
一、Claude Code 的整体架构
1.1 核心架构设计
Claude Code 采用分层架构,每一层各司其职:
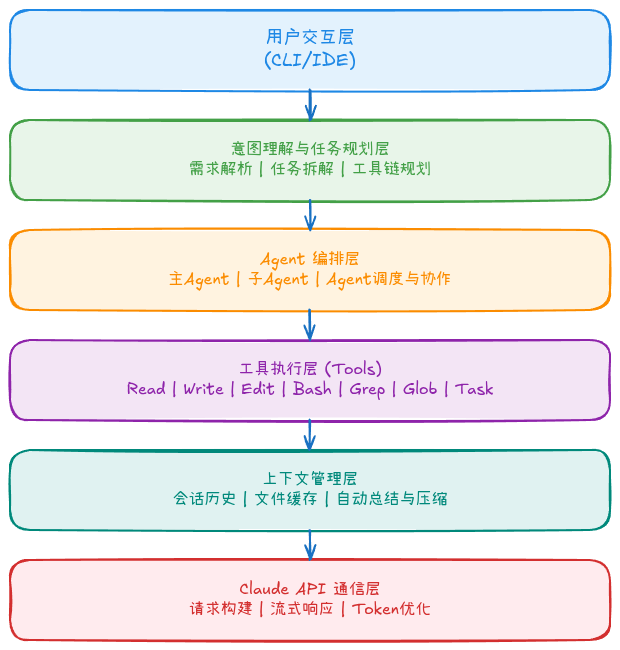
图1: Claude Code 分层架构设计,展示了从用户输入到 API 调用的完整数据流
为什么这样设计?
- 意图理解与工具执行分离:让 AI 专注于"想做什么",而不是"怎么做"
- Agent 编排层实现灵活扩展:可以随时添加新的专业 Agent
- 上下文管理独立:优化 Token 使用,提升响应速度
- 工具层标准化:所有工具遵循统一接口,易于扩展
1.2 架构的实际影响
场景 1:为什么 Claude Code 能处理大型项目?
传统 AI 助手通常有上下文长度限制(如 8K tokens),一个稍大的文件就会超限。Claude Code 通过:
- 按需加载:只读取必要的文件
- 智能总结:对长文件进行摘要
- 分层缓存:频繁访问的内容优先保留
这样即使项目有上千个文件,也能高效处理。
场景 2:为什么有时响应很慢?
当你的请求触发了以下行为,响应会变慢:
- 调用多个子 Agent(如先 Explore 再 Plan)
- 读取大量文件(每次 Read 都是 API 调用)
- 执行耗时命令(如 npm install)
理解这一点,你就知道如何优化:明确指定文件路径,而不是让它全局搜索。
1.3 与其他 AI 工具的架构对比
| 工具 | 架构模式 | 工具调用 | 上下文管理 |
|---|---|---|---|
| Claude Code | 分层 Agent 架构 | 丰富工具链 | 智能压缩 + 缓存 |
| GitHub Copilot | IDE 插件模式 | 无独立工具 | 仅当前文件 |
| Cursor | IDE 集成 + Agent | 部分工具支持 | 项目级上下文 |
| ChatGPT | Web 对话 | 无系统工具 | 纯对话历史 |
Claude Code 的架构优势在于:完整的任务闭环能力------从理解需求到执行验证,全程自动化。
二、上下文管理:Claude Code 的记忆系统
2.1 什么是上下文?
在 AI 对话中,**上下文(Context)**包括:
- 对话历史:你和 Claude Code 的所有交互记录
- 文件内容:读取过的代码、配置文件
- 命令输出:执行命令的结果
- 项目元信息:技术栈、目录结构、依赖关系
Claude Code 需要在有限的 Token 预算内(如 200K tokens)管理这些信息。
2.2 上下文管理策略
策略 1:分层优先级
Claude Code 对上下文内容设置不同优先级:
高优先级 (Always Keep):
- 用户当前输入
- 最近 3 轮对话
- 正在编辑的文件
- 任务列表 (Todo List)
中优先级 (Conditionally Keep):
- 最近读取的文件(10分钟内)
- 相关代码片段
- 命令执行结果
低优先级 (Can Be Summarized):
- 早期对话历史
- 已完成的任务
- 大型文件的完整内容实际影响:
你可能遇到过这种情况:
用户: 帮我重构用户认证模块
[Claude 分析了 10 个文件,制定了方案]
用户: (10分钟后) 现在实现第一步
[Claude: "请问你希望重构哪个模块?"]这是因为早期的对话被总结压缩了,细节丢失。解决方法:
- 保持连续对话,不要中断太久
- 关键信息写入
claude.md或 Todo List
策略 2:智能总结与压缩
当上下文接近 Token 限制时,Claude Code 会:
-
自动触发总结:
[System] Context approaching limit (180K/200K tokens) [System] Summarizing conversation... [System] Preserved key information: - Task: Refactor user authentication - Files modified: Auth.ts, Login.tsx - Current status: Step 2 of 5 in progress -
保留核心信息:
- 任务目标和进度
- 关键代码片段
- 错误和警告信息
-
压缩历史对话:
- 合并相似轮次
- 删除冗余内容
- 提取关键决策点
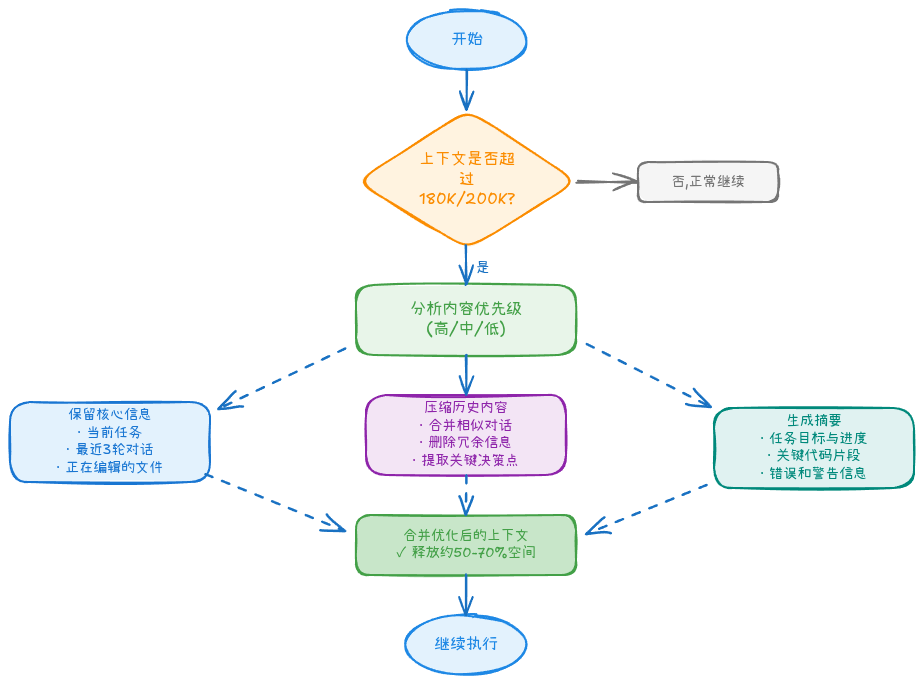
图2: 上下文压缩机制,当接近 Token 限制时自动触发优化流程
真实案例:
在重构一个 5000 行的大文件时:
bash
# 初始:完整读取文件(~8000 tokens)
> 帮我分析 UserService.ts 的问题
[Claude 读取完整文件,进行分析...]
# 10分钟后:文件被压缩为摘要(~500 tokens)
> 现在优化第 3 个方法
[Claude 重新读取文件,因为摘要不包含方法细节]优化技巧:
- 大文件分阶段处理,每次专注一个部分
- 使用
--context-window参数增大上下文限制 - 关键信息复制到单独的小文件中
策略 3:文件缓存机制
Claude Code 对读取过的文件进行缓存:
typescript
// 伪代码:文件缓存逻辑
interface FileCache {
path: string;
content: string;
timestamp: Date;
accessCount: number;
summary?: string;
}
// 缓存策略
const cachePolicy = {
maxSize: 50 * 1024 * 1024, // 50MB
ttl: 15 * 60 * 1000, // 15分钟
evictionStrategy: 'LRU', // 最近最少使用
};实际效果:
第一次读取文件:
> 查看 User.ts 的内容
[Executing: Read tool for src/models/User.ts]
[API Call: ~500ms]
✓ File cached (valid for 15 minutes)后续读取(15分钟内):
> User.ts 里的 validateEmail 方法是什么?
[Using cached content]
[Response time: ~50ms, 10x faster!]2.3 如何优化上下文使用
技巧 1:主动管理上下文
bash
# 查看当前上下文使用情况
> /context status
Context Usage: 125K / 200K tokens (62.5%)
- Conversation: 45K tokens
- File contents: 60K tokens
- Command outputs: 20K tokens
# 清理不必要的上下文
> /context clear
# 或指定清理类型
> /context clear files技巧 2:使用 Todo List 持久化信息
bash
> 创建一个任务列表,记录重构计划
[Claude 创建 Todo List,写入 .claude/tasks.json]
# 即使对话被总结,Todo List 也会保留技巧 3:利用 claude.md 存储项目规范
markdown
# 项目规范 (claude.md)
## 架构设计
- 使用 Clean Architecture 分层
- Controller → Service → Repository
## 编码规范
- 使用 TypeScript strict mode
- 函数命名:动词开头(getUserById)这样 Claude Code 会自动加载这些规范,无需每次对话都重复说明。
三、工具系统:Claude Code 的双手
3.1 工具系统概览
Claude Code 通过**工具(Tools)**与文件系统、命令行、代码库交互。所有工具遵循统一接口:
typescript
interface Tool {
name: string;
description: string;
parameters: ParameterSchema;
execute: (params: any) => Promise<ToolResult>;
}核心工具分类:
| 类别 | 工具名称 | 用途 | 使用频率 |
|---|---|---|---|
| 文件操作 | Read | 读取文件内容 | ⭐⭐⭐⭐⭐ |
| Write | 创建/覆盖文件 | ⭐⭐⭐⭐ | |
| Edit | 精确修改文件(字符串替换) | ⭐⭐⭐⭐⭐ | |
| 代码搜索 | Glob | 按模式搜索文件 | ⭐⭐⭐⭐ |
| Grep | 搜索文件内容 | ⭐⭐⭐⭐ | |
| 命令执行 | Bash | 执行 Shell 命令 | ⭐⭐⭐⭐⭐ |
| 任务管理 | TodoWrite | 创建/更新任务列表 | ⭐⭐⭐ |
| TaskCreate | 创建子任务 | ⭐⭐⭐ | |
| 交互 | AskUserQuestion | 向用户提问 | ⭐⭐⭐ |
| Agent | Task | 调用子 Agent | ⭐⭐⭐⭐ |
3.2 核心工具详解
工具 1: Read - 读取文件
使用场景:
- 分析代码结构
- 查看配置文件
- 读取日志
实际调用示例:
用户: 查看 package.json 的依赖
[Claude 内部工具调用]
Tool: Read
Parameters:
file_path: /path/to/project/package.json
Result:
{
"name": "my-app",
"dependencies": {
"express": "^4.18.0",
"typescript": "^5.0.0"
}
}
[Claude 回复用户]
项目使用了 Express 4.18 和 TypeScript 5.0...优化建议:
❌ 低效:让 Claude Code 自己搜索
> 帮我找一下配置文件在哪里,然后查看内容
[触发 Glob 搜索 → Read 多个文件 → 浪费时间]✅ 高效:直接指定路径
> 查看 ./config/app.json 的内容
[直接 Read → 立即返回结果]工具 2: Edit - 精确修改文件
核心原理 :Edit 工具使用字符串精确匹配替换,而不是智能理解代码。
错误示例:
typescript
// 原文件内容
function getUserById(id: string) {
return db.users.findOne({ id });
}
// Claude Code 尝试修改
Tool: Edit
old_string: "return db.users.findOne({ id });"
new_string: "return await db.users.findOne({ id });"
// ❌ 失败!因为原文件可能有额外空格或换行
// 实际内容: "return db.users.findOne({ id });\n"正确用法:
typescript
// Claude Code 会先 Read 文件,获取精确内容
Tool: Read
file_path: src/services/UserService.ts
// 然后使用精确匹配的字符串
Tool: Edit
old_string: "function getUserById(id: string) {\n return db.users.findOne({ id });\n}"
new_string: "async function getUserById(id: string) {\n return await db.users.findOne({ id });\n}"为什么这样设计?
- 安全性:避免误修改相似代码
- 精确性:用户可以明确看到修改内容
- 可逆性:修改失败不会破坏文件
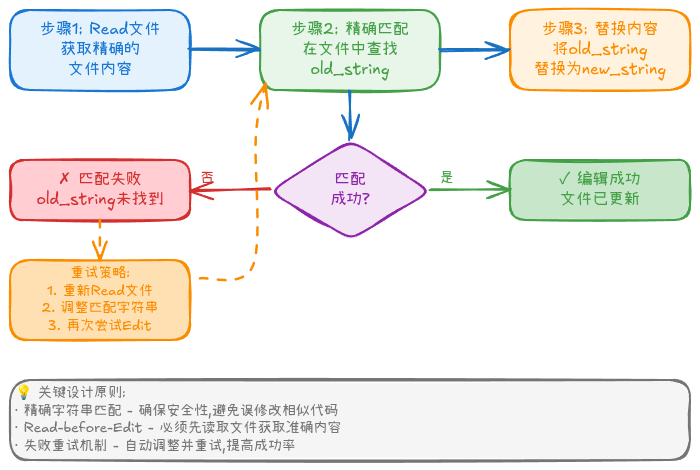
图3: Edit 工具的精确匹配机制,确保代码修改的安全性和准确性
工具 3: Bash - 命令执行
强大之处:可以执行任何 Shell 命令,实现自动化。
常见用途:
bash
# 安装依赖
Bash: npm install axios
# 运行测试
Bash: npm test
# Git 操作
Bash: git add . && git commit -m "Refactor user service"
# 文件操作
Bash: mkdir -p src/components/common
# 编译构建
Bash: npm run build安全机制:
Claude Code 有权限控制系统(后续文章详解),高危命令会被拦截:
bash
# ⚠️ 会触发确认
Bash: rm -rf node_modules
[System] This command may delete important files.
[User] Confirm execution? [y/N]
# 🚫 直接拒绝执行
Bash: sudo rm -rf /
[System] Command blocked: Dangerous operation detected工具 4: Task - 调用子 Agent
作用:当主 Agent 遇到需要专业知识的任务时,调用子 Agent 处理。
调用时机:
用户: 帮我探索这个代码库的结构
[主 Agent 判断: 这是探索任务,应该调用 Explore Agent]
Tool: Task
subagent_type: Explore
prompt: "Analyze the codebase structure and identify key components"
[Explore Agent 开始工作...]
- 使用 Glob 查找关键文件
- 分析目录结构
- 识别技术栈
- 生成架构摘要
[返回结果给主 Agent,由主 Agent 呈现给用户]Agent 类型:
| Agent 类型 | 专长 | 使用场景 |
|---|---|---|
| Explore | 代码库探索 | 首次接触项目 |
| Plan | 方案设计 | 复杂功能开发前 |
| Backend-Architect | 后端架构设计 | API/数据库设计 |
| Test-Runner | 测试执行 | 自动化测试 |
| General-Purpose | 通用任务 | 多步骤复杂任务 |
3.3 工具调用链路分析
让我们通过一个真实案例,看看 Claude Code 如何调用工具:
案例:用户要求"优化登录 API 的性能"
步骤 1: 理解需求
→ 识别关键词: "优化"、"登录 API"、"性能"
步骤 2: 定位文件
→ Tool: Glob
pattern: "**/login*.ts"
result: src/routes/login.ts, src/services/LoginService.ts
步骤 3: 分析代码
→ Tool: Read (src/routes/login.ts)
→ Tool: Read (src/services/LoginService.ts)
步骤 4: 识别问题
→ 发现: 每次登录都查询数据库
→ 方案: 添加 Redis 缓存
步骤 5: 询问用户
→ Tool: AskUserQuestion
question: "是否要添加 Redis 缓存?"
options: ["Yes", "No", "Use in-memory cache"]
步骤 6: 实现修改(假设用户选择 Yes)
→ Tool: Bash (npm install redis)
→ Tool: Write (src/config/redis.ts)
→ Tool: Edit (src/services/LoginService.ts)
修改: 添加缓存逻辑
步骤 7: 测试验证
→ Tool: Bash (npm test)
→ 如果失败,返回步骤 6 修复
步骤 8: 完成反馈
→ 总结修改内容
→ 询问是否需要进一步优化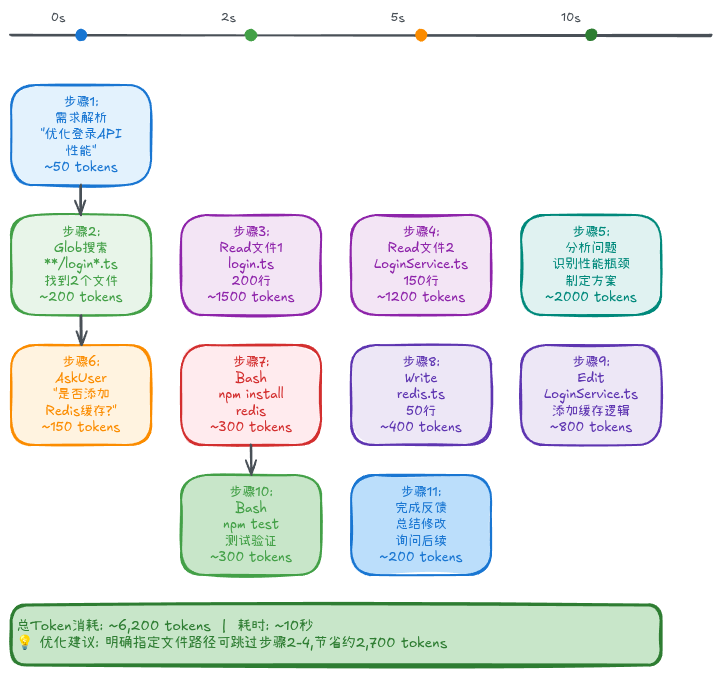
图4: 优化登录 API 性能的完整工具调用链路,展示每个步骤的 Token 消耗
Token 消耗分析:
Read (login.ts, 200 行) ~1,500 tokens
Read (LoginService.ts, 150 行) ~1,200 tokens
Write (redis.ts, 50 行) ~400 tokens
Edit (LoginService.ts) ~800 tokens
Bash 命令输出 ~300 tokens
对话交互 ~2,000 tokens
────────────────────────────────────────────
总计 ~6,200 tokens这就是为什么明确需求能节省 Token:如果你一开始就说"在 LoginService.ts 添加 Redis 缓存",可以跳过步骤 2 和 3,节省 ~2,700 tokens。
四、Agent 模式:从单打独斗到团队协作
4.1 什么是 Agent?
在 Claude Code 中,Agent 是一个具有特定能力 和工具权限的智能单元。
类比:把 Agent 想象成一个开发团队:
- 主 Agent:项目经理,负责理解需求、分配任务、协调进度
- Explore Agent:架构师,负责分析代码库、梳理结构
- Plan Agent:设计师,负责制定方案、规划实施步骤
- Backend-Architect Agent:后端专家,负责 API 和数据库设计
- Test-Runner Agent:QA 工程师,负责执行测试
4.2 Agent 的工作流程
单一 Agent 模式(简单任务):
用户: 修改 README.md,添加安装说明
[主 Agent 独立完成]
→ Read (README.md)
→ Edit (README.md)
→ 完成多 Agent 协作模式(复杂任务):
用户: 帮我分析这个项目并重构用户模块
[主 Agent 规划]
→ 任务 1: 探索项目结构
→ 调用 Explore Agent
→ Glob 搜索所有文件
→ 分析技术栈和架构
→ 返回摘要报告
→ 任务 2: 设计重构方案
→ 调用 Plan Agent
→ 基于 Explore 结果
→ 制定详细计划
→ 列出风险和注意事项
→ 返回 Plan 文档
→ 任务 3: 执行重构
→ 主 Agent 根据 Plan 逐步实施
→ Read/Edit 文件
→ 运行测试
→ 修复错误
→ 任务 4: 验证结果
→ 调用 Test-Runner Agent
→ 执行所有测试
→ 生成测试报告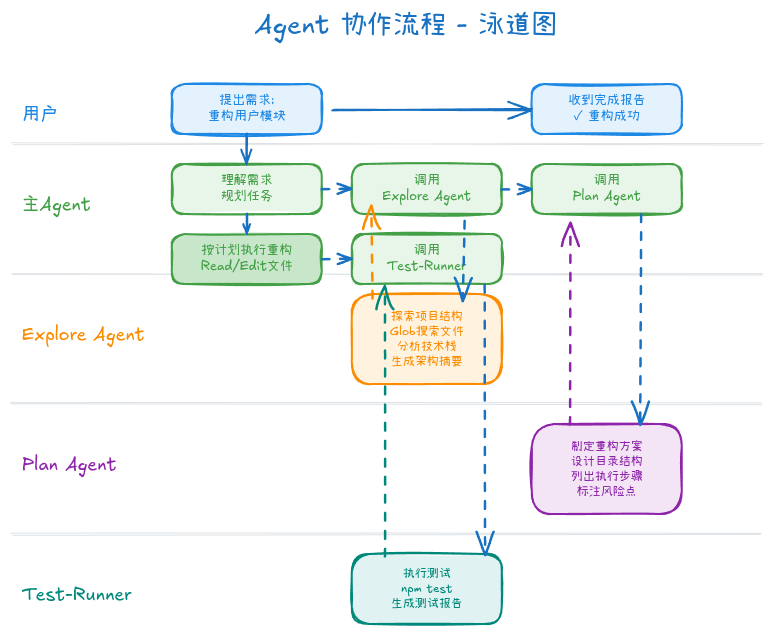
图5: 多 Agent 协作模式,展示主 Agent 如何调度 Explore、Plan、Test-Runner 等子 Agent
4.3 Agent 的能力边界
每个 Agent 有不同的工具权限:
| Agent | 可用工具 | 限制 |
|---|---|---|
| 主 Agent | 全部工具 | 无限制 |
| Explore Agent | Read, Glob, Grep | 只读,不能修改 |
| Plan Agent | Read, Glob, Grep | 只读,不能修改 |
| 执行类 Agent | Read, Write, Edit, Bash | 可修改,但需遵循 Plan |
为什么这样设计?
- 安全性:Explore Agent 不能误修改文件
- 专注性:Plan Agent 专注于设计,不执行
- 可控性:执行类 Agent 必须先有明确计划
4.4 如何触发 Agent 调用?
自动触发(Claude Code 判断):
# 探索型任务 → Explore Agent
用户: 这个项目是做什么的?
用户: 分析代码库的架构
# 设计型任务 → Plan Agent
用户: 我想添加一个支付模块,帮我设计方案
用户: 重构这个模块,先制定计划
# 复杂任务 → General-Purpose Agent
用户: 生成 API 文档并部署到 GitHub Pages手动触发(使用 Task 工具):
用户: /task explore "分析 Android 项目的模块依赖关系"
用户: /task plan "设计用户认证系统"五、实战案例:通过日志分析工作流程
5.1 案例背景
让我们通过一个真实案例,分析 Claude Code 的完整工作流程:
任务: "帮我修复登录功能的 Bug:用户点击登录后没有反应"
5.2 完整工具调用日志
[00:00.000] 用户输入
User: 帮我修复登录功能的 Bug:用户点击登录后没有反应
[00:00.050] 主 Agent 分析
[Agent] Understanding task: Bug fix in login functionality
[Agent] Strategy: Locate login code → Analyze → Identify issue → Fix
[00:00.100] 步骤 1: 定位相关文件
[Tool] Glob
pattern: "**/*login*.{ts,tsx,js,jsx}"
result: [
"src/pages/Login.tsx",
"src/services/LoginService.ts",
"src/api/login.ts"
]
[00:01.200] 步骤 2: 读取前端代码
[Tool] Read
file_path: src/pages/Login.tsx
lines: 120
tokens: ~1,800
[00:02.500] 步骤 3: 读取服务层代码
[Tool] Read
file_path: src/services/LoginService.ts
lines: 85
tokens: ~1,300
[00:03.800] 步骤 4: Agent 分析问题
[Agent] Analysis:
- Login.tsx line 45: onClick handler missing await
- LoginService.login() returns Promise but not handled
- No error catching in frontend
[Agent] Root cause: Async function not properly awaited
[00:03.900] 步骤 5: 修复代码
[Tool] Edit
file_path: src/pages/Login.tsx
old_string:
const handleLogin = () => {
LoginService.login(username, password);
};
new_string:
const handleLogin = async () => {
try {
await LoginService.login(username, password);
} catch (error) {
console.error('Login failed:', error);
}
};
[00:04.500] 步骤 6: 运行测试
[Tool] Bash
command: npm test -- Login.test.tsx
output:
✓ Should handle login success (125ms)
✓ Should handle login failure (98ms)
All tests passed!
[00:06.200] 完成反馈
[Agent] 问题已修复!
- 原因: 异步函数未正确等待
- 修改: 添加 async/await 和错误处理
- 测试: 所有测试通过
需要我解释具体的技术细节吗?5.3 关键观察点
观察 1: 工具调用的合理性
Claude Code 没有盲目读取所有文件,而是:
- 先用 Glob 定位候选文件
- 只读取相关的 2 个文件
- 定位问题后直接修复
观察 2: 上下文的使用
[Context Before Fix]
- User input: ~50 tokens
- File 1 content: ~1,800 tokens
- File 2 content: ~1,300 tokens
- Total: ~3,150 tokens
[Context After Fix]
- 保留: 修改的代码片段 (~200 tokens)
- 压缩: 文件摘要 (~500 tokens)
- 总计节省: ~2,450 tokens观察 3: 错误处理
如果修复失败:
[Tool] Edit (failed)
error: "old_string not found in file"
[Agent] Retry strategy:
→ Re-read file with context
→ Adjust string matching
→ Retry Edit
[Tool] Read (with full context)
[Tool] Edit (success)六、优化建议与最佳实践
6.1 提升响应速度的技巧
技巧 1: 明确指定文件路径
❌ 慢:
> 帮我修改配置文件
[触发 Glob 搜索 → 读取多个候选文件]✅ 快:
> 帮我修改 ./config/app.json
[直接 Read 指定文件]技巧 2: 分阶段处理大任务
❌ 低效:
> 重构整个项目,添加测试,优化性能,更新文档
[一次性任务过大,需要多次上下文压缩]✅ 高效:
> 先重构用户模块
[完成后]
> 现在添加测试
[完成后]
> 优化性能技巧 3: 使用缓存
在 15 分钟内反复引用同一文件:
> 查看 User.ts 的结构
[首次 Read,缓存文件]
> User.ts 中的 validateEmail 方法怎么实现的?
[使用缓存,快速响应]6.2 避免上下文浪费
问题场景:
> 帮我分析这 10 个文件的依赖关系
[读取 10 个文件,消耗大量 tokens]
> (5分钟后) 第一个文件有什么问题?
[上下文已压缩,需要重新读取]优化方案:
> 先分析 File1.ts 和 File2.ts 的依赖
[处理 2 个文件,保留详细上下文]
> 再分析 File3.ts 和 File4.ts
[逐步扩展,保持上下文连续性]6.3 充分利用 Agent
场景: 首次接触新项目
不要这样:
> 帮我看看这个项目是做什么的
[主 Agent 随机读取文件,效率低]应该这样:
> /task explore "全面分析这个项目的架构和技术栈"
[Explore Agent 系统化探索,生成完整报告]场景: 复杂功能开发
不要这样:
> 直接帮我实现支付模块
[主 Agent 边想边做,容易出错]应该这样:
> /task plan "设计支付模块的实现方案"
[Plan Agent 先制定详细计划]
> 根据这个计划开始实现
[主 Agent 按计划执行,思路清晰]七、常见问题与调试
7.1 为什么 Claude Code "忘记"了之前的内容?
原因: 上下文被压缩或超出 Token 限制。
解决方法:
- 保持对话连续性,避免长时间中断
- 关键信息写入
claude.md或 Todo List - 使用
/context status查看上下文使用情况
7.2 为什么有时工具调用失败?
常见失败原因:
-
Edit 工具: 字符串不匹配
[Tool] Edit failed: old_string not found 原因: 文件内容与 old_string 不完全一致(空格/换行) 解决: Claude Code 会自动 Re-read 后重试 -
Bash 工具: 命令执行错误
[Tool] Bash failed: npm: command not found 原因: 环境变量未配置 解决: 检查 PATH 或使用完整路径 -
Glob 工具: 未找到文件
[Tool] Glob result: [] 原因: 模式匹配错误或文件不存在 解决: 检查文件路径和模式语法
7.3 如何查看详细的工具调用日志?
bash
# 启动 Claude Code 时开启 debug 模式
claude --debug
# 或设置环境变量
export CLAUDE_LOG_LEVEL=debug
claude输出示例:
[DEBUG] Tool call: Read
[DEBUG] file_path: src/App.tsx
[DEBUG] tokens: 1,234
[DEBUG] cache: miss
[DEBUG] duration: 456ms
[DEBUG] Tool call: Edit
[DEBUG] old_string length: 45 chars
[DEBUG] new_string length: 78 chars
[DEBUG] result: success八、总结与展望
8.1 核心要点回顾
通过本文,我们深入理解了 Claude Code 的工作机制:
1. 架构设计
- 分层架构:意图理解 → Agent 编排 → 工具执行 → 上下文管理
- 每层独立优化,各司其职
2. 上下文管理
- 有限 Token 预算(200K)需要智能管理
- 分层优先级、智能压缩、文件缓存
- 理解上下文机制,避免"失忆"问题
3. 工具系统
- 标准化工具接口,易于扩展
- 核心工具:Read、Edit、Bash、Task
- 理解工具调用链路,优化使用策略
4. Agent 协作
- 主 Agent + 子 Agent 团队模式
- 不同 Agent 有不同专长和权限
- 复杂任务自动调度子 Agent
8.2 实践建议
立即可用的技巧:
-
明确需求,指定路径
- 不要让 Claude Code 盲目搜索
- 直接指定文件路径,节省时间
-
保持对话连续性
- 关键任务不要中断太久
- 重要信息写入
claude.md
-
分阶段处理大任务
- 将复杂任务拆分为多个小步骤
- 每个步骤完成后再进行下一步
-
善用 Agent
- 探索项目时使用 Explore Agent
- 复杂功能开发前使用 Plan Agent
参考资料
🔗 相关文章:
💡 思考题: 在你的项目中,哪些任务适合使用 Claude Code?哪些不适合?欢迎在评论区分享你的思考!
如果这篇文章对你有帮助,欢迎点赞、收藏、分享!有任何问题或建议,欢迎在评论区留言讨论。让我们一起学习,一起成长!
也欢迎访问我的个人主页发现更多宝藏资源