一、搜索引擎选型Lucene vs Solr vs Elasticsearch
┌─────────────────────────────────┐
│ Apache Lucene │
│ (核心搜索库,类库,Java实现) │
└──────────────┬──────────────────┘
│
┌────────────────────────┼────────────────────────┐
│ │ │
▼ ▼ ▼
┌────────────────────┐ ┌────────────────────┐ ┌────────────────────┐
│ Apache Solr │ │ Elasticsearch │ │ 其他衍生产品 │
│ (企业级搜索平台) │ │ (实时分布式搜索) │ │ (如:OpenSearch) │
└────────────────────┘ └────────────────────┘ └────────────────────┘选择 Apache Solr,如果:
-
你的项目在传统的Java企业环境中,且团队熟悉Apache和Java生态。
-
你需要一个功能大而全、开箱即用、稳定可靠的搜索解决方案,对实时性要求不是极端高。
-
你的使用场景是经典的文本搜索(如电商商品搜索、新闻网站搜索)。
-
你非常看重Apache基金会的纯开源模式和社区治理。
选择 Elasticsearch,如果:
-
你需要处理大量实时、快速变化的数据(如日志、监控数据、应用事件)。
-
分布式扩展和易用性是你的首要考虑,希望简单几步就能搭建一个集群。
-
你计划构建可观测性平台(日志、指标、追踪),ELK Stack是天然选择。
-
你的团队更喜欢RESTful API和JSON,追求现代化的开发体验。
-
你需要强大的商业支持和丰富的托管云服务(如Elastic Cloud,AWS OpenSearch等)。
考虑 Lucene(直接使用),如果:
-
你正在开发一个Java桌面或嵌入式应用,需要将搜索功能集成其中。
-
你对性能有极致要求,希望完全掌控搜索引擎的每一个环节。
-
你正在学习搜索引擎的底层原理。
现状与趋势
近年来,Elasticsearch 凭借其分布式架构的先天优势、出色的开发者体验以及ELK Stack在日志分析市场的统治地位,获得了更广泛的市场份额和社区影响力。它的应用场景已远远超出了"搜索",成为了一个通用的实时分布式搜索和分析引擎。
Solr 依然非常强大、稳定,在许多传统企业搜索场景中占据重要地位,并且持续发展,不断吸收优点。
如果你谁都不懂就学ES吧。
二、什么是ES
Elasticsearch 是一个分布式的高性能的搜索和数据分析引擎,简称ES。ES底层基于Lucene,Lucene是一套用于全文检索和搜索的工具包,是类库,ES在Lucene的基础上开发了一个强大的搜索引擎。
分布式搜索引擎=搜索引擎+分布式存储与搜索。
三、ES优点
- ES使用了倒排索引作为存储结构并大量使用缓存机制,因此具有很高的查询性能;
- ES是分布式的,易扩展,节点可扩展至上百台服务器,处理PB级别的数据。并支持配置数据副本,容错性好;
- ES支持RESTful API,可以以HTTP接口调用的方式使用,上手非常快;
四、ES工作原理
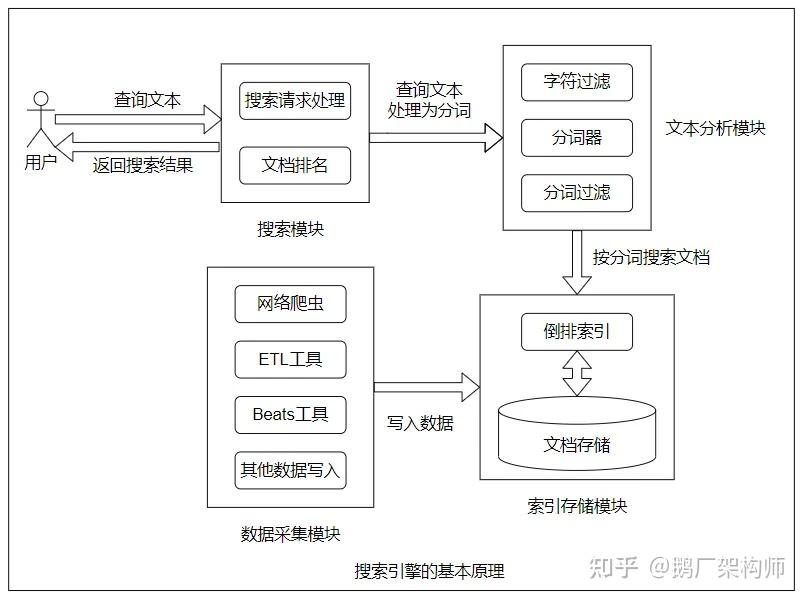
五、使用场景
| 场景分类 | 典型用例 | 说明 |
|---|---|---|
| 日志与指标分析 | 集中式日志管理(如ELK Stack)、应用性能监控(APM)、服务器指标收集 | 实时采集、存储和分析日志数据,支持全文检索和聚合分析,常用于故障排查和系统监控。 |
| 全文搜索 | 电商商品搜索、新闻/博客内容检索、应用内搜索(如用户、帖子) | 提供高性能、相关性排序的全文检索,支持多字段、模糊搜索、同义词、自动补全等功能。 |
| 实时数据分析 | 实时仪表盘、业务指标分析(如点击率、用户行为)、趋势分析 | 利用聚合(Aggregation)功能对大规模数据进行实时统计、分组、计算,支持可视化(如Kibana)。 |
| 安全分析 | 安全信息与事件管理(SIEM)、异常行为检测、威胁狩猎 | 通过关联和分析日志数据(如网络流量、登录记录)检测安全威胁,支持实时告警。 |
| 商业智能(BI) | 销售数据报告、用户行为分析、运营数据挖掘 | 结合Kibana或第三方BI工具,对结构化/非结构化数据进行探索式分析和可视化。 |
| 地理空间数据查询 | 位置服务(如附近门店)、轨迹分析、地理围栏 | 支持地理坐标数据类型和空间查询(如距离过滤、边界框查询),适用于地图类应用。 |
| 自动补全与建议 | 搜索框自动补全、相关搜索词推荐、纠错提示 | 利用Suggesters(如Completion Suggester)实现低延迟的实时搜索建议和纠错功能。 |
| 应用性能监控 | 跟踪请求链路、数据库查询性能、代码级性能分析 | 集成APM工具(如Elastic APM),收集应用性能数据,帮助优化代码和架构。 |
| 事件溯源与审计 | 用户操作记录、系统变更追踪、合规性审计 | 存储不可变的事件序列,便于回溯历史状态或满足合规要求(如GDPR、ISO27001)。 |
| 机器学习与异常检测 | 自动检测异常流量、预测性维护、用户行为异常识别 | 内置机器学习功能(Elastic ML),可自动发现数据模式并触发告警。 |
简单来说,当你的需求是 "在海量数据中,快速找到相关信息并进行洞察" 时,就应该考虑使用 Elasticsearch。
总之,适合处理大规模、高并发、实时检索和分析的数据需求
六、不适合的场景
-
频繁更新的强事务性数据(如银行交易)。
-
复杂关联查询(如多表JOIN)。
-
需要ACID合规的写操作。
七、倒排索引
1.倒排索引解释
倒排索引(Inverted Index)是一种数据结构,用于在大规模文档集合中快速定位包含特定关键词的文档。相对于正排索引,倒排索引以关键词为中心,将每个关键词映射到包含该关键词的文档列表。这种颠倒的结构使得搜索引擎能够高效地响应用户的查询,快速返回相关的文档。
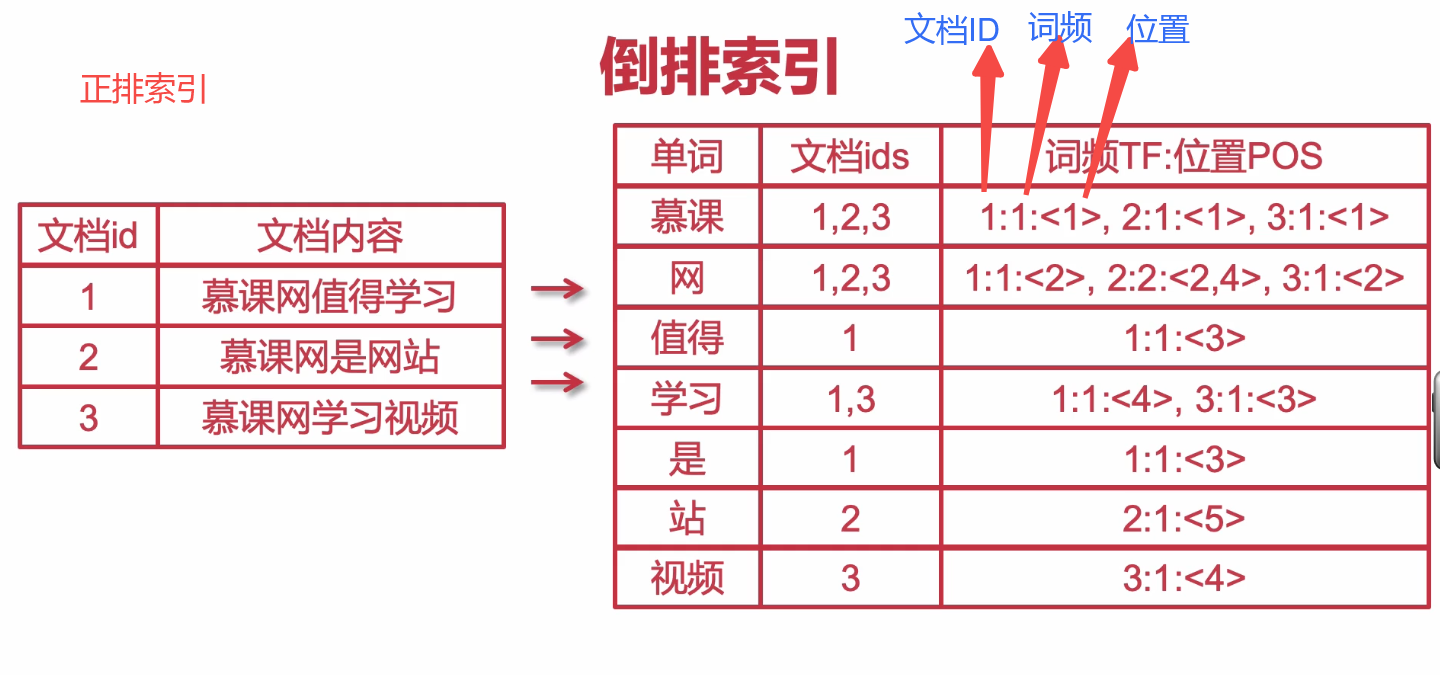
同样以上面的博客集合作为示例,
- 博客1:《LangChain学习笔记------Model I/O》
- 内容包含关键词:LangChain、学习笔记、Model I/O。
- 博客2:《Docker存储驱动初探》
- 内容包含关键词:Docker、存储驱动、初探。
- 博客3:《几种常见的消息队列介绍》
- 内容包含关键词:消息队列、介绍、常见。
倒排索引示例:
| 关键词 | 文档ID列表 |
|---|---|
| LangChain | 1 |
| 学习笔记 | 1 |
| Model I/O | 1 |
| Docker | 2 |
| 存储驱动 | 2 |
| 初探 | 2 |
| 消息队列 | 3 |
| 介绍 | 3 |
| 常见 | 3 |
倒排索引示例:
通过这个倒排索引示例,我们可以看到每个关键词都与包含该关键词的博客的文档ID关联。例如,如果用户查询关键词"消息队列",搜索引擎可以迅速找到文档ID列表为3的博客,即《几种常见的消息队列介绍》。这种方式使得搜索引擎能够快速过滤掉与查询无关的文档,提高检索效率。再比如:
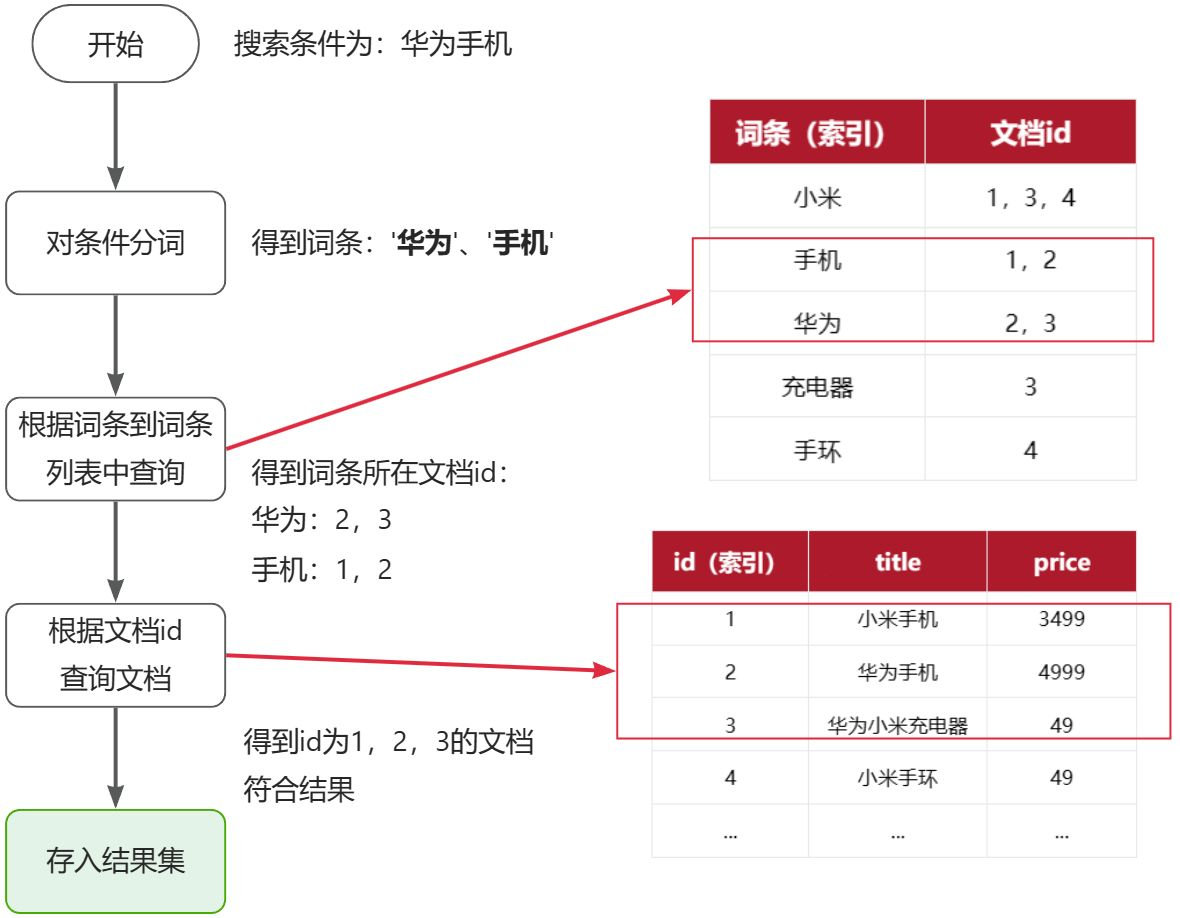
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
2.索引
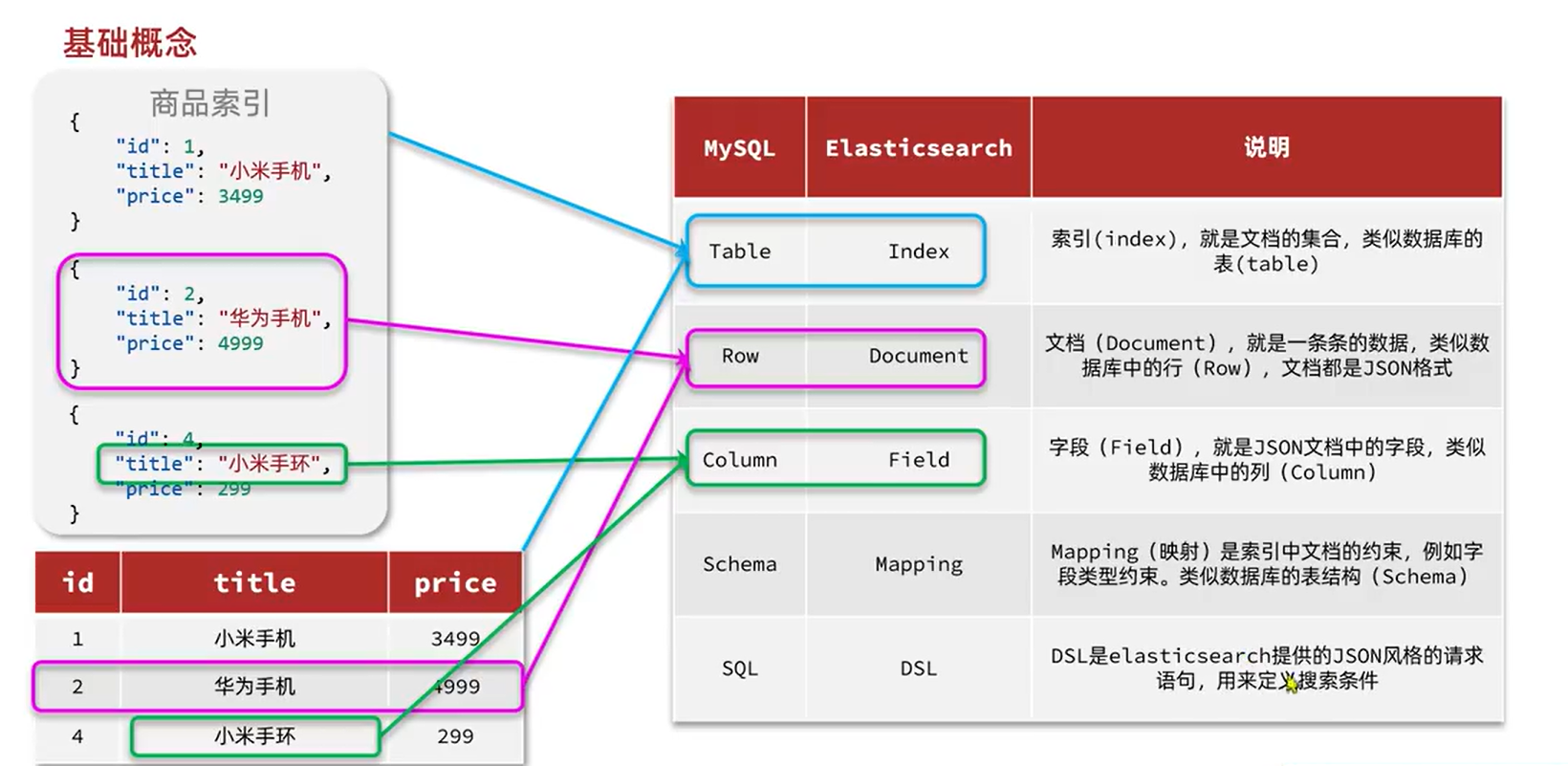
我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:
商品索引
{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "三星手机",
"price": 3999
}用户索引
{
"id": 101,
"name": "张三",
"age": 21
}
{
"id": 102,
"name": "李四",
"age": 24
}
{
"id": 103,
"name": "麻子",
"age": 18
}订单索引
{
"id": 10,
"userId": 101,
"goodsId": 1,
"totalFee": 294
}
{
"id": 11,
"userId": 102,
"goodsId": 2,
"totalFee": 328
}所有用户文档,就可以组织在一起,称为用户的索引;
所有商品的文档,可以组织在一起,称为商品的索引;
所有订单的文档,可以组织在一起,称为订单的索引;
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
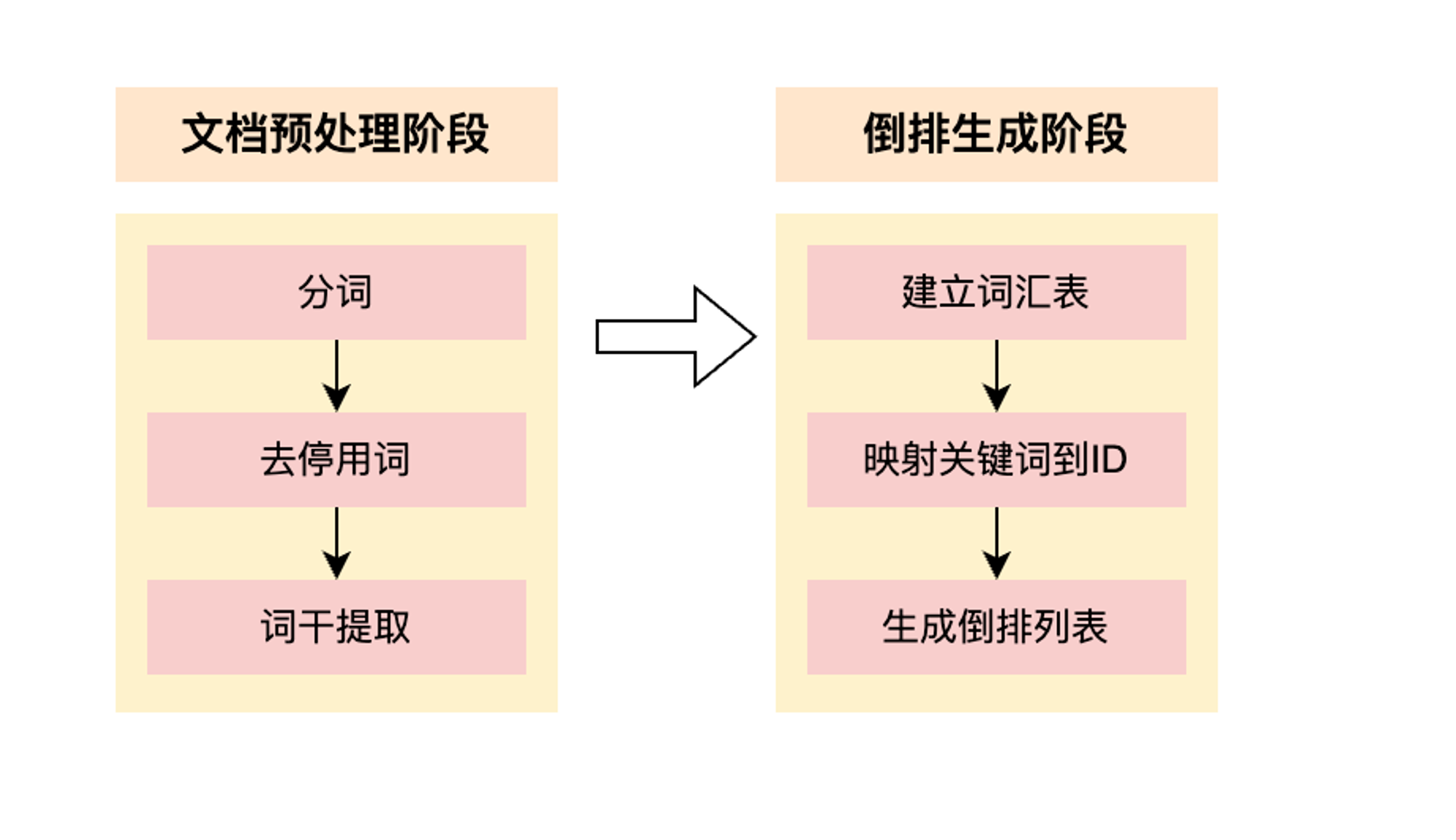
3.倒排索引的构建过程
构建倒排索引是一个复杂而关键的过程,它涉及多个步骤,可以归纳为两个阶段:
- 文档预处理阶段
- 倒排生成阶段
文档预处理阶段
- 分词(Tokenization): 将文档拆分成单词或词汇单元。这个过程使用分词器,将文本切分成有意义的词语,形成一个词汇列表。
- 去停用词(Stopword Removal): 移除常见且在搜索中没有实际意义的词语,如"的"、"是"等。这有助于提高倒排索引的效率和准确性。
- 词干提取(Stemming): 将词语还原为其词干形式,去除词尾,以便将相关的词汇映射到同一词根,减少索引的大小。
倒排生成阶段
- 建立词汇表: 将预处理后的文档中的所有唯一词语构建成一个词汇表。每个词汇都有一个唯一的标识符。
- 映射关键词到文档ID: 遍历每个文档,对于文档中的每个关键词,将其映射到文档的唯一标识符(文档ID)。这样的映射关系通常以字典的形式保存。
- 生成倒排列表: 对于每个关键词,创建一个倒排列表,其中包含映射到该关键词的所有文档ID。倒排列表实际上是一个映射,将关键词与包含该关键词的文档关联起来。
4.检索过程分析
搜索引擎的检索过程是通过倒排索引来实现的,这个过程可以分为几个关键步骤,让我们逐步解析搜索引擎如何利用倒排索引进行检索,并强调倒排索引在快速定位相关文档方面的高效性。
1. 用户查询输入:
- 用户在搜索引擎中输入关键词或查询短语,希望找到相关的文档。
2. 关键词分析:
- 搜索引擎对用户输入的查询进行关键词分析,进行类似于文档预处理的步骤,包括分词、去停用词、词干提取等。
3. 查询到关键词的倒排列表:
- 对于每个关键词,搜索引擎通过倒排索引找到与之相关的文档ID列表。
4. 倒排列表的交集操作:
- 如果查询包含多个关键词,搜索引擎会对这些关键词的倒排列表进行交集操作,得到包含所有关键词的文档ID列表。
5. 文档排序和排名:
- 搜索引擎根据某种算法对得到的文档ID列表进行排序和排名,以便将最相关的文档排在前面。
6. 返回搜索结果:
- 最终,搜索引擎将排名最高的文档作为搜索结果返回给用户,呈现在搜索结果页面上。
倒排索引的设计使得搜索引擎能够在海量文档中迅速定位包含查询关键词的文档,因此在检索过程中具有高效性。通过直接访问倒排列表,搜索引擎可以快速获取包含关键词的文档ID,而不需要逐一扫描所有文档。这种高效的检索过程是搜索引擎能够迅速响应用户查询的关键。
部分内容声明:
版权声明:本文为CSDN博主「ShlyxCoder」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/2301_80073794/article/details/148309544