一、引言:为什么需要Expert Iteration?
在大语言模型的监督微调(SFT)中,一个核心痛点在于:高质量的推理轨迹数据非常稀缺且制作成本高昂。人类专家编写复杂的数学推导或代码逻辑耗时费力,这严重制约了模型推理能力的提升。
Expert Iteration(EI) 正是为了解决这一难题而生的"自举"(Bootstrapping)方法。其核心思想是:让模型自己生成多种解答方案,通过自动化验证器筛选出正确解,再用这些"专家级"答案反过来训练模型,形成一个自我强化的闭环。
这种方法特别适用于数学解题和代码生成等领域,因为这类问题的正确性可以通过计算或单元测试进行自动化验证。
二、Expert Iteration的核心流程
EI是一个简洁而高效的迭代循环,主要包含以下核心步骤:
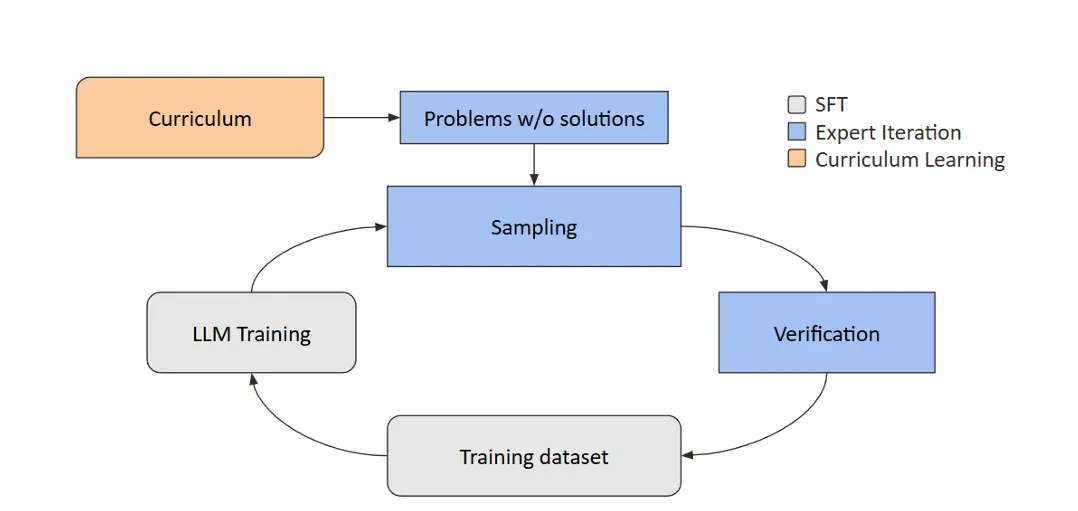
该循环将持续进行多轮。随着迭代的推进,模型生成正确答案的概率会逐渐提高,训练数据的质量和数量也随之增长,从而驱动模型性能稳步提升。
三、关键技术组件与实现细节
1. 并行生成(Rollouts)
"Rollout"是指模型针对同一个问题采样生成多个候选解答。关键参数 G 代表每个问题生成的解答数量(例如 G=4)。
-
权衡 :增加
G会提高计算成本,但同时也能增加至少找到一个正确答案的概率,并为训练集提供更多数据。 -
实现建议 :为实现高吞吐量 的生成,推荐使用专门的推理服务器(如 vLLM ),它能利用高效的PagedAttention和KV缓存技术,远超标准
model.generate()方法的效率。
2. 验证器/评分器(Verifier/Grader)
验证器是EI流程自动化的关键,它替代了昂贵的人力审查。一个健壮的验证器需要:
-
答案提取 :从模型输出的文本中(例如在
<answer>...</answer>标签内)准确提取出最终答案。 -
格式归一化 :处理空格、LaTeX格式(如
\frac{1}{2}与1/2)、去除"boxed"包装等,将答案标准化。 -
等价性判断:进行数值或符号层面的等价性检查,而不仅仅是字符串匹配。
3. 训练目标
最简单直接的训练方式,就是使用筛选出的"正确解答"对模型进行标准的监督微调 。训练时需要注意只对回答部分计算损失 ,通常在标签中会将提示词部分的位置标记为 -100 来屏蔽损失计算,防止模型学习"预测问题本身"。
四、系统架构设计与伪代码实现
一个高效且实用的EI系统,通常会将"生成"和"训练"两大任务进行物理分离。
🎯 架构设计:双GPU分离部署
-
推理GPU :专门运行 vLLM 引擎,负责高速、大批量的答案生成(Rollout)。
-
训练GPU :专门运行 Hugging Face Transformers 训练栈,负责计算密集型的模型参数更新。
这种分离架构的优势:
-
避免资源争抢(例如优化器状态与KV缓存竞争显存)。
-
系统设计更清晰,便于独立优化和扩展。
-
能充分发挥各自框架的优势。
🛠️ 伪代码实现
以下是EI核心循环的关键步骤伪代码:
步骤1: 使用vLLM为每个问题生成多个解答
from vllm import LLM, SamplingParams
# 初始化vLLM推理引擎(部署在独立GPU上)
llm = LLM(
model="Qwen/Qwen2.5-Math-1.5B",
device="cuda:1",
dtype=torch.bfloat16,
enable_prefix_caching=True # 启用前缀缓存加速
)
# 设置采样参数,每个提示词生成n个候选答案
sampling_params = SamplingParams(
temperature=1.0,
top_p=1.0,
n=4, # G=4,每个问题生成4个答案
max_tokens=1024,
stop=["</answer>"],
)
outputs = llm.generate(prompts, sampling_params) # 批量高效生成步骤2: 使用验证器筛选正确解答
def reward_fn(model_output, gold_answer):
# 实现答案提取、标准化和等价性判断的逻辑
# 返回一个字典,例如 {"reward": 1.0} 或 {"reward": 0.0}
...
good_examples = []
for i, output in enumerate(outputs):
gold_answer = gold_answers[i]
for candidate in output.outputs:
if reward_fn(candidate.text, gold_answer)["reward"] == 1.0:
# 收集高质量的 <问题, 答案> 对
good_examples.append({
"prompt": prompts[i],
"response": candidate.text
})步骤3: 使用Hugging Face Transformers进行监督微调
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-Math-1.5B").cuda() # 部署在训练GPU上
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Math-1.5B")
# 准备训练数据:将prompt和response拼接,并在计算损失时mask掉prompt部分
# ... (数据准备代码)
# 使用标准的SFT流程进行微调
training_args = TrainingArguments(
output_dir="./ei_sft_checkpoint",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
num_train_epochs=1,
logging_steps=10,
save_steps=100,
)
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()步骤4: 将更新后的模型权重热加载到vLLM引擎
def load_policy_into_vllm_instance(trained_model, vllm_engine):
"""
核心:将训练好的模型权重直接热交换到正在运行的vLLM引擎中,
无需重启引擎或进行耗时的磁盘I/O操作。
"""
state_dict = trained_model.state_dict()
# 获取vLLM引擎内部的模型引用
llm_internal_model = vllm_engine.llm_engine.model_executor.driver_worker.model_runner.model
# 直接加载权重
llm_internal_model.load_weights(state_dict.items())五、实战建议与常见问题
-
如果初始模型很弱怎么办? 可以调高
G值(生成更多候选答案),以增加获取正确解答的机会,为后续迭代积累"种子"数据。 -
为什么不用Hugging Face的
model.generate()? 在需要大规模、持续生成的EI或RLHF场景中,vLLM等专用推理引擎在吞吐量和内存效率上具有数量级优势。 -
每次迭代都要保存和重新加载模型吗? 最佳实践是像上述伪代码一样,直接进行权重热加载,这能避免磁盘I/O和引擎重启开销,极大加速迭代周期。
六、总结
Expert Iteration 是一种强大而实用的模型自我提升范式 。它巧妙地将采样多样性 、自动化验证 和监督微调结合在一个闭环中,能够持续地将模型的"成功尝试"蒸馏为自身的训练数据。
这种方法降低了对人工标注数据的依赖,是快速提升大语言模型在可验证领域(如数学、编程)推理性能的有效手段。如果你已经拥有一个可靠的验证器,不妨尝试用EI来让你的模型"自教自学",实现性能的滚动增长。
希望这篇文章能为你的大模型优化实践提供新的思路!