大模型,英文名叫Large Model,大型模型。早期的时候,也叫Foundation Model,基础模型。
大模型是一个简称,完整的叫法,应该是"人工智能预训练大模型"。预训练,是一项技术,我们后面再解释。
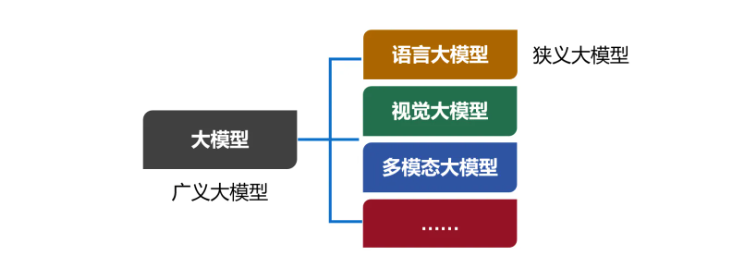
我们现在口头上常说的大模型,实际上特指大模型的其中一类,也是用得最多的一类------语言大模型(Large Language Model,也叫大语言模型,简称LLM)。
除了语言大模型之外,还有视觉大模型、多模态大模型等。现在,包括所有类别在内的大模型合集,被称为广义的大模型。而语言大模型,被称为狭义的大模型。
一、大模型基础简介
大模型(Large Language Model, LLM)是基于海量文本数据训练而成的深度学习模型,具备自然语言理解、生成、推理等核心能力,典型代表有GPT系列(OpenAI)、DeepSeek系列、Llama系列(Meta)等。
从开发视角,大模型可分为三类核心类型,对应不同的应用场景:
通用大模型:适用于文本生成、总结、翻译、问答等基础任务,如GPT-4、DeepSeek-R1。
聊天大模型:专为对话场景优化,支持多轮交互、上下文记忆,如GPT-4o、DeepSeek-Chat。
嵌入大模型(Embedding Model):根据文本生成embedding,用于语义检索、相似度计算、构建RAG应用,如text-embedding-3-small(OpenAI)、deepseek-embed-base(DeepSeek)
二、大模型调用方式
大模型调用方式主要包括厂商专用sdk和langchain体系调用两种方式。
2.1 OpenAI
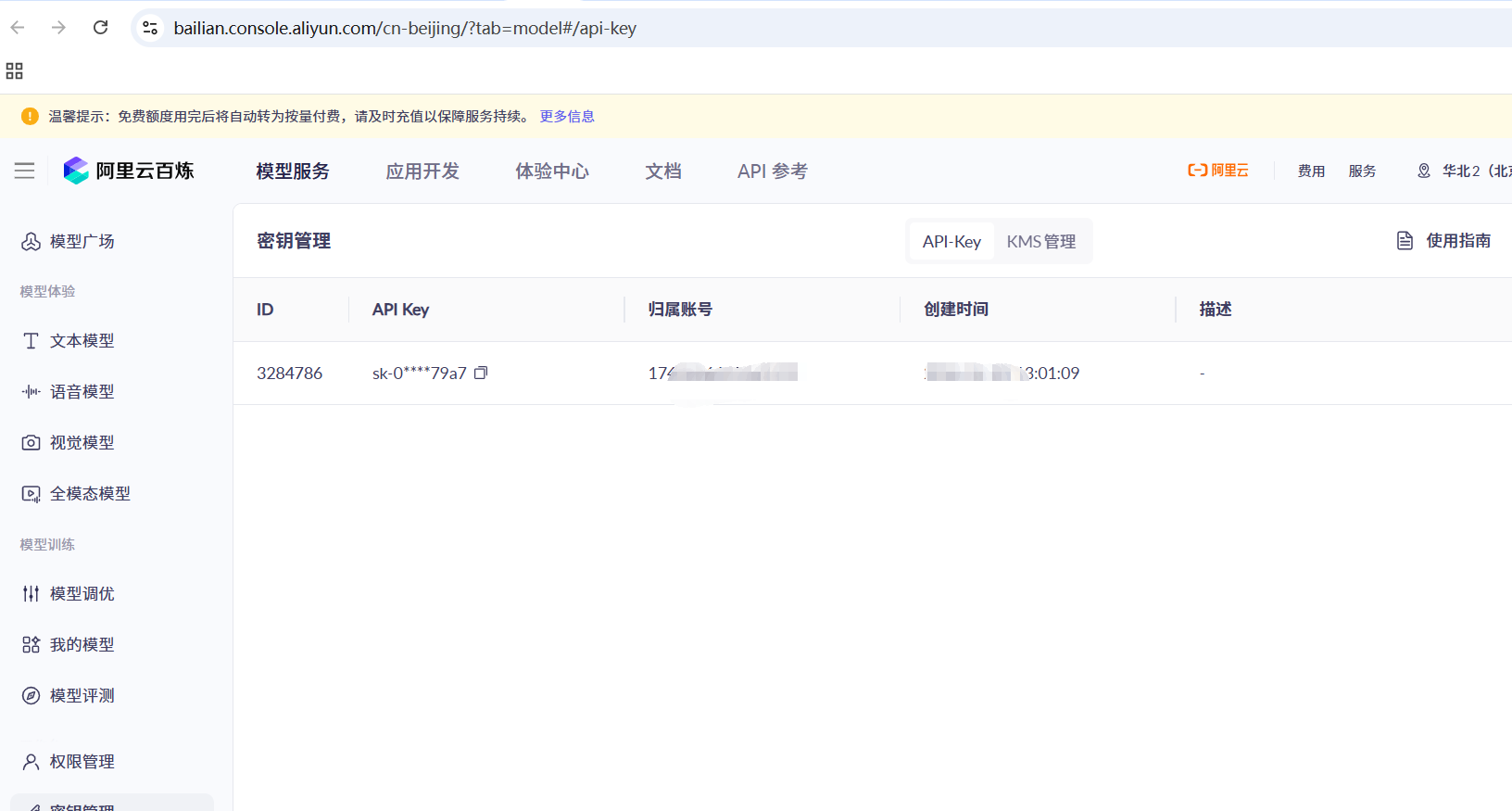
同义千问大模型的接入。我们去阿里云百炼上注册账号,获取apikey.
这里我们先安装python 环境

注册后获取apikey :
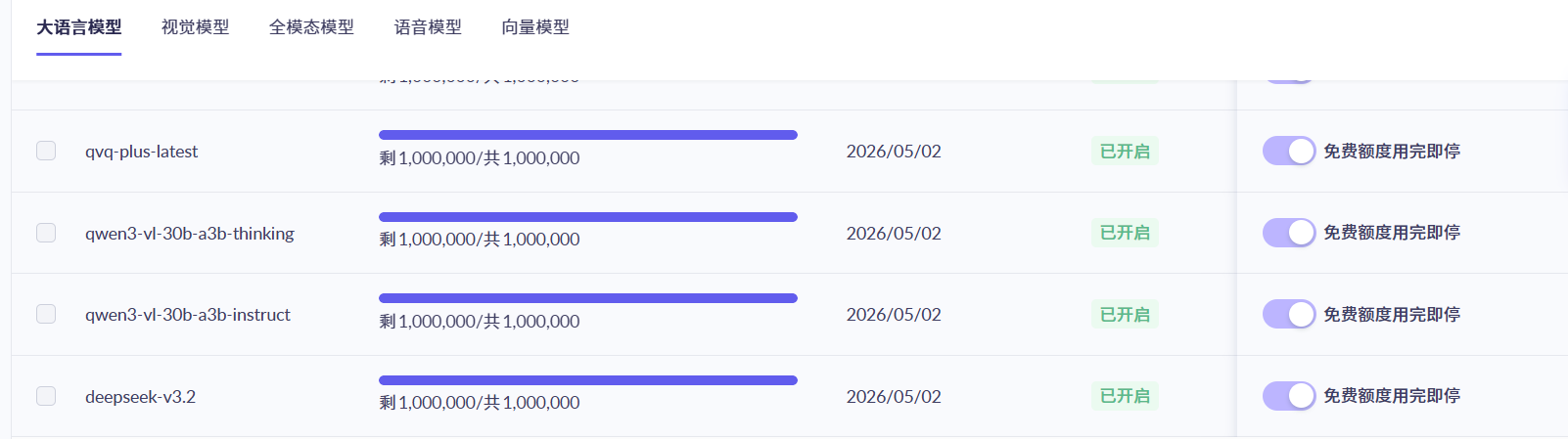
可以获取免费的token ,可以看到有各种大模型的model ,基本都是免费100万的token,基本够我们使用了。


接着我们来安装openai
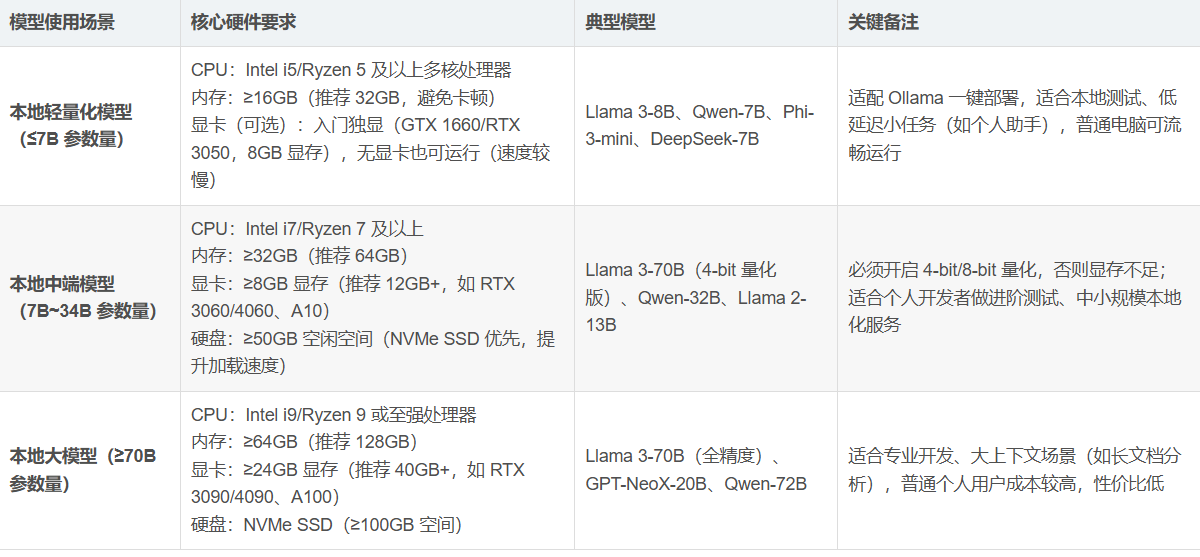
Ollama 是一个强大的本地推理大模型平台,旨在简化模型的本地部署、管理和推理工作流。它允许用户在本地机器上拉取、管理、运行大模型,并提供多种访问方式,包括本地 CLI、HTTP 接口以及通过 OpenAI 客户端的集成。这篇文章将详细介绍 Ollama 的功能,如何使用 Ollama 拉取模型、运行模型,并通过多种方式访问推理服务。 这里不错介绍,由于本地机器配置问题,性能不够,就不做介绍。硬件配置要求大体如下:
调用本地机器时,只需要把base_url 改为"http://localhost:11434/v1"即可。本地机器配置有限,就不做介绍。
接下来我们来使用OpenAI类对象,写一个Chat程序,qwen3-max是聊天模型,用流的方式输出:
主要参数有2个:
model:选择所用模型,如代码的qwen3-max
messages:提供给模型的消息类型:list,可以包含多个字典消息每个字典消息包含2个key
role:角色
content:内容
system角色:设定助手的整体行为、角色和规则,为对话提供上下文框架(如指定助手身份、回答风格、核心要求),是全局的背景设定,影响后续所有交互。
assistant角色:代表AI助手的回答,可以在代码中认为设定user角色:代表用户,发送问题、指令或需求
from openai import OpenAI
# 1. 获取client对象,OpenAI类对象
client = OpenAI(
api_key="sk-xxxxxxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 2. 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": "你是一个Python编程专家,并且话非常多"},
{"role": "assistant", "content": "好的,我是编程专家,并且话非常多,你要问什么?"},
{"role": "user", "content": "输出1-10的数字,使用python代码编写"}
],
stream=True # 开启了流式输出的功能
)
# 3. 处理结果
# print(response.choices[0].message.content)
for chunk in response:
print(
chunk.choices[0].delta.content,
end=" ", # 每一段之间以空格分隔
flush=True # 立刻刷新缓冲区
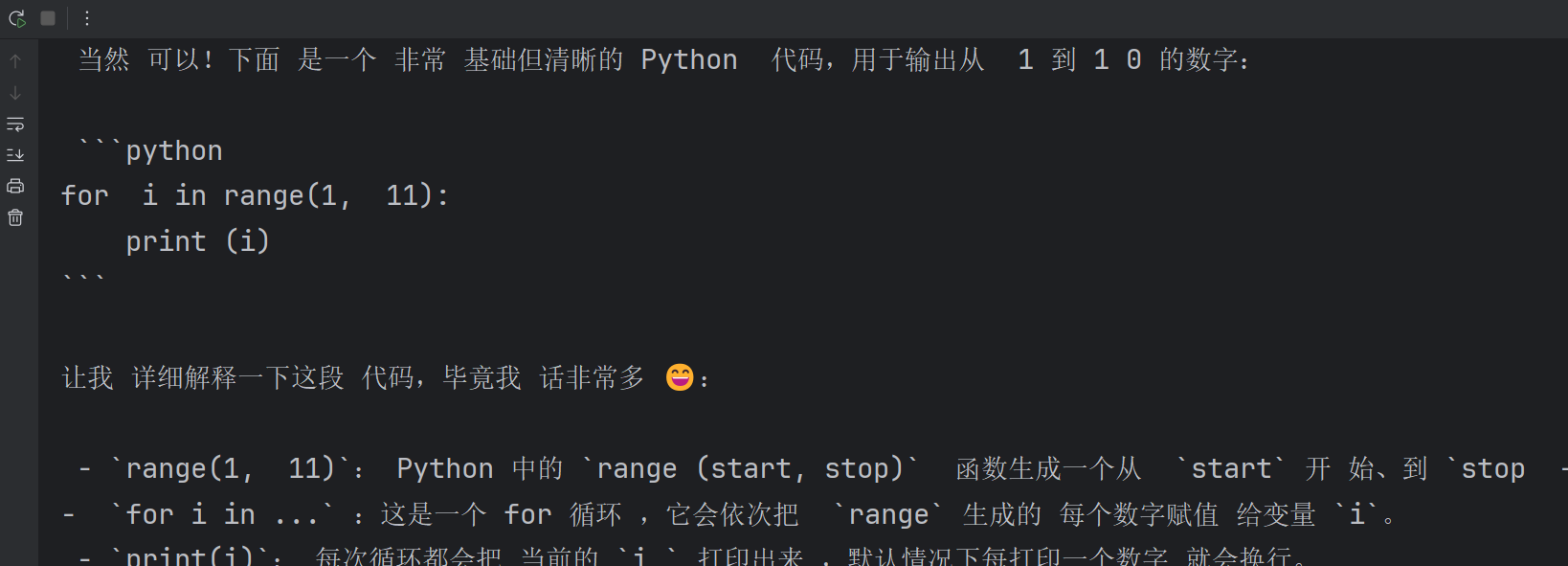
)接着我们可以看到流式输出:
为了隐藏apikey,我们可以在环境变量里面设置配置:
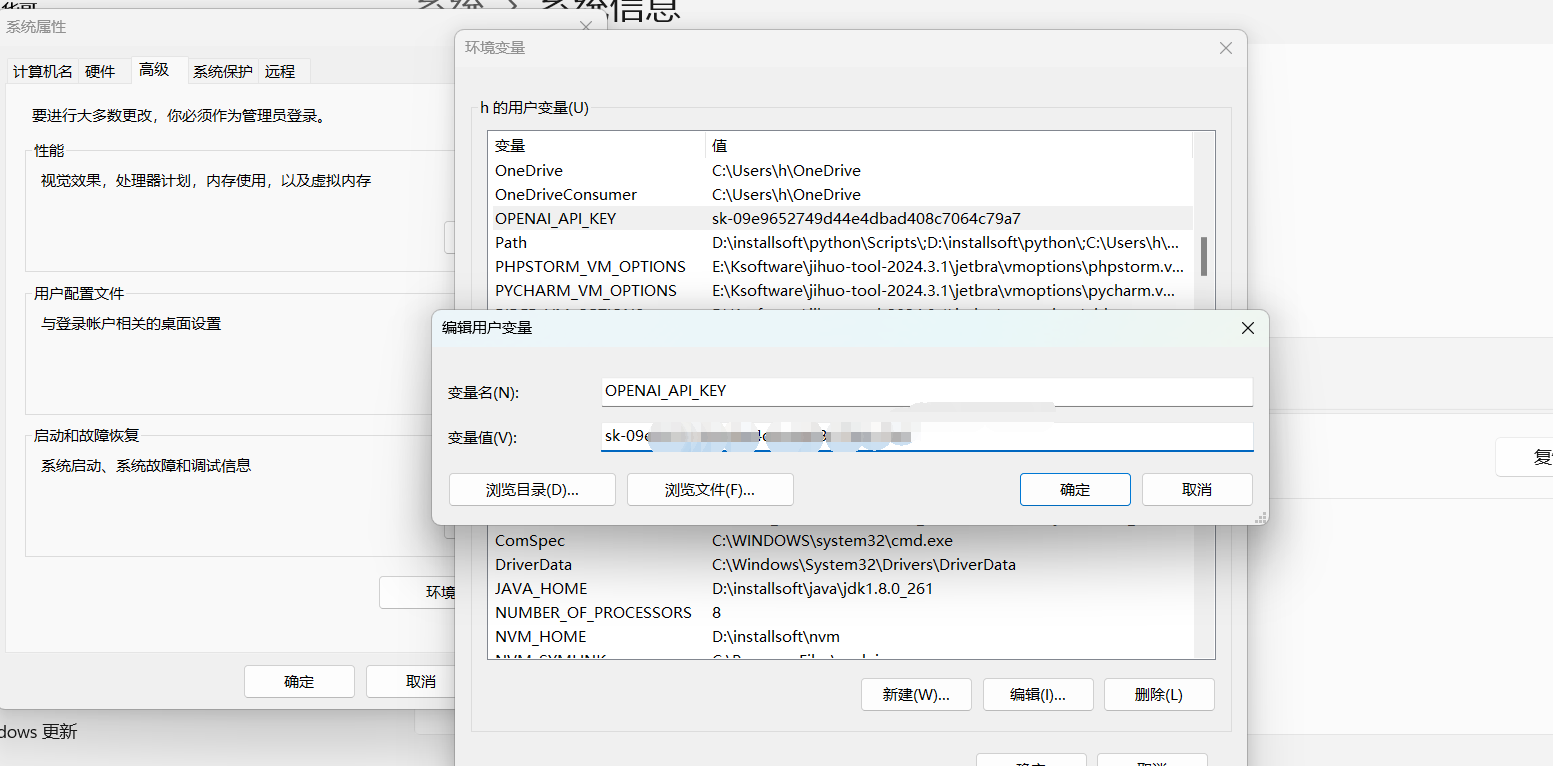
在用户变量里面添加OPENAI_API_KEY之后,一定要从启电脑才可以生效!!
2.2 langchan_openai
-
langchain-openai 是基于 openai 原生 SDK 的上层封装库,依赖 openai 实现底层的 API 调用,简单说,就是针对 LangChain 生态做了适配,使其能够完美适配langchain的其他组件
-
Agent、LangChain和RAG三者关系:Agent是具备记忆、规划等能力的智能体;LangChain是提供基础设施的开发框架;RAG用于知识检索增强。
LangChain的定位是代码驱动的开发工具,适合需要高度定制化功能的场景。用户需通过 Python 编写代码,灵活组合模块(如记忆管理、RAG、Agent 等)构建复杂应用 。它更适合技术团队,尤其是需要结合多模型、多数据源的高阶开发者,这样拥有了更多的灵活度,以及更方便开发一些高级智能体。
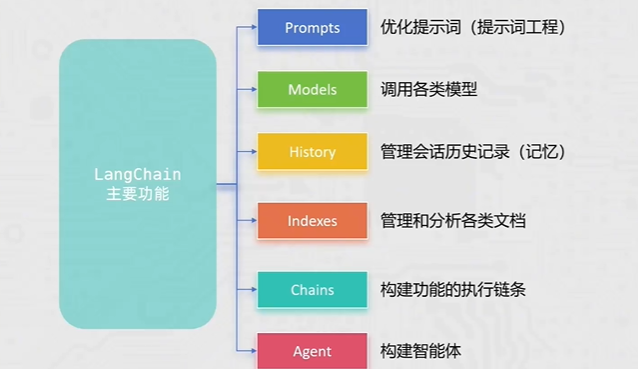
langchain:核心包
langchain-community:社区支持包,提供了更多的第三方模型调用(我们用的阿里云千问模型就需要这个包)langchain-ollama:Ollama支持包,支持调用Ollama托管部署的本地模型
dashscope:阿里云通义千问的Python SDK
chromadb:轻量向量数据库(后续使用)
接着我们安装一下,pip安装依赖包会很慢,我们可以通过镜像来安装:
常用国内镜像源推荐(实测清华源速度最快、最稳定):
- 清华大学:
https://pypi.tuna.tsinghua.edu.cn/simple - 阿里云:
https://mirrors.aliyun.com/pypi/simple/ - 中国科技大学:
https://pypi.mirrors.ustc.edu.cn/simple/ - 豆瓣:
http://pypi.douban.com/simple/
pip install langchain langchain-community langchain-ollama dashscope chromadb -i https://mirrors.aliyun.com/pypi/simple/
这样我们的LangChain环境就搞好了。
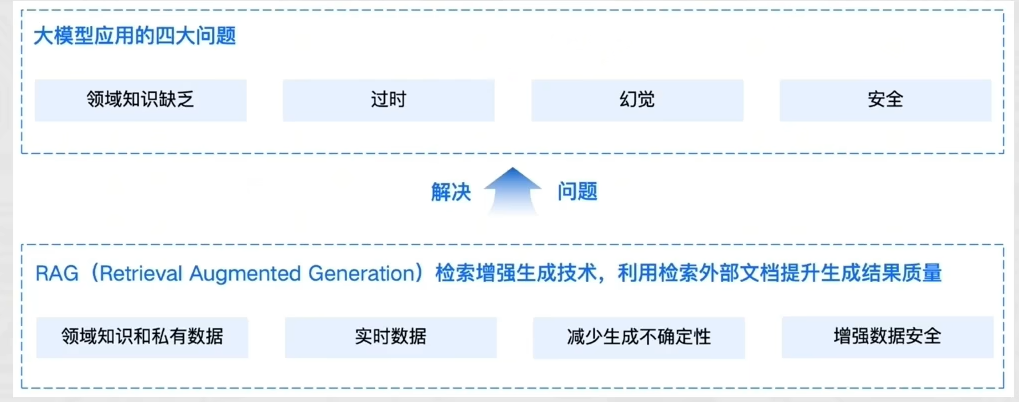
通用的基础大模型存在一些问题:
LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息
RAG工作分为两条线:
离线准备线/在线服务线
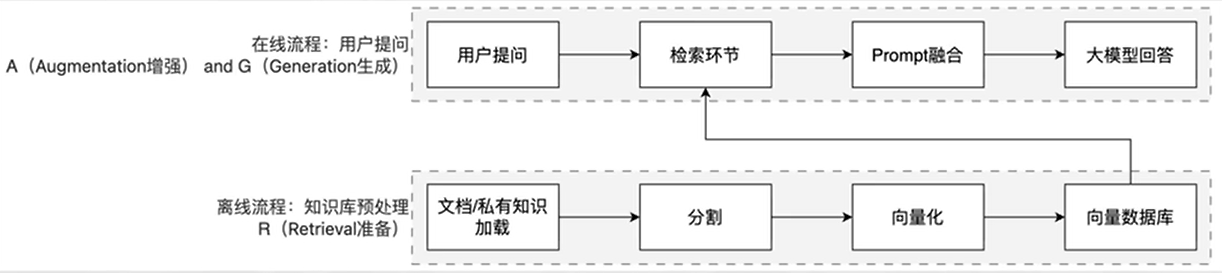
RAG的核心价值:
解决知识实效性问题:大模型的训练数据有截止时间,RAG可以接入最新文档(如公司财报、政策文件),让模型输出"与时俱进"
降低模型幻觉:模型的回答基于检索到的事实性资料,而非纯靠自身记忆,大幅减少编造信息的概率。
无需重新训练模型:相比微调(Fine-tuning),RAG只需更新知识库,成本更低、效率更高。
LangChain 消息简写:
下面我们来生成一个聊天模型写搜古诗:
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
# 得到模型对象, qwen3-max就是聊天模型
model = ChatTongyi(model="qwen3-max")
# 准备消息列表
messages = [
SystemMessage(content="你是一个边塞诗人。"),
HumanMessage(content="写一首唐诗"),
AIMessage(content="锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content="按照你上一个回复的格式,在写一首唐诗。")
]
# 调用stream流式执行
res = model.stream(input=messages)
# for循环迭代打印输出,通过.content来获取到内容
for chunk in res:
print(chunk.content, end="", flush=True)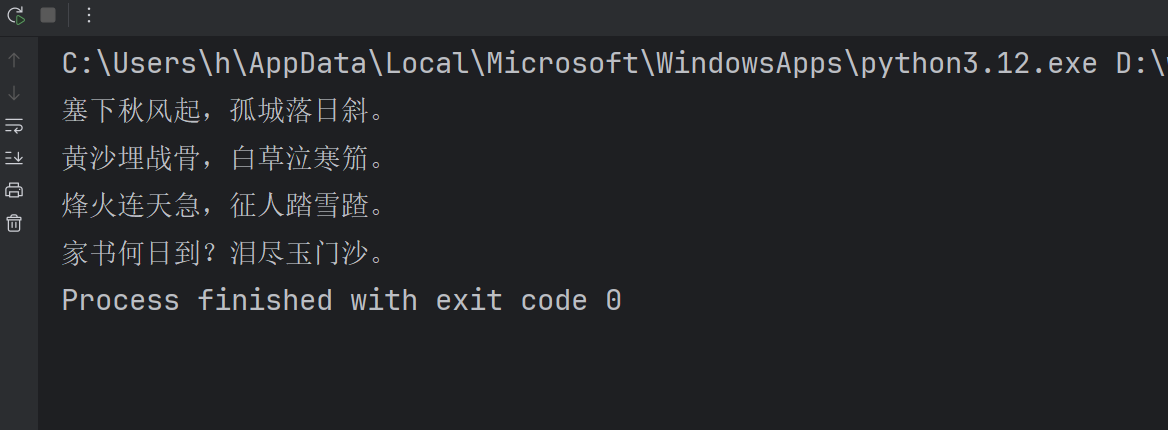
少样本模板(Few-Shot Prompt Template)
组装FewShotPromptTemplate对象,获取追踪提示词
from langchain_core.prompts import FewShotPromptTemplate
FewShotPromptTemplate(
examples=None,
example_prompt=None,
prefix=None
suffix=None,
input_variables=None)
参数:
examples:示例数据,list,内套字典
example_prompt:示例数据的提示词模板
prefix:组装提示词,示例数据前内容suffix:组装提示词,示例数据后内容
input_variables:列表,注入的变量列表
如下代码:
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_community.llms.tongyi import Tongyi
# 示例的模板
example_template = PromptTemplate.from_template("单词:{word}, 反义词:{antonym}")
# 示例的动态数据注入 要求是list内部套字典
examples_data = [
{"word": "大", "antonym": "小"},
{"word": "粗", "antonym": "细"},
]
few_shot_template = FewShotPromptTemplate(
example_prompt=example_template, # 示例数据的模板
examples=examples_data, # 示例的数据(用来注入动态数据的),list内套字典
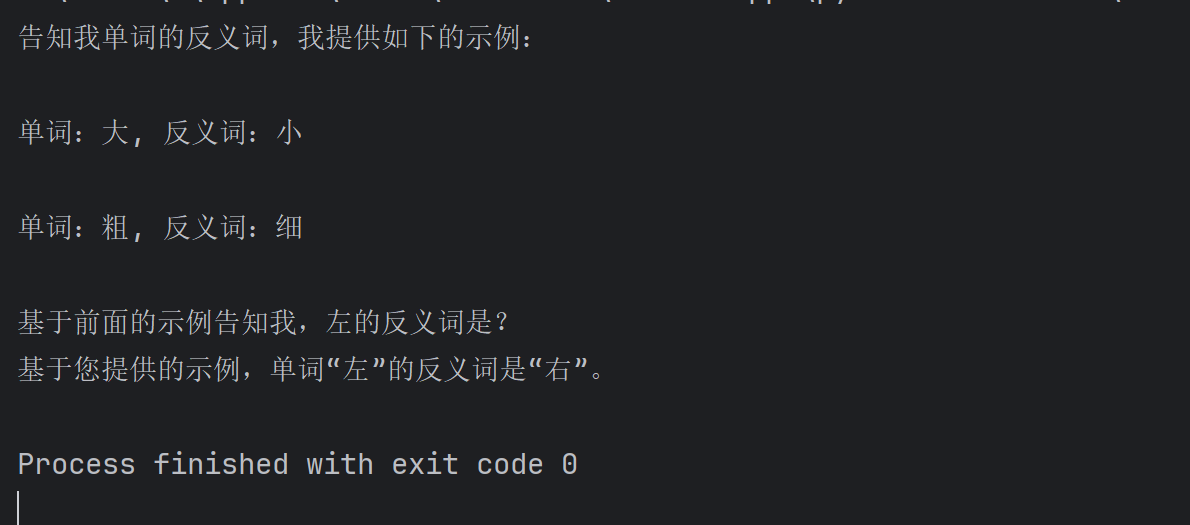
prefix="告知我单词的反义词,我提供如下的示例:", # 示例之前的提示词
suffix="基于前面的示例告知我,{input_word}的反义词是?", # 示例之后的提示词
input_variables=['input_word'] # 声明在前缀或后缀中所需要注入的变量名
)
prompt_text = few_shot_template.invoke(input={"input_word": "左"}).to_string()
print(prompt_text)
model = Tongyi(model="qwen-max")
print(model.invoke(input=prompt_text))可以看到prompts输出结果:
三. chain链的构建和使用
chain链是将多个基础组件(Prompt、LLM 模型、输出解析器、工具等)按逻辑串联起来的执行流程,解决单一组件无法完成的复杂任务,上一个组件的输出作为下一个组件的输入。
构建chain链的组件,一般得是Runnable子类对象,(普通方法、字典也可加入)。langchain的绝大多数组件都是Runnable接口的子类,包括提示词模板,模型类等等,为什么都有invoke、stream方法,就是继承重写了Runnable接口的invoke抽象方法。
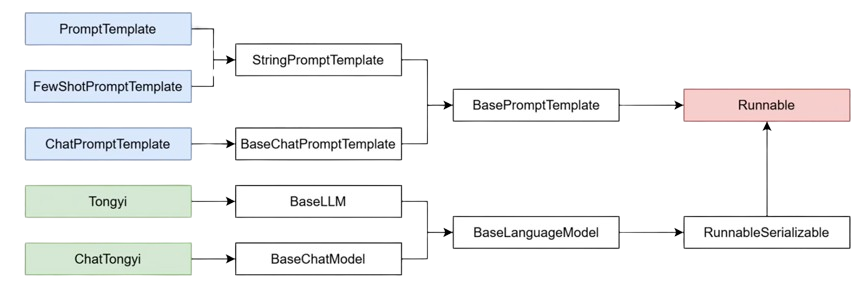
chain链的构建是通过 | 或连接符 进行连接,本质上是langchain各类组件对__or__()魔术方法的重写实现的,比如
chain = prompt | model | parser
返回值chain对象也是RunnableSerializable对象,RunnableSerializable对象是Runnable接口的直接子类也是绝大多数组件的父类,因此,chain对象也是通过invoke或者stream进行阻塞执行或者流式执行整条链条上的所有组件节点。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个边塞诗人,可以作诗。"),
MessagesPlaceholder("history"),
("human", "请再来一首唐诗"),
]
)
history_data = [
("human", "你来写一个唐诗"),
("ai", "床前明月光,疑是地上霜,举头望明月,低头思故乡"),
("human", "好诗再来一个"),
("ai", "锄禾日当午,汗滴禾下锄,谁知盘中餐,粒粒皆辛苦"),
]
model = ChatTongyi(model="qwen3-max")
# 组成链,要求每一个组件都是Runnable接口的子类
chain = chat_prompt_template | model
# 通过链去调用invoke或stream
# res = chain.invoke({"history": history_data})
# print(res.content)
# 通过stream流式输出
for chunk in chain.stream({"history": history_data}):
print(chunk.content, end="", flush=True)输出结果:

以上是简单的基于主流的LangChain技术从大模型提示词已经apikey得使用,AI智能体有很多需要学习,后面继续。