稍后同步代码到Github Repo
一、任务分析
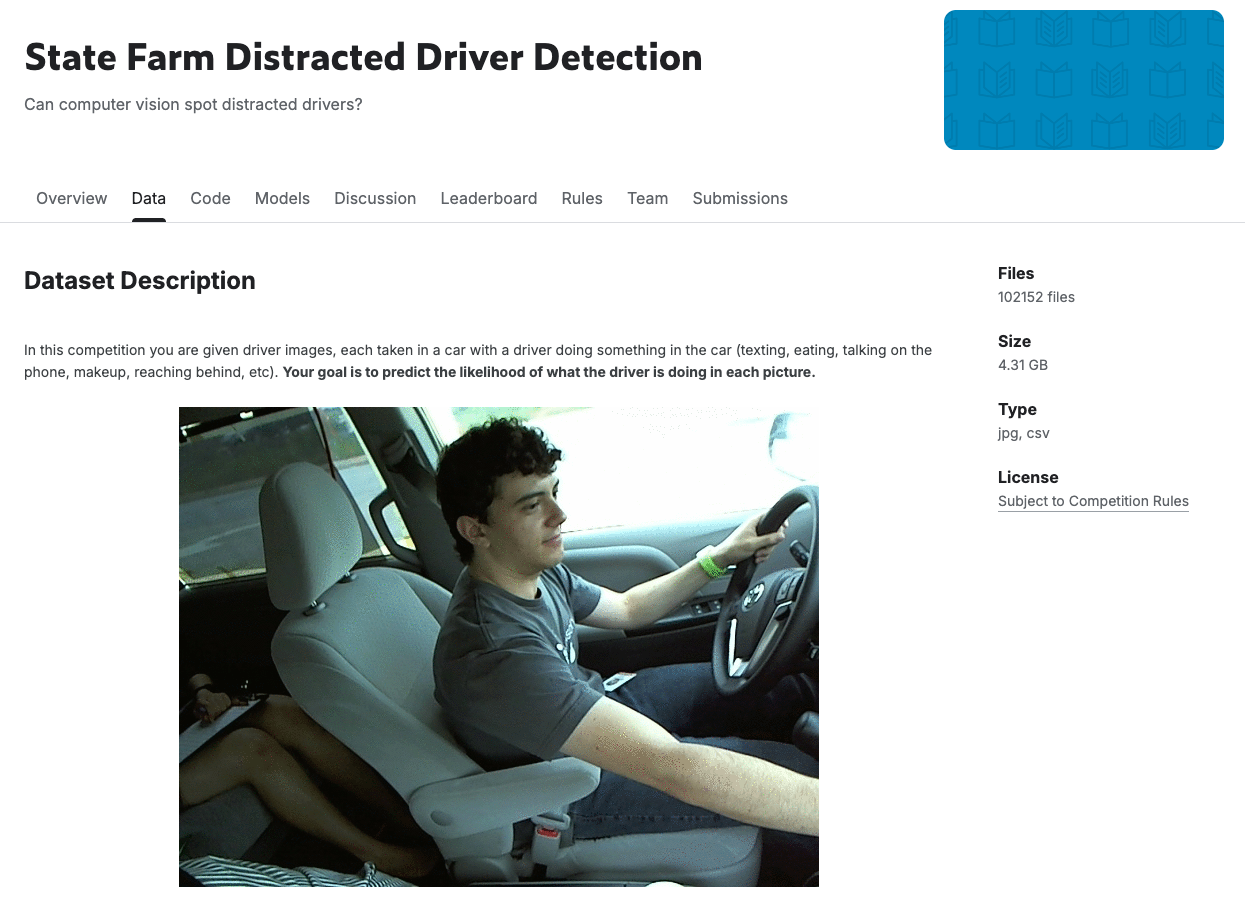
首先明确,目标任务是在本地对驾驶行为的识别,使用驾驶行为数据集,用于后续的分析和处理,由此计划两个方案:
- 方案一:骨架提取 -> 动作分类 (Pipeline 方案):
-
关于数据集与标注:骨架提取(Pose Estimation)本质上属于回归任务,需要大量关键点(Keypoints)标注数据支撑。通常不会从零开始训练,而是直接采用现成的预训练模型(如Google的MoveNet或MediaPipe的轻量级模型)。你现有的驾驶员数据集仅包含分类标签,无法满足骨架模型的训练需求。
-
算力分配方案(CPU vs NPU):
-
骨架提取模块:由于采用深度学习模型(本质为卷积神经网络),计算量极大,必须优先部署在NPU上运行。若交由CPU处理,在MCU平台上的单帧推理时间可能长达数秒。
-
动作分类模块:输入仅为17个关键点的一维坐标数据,可采用以下任一方案:
- 直接编写启发式规则(Heuristic Rules)由CPU处理
- 改用传统机器学习算法(如SVM、决策树)在CPU上执行
- 继续使用NPU运行简单的多层感知机(MLP)
-
-
致命风险: 现成的骨架提取模型通常包含比较复杂的算子(比如特殊的 Reshape、ArgMax、或者自定义的后处理层)。RUHMI 这种针对 MCU 的 AI 编译器,很有可能不支持这些复杂算子,导致编译失败或者强制 fallback 到 CPU。
-
这里参考了RUHMI支持算子列表
- 方案二:端到端视觉模型 (End-to-End 方案)
- 直接实现一个图像分类的模型,而且由于prototype当中任务简单,可以直接作为标准的图片分类模型来处理,而不需要过于复杂的Detector。
- Darknet 的 C 代码如果不能被编译器有效映射到 NPU,纯靠 CPU 跑会卡成幻灯片。
二、模型训练
1. 数据提取
- 下载数据集
bash
kaggle competitions download -c state-farm-distracted-driver-detection- 因为任务比较简单,所以直接从数据集当中提取一部分数据作为训练数据,这里选取了三个类别,每个类别400张图片用于训练、120张图片用于验证
bash
使用压缩包: state-farm-distracted-driver-detection.zip
c0: train=400 张, val=120 张
c6: train=400 张, val=120 张
c7: train=400 张, val=120 张- 后续再提取30张图片用作PTQ的校准
2. 模型构建
- 手动构建了CNN用于分类:
python
class TinyMCUCNN(nn.Module):
"""
极简 CNN:
仅使用以下算子,保证对 MCU INT8 量化编译器友好:
- Conv2d
- ReLU
- MaxPool2d
- Flatten
- Linear
"""3. 模型训练
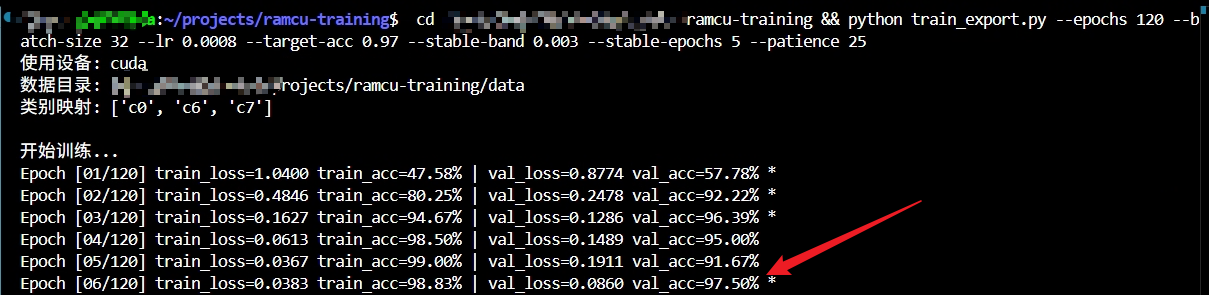 模型训练
模型训练
- 最终模型在这个任务上的准确率达到了97.50%
三、模型转换和编译
1. 模型校准
bash
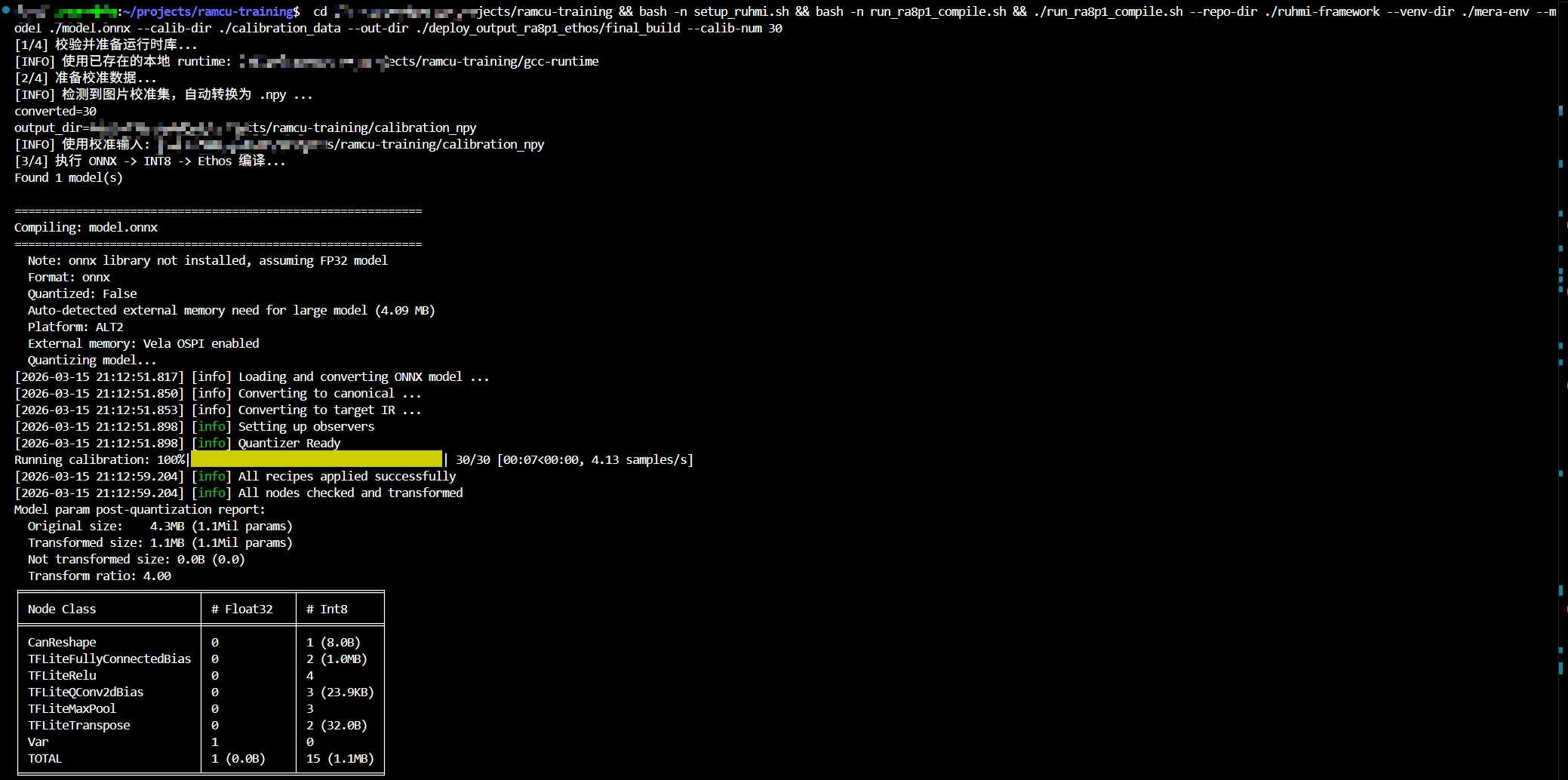
echo "[1/4] 校验并准备运行时库..."
ensure_runtime_lib
RUNTIME_LIB="$RUNTIME_PREFIX/lib"
if [[ -d "$RUNTIME_LIB" ]]; then
export LD_LIBRARY_PATH="$RUNTIME_LIB:${LD_LIBRARY_PATH:-}"
fi
echo "[2/4] 准备校准数据..."
CALIB_SOURCE="$(prepare_calibration_data)"
echo "[INFO] 使用校准输入: $CALIB_SOURCE"
echo "[3/4] 执行 ONNX -> INT8 -> Ethos 编译..."
mkdir -p "$OUT_DIR"
export PATH="$VENV_DIR/bin:${PATH}"
cd "$REPO_DIR"
"$VENV_DIR/bin/python" scripts/mcu_compile.py \
"$MODEL_PATH" \
"$OUT_DIR" \
--npu \
--quantize \
--calib-data "$CALIB_SOURCE" \
--calib-num "$CALIB_NUM" \
--ref-data
echo "[4/4] 汇总输出目录..."
DEPLOY_DIR="$(find "$OUT_DIR" -type d -path '*/deploy' | head -n 1 || true)"
SRC_DIR="$(find "$OUT_DIR" -type d -path '*/deploy/build/MCU/compilation/src' | head -n 1 || true)"
echo
echo "[DONE] 编译流程完成。"
echo "输出根目录: $OUT_DIR"
if [[ -n "$DEPLOY_DIR" ]]; then
echo "部署目录: $DEPLOY_DIR"
fi
if [[ -n "$SRC_DIR" ]]; then
echo "C代码目录: $SRC_DIR"
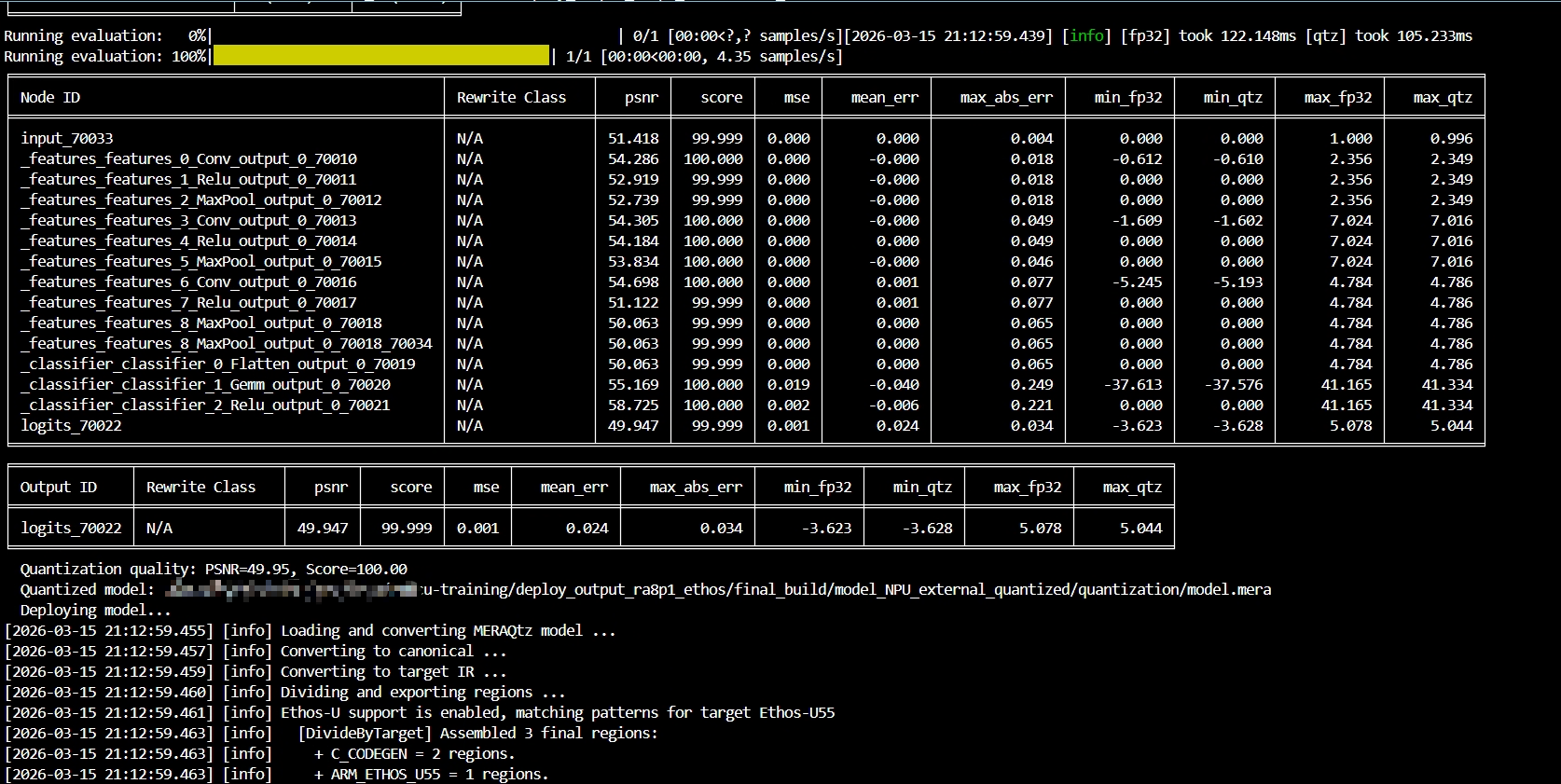
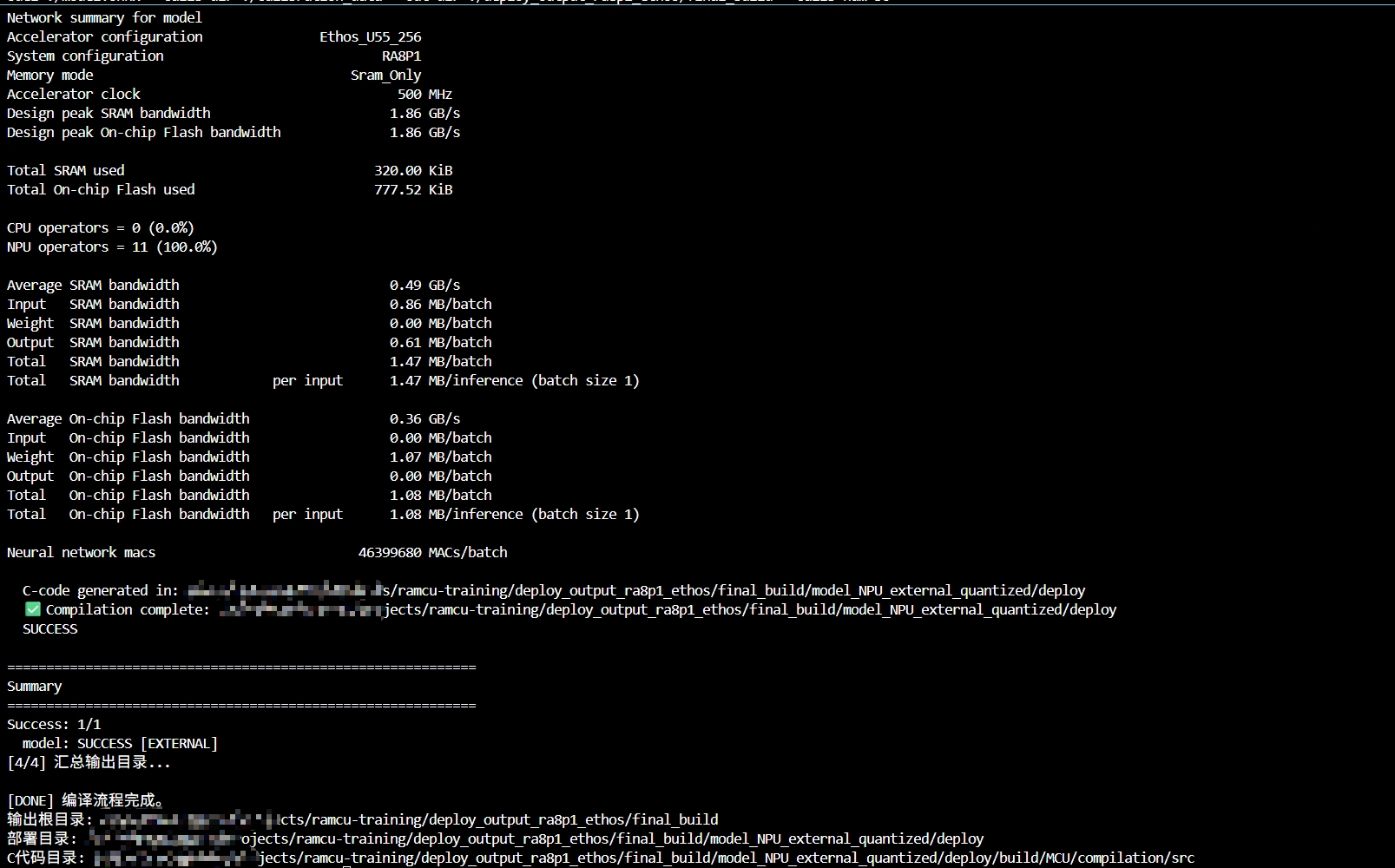
fi编译在量化阶段,被系统 C++ 运行库卡住:缺少 GLIBCXX_3.4.31/3.4.32,这是 fe_onnx_cli 的依赖问题:
- 系统最高只有 GLIBCXX_3.4.30,Conda 里也不够,必须补一个更新的 libstdc++ 运行库才能让 MERA 的 fe_onnx_cli 工作
2. 模型转换