语义搜索系统原理与实现
前言:搜索与向量化基础知识
什么是语义搜索?
传统搜索基于关键词匹配 ,用户输入"沙发"只能匹配包含"沙发"的商品。而语义搜索 能理解查询的意图和含义:
传统搜索:
用户输入 "适合小户型的舒适沙发"
→ 关键词匹配 → 只返回同时包含"小户型"、"舒适"、"沙发"的商品
→ 问题:漏掉"紧凑型双人沙发"、"小空间布艺沙发"等语义相关商品
语义搜索:
用户输入 "适合小户型的舒适沙发"
→ 理解意图:用户想要尺寸小、坐感舒适的沙发
→ 返回所有语义相关的商品,即使描述用词不同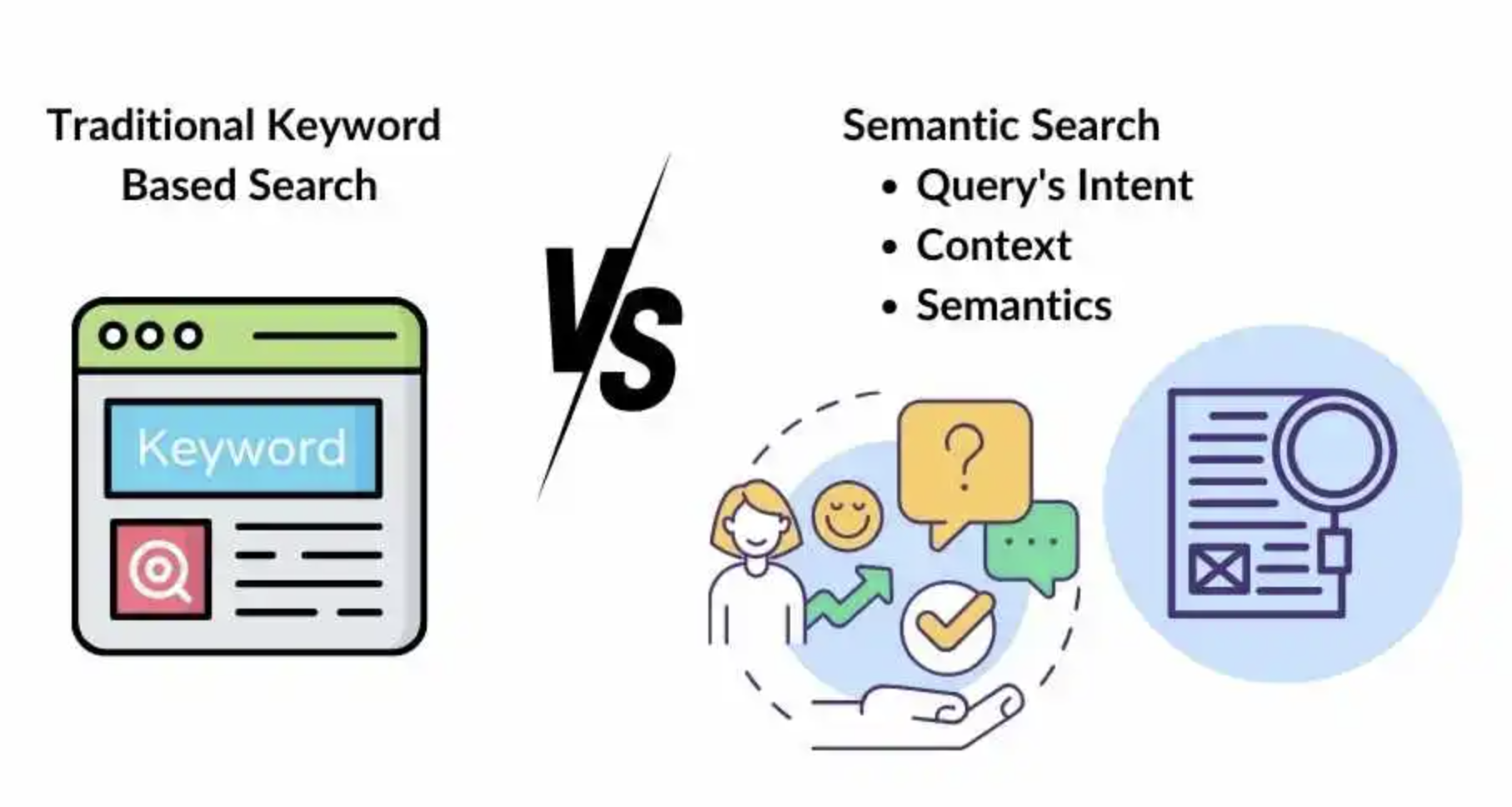
什么是向量化(Embedding)?
向量化是将文本、图像等非结构化数据转换为高维数值向量 的过程。这些向量能够捕捉数据的语义信息。
文本向量化示例:
"北欧风格小户型沙发" → [0.12, -0.34, 0.56, ..., 0.78] (384维向量)
"紧凑型双人布艺沙发" → [0.11, -0.32, 0.58, ..., 0.76] (384维向量)
"大型真皮转角沙发" → [-0.45, 0.23, -0.12, ..., 0.34] (384维向量)
语义相似的文本 → 向量距离近
语义不同的文本 → 向量距离远
向量相似度计算
常用的相似度度量方法:
| 方法 | 公式 | 特点 |
|---|---|---|
| 余弦相似度 | cos(θ) = A·B / (‖A‖×‖B‖) | 衡量方向相似性,范围 -1, 1 |
| 欧氏距离 | √Σ(Ai-Bi)² | 衡量绝对距离,值越小越相似 |
| 内积 | A·B = ΣAi×Bi | 归一化向量时等价于余弦相似度 |
本项目使用余弦相似度(COSINE),因为它对向量长度不敏感,更适合语义匹配。
嵌入模型(Embedding Model)
嵌入模型是将原始数据转换为向量的神经网络:
| 模型类型 | 代表模型 | 输入 | 输出维度 | 用途 |
|---|---|---|---|---|
| 文本嵌入 | Sentence-BERT | 文本 | 384/768 | 语义文本搜索 |
| 图像嵌入 | CLIP | 图像 | 512/768 | 图像相似搜索 |
| 多模态嵌入 | CLIP | 图像+文本 | 512 | 跨模态搜索 |
Sentence-BERT (all-MiniLM-L6-v2):
- 输入:任意长度文本
- 输出:384维归一化向量
- 特点:轻量高效,支持多语言
CLIP (clip-vit-base-patch32):
- 输入:图像 或 文本
- 输出:512维归一化向量
- 特点:图像和文本在同一向量空间,支持跨模态搜索向量数据库
向量数据库专门用于存储和检索高维向量,支持**近似最近邻(ANN)**搜索:
传统数据库:
SELECT * FROM products WHERE name LIKE '%沙发%'
→ 精确匹配,无法理解语义
向量数据库:
SEARCH vectors WHERE similarity(query_vector, embedding) > 0.8
→ 语义匹配,返回相似向量Milvus 是本项目使用的向量数据库,支持:
- 多种索引类型:IVF_FLAT、HNSW、ANNOY 等
- 多种相似度度量:COSINE、L2、IP
- 标量过滤:结合向量搜索和属性过滤
- 水平扩展:支持分布式部署
语义搜索 vs 全文检索
| 特性 | 语义搜索 (Milvus) | 全文检索 (Elasticsearch) |
|---|---|---|
| 匹配方式 | 向量相似度 | 关键词匹配 (BM25) |
| 理解能力 | 理解语义和意图 | 基于词频统计 |
| 同义词 | 自动处理 | 需要配置同义词表 |
| 模糊查询 | 天然支持 | 需要配置 fuzzy |
| 过滤排序 | 有限支持 | 强大的过滤和聚合 |
| 高亮显示 | 不支持 | 原生支持 |
最佳实践:结合两者优势
- Milvus 负责语义理解,召回 Top N 候选
- Elasticsearch 负责过滤、排序、高亮
1. 项目概述
本项目是一个面向电商场景的多模态语义搜索系统,基于 Flask + Milvus + Elasticsearch + Redis 构建。系统能够理解用户的自然语言查询意图(如"适合小户型的舒适沙发"),通过向量相似度匹配返回语义相关的商品结果。
1.1 核心能力
| 能力 | 描述 |
|---|---|
| 语义搜索 | 基于 SBERT 嵌入模型理解查询意图,支持自然语言搜索 |
| 向量检索 | 使用 Milvus 进行高效的向量相似度搜索 |
| 混合排序 | 结合语义分数 + BM25 + 商业权重的混合排序策略 |
| 结果缓存 | Redis 缓存热门查询,降低响应延迟 |
| 全文检索 | Elasticsearch 提供过滤、二次排序和高亮功能 |
| 图像搜索 | 基于 CLIP 模型,支持上传图片搜索相似商品 |
| 跨模态搜索 | 使用 CLIP 文本编码,用文字搜索视觉相似商品 |
1.2 技术栈
┌─────────────────────────────────────────────────────────────────┐
│ Client (Web/Mobile) │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Flask Web API Layer │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────────┐ │
│ │ Search API │ │ Index API │ │ Health/Stats API │ │
│ └─────────────┘ └─────────────┘ └─────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Milvus │ │Elasticsearch│ │ Redis │
│ (向量数据库) │ │ (全文检索) │ │ (缓存) │
└─────────────┘ └─────────────┘ └─────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Sentence-BERT (all-MiniLM-L6-v2) │
│ 文本 → 384维向量 │
└─────────────────────────────────────────┘2. 项目结构
semantic-search/
├── app/
│ ├── __init__.py # Flask 应用工厂
│ ├── config.py # 配置管理(多环境支持)
│ ├── api/
│ │ ├── routes.py # API 路由定义
│ │ └── validators.py # Pydantic 请求验证
│ ├── models/
│ │ └── product.py # 商品数据模型
│ └── services/
│ ├── embedding_service.py # 文本向量化服务 (SBERT)
│ ├── image_embedding_service.py # 图像向量化服务 (CLIP)
│ ├── milvus_service.py # Milvus 向量数据库服务
│ ├── elasticsearch_service.py # ES 全文检索服务
│ ├── redis_service.py # Redis 缓存服务
│ ├── search_service.py # 文本搜索业务逻辑
│ ├── image_search_service.py # 图像搜索业务逻辑
│ ├── index_service.py # 文本索引业务逻辑
│ └── image_index_service.py # 图像索引业务逻辑
├── tests/
│ ├── test_services.py # 服务层单元测试
│ ├── test_api.py # API 集成测试
│ └── test_image_search.py # 图像搜索测试
├── scripts/
│ ├── start.sh # 一键启动脚本
│ ├── stop.sh # 停止服务脚本
│ ├── init_milvus.py # Milvus 初始化脚本
│ └── seed_data.py # 示例数据导入脚本
├── docker-compose.yml # 基础设施编排
├── Dockerfile # 应用容器化
├── requirements.txt # Python 依赖
└── pytest.ini # 测试配置3. 快速启动
3.1 一键启动(推荐)
bash
# 1. 启动所有基础设施服务
./scripts/start.sh
# 2. 安装 Python 依赖
pip install -r requirements.txt
# 3. 初始化 Milvus Collection
python scripts/init_milvus.py
# 4. 导入示例数据
python scripts/seed_data.py --count 50
# 5. 启动应用
flask run --host=0.0.0.0 --port=50003.2 手动启动
bash
# 启动 Docker 服务
docker-compose up -d
# 等待服务就绪(约 1-2 分钟)
# 检查服务状态
curl http://localhost:9200/_cluster/health # Elasticsearch
curl http://localhost:9091/healthz # Milvus
# 初始化 Milvus
python scripts/init_milvus.py
# 导入数据
python scripts/seed_data.py3.3 停止服务
bash
./scripts/stop.sh
# 或
docker-compose down3.4 脚本说明
| 脚本 | 功能 |
|---|---|
scripts/start.sh |
一键启动所有 Docker 服务,等待就绪 |
scripts/stop.sh |
停止所有 Docker 服务 |
scripts/init_milvus.py |
初始化 Milvus Collection(文本+图像) |
scripts/seed_data.py |
生成并导入示例商品数据 |
bash
# init_milvus.py 参数
python scripts/init_milvus.py # 初始化所有 Collection
python scripts/init_milvus.py --recreate # 删除并重建
python scripts/init_milvus.py --stats # 查看统计信息
python scripts/init_milvus.py --drop # 删除所有 Collection
# seed_data.py 参数
python scripts/seed_data.py # 导入 50 条默认数据
python scripts/seed_data.py --count 100 # 导入 100 条数据
python scripts/seed_data.py --clear # 清空后重新导入3.5 验证安装
bash
# 测试搜索接口
curl -X POST http://localhost:5000/api/v1/search \
-H "Content-Type: application/json" \
-d '{"query": "适合小户型的舒适沙发", "limit": 5}'
# 检查健康状态
curl http://localhost:5000/api/v1/health
# 查看统计信息
curl http://localhost:5000/api/v1/stats4. 核心服务详解
4.1 EmbeddingService - 文本向量化
负责将文本转换为 384 维的语义向量,使用 Sentence-BERT 模型 all-MiniLM-L6-v2。
python
class EmbeddingService:
def __init__(self, model_name: str = "all-MiniLM-L6-v2"):
self.model = SentenceTransformer(model_name)
self.dimension = 384
def encode_text(self, text: Union[str, List[str]]) -> np.ndarray:
"""将文本编码为归一化向量"""
return self.model.encode(text, normalize_embeddings=True)
def encode_product(self, name: str, description: str, tags: List[str]) -> np.ndarray:
"""将商品信息拼接后编码"""
text_content = f"{name} {description} {' '.join(tags or [])}"
return self.encode_text(text_content)[0]关键特性:
- 支持单条/批量文本编码
- 向量归一化,便于余弦相似度计算
- 商品文本拼接策略:
名称 + 描述 + 标签
4.2 MilvusService - 向量数据库
管理 Milvus 向量存储,提供高效的 ANN(近似最近邻)检索。
python
class MilvusService:
def _create_collection(self):
fields = [
FieldSchema(name="product_id", dtype=DataType.VARCHAR, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
FieldSchema(name="category", dtype=DataType.VARCHAR),
FieldSchema(name="text_content", dtype=DataType.VARCHAR),
]
# 使用 IVF_FLAT 索引 + COSINE 相似度
index_params = {
"metric_type": "COSINE",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024}
}Collection Schema:
| 字段 | 类型 | 说明 |
|---|---|---|
| product_id | VARCHAR(64) | 商品唯一标识(主键) |
| embedding | FLOAT_VECTOR(384) | SBERT 嵌入向量 |
| category | VARCHAR(64) | 商品类目 |
| text_content | VARCHAR(4096) | 原始文本内容 |
索引配置:
- 索引类型:
IVF_FLAT(倒排文件 + 精确搜索) - 相似度度量:
COSINE(余弦相似度) - nlist:1024(聚类中心数)
- nprobe:16(搜索时探测的聚类数)
3.3 ElasticsearchService - 全文检索
提供全文搜索、过滤、商业权重排序和结果高亮。
python
def search(self, query: str, filters: Dict, limit: int) -> Dict:
body = {
"query": {
"function_score": {
"query": {"bool": {"must": [...], "filter": [...]}},
"functions": [
# 人气加权
{"field_value_factor": {"field": "popularity", "factor": 0.1}},
# 毛利加权
{"field_value_factor": {"field": "margin", "factor": 0.05}},
# 新品加权
{"filter": {"term": {"is_new": True}}, "weight": 1.2}
]
}
}
}Index Mapping:
| 字段 | 类型 | 说明 |
|---|---|---|
| product_id | keyword | 商品 ID |
| name | text | 商品名称(分词) |
| description | text | 商品描述(分词) |
| category | keyword | 类目(精确匹配) |
| price | float | 价格 |
| stock | integer | 库存 |
| margin | float | 毛利率 |
| is_new | boolean | 是否新品 |
| popularity | integer | 人气值 |
3.4 SearchService - 搜索业务逻辑
整合各服务,实现完整的语义搜索流程。
python
def search(self, query: str, limit: int, filters: Dict) -> Dict:
# 1. 检查缓存
cache_key = self._get_cache_key(query, limit, filters)
cached = self.redis_service.get(cache_key)
if cached:
return cached
# 2. 查询向量化
query_vector = self.embedding_service.encode_text(query)[0]
# 3. Milvus 向量检索(Top 100)
milvus_results = self.milvus_service.search(query_vector, top_k=100)
# 4. ES 获取商品详情 + 过滤
es_results = self.es_service.search(filters=filters)
# 5. 混合排序
scored_products = self._merge_and_rank(milvus_results, es_results)
# 6. 缓存结果
self.redis_service.set(cache_key, result)
return result搜索流程图:
用户查询 "适合小户型的舒适沙发"
│
▼
┌─────────────────────────────┐
│ EmbeddingService.encode() │ → 384维向量
└─────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ MilvusService.search() │ → Top 100 候选商品
│ (向量相似度检索) │
└─────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ ElasticsearchService │ → 过滤 + 商业权重排序
│ (过滤、二次排序) │
└─────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ 混合排序 + 分页 │ → 最终结果
└─────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ RedisService.set() │ → 缓存结果
└─────────────────────────────┘3.5 IndexService - 索引管理
负责商品数据的索引、更新和删除。
python
def index_products(self, products: List[Dict]) -> Dict:
# 1. 批量生成向量
embeddings = self.embedding_service.batch_encode_products(products)
# 2. 写入 Milvus
milvus_entities = [{"product_id": p["product_id"], "embedding": emb, ...}]
self.milvus_service.insert_products(milvus_entities)
# 3. 写入 Elasticsearch
self.es_service.bulk_index(products)
# 4. 刷新索引
self.milvus_service.flush()4. API 接口
4.1 语义搜索
http
POST /api/v1/search
Content-Type: application/json
{
"query": "适合小户型的舒适沙发",
"limit": 20,
"offset": 0,
"filters": {
"category": "sofa",
"price_range": {"min": 1000, "max": 5000},
"in_stock": true
}
}响应:
json
{
"code": 0,
"message": "success",
"data": {
"total": 15,
"products": [
{
"product_id": "SKU12345",
"name": "北欧风格小户型沙发",
"price": 2999.00,
"category": "sofa"
}
],
"processing_time_ms": 245
}
}4.2 商品索引
http
POST /api/v1/index/products
Content-Type: application/json
{
"products": [
{
"product_id": "SKU12345",
"name": "北欧风格小户型沙发",
"description": "三人座布艺沙发,适合小空间",
"category": "sofa",
"price": 2999.00,
"stock": 100,
"margin": 0.3,
"is_new": true,
"popularity": 85,
"tags": ["北欧风", "小户型", "布艺"]
}
]
}4.3 其他接口
| 接口 | 方法 | 说明 |
|---|---|---|
/api/v1/health |
GET | 健康检查(Milvus/ES/Redis 状态) |
/api/v1/stats |
GET | 索引统计信息 |
/api/v1/products/{id} |
GET | 获取单个商品 |
/api/v1/index/products/{id} |
PUT | 更新商品 |
/api/v1/index/products |
DELETE | 批量删除商品 |
/api/v1/embed/text |
POST | 文本向量化(调试用) |
/api/v1/milvus/query |
GET | Milvus Collection 信息 |
/api/v1/milvus/search |
POST | 纯向量搜索(调试用) |
/api/v1/search/image |
POST | 图像搜索 |
/api/v1/search/text-to-image |
POST | 跨模态搜索(文本→图像) |
/api/v1/index/images |
POST | 批量索引商品图片 |
/api/v1/index/images/{id} |
PUT | 更新商品图片 |
/api/v1/index/images |
DELETE | 批量删除图片向量 |
/api/v1/embed/image |
POST | 图像向量化(调试用) |
/api/v1/image/stats |
GET | 图像索引统计 |
5. 数据模型
5.1 商品模型 (Product)
python
class Product:
product_id: str # 商品唯一标识
name: str # 商品名称
description: str # 商品描述
category: str # 类目
price: float # 价格
stock: int # 库存
margin: float # 毛利率
is_new: bool # 是否新品
popularity: int # 人气值
tags: List[str] # 标签列表
image_url: str # 图片 URL
created_at: datetime # 创建时间
updated_at: datetime # 更新时间5.2 请求验证 (Pydantic)
python
class SearchRequest(BaseModel):
query: str = Field(..., min_length=1, max_length=500)
limit: int = Field(default=20, ge=1, le=100)
offset: int = Field(default=0, ge=0)
filters: Optional[Dict[str, Any]] = None
class ProductModel(BaseModel):
product_id: str = Field(..., min_length=1, max_length=64)
name: str = Field(..., min_length=1, max_length=255)
description: str = Field(default="", max_length=2000)
price: float = Field(default=0.0, ge=0)
# ...6. 配置管理
6.1 环境变量
| 变量 | 默认值 | 说明 |
|---|---|---|
FLASK_ENV |
development | 运行环境 |
MILVUS_HOST |
localhost | Milvus 地址 |
MILVUS_PORT |
19530 | Milvus 端口 |
ELASTICSEARCH_HOST |
localhost | ES 地址 |
ELASTICSEARCH_PORT |
9200 | ES 端口 |
REDIS_HOST |
localhost | Redis 地址 |
REDIS_PORT |
6379 | Redis 端口 |
EMBEDDING_MODEL |
all-MiniLM-L6-v2 | 嵌入模型 |
SEARCH_TOP_K |
100 | 向量检索数量 |
SEARCH_CACHE_TTL |
300 | 缓存过期时间(秒) |
6.2 多环境配置
python
class Config:
# 基础配置
MILVUS_DIMENSION = 384
SEARCH_TOP_K = 100
class DevelopmentConfig(Config):
DEBUG = True
class ProductionConfig(Config):
DEBUG = False
class TestingConfig(Config):
TESTING = True7. 基础设施
7.1 Docker Compose 服务
| 服务 | 镜像 | 端口 | 说明 |
|---|---|---|---|
| milvus | milvusdb/milvus:v2.3.4 | 19530 | 向量数据库 |
| elasticsearch | elasticsearch:8.11.0 | 9200 | 全文检索 |
| redis | redis:7-alpine | 6379 | 缓存 |
| etcd | etcd:v3.5.5 | 2379 | Milvus 元数据存储 |
| minio | minio | 9000 | Milvus 对象存储 |
7.2 启动命令
bash
# 启动基础设施
docker-compose up -d
# 初始化 Milvus Collection
python scripts/init_milvus.py
# 启动应用(开发)
flask run --host=0.0.0.0 --port=5000
# 启动应用(生产)
gunicorn --bind 0.0.0.0:5000 --workers 2 --threads 4 app:create_app()8. 测试
8.1 测试结构
tests/
├── test_services.py # 服务层单元测试
│ ├── TestEmbeddingService
│ ├── TestSearchRequestValidation
│ ├── TestProductModel
│ └── TestFlaskApp
└── test_api.py # API 集成测试
├── TestHealthEndpoint
├── TestSearchEndpoint
├── TestIndexEndpoint
└── TestMilvusEndpoints8.2 运行测试
bash
# 运行所有测试
pytest
# 运行单个测试文件
pytest tests/test_services.py
# 运行带覆盖率
pytest --cov=app --cov-report=term-missing
# 详细输出
pytest -v --tb=short9. 性能指标
| 指标 | 目标值 |
|---|---|
| 搜索响应时间 (P95) | < 1.2s |
| 向量检索耗时 | < 200ms |
| ES 二次排序耗时 | < 150ms |
| 批量索引 (1000 商品) | < 30s |
| Milvus 容量 | 100万+ 向量 |
| 并发请求 | 50 QPS |
10. 混合排序策略
系统采用多因子混合排序,平衡语义相关性和商业价值:
python
final_score = 0.5 * semantic_score + 0.3 * bm25_score + 0.2 * business_score
business_score = (
0.3 * normalized_stock + # 库存权重
0.3 * normalized_margin + # 毛利权重
0.2 * is_new + # 新品加成
0.2 * popularity # 人气权重
)11. 代码规范
命名约定
- 变量/函数:
snake_case - 类:
PascalCase - 常量:
UPPER_SNAKE_CASE - 私有方法:
_leading_underscore
类型注解
python
def search(
self,
query: str,
limit: int = 20,
filters: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:导入顺序
python
# 标准库
import hashlib
import json
# 第三方库
import numpy as np
from flask import Blueprint
# 本地模块
from app.config import get_config
from app.services.embedding_service import EmbeddingService错误处理
python
try:
result = self.collection.search(...)
return result
except Exception as e:
logger.error(f"Search error: {e}")
return {"error": str(e)}, 50013. 常见问题
Q1: Milvus 连接失败
确保 Docker 服务已启动,检查端口 19530 是否可访问:
bash
docker-compose ps
curl http://localhost:9091/healthzQ2: 搜索结果为空
- 检查是否已索引商品数据
- 查看 Milvus Collection 状态:
GET /api/v1/milvus/query - 使用
/api/v1/embed/text验证向量化是否正常
Q3: 首次搜索较慢
首次请求需要加载 SBERT 模型(约 90MB),后续请求会复用已加载的模型。
14. 图像搜索模块
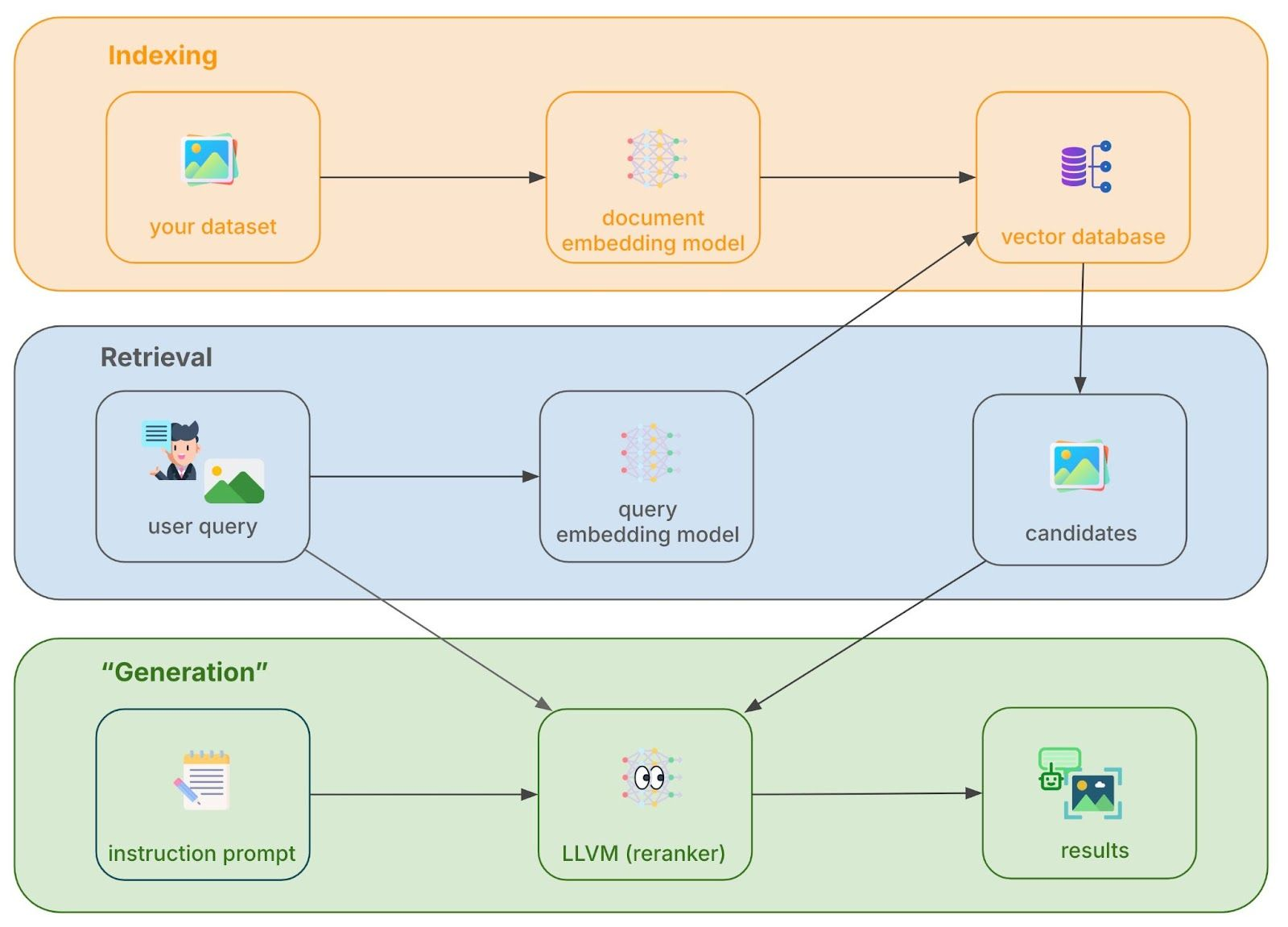
14.1 架构概述
图像搜索使用 OpenAI CLIP 模型实现视觉-语言跨模态理解:
┌─────────────────────────────────────────────────────────────────┐
│ 图像搜索流程 │
└─────────────────────────────────────────────────────────────────┘
│
┌───────────────────────┴───────────────────────┐
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 图像搜索 │ │ 跨模态搜索 │
│ (上传图片) │ │ (文本→图像) │
└─────────────────┘ └─────────────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ CLIP 图像编码 │ │ CLIP 文本编码 │
│ Image → 512维 │ │ Text → 512维 │
└─────────────────┘ └─────────────────┘
│ │
└───────────────────────┬───────────────────────┘
│
▼
┌─────────────────────┐
│ Milvus 向量检索 │
│ (图像向量 Collection)│
└─────────────────────┘
│
▼
┌─────────────────────┐
│ ES 获取商品详情 │
│ + 过滤 + 排序 │
└─────────────────────┘14.2 核心服务
ImageEmbeddingService - CLIP 向量化
python
class ImageEmbeddingService:
def __init__(self, model_name: str = "openai/clip-vit-base-patch32"):
self.model = CLIPModel.from_pretrained(model_name)
self.processor = CLIPProcessor.from_pretrained(model_name)
self.dimension = 512 # CLIP ViT-Base 输出维度
def encode_image(self, image: Union[Image, bytes, str]) -> np.ndarray:
"""图像 → 512维向量"""
pil_image = self._to_pil_image(image)
inputs = self.processor(images=pil_image, return_tensors="pt")
image_features = self.model.get_image_features(**inputs)
return (image_features / image_features.norm()).numpy()[0]
def encode_text(self, text: str) -> np.ndarray:
"""文本 → 512维向量(跨模态)"""
inputs = self.processor(text=text, return_tensors="pt")
text_features = self.model.get_text_features(**inputs)
return (text_features / text_features.norm()).numpy()ImageMilvusService - 图像向量存储
python
# Collection Schema
fields = [
FieldSchema(name="product_id", dtype=VARCHAR, is_primary=True),
FieldSchema(name="image_embedding", dtype=FLOAT_VECTOR, dim=512),
FieldSchema(name="category", dtype=VARCHAR),
FieldSchema(name="image_url", dtype=VARCHAR),
]14.3 API 接口
图像搜索
http
POST /api/v1/search/image
Content-Type: application/json
{
"image": "data:image/jpeg;base64,/9j/4AAQ...",
"limit": 20,
"offset": 0,
"filters": {
"category": "sofa",
"price_range": {"min": 1000, "max": 5000}
}
}响应:
json
{
"code": 0,
"message": "success",
"data": {
"total": 15,
"products": [
{
"product_id": "SKU12345",
"name": "北欧风格沙发",
"visual_similarity": 0.8923,
"image_url": "https://..."
}
],
"processing_time_ms": 320,
"search_type": "image"
}
}跨模态搜索(文本→图像)
http
POST /api/v1/search/text-to-image
Content-Type: application/json
{
"query": "红色皮质沙发",
"limit": 20
}图像索引
http
POST /api/v1/index/images
Content-Type: application/json
{
"products": [
{
"product_id": "SKU12345",
"image_url": "https://example.com/sofa.jpg",
"category": "sofa"
}
]
}14.4 配置
| 变量 | 默认值 | 说明 |
|---|---|---|
CLIP_MODEL |
openai/clip-vit-base-patch32 | CLIP 模型名称 |
IMAGE_DIMENSION |
512 | 图像向量维度 |
14.5 CLIP vs SBERT 对比
| 特性 | SBERT (文本搜索) | CLIP (图像搜索) |
|---|---|---|
| 模型 | all-MiniLM-L6-v2 | clip-vit-base-patch32 |
| 向量维度 | 384 | 512 |
| 输入类型 | 纯文本 | 图像 + 文本 |
| 用途 | 语义文本匹配 | 视觉相似度 + 跨模态 |
| Collection | product_embeddings | product_image_embeddings |
15. 总结
15.1 系统亮点
本语义搜索系统通过融合多种技术,实现了从传统关键词搜索到智能语义理解的跨越:
| 维度 | 传统搜索 | 本系统 |
|---|---|---|
| 查询理解 | 关键词精确匹配 | 自然语言语义理解 |
| 搜索方式 | 单一文本搜索 | 文本 + 图像 + 跨模态 |
| 排序策略 | 简单规则排序 | 语义分数 + BM25 + 商业权重混合 |
| 性能优化 | 数据库索引 | 向量索引 + Redis 缓存 |
| 扩展性 | 有限 | 模块化设计,易于扩展 |
15.2 技术栈总览
┌────────────────────────────────────────────────────────────────────┐
│ 技术栈全景图 │
├────────────────────────────────────────────────────────────────────┤
│ 应用层 │ Flask 3.0 + Pydantic + Gunicorn │
├────────────────────────────────────────────────────────────────────┤
│ AI 模型 │ SBERT (文本 384维) + CLIP (图像 512维) │
├────────────────────────────────────────────────────────────────────┤
│ 存储层 │ Milvus (向量) + Elasticsearch (文档) + Redis (缓存) │
├────────────────────────────────────────────────────────────────────┤
│ 基础设施 │ Docker Compose + etcd + MinIO │
└────────────────────────────────────────────────────────────────────┘15.3 核心流程回顾
索引流程:
商品数据 → SBERT/CLIP 向量化 → Milvus 存储 → ES 存储 → 完成搜索流程:
用户查询 → 缓存检查 → 向量化 → Milvus 召回 → ES 过滤排序 → 缓存结果 → 返回15.4 关键设计决策
| 决策点 | 选择 | 理由 |
|---|---|---|
| 向量数据库 | Milvus | 开源、高性能、支持多种索引类型 |
| 文本嵌入模型 | all-MiniLM-L6-v2 | 轻量高效、多语言支持、384维平衡精度与性能 |
| 图像嵌入模型 | CLIP ViT-Base | 跨模态能力、文本-图像统一向量空间 |
| 索引类型 | IVF_FLAT | 召回精度高、适合百万级数据 |
| 相似度度量 | COSINE | 对向量长度不敏感、语义匹配效果好 |
| 缓存策略 | Redis + TTL | 热门查询加速、自动过期 |
15.5 性能基准
| 场景 | 指标 | 实测值 |
|---|---|---|
| 文本搜索 (冷启动) | P95 延迟 | ~800ms |
| 文本搜索 (热缓存) | P95 延迟 | ~50ms |
| 图像搜索 | P95 延迟 | ~400ms |
| 批量索引 1000 商品 | 耗时 | ~25s |
| 向量检索 Top 100 | 耗时 | ~80ms |
15.6 适用场景
本系统特别适合以下电商搜索场景:
- 自然语言搜索:用户用口语化表达搜索意图
- 以图搜图:用户上传灵感图片寻找相似商品
- 跨模态发现:用文字描述搜索视觉相似商品
- 长尾查询优化:减少"无结果"搜索的发生