👇作者其它专栏
目录
1.为什么学习string类
2.标准库中的string类
3.string类的模拟实现
4.扩展
1.为什么学习string类
1.1C语言中的字符串
C语言中,字符串是以'\0'结尾的一些字符的集合,为方便操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,容易出现越界访问。
2.标准库中的string类
2.1string类
使用string类时,必须包含#include<string>头文件与using namespace std;
2.2auto与范围for
auto关键字
●在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,后来这个不重要了 。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编辑器,auto声明的变量必须由编译器在编译时期推导而得。
●用auto声明指针类型时,用auto和auto*没有任何区别;但用auto引用类型是必须加&。
●当在同一行声明多个变量时,这些必须是相同的类型,否则编译器会将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其它变量。
●auto不能作为函数的参数,可以做返回值,但是谨慎使用
●auto不能直接用来声明数组
#include <iostream>
using namespace std;
int fun1(){
return 1;
}
//不能做参数
void func2(auto a){}
//可以做返回值,但是建议谨慎使用
auto func3(){
return 3;
}
int main(){
int a=1;
auto b=a;
auto c='a';
auto d=func1();
//编译报错,类型包含auto的符号必须具有初始值设定项
auto e;
cout<<typeid(b).name()<<endl;
cout<<typeid(c).name()<<endl;
cout<<typeid(d).name()<<endl;
int x=1;
auto y=&x;
auto *z=&x;
auto &m=x;
cout<<typeid(x).name()<<endl;
cout<<typeid(y).name()<<endl;
cout<<typeid(z).name()<<endl;
auto aa=1,bb=2;
// 编译报错,声明符列表中,auto必须始终推导为同一类型
auto cc=3,dd=4.0;
//编译报错,auto\[\],数组不能具有包含auto的元素类型
auto array\[\]={1,2,3};
return 0;
}
#include <iostream>#include <string>
#include <map>
using namespace std;
int main(){
std::map<std::string,std::string> fruit={{"apple,"苹果"},{"orange","橙子"},{"pear","梨"}};
//auto的作用
//std::map<std::string,std::string>::iterator it=fruit.begin();
auto it=fruit.begin();
while(it!=fruit.end()){
cout<<it->first<<":"<<it->second<<endl;
++it;
}
return 0;
}
范围for
●对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号":"分为两部分:第一部分范围内用于迭代的变量,第二部分则表示被迭代的范围,自动迭代,自动取数据,自动判断结束。
●范围for可以作用到数组和容器对象上进行遍历
●范围for的底层:容器遍历实际就是替换为迭代器
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main(){
int arr\[\]={1,2,3,4,5};
//C++98
for(int i=0;i<sizeof(arr)/sizeof(arr0);i++){
arri++;
cout<<arri<<" ";
}
cout<<endl;
//C++11
for(auto &e:arr){//改变数组传引用
e++;
cout<<e<<" ";
}
cout<<endl;
string str("hello wordl");
for(auto c:str){
cout<<c<<" ";
}
cout<<endl;
return 0;
2.3sting类的常用接口说明
1.string类对象的常见构造
|--------------------------------------------------------------------------------------------|-----------------------|
| constructor函数名称 | 功能说明 |
| string() | 构造空的string类对象,即空字符串 |
| string(const char*s) | 用C-string来构造string类对象 |
| string(size_t n,char c) | string类对象中包含n个字符c |
| string(const string& s) | 拷贝构造函数 |
void Test(){
string s1; //构造空的string类对象s1
string s2("hello world"); //用c格式字符串构造string类对象s2
string s3(s2); //拷贝构造
}
2.string类对象的容量操作
|-------------------------------------------------------------------------------------|------------------------------|
| 函数名称 | 功能说明 |
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty(重点) | 检测字符串释放为空串,是返回true,否则返回false |
| clear(重点) | 清空有效字符 |
| reserve(重点) | 为字符串预留空间 |
| resize(重点) | 将有效字符的个数改成n个,多出的空间用字符c填充 |
注:
●size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其它容器的接口保持一致,一般情况下基本都是用size()
●clear()只是将string中有效字符清空,不改变底层空间大小
●resize(size_t n)与resize(size_t n,char c)都是将字符串中有效空间中有效个数改变到n个,不同的是当字符个数增多时,resize(size_t n)用0来填充多出的空间,resize(size_t n,char c)用字符c来填充多出的元素空间。注意:resize是将元素个数减少,底层空间总大小不变
●reseve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserve不会改变容量大小
3.string类对象的访问及遍历操作
|---------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------|
| 函数名称 | 功能说明 |
| operator\[\](重点) | 返回pos位置的字符,const string类对象调用 |
| begin+end | begin获取第一个字符的迭代器+end获取最后一个字符下一个位置的迭代器 |
| rbegin+rend | rbegin获取最后一个字符的迭代器+rend获取第一个字符上一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for的新遍历方式 |
4.string类对象的修改操作
|-----------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------|
| 函数名称 | 功能说明 |
| push_back | 在字符串后尾插字符c |
| append | 在字符串后追加一个字符串 |
| operator+=(重点) | 在字符串后追加字符串str |
| c_str(重点) | 返回C格式字符串 |
| find+npos(重点) | 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置 |
| rfind | 从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
注:
●在string尾部追加字符时,s.push_back(c)/s.append(1,c)/s+='c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串
●对string操作时,若能大概预估放多少字符,可以先通过reserve把空间预留好
5.string类非成员函数
|---------------------------------------------------------------------------------------------------------------|-----------------------|
| 函数名称 | 功能说明 |
| operator+ | 尽可能少用,因为传值返回,导致深拷贝效率低 |
| operator>>(重点) | 输入运算符重载 |
| operator<<(重点) | 输出运算符重载 |
| getline(重点) | 获取一行字符串 |
| relational operator(重点) | 大小比较 |
6.vs和g++下string结构的说明
注:下述结构是32位平台下进行验证,32位平台下指针占4个字节
●vs下string的结构
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义string中字符串的存储空间:
▢当字符串长度小于16时,使用内部固定的字符数组来存放
▢当字符串长度大于等于16时,从堆上开辟空间
union_Bxty{
//storage for small buffer or pointer to lager one
value_type_Buf_BUF_SIZE;
pointer _Ptr;
char _Alias_BUF_SIZE;//to permit aliasing
}_Bx;
这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量
最后还有一个指针做一些其它事情
故总共占16+4+4+4=28字节
●g++下string的结构
g++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包括了一个指针,该指针将来指向一块堆空间,内部包括了如下字段:
▢空间总大小
▢字符串有效长度
▢引用计数
struct Rep_base{
size_type _M_length;
size_type _M_capacity;
_Atomic_word _M_refcount;
};
▢指向堆空间的指针,用来存储字符串
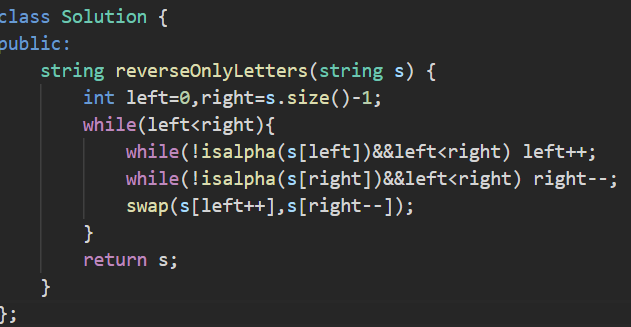
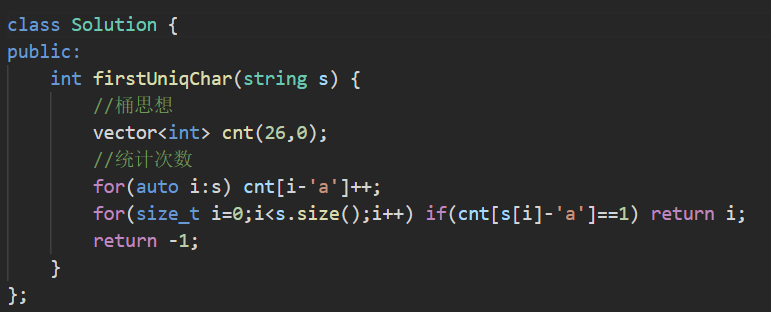
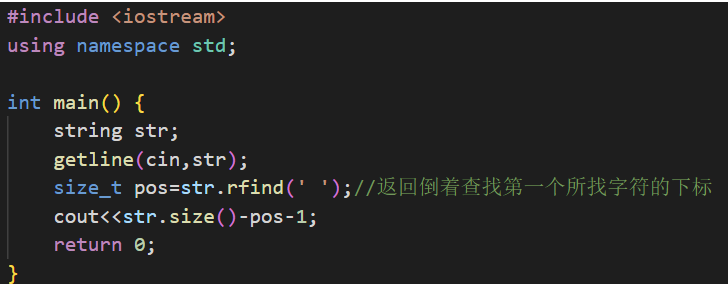
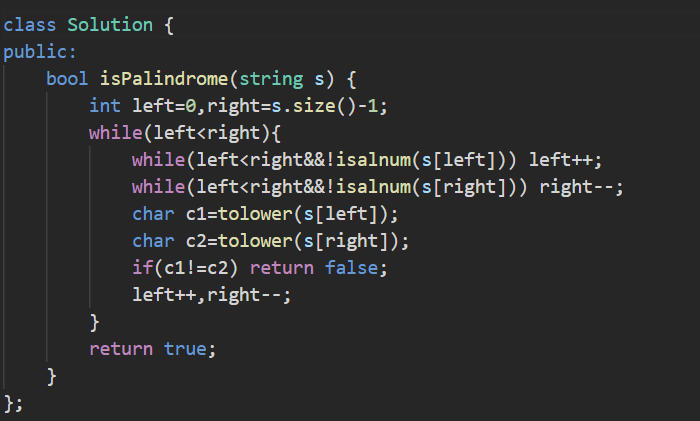
7.练习
3.string类的模拟实现
3.1经典的string类问题
在面试中,面试官总喜欢让学生自己来模拟实现string类,最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析构函数。以下string类的实现是否有问题?
//为和标准库区分,使用String
class String{
public:
/*String()
:str(new char1)
{*_str='\0';}*/
//String (const char *str="\0")错误示范,字符与字符串混用
//String (const char *str=nullptr)错误示范
String(const char *str=""){
//构造String类对象是,若传递nullptr指针,可以认为程序非
if(nullptr==str){
assert(false);
return ;
}
_str=new char strlen(str)+1;
strcpy(_str,str);
}
~String(){
if(_str){
delete \[\]_str;
_str=nullptr;
}
}
private:
char *_str;
};
void TestString(){
String s1("hello world");
String s2(s1);
}
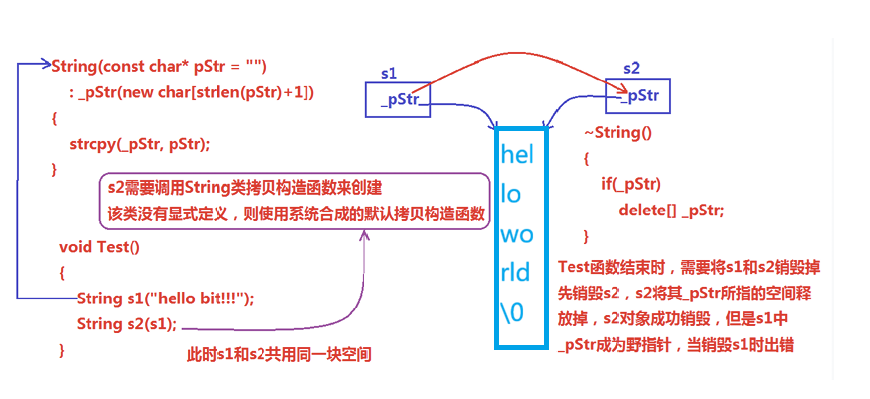
说明:上述String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器回合成默认的,当用s1构造s2式,编译器回调用默认的拷贝构造。最终导致s1、s2共用同一块内存空间,在释放时同一块空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
3.2浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来 。如果对象中管理资源 ,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续堆资源进行操作时,就会发生访问违规。
可以采用深拷贝解决浅拷贝问题,即:每个对象都有一份独立的资源,不要和其他对象共享。
3.3深拷贝
若一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。一般情况都是按照深拷贝方式提供。

3.3.1传统版写法的string类
class String{
public:
String(const char *str=""){
//构造String类对象是,若传递nullptr指针,可以认为程序非
if(nullptr==str){
assert(false);
return ;
}
_str=new char strlen(str)+1;
strcpy(_str,str);
}
String(const String &s)
:_str(new charstrlen(s._str)+1
{
strcpy(_str,s._str);
}
String &operator=(const String &s){
if(this!=&s){
char *pstr=new charstrlen(s._str)+1;
strcpy(pstr,s._str);
delete\[\] _str;
_str=pstr;
}
return *this;
}
~String(){
if(_str){
delete \[\]_str;
_str=nullptr;
}
}
private:
char *_str;
};
3.3.2现代版写法的String类
class String{
public:
String(const char *str=""){
//构造String类对象是,若传递nullptr指针,可以认为程序非
if(nullptr==str){
assert(false);
return ;
}
_str=new char strlen(str)+1;
strcpy(_str,str);
}
String(const String &s)
:_str(new charstrlen(s._str)+1
{
String str(s._str);
swap(_str,str._str);
}
String &operator=(String &s){
swap(_str,s._str);
return *this;
}
String &operator=(const String &s){
if(this!=&s){
String str(s);
swap(_str,str._str);
}
return *this;
}
~String(){
if(_str){
delete \[\]_str;
_str=nullptr;
}
}
private:
char *_str;
};
3.4写时拷贝(了解)
写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的。
引用计数:用来记录资源使用这的个数。在构造时,将资源的的计数给成1,每增加一个对象使用该资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源,若计数为1,说明该对象是资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有其他对象在使用该资源。