欢迎来到并行计算的真实世界。如果说传统的串行程序是一辆追求极致单步响应速度的跑车,那么我们即将学习的异构数据并行程序,就是一支能够同时处理海量任务的超级舰队。
本章是引导你从"串行思维"跨越到"并行思维"的破冰之旅。在这里,我们将彻底打破传统围绕 for 循环构建的编程习惯,带你从底层硬件架构出发,去理解 GPU 天生为"吞吐量"而生的设计哲学。
通过本章的学习,你将掌握以下核心内容:
-
架构认知: 深刻理解 CPU(低延迟导向)与 GPU(高吞吐量导向)在底层硅片设计和调度策略上的根本差异。
-
思维转换: 区分任务并行与数据并行,理解为何图像处理、科学模拟与矩阵运算是 GPU 的天然主场。
-
核心抽象: 掌握 CUDA 编程模型中"网格(Grid)-线程块(Block)-线程(Thread)"的三级组织架构,并熟练运用黄金公式计算全局唯一的线程索引。
-
代码实战: 掌握异构内存管理 API,从零开始编写并运行你的第一个真正的 GPU 并行程序------向量加法。
-
工程规范: 了解
nvcc编译管线,掌握应对 GPU 异步执行特性的标准错误检查(Error Checking)宏定义与调试机制。
引言:异构计算架构简介
在进入具体的并行代码编写之前,我们需要先建立一个核心概念:异构计算。
传统的计算机程序主要在中央处理器(CPU)上单线程或多线程运行,这是一种同构的计算模式。然而,随着深度学习、科学模拟和图像处理等应用对算力需求的呈指数级增长,仅仅依靠提升单核 CPU 的时钟频率早已触及物理极限(即"功耗墙")。异构计算由此成为主流,它指的是在一个系统中协同使用不同类型的处理器或计算单元(如 CPU、GPU、FPGA 或专用的 AI 加速器),遵循"让最合适的硬件做最合适的工作"的原则。
在现代异构数据并行计算模型(例如 CUDA 或 OpenCL)中,程序架构通常围绕两个基本实体展开:
-
主机(Host): 通常指 CPU 及其所在的系统主存(RAM)。它是整个程序的"指挥官",擅长处理复杂的控制逻辑、操作系统交互、网络 I/O 以及任务的调度。
-
设备(Device): 通常指 GPU(图形处理器)及其独立的显存(VRAM)或其他加速卡。它是程序的"主力计算军团",专门负责处理计算密集型、高度并行化的任务。
一个典型的异构计算程序的生命周期通常包含以下几个步骤:
-
主机在系统内存中初始化数据。
-
主机将数据通过 PCIe 总线拷贝到设备的显存中。
-
主机向设备发送指令,启动设备上的成千上万个独立线程进行并行计算。
-
计算完成后,主机将结果从设备显存拷贝回系统内存。
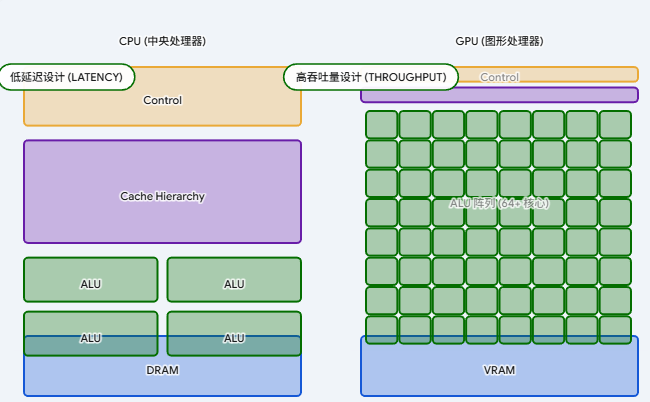
CPU 与 GPU 的设计哲学对比:延迟导向 vs. 吞吐量导向
要深刻理解为什么 GPU 在数据并行任务上拥有远超 CPU 的性能,我们需要剖析它们底层设计哲学的根本分歧。它们天生是为了解决完全不同类型的计算问题而诞生的。
-
CPU:致力于降低延迟(Latency-Oriented) CPU 被设计为尽可能快地完成单一的、复杂的指令流。现实中的通用程序充满了复杂的逻辑跳转(如海量的
if-else分支)和不可预测的数据内存访问。为了让串行代码跑得飞快,CPU 芯片内部的大部分晶体管并没有用于计算,而是被用来构建巨大的多级缓存(L1/L2/L3 Cache)以及极其复杂的控制逻辑部件(如分支预测器、乱序执行单元)。因此,CPU 只有少量的算术逻辑单元(ALU),但它的每个核心都极其强大,能够以极低的延迟响应复杂的串行任务。 -
GPU:致力于最大化吞吐量(Throughput-Oriented) GPU 的设计初衷是处理图形渲染------这要求对屏幕上数以百万计的独立像素进行极其相似的矩阵或向量数学运算。这是一种极其纯粹的"数据并行"任务。基于这一需求,GPU 的设计者无情地砍掉了复杂的控制逻辑和庞大的单线程缓存,将绝大部分宝贵的硅片面积投入到了计算核心(ALU)上。
一个现代 GPU 可能拥有数以千计甚至上万个简单的流处理器。当 GPU 中的某一组线程在读取显存遇到延迟时,GPU 的控制策略并非像 CPU 那样利用巨大的缓存去弥补,而是零开销地瞬间切换到另一组已经准备好数据的线程上继续执行计算。通过这种用海量线程来"隐藏"内存访问延迟的策略,GPU 实现了极为惊人的整体浮点运算吞吐量。
这种硬件架构的根本差异,决定了我们的编程范式必须发生巨大的转变:在编写 CPU 程序时,我们致力于优化单一线程的执行效率并减少内存延迟;而在编写 GPU 异构程序时,我们的首要任务是寻找并最大程度地暴露程序中的数据并行性,以提供足够庞大的线程规模,去喂饱那成千上万个嗷嗷待哺的计算核心。
第一章:数据并行性基础
当我们谈论"并行计算"时,我们通常指的是同时执行多个计算操作。然而,根据我们拆分工作的方式,并行计算主要可以划分为两大基本范式:任务并行 和 数据并行。理解这两者的区别,是编写高效异构程序的关键。
任务并行:
任务并行 是指将一个复杂的应用程序分解为多个不同的功能模块或任务,并将它们分配给不同的处理单元同时执行。
-
生活中的类比: 想象一个厨房在准备一场晚宴。主厨负责烤牛排,副手负责切沙拉,糕点师负责烤甜点,另一个人负责布置餐桌。每个人都在做完全不同的事情,使用不同的工具,但他们共同推进了"准备晚宴"这个大目标。
-
计算机中的体现: 现代多核 CPU 非常擅长任务并行。在一个现代视频游戏中,CPU 可能用一个核心处理物理引擎碰撞(Physics),另一个核心处理人工智能逻辑(AI),第三个核心负责网络通信(Network I/O),第四个核心负责音频解码(Audio)。这些任务逻辑复杂、分支众多且彼此差异巨大。
数据并行:
数据并行 则是指针对一个庞大的数据集,将相同的计算操作(或指令)同时应用于数据集合的不同部分。
-
生活中的类比: 想象有一万份单项选择题考卷需要批改。如果你有一百位老师,最快的方法不是让每个老师负责不同的改卷步骤,而是给每位老师分配一百份考卷,并且所有老师都拿着同一份标准答案(相同的指令),同时进行批改(不同的数据)。
-
计算机中的体现: 这正是 GPU 的统治领域。GPU 拥有成千上万个轻量级核心,它们被设计为在同一时刻,对内存中不同位置的数据执行一模一样的数学运算。这种模式被称为 SIMD(单指令多数据流,Single Instruction, Multiple Data) 或在 CUDA 架构中更准确地称为 SIMT(单指令多线程,Single Instruction, Multiple Threads)。
为什么图像处理和矩阵运算天然适合数据并行?
让我们看两个经典的例子,这也是我们后续编写代码时最常遇到的场景:
1. 图像处理(如彩色转灰度)
一张 4K 分辨率的图片包含超过 800 万个像素。要将这张彩色图片转换为黑白灰度图,我们需要对每一个像素的红(R)、绿(G)、蓝(B)通道执行相同的数学公式:
在这 800 万次计算中,像素 A 的计算结果绝对不会影响像素 B 的计算结果。它们是完全独立的。这就是完美的数据并行场景。如果在一个拥有 8000 个核心的 GPU 上运行,GPU 可以瞬间抓取 8000 个像素,在一个时钟周期或极短的时间内同时完成这 8000 次相同的公式计算。
2. 矩阵加法 ()
假设我们有两个 的大型矩阵
和
相加。我们需要执行一百万次独立的加法操作:计算
。同样,每一个元素的相加操作与其它元素完全无关,非常适合分配给成千上万个 GPU 线程去并发执行。
核心总结: 异构编程的本质,就是剥离程序中复杂的控制逻辑(交给 CPU 做任务并行),剥离出那些"数据量巨大、计算规则统一且相互独立"的循环体,将它们转化为成千上万个线程(交给 GPU 做数据并行)。
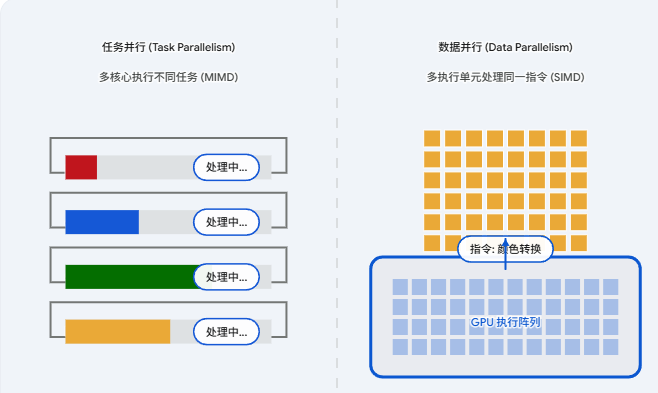
左边就是CPU的任务并行,右边就是GPU的数据并行。
第二章:CUDA 编程模型初探:网格与线程块
当我们说 GPU 可以同时运行数以万计的线程时,你可能会问:程序员该如何管理这上万个线程?如果这上万个线程都在执行同一段代码,它们怎么知道自己该去处理内存中的哪一部分数据?
为了解决这个问题,NVIDIA 的 CUDA 编程模型提出了一种高度结构化、可扩展的线程组织层次。这种层次结构不仅方便程序员管理,也完美契合了底层 GPU 硬件的物理架构。
1. 核函数(Kernel Function)
在 CUDA 中,我们在 CPU(主机)上调用,而在 GPU(设备)上执行的函数被称为核函数(Kernel) 。 在 C/C++ 代码中,我们通过在函数定义前加上 __global__ 限定符来声明它。当主机启动一个核函数时,GPU 会生成成千上万个线程来并发执行这段代码。
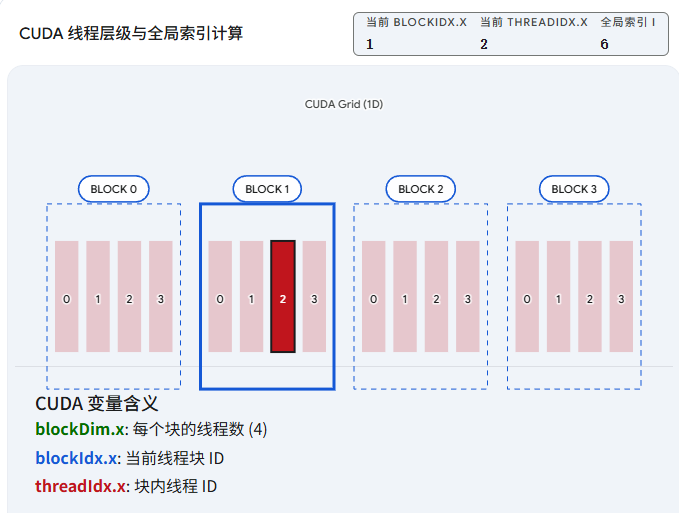
2. 三级线程层级结构:Grid -> Block -> Thread
为了组织这些海量的线程,CUDA 采用了"网格-线程块-线程"的三级结构:
-
线程(Thread): 最基本的执行单元。每个线程执行核函数的一个实例,拥有自己的指令地址寄存器和局部变量。
-
线程块(Block): 由一组并发执行的线程组成。这是一个极其重要的概念,因为同一个 Block 内的线程可以通过一块极速的"共享内存(Shared Memory)"进行数据交换,并且可以通过内置函数进行同步(Synchronization)。
-
网格(Grid): 由一组执行相同核函数的 Block 组成。一个核函数的启动对应一个 Grid。不同 Block 之间的线程通常是相互独立的,无法进行轻量级的同步。
通俗的比喻: 假设我们要建一栋摩天大楼(执行一个 Kernel/Grid)。我们将工程分包给多个施工队(Block)。每个施工队里有许多工人(Thread)。同一个施工队的工人可以轻松地互相递砖头、喊话协调(共享内存与同步);但不同施工队之间距离太远,各自独立干活,互不干扰。
3. 我是谁?我在哪?(内置坐标变量)
因为所有的线程都在执行同一段核函数代码(SPMD,单程序多数据),线程必须依靠自己独特的"坐标"来计算出自己应该读取哪里的数据。
CUDA 为每个线程提供了几个极其关键的内置变量(Built-in Variables),它们由硬件直接填充:
-
threadIdx:当前线程在其所属 Block 中的坐标索引。 -
blockIdx:当前线程所属的 Block 在整个 Grid 中的坐标索引。 -
blockDim:一个 Block 中包含的线程维度大小(例如一个 Block 里有多少个线程)。 -
gridDim:一个 Grid 中包含的 Block 维度大小。
注:这些变量都是内置的 dim3 向量类型,包含 .x, .y, .z 三个分量,这意味着你可以将线程组织成一维、二维或三维的结构,以完美适配向量、矩阵或空间体素的数据计算。
4. 黄金公式:计算全局唯一索引
对于最常见的一维数据处理(例如我们马上要在下一节写的向量加法),我们如何将两级坐标(Block 索引和 Thread 索引)展平,计算出该线程在所有线程中的全局唯一 ID 呢?
这就引出了并行编程中最著名的一维索引公式:
-
:计算出在当前 Block 之前,已经有多少个线程存在了。
-
-
最终得到的
Array[i])的全局索引。
第三章:第一个并行程序:向量加法
假设我们有两个包含 100 万个浮点数的一维数组(向量) 和
,我们需要将它们对应位置的元素相加,并将结果存储在数组
中。即:
。
如果是在传统的 CPU C++ 程序中,我们会写一个简单的 for 循环:
cpp
void vecAdd_CPU(float *A, float *B, float *C, int N) {
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
}但在 GPU 编程中,我们要彻底抛弃这种串行循环的思维。我们要让成千上万个线程同时 去执行加法操作。一个完整的 CUDA 程序分为两部分:设备代码(Device Code,即核函数)和主机代码(Host Code,负责统筹管理)。
1. 编写设备代码:核函数 (Kernel)
这是真正在 GPU 上成百上千个核心中并发执行的代码。我们用 __global__ 关键字来修饰它。
cpp
// CUDA 核函数:每个线程计算向量中的一个元素
__global__ void vecAdd_GPU(float *A, float *B, float *C, int N) {
// 黄金公式:计算当前线程的全局唯一索引 i
int i = blockDim.x * blockIdx.x + threadIdx.x;
// 边界检查:防止线程索引超出数组实际长度
if (i < N) {
C[i] = A[i] + B[i]; // 剥离了 for 循环,每个线程只做一次加法!
}
}核心思想转变: 注意看,这里没有 for 循环 !因为循环被转化为空间上的并行了。每一个启动的线程,都会通过计算自己的索引 i,精确地找到自己负责的那个元素,完成一次加法后就退出。
2. 编写主机代码:统筹帷幄 (Host)
GPU 是个纯粹的运算机器,它自己不会去内存里抓数据。因此,我们需要 CPU(主机)来为它准备好一切。一个典型的 CUDA 主机代码包含四个标准步骤:
这套"分配显存 -> 拷贝进去 -> 执行计算 -> 拷贝出来 -> 释放显存"的流程,是几乎所有异构计算程序的不变基石。
cpp
#include <stdio.h>
int main() {
int N = 1000000; // 100万个元素
size_t size = N * sizeof(float);
// [主机端] 分配内存并初始化 A 和 B (代码略)
float *h_A = ...; float *h_B = ...; float *h_C = ...;
// ---------------------------------------------------------
// 步骤 1: [设备端] 在 GPU 显存中分配空间 (cudaMalloc)
// ---------------------------------------------------------
float *d_A, *d_B, *d_C;
cudaMalloc((void**)&d_A, size);
cudaMalloc((void**)&d_B, size);
cudaMalloc((void**)&d_C, size);
// ---------------------------------------------------------
// 步骤 2: 数据传输 -> 将数据从 CPU 拷贝到 GPU (cudaMemcpy)
// ---------------------------------------------------------
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// ---------------------------------------------------------
// 步骤 3: 启动核函数 -> 定义网格和线程块大小
// ---------------------------------------------------------
int threadsPerBlock = 256; // 每个 Block 包含 256 个线程
// 计算需要多少个 Block,向上取整确保覆盖所有元素
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// 核心语法 <<<Grid大小, Block大小>>>
vecAdd_GPU<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// ---------------------------------------------------------
// 步骤 4: 数据回传 -> 将计算结果从 GPU 拷贝回 CPU
// ---------------------------------------------------------
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// [设备端] 释放显存
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
return 0;
}第四章:程序的编译与错误检查
在传统的 C/C++ 开发中,我们习惯使用 GCC、Clang 或 MSVC 等编译器。但当我们编写了包含主机代码(CPU)和设备代码(GPU)的混合源文件(通常以 .cu 为扩展名)时,传统的编译器就"傻眼"了,因为它根本不认识 __global__ 或者 <<<...>>> 这些奇怪的语法。
这时候,我们就需要引入专门的异构编译工具链。
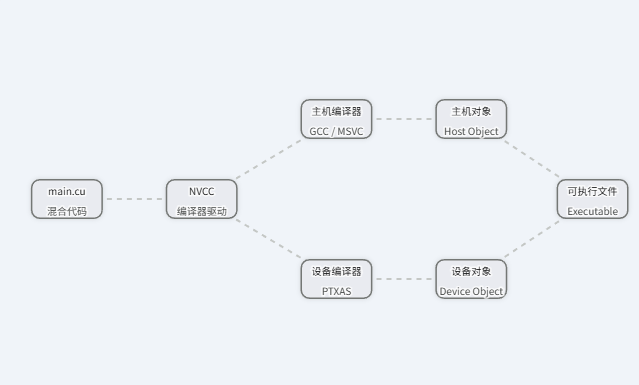
1. NVCC 编译器的工作原理
在 CUDA 生态中,标准编译器是 nvcc (NVIDIA CUDA Compiler) 。 准确地说,nvcc 更像是一个"编译器驱动程序(Driver)"。它的核心工作逻辑是代码分离(Separation):
-
分离:
nvcc首先解析.cu文件,将其中的主机代码(标准的 C/C++)和设备代码(CUDA 扩展部分)剥离开来。 -
分发主机代码: 将纯主机代码移交给系统自带的宿主编译器(比如 Linux 下的 GCC,Windows 下的 MSVC)进行编译。
-
编译设备代码: 调用 NVIDIA 自己的底层编译器组件,将设备代码编译为 PTX(一种中间汇编指令)或特定 GPU 架构的机器码(SASS)。
-
链接: 最后,将编译好的主机目标文件和设备目标文件链接在一起,生成最终的可执行文件。
2. 异步执行带来的"沉默地雷"
在异构计算中,有一个极易让初学者崩溃的特性:核函数的启动是完全异步的(Asynchronous)。
当你执行 vecAdd_GPU<<<grid, block>>>(...) 时,CPU 只是向 GPU 发送了一个"开始干活"的指令,然后 CPU 会瞬间返回,继续执行下一行代码,根本不会等待 GPU 把活干完。
这种设计是为了让 CPU 和 GPU 能够并行工作(重叠计算),最大化系统吞吐量。但这带来了一个致命问题:如果 GPU 在执行计算时崩溃了(比如数组越界访问),CPU 在调用核函数的那一瞬间是毫无察觉的。 程序不会在 <<<...>>> 这一行报错,而是可能在后续尝试拷贝数据回 CPU 时突然崩溃,或者直接静默失败,输出一堆乱码。
3. 编写标准的错误检查宏 (Error Checking Macro)
为了捕获这些"沉默的地雷",我们必须养成在每一个 CUDA API 调用和核函数执行后进行严格错误检查的习惯。
在工程实践中,我们通常会定义一个统一的宏(Macro)来包装这些调用。
cpp
#include <stdio.h>
// 宏定义:捕获并打印 CUDA 错误信息
#define CUDA_CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \
fprintf(stderr, "code: %d, reason: %s\n", error, \
cudaGetErrorString(error)); \
exit(1); \
} \
}
// 检查核函数异步执行的错误
#define CHECK_KERNEL_ERRORS() \
{ \
/* 捕获核函数启动时的同步错误(如无效的 block 参数)*/ \
CUDA_CHECK(cudaGetLastError()); \
/* 强制 CPU 等待 GPU 执行完毕,捕获执行过程中的异步错误(如越界)*/ \
CUDA_CHECK(cudaDeviceSynchronize()); \
}如何使用它? 我们将 2.4 节中的代码用这个宏包装起来,它就变成了符合工程标准的安全代码:
cpp
// 1. 包装内存分配和拷贝
CUDA_CHECK(cudaMalloc((void**)&d_A, size));
CUDA_CHECK(cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice));
// 2. 启动核函数(注意:核函数启动本身不能直接被宏包装)
vecAdd_GPU<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 3. 立即捕获核函数可能产生的错误
CHECK_KERNEL_ERRORS();
// 4. 包装数据回传
CUDA_CHECK(cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost));通过引入 cudaDeviceSynchronize(),我们强制 CPU 停下来等待 GPU 汇报工作结果。如果在计算过程中发生了内存越界,系统会精准地打印出错误发生的文件名、行号以及具体的错误原因(比如 an illegal memory access was encountered)
关于API的额外说明:
API 的全称是 Application Programming Interface(应用程序编程接口)。
在 CUDA 中的意义: NVIDIA 的工程师写好了底层与 GPU 硬件沟通的极其复杂的驱动代码,然后将其包装成了一个个简单的函数(如 cudaMalloc、cudaMemcpy)。这些函数就是 CUDA API。我们调用这些 API,就是在给 GPU 下达指令。
在 CUDA C/C++ 中,几乎所有的 CUDA API 调用(除了核函数 <<<...>>> 本身)都会返回一个状态码,用来告诉我们"后厨的菜做成功了没有"。
这个返回值的专门类型叫做 cudaError_t 。它本质上是一个枚举(enum)类型,如果一切顺利,它的值会是 cudaSuccess(也就是数字 0)。
做个全景示范:
cpp
#include <stdio.h>
#include <cuda_runtime.h>
int main() {
int V = 1000; // 假设我们要分配 1000 个整数
// 1. 计算需要的总字节数
// 整数个数 乘以 每个整数占用的字节数(通常是4字节)
size_t size = V * sizeof(int);
// 2. 声明设备端指针(这只是一张暂时空白的"房卡")
int *d_array;
// 3. 声明用于接收 API 状态的 ERR 变量
cudaError_t ERR;
// 4. 调用 API 分配内存,并接收返回值
// 注意:一定要传入指针的地址 &d_array,并强制转换为 (void**)
ERR = cudaMalloc((void**)&d_array, size);
// 5. 检查 API 是否执行成功
if (ERR != cudaSuccess) {
// 如果失败,打印出具体的错误原因
printf("GPU内存分配失败!原因: %s\n", cudaGetErrorString(ERR));
return -1; // 退出程序
} else {
printf("成功在 GPU 上分配了 %d 个整数的内存!\n", V);
}
// ... 后续计算 ...
// 释放内存
cudaFree(d_array);
return 0;
}概率习题:
习题 1:基础线程到数据的映射
题目: 如果我们要让网格(Grid)中的每个线程计算向量加法的一个输出元素,将线程/块索引映射到数据索引 i 的 C 语言表达式是什么?
习题 2:步长与多元素处理(进阶映射)
题目: 假设我们要修改程序,让每个线程计算向量加法中的两个相邻 元素。将线程/块索引映射到该线程处理的第一个 数据元素索引 i 的表达式是什么?
习题 3:网格与线程边界计算
题目: 对于向量加法,假设向量的长度为 8000,且每个线程计算一个输出元素。如果你设定线程块大小(Block Size)为 1024 个线程,那么整个网格(Grid)中总共会被启动多少个线程?
习题 4:CUDA 内存分配的 C 语言陷阱
题目: 假设我们有一个指向浮点数的指针 float *A_d;。以下哪一行代码是正确地在设备(GPU)上分配内存的语法?
A. cudaMalloc((void*)&A_d, size);
B. cudaMalloc(A_d, size);
C. cudaMalloc((void**)A_d, size);
D. cudaMalloc((void**)&A_d, size);
习题 5:数据传输方向
题目: 假设 A_h 是主机端(CPU)数组,A_d 是设备端(GPU)数组,两者都已经分配了 3000 字节的空间。现在需要将数据从 CPU 传输到 GPU,正确的 cudaMemcpy 语句应该怎么写?
解答:
1.答案: i = blockIdx.x * blockDim.x + threadIdx.x;
思路点拨: 这是贯穿整个 CUDA 编程的最核心公式。blockIdx.x * blockDim.x 计算的是在当前线程块(Block)之前,所有排在前面的线程块所包含的线程总数。加上当前线程在自己所属 Block 内部的偏移量 threadIdx.x,就能得到该线程在整个网格中的全局绝对位置。
2.答案: i = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
思路点拨: 既然每个线程要处理 2 个元素,这就意味着数据数组在逻辑上被按每 2 个元素分成了多个"组"。线程的全局唯一 ID 依然是 blockIdx.x * blockDim.x + threadIdx.x,这代表它是第几个"组"的负责人。为了找到它负责的这组数据的起始内存地址,只需将它的全局线程 ID 乘以 2 即可。
3.答案: 8192 个线程。
思路点拨: 这是一道极易踩坑的经典题。很多初学者会回答 8000。但硬件启动线程块时,只能启动完整的块 。 计算所需 Block 数量的公式是:向上取整(8000 / 1024) = 8 个 Block。 既然启动了 8 个完整的 Block,且每个 Block 有 1024 个线程,那么总启动线程数就是 8 * 1024 = 8192 个。这也是为什么我们在 2.4 节的核函数中必须要写 if (i < N) 这个边界检查的原因,因为会有 192 个多余的线程被启动,如果不加限制,它们就会导致内存越界访问!
4.答案: D
思路点拨: 这一题考察的是 C 语言指针的基础以及 API 的设计。cudaMalloc 函数的任务是去 GPU 上开辟一块空间,并且将这块空间的起始地址写入到你提供的指针变量中 。 因为函数内部要修改你传入的指针(A_d)的值,它就必须知道这个指针本身在内存中的地址,因此必须传入指针的地址 &A_d(这是一个二级指针)。同时,为了兼容各种数据类型,API 定义为 void**,所以需要进行强制类型转换。
5.答案: cudaMemcpy(A_d, A_h, 3000, cudaMemcpyHostToDevice);
思路点拨: 重点在于参数的顺序:(目标地址, 源地址, 字节数, 传输方向常量)。记住,它和 C 标准库里的 memcpy 是一脉相承的,永远是目标在前,源在后 (就像赋值语句 A_d = A_h 一样)。同时,必须显式地指定 cudaMemcpyHostToDevice,告诉系统底层的 DMA 控制器数据流向。
实战习题:
考虑以下 CUDA 核函数以及调用它的相应主机函数:
cpp
__global__ void foo_kernel(float* a, float* b, unsigned int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
b[i] = 2.7f * a[i] - 4.3f;
}
}
void foo(float* a_d, float* b_d) {
unsigned int N = 200000;
// 执行配置:<<<(N + 128 - 1)/128, 128>>>
foo_kernel<<<(N + 128 - 1) / 128, 128>>>(a_d, b_d, N);
}问题:
-
a. 每个线程块(Block)中有多少个线程?
-
b. 整个网格(Grid)中总共有多少个线程?
-
c. 整个网格中总共有多少个线程块?
-
d. 有多少个线程执行了计算
if条件语句(即判断i < N)的代码? -
e. 有多少个线程执行了
if语句内部的计算代码?
a. 每个线程块(Block)中有多少个线程?
-
答案: 128
-
解析: 核函数的执行配置语法是
<<<网格大小, 线程块大小>>>。在主机代码foo中,第二个参数显式指定了 128,这意味着每一个 Block 被硬编码为包含 128 个线程。
b. 整个网格(Grid)中总共有多少个线程?
-
答案: 200,064
-
解析: 网格中的总线程数 = 线程块总数 × 每个线程块的线程数。根据 c 题的计算,网格中启动了 1563 个线程块,因此总线程数为 1563 × 128 = 200,064 个线程。
c. 整个网格中总共有多少个线程块?
-
答案: 1,563
-
解析: 线程块的数量由公式
(N + 128 - 1) / 128决定。这是一种在 C 语言整数除法中实现"向上取整"的经典编程技巧。 代入 N = 200000 进行计算:(200000 + 127) / 128 = 200127 / 128。 在 C/C++ 的整数除法中,小数部分会被直接截断舍弃,因此 200127 / 128 = 1563。这意味着 GPU 实际启动了 1563 个完整的线程块。
d. 有多少个线程执行了 if 条件判断的代码?
-
答案: 200,064
-
解析: 这是一个极易踩坑的核心概念!硬件在分配和启动线程时,只能以完整的 Block 为最小单位进行分配 。既然系统最终启动了 1563 个 Block,那么包含在其中的全部 200,064 个线程都会被真实地分配到流处理器上并开始运行。因此,所有 被启动的线程都会首先计算出自己的全局索引
i,并执行if (i < N)这行条件评估代码。
e. 有多少个线程执行了 if 语句内部的计算代码?
-
答案: 200,000
-
解析: 只有满足条件(即全局索引
i的范围在 0 到 199,999 之间)的真实有效线程,才会进入if代码块内部执行实际的内存读写和浮点数运算。超出这个范围的 64 个多余线程(200,064 - 200,000)在条件判断为假后,直接越过了计算代码并结束生命周期。这就是我们在核函数中必须编写边界保护代码的根本原因。