目的
为避免一学就会、一用就废,这里做下笔记
模型文件夹说明
以魔塔社区中Qwen2.5-VL-7B-Instruct-bnb-4bit为例,模型文件清单如下:
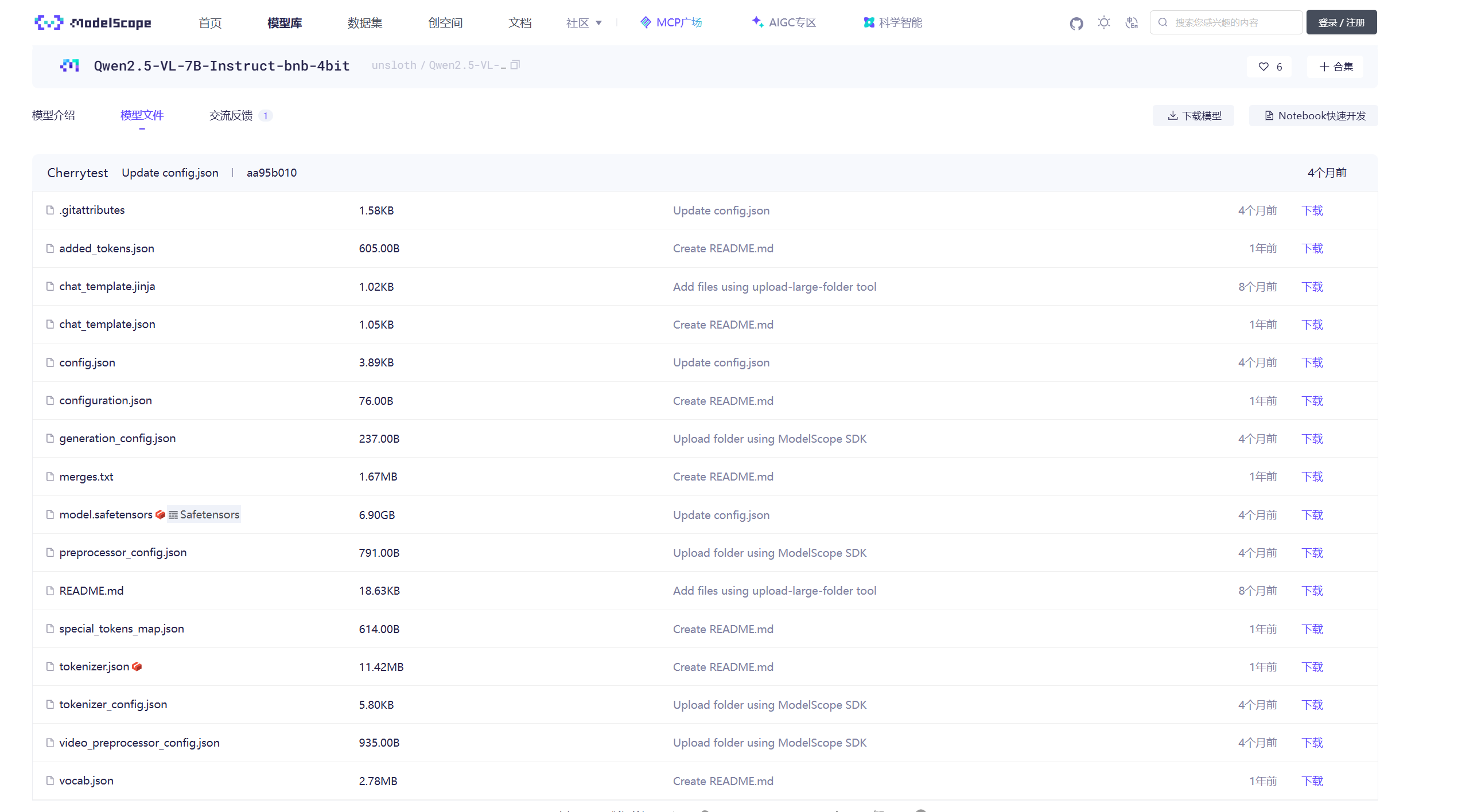
模型文件名称
模型名称 Qwen2.5-VL-7B-Instruct-bnb-4bit 本身包含技术信息如下:
| 名称部分 | 代表含义 | 说明 |
|---|---|---|
| Qwen2.5 | 基础模型系列与版本 | 这是阿里通义千问模型家族的第2.5代版本。 |
| VL | 模型能力 | 代表 V ision-L anguage,即视觉-语言多模态模型。表明该模型不仅能处理文本,还能理解和生成关于图像的内容。 |
| 7B | 模型参数量 | 代表 7 B illion,即70亿参数。这决定了模型的规模、能力和所需的计算资源。 |
| Instruct | 模型格式与训练方式 | 代表该模型是经过指令微调的版本,针对用户问答、遵循指令的对话场景进行了优化,可以直接用于对话交互。 |
| bnb-4bit | 量化方法与精度 | 这是最关键的后缀,表明该模型使用了 B itsa ndB ytes 库进行的 4位量化 。这能大幅降低模型对显存的需求(约原大小的1/4),使其能在消费级GPU上运行,但可能会带来轻微的精度损失。 |
重要模型与配置文件
⭐model.safetensors (6.90GB)
核心模型权重文件 。这是最重要的文件,包含了模型经过4位量化(bnb-4bit)后的所有权重参数。Safetensors 是一种新的、更安全(不直接执行代码)且加载速度更快的文件格式,替代了传统的 pytorch_model.bin。
⭐config.json
模型结构配置文件。它定义了模型的"骨架",例如网络的层数、注意力头数、隐藏层维度等所有超参数。加载模型时必须使用此文件来重建模型结构。
⭐generation_config.json
文本生成策略配置文件 。它控制模型在对话或生成文本时的行为,例如是否使用"采样"(do_sample)、温度值(temperature)、重复惩罚(repetition_penalty)等。这直接影响模型输出的"创造性"和"稳定性"。
关键分词与词汇文件
⭐tokenizer.json
分词器主文件 。现代分词器(如 tiktoken 或 sentencepiece)的核心文件,包含将文本拆分为模型能理解的词元(token)所需的所有规则和数据。对于Qwen系列模型尤为重要。
tokenizer_config.json
分词器行为配置文件。指定使用哪个分词器类、特殊标记(如句首、句尾标记)的定义等,是正确初始化分词器的指南。
vocab.json, merges.txt
分词器词汇表与合并规则文件 。这两个文件通常一起使用,是传统BPE分词器的核心。vocab.json 是词汇表,merges.txt 定义了如何将字符合并为子词。
特殊标记与模板文件
special_tokens_map.json
特殊标记映射文件 。将标记的功能名(如"pad_token")映射到其对应的具体字符串(如"<|endoftext|>")。确保代码能通过功能名找到正确的标记。
added_tokens.json
额外添加的标记。记录在基础词汇表之外,为特定任务(如指令微调)新添加的特殊标记。例如,多模态模型用于标识图像位置的标记。
chat_template.jinja 或 chat_template.json
对话格式模板 。定义了如何将用户的对话历史和指令,按照模型训练时所见的格式(例如 "<|im_start|>user\n...<|im_end|>")组织成字符串。这是确保模型遵循指令、正确回复的关键。
其他辅助文件
⭐preprocessor_config.json
预处理器配置文件 。对于多模态模型(VL) 至关重要。它定义了如何处理输入的图像(如调整尺寸、归一化),将其转换为模型视觉编码器所需的张量格式。
video_preprocessor_config.json
视频预处理器配置文件。作为VL模型的扩展,可能包含用于处理视频帧(视作多张图像)的额外配置。
README.md
模型说明文档。通常包含模型介绍、使用方法、训练数据、许可证等关键信息。
.gitattributes, configuration.json
次要工具文件 。.gitattributes 为Git版本控制配置。configuration.json 通常是内部配置文件,对普通用户影响不大。