在当今人工智能飞速发展的时代,生成式预训练Transformer(GPT)模型已经成为自然语言处理领域的里程碑式技术。GPT系列模型凭借其卓越的文本生成能力和强大的语言理解能力,在对话系统、内容创作、代码生成等多个领域展现出惊人的潜力。本文将通过一个完整的教学演示项目,深入剖析GPT模型的核心原理、关键技术实现以及实际应用方法,帮助读者全面掌握这一重要技术。
1. 环境准备与项目初始化
1.1. 核心依赖库介绍
本项目基于PyTorch深度学习框架和Hugging Face Transformers库构建。这些工具的选择并非偶然,它们代表了当前自然语言处理领域的最佳实践:
-
PyTorch 2.0+:提供动态计算图和强大的GPU加速支持,简化了模型开发和调试过程。
-
Transformers 4.30+:Hugging Face推出的预训练模型库,包含了GPT-2在内的众多先进模型。
-
Python 3.8+:确保代码的现代性和兼容性。
1.2. 设备配置策略
在深度学习项目中,合理利用硬件资源至关重要。我们的实现中包含了智能设备检测机制:
python
# 自动检测可用设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')这种策略确保了代码在不同环境下的可移植性。GPU的并行计算能力可以将训练速度提升10-100倍,特别是对于GPT-2这样的参数量达到1.5亿的大模型。
2. 预训练模型加载与配置
2.1. 分词器的重要性
分词器是自然语言处理模型的门户,它负责将人类可读的文本转换为模型可处理的数字表示。GPT-2使用的是字节对编码(Byte-Pair Encoding, BPE)算法:
python
self.tokenizer = AutoTokenizer.from_pretrained("gpt2")
self.tokenizer.pad_token = self.tokenizer.eos_token # 统一特殊标记BPE算法的优势在于它能够在字符级和词级之间取得平衡,有效处理未登录词问题。通过设置pad_token为eos_token,我们确保了生成过程的连贯性。
2.2. 模型架构解析
GPT-2采用纯解码器的Transformer架构,这一设计使其特别适合生成式任务:
python
self.gpt_model = GPT2LMHeadModel.from_pretrained("gpt2").to(self.device)
self.gpt_base = GPT2Model.from_pretrained("gpt2").to(self.device)我们同时加载了带有语言建模头的完整模型(GPT2LMHeadModel)和基础模型(GPT2Model),这种设计允许我们在不同场景下灵活使用模型的不同组件。GPT-2模型包含约1.5亿参数,分布在12个Transformer层中。
3. 核心功能实现详解
3.1. 分词过程可视化
理解分词过程对于掌握GPT模型至关重要。我们通过具体示例展示BPE分词的工作原理:
python
text = "Natural language processing is revolutionizing AI"
tokens = self.tokenizer.tokenize(text)
# 输出: ['Natural', 'Ġlanguage', 'Ġprocessing', 'Ġis', 'Ġrevolution', 'izing', 'ĠAI']值得注意的是,BPE分词会在某些token前添加特殊符号(如Ġ表示空格),这种设计保留了原始文本的结构信息。通过分析分词结果,我们可以理解模型是如何"看待"输入文本的。
3.2. 前向传播机制
前向传播是模型推理的核心过程。我们通过具体的代码实现展示GPT-2如何计算输出:
python
with torch.no_grad():
outputs = self.gpt_model(**inputs, labels=inputs['input_ids'])
print(f"输出logits形状: {outputs.logits.shape}")
# 典型输出: torch.Size([1, 序列长度, 词汇表大小])torch.no_grad()上下文管理器禁用梯度计算,这在推理阶段可以显著减少内存占用。GPT-2的输出logits代表了每个位置上词汇表中每个token的未归一化得分,通过softmax函数可以转换为概率分布。
4. 文本生成技术深度解析
4.1. 生成策略对比
GPT模型提供了多种文本生成策略,每种策略都有其适用场景:
- 贪婪解码
最简单的生成策略,每一步都选择概率最高的token。优点是确定性强,缺点是容易生成重复、单调的文本。
- 随机采样
从整个词汇表的概率分布中随机采样,创造性最强但可能生成不合理的内容。
- Top-k采样
限制只从概率最高的k个token中采样,平衡了创造性和合理性。经验上,k=50效果较好。
- Top-p(核)采样
动态调整候选token集合,只保留累积概率达到p的最小token集合。这种方法能够根据上下文自适应调整采样范围。
4.2. 温度参数的影响
温度参数控制着生成文本的随机性,是文本生成中最重要的超参数之一:
python
# 高温生成(temperature=1.2)
generated_outputs = self.gpt_model.generate(
inputs['input_ids'],
temperature=1.2, # 增加随机性
do_sample=True
)
# 低温生成(temperature=0.3)
conservative_outputs = self.gpt_model.generate(
inputs['input_ids'],
temperature=0.3, # 减少随机性
do_sample=True
)高温设置(>1.0)会使概率分布更平坦,增加生成多样性;低温设置(<1.0)会使概率分布更尖锐,生成更确定、保守的文本。实际应用中,通常设置在0.7-1.0之间。
5. 自回归语言建模原理
5.1. 自回归机制
GPT采用自回归(Autoregressive)生成方式,即每一步的生成都依赖于之前生成的所有token:
python
next_token_logits = outputs.logits[:, -1, :] # 获取最后一个位置的logits这种机制模拟了人类的语言生成过程:在给定前文的情况下,预测下一个最可能的词。自回归生成的优势在于生成的连贯性强,但缺点是推理速度较慢,因为必须串行生成每个token。
5.2. 概率分布分析
通过分析下一个token的概率分布,我们可以深入理解模型的"思考"过程:
python
top_tokens = torch.topk(next_token_logits, k=top_k, dim=-1)
for i in range(top_k):
token_id = top_tokens.indices[0, i].item()
token = self.tokenizer.decode(token_id)
prob = torch.softmax(next_token_logits, dim=-1)[0, token_id].item()
print(f"{token}: {prob:.4f}")这种分析不仅有助于调试模型,还能让我们了解模型在特定语境下的知识局限性和偏好。
6. 模型微调实战
6.1. 微调策略设计
微调是将预训练模型适应到特定任务的关键步骤。我们的实现展示了故事续写任务的微调过程:
python
optimizer = AdamW(self.gpt_model.parameters(), lr=5e-5)我们选择了AdamW优化器,它是Adam优化器的改进版本,加入了权重衰减正则化。学习率设置为5e-5,这是一个经过实践验证的适合GPT-2微调的初始学习率。
6.2. 损失函数与训练循环
自回归语言建模任务使用交叉熵损失函数,目标是最小化预测分布与真实分布之间的差异:
python
outputs = self.gpt_model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()训练过程中,我们监控每个epoch的平均损失值,这有助于判断模型是否在有效学习。通常,微调2-3个epoch就能在特定任务上看到明显改进。
6.3. 微调效果评估
微调后,模型在特定领域(如故事续写)的表现会显著提升:
python
test_prompt = "In a distant galaxy,"
generated_story = self.tokenizer.decode(test_outputs[0], skip_special_tokens=True)通过对比微调前后的生成结果,我们可以直观评估微调的效果。有效的微调应该使生成的文本更符合目标领域的风格和内容要求。
7. GPT技术演进与对比分析
7.1. GPT技术演进历程
GPT系列的发展历程体现了自然语言处理领域的技术进步:

这一演进趋势显示出几个关键方向:模型规模指数级增长、训练数据多样化、从单模态到多模态扩展、以及更强的推理和泛化能力。
7.2. GPT与BERT对比分析
GPT和BERT代表了Transformer架构的两种主要应用范式:
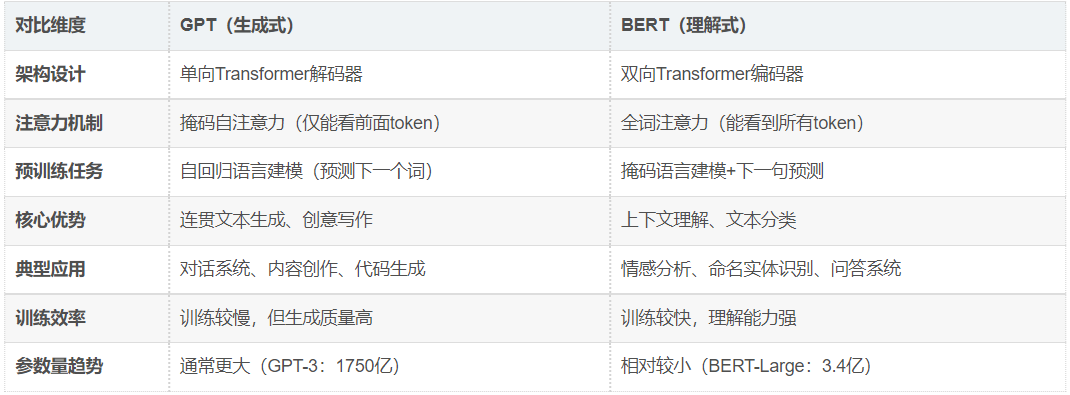
选择GPT还是BERT取决于具体任务需求:需要生成新内容时选择GPT,需要理解或分析现有内容时选择BERT。
8. 文本生成策略最佳实践
8.1. 策略选择指南
根据不同的应用场景,选择合适的生成策略至关重要:
-
创意写作:使用Top-p采样(p=0.9)结合中等温度(0.8)
-
技术文档:使用Top-k采样(k=40)结合较低温度(0.5)
-
对话系统:使用束搜索(beam_search)结合长度惩罚
-
代码生成:使用贪婪解码或低温度采样确保准确性
8.2. 参数调优经验
基于实践经验,我们总结了一些参数调优的指导原则:
-
温度:0.5-1.0之间调整,太高会导致不连贯,太低会缺乏创造性
-
Top-k:一般设置在20-50之间,平衡多样性和质量
-
Top-p:0.85-0.95之间效果较好,适应性强于固定k值
-
重复惩罚:设置
no_repeat_ngram_size=2可以有效减少重复
9. 性能优化与部署建议
9.1. 推理优化技术
在实际部署中,GPT模型的推理效率是需要重点考虑的问题:
-
量化压缩:将模型权重从FP32转换为INT8,减少75%内存占用
-
知识蒸馏:训练小型学生模型模仿大型教师模型
-
缓存机制:缓存已计算的注意力结果,避免重复计算
-
批处理优化:合理设置批处理大小,充分利用GPU并行能力
9.2. 部署架构设计
生产环境中的GPT部署需要考虑多个方面:
python
# 示例:生产环境配置
production_config = {
"max_length": 512, # 限制生成长度
"temperature": 0.7, # 平衡创造性和一致性
"top_p": 0.9, # 使用核采样
"repetition_penalty": 1.2, # 减少重复
"do_sample": True, # 启用采样
"num_return_sequences": 1 # 返回序列数
}10. 未来展望与研究方向
10.1. 技术发展趋势
GPT技术的未来发展可能沿着以下几个方向:
-
多模态融合:结合视觉、语音等多模态信息
-
推理能力增强:改进逻辑推理和数学计算能力
-
效率提升:降低计算和存储需求,使模型更易部署
-
可控性改进:增强生成内容的可控性和安全性
-
个性化适应:根据用户偏好调整生成风格
10.2. 伦理与社会影响
随着GPT能力的增强,伦理和社会影响问题日益重要:
-
偏见缓解:减少训练数据中的社会偏见
-
事实核查:提高生成内容的真实性和准确性
-
透明度和可解释性:让用户理解模型的决策过程
-
责任归属:明确AI生成内容的责任归属
11. 完整源代码
python
# 导入torch库,用于张量操作和自动求导
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel, GPT2Model
# 从torch.optim导入AdamW类,用于优化模型参数
from torch.optim import AdamW
import warnings
warnings.filterwarnings("ignore")
# 设置输出中文字符的显示
import sys
sys.stdout.reconfigure(encoding='utf-8')
class GPTTeachingDemo:
# 初始化GPT演法类
def __init__(self):
print("\n====初始化GPT演法类====")
# 检查是否有可用的GPU,若有则使用GPU,否则使用CPU
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"\n当前设备: {self.device}")
# 1.加载预训练GPT模型
def load_gpt_model(self):
print("\n====加载预训练GPT模型====")
try:
# 加载tokenizer
self.tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 设置pad_token, 确保pad_token_id 与 eos_token_id 相同
self.tokenizer.pad_token = self.tokenizer.eos_token
# 加载GPT模型
self.gpt_model = GPT2LMHeadModel.from_pretrained("gpt2").to(self.device)
self.gpt_base = GPT2Model.from_pretrained("gpt2").to(self.device)
print("\n成功加载GPT模型")
print(f"\n模型参数数量: {sum(p.numel() for p in self.gpt_model.parameters())}")
return True
except Exception as e:
print(f"\n模型加载失败: {str(e)}")
print("\n请检查网络连接或下载模型文件到本地")
print("\n离线模式: 设置环境变量 HF_HUB_OFFLINE=1")
print("\n或手动下载模型到: ~/.cache/huggingface/hub/")
return False
# 2.演示分词功能
def demo_gpt_tokenization(self):
print("\n====演示GPT分词功能====")
# 演示文本
text = "Natural language processing is revolutionizing AI"
# 对文本进行分词
tokens = self.tokenizer.tokenize(text)
print(f"\n原始文本: {text}")
print(f"\n分词结果: {tokens}")
# 转换为ID, 并添加特殊token
input_ids = self.tokenizer.encode(text, add_special_tokens=True)
print(f"\nID结果: {input_ids}")
print(f"\n特殊token: [EOS]={self.tokenizer.eos_token_id}")
# 3.演示前向传播
def demo_gpt_forward(self):
print("\n====演示GPT前向传播====")
# 演示文本
text = "The future of AI is"
# 对文本进行编码, 并添加特殊token
inputs = self.tokenizer(text, return_tensors='pt').to(self.device)
# 禁用梯度计算, 节省内存
with torch.no_grad():
# 前向传播, 获取模型输出
outputs = self.gpt_model(**inputs, labels = inputs['input_ids'])
print(f"\n输入文本:{text}")
print(f"\n输出logits形状: {outputs.logits.shape}")
print(f"\n损失值:{outputs.loss:.4f}")
# 4.演示生成文本
def demo_text_generation(self):
print("\n====演示GPT文本生成====")
# 基础文本生成
prompt = "The benefits of artificial intelligence include"
print(f"\n提示文本: {prompt}")
# 对提示文本进行编码, 并添加特殊token
inputs = self.tokenizer(prompt, return_tensors='pt').to(self.device)
# 禁用梯度计算, 节省内存
with torch.no_grad():
# 生成文本, 最大长度为50
generated_outputs = self.gpt_model.generate(
inputs['input_ids'], # 输入文本的ID张量
max_length=50, # 生成文本的最大长度
num_return_sequences=1, # 返回的文本序列数量
no_repeat_ngram_size=2, # 防止生成重复的N-gram
temperature=0.7, # 控制生成文本的随机性, 较高值会使生成更随机
do_sample=True, # 是否使用采样策略, 而不是贪婪解码
top_k=50, # 仅从top_k个token中采样
top_p=0.9, # 仅从top_p概率质量中采样
pad_token_id=self.tokenizer.eos_token_id # 填充token ID, 用于结束生成
)
# 解码生成的文本
generated_text = self.tokenizer.decode(generated_outputs[0], skip_special_tokens=True)
print(f"\n生成文本: {generated_text}")
print()
# 演示不同参数的效果
print("===不同生成参数对比===")
# 高创造性生成 (高温度)
creative_outputs = self.gpt_model.generate(
inputs['input_ids'],
max_length=30,
temperature=1.2,
do_sample=True,
top_k=50,
pad_token_id=self.tokenizer.eos_token_id
)
creative_text = self.tokenizer.decode(creative_outputs[0], skip_special_tokens=True)
print(f"\n较高温度生成: {creative_text}")
# 保守生成 (低温度)
conservative_outputs = self.gpt_model.generate(
inputs['input_ids'],
max_length=30,
temperature=0.3,
do_sample=True,
top_k=50,
pad_token_id=self.tokenizer.eos_token_id
)
conservative_text = self.tokenizer.decode(conservative_outputs[0], skip_special_tokens=True)
print(f"\n较低温度生成: {conservative_text}")
# 5.演示自回归语言建模
def demo_gpt_autoregressive(self):
print("\n====演示GPT自回归语言建模====")
text = "The weather today is"
print(f"\n输入序列: {text}")
inputs = self.tokenizer(text, return_tensors='pt').to(self.device)
# 禁用梯度计算, 节省内存
with torch.no_grad():
# 前向传播, 获取模型输出
outputs = self.gpt_model(**inputs)
# 提取最后一个token的logits
next_token_logits = outputs.logits[:, -1, :]
# 获取top_k个概率最高的token
top_k = 5
top_tokens = torch.topk(next_token_logits, k=top_k, dim=-1)
print("\n预测下一个Token(Top 5):")
for i in range(top_k):
# 获取token ID
token_id = top_tokens.indices[0, i].item()
# 解码token ID为文本
token = self.tokenizer.decode(token_id)
# 计算token的概率
prob = torch.softmax(next_token_logits, dim=-1)[0, token_id].item()
# 打印token和概率
print(f"{token}: {prob:.4f}")
# 6.创建文本生成数据集
def create_generation_dataset(self):
# 模拟故事续写数据集
prompts = [
"Once upon a time, in a magical forest,",
"The scientist discovered a new element that",
"In the year 2050, artificial intelligence",
"The young adventurer found an ancient map leading to"
]
return prompts
# 7.GPT微调实战:故事续写
def fine_tune_gpt_generator(self):
# 准备数据
prompts = self.create_generation_dataset()
# 训练参数
optimizer = AdamW(self.gpt_model.parameters(), lr=5e-5)
num_epochs = 2
print("\n开始微调")
for epoch in range(num_epochs):
total_loss = 0
for prompt in prompts:
# 编码输入
inputs = self.tokenizer(prompt, return_tensors='pt', padding = True, truncation=True).to(self.device)
# 创建标签(自回归任务)
labels = inputs['input_ids'].clone()
# 前向传播
outputs = self.gpt_model(**inputs, labels=labels)
# 提取损失
loss = outputs.loss
# 反向传播
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 累加损失
total_loss += loss.item()
# 计算平均损失
avg_loss = total_loss / len(prompts)
print(f"Epoch {epoch+1}/{num_epochs}, Average Loss: {avg_loss:.4f}")
print("\n微调完成")
# 测试微调效果
test_prompt = "In a distant galaxy,"
# 对测试提示进行编码, 并添加特殊Token
test_inputs = self.tokenizer(test_prompt, return_tensors='pt').to(self.device)
# 禁用梯度计算, 节省内存
with torch.no_grad():
# 生成文本
test_outputs = self.gpt_model.generate(
test_inputs['input_ids'], # 输入文本的ID张量
max_length=40, # 生成文本的最大长度
temperature=0.8, # 控制生成文本的随机性, 较高值会使生成更随机
do_sample=True, # 是否使用采样策略, 而不是贪婪解码
pad_token_id=self.tokenizer.eos_token_id # 填充token ID, 用于结束生成
)
generated_story = self.tokenizer.decode(test_outputs[0], skip_special_tokens=True)
print(f"\n微调后生成故事: \n{generated_story}")
# 8. GPT技术演进演示
def demo_gpt_evolution(self):
evolution = {
"GPT-1": {
"参数量": "1.17亿",
"特点": "首次大规模预训练",
"性能": "基础语言建模"
},
"GPT-2": {
"参数量": "15亿",
"特点": "零样本学习能力",
"性能": "多任务适应性强"
},
"GPT-3": {
"参数量": "1750亿",
"特点": "少样本和零样本学习",
"性能": "接近人类水平"
},
"GPT-4": {
"参数量": "未知",
"特点": "多模态能力",
"性能": "更强的推理能力"
}
}
print("GPT技术演进对比:")
for version, info in evolution.items():
print(f"\n{version}:")
for key, value in info.items():
print(f"{key}:{value}")
# 9.GPT与BERT对比分析
def compare_gpt_vs_bert(self):
comparison = {
"架构设计": {
"GPT": "单向Transformer解码器(自回归)",
"BERT": "双向Transformer编码器(自编码)"
},
"注意力机制": {
"GPT": "掩码自注意力(因果掩码)",
"BERT": "全词注意力(无掩码)"
},
"预训练任务": {
"GPT": "自回归语言建模(预测下一词)",
"BERT": "掩码语言建模(MLM)+下一句预测(NSP)"
},
"核心优势": {
"GPT": "文本生成、创意写作、对话系统",
"BERT": "文本理解、分类、问答系统"
},
"应用场景": {
"GPT": "内容创作(采纳率72%)、代码生成",
"BERT": "文本分类(准确率94.9%)、NER(F1值96.6%)"
},
"参数规模": {
"GPT": "GPT-3达1750亿参数",
"BERT": "Base版1.1亿参数"
}
}
print("GPT与BERT核心对比:")
for aspect, models in comparison.items():
print(f"\n{aspect}:")
print(f"GPT: {models['GPT']}")
print(f"BERT: {models['BERT']}")
# 10.文本生成策略演示
def demo_generation_strategies(self):
print("\n====文本生成策略演示====")
prompt = "Machine learning is"
strategies = {
"贪婪解码": {"do_sample": False, "temperature": 1.0},
"随机采样": {"do_sample": True, "temperature": 1.0, "top_k": 50},
"Top-p采样": {"do_sample": True, "temperature": 0.8, "top_p": 0.9},
"Top-k采样": {"do_sample": True, "temperature": 0.8, "top_k": 40}
}
# 对提示进行编码, 并添加特殊Token
inputs = self.tokenizer(prompt, return_tensors='pt').to(self.device)
print(f"提示:{prompt}")
print("\n不同生成策略结果:")
# 对每个生成策略进行演示
for strategy_name, params in strategies.items():
# 禁用梯度计算, 节省内存
with torch.no_grad():
# 生成文本
outputs = self.gpt_model.generate(
inputs['input_ids'],
max_length=20,
pad_token_id=self.tokenizer.eos_token_id,
**params,
)
# 解码生成的文本, 移除特殊Token
generated = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\n{strategy_name}: {generated[len(prompt):].strip()}")
# 11. 运行所有演示
def run_all_demos(self):
# 先加载模型
if not self.load_gpt_model():
print("模型加载失败,无法运行演示")
return
self.demo_gpt_tokenization() # 1. 演示GPT分词
self.demo_gpt_forward() # 2. 演示GPT前向传播
self.demo_text_generation() # 3. 演示文本生成
self.demo_gpt_autoregressive() # 4. 演示GPT自回归生成
self.create_generation_dataset() # 5. 创建生成数据集
self.fine_tune_gpt_generator() # 6. 微调GPT生成器
self.demo_gpt_evolution() # 7. GPT技术演进演示
self.compare_gpt_vs_bert() # 8. GPT与BERT对比分析
self.demo_generation_strategies() # 9. 文本生成策略演示
# 主程序
if __name__ == "__main__":
demo = GPTTeachingDemo()
demo.run_all_demos()12. 结语
GPT模型代表了当前自然语言生成技术的最高水平,通过本文的教学演示,我们从基础原理到实践应用,全面探索了这一技术的各个方面。从模型加载到文本生成,从基础使用到高级微调,我们提供了完整的实践指南。
随着技术的不断进步,GPT及其后续模型将在更多领域发挥重要作用。掌握这些技术不仅有助于理解当前AI的发展现状,也为未来的技术创新奠定了基础。我们鼓励读者基于本文的示例代码进一步探索,开发出满足特定需求的GPT应用。