任务背景
大型语言模型虽然取得了显著进展,但其固定的上下文窗口限制了其在长文本和复杂任务中的应用。即使是在其窗口范围内,仍存在"上下文衰退"现象,即模型对早期输入信息的理解和记忆逐渐减弱。这一问题在需要长期规划、多步骤推理或复杂交互的智能体任务中尤为突出。在智能体系统中,模型需要在长时间跨度内保持目标一致性、避免任务漂移和循环失败。下文压缩技术通过摘要生成、选择性遗忘、滑动窗口等手段减少输入长度,但往往丢失细节信息或导致语义断裂。任务分解则将复杂任务拆分为多个子任务,分别处理后再进行整合,但在缺乏全局协调机制时容易导致目标偏移或上下文不一致。这些方法虽能在一定程度上扩展模型的处理范围,却难以在长序列中保持语义的连贯性与任务的整体性。
方法概述
递归语言模型(Recursive Language Model) 是一种允许语言模型在超出其固定上下文窗口的情况下仍能持续处理输入的架构。其核心思想是通过递归调用机制,使模型能够将复杂任务分解为子任务,并在执行过程中动态引入新的上下文信息。这种机制不仅增强了模型在长序列任务中的灵活性与适应性,还能通过层级化的推理结构保持上下文的连续性与一致性。递归调用可以是对模型自身的调用,也可以是对子模型或外部工具的调用,每次调用都会返回执行结果作为后续推理的依据。这种设计使得模型能够在长程规划、多步推理与动态调整中表现出更强的鲁棒性与智能性。
具体来说,RecursiveLM 通过以下机制工作:
递归调用:模型可以调用自身(递归推理)、子模型或外部工具来执行子任务,并将返回结果作为新的上下文信息注入到后续的推理过程中。
任务分解与重组:模型在运行过程中动态地将总任务分解为可执行的子任务,并根据执行反馈动态调整后续步骤,实现"按需规划"。
上下文持久化与再注入:模型在递归过程中通过结构化方式(如摘要、关键信息保留、层次化上下文管理)保持跨层级、跨时间步的语义一致性与任务目标一致性。
控制机制:通过控制器模块或启发式策略动态管理递归深度、调用频率与资源分配,避免无限递归或效率低下。
RecursiveLM 不仅是一种模型架构,更是一种系统级推理范式。它适用于多种场景,如长文本生成、复杂问题求解、多智能体协作、代码生成与理解、医学诊断辅助等需要长期依赖与结构化推理的任务。
论文介绍
ADAPT: As-Needed Decomposition and Planning with Language Models1
ADAPT的核心创新在于其 "按需" 的动态递归思想。它不再一次性制定完整计划,而是采用"先尝试,不行再分解"的务实策略。其工作流程像一个精明的管理者,分为三步,并引入两个LLM角色:执行者 和 规划者。
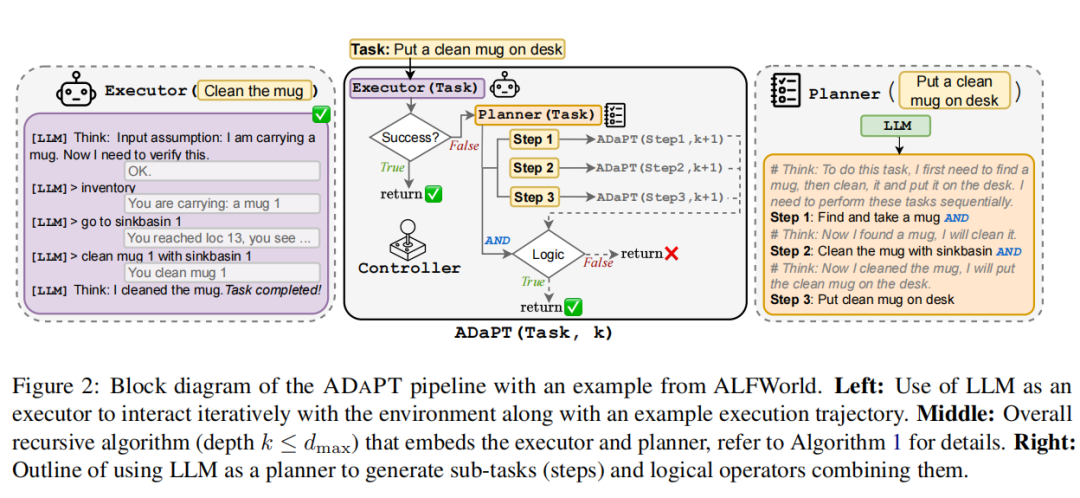
第一阶段:尝试执行。 面对一个总任务(如"把一个干净的杯子放到桌上"),ADAPT首先让"执行者"LLM直接尝试完成。这个执行者具备基础技能(如拿取、清洁、加热物品)。ADAPT让执行者LLM自己判断当前任务是否成功。如果输出"任务完成",则流程结束;如果输出"任务失败"或无法推进,则触发第二阶段。
第二阶段:递归分解与规划。 一旦执行者失败,规划者LLM登场。它的任务不是制定庞大计划,而是仅针对当前失败的这个(子)任务,生成一个简短(3-5步)的分解方案,并注明步骤间的逻辑关系("与"表示顺序执行,"或"表示尝试不同分支)。例如,"找杯子"可以分解为"在台面上找杯子" 或 "在橱柜里找杯子"。
第三阶段:递归执行与汇总。 生成的新子任务,会再次被送入ADAPT流程(即回到第一阶段),形成递归。每个子任务都会经历"尝试执行-失败则再分解"的循环,直到所有叶子任务都被执行者搞定,最终结果沿递归树向上汇总,完成总任务。
这种设计的精妙之处在于其动态适应性:它只在LLM"力所不及"的难点上进行分解,把计算资源精准聚焦于复杂子任务。同时,通过递归结构,它天然地构建了任务难度与分解深度的对齐------越复杂的子任务,会被分解得越细。ADAPT提供了一种构建稳健、自适应LLM智能体的清晰范式。它将"规划"从一项前置的、一次性的工作,转变为贯穿任务始终的、与"执行"深度交织的动态过程。这更接近人类解决问题的方式:先尝试直接解决,遇到困难时停下来拆解,对拆解后的子问题再次尝试。
这种方法的一大实用优势是成本可控:昂贵的"规划者"LLM仅在必要时被调用,大部分基础操作由相对便宜的"执行者"完成。论文甚至展示了可以用更强的LLM(如GPT-3.5)做规划,用较小的开源模型(如LLaMA-2)做执行,在降低成本的同时仍能大幅提升效果。
ReCAP: Recursive Context-Aware Reasoning and Planning for Large Language Model Agents2
RECAP针对现有LLM智能体在长视野任务中的另一类核心问题------上下文漂移与跨层级连续性断裂------提出了一个新颖的解决方案。ReCAP的核心创新在于其 "前瞻性全计划分解"与"结构化上下文再注入" 的双重机制。现有方法通常面临两难:像ReAct这样的序列化方法,在长轨迹中早期计划容易被后续信息覆盖,导致目标丢失;而像THREAD、ADaPT等分层方法,子任务在孤立上下文中执行,信息在不同层级间割裂。
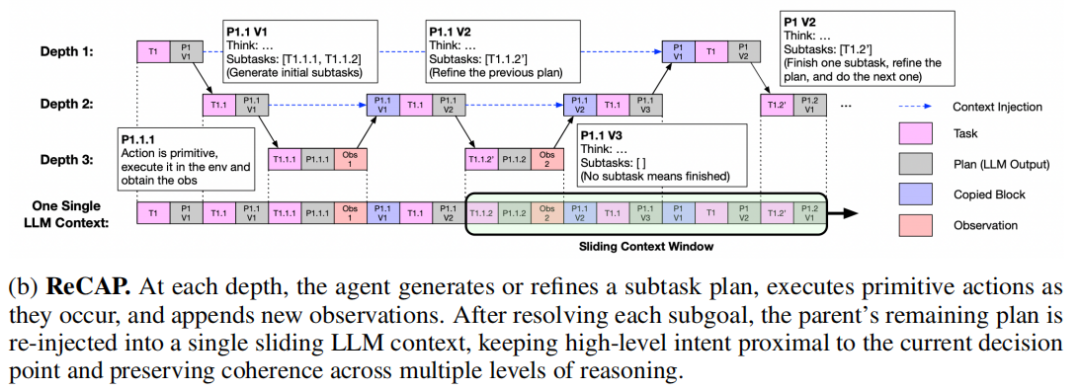
ReCAP通过三个精巧设计解决了这些问题。首先,它在每个递归节点一次性生成完整的子任务列表,但只执行第一个任务,完成后根据最新观察动态细化剩余计划,这既保证了规划的全局视野,又保留了灵活调整的空间。其次,也是最关键的一点,ReCAP维护一个跨所有递归层级的共享LLM上下文。当从子任务返回父任务时,系统会结构化地重新注入父任务的描述、思考和剩余子任务,这种"回溯式再注入"确保了高层目标与底层执行在漫长递归中始终保持对齐。
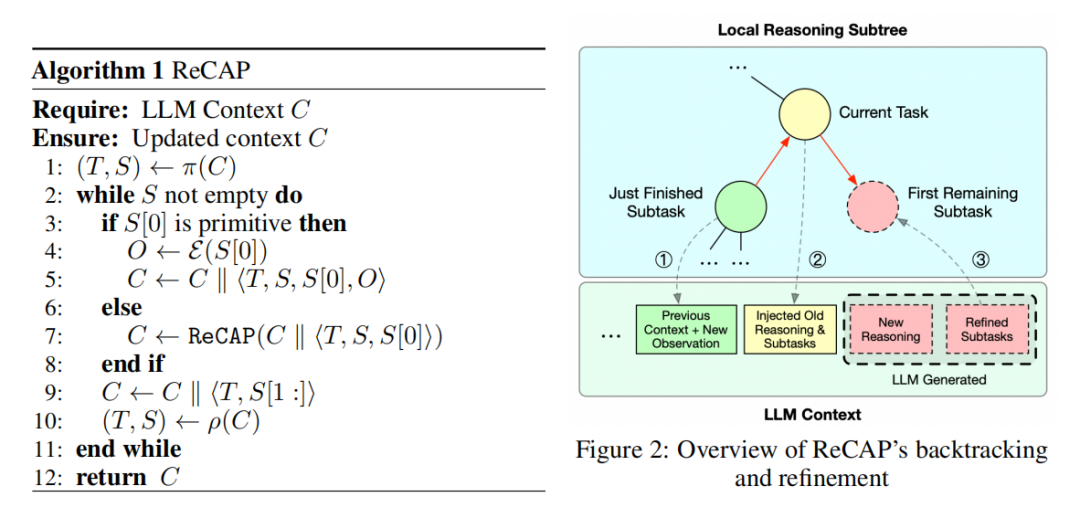
最后,ReCAP通过滑动窗口技术限制活动提示的大小,仅保留最近的对话轮次,同时通过结构化再引入保证关键信息不丢失,使得内存开销仅随任务树深度线性增长,而非总轨迹长度,实现了高效可扩展。
ReCAP通过将递归执行置于统一的、可回溯的上下文管理中,证明了如何组织与再利用上下文,其重要性不亚于单纯扩展上下文的长度,为构建连贯、自适应的长视野智能体提供了又一个强有力的系统级范式。
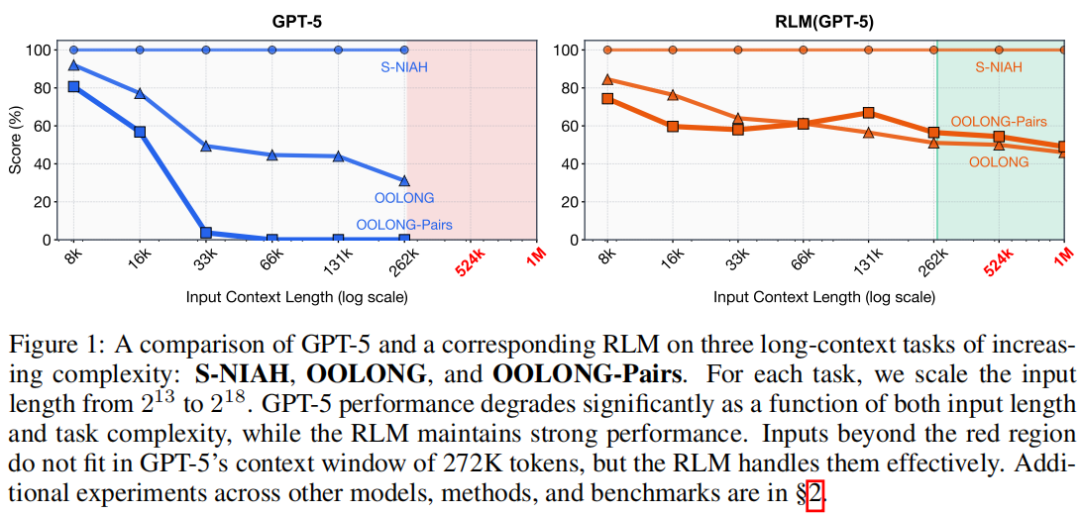
Recursive Language Models3
RLM提出了一种范式级的解决方案:将长提示视为"外部环境变量",通过代码交互与递归自我调用进行"离线处理"。现有长文本处理方法面临双重困局:像"上下文压缩"这样的有损方法会丢失关键细节;而像传统检索或CodeAct这样的方法,依然受限于基础模型单次推理的"内存墙"。
RLM彻底重构了模型与输入的交互方式。它不将长文本送入Transformer,而是将其作为一个变量(如context)加载到一个Python REPL(交互式编程环境)中。模型被赋予在环境中编写和执行代码的能力,可以编程式地"窥探"(如print(context:1000))、筛选(如正则表达式搜索)、分块处理这个变量。这相当于为模型提供了一个可以随意翻查、索引、操作外部"硬盘数据"的编程工具箱,而非必须将数据全部装入有限的"工作内存"。
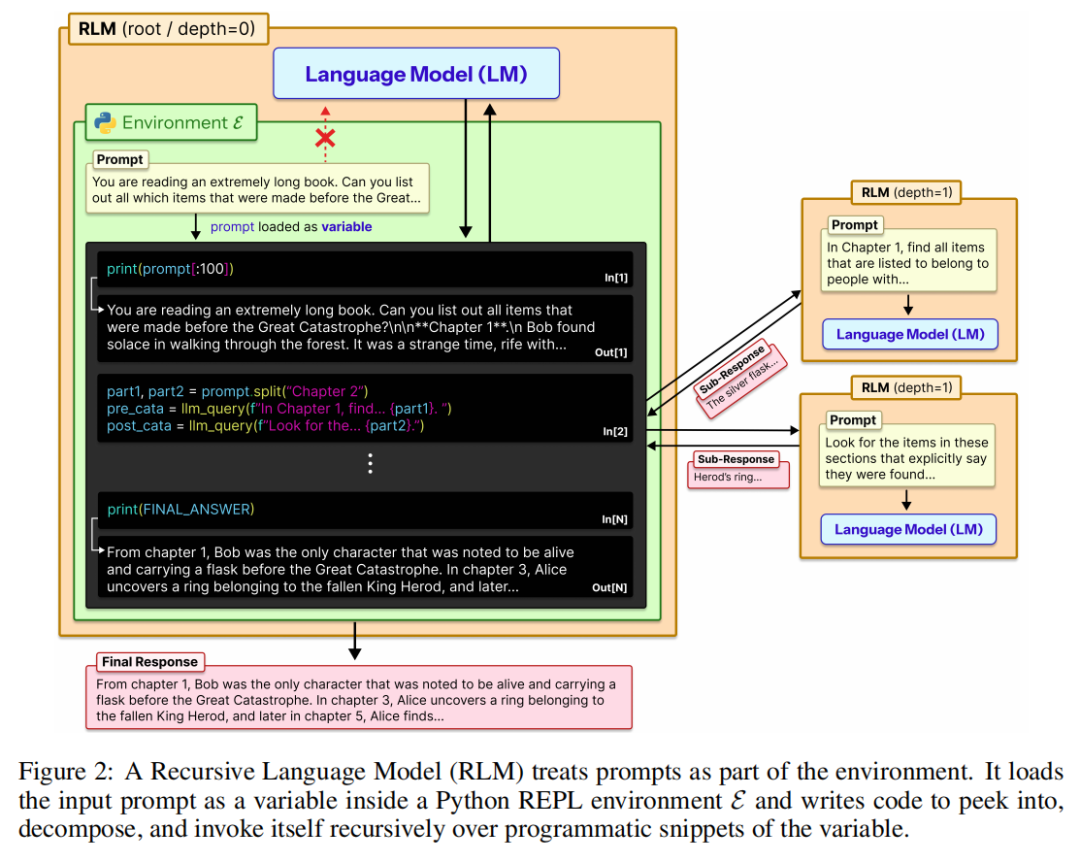
RLM同时鼓励模型在其编写的代码中,递归地调用自身(或更小的子模型)来处理子任务。面对一个超长context,模型可以策略性地将其分块,对每个块发起一次新的LLM调用进行语义分析、信息提取或摘要,并将结果存储回环境变量中。最后,模型再聚合这些中间结果,形成最终答案。这种设计使得推理链的长度和处理的文本总量在理论上不再受限于任何单次模型的上下文窗口,仅受外部存储和计算成本的约束。

RLM通过将长上下文管理从"神经网络的内部负担"转变为"模型可编程操控的外部对象",证明了处理超长文本的关键,或许不在于让模型"一次记住更多",而在于赋予它一套方法来"有策略地忘记与回顾"。这为构建能够驾驭千万乃至亿级token文档的下一代智能体,开辟了一条全新的、可扩展的系统架构之路。
Beyond Outlining: Heterogeneous Recursive Planning for Adaptive Long-form Writing with Language Models4
当大模型被要求撰写一篇长文,无论是小说还是技术报告,最常见的指令是"先列个提纲"。这背后是一种根深蒂固的假设:写作是一个线性执行计划的过程,仿佛只要前期规划足够周密,后续的文本生成就能水到渠成。然而,真正的写作,尤其是创造性的长文写作,远比这复杂。
由KAUST团队提出的 WriteHERE 框架,正是为了打破这种"计划与写作"的二分法。它的核心理念颇具启发性:写作本身,就应该是一个持续的、动态的规划过程。WriteHERE不再将"列提纲"视为一个孤立的前置阶段,而是将其溶解在整个写作的生命周期里,成为一种与检索信息、生成文本深度交织、随时可能被触发的推理活动。这更接近人类作家的工作状态------我们并非完全按计划行事,而是在与材料和思想的持续对话中,一边写,一边想,一边重新规划。
为了实现这种动态性,WriteHERE设计了一套精巧的双引擎系统。首先,它识别出写作中三种最基础的认知操作:检索 (从外部获取信息)、推理 (分析、规划、设计结构)和创作(实际生成文本)。系统从一个顶层的写作目标开始,递归地将这个大任务分解为更小的子任务,并为每一个子任务打上这三种类型之一的标签。
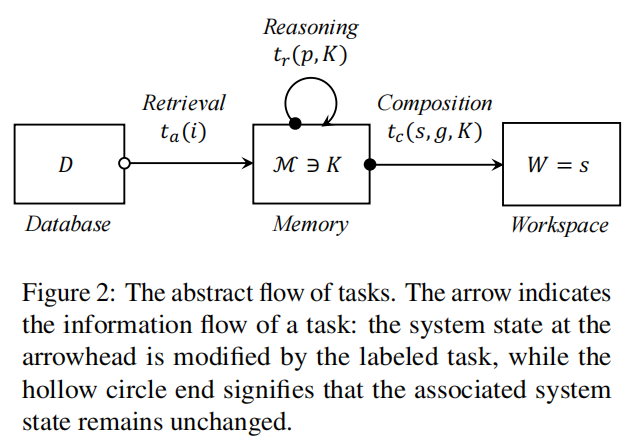
WriteHERE 的第二个引擎是一个基于状态的分层任务调度器。它把所有的任务及其依赖关系组织成一张有向无环图,每个任务都有"活跃"、"挂起"或"静默"的状态。系统像一个精明的项目经理,总是优先处理那些依赖已满足的、最紧迫的"活跃"任务。当一个任务被选中,系统会判断它是否已足够简单到可以直接执行。如果是,就立即调用相应的"执行器"去完成它,并将结果存入共享记忆;如果不是,就当场启动"规划器",将它进一步分解成几个子任务,然后挂起自身,等待子任务们去完成。这个过程循环往复,直到最终目标达成。
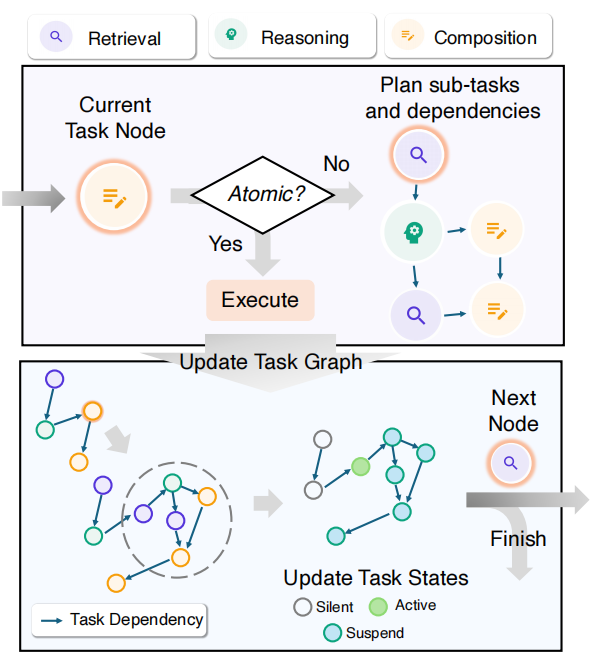
这个机制的妙处在于其实时的反馈与适应能力。每一步执行产生的新信息(比如搜到的一份颠覆性资料)会立刻更新到全局记忆中。这可能会立刻激活某些之前因信息不足而"挂起"的任务,也可能会触发对后续任务的全新规划。
总结
递归式语言模型是一整套围绕"按需分解---递归执行---结构化记忆"的系统范式。从这些工作可以抽象出递归式语言模型在长上下文与复杂任务上的共性原则:
-
任务与计划是动态的:不再依赖一次性全局计划,而是在执行中不断分解、修正与重组子任务。
-
上下文是结构化可管理的资源:通过分层记忆、滑动窗口、再注入和外部存储,把"记住什么、何时回顾"变成显式决策,而不是被动依赖固定窗口。
-
模型调用是可组合的工具:同一或不同等级的模型可以作为工具被反复调用,与代码、检索系统、外部环境协同工作,形成"同一智能体中的多进程协作"。
面向未来,大模型能力的提升与上下文窗口的扩展并不能自动解决长期依赖与复杂规划问题。更加关键的是如何围绕递归式调用、可编程环境与层级化记忆,设计一整套系统级的推理与控制机制。RecursiveLM 及相关工作提供了一条清晰的方向:让模型从"被动的单次回答器"演化为"主动管理任务与上下文的递归推理系统",这将是构建下一代长视野智能体与大规模知识工作流的关键基础设施。
参考文献
1Prasad, A., Koller, A., Hartmann, M., Clark, P., Sabharwal, A., Bansal, M., & Khot, T. (2024). ADaPT: As-Needed Decomposition and Planning with Language Models. In K. Duh, H. G'omez-Adorno, & S. Bethard (Eds.), Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, June 16-21, 2024 (pp. 4226--4252). Association for Computational Linguistics.
2Zhang, Z., Chen, T., Xu, W., Pentland, A., & Pei, J. (2025). ReCAP: Recursive Context-Aware Reasoning and Planning for Large Language Model Agents. CoRR, abs/2510.23822.
3Zhang, A. L., Kraska, T., & Khattab, O. (2025). Recursive Language Models.
4Xiong, R., Chen, Y., Khizbullin, D., Zhuge, M., & Schmidhuber, J. (2025). Beyond Outlining: Heterogeneous Recursive Planning for Adaptive Long-form Writing with Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 24678--24714.