一、什么是Longhorn
Longhorn 是一款专为 K8s 打造的分布式块存储系统,核心标签是 "轻量、可靠、开源免费"。它不依赖特定云厂商,能让 K8s 集群在任何环境下(公有云、私有云、物理机)都能获得稳定的持久化存储能力,尤其适配分布式有状态应用(如数据库、消息队列等)的存储需求。
Longhorn 的功能设计围绕 "便捷性、高可用、可扩展性" 展开,几乎覆盖了 K8s 存储的核心需求:
- 灵活的持久化存储支持:可将块存储划分为 Longhorn 卷,通过 K8s 的 Persistent Volume(PV)、Persistent Volume Claim(PVC)直接对接 workloads,也能通过存储类(Storage Class)自动创建 PV,无需手动配置,适配无云厂商依赖的场景。
- 高可用的副本机制:支持将卷的副本跨多个节点或数据中心部署,副本采用瘦供给(thin-provisioned)模式,节省存储资源;同时 Longhorn 会实时监控副本健康状态,故障时自动重建,避免数据丢失。
- 完善的备份与灾备方案:可将备份数据存储到 NFS、AWS S3 等外部存储,还支持创建跨集群灾备卷,-primary 集群数据可通过备份快速在备用集群恢复,应对极端故障。
- 自动化的快照与备份调度:支持按小时、日、周、月、年设定定时快照和备份任务,可自定义执行时间(如每周日凌晨 3 点),并配置保留的快照 / 备份集数量,无需人工干预。
- 无感知升级与快速恢复:升级 Longhorn 时不会影响正在使用的持久卷(PV),业务无中断;同时支持从备份直接恢复卷数据,操作简单高效。
Longhorn的架构
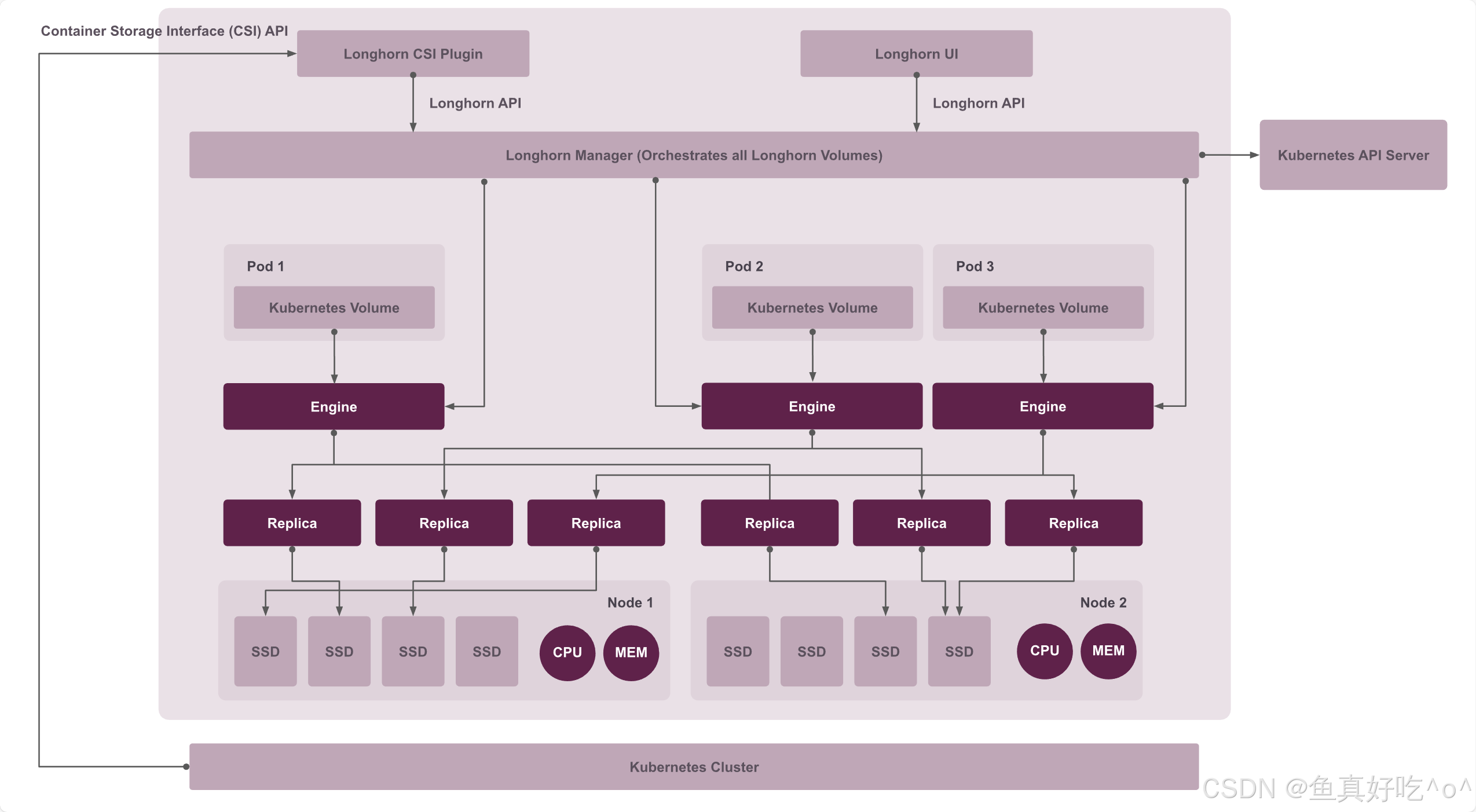
Longhorn的核心组件
| 组件名称 | 部署类型 | 主要作用 |
|---|---|---|
| Longhorn Manager | DaemonSet(每个节点一个) | 核心控制器,管理所有 Longhorn CRD 资源,协调卷的创建、附加、复制、快照、备份、故障恢复等生命周期操作 |
| Instance Manager | DaemonSet(每个节点一对) | 在节点上启动和管理引擎进程(engine)和副本进程(replica),负责实际的数据 I/O 和同步 |
| Engine Image | DaemonSet(每个节点一个) | 预部署 engine 镜像,确保快速启动 engine 进程,避免实时拉取镜像延迟 |
| Longhorn CSI Plugin | DaemonSet(每个节点一个) | CSI 驱动节点侧插件,处理卷的 attach/detach、mount/unmount 操作 |
| CSI Attacher | Deployment(多个副本) | CSI 外部 attacher,处理 VolumeAttachment 资源,实现卷的安全附加/分离 |
| CSI Provisioner | Deployment(多个副本) | CSI 外部 provisioner,根据 PVC 动态创建 Longhorn Volume |
| CSI Resizer | Deployment(多个副本) | CSI 外部 resizer,支持 Longhorn Volume 的在线扩容 |
| CSI Snapshotter | Deployment(多个副本) | CSI 外部 snapshotter,支持卷快照创建和恢复 |
| Longhorn Driver Deployer | Deployment(单个) | 部署并注册 CSI 驱动,确保驱动在集群中正确可用 |
| Longhorn UI | Deployment(多个副本) | 提供 Web 图形界面,用于查看和管理 Longhorn 资源 |
组件工作流程
卷创建:用户创建 PVC → CSI Provisioner 监听到 PVC → 调用 Longhorn Manager 创建 Volume CR → Manager 在多个节点调度 Replica → Instance Manager 在对应节点启动 Replica 进程(从 Engine Image 拉取镜像)并同步数据 → Manager 创建并启动 Engine 进程。
卷附加与使用:Pod 调度到节点并需要卷 → CSI Attacher 处理 VolumeAttachment → Longhorn Manager 更新 Engine 状态 → 节点上的 CSI Plugin(通过 Instance Manager)将 Engine 附加到 Pod → 卷 mount 到容器内,开始正常 I/O。
扩容/快照/备份:扩容由 CSI Resizer 触发 Manager 处理;快照由 CSI Snapshotter 触发 Manager 创建系统快照;备份由 Manager 协调 Replica 将数据备份到外部存储(如 NFS/S3)。
故障恢复:Manager 持续监控节点/Replica 状态,一旦故障,自动在健康节点重建 Replica 并同步数据,确保高可用。
整体上,Longhorn Manager 是控制中枢,协调所有操作;CSI 侧车组件负责与 Kubernetes Storage API 对接;Instance Manager + Engine/Replica 构成数据平面,执行实际存储任务;Engine Image 提供性能优化。整个流程完全分布式、无单点瓶颈。
二、Helm安装Longhorn
前提条件
安装 Longhorn 的 Kubernetes 集群中每个节点必须满足以下要求:
- 一个与Kubernetes兼容的容器运行时(Docker v1.13+,containerd v1.3.7+ 等)Kubernetes >= v1.25
- open-iscsi已安装,守护进程在所有节点上运行。这是必要的,因为Longhorn依赖主机为Kubernetes提供持久的体积。如需安装帮助,请参阅"Longhorn | Documentation"。
- RWX 支持要求每个节点都安装了 NFSv4 客户端Longhorn | Documentation与curl findmnt grep awk blkid lsblk。
- 主机文件系统支持存储数据的功能。目前我们支持:file extents ext4 XFS
Longhorn 命令行工具可用于检查 Longhorn 环境中的潜在问题。
longhornctl install preflight:安装 Longhorn 前,完成依赖项安装与环境配置。longhornctl check preflight:检查前置环境潜在问题,确保 Longhorn 可正常部署。
安装Longhorn
bash
# 添加Longhorn的Helm仓库:
[root@k8s-master ~]# helm repo add longhorn https://charts.longhorn.io
# 从仓库获取最新Chart:
[root@k8s-master ~]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "longhorn" chart repository
Update Complete. ⎈Happy Helming!⎈
# 在命名空间中安装Longhorn。longhorn-system
[root@k8s-master ~]# helm install longhorn longhorn/longhorn --namespace longhorn-system --create-namespace --version 1.10.1资源全部Running即可。
bash
[root@k8s-master ~]# kubectl get po,svc -n longhorn-system
NAME READY STATUS RESTARTS AGE
pod/csi-attacher-b5547c89c-4gklw 1/1 Running 0 45s
pod/csi-attacher-b5547c89c-7kznh 1/1 Running 0 45s
pod/csi-attacher-b5547c89c-qpsp7 1/1 Running 0 45s
pod/csi-provisioner-6d9fbbd668-khqk4 1/1 Running 0 45s
pod/csi-provisioner-6d9fbbd668-n69rq 1/1 Running 0 45s
pod/csi-provisioner-6d9fbbd668-rrxpl 1/1 Running 0 45s
pod/csi-resizer-588c678f58-jlzjr 1/1 Running 0 45s
pod/csi-resizer-588c678f58-rzh5n 1/1 Running 0 45s
pod/csi-resizer-588c678f58-vtfwq 1/1 Running 0 45s
pod/csi-snapshotter-589f996dc-clwbb 1/1 Running 0 45s
pod/csi-snapshotter-589f996dc-cq7nm 1/1 Running 0 45s
pod/csi-snapshotter-589f996dc-zpn24 1/1 Running 0 45s
pod/engine-image-ei-3154f3aa-7w96m 1/1 Running 0 48s
pod/engine-image-ei-3154f3aa-9kdb5 1/1 Running 0 48s
pod/engine-image-ei-3154f3aa-jrwsk 1/1 Running 0 48s
pod/instance-manager-060839cb71ef009217e592b449fbc862 1/1 Running 0 23s
pod/instance-manager-297b1b768d1d4db5f2e07f0b38982100 1/1 Running 0 20s
pod/instance-manager-4062cd5b4c8324230fc94387619727ca 1/1 Running 0 18s
pod/longhorn-csi-plugin-94wwf 3/3 Running 0 45s
pod/longhorn-csi-plugin-fwsxn 3/3 Running 0 45s
pod/longhorn-csi-plugin-rdp5b 3/3 Running 0 45s
pod/longhorn-driver-deployer-58768fb7fd-kq6hj 1/1 Running 1 (50s ago) 59s
pod/longhorn-manager-578p5 2/2 Running 0 59s
pod/longhorn-manager-gjjz8 2/2 Running 1 (54s ago) 59s
pod/longhorn-manager-xb7n9 2/2 Running 0 59s
pod/longhorn-ui-7b9c99fd9-bmg96 1/1 Running 0 59s
pod/longhorn-ui-7b9c99fd9-tpqs9 1/1 Running 0 59s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/longhorn-admission-webhook ClusterIP 10.103.39.127 <none> 9502/TCP 60s
service/longhorn-backend ClusterIP 10.104.167.225 <none> 9500/TCP 60s
service/longhorn-frontend ClusterIP 10.96.164.124 <none> 80/TCP 60s
service/longhorn-recovery-backend ClusterIP 10.106.36.242 <none> 9503/TCP 60s
[root@k8s-master ~]# kubectl get csidrivers.storage.k8s.io
NAME ATTACHREQUIRED PODINFOONMOUNT STORAGECAPACITY TOKENREQUESTS REQUIRESREPUBLISH MODES AGE
csi.tigera.io true true false <unset> false Ephemeral 86d
driver.longhorn.io true true true <unset> false Persistent 28m对方访问暴露,官方推荐使用Ingress-nginx的basic安全认证,需要创建一个Ingress,允许外部流量到达Longhorn的UI。
但是这里就先不麻烦怎么访问了,因为集群回快照没有安装ingress...我们直接修改为NodePort类型。
bash
[root@k8s-master ~]# kubectl -n longhorn-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
longhorn-admission-webhook ClusterIP 10.103.39.127 <none> 9502/TCP 3m23s
longhorn-backend ClusterIP 10.104.167.225 <none> 9500/TCP 3m23s
longhorn-frontend NodePort 10.96.164.124 <none> 80:30179/TCP 3m23s
longhorn-recovery-backend ClusterIP 10.106.36.242 <none> 9503/TCP 3m23s在页面中,Longhorn会显示集群空间使用信息:Dashboard
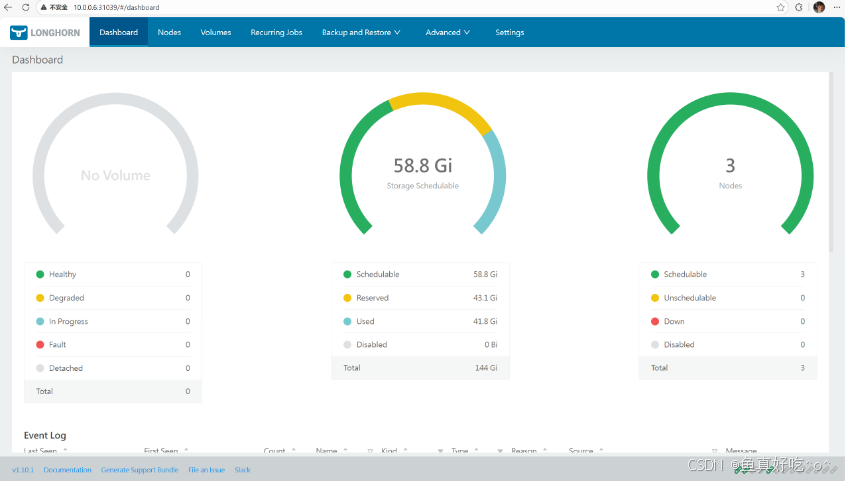
`Schedulable`:Longhorn队体积调度的实际空间。
`Reserved`:为其他应用和系统预留的空间。
`Used`:Longhorn、系统及其他应用实际使用的空间。
`Disabled`: Longhorn 卷不允许调度的磁盘/节点的总空间。
彩蛋:自动拉取镜像脚本
此脚本针对于Longhorn的v1.10.1版本,运行时为containerd.(docker修改拉取命令即可。)
bash
#!/bin/bash
#Maintainer: CFC
set -euo pipefail # 出错立即退出、未定义变量报错、管道失败触发报错
HUAWEI_REGISTRY="swr.cn-north-4.myhuaweicloud.com/ddn-k8s/"
# 定义需要拉取的官方镜像列表
OFFICIAL_IMAGES=(
"docker.io/longhornio/livenessprobe:v2.17.0-20251030"
"docker.io/longhornio/longhorn-manager:v1.10.1"
"docker.io/longhornio/longhorn-share-manager:v1.10.1"
"docker.io/longhornio/longhorn-ui:v1.10.1"
"docker.io/longhornio/csi-node-driver-registrar:v2.15.0-20251030"
"docker.io/longhornio/longhorn-engine:v1.10.1"
"docker.io/longhornio/csi-snapshotter:v8.4.0-20251030"
"docker.io/longhornio/csi-resizer:v1.14.0-20251030"
"docker.io/longhornio/csi-provisioner:v5.3.0-20251030"
"docker.io/longhornio/csi-attacher:v4.10.0-20251030"
"longhornio/longhorn-instance-manager:v1.10.1"
)
for IMAGE in "${OFFICIAL_IMAGES[@]}"; do
HUAWEI_IMAGE="${HUAWEI_REGISTRY}${IMAGE}"
echo -e "\n====================================="
echo "开始处理镜像:${IMAGE}"
echo "华为云镜像地址:${HUAWEI_IMAGE}"
echo -e "=====================================\n"
echo "【步骤1】拉取华为云镜像..."
ctr -n k8s.io images pull "${HUAWEI_IMAGE}"
if [ $? -eq 0 ]; then
echo "✅ 拉取${HUAWEI_IMAGE}成功!"
else
echo "❌ 拉取${HUAWEI_IMAGE}失败!请检查网络/镜像地址"
exit 1
fi
echo -e "\n【步骤2】打官方镜像标签..."
ctr -n k8s.io images tag "${HUAWEI_IMAGE}" "${IMAGE}"
if [ $? -eq 0 ]; then
echo "✅ 为${IMAGE}打标签成功!"
else
echo "❌ 为${IMAGE}打标签失败!"
exit 1
fi
echo -e "\n-------------------------------------"
echo "🎉 镜像${IMAGE}处理完成!"
echo -e "-------------------------------------\n"
done
echo -e "\n====================================="
echo "✅ 所有Longhorn镜像拉取+打标全部完成!"
echo "📌 验证命令:ctr -n k8s.io images ls | grep longhornio"
echo "=====================================\n"三、认识Node与Volumes
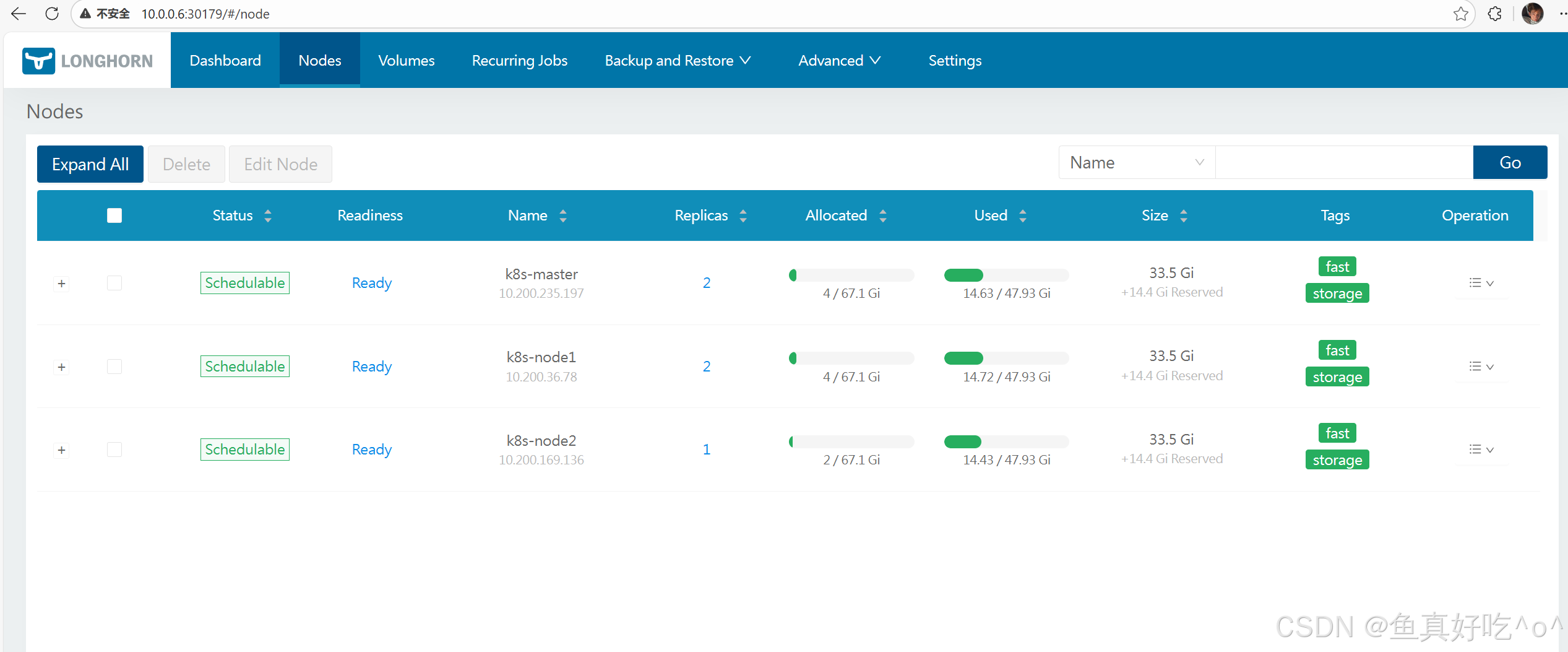
Nodes
Longhorn 的 Node:对应 K8s 集群中的节点,是提供物理存储资源的载体,运行 Longhorn 管理组件并承载卷副本,是存储能力的基础。
在页面中,Longhorn 会显示每个节点的空间分配、排程和使用情况:Node
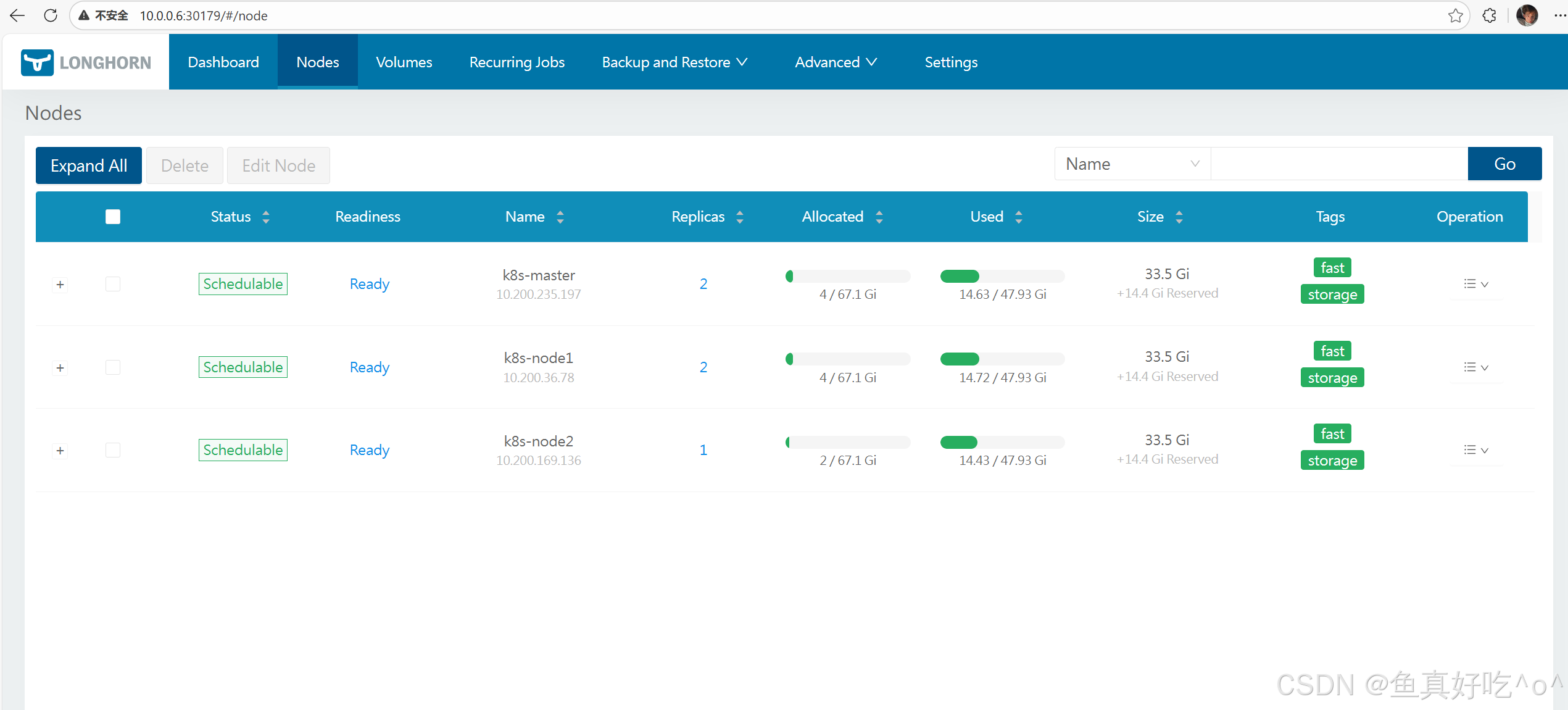
- Status:节点的调度状态,这里 "Scheduleable" 表示该节点可被 Longhorn 用于调度卷的副本。
- Readiness:节点的就绪状态,"Ready" 代表节点正常可用,能参与 Longhorn 的存储操作。
- Name :节点的标识信息,包含 K8s 集群内的节点名称(如
k8s-master)和对应的节点 IP。 - Replicas:当前运行在该节点上的 Longhorn 卷副本数量。
- Allocated:Longhorn 在该节点上已分配的存储空间(分子),以及该节点可分配的存储总上限(分母)。
- Used:该节点实际使用的物理存储容量(分子),以及节点的存储总容量(分母)。
- Size :节点的存储配置相关信息,包含节点的存储基础大小,以及额外预留的存储空间(
+14.4 Gi Reserved)。 - Tags:给节点打的标签,用于 Longhorn 卷副本的调度筛选(比如指定卷的副本仅调度到带有特定标签的节点)。
- Operation:针对该节点的操作入口(下拉菜单),通常包含维护模式切换、详情查看等操作选项。
存储标签
存储标签功能允许仅使用特定节点或磁盘存储Longhorn卷数据。例如,对性能敏感的数据可仅使用标记为fastssdnvmebaremetal的高性能磁盘,或仅使用标记为fastssdnvmebaremetal的高性能节点。 该功能同时支持磁盘和节点。
设置
标签可以通过Longhorn的UI设置:
-
节点 -> 选择一个节点 -> 编辑节点和磁盘
-
点击或添加新标签。
+New Node Tag``+New Disk Tag
节点或磁盘上所有现有的调度副本都不会受到新标签的影响。
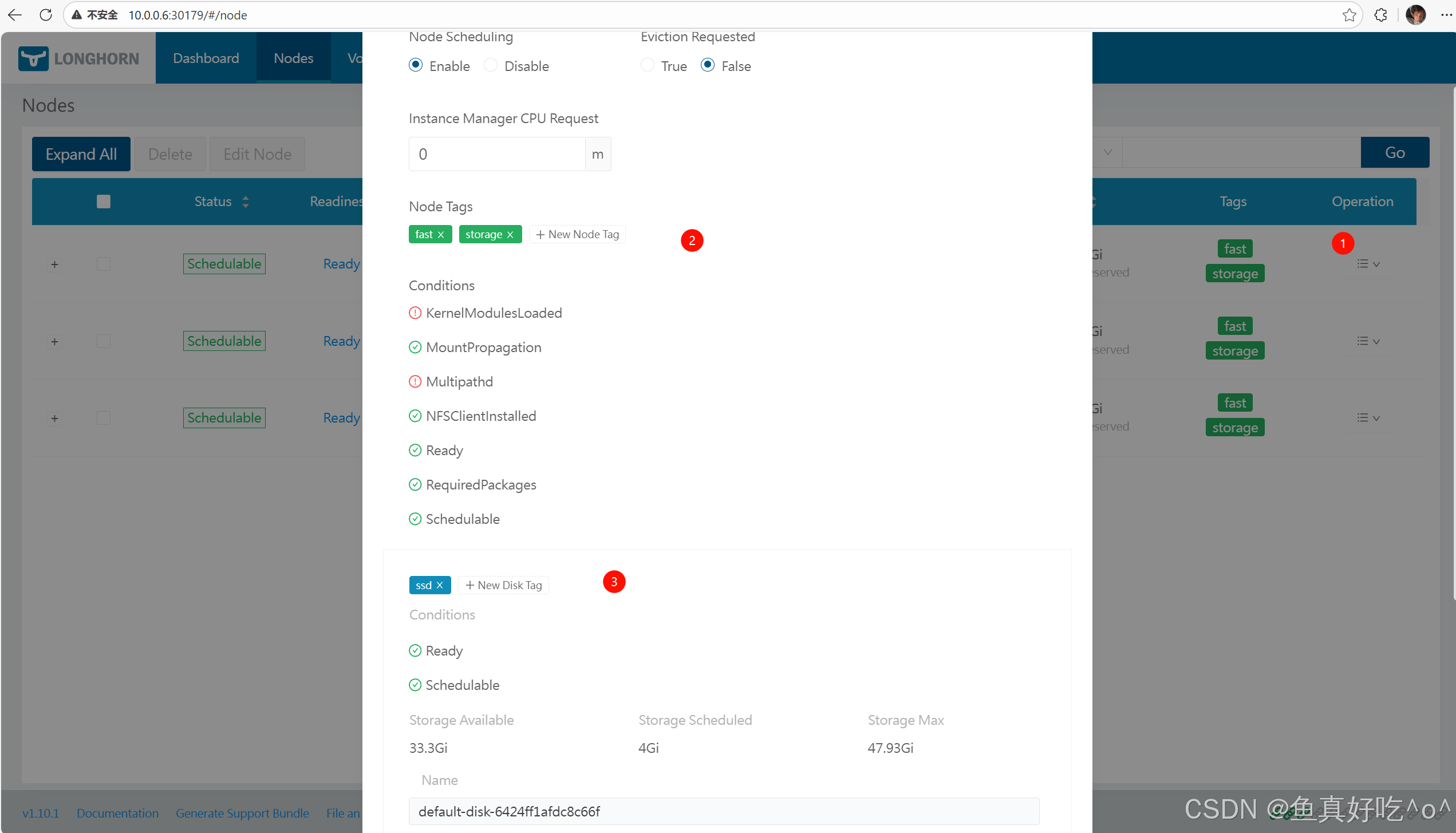
用途
当一个卷指定多个标签时,磁盘和节点(磁盘所属)必须拥有所有指定的标签才能可用。
背景 & 适用场景
-
新加入的 Kubernetes 节点默认没有 Longhorn 的磁盘配置或标签。
-
通过在 Kubernetes 层给节点加标签/注解,Longhorn 会自动生成默认磁盘以及节点设置。
-
对于具有多个磁盘的节点或需要统一策略的大规模集群特别有用。
添加默认 Node Tags(节点标签)这一步只是打上tag,具体能不能直接调度副本到此集群,还要看:
① 节点是否被 Longhorn 接管
② 节点上是否存在 Schedulable 的 Disk
③ Replica 的调度规则是否命中这些标签
目的: 给新节点自动设置 Longhorn 节点标签(例如:ssd、fast 等),用于调度或 StorageClass 策略选择。
$ 方法:
扩容节点到 Kubernetes 集群。
给新节点添加注解:kubectl annotate node <节点名> node.longhorn.io/default-node- tags='"fast","storage"',等待 Longhorn 自动同步到对应的 Longhorn 节点对象上。
$ 结果:
如果节点原来没有标签,Longhorn 会复制注解中的标签。
如果有已有标签则不会覆盖。
定制默认磁盘配置
先决条件
Longhorn 的设置里必须开启:
Create Default Disk on Labeled Nodes(仅对有标签的节点创建默认磁盘)
如果关闭,则无论标签如何,Longhorn 都会在所有新节点上用 settings.default-data-path 自动创建默认磁盘。

标签规则
| Label 键 | Label 值 | Longhorn 行为 |
|---|---|---|
node.longhorn.io/create-default-disk=true |
true |
Longhorn 在新节点上根据 settings.default-data-path 创建默认磁盘(如果该节点还没磁盘)。 |
node.longhorn.io/create-default-disk=config |
config |
Longhorn 根据 JSON 注解生成自定义磁盘列表。这有这个可以自定义磁盘。 |
| 未设置 | − | 尽管 setting 开启,不会自动创建默认磁盘。 |
⚠️ 如果标签值错误或注解 JSON 解析失败,将忽略整个配置。
bash
📌 注解格式示例
注解键:
node.longhorn.io/default-disks-config
注解值示例:
[
{
"path":"/mnt/disk1",
"allowScheduling":true
},
{
"name":"fast-ssd-disk",
"path":"/mnt/disk2",
"allowScheduling":false,
"storageReserved":10485760,
"tags":["ssd","fast"]
}
]
含义说明:
字段 说明
path 磁盘挂载路径
name 磁盘自定义名称(可选)
allowScheduling 是否允许Replica 可以调度到这个 Disk(true是Replica 可以调度到这个 Disk)(false是这个 Disk 只挂着,不放数据)
storageReserved 保留空间(字节)给宿主机 预留空间,Longhorn 不会用这部分,防止磁盘被打满导致
tags 与节点相同的调度策略标签| Disk | 是否参与副本调度 | 用途 |
|---|---|---|
/mnt/disk1 |
✅ 是 | 唯一可写 Replica 的磁盘 |
/mnt/disk2 |
❌ 否 | 完全不承载任何 Replica 数据 |
bash
那 disk2 什么时候"会被用到"?
# 场景 1:disk1 快满了,但业务不能停
# 场景 2:你只想让 某一个 Volume 用
比如:
1️⃣ 查看磁盘真实信息
lsblk -f
你会看到类似:
NAME FSTYPE UUID MOUNTPOINT
sdb xfs 3f1a7c32-0c58-4a8d-aee3-9c3c5c1fbe11
nvme0n1 ext4 91b7d2a1-0e6f-4b93-9e3f-62f98c8f0b99
# 格式化(如果是新盘)
/dev/sdb → XFS(推荐给 Longhorn)
mkfs.xfs /dev/sdb
/dev/nvme0n1 → ext4(看你用途)
mkfs.ext4 /dev/nvme0n1
# 创建挂载目录
mkdir -p /mnt/disk1
mkdir -p /mnt/disk2
# 写入 /etc/fstab(关键)
编辑文件
vim /etc/fstab
添加(示例)
UUID=3f1a7c32-0c58-4a8d-aee3-9c3c5c1fbe11 /mnt/disk1 xfs defaults,noatime 0 0
UUID=91b7d2a1-0e6f-4b93-9e3f-62f98c8f0b99 /mnt/disk2 ext4 defaults,noatime 0 0
📌 UUID 是绑定"这块盘"的,不会乱
# 验证(一定要做)
mount -a
然后:
df -h | grep /mnt
你应该看到:
/dev/sdb 2.0T ... /mnt/disk1
/dev/nvme0n1 500G ... /mnt/disk2如果/mnt/disk1空间不够了,需要打开disk2,迁移一些空间到2上面,该怎么办?
bash
正确操作流程(生产可用)
🟢 场景前提
/mnt/disk1 快满了
/mnt/disk2 是一块独立磁盘
之前 allowScheduling=false
# Step 1:临时开放 disk2(允许调度)
给节点打注解(或改已有的):
kubectl annotate node <node-name> \
node.longhorn.io/create-default-disk='[
{"path":"/mnt/disk1","allowScheduling":true},
{"path":"/mnt/disk2","allowScheduling":true}
]' --overwrite
👉 此时:
disk2 正式成为 Longhorn Disk
但还不会自动搬数据
# Step 2:触发 Replica 重建(核心步骤)
通过 Longhorn UI / API:
找到 Volume
删除一个位于 /mnt/disk1 的 Replica
Longhorn 会:
自动在 /mnt/disk2 新建 Replica
从其他 Replica 同步数据
📌 这是 副本级"迁移",不是文件迁移。
# Step 3(可选):再次关闭 disk2
如果你只是"救急":
kubectl annotate node <node-name> \
node.longhorn.io/create-default-disk='[
{"path":"/mnt/disk1","allowScheduling":true},
{"path":"/mnt/disk2","allowScheduling":false}
]' --overwrite
已经建在 disk2 的 Replica 不会被删除
只是以后不再往 disk2 新放.Kubernetes自定义StorageClass
参考如下配置:
https://raw.githubusercontent.com/longhorn/longhorn/v1.10.1/examples/storageclass.yaml
针对于存储的配置在Volumes会详细讲解。
使用 Kubernetes StorageClass 参数来指定标签。
你可以在默认的 Longhorn StorageClass 中添加名为fast\storage...的参数来指定标签。
bash
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-ssd-fast # 自定义存储类名称,后续PVC需关联此名称
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: "Delete"
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "480"
diskSelector: "ssd" # Longhorn的磁盘存储标签
nodeSelector: "storage,fast" # Longhorn的节点存储标签针对于这些标签选择,他们都是且的关系,比如nodeSelector,两者必须都包含。
| 配置项 | 含义与作用 | 关键注意事项 |
|---|---|---|
provisioner |
指定 K8s 使用 Longhorn 的 CSI 驱动管理 PV/PVC,是 Longhorn 存储类的核心标识,不可修改 | 必须固定为 driver.longhorn.io,否则无法关联 Longhorn 存储系统 |
allowVolumeExpansion |
开启卷扩容功能 | 支持在线 / 离线扩容 PVC(修改 PVC 的storage.requests即可),Longhorn 1.8 + 支持 RWX 卷扩容、1.10 + 支持 V2 引擎卷扩容 |
reclaimPolicy |
PVC 删除后,关联的 Longhorn 卷 / 副本的回收策略 | Delete= 自动删除卷和数据;可选Retain= 保留数据(需手动清理),按需调整 |
volumeBindingMode |
PVC 与 PV 的绑定时机 | Immediate=PVC 创建后立即绑定 PV;若需 Pod 调度后再绑定,可改为WaitForFirstConsumer |
numberOfReplicas |
每个 Longhorn 卷的副本数(高可用核心配置) | 3 副本为高可用推荐值,需确保集群中符合nodeSelector的节点数≥3,否则卷创建失败 |
staleReplicaTimeout |
过期副本清理超时时间(单位:分钟) | 480 分钟 = 8 小时,失联超此时长的副本会被自动清理;网络波动大的场景建议调大(如默认 2880 分钟) |
diskSelector |
限定卷副本仅调度到带ssd标签的 Longhorn 磁盘 |
需先给 Longhorn 管理的磁盘打ssd标签(通过 Longhorn UI/CLI/API 设置) |
nodeSelector |
限定卷副本仅调度到同时带storage和fast标签的 K8s 节点 |
需先给目标节点打标签:kubectl label node <节点名> storage=xxx fast=xxx |
bash
[root@k8s-master ~/longhorn]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 13m
longhorn-ssd-fast driver.longhorn.io Delete Immediate true 2s
longhorn-static driver.longhorn.io Delete Immediate true 13m创建Pod来测试SC动态存储
bash
[root@k8s-master ~/longhorn/test]# cat pvc.yaml
# pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-pvc-sc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn-ssd-fast
resources:
requests:
storage: 1Gi
[root@k8s-master ~/longhorn/test]# cat pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-pvc-demo
spec:
replicas: 1
selector:
matchLabels:
apps: v1
template:
metadata:
labels:
apps: v1
spec:
volumes:
- name: data
# 声明存储卷的类型是pvc
persistentVolumeClaim:
# 声明pvc的名称
claimName: longhorn-pvc-sc
- name: dt
hostPath:
path: /etc/localtime
initContainers:
- name: init01
image: myweb:v1
volumeMounts:
- name: data
mountPath: /data
- name: dt
mountPath: /etc/localtime
command:
- /bin/sh
- -c
- date -R > /data/index.html ; echo www.vamos.com >> /data/index.html
containers:
- name: c1
image: myweb:v1
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
- name: dt
mountPath: /etc/localtime
bash
[root@k8s-master ~/longhorn/test]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-pvc-demo-86bf569477-kfgrt 1/1 Running 0 2m40s 10.200.36.107 k8s-node1 <none> <none>
[root@k8s-master ~/longhorn/test]# curl 10.200.36.107
Thu, 29 Jan 2026 16:11:17 +0800
www.vamos.com
[root@k8s-master ~/longhorn/test]# kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/pvc-41fec105-e76d-4f07-a749-fbda83d57ad1 1Gi RWO Delete Bound default/longhorn-pvc-sc longhorn-ssd-fast <unset> 3m48s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/longhorn-pvc-sc Bound pvc-41fec105-e76d-4f07-a749-fbda83d57ad1 1Gi RWO longhorn-ssd-fast <unset> 3m50s默认副本存储路径
默认保存了3(3个节点)副本,路径也告诉了/var/lib/longhorn/,
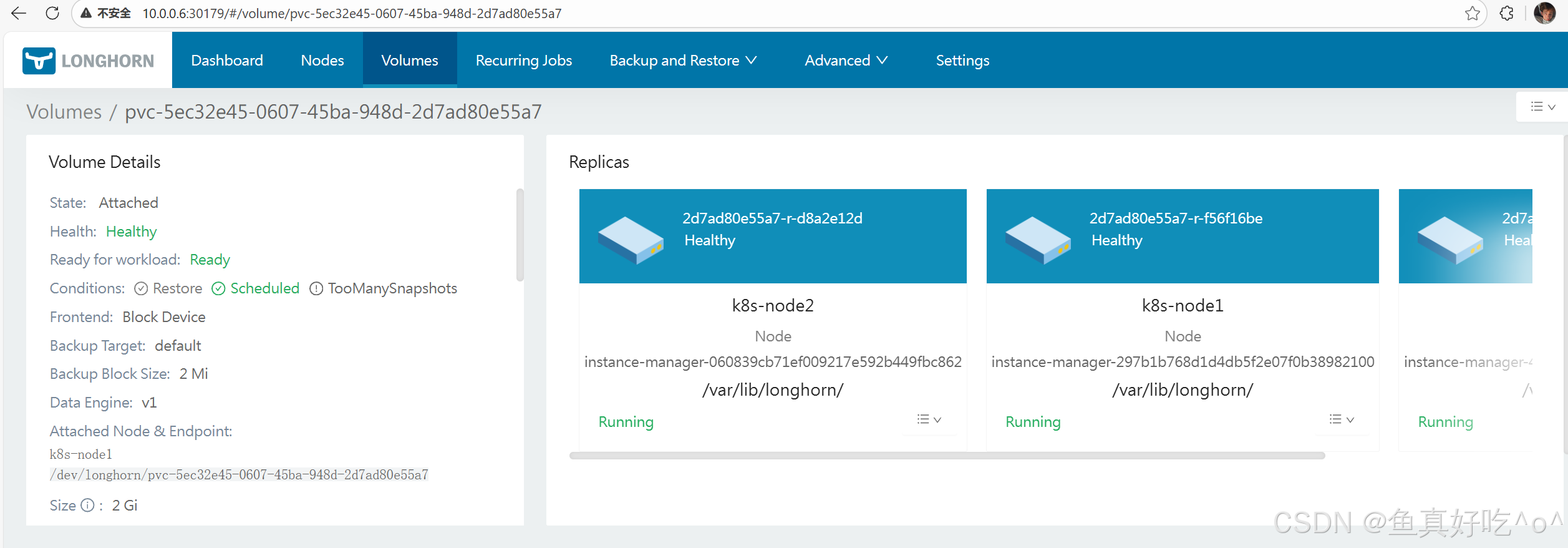
bash
[root@k8s-master ~/longhorn/test]# ll /var/lib/longhorn/
total 20
drwxr-xr-x 3 root root 4096 Jan 29 15:39 engine-binaries/
drwxr-xr-x 2 root root 4096 Jan 29 15:40 logs/
-rw-r--r-- 1 root root 126 Jan 29 15:40 longhorn-disk.cfg
drwxr-xr-x 3 root root 4096 Jan 29 16:11 replicas/
drwxr-xr-x 2 root root 4096 Jan 29 15:40 unix-domain-socket/
[root@k8s-master ~/longhorn/test]# ll /var/lib/longhorn/replicas/
total 4
drwx------ 2 root root 4096 Jan 29 16:13 pvc-41fec105-e76d-4f07-a749-fbda83d57ad1-a450dd1f/
[root@k8s-master ~/longhorn/test]# ll /var/lib/longhorn/replicas/pvc-41fec105-e76d-4f07-a749-fbda83d57ad1-a450dd1f/
total 49832
-rw-r--r-- 1 root root 1073741824 Jan 29 16:12 volume-head-001.img
-rw-r--r-- 1 root root 163 Jan 29 16:12 volume-head-001.img.meta
-rw-r--r-- 1 root root 1073741824 Jan 29 16:12 volume-snap-snap-872a2c2727624b6d.img
-rw-r--r-- 1 root root 142 Jan 29 16:13 volume-snap-snap-872a2c2727624b6d.img.meta
-rw-r--r-- 1 root root 179 Jan 29 16:12 volume.meta
[root@k8s-master ~/longhorn/test]#
bash
[root@k8s-master ~/longhorn/test]# kubectl -n longhorn-system get volume.longhorn.io
NAME DATA ENGINE STATE ROBUSTNESS SCHEDULED SIZE NODE AGE
pvc-41fec105-e76d-4f07-a749-fbda83d57ad1 v1 attached healthy 1073741824 k8s-node1 6m44s
[root@k8s-master ~/longhorn/test]# kubectl -n longhorn-system get replica.longhorn.io
NAME DATA ENGINE STATE NODE DISK INSTANCEMANAGER IMAGE AGE
pvc-41fec105-e76d-4f07-a749-fbda83d57ad1-r-c88c628d v1 running k8s-node1 ff82261c-4ec7-44d7-8290-b5debfa9e2bb instance-manager-297b1b768d1d4db5f2e07f0b38982100 longhornio/longhorn-engine:v1.10.1 7m54s
pvc-41fec105-e76d-4f07-a749-fbda83d57ad1-r-e39e2262 v1 running k8s-node2 4c2a7f3b-a89c-492f-b964-b41187ab4034 instance-manager-060839cb71ef009217e592b449fbc862 longhornio/longhorn-engine:v1.10.1 7m54s
pvc-41fec105-e76d-4f07-a749-fbda83d57ad1-r-ea89f6bd v1 running k8s-master 5e3e60b9-e1fa-4001-9235-d6f413b1d5c5 instance-manager-4062cd5b4c8324230fc94387619727ca longhornio/longhorn-engine:v1.10.1 7m54s如何把新磁盘加入节点
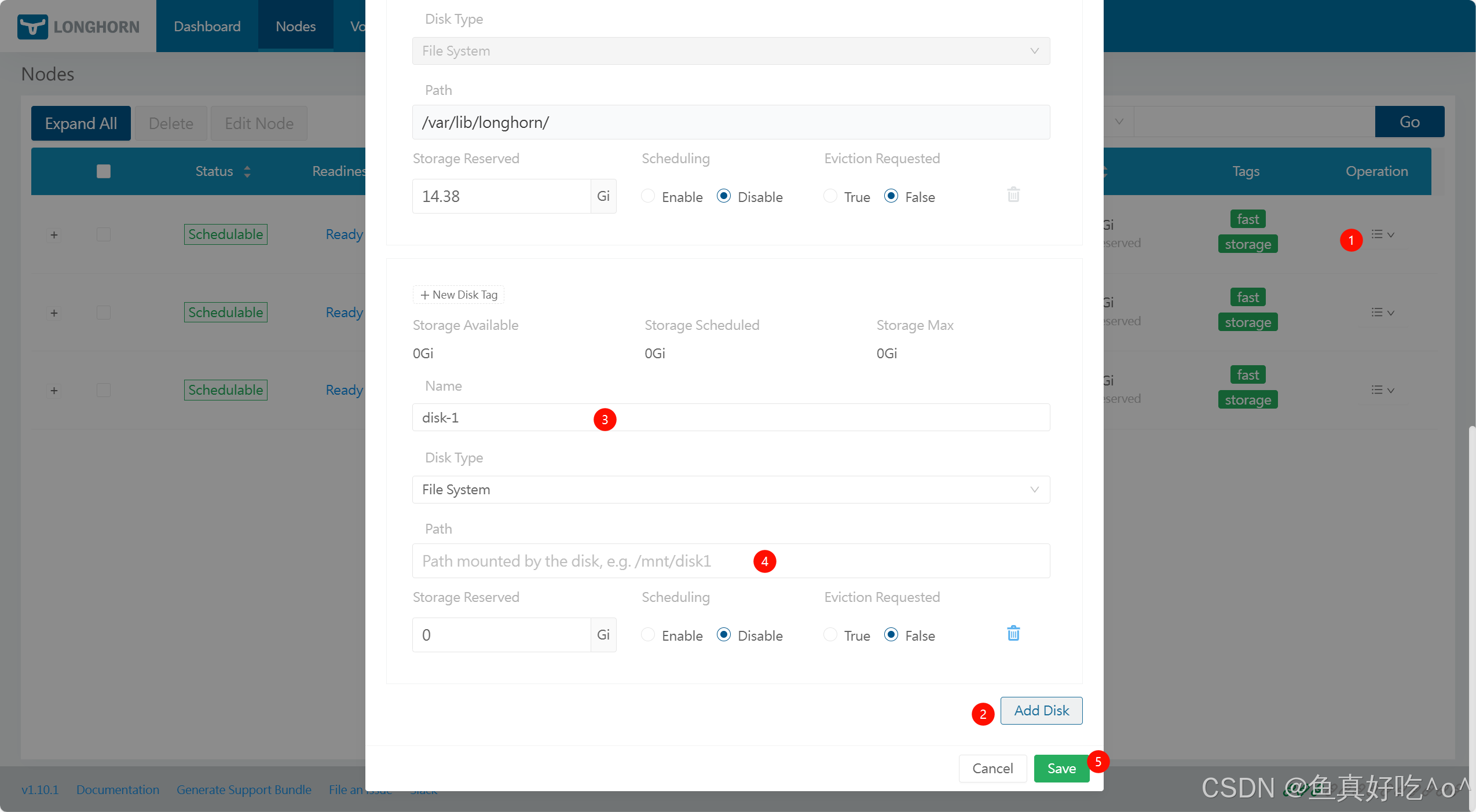
通俗解释(步骤)
选磁盘:通常是挂载了单独数据盘的路径
格式化:建议用 ext4 或 xfs 文件系统
挂载目录:把盘挂在如 /mnt/disk1
通知 Longhorn:
通过 UI → Nodes → Edit Disks
或者通过 kubectl edit node.longhorn.io 将磁盘路径添加到。例如:spec.disks
...
spec:
...
disks:
...
example-disk:
allowScheduling: true
diskDriver: ""
diskType: filesystem
evictionRequested: false
path: /mnt/example-disk
storageReserved: 0
tags: \[\]
...
注意事项:
✔ 不能重复添加
Longhorn 会用 文件系统 ID 来检查重复挂载,所以:
不能添加已经被用过的路径
不能把同一个磁盘在同一节点定义两次
✔ 挂载必须在系统层面稳定
官方建议在 /etc/fstab 持久挂载盘,要避免:
用符号链接
挂载在临时路径
因为 Longhorn 需要稳定识别磁盘路径,尤其是重启后。
可选配置(影响 Disk 调度行为)
storageReserved:先给磁盘 "留保底空间"(给系统 / 非 Longhorn 用途);StorageMinimalAvailablePercentage:再给磁盘 "设动态安全线"(防写爆、性能崩);StorageOverProvisioningPercentage:最后 "放大逻辑空间"(利用 thin provision 提高利用率)。
storageReserved
先给每个磁盘预留系统必需的固定空间(避免 Longhorn 占满磁盘后,系统日志 / 临时文件没空间):
- 建议值:每个磁盘设
2~5Gi(小磁盘 2Gi,大磁盘 5Gi); - 举例:100Gi 磁盘设
storageReserved=5Gi,先扣掉 5Gi 给系统,Longhorn 实际可用 95Gi。
StorageMinimalAvailablePercentage
给所有磁盘设动态硬水位(防满盘、性能雪崩、副本故障):
- 核心依据:ext4/xfs 在磁盘使用超 80% 后性能会明显下降,因此这个参数要对应 "磁盘可用不低于 20%~30%";
- 建议场景:
- 稳定型业务(数据库 / 核心应用):设
30%(磁盘使用不超过 70%,避免性能波动); - 弹性型业务(测试 / 非核心应用):设
20%(磁盘使用不超过 80%,性能影响可接受);
- 稳定型业务(数据库 / 核心应用):设
- 举例:100Gi 磁盘(已扣 5Gi reserved),设 30% 则至少留
95Gi×30%≈28.5Gi空闲,Longhorn 实际可用到95-28.5=66.5Gi时,就不再调度新副本。
StorageOverProvisioningPercentage
基于业务实际写入量,放大逻辑调度空间(利用 thin provision / 稀疏快照的空间节省特性):
- 核心依据:业务中 Volume 的 "实际写入量" 与 "声明大小" 的比例(比如声明 100Gi 实际只写 30Gi,就可以超卖);
- 建议场景:
- 稳定型业务:设
150%(降低超卖比例,减少物理空间不足风险); - 弹性型业务:设
200%~300%(默认 200%,最大化空间利用率);
- 稳定型业务:设
- 举例:100Gi 磁盘(已扣 5Gi reserved),设 200% 则 Longhorn 允许逻辑上调度
95Gi×200%=190Gi的 Volume------ 只要这些 Volume 的实际写入不超过 "硬水位线内的空间"(66.5Gi),就不会出问题。
这三个参数不能互相替代,必须搭配使用:
- 只开
storageReserved:磁盘可能用到 95%(扣完 reserved),触发性能雪崩;- 只开
StorageMinimalAvailablePercentage:系统可能没空间用(比如 Longhorn 占满剩余空间);- 只开
StorageOverProvisioningPercentage:超卖太多会导致实际物理空间触达硬水位,新副本无法调度。
删除磁盘
你不能强制删掉有正在使用的数据的磁盘。
要先:
把这个 Disk 的 allowScheduling 设为 false
等待 Longhorn 将上面的 Replica 跨其它 Disk/节点迁移掉
确认空了以后再安全删除
Scheduling调度
主要讲解 Longhorn 如何为存储卷(Volume)的副本(Replica)自动选择 Kubernetes 节点(Node)和磁盘(Disk)。 调度过程分为两个阶段:
节点与区域选择阶段(Node and Zone Selection Stage)------优先保证故障容错,把副本分散到不同节点和不同可用区(Zone)。
磁盘选择阶段(Disk Selection Stage)------在选好的节点上,进一步挑选合适的磁盘,确保空间足够并遵守反亲和规则。
如果任一阶段不满足条件,调度就会失败。整个机制依赖标签(Tags)、反亲和性(Anti-Affinity)和存储空间检查来实现灵活、可控的高可用调度。
调度策略整体流程
Longhorn 的副本调度是两阶段的:
先选节点和区域(Node/Zone Selection)。
再在选好的节点上选磁盘(Disk Selection)。
只有前一阶段满足条件,才会进入下一阶段;任意阶段失败 → 整个调度失败,卷会进入故障状态等待修复。
通俗说:就像安排座位,先决定坐哪一排(节点/区域),再决定具体哪个位置(磁盘),每一步都有严格规则。
第一阶段:节点与区域选择
核心目标:故障容错,尽量把同一个卷的多个副本分散到不同节点、不同可用区,避免单点故障。
关键机制:
- 节点标签匹配(Node Tag Matching)
你可以给节点贴"标签"(比如"ssd""high-io"),卷说"我只想放在有这些标签的节点上",调度器就只挑匹配的节点。
- 已封锁节点处理(Cordoned Node Handling)
Kubernetes 中被 kubectl cordon 的节点默认不参与调度(由设置 Disable Scheduling On Cordoned Node 控制,默认 true)。
- 反亲和规则(Anti-Affinity Rules Across Nodes and Zones)
尽量把副本分散到不同 Kubernetes Zone(通过 topology.kubernetes.io/zone 标签识别);同样是"软"规则,优先但不强制。
第二阶段:磁盘选择
1. 磁盘标签匹配
- 是啥?:给磁盘贴标签(比如 "ssd 快盘""hdd 慢盘"),卷可以指定 "只选带某标签的盘"
- 干啥用?:区分不同性能 / 用途的磁盘,比如把核心业务卷放 SSD 盘
2. 可用空间检查
- 是啥?:调度副本前先查磁盘空间,两个规矩:① 必须留够保底空间(默认留 25%),快写满了就不让新副本进来;② 允许 "超卖空间"(默认卖 2 倍)------ 因为很多卷实际用的比声明的小,不用白不用
- 干啥用?:既防磁盘写爆、性能崩溃,又不浪费存储空间
3. 磁盘软反亲和
- 是啥?:同一卷的多个副本,优先放不同磁盘;实在没其他盘了,才挤同一盘
- 干啥用?:分散风险,别一个磁盘坏了,卷的多个副本都没了
4. 磁盘硬反亲和
- 是啥?:强制同一卷的副本不能放同一磁盘,没符合条件的盘就不调度
- 干啥用?:给核心业务(比如数据库)用,确保副本绝对隔离,更安全
重要全局设置
(Settings,在 Longhorn UI 的 Setting 页面配置)
这些是系统级开关,影响所有卷的调度行为:
-
Allow Empty Node Selector Volume(默认 true) 允许卷不设置节点标签时,可以调度到任意节点(包括有标签的)。
-
Allow Empty Disk Selector Volume(默认 true) 同上,针对磁盘标签。
-
Disable Scheduling On Cordoned Node(默认 true) 是否禁止在被 cordon 的节点上调度新副本。
-
Replica Node/Zone/Disk Level Soft Anti-Affinity(默认 enabled) 控制上述软反亲和是否生效。
-
Storage Minimal Available Percentage & Storage Over Provisioning Percentage 控制空间检查的严格程度。
Longhorn 的调度系统通过标签 + 软/硬反亲和 + 空间检查,在保证高可用(分散副本)和资源合理利用之间取得平衡。你可以根据实际硬件和需求,通过标签和全局设置来精细控制副本落在哪里。
在禁用的磁盘或节点上驱逐副本
主要讲解如何安全地将存储卷的副本(Replica)从已被禁用调度的磁盘(Disk)或节点(Node)上自动驱逐(Evict)到其他可用位置。 核心目标:在维护或替换硬件时,平滑迁移数据,同时保持卷的高可用性(不降低副本数量)。
驱逐的前提:
-
磁盘/节点必须先禁用调度(Disable Scheduling)。
-
再设置Eviction Requested = true 来触发自动驱逐。
驱逐机制是保守安全的 :Longhorn 会逐个卷处理,只在新副本成功重建 后才驱逐旧副本;支持附着和分离状态的卷(分离卷会自动临时附着)。 如果出错(如无空间、无可用节点),驱逐会暂停直到问题解决,或手动取消。
一句话:这是 Longhorn 的"安全搬家"功能,让你能安全下线磁盘/节点,而不影响正在使用的存储卷。
驱逐过程(Eviction Process)
你设置 Eviction Requested = true。
Longhorn 检查所有受影响的卷。
对每个卷:先在别处重建一个新副本 → 成功后 → 删除旧副本。
重复直到该磁盘/节点上副本数为 0。
如何操作驱逐(UI 操作步骤)
驱逐磁盘
驱逐节点
-
取消驱逐
-
把对应磁盘/节点的 Eviction Requested 改回 false 即可。
-
已驱逐的副本不会回来,剩余的会留在原地。
-
在驱逐时可以实时查看状态
查看进度:
在 Node/Disk 列表里看 Replicas 数量 → 成功驱逐后应降到 0。
点击 Replicas 数量 → 看具体副本名称 → 点击副本 → 跳转到卷页面查看状态。
出错处理:
如果调度失败(如无空间、无可用磁盘/节点),驱逐会自动暂停。
错误会显示在 UI 并记录在 Event log。
解决办法:清理空间、添加新磁盘/节点,或手动取消驱逐。
通俗说:驱逐不是一蹴而就,看副本数慢慢归零;出问题会停下来等你修好。
节点驱逐和磁盘驱逐的区别
-
磁盘驱逐 :针对节点上的单个磁盘,其他磁盘仍可正常使用。
-
节点驱逐 :针对整个节点(所有磁盘上的副本都会被驱逐)。
-
其他逻辑完全一样(逐卷、安全重建后驱逐)。
Longhorn 的驱逐功能让你能安全"退役"磁盘或节点------先封锁、再请求驱逐,系统自动、一件一件地把副本搬走,保证数据始终高可用。实际操作时记得先禁用调度、监控事件日志,出错就暂停等你处理。
节点状态
bash
$ Ready
节点完全"准备就绪"------longhorn-manager Pod 在运行、Kubernetes 节点状态 Ready、没有 CPU/内存/磁盘等资源压力。相当于节点整体健康,无资源瓶颈。
$ Schedulable
节点没有被 kubectl cordon(不可调度),可以正常接受新工作负载(Pod)。如果被 cordon,这里会警告,提醒你节点已被暂停调度。
$ MountPropagation
检查节点是否支持"挂载传播"(Mount Propagation),这是 Longhorn 卷在同一节点多个容器/Pod 间共享的关键功能。如果不支持,RWX 卷或某些共享场景会出问题。
$ Multipathd
检查 multipathd 服务(多路径守护进程)是否在运行。如果在运行,可能干扰卷挂载启动(常见 iSCSI 问题)。官方建议关闭它,避免冲突(参考故障排查文档)。
$ RequiredPackages
检查节点是否安装了 Longhorn 必需的软件包,缺任何一个都会警告。
$ NFSClientInstalled
专门检查 NFS 客户端版本是否支持 v4.0+(RWX 共享卷和备份必须)。即使 RequiredPackages 通过,这里会额外验证版本兼容性。
$ KernelModulesLoaded
检查关键内核模块是否已加载。没有这些模块,加密、SPDK 高性能引擎或 NVMe 功能会失效。
$ HugePagesAvailable
检查节点是否正确配置了 2Mi 巨页内存(HugePages),这是 v2 数据引擎(高性能模式)的硬性要求。配置不足会影响 SPDK 等功能性能。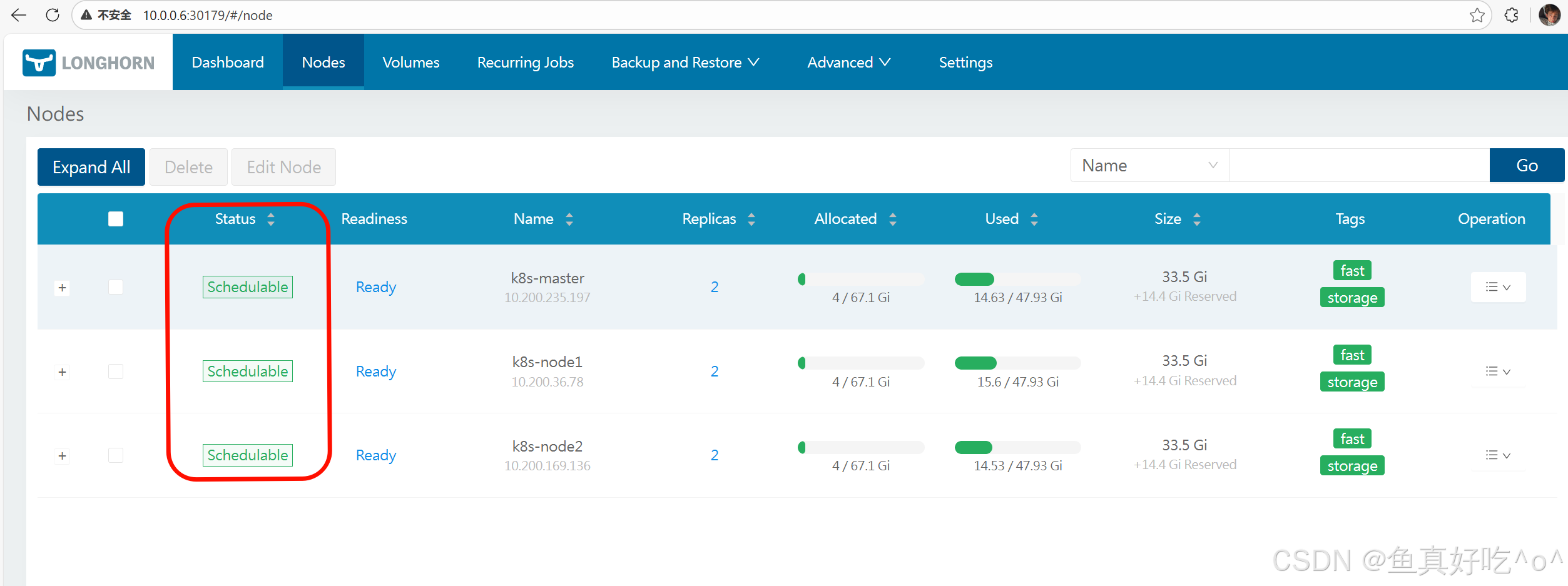
Volumes
Longhorn 的 Volumes:即 Longhorn 卷,是面向有状态应用的持久化存储单元,通过多副本机制保障高可用,可直接对接 K8s 的 PV/PVC 供应用使用。
创建Longhorn卷册
- 动态供给(Dynamic Provisioning):用 kubectl + Longhorn StorageClass,自动创建卷。
- UI 手动创建:先在 Longhorn UI 创建 detached 卷,再手动绑定 PV/PVC。
通过 kubectl 创建卷通过StorageClass
最常用方式:定义 StorageClass → 创建 PVC → Kubernetes 自动调用 Longhorn 驱动创建卷和 PV。
步骤 1:创建 StorageClass
bash
kubectl create -f https://raw.githubusercontent.com/longhorn/longhorn/v1.10.1/examples/storageclass.yaml
bash
[root@k8s-master ~/longhorn-sc]# cat storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-csi
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "480"
fromBackup: ""
fsType: "ext4"
# 字面含义:文件系统类型为 ext4
# 实际作用:指定存储插件在初始化 PV 的底层存储设备(磁盘 / 块存储) 时,会自动对设备进行格式化,并使用ext4文件系统;后续 K8s 容器挂载该 PV 时,直接使用这个格式化后的文件系统。
# mkfsParams: "-I 256 -b 4096 -O ^metadata_csum,^64bit"
# backingImage: "bi-test"
# backingImageDataSourceType: "download"
# backingImageDataSourceParameters: '{"url": "https://backing-image-example.s3-region.amazonaws.com/test-backing-image"}'
# backingImageChecksum: "SHA512 checksum of the backing image"
# unmapMarkSnapChainRemoved: "ignored"
# diskSelector: "ssd,fast"
# nodeSelector: "storage,fast"
# recurringJobSelector: '[{"name":"snap-group", "isGroup":true},
# {"name":"backup", "isGroup":false}]'
# nfsOptions: "soft,timeo=150,retrans=3"
[root@k8s-master ~/longhorn-sc]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 18h
longhorn-csi driver.longhorn.io Delete Immediate true 21s
longhorn-static driver.longhorn.io Delete Immediate true 18h步骤 2:创建带 PVC 的 Pod
bash
kubectl create -f https://raw.githubusercontent.com/longhorn/longhorn/v1.10.1/examples/pod_with_pvc.yaml
bash
[root@k8s-master ~/longhorn-sc]# cat pod_with_pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-volv-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn-csi
resources:
requests:
storage: 2Gi
---
apiVersion: v1
kind: Pod
metadata:
name: volume-test
namespace: default
spec:
restartPolicy: Always
containers:
- name: volume-test
image: myweb:v1
imagePullPolicy: IfNotPresent
livenessProbe:
exec:
command:
- ls
- /data/lost+found
initialDelaySeconds: 5
periodSeconds: 5
volumeMounts:
- name: volv
mountPath: /data
ports:
- containerPort: 80
volumes:
- name: volv
persistentVolumeClaim:
claimName: longhorn-volv-pvc
[root@k8s-master ~/longhorn-sc]# kubectl apply -f pod_with_pvc.yaml
persistentvolumeclaim/longhorn-volv-pvc created
pod/volume-test created
[root@k8s-master ~/longhorn-sc]# kubectl get po -w
NAME READY STATUS RESTARTS AGE
volume-test 0/1 ContainerCreating 0 3s
volume-test 0/1 ContainerCreating 0 14s
volume-test 1/1 Running 0 15s
bash
[root@k8s-master ~/longhorn-sc]# kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7 2Gi RWO Delete Bound default/longhorn-volv-pvc longhorn-csi <unset> 58s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/longhorn-volv-pvc Bound pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7 2Gi RWO longhorn-csi <unset> 61s
[root@k8s-master ~/longhorn-sc]# 验证3副本
bash
[root@k8s-master ~/longhorn-sc]# ll /var/lib/longhorn/replicas/
total 4
drwx------ 2 root root 4096 Jan 30 10:05 pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7-ff8804e6/
[root@k8s-master ~/longhorn-sc]# ssh k8s-node1 "ls -l /var/lib/longhorn/replicas/"
total 4
drwx------ 2 root root 4096 Jan 30 10:05 pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7-f4a1dc1c
[root@k8s-master ~/longhorn-sc]# ssh k8s-node2 "ls -l /var/lib/longhorn/replicas/"
total 4
drwx------ 2 root root 4096 Jan 30 10:05 pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7-4ce43d45通过 Longhorn UI 创建卷
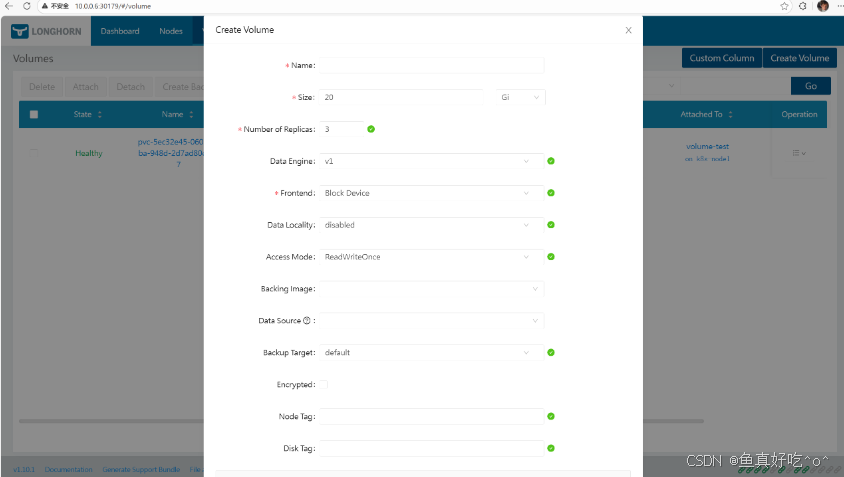
现在是在 Longhorn UI 里直接创建 Volume,这个流程不需要提前准备 PVC。
如果你是想给 Kubernetes 使用,创建完这个 Volume 后,你可以后续再创建 PVC 并关联它;
也可以反过来,直接在 Kubernetes 里定义 PVC,由 Longhorn 动态地自动创建对应的 Volume(这种方式更常用)。
后续关联 PVC 的思路
如果你是想给 Kubernetes 用这个 Volume,创建完成后可以这样做:
在 Kubernetes 里创建一个 PVC,在 spec.csi.volumeHandle 字段中填入你刚才创建的 Volume 名称;
或者更推荐的方式是:直接在 Kubernetes 里定义 PVC,由 Longhorn 的 CSI 驱动自动创建对应的 Volume,这样不需要你在 UI 里手动操作。
bash
[root@k8s-master ~/longhorn-sc]# kubectl get volumes.longhorn.io -n longhorn-system
NAME DATA ENGINE STATE ROBUSTNESS SCHEDULED SIZE NODE AGE
app-data-vol-01 v1 detached unknown 524288000 106s
pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7 v1 attached healthy 2147483648 k8s-node1 11m
bash
[root@k8s-master ~/longhorn-sc]# cat bound-uiCreate-volumes-pvc.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: app-data-pv-01 # 自定义 PV 名字
spec:
capacity:
storage: 500Mi # 必须 ≥ Longhorn 卷的大小(这里是 524288000 bytes ≈ 500Mi)
volumeMode: Filesystem
accessModes:
- ReadWriteOnce # 或 ReadWriteMany 如果你配置了 RWX
persistentVolumeReclaimPolicy: Delete # 或 Retain(推荐 Retain 防止误删)
storageClassName: longhorn-csi # 关键:必须是这个(或你在 Setting → General → Default Longhorn Static StorageClass Name 中改的)
csi:
driver: driver.longhorn.io
fsType: ext4 # 默认 ext4,可改 xfs
volumeHandle: app-data-vol-01 # 关键:填你的 Longhorn 卷名字
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: app-data-pvc-01 # 自定义 PVC 名字
namespace: default # 改成你的 namespace
spec:
accessModes:
- ReadWriteOnce # 必须和 PV 一致
resources:
requests:
storage: 500Mi # 必须 ≥ Longhorn 卷大小
storageClassName: longhorn-csi # 必须和 PV 一致
volumeName: app-data-pv-01 # 可选:直接绑定指定 PV(推荐,防止匹配错)
[root@k8s-master ~/longhorn-sc]# cat test-pod-ui-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pod
namespace: default
spec:
containers:
- name: test
image: myweb:v1
volumeMounts:
- mountPath: /data
name: vol
volumes:
- name: vol
persistentVolumeClaim:
claimName: app-data-pvc-01
bash
[root@k8s-master ~/longhorn-sc]# kubectl -n longhorn-system get volumes.longhorn.io
NAME DATA ENGINE STATE ROBUSTNESS SCHEDULED SIZE NODE AGE
app-data-vol-01 v1 attached healthy 524288000 k8s-node1 8m46s
pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7 v1 attached healthy 2147483648 k8s-node1 18m
[root@k8s-master ~/longhorn-sc]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pod 1/1 Running 0 50s 10.200.36.121 k8s-node1 <none> <none>
volume-test 1/1 Running 0 19m 10.200.36.120 k8s-node1 <none> <none>删除Longhorn卷册
如何永久删除不再需要的 Longhorn 卷(包括其所有副本和数据)。
核心方式分为两种:
-
通过 Kubernetes(适用于动态供给卷):删除 PVC,触发自动清理 PV 和 Longhorn 卷(前提是 PV 的 persistentVolumeReclaimPolicy: Delete)。
-
通过 Longhorn UI(最通用,适用于所有卷,包括静态供给):直接在 UI 操作删除单卷或多卷。
删除是永久性操作 ,会不可逆地丢失卷数据;UI 会对关联的 PV/PVC (会一并删除)和attached 卷(可能正在使用)发出警告,防止误操作。页面没有涉及复杂场景如 faulted replicas 的 salvage、force delete 或 recurring jobs 的影响,重点在于简单、安全删除。
一句话:删除卷的最可靠方式是 Longhorn UI,它会给你必要警告;Kubernetes 方式只适合动态供给且配置了自动回收的场景。
通过 Kubernetes 删除卷
官方条件:
-
只适用于动态供给的卷。
-
PV 的 persistentVolumeReclaimPolicy 必须是 Delete(默认就是,如果用官方 StorageClass)。
bash
[root@k8s-master ~]# kubectl delete pvc app-data-pvc-01
persistentvolumeclaim "app-data-pvc-01" deletedKubernetes 自动:
-
清理 PV(根据 reclaim policy)。
-
调用 Longhorn 删除底层卷。
限制:不适用于静态供给卷(因为没有动态 provisioner 触发清理)。
通过 Longhorn UI 删除卷
官方优势 :适用于所有 Longhorn 卷,无论动态还是静态供给。
单卷删除步骤:
-
进入 Longhorn UI 的 Volumes 页面。
-
找到目标卷,在 Operation 下拉菜单中选择 Delete。
-
弹窗确认删除(会显示警告)。
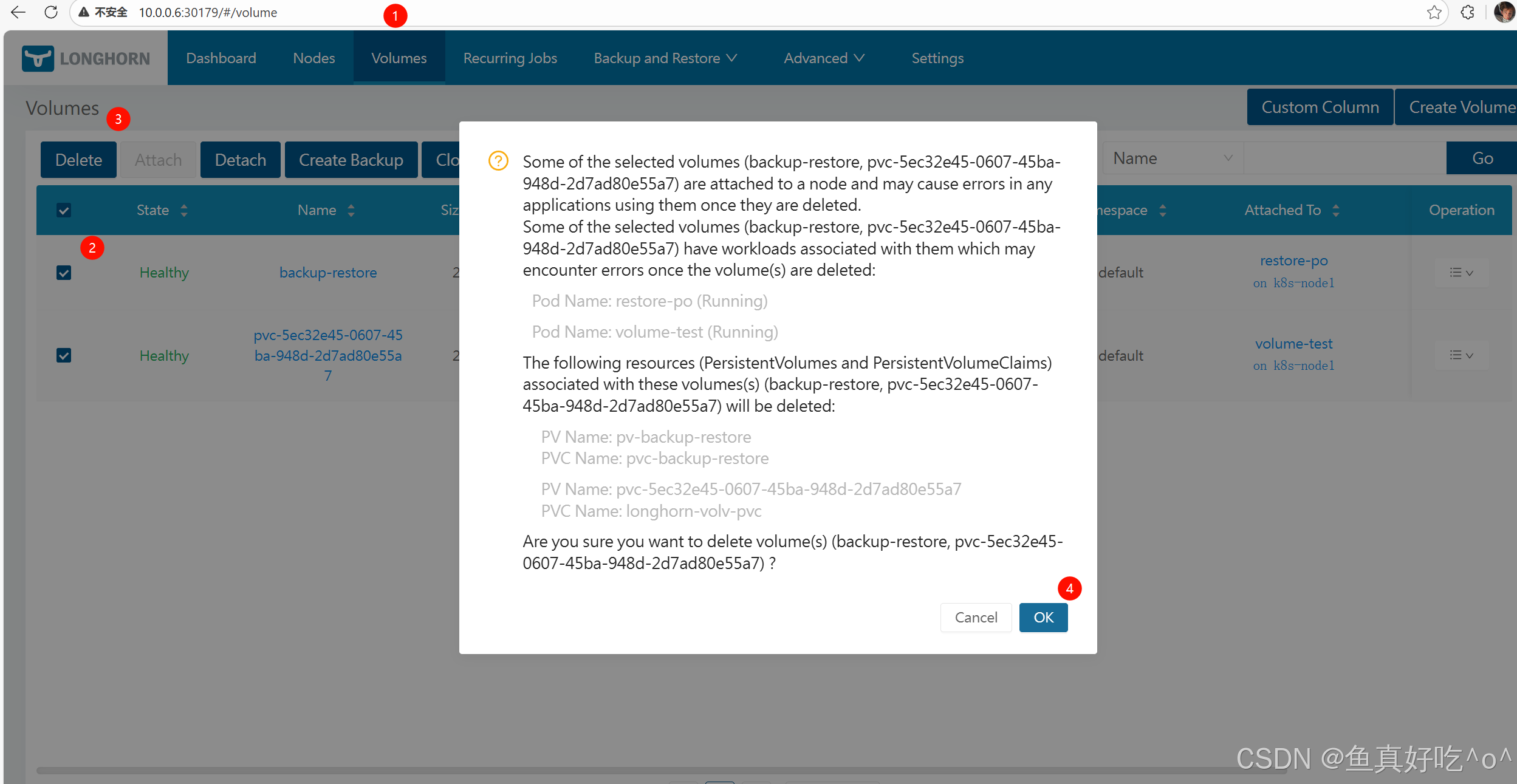
多卷批量删除步骤:
-
在 Volumes 页面,勾选多个卷的复选框。
-
在页面顶部操作栏选择 Delete。
-
确认删除。
bash
[root@k8s-node1 ~]# ll /var/lib/longhorn/replicas/
total 8
drwx------ 2 root root 4096 Jan 30 13:42 app-data-vol-01-ef4419ff/
drwx------ 2 root root 4096 Jan 30 13:42 pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7-f4a1dc1c/
[root@k8s-node1 ~]# ll /var/lib/longhorn/replicas/app-data-vol-01-ef4419ff/
total 48820
-rw------- 1 root root 4096 Jan 30 13:42 revision.counter
-rw-r--r-- 1 root root 524288000 Jan 30 13:42 volume-head-002.img
-rw-r--r-- 1 root root 178 Jan 30 13:42 volume-head-002.img.meta
-rw-r--r-- 1 root root 524288000 Jan 30 13:42 volume-snap-930935a6-a528-42eb-be03-6cb6078b99b7.img
-rw-r--r-- 1 root root 158 Jan 30 13:42 volume-snap-930935a6-a528-42eb-be03-6cb6078b99b7.img.meta
-rw-r--r-- 1 root root 193 Jan 30 13:42 volume.meta
[root@k8s-node1 ~]# ll /var/lib/longhorn/replicas/app-data-vol-01-ef4419ff/
ls: cannot access '/var/lib/longhorn/replicas/app-data-vol-01-ef4419ff/': No such file or directoryLonghorn 删除卷很简单,UI 方式最万能且有警告保护;Kubernetes 方式依赖动态供给和 Delete reclaim policy。实际操作时,永远先看 UI 警告,确认无 PV/PVC 依赖和无 attached 状态,再删------删了就真没了!
Detaching Volumes分离卷
主要讲解如何安全 detach(分离) Longhorn 卷,使其从 attached 状态变为 detached。
-
核心前提:Longhorn 卷只有在不再被任何 Kubernetes Pod 使用时才会自动 detach。因此,detach 的本质是先 shutdown 或删除所有使用该卷的 Pods/workloads(Kubernetes 会自动处理 detach)。 页面针对常见 Kubernetes workload 类型(Deployment、StatefulSet、DaemonSet 等)提供具体操作方法,适用于系统维护、升级 Longhorn 等需要全局 detach 卷的场景。 最后一步:等待自动 detach 完成,再在 Longhorn UI 手动 detach 剩余卷(通常是非 Kubernetes 创建的卷)。
-
一句话:detach 卷的关键不是直接操作卷,而是先停掉用卷的 Pods;页面提供各种 workload 的"停机"指南,确保所有卷安全 detach。
适用场景:主要为系统级维护(如 Longhorn 升级),需要所有卷 detached 时使用。日常单个卷 detach 通常靠删除 Pod 自动完成,不需要这些复杂步骤。
核心原则:
-
Kubernetes 删除 Pod 时 → 自动触发卷 detach。
-
没有 Pod 用卷 → 卷自动变为 detached。
-
通俗:卷的 attached 状态完全依赖 Pod 的使用,没 Pod 了就自然 detach。
针对不同 workload 类型停掉 Pods
页面按 Kubernetes 资源类型分类,提供具体操作(全用 kubectl edit 或 delete):
- Deployment 官方:kubectl edit deploy/<name> → 设置 .spec.replicas: 0。 通俗:把副本数改成 0,所有 Pods 就 shutdown 了,卷自动 detach。
- StatefulSet 官方:kubectl edit statefulset/<name> → 设置 .spec.replicas: 0。 通俗:同 Deployment,副本数归零(StatefulSet 会顺序 shutdown Pods)。
- DaemonSet 官方:kubectl edit ds/ → 在 pod template 加 nodeSelector:
spec:
template:
spec:
nodeSelector:
no-schedule: "true" # 一个不存在的标签,确保无节点匹配
通俗:DaemonSet 不能直接 replicas=0,所以加个假 nodeSelector,让它在所有节点都"调度失败",Pods 自动删掉。
- Pod(裸 Pod,非 controller 管理) 官方:kubectl delete pod/<name>。 通俗:直接删 Pod,没法暂停,只能删(删后卷自动 detach)。没有 controller 的 Pod 无法 suspend。
- CronJob 官方:kubectl edit cronjob/<name> → 设置 .spec.suspend: true。 额外:等待当前运行的 Job 完成,或手动删相关 Pods。 通俗:暂停未来调度;正在跑的得手动处理。
- Job(单次运行) 官方:建议等它自然完成;否则 kubectl delete job/<name>。 通俗:单跑任务最好让它跑完再删,避免中断。
- ReplicaSet 官方:kubectl edit replicaset/<name> → 设置 .spec.replicas: 0。
- ReplicationController(旧资源) 官方:kubectl edit rc/<name> → 设置 .spec.replicas: 0。
总结这一节:所有方法的核心都是"让 Pods 消失",这样卷才能自动 detach。选择对应 workload 类型的方法就行。
最后步骤
官方:
-
等待所有 Kubernetes 管理的卷完成 detach(查 Longhorn UI Volumes 页面,状态从 attached 变为 detached)。
-
在 Longhorn UI 手动 detach 剩余的卷(Operation → Detach)。
剩余卷来源 :这些是手动/UI 创建的卷(非动态供给),Kubernetes 管不着,所以得自己去 UI 点 Detach。
警告与注意事项
-
页面无明确严重警告
但隐含风险:
-
操作会中断业务(所有 Pods shutdown)。
-
建议在维护窗口操作,事后重建/恢复 workloads。
-
对于正在运行的 Job/CronJob,需要手动处理当前任务。
-
-
最佳实践
(隐含):
-
最简单方式:直接删 workloads,升级完再重建(适合测试或可中断环境)。
-
优雅方式:用 replicas=0 或 suspend,保持资源定义不变,事后改回来即可。
-
通俗:别在生产高峰期干这事,提前规划好回滚。
-
页面未涉及 单个卷的日常 detach (那通常自动)、faulted 卷的 salvage (在其他文档)或 force detach 等高级操作。
Longhorn 卷的 detach 完全依赖"停用 Pods",页面提供各种 Kubernetes workload 的停机方法(主要是 replicas=0 或 suspend),最后手动处理非 Kubernetes 卷------整个流程是为系统升级等全局维护设计的,确保所有卷安全 detached 而不直接操作卷本身。
ReadWriteMany (RWX) Volumes
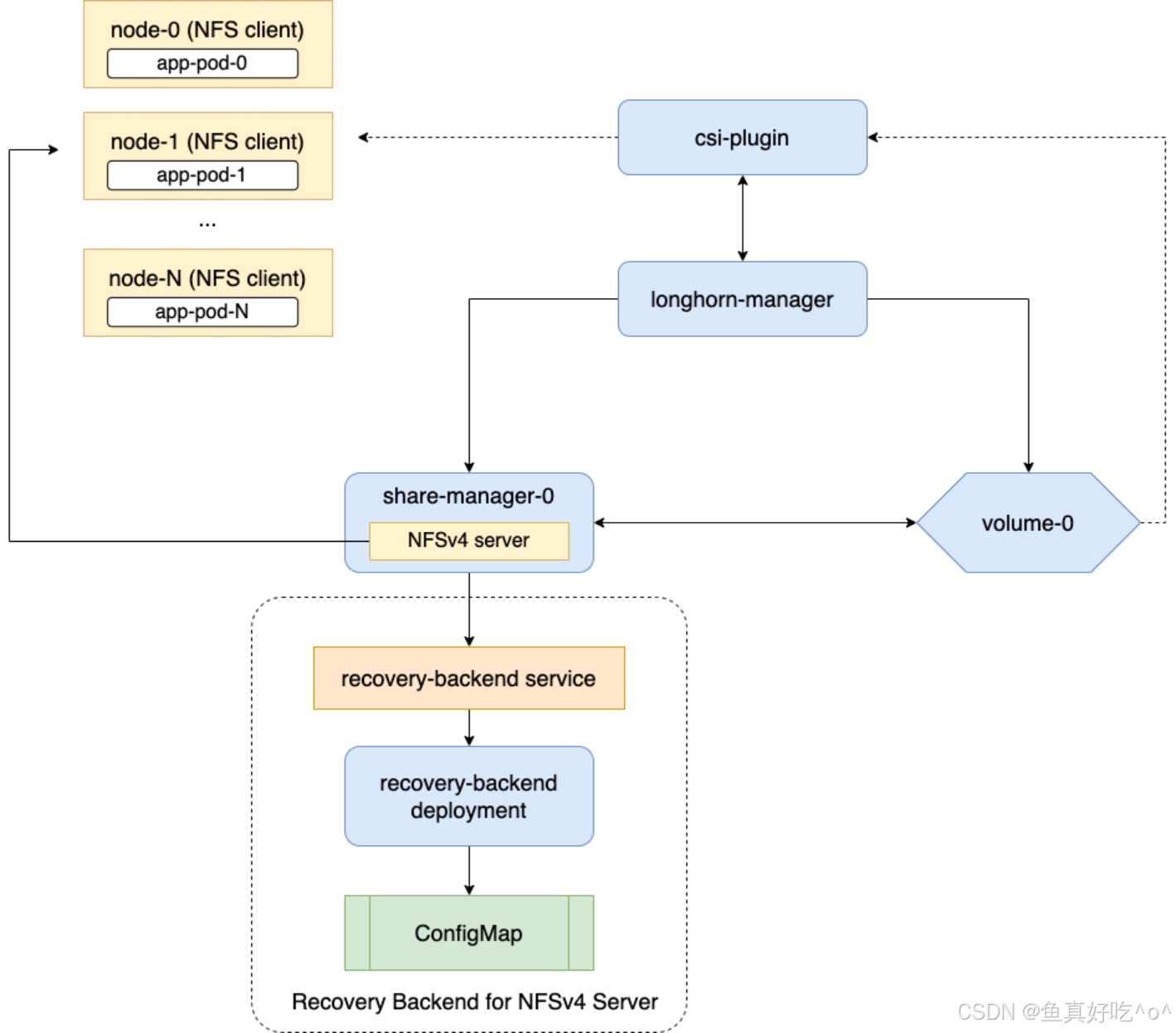
1.概述与支持
官方机制 :Longhorn 支持 ReadWriteMany (RWX) 卷,通过 share-manager pods 中的 NFSv4 servers 暴露普通 Longhorn 卷。每个活跃 RWX 卷自动创建:
-
share-manager-<volume-name> pod(在 longhorn-system namespace)。
-
对应的 Kubernetes Service 作为 NFS 端点。
简单说就是RWX 让多个 Pod 同时读写同一个卷,像网络共享盘。Longhorn 不直接块共享,而是用 NFS "桥接"普通卷,每个卷配一个专用 NFS 小服务器(pod)。
特殊行为:升级 Longhorn 后,如果 RWX 卷是 non-migratable(不可迁移,默认)且仍 attached,share-manager pod 的镜像更新会延迟,直到卷 detach 后重建 pod 才生效。
2.前提条件
必须满足,否则无法使用 RWX:
- NFSv4 客户端安装:每个客户端节点(worker node)必须有 NFSv4 客户端工具(如 /sbin/mount.nfs)。缺了会报错:"need a /sbin/mount.<type> helper program"。
bash
# 检查内核是否启用了支持:NFSv4
[root@k8s-master ~]# cat /boot/config-`uname -r`| grep CONFIG_NFS_V4
# 检查内核是否启用了支持:NFSv4.1
[root@k8s-master ~]# cat /boot/config-`uname -r`| grep CONFIG_NFS_V4_1
# 检查内核是否启用了支持:NFSv4.1
[root@k8s-master ~]# cat /boot/config-`uname -r`| grep CONFIG_NFS_V4_2
安装NFSv4客户端的命令因Linux发行版而异。
对于Debian和Ubuntu,请使用以下命令:
[root@k8s-master ~]# apt-get -y install nfs-common
对于带有 的 RHEL、CentOS 和 EKS,请使用以下命令:EKS Kubernetes Worker AMI with AmazonLinux2 image
[root@k8s-master ~]# yum install -y nfs-utils
对于SUSE/OpenSUSE,你可以通过以下方式安装NFSv4客户端:
[root@k8s-master ~]# zypper install -y nfs-client-
节点唯一 hostname :Kubernetes 集群中每个节点 hostname 必须唯一。用于 longhorn-nfs-recovery-backend 服务存储客户端信息,实现锁恢复(grace period)。
-
90 秒 grace period:share-manager pod 重启后,给客户端 90 秒 reclaim locks(锁恢复)时间。
通俗说:提前在所有节点装好 NFS 客户端;hostname 不能重复(避免锁恢复混乱)。
3.如何工作
-
Share Manager Pod:专用 pod,运行 NFSv4 server,导出卷。
-
NFS Server :默认用 NFSv4.1,挂载选项:softerr, timeo=600, retrans=5(软错误、重试)。
-
快速故障转移(Fast Failover):可选功能,将 grace period 从 90 秒减到 30 秒,通过直接心跳监控加速恢复。
-
DNS 依赖 :share-manager pod 用 Kubernetes DNS 通信 recovery backend。DNS 故障会导致卷创建/删除/恢复失败 → 强烈推荐 DNS 高可用。
通俗说:每个 RWX 卷有个"小 NFS 服务器" pod;pod 挂了有 90 秒(或 30 秒)缓冲让客户端恢复锁;整个系统靠 DNS 正常工作。
4.创建 RWX 卷
必须条件:
-
accessMode: ReadWriteMany
-
parameters.migratable: false(禁用迁移)
-
创建方式
-
动态供给:PVC 请求 ReadWriteMany → 自动创建 RWX 卷。
-
手动/UI 创建(如恢复、DR 卷):UI 中设置 access mode。
-
PV/PVC via UI:继承卷的 access mode。
-
修改 access mode:仅在卷未绑定 PVC 时可通过 UI 改。
-
自动更新:RWX PVC 使用卷时,卷 access mode 自动设为 RWX。
-
-
控制 share-manager pod 调度
(StorageClass 参数):
-
shareManagerNodeSelector:标签选择器(如 "key1:value1;key2:value2")。
-
allowedTopologies:转换 StorageClass 的 topology 为 affinity。
-
shareManagerTolerations:容忍污点(如 "nodetype=storage:NoSchedule")。
-
通俗说:创建时强制非迁移 + RWX 模式;用 StorageClass 参数精细控制 NFS pod 落在哪些节点(数据本地性、合规)。
bash
[root@k8s-master ~/longhorn-sc]# cat rwx-pvc-pod.yaml
# rwx-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
allowVolumeExpansion: true
parameters:
numberOfReplicas: "3"
migratable: "false" # RWX模式 必须 false
accessMode: "ReadWriteMany" # 可选,PVC 也会覆盖
nfsOptions: "vers=4.1,softerr,timeo=600,retrans=5"
---
# rwx-demo.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-rwx-pvc
namespace: default
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: longhorn-rwx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: rwx-test
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: rwx-test
template:
metadata:
labels:
app: rwx-test
spec:
containers:
- name: myweb
image: myweb:v1
volumeMounts:
- mountPath: /data
name: shared
volumes:
- name: shared
persistentVolumeClaim:
claimName: longhorn-rwx-pvc
bash
[root@k8s-master ~/longhorn-sc]# kubectl get po -l app=rwx-test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rwx-test-5b88955975-57z46 1/1 Running 0 9m43s 10.200.169.154 k8s-node2 <none> <none>
rwx-test-5b88955975-6lzmj 1/1 Running 0 9m41s 10.200.235.231 k8s-master <none> <none>
rwx-test-5b88955975-nw2ff 1/1 Running 0 9m44s 10.200.36.74 k8s-node1 <none> <none>
[root@k8s-master ~/longhorn-sc]# kubectl get svc -n longhorn-system -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
longhorn-admission-webhook ClusterIP 10.96.95.50 <none> 9502/TCP 23h longhorn.io/admission-webhook=longhorn-admission-webhook
longhorn-backend ClusterIP 10.103.228.115 <none> 9500/TCP 23h app=longhorn-manager
longhorn-frontend NodePort 10.106.54.227 <none> 80:30179/TCP 23h app=longhorn-ui
longhorn-recovery-backend ClusterIP 10.98.22.121 <none> 9503/TCP 23h longhorn.io/recovery-backend=longhorn-recovery-backend
pvc-770ce331-bcca-4fb7-9e69-10c9b54c22bc ClusterIP 10.110.180.221 <none> 2049/TCP 16m longhorn.io/managed-by=longhorn-manager,longhorn.io/share-manager=pvc-770ce331-bcca-4fb7-9e69-10c9b54c22bc验证RWX特性
bash
[root@k8s-master ~/longhorn-sc]# kubectl exec -it rwx-test-5b88955975-57z46 -- sh
/ # cd /data/
/data # ls -l
total 20
drwx------ 2 root root 16384 Jan 30 06:27 lost+found
-rw-r--r-- 1 root root 2610 Jan 30 06:32 test.txt
/data # echo "我是第一个进入的Pod,我是$HOSTNAME" > me.txt
/data # ls -l
total 24
drwx------ 2 root root 16384 Jan 30 06:27 lost+found
-rw-r--r-- 1 root root 60 Jan 30 06:35 me.txt
-rw-r--r-- 1 root root 2610 Jan 30 06:32 test.txt
/data # cat me.txt
我是第一个进入的Pod,我是rwx-test-5b88955975-57z46
/data # 其他Pod必须也能看到
bash
[root@k8s-master ~/longhorn-sc]# kubectl exec -it rwx-test-5b88955975-6lzmj -- sh
/ # cd /data/
/data # ls -l
total 24
drwx------ 2 root root 16384 Jan 30 06:27 lost+found
-rw-r--r-- 1 root root 60 Jan 30 06:35 me.txt
-rw-r--r-- 1 root root 2610 Jan 30 06:32 test.txt
/data # cat me.txt
我是第一个进入的Pod,我是rwx-test-5b88955975-57z46
/data # echo "我是第二个进入的Pod,我是$HOSTNAME" >> me.txt
/data # cat me.txt
我是第一个进入的Pod,我是rwx-test-5b88955975-57z46
我是第二个进入的Pod,我是rwx-test-5b88955975-6lzmj
/data # exit第三个Pod我们就看一下挂载情况吧,不循环演示文件了
bash
[root@k8s-master ~/longhorn-sc]# kubectl exec -it rwx-test-5b88955975-nw2ff -- sh
/ # df -Th
Filesystem Type Size Used Available Use% Mounted on
overlay overlay 47.9G 14.3G 31.2G 31% /
tmpfs tmpfs 64.0M 0 64.0M 0% /dev
10.110.180.221:/pvc-770ce331-bcca-4fb7-9e69-10c9b54c22bc
nfs4 9.7G 0 9.7G 0% /data5.卸载与移除
-
必须从所有客户端正确 unmount 后才能 detach。
-
卷 detach/删除时,share-manager pod 自动终止。
通俗说:先 umount 所有地方,再 detach;硬挂载可能卡。
Longhorn RWX 通过 NFSv4 + share-manager pod 实现多节点共享,创建简单但有前提(NFS 客户端、唯一 hostname);性能/一致性有限制,适合低并发共享文件场景------用时优先 soft mount、DNS HA,并理解 90 秒 grace period 的锁恢复风险。
定期清理(TRIM)文件系统
Longhorn 像"囤积狂",删了东西不扔(不 TRIM),快照是"备份箱"占满历史垃圾,重写还可能开新箱子------不主动清理,空间容易爆。
bash
# 简单实际例子(用小数字,假设 1 个副本简化)
名义大小:10 GB(房间上限)。
你写满了 10 GB 数据,然后删掉重写(常见日志场景)。
由于不 TRIM + 重写不复用,每个"版本"都接近 10 GB。
场景 1:你取了 2 个快照(总链:当前 head + 2 个历史 = 3 个)
当前实际占用:大约 3 × 10 GB = 30 GB(每个快照一份完整历史)。
想删最老快照:
系统先复制剩余链(head + 1 个快照 = 2 个)到临时新链 → 需要额外 20 GB 临时空间。
复制完,再扔旧链 → 回收 10 GB,实际降到 20 GB。
总需要空间:30 GB(当前) + 20 GB(临时) = 50 GB。
公式简化:(快照数 2 + 1 当前 + 1 临时) × 10 GB ≈ 40 GB(公式是保守估算)。
如果你只预留 35 GB(觉得"10 GB 卷 + 点余量"够了):
删除快照时,临时需要 20 GB → 没地儿 → 操作失败!
结果:空间永远 30 GB 降不下来 → 下次再取快照就爆 → 卷故障。安全但需谨慎:
-
TRIM 是标准操作(Linux fstrim),对数据无害,只释放已删块。
-
但如果卷正在高负载写,TRIM 可能短暂影响性能(IO 暂停)。
-
某些旧文件系统或配置不支持 TRIM(会失败)。
所以为了避免这种情况,我们对于快照和TRIM频率定期管理。
方法 A --- Longhorn UI
-
进入 Recurring Jobs 页面
-
点击 Create Recurring Job
-
填写 cron、task、retain 等参数
-
在卷详情页将任务关联到卷(或 StorageClass)
Longhorn UI 会自动在后台创建 RecurringJob CR 并赋予卷标签。
方法 B --- 使用 YAML
bash
apiVersion: longhorn.io/v1beta2
kind: RecurringJob
metadata:
name: snapshot-1
namespace: longhorn-system
spec:
cron: "0 3 * * *"
task: "snapshot"
groups:
- default
- group1
retain: 1
concurrency: 2
labels:
label/1: a
label/2: b
bash
apiVersion: longhorn.io/v1beta2
kind: RecurringJob
metadata:
name: filesystem-trim-daily # 任务名见名知意,方便管理
namespace: longhorn-system
spec:
cron: "0 2 * * *" # 执行频率:每天凌晨2点(避开业务高峰,推荐)
task: "filesystem-trim" # 核心:任务类型改为文件系统修剪
groups:
- default # 分组,方便批量关联到多个卷
concurrency: 1 # 同时执行1个trim任务即可,无需多并发
# 以下2个参数对trim无效,Longhorn会自动忽略,可删可留
retain: 1
labels:
trim: daily-
apiVersion,kind--- CRD 类型(RecurringJob 自定义资源) -
metadata.name--- 定时任务名称,不可重复(≤40 字符) -
spec.cron--- CRON 表达式:决定任务的执行时间(和普通 Linux cron 语法兼容) -
spec.task--- 要执行的任务类型,这里是snapshot(定期创建快照) -
spec.groups--- 任务所属组,可用于批量关联多个卷(如default,group1) -
spec.retain--- 保留数量:这个任务最终会保留 1 个快照(旧的自动清理) -
spec.concurrency--- 同时允许几个任务并行执行,示例是2(官方写法) -
spec.labels--- 创建快照时自动附加的用户标签(Key/Value 键值对)
Volume Expansion扩容
Longhorn 的卷扩容分两步:先扩展块设备(block device) ,然后 扩展文件系统(filesystem);自 v1.4.0 起支持在线扩容(attached 卷可在读写或 rebuild 时直接扩容)。
扩容的两种官方方式
通过 PVC(推荐)
修改对应 PVC 的 spec.resources.requests.storage,Kubernetes CSI 流程会触发 Longhorn 扩容并且保持 PVC/PV 一致。
官方给出的 PVC 示例结构(页面示例片段,表示要修改 spec.resources.requests.storage):
bash
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-simple-pvc
namespace: default
spec:
resources:
requests:
storage: 1Gi # 扩大就行
storageClassName: longhorn优点:PVC/PV 会自动更新,一致性由 Kubernetes/CSI 保证。
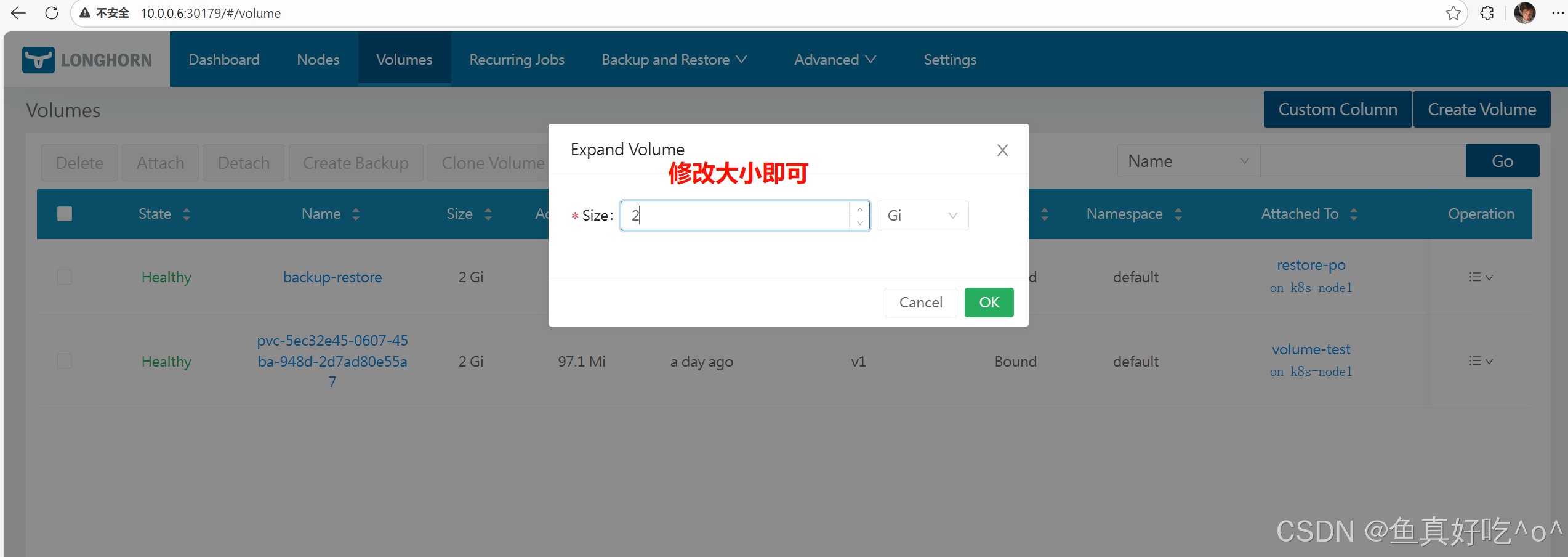
通过 Longhorn UI(手工)
在 Longhorn UI 的卷详情页点击 Expand。适合临时或 UI 操作场景。
Longhorn 会尝试自动扩展文件系统,但仅在满足所有条件时:
-
扩展后的大小必须大于当前文件系统大小;
-
卷内必须存在 Linux 文件系统;
-
支持的文件系统类型:ext4 或 xfs;
-
扩展大小必须低于该文件系统允许的最大文件/卷大小(例如 ext4 的 16TiB 限制);
-
卷需要在 block device frontend 下(即是块设备前端)。
Longhorn 把这个卷"以什么形式"提供给节点和 Pod 使用
官方定义里,常见的 Frontend 有两类(你在 UI 里能看到):
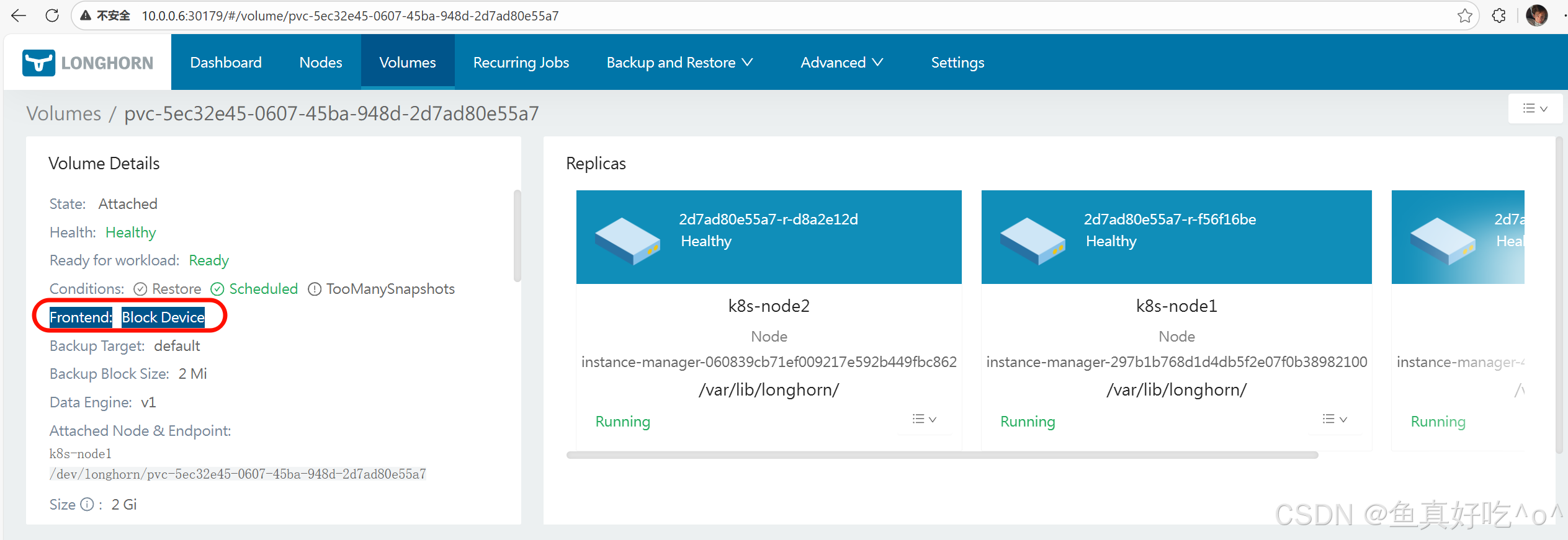
| Frontend 类型 | 官方名称 | 对操作系统的表现 |
|---|---|---|
| Block Device Frontend | blockdev |
/dev/longhorn/<volume-name> |
| NFS Frontend(RWX) | nfs |
通过 NFS Server 挂载 |
不是 block device frontend 的情况
❌ NFS Frontend(RWX 卷)
当卷是 RWX(ReadWriteMany) 时:
-
Longhorn 会启动一个 NFS Server
-
Pod 看到的是:
nfs://<ip>:/export/xxx -
对 Pod 来说:
-
这是网络文件系统
-
不是块设备
-
-
Longhorn 无法在 NFS 层自动扩展文件系统
👉 所以官方明确要求:
文件系统自动扩展 只适用于 block device frontend
volume-conditions卷状态
| 条件名称 | 官方含义 | UI 上通常表现 |
|---|---|---|
| Scheduled | 是否 Replica 都调度成功 | 展示是否健康调度 |
| TooManySnapshots | 快照数量过多 | 可能显示警告 |
| Restore | 正在恢复备份 | 显示正在 Restore 中 |
| WaitForBackingImage | 正在等待 backing image | 卷 Pending / 不可用 |
| OfflineRebuildingInProgress | 离线重建进行中 | 可能看到 Rebuild 进度 |
四、备份与恢复
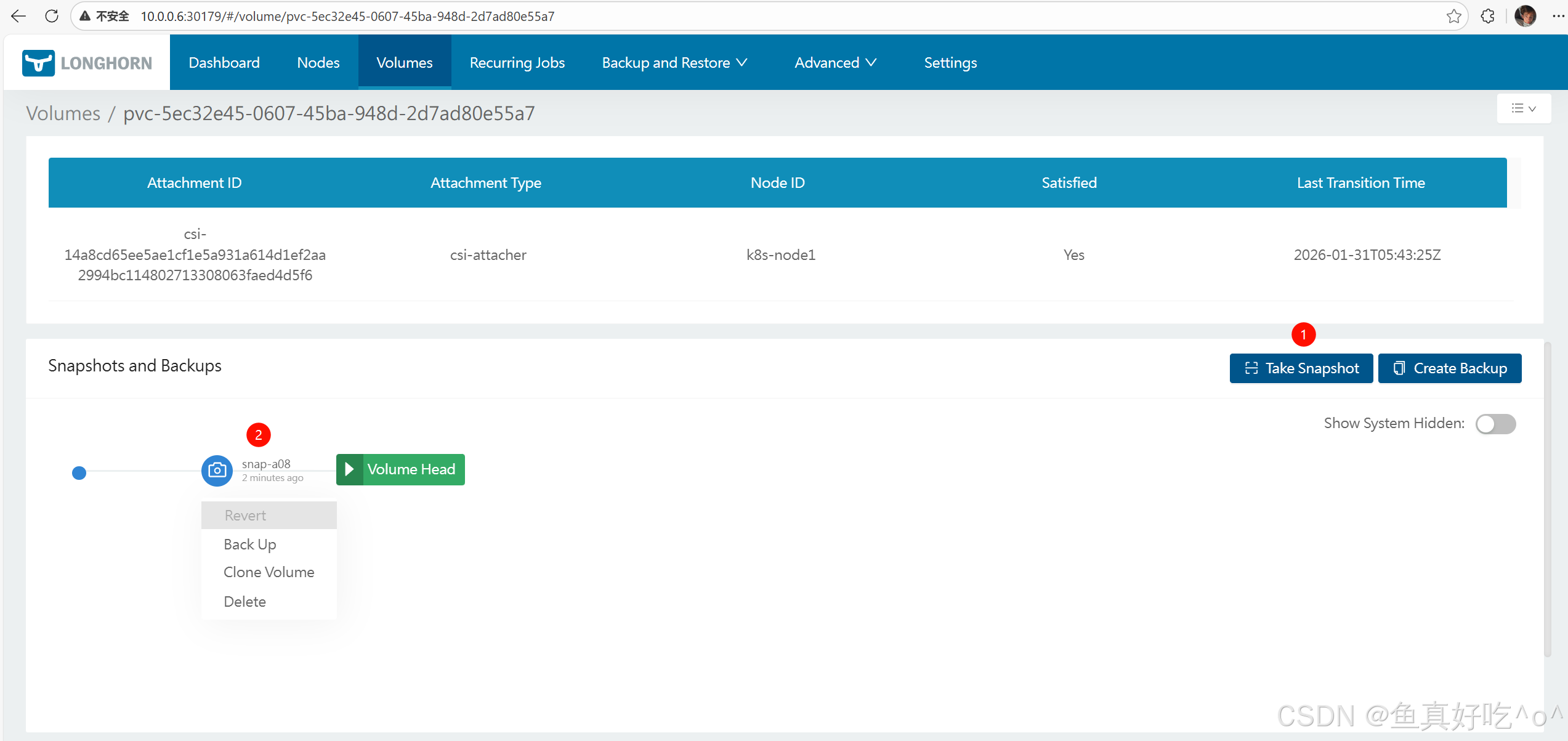
创建快照
快照(Snapshot)是 Longhorn 卷在某一时间点的数据状态 。 你可以通过 Longhorn UI 或 Snapshot Custom Resource(CR) 来创建、列出、删除快照。
快照本身是历史版本的捕获,可以用于日后恢复、备份、回滚等操作(备份单独有文档)。创建快照不会破坏当前卷的读写。
一、如何通过 UI 创建快照(官方步骤)
这是官方示例流程,你可以按顺序做:
-
在 Longhorn UI 顶部导航栏点击 Volumes。
-
选择你想创建快照的 Volume。
-
在该 Volume 的详情页点击 Take Snapshot 按钮。
执行成功后:
-
快照会出现在该卷的快照列表中
-
该快照位置显示在 Volume Head 之前(说明这是老版本)
二、如何通过 CR(Kubernetes YAML)创建快照(官方示例)
Longhorn 使用自己的 Snapshot CRD(Group: longhorn.io, Kind: Snapshot) 来管理快照,不是 Kubernetes 原生 PVC 快照。
bash
apiVersion: longhorn.io/v1beta2
kind: Snapshot
metadata:
name: longhorn-test-snapshot
namespace: longhorn-system
spec:
volume: pvc-840804d8-6f11-49fd-afae-54bc5be639de # 把这个换成你的卷名
createSnapshot: true删除快照
bash
kubectl delete snapshot.longhorn.io longhorn-test-snapshot \
-n longhorn-system快照空间管理
通过全局设置和卷级设置限制每个卷的最大快照数量(Max Count)和总快照大小(Max Aggregate Size)。
当达到限制时,新快照创建会阻塞,必须手动删除旧快照才能继续;限制不包括已删除快照、backing images 和 volume head;最小需保留 2 个快照(系统功能要求)。
一句话:这是主动"上限控制"工具,配合之前学的 prune/coalesce(被动回收),双管齐下管理快照空间------预先设限,避免空间危机。
全局设置(Global Settings,在 Longhorn UI Setting 页面)

Snapshot Max Count(snapshot-max-count):
Snapshot Max Count 是 Longhorn(v1.6.0+)的一个快照数量上限设置,用于限制每个卷同时存在的活跃快照最大数量(不包括 volume head、已标记删除的快照和 backing images)。
-
范围:2--250(最小 2,因为系统功能如重建需要至少 2 个)。
-
默认:250。
-
作用:对新创建卷生效(无卷级自定义时用这个)。
-
重要 :修改全局设置不影响已有卷(已有卷保持旧规则)。
通俗说:集群级"默认上限",只管新生卷;老卷不受影响。
卷级设置(Volume-Specific Settings,在卷详情页面配置)
Snapshot Max Count(SnapshotMaxCount):
-
值:0(默认,用全局设置)或 2--250。
-
0 = 禁用卷级限制,用全局。
Snapshot Max Size(SnapshotMaxSize):
-
值:0(默认,禁用大小限制)或
> 2 × Volume.Spec.Size
(卷名义大小)。
- 最小必须 > 2x,因为至少需支持 2 个快照(系统要求)。
-
自动调整:如果卷扩容(expand),且当前 Max Size < 新卷大小的 2x,系统自动上调到 2x 新大小(防止限制太严)。
通俗说:每个卷可以自定义"快照上限"和"快照总空间上限"。大小限制像"快照专用仓库容量",必须预留至少 2 倍卷大小的仓库(给最小快照用)。
定期快照
通过 CRON 表达式定义调度时间,支持多种任务类型(snapshot、backup、filesystem-trim 等);配置方式灵活(全局 default、卷级 label、PVC 级、StorageClass 级);只在有新数据时才创建(避免空操作);关键字段包括 retain(保留数)、concurrency(并发数)。
是 Longhorn 的"定时器"功能,让快照/备份/清理/TRIM 自动运行,生产必备,避免手动操作。
1.概述
官方机制 :Recurring jobs 是独立的定时任务或任务组,使用 CRON 表达式 调度自动化创建快照/备份。 支持任务类型:snapshot、backup、filesystem-trim 等。 智能优化 :只有卷有新数据(自上次操作以来)时才创建新快照/备份,避免空/冗余操作。
通俗说:像手机的"定时提醒"------每隔一段时间自动拍快照或备份,但如果数据没变,就不浪费空间拍空照片。
任务类型(task)(完整列表,不要遗漏):
-
snapshot:定时创建快照(先清理旧的)。
-
snapshot-force-create:强制创建快照(不清理)。
-
backup:定时创建快照 + 备份(先清理旧快照)。
-
backup-force-create:强制创建快照 + 备份。
-
snapshot-cleanup:定时清理可移除的快照和系统快照(retain 被忽略,强制为 0)。
-
snapshot-delete:定时删除超出保留数的快照(retain 独立计算)。
-
filesystem-trim:定时 TRIM 文件系统回收空间。
2.配置方式
全局/默认(Global/Default) :把任务加到 default group,所有无自定义任务的卷自动继承。
卷级(Per-Volume):通过 UI(Volume 详情页)或 kubectl label 给卷打标签(recurring-job-group.longhorn.io 或 recurring-job.longhorn.io)。
PVC 级 :先打标签 recurring-job.longhorn.io/source=enabled,然后 PVC 标签会同步并覆盖卷标签(优先级最高)。
StorageClass 级:在 parameters 加 recurringJobSelector(JSON 数组),自动应用到用这个 SC 创建的所有卷。
通俗说:配置像"继承链"------StorageClass 给大批量默认,PVC/卷级精细覆盖,全局 default 兜底。
优先级:PVC 标签 > Volume 标签 > StorageClass > Global default。
限制 :定时任务默认只在卷 attached 时运行(可通过设置 allow-recurring-job-while-volume-detached 启用 detached 时运行)。
3.CRON 表达式语法
和 Linux cron 一样,灵活定义"每天凌晨 2 点""每周一 0 点"等。
4.官方案例
示例 1:RecurringJob YAML(核心 CRD 示例)
bash
apiVersion: longhorn.io/v1beta2
kind: RecurringJob
metadata:
name: snapshot-1
namespace: longhorn-system
spec:
cron: "* * * * *"
task: "snapshot"
groups:
- default
- group1
retain: 1
concurrency: 2
labels:
label/1: a
label/2: b-
apiVersion/kind:定义 Longhorn 的 RecurringJob 资源。
-
metadata.name:任务名 snapshot-1(唯一)。
-
spec.cron: "* * * * *":每分钟运行一次(测试用;生产别这么频)。
-
spec.task: "snapshot":任务类型------定时拍快照(有新数据才拍)。
-
spec.groups:属于 default(全局兜底)和 group1 组。
-
spec.retain: 1:只保留 1 个快照(旧的自动删)。
-
spec.concurrency: 2:允许 2 个此任务并发跑(防积压)。
-
spec.labels:创建的快照带这些标签(方便筛选)。
快照这里就不展开讲了,因为很好理解的快照的概念。
快照恢复浅谈
拍摄快照
如果要恢复还需要分离卷,停止一会业务之后即可恢复。这个我们在Volumes哪里介绍过。当然你也可以通过快照去克隆一个新volume出来然后挂载使用,生产环境快照还是很常用的。
卷备份与恢复
备份目标是一个端点,用于存储卷备份;从 v1.8.0 开始支持多个备份存储;支持类型包括 S3-compatible(推荐,AWS S3/GCP/MinIO/Azure Blob)和 NFS/SMB/CIFS;配置方式通过 Longhorn UI(Backup and Restore > Backup Targets)或直接编辑 ConfigMap/Secret;必须创建对应 Kubernetes Secret 存储凭证;强烈推荐 S3(可靠、无需挂载);禁止在备份存储侧设置 retention policy(Longhorn 自己管理生命周期)。
1.备份目标概述(Overview of Backup Target)
官方概念 :Backup target 是访问 backupstore 的端点;backupstore 是存储 Longhorn 卷备份的服务器。 从 v1.8.0+ 支持多个备份存储 (多目标)。 推荐:先设置默认备份目标,再创建新目标;优先用对象存储(如 S3)------更可靠、无需挂载/卸载(避免 failover/升级问题)。
通俗说:备份目标就像"云硬盘位置"------告诉 Longhorn "备份放哪儿"。S3 最稳(像 AWS 云桶),NFS/SMB 像网络共享盘(但麻烦点)。
支持类型(不要遗漏):
-
S3-compatible:AWS S3、GCP Cloud Storage、MinIO、Azure Blob Storage(推荐)。
-
NFS。
-
SMB/CIFS。
2.配置方式(Configuration Methods)
-
主要方式 :Longhorn UI → Backup and Restore > Backup Targets → 设置 URL + Credential Secret。
-
高级方式
-
Helm values.yaml(安装/升级时)。
-
Kubernetes ConfigMap longhorn-default-resource(直接编辑默认设置)。
-
-
通俗说:UI 最简单(填 URL 和 Secret);高级用 YAML/ConfigMap 适合自动化。
3. 凭证要求(Required Credentials)
-
通用:大多数类型需 Kubernetes Secret(namespace: longhorn-system)存储凭证。
-
S3-compatible
(AWS/GCP/MinIO):
-
Secret 键:AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY;可选代理/端点。
-
支持 AWS STS AssumeRole(临时凭证)。
-
-
Azure Blob:AZBLOB_ACCOUNT_NAME、AZBLOB_ACCOUNT_KEY;可选端点/证书。
-
SMB/CIFS:CIFS_USERNAME、CIFS_PASSWORD。
-
NFS:无需凭证(靠网络访问 + NFSv4 支持)。
通俗说:凭证全放 Secret 里(安全),UI 选 Secret 名就行。
本地测试 MinIO 备份案例
1.部署MinIO
bash
kubectl create -f https://raw.githubusercontent.com/longhorn/longhorn/v1.10.1/deploy/backupstores/minio-backupstore.yaml
bash
[root@k8s-master ~]# kubectl get po,svc
NAME READY STATUS RESTARTS AGE
pod/longhorn-test-minio-54d5c878fb-mzt6r 1/1 Running 0 26s
pod/volume-test 1/1 Running 2 (43m ago) 23h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 88d
service/minio-service ClusterIP 10.98.246.176 <none> 9000/TCP 26s进入Longhorn的UI。点击**"备份和恢复/备份目标"**,创建或编辑备份目标。
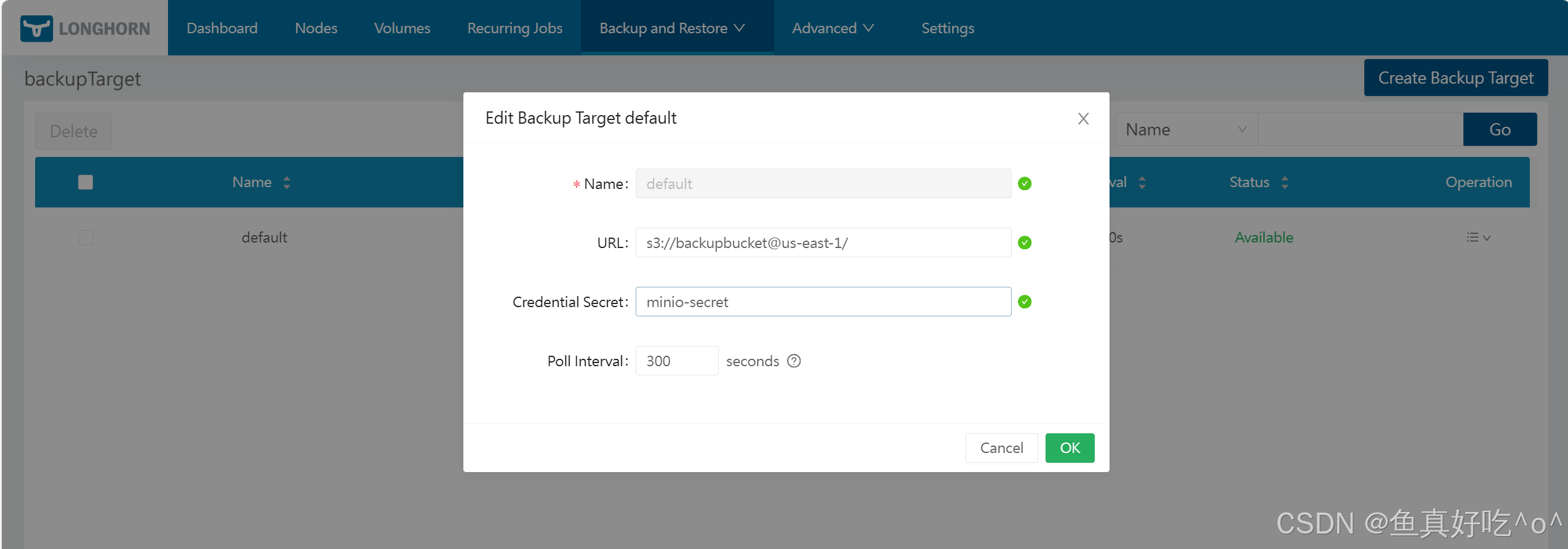
将网址设置为:
s3://backupbucket@us-east-1/
将凭证秘密设置为:
minio-secret
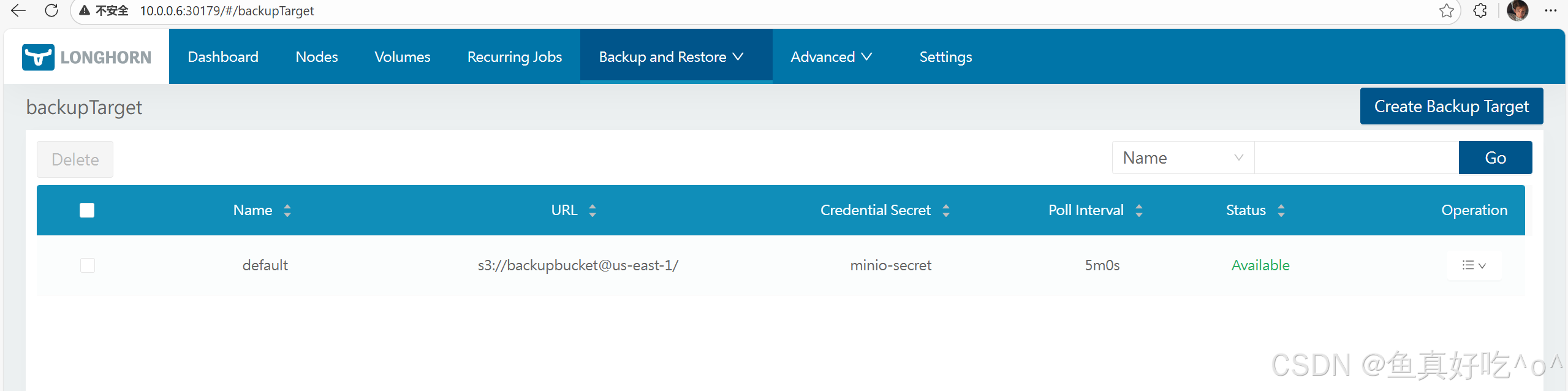
备份目标配置核心是UI 填 URL + Secret(凭证放 Secret);首选 S3(可靠),测试 MinIO;所有类型示例完整------实际用时,先创 Secret,再 UI 设置,禁备份存储侧 retention!生产必配 S3 + 多备份存储。
如果出现了报错,请检查BackupTarget资源配置
2.创建备份
Longhorn 的 Backup 是将某个 Volume 的某个 Snapshot 的数据上传到远端 Backupstore(通过 Backup Target 指定)。
Longhorn 支持 增量备份(默认)和 全量备份(从 v1.7.0 起),并在 Backup CR 的状态中记录上传的数据量等指标。
| 官方术语 | 定义 | 通俗理解 |
|---|---|---|
| Backup | Longhorn 备份对象(Custom Resource) | 把 Snapshot 的数据保存到远端 |
| Snapshot | 卷在某一时间点的数据视图 | 备份的基础和数据源 |
| Backupstore | 远端存储,用于存放备份 | 比如 S3、NFS、Azure Blob 等 |
| Backup Target | 用于访问 Backupstore 的 endpoint | 指向存储备份的外部位置 |
| backupMode: incremental | 增量模式,只上传变化的数据块 | 默认模式,节省流量/时间 |
| backupMode: full | 全量模式,上传全部数据块并覆盖 | 在某些情况下更安全可靠 |
| status.newlyUploadDataSize | 本次上传到 backupstore 的新数据大小 | 观察增量备份效率 |
| status.reUploadDataSize | 全量备份时覆盖的远端数据块大小 | 看覆盖的范围/成本 |
先在已挂载的卷总写入数据
bash
[root@k8s-master ~]# cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: lh-backup-writer
spec:
containers:
- name: writer
image: myweb:v1
command: ["sh", "-c", "sleep 3600"]
volumeMounts:
- mountPath: /data
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: lh-backup-test-pvc
/ # echo "i am $HOSTNAME,now is `date`" >> /data/mess.txt
/ # cat /data/mess.txt
i am lh-backup-writer,now is
i am lh-backup-writer,now is Sat Jan 31 02:25:00 UTC 2026
i am lh-backup-writer,now is Sat Jan 31 02:25:09 UTC 2026然后创建备份
官方 UI 操作(标准案例)
-
在 Longhorn UI 打开 Volumes 页面
-
选择要备份的 Volume
-
点击 Create Backup
-
(可选)填写 Labels
-
点击 OK → Backup 创建成功
-
在 Backup 页面可以看到该条备份记录
👉 UI 是官方推荐的可视化操作方法。
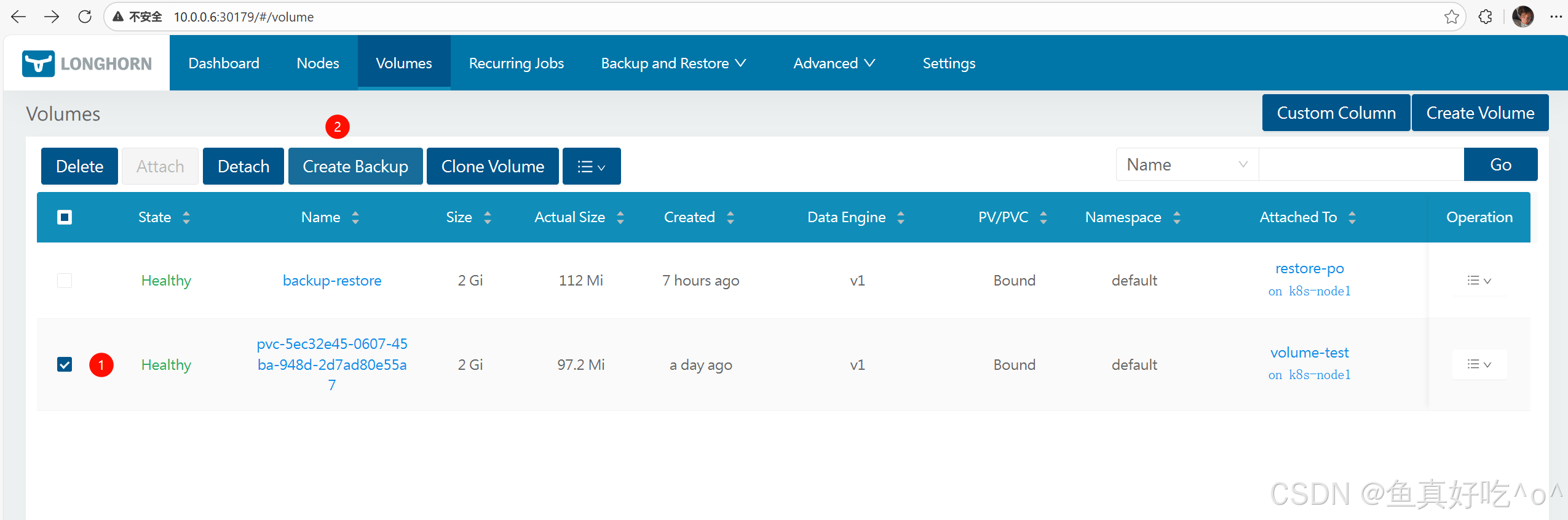
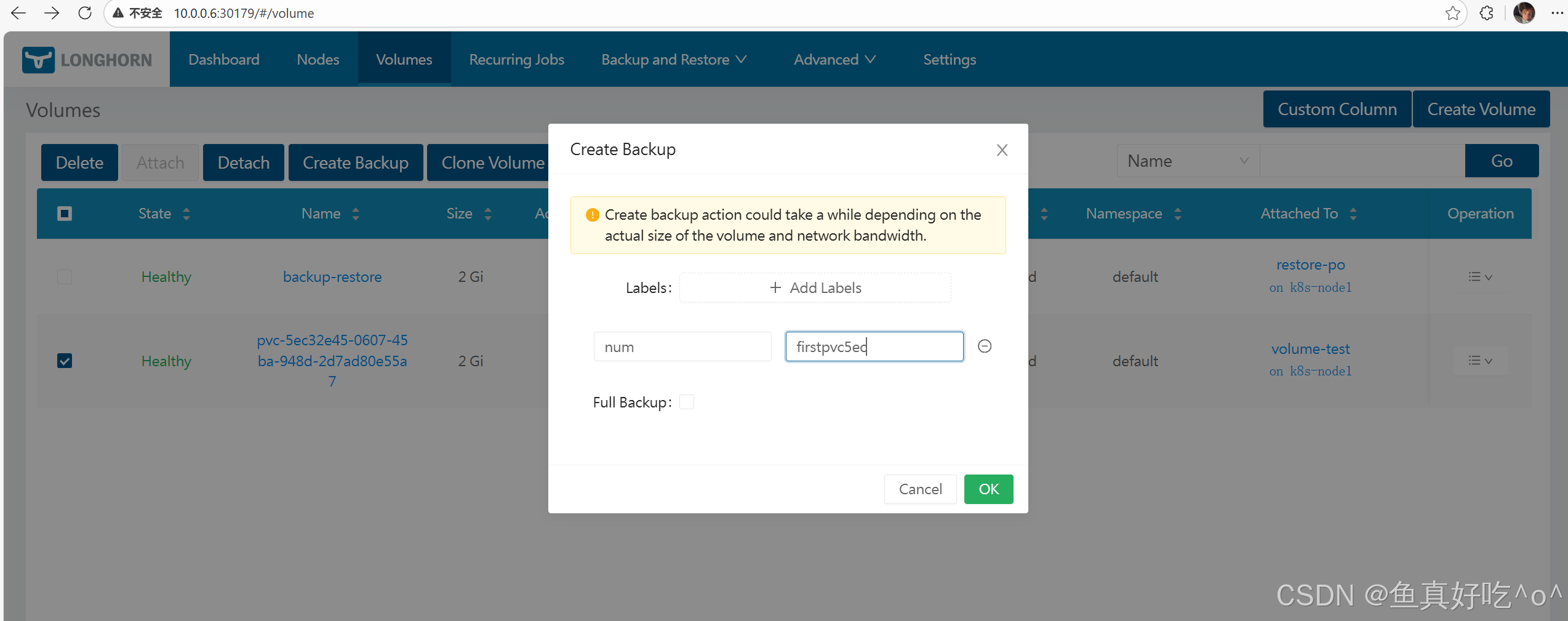
说明:
这个full backup不勾选默认就是增量备份,但是如果这个卷是第一次备份,勾选不勾选都是全量备份。
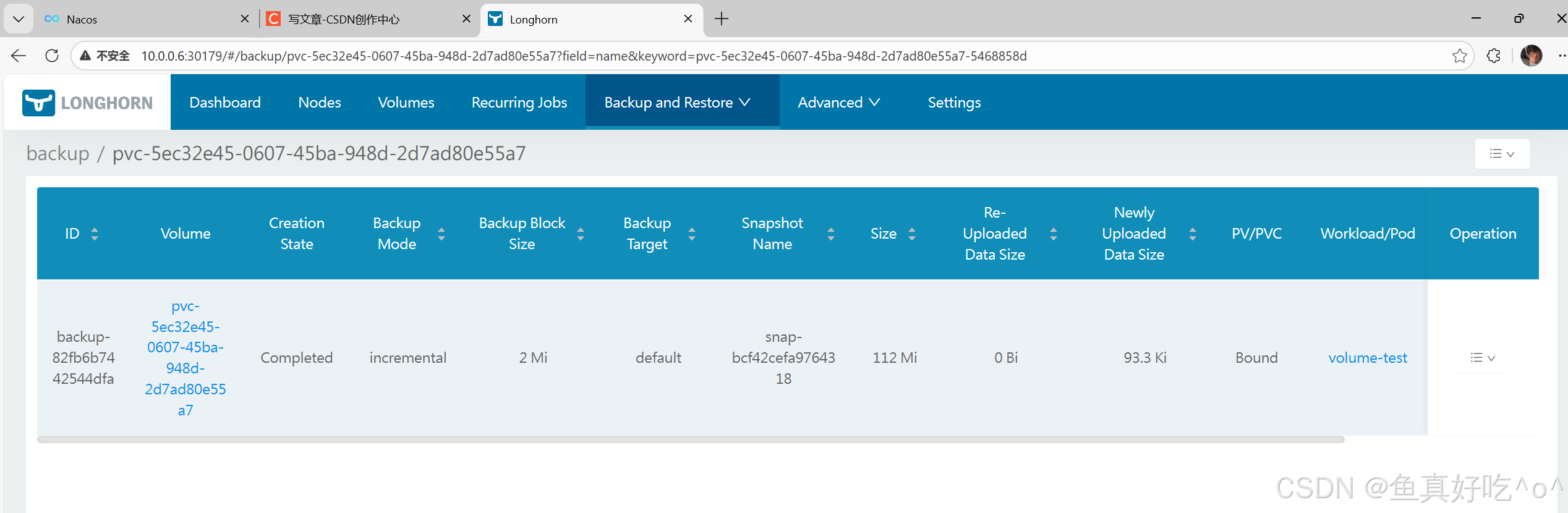
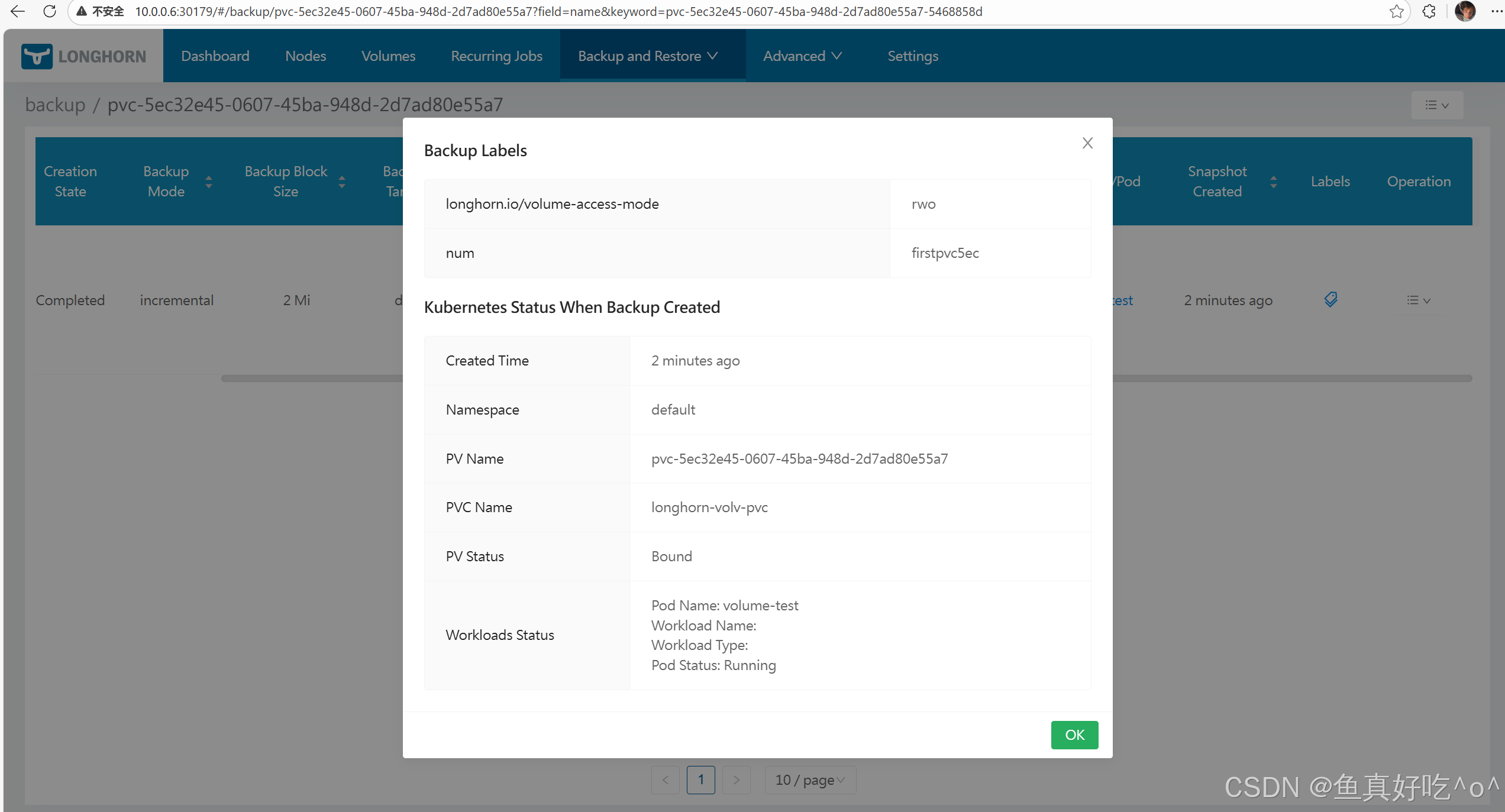
当然有UI基本就有yaml格式
3.从备份恢复
接备份上文,我们先删除Pod与破坏卷
bash
[root@k8s-master ~]# kubectl delete -f pod.yaml && rm -rf /var/lib/longhorn/replicas/pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7-055eaf2f/ 要恢复备份数据,
-
导航到**备份。**菜单
-
选择你想恢复的备份,然后点击**"恢复最新备份"。**
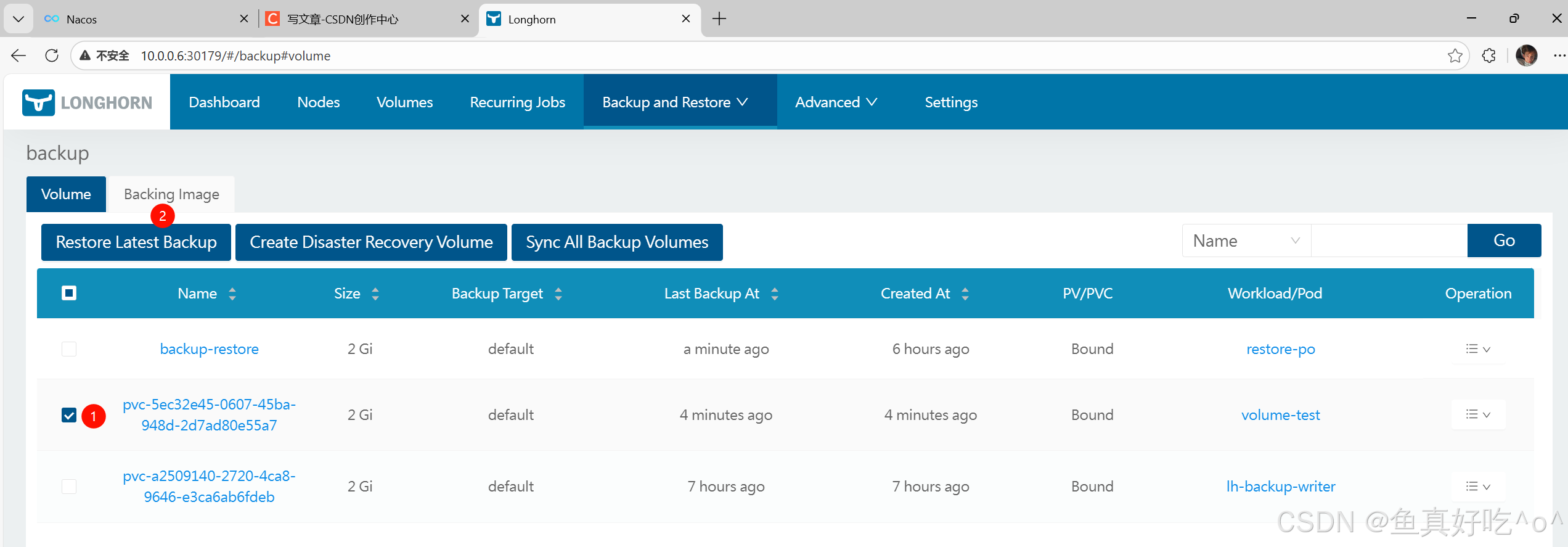
-
在名称字段中,选择你想要恢复的卷。
-
点击确定。
然后你可以在从备份恢复一个卷后,从该卷创建PV/PVC。这里你可以指定,或者保持空置,使用从备份体积PVC继承的。它们应该已经在集群里,以防止进一步的问题。storageClassName``storageClassName``StorageClass
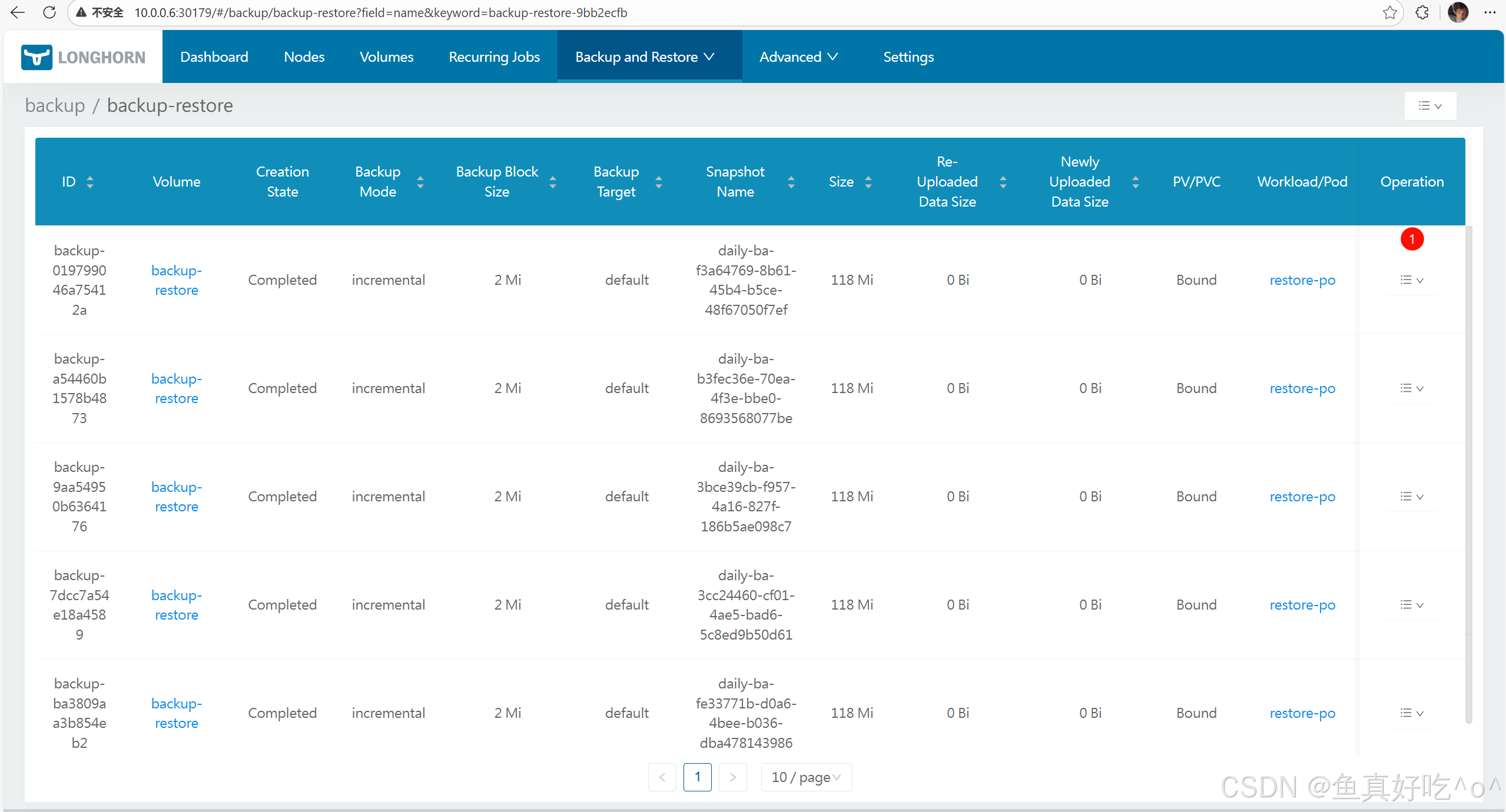
假如一个卷你备份了多个增量的备份,你可以点击进去,然后点击restore
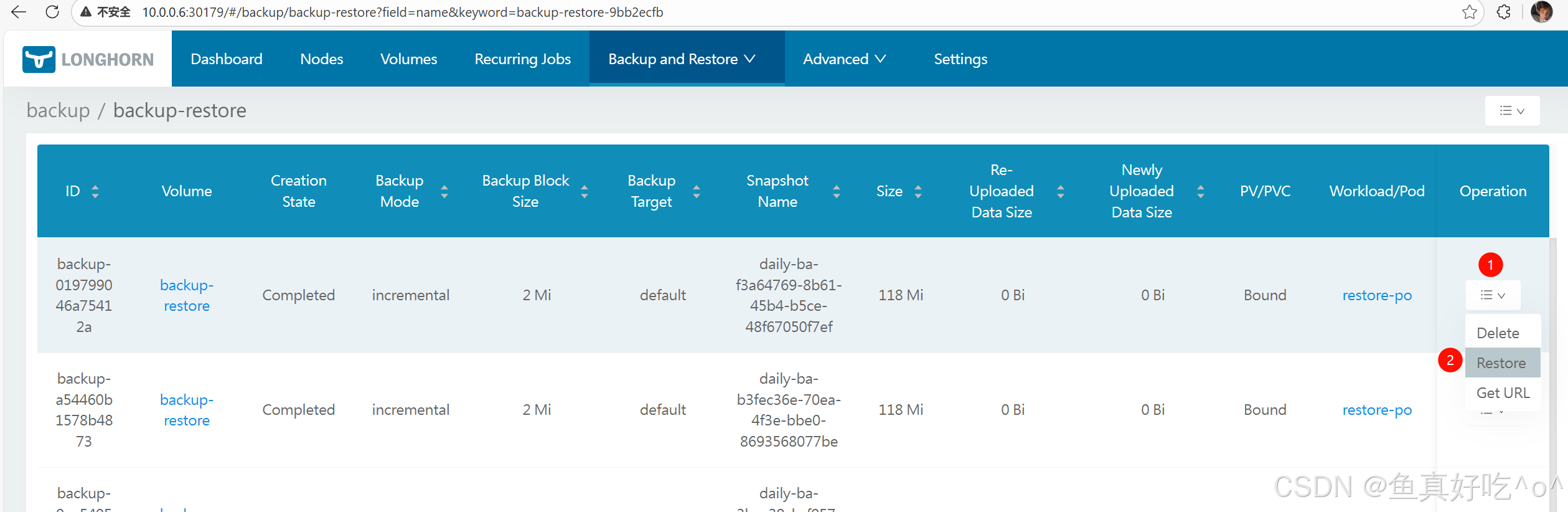
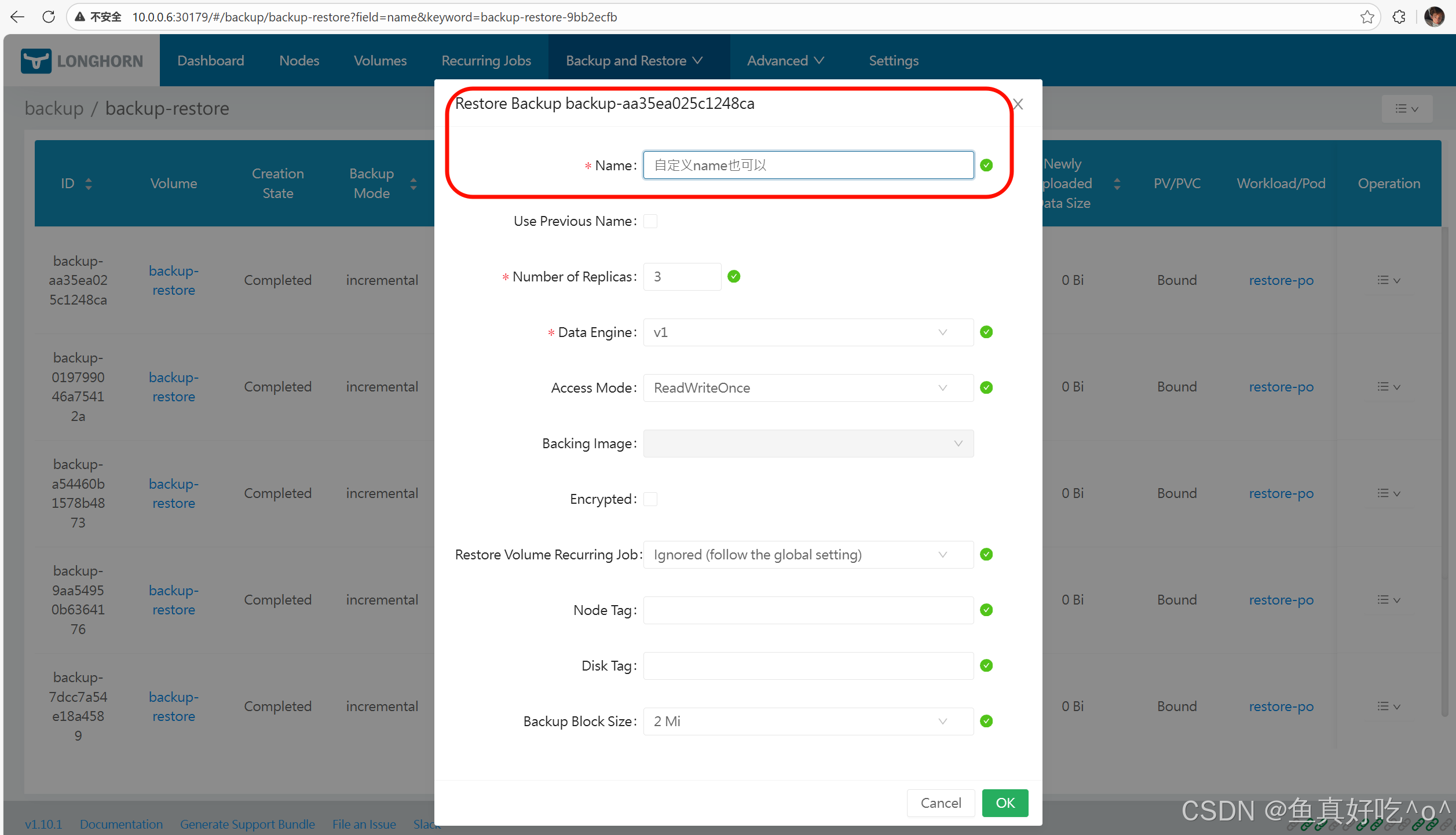
然后创建PV,PVC,POD测试
bash
[root@k8s-master ~]# cat pv.yaml pvc.yaml pod.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-backup-restore # 自定义 PV 名称
spec:
capacity:
storage: 2Gi # 必须和 Longhorn Volume 的 Size 一致(截图中是 2Gi)
accessModes:
- ReadWriteOnce # Longhorn 支持的访问模式,根据需求选择(如 RWX、ROX)
csi:
driver: driver.longhorn.io # Longhorn 的 CSI 驱动名,固定值
fsType: ext4 # 文件系统类型(如 ext4、xfs,按需选择)
volumeHandle: backup-restore # 关键:必须和 Longhorn Volume 的名称完全一致(截图中是 backup-restore)
storageClassName: longhorn-csi # 存储类名称,需和后续 PVC 保持一致(Longhorn 默认存储类为 longhorn)
persistentVolumeReclaimPolicy: Retain # 回收策略(Retain/Delete,建议测试环境用 Retain)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-backup-restore # 自定义 PVC 名称
namespace: default # 必须和 Longhorn Volume 的 Namespace 一致(截图中是 default)
spec:
accessModes:
- ReadWriteOnce # 必须和 PV 的 accessModes 完全一致
resources:
requests:
storage: 2Gi # 必须和 PV 的 capacity 完全一致
storageClassName: longhorn-csi # 必须和 PV 的 storageClassName 完全一致
volumeName: pv-backup-restore # 可选:指定绑定到该 PV,避免自动匹配其他 PV
apiVersion: v1
kind: Pod
metadata:
name: restore-po
spec:
containers:
- name: writer
image: myweb:v1
command: ["sh", "-c", "sleep 3600"]
volumeMounts:
- mountPath: /data
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: pvc-backup-restore可以发现数据已经恢复了。
bash
[root@k8s-master ~]# kubectl get po
NAME READY STATUS RESTARTS AGE
longhorn-test-minio-54d5c878fb-mzt6r 1/1 Running 0 73m
restore-po 1/1 Running 0 16s
volume-test 1/1 Running 2 (116m ago) 24h
[root@k8s-master ~]# kubectl exec -it restore-po -- sh
/ # cd /data/
/data # ll
sh: ll: not found
/data # ls -l
total 24
drwx------ 2 root root 16384 Jan 31 01:55 lost+found
-rw-r--r-- 1 root root 146 Jan 31 02:25 mess.txt
-rw-r--r-- 1 root root 50 Jan 31 01:56 verify.txt
/data # cat mess.txt
i am lh-backup-writer,now is
i am lh-backup-writer,now is Sat Jan 31 02:25:00 UTC 2026
i am lh-backup-writer,now is Sat Jan 31 02:25:09 UTC 2026
/data # exit
bash
[root@k8s-master ~]# ll /var/lib/longhorn/replicas/
total 8
drwx------ 2 root root 4096 Jan 31 10:48 backup-restore-df8e30fe/
drwx------ 2 root root 4096 Jan 31 09:24 pvc-5ec32e45-0607-45ba-948d-2d7ad80e55a7-055eaf2f/
[root@k8s-master ~]# 为Kubernetes StatefulSets 恢复卷
Longhorn 支持从 Backup 恢复出多个卷,并将这些恢复出来的卷用在 Kubernetes StatefulSet 中。 恢复过程包含:
-
在 Longhorn UI 或 CLI 上把备份恢复成新的 Longhorn 卷(Restore Volume),
-
在 Kubernetes 中创建与这些恢复卷匹配的 PV 和 PVC,
-
按 StatefulSet 命名规范创建 PVC,
-
最终部署或重建 StatefulSet,从而恢复原 StatefulSet 的数据。
Longhorn 没有一键恢复 StatefulSet,而是分步执行,官方示例如下(按官方结构写法整理):
- 恢复备份生成 Longhorn 卷(Restore Volume)
在 Longhorn UI 的 Backup 页面:
-
选中某个 Backup
-
点击 Restore
-
输入要创建的 Volume 名称
-
Longhorn 生成一个新卷(包含备份的数据)
👉 这步生成的 Volume 会出现在 Longhorn 的 Volumes 列表中(此时尚不是 Kubernetes PV/PVC)。
为每个恢复出的 Longhorn 卷创建 PersistentVolume (PV)
恢复的卷要让 Kubernetes 看到,需要手动或通过 manifest 创建 PV:
bash
apiVersion: v1
kind: PersistentVolume
metadata:
name: statefulset-vol-0
spec:
capacity:
storage: <size> # 和 Longhorn 卷大小一致
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
csi:
driver: driver.longhorn.io
fsType: ext4
volumeAttributes:
numberOfReplicas: <replicas>
volumeHandle: statefulset-vol-0
storageClassName: longhorn为这些 PV 创建对应的 PersistentVolumeClaims (PVC)
bash
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: data-webapp-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi # 必须 match PV capacity
storageClassName: longhorn
volumeName: statefulset-vol-0 # 绑定到刚创建的 PV重新创建 StatefulSet 资源
bash
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: webapp
spec:
serviceName: "nginx"
replicas: 2
template:
...
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: longhorn
resources:
requests:
storage: 2Gi官方提供了一个示例流程(简化版)如下:
假设 :StatefulSet 名称为 webapp,模板 PVC 名是 data,有 2 个副本,各自卷原名分别为 pvc-01a、pvc-02b:
| 原始卷 Backup 名 | 恢复后的 Volume 名 |
|---|---|
pvc-01a |
statefulset-vol-0 |
pvc-02b |
statefulset-vol-1 |
然后:
-
创建 PV/Claim
-
为
statefulset-vol-0/1分别创建PersistentVolume -
再创建
data-webapp-0和data-webapp-1PVC
-
-
部署 StatefulSet
-
StatefulSet 名
webapp -
replicas: 2
-
VolumeClaimTemplates 名称
data
-
恢复结果: StatefulSet 会自动用这些 PVC 给 Pods 挂载恢复后的卷,数据就与备份一致。
恢复 StatefulSet 数据的实质是:把 Backup 从远端还原为一个或多个 Longhorn 卷 → 在 Kubernetes 里为这些卷创建 PV/PVC → 让 StatefulSet 使用这些 PVC 来挂载卷,重建 Pods 即恢复原 StatefulSet 状态。
定时备份volume与快照
bash
[root@k8s-master ~]# cat cronjob.yaml
apiVersion: longhorn.io/v1beta2
kind: RecurringJob
metadata:
name: daily-backup
namespace: longhorn-system
spec:
task: backup
cron: "* * * * *" # 每分钟备份一次(测试用)
groups:
- defaulr
- firsttest
retain: 7
concurrency: 1
# 可选:周期性全量策略
parameters:
full-backup-interval: "0" # 0 表示"每次都是增量"(第一次等价全量)
[root@k8s-master ~]# kubectl get -f cronjob.yaml
NAME GROUPS TASK CRON RETAIN CONCURRENCY AGE LABELS
daily-backup ["defaulr","firsttest"] backup * * * * * 7 1 63s {}通过 UI
在 Longhorn UI 进入 Volume → Recurring Jobs → 选择你创建的 group。
等待10分钟...应该只会出现7个备份才对
bash
[root@k8s-master ~]# kubectl -n longhorn-system get backups.longhorn.io
NAME SNAPSHOTNAME SNAPSHOTSIZE SNAPSHOTCREATEDAT BACKUPTARGET STATE LASTSYNCEDAT
backup-182523165a404a67 daily-ba-edb66dcf-f663-4437-825a-c47f638ea682 119537664 2026-01-31T03:09:06Z default Completed 2026-01-31T03:09:10Z
backup-1e378f0225b044f4 daily-ba-d5170b46-1d31-46a8-bdc6-4ea2093f8671 119537664 2026-01-31T03:06:05Z default Completed 2026-01-31T03:06:10Z
backup-a9a5097157774ae8 daily-ba-986b0ee8-4b02-4f86-aec3-14fe11ddeb2c 119537664 2026-01-31T03:10:06Z default Completed 2026-01-31T03:10:10Z
backup-eaa240a2f0d84f9f daily-ba-bb84c586-b729-46d9-9626-0ef2c66ac622 119537664 2026-01-31T03:07:06Z default Completed 2026-01-31T03:07:10Z
backup-eb6f16d1fd7541d5 daily-ba-6ac1f55c-ee0a-4905-b0dd-61286a310894 119537664 2026-01-31T03:12:05Z default Completed 2026-01-31T03:12:10Z
backup-f486ba02b90f4ac4 daily-ba-1f381587-ca55-4587-a2ba-bf2071989bdf 119537664 2026-01-31T03:08:05Z default Completed 2026-01-31T03:08:10Z
backup-f57f8d0c1d5c4815 daily-ba-92b44a00-8072-4126-a83c-6247f40333c2 119537664 2026-01-31T03:11:06Z default Completed 2026-01-31T03:11:10Z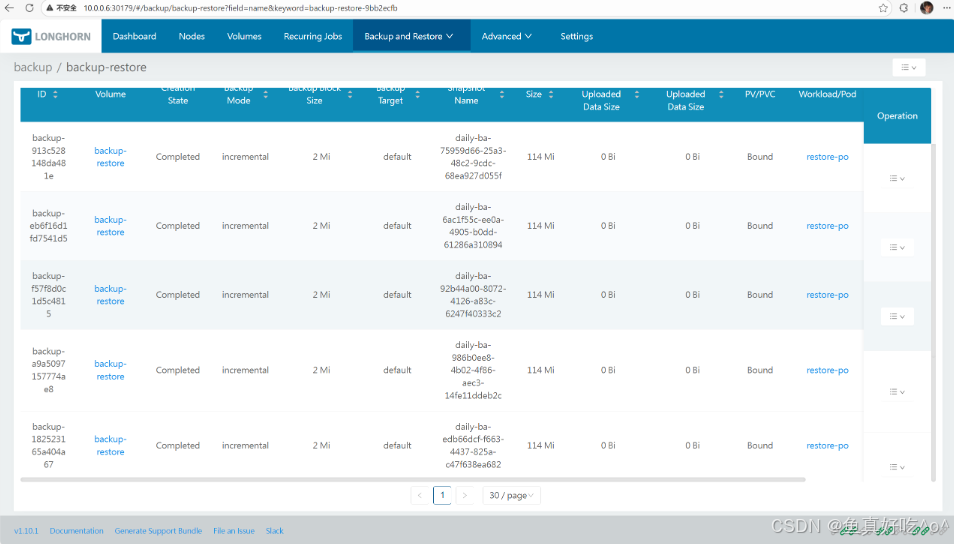
五、总结
核心优势
Longhorn 最突出的特点是 "简单却不简陋":作为 CNCF 孵化的开源工具,它无需依赖复杂的外部组件,通过 Helm、kubectl 等 K8s 原生方式即可快速安装,还支持镜像自动拉取脚本简化部署;架构上采用 "控制面(Longhorn Manager)+ 数据面(Longhorn Engine)" 分层设计,每个卷对应独立引擎的微服务模式,既隔离故障域,又降低分布式存储的复杂度。
在功能覆盖上,它完美适配有状态应用的全生命周期需求:从 Node 与磁盘的灵活管理(新增、删除、标签划分、默认配置定制),到 Volumes 的多方式创建(UI、kubectl、StorageClass 动态供应)、扩容、TRIM 清理,再到 RWX 模式支持多 Pod 共享存储,每一项功能都贴合 K8s 运维的实际场景,无论是单节点读写的数据库,还是多节点共享的配置存储,都能精准适配。
存储安全
Longhorn 把 "数据可靠性" 刻在设计里:通过多副本机制(默认跨节点调度)保障卷的高可用,搭配 "storageReserved、StorageMinimalAvailablePercentage、StorageOverProvisioningPercentage" 三大配置,既防止磁盘写爆、性能雪崩,又避免存储资源浪费;调度机制分两阶段精准筛选节点与磁盘,结合磁盘标签匹配、软 / 硬反亲和策略,进一步降低单节点 / 磁盘故障的影响。
灾备层面,它构建了 "快照 + 备份" 的双重保障:支持手动 / 定时快照,配合快照空间管理避免冗余;备份可对接 MinIO 等 S3 兼容存储,支持增量备份与定时任务,恢复流程适配 K8s StatefulSets 等有状态应用,无论是单卷恢复还是跨集群灾备,都能快速落地,让数据安全有迹可循。
易用性
对于 K8s 运维者而言,Longhorn 大幅降低了分布式存储的使用成本:可视化 UI 可一站式管理节点、卷、快照、备份,关键状态(volume-conditions)清晰可查;同时支持 CLI(longhornctl)与 YAML 配置,适配自动化运维需求。
从基础的磁盘加入、副本调度,到进阶的节点 / 磁盘驱逐、卷扩容、维护模式快照恢复,每一步操作都有明确的流程与防护机制(如分离卷前提醒停掉关联 Pod、恢复快照需切换维护模式),既避免误操作导致的数据风险,又让复杂操作变得直观可控。
最终价值:谁该选择 Longhorn?
无论是中小企业的私有 K8s 集群,还是大型企业的混合云环境,无论是核心业务的数据库存储,还是测试环境的临时存储需求,Longhorn 都能以 "开源免费、部署简单、功能全面、数据可靠" 的优势成为优选。它不只是一款存储工具,更是 K8s 有状态应用的 "存储安全网"------ 让运维者无需深陷分布式存储的底层复杂度,就能轻松实现存储资源的灵活管理与数据的万无一失。