高并发、分布式场景下的ID生成策略
目录
-
\[#为什么需要设计ID生成\|为什么需要设计ID生成\]
-
\[#UUID\|UUID\]
-
\[#雪花算法 Snowflake\|雪花算法 Snowflake\]
-
\[#数据库自增ID\|数据库自增ID\]
-
\[#Redis原子计数\|Redis原子计数\]
-
\[#号段模式 Segment\|号段模式 Segment\]
-
\[#Leaf 分布式ID生成系统\|Leaf 分布式ID生成系统\]
-
\[#方案对比与选择建议\|方案对比与选择建议\]
为什么需要设计ID生成
在很多项目刚开始的时候,生成 ID 似乎是一件非常简单的事情。数据库里的 AUTO_INCREMENT 往往就能满足需求,开发者也很少会专门去思考这个问题。但当系统逐渐发展,访问量越来越大,甚至开始拆分成多个服务、部署在多台机器上时,一个看似简单的问题就会变得复杂起来:在高并发、分布式的环境下,如何生成一个既唯一又高效的 ID?
如果处理不好,就可能出现 ID 冲突、数据库性能瓶颈,甚至影响整个系统的稳定性。因此,在实际的后端开发中,ID 生成往往会被单独设计成一套机制。从最简单的数据库自增,到使用 Redis 计数器,再到像 Snowflake 这样的分布式算法,不同的方案都有各自的适用场景。
UUID
UUID(Universally Unique Identifier)是一个128位的全局唯一标识符,通常以32个十六进制数字表示,分为5组,例如:550e8400-e29b-41d4-a716-446655440000。Java中可以使用 UUID.randomUUID().toString() 生成(版本4,随机生成)。
优点
- 本地生成:完全在本地生成,无需网络请求或数据库查询
- 全局唯一:理论上重复概率极低,适用于分布式环境
- 简单易用:API简单,无需额外配置
缺点
- 无序性:生成的ID完全随机,作为数据库主键时会导致B+树索引频繁分裂,严重影响写入性能
- 长度大:128位(16字节)存储空间较大,作为索引效率较低
- 无业务含义:ID本身不携带任何时间、机器等业务信息
适用场景
- 生成临时令牌(Token)、会话ID(Session ID)
- 文件上传时的临时文件名
- 不入库的临时标识符
- 分布式追踪ID(Trace ID)
注意 :虽然UUID可以解决分布式唯一性问题,但由于其无序性和长度问题,通常不建议作为数据库主键使用。在高并发写入场景下,性能影响显著。
雪花算法 (Snowflake)
雪花算法是 Twitter 开源的分布式 ID 生成算法,生成的 ID 是一个 64 位的长整数,具有趋势递增 、全局唯一的特点,适合在高并发分布式环境中使用。
算法原理
雪花算法生成的 64 位 ID 由以下几部分组成:
| 位数 | 含义 | 说明 |
|---|---|---|
| 1 | 符号位 | 保证为正数,固定为0 |
| 41 | 时间戳 | 毫秒级时间戳,从自定义 epoch 开始计算 |
| 10 | 机器ID | 可配置为机房ID + 机器ID,唯一标识节点 |
| 12 | 序列号 | 同一毫秒内的自增序列(0-4095) |
- 时间戳(41位):保证 ID 随时间递增,最多可使用约 69 年(2^41/1000/60/60/24/365)
- 机器ID(10位):最多支持 1024 个节点,保证分布式环境下不冲突
- 序列号(12位):同一毫秒内最多生成 4096 个 ID
ID 生成步骤
- 获取当前时间戳(毫秒)
- 检查时钟回拨:如果当前时间小于上次生成时间,抛出异常或等待
- 生成序列号 :
- 如果当前时间戳与上次相同:序列号 +1(超过最大值则等待下一毫秒)
- 如果不同:序列号重置为 0
- 组合各部分 :
(时间戳 << 22) | (机器ID << 12) | 序列号
伪代码实现
Java
/**
* 雪花算法 ID 生成器
*/
public class SnowflakeIdGenerator {
private final long epoch = 1609459200000L; // 2021-01-01 00:00:00
private final long workerIdBits = 10L;
private final long sequenceBits = 12L;
private final long maxWorkerId = ~(-1L << workerIdBits); // 1023
private final long maxSequence = ~(-1L << sequenceBits); // 4095
private final long workerIdShift = sequenceBits;
private final long timestampShift = sequenceBits + workerIdBits;
private long lastTimestamp = -1L;
private long sequence = 0L;
public synchronized long nextId() {
long timestamp = currentTimeMillis();
// 检查时钟回拨
if (timestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨异常,拒绝生成ID");
}
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & maxSequence;
if (sequence == 0) {
// 同一毫秒内序列号用尽,等待下一毫秒
timestamp = waitNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - epoch) << timestampShift)
| (workerId << workerIdShift)
| sequence;
}
private long waitNextMillis(long lastTimestamp) {
long timestamp = currentTimeMillis();
while (timestamp <= lastTimestamp) {
timestamp = currentTimeMillis();
}
return timestamp;
}
}优缺点分析
优点
- 高性能:完全在本地内存计算,无网络开销
- 高并发:单机单毫秒可生成 4096 个 ID,分布式下性能线性扩展
- 趋势递增:ID 随时间递增,适合作为数据库索引
- 可解析:ID 可反解析出生成时间、机器ID等信息
缺点
- 时钟回拨问题 :服务器时间回退会导致 ID 重复
- 解决方案 :
- 等待时间追平(适合小范围回拨)
- 使用备用时间源(如 NTP 服务器)
- 记录最近时间戳,拒绝服务直到时间恢复
- 使用 Leaf-Snowflake 等改进方案
- 解决方案 :
- 机器ID分配 :需要手动或通过协调服务分配机器ID
- 分配方案 :
- 配置文件手动指定
- 使用 ZooKeeper/Etcd 动态分配
- 基于数据库分配和持久化
- 分配方案 :
性能指标
- 单机 QPS:理论最大 409.6 万/秒(实际受限于系统时钟精度)
- 支持节点数:最多 1024 个节点
- 可用年限:约 69 年(从自定义 epoch 开始)
数据库自增ID
数据库自增ID是最简单的ID生成方式,通过在表中设置AUTO_INCREMENT字段,由数据库自动维护ID的递增。
单机场景
在单机MySQL中,使用AUTO_INCREMENT非常简单:
mysql
CREATE TABLE `orders` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`data` VARCHAR(255),
PRIMARY KEY (`id`)
) ENGINE=InnoDB;工作原理
- MySQL通过自增锁保证并发安全,同一时刻只有一个事务能获取自增值
- 自增ID保证连续递增(在事务回滚时会有空洞)
- 性能较高,但存在单点瓶颈
分布式场景的问题
在分布式数据库(分库分表)环境中,直接使用AUTO_INCREMENT会导致ID冲突:
- 每个分片独立自增,会产生重复ID
- 无法保证全局唯一性和有序性
分布式解决方案:存根表
通过一个独立的存根表(Stub Table) 集中分配ID,解决分布式ID冲突问题。
表结构设计
mysql
CREATE TABLE `sequence_id` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`stub` CHAR(1) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB COMMENT='ID分配存根表';stub:业务标识(如 'order'、'user'),唯一索引保证每个业务独立序列id:当前最大ID,自增字段
ID分配流程
- 插入或更新存根表,获取新ID:
mysql
-- 原子操作:如果stub存在则id+1,不存在则插入
INSERT INTO sequence_id (stub)
VALUES ('order')
ON DUPLICATE KEY UPDATE id = LAST_INSERT_ID(id + 1);- 使用获取的ID插入业务表:
mysql
INSERT INTO orders (id, data)
VALUES (LAST_INSERT_ID(), '订单数据');关键机制:LAST_INSERT_ID()
LAST_INSERT_ID()是MySQL的会话级函数,返回当前连接最后生成的自增ID- 即使在高并发下,每个连接都能正确获取自己生成的ID,不会冲突
- 事务安全,连接断开后失效
优缺点分析
优点
- 简单可靠:利用数据库原生能力,实现简单
- 绝对有序:ID严格连续递增
- 高可用:数据库具备主从复制、故障恢复能力
缺点
- 性能瓶颈:每次生成ID都需要数据库交互,QPS受限
- 单点故障:存根表数据库成为单点
- 扩展性差:无法线性扩展,性能受数据库限制
优化方案
- 批量获取:一次获取多个ID,在应用层缓存(类似号段模式)
- 多存根表:按业务拆分多个存根表,分散压力
- 数据库集群:使用分布式数据库或读写分离
适用场景:中小型系统,ID生成频率不高(< 1000 QPS),对数据库依赖较强的传统架构。
Redis原子计数
Redis 作为高性能内存数据库,提供原子递增命令,可以用于实现分布式环境下的全局ID生成。
核心命令
redis
# 基本递增,返回递增后的值
INCR id:counter
# 指定步长递增
INCRBY id:counter 100
# 设置初始值(如果key不存在)
SET id:counter 1000 NX实现方案
1. 简单计数器
java
public class RedisIdGenerator {
private Jedis jedis;
public Long nextId(String bizType) {
String key = "id:counter:" + bizType;
return jedis.incr(key);
}
}2. 带时间戳的ID
结合时间戳保证ID趋势递增:
java
public Long nextId(String bizType) {
String date = LocalDate.now().format(DateTimeFormatter.BASIC_ISO_DATE); // yyyyMMdd
String key = "id:counter:" + bizType + ":" + date;
Long seq = jedis.incr(key);
// 组合:日期 + 序列号,如 202603160001
return Long.parseLong(date + String.format("%04d", seq));
}优点
1. 原子性保证
- Redis单线程执行命令,
INCR操作天然原子性 - 无需额外锁机制,高并发下不会出现竞态条件
2. 高性能
- 内存操作,响应时间通常在毫秒级
- 单节点QPS可达10万+
3. 灵活性
- 支持按业务类型、日期等维度拆分计数器
- 可设置过期时间,自动清理历史数据
缺点与挑战
1. 中心化瓶颈
- 所有ID生成请求集中到Redis单节点/集群
- 在极高并发(>10万QPS)下可能成为性能瓶颈
2. 网络开销
- 每次生成ID都需要网络往返
- 增加了延迟(通常1-2ms)
3. 可用性问题
- Redis故障会导致ID生成服务不可用
- 需要部署Redis集群、持久化、备份等高可用方案
4. 数据持久化
- 计数器需要持久化,避免重启后ID重复
- RDB/AOF持久化可能影响性能
优化方案
1. 本地缓存批处理
- 应用层缓存一批ID,减少Redis访问频率
- 类似号段模式,但使用Redis作为存储后端
2. Redis集群分片
- 不同业务使用不同Redis分片
- 使用Hash Tag保证同一业务计数器在同一个分片
3. 多级缓存
- L1: 应用本地缓存(号段)
- L2: Redis集群
- L3: 数据库持久化
性能指标
- 单节点QPS:8-12万(取决于网络和Redis配置)
- 延迟:0.5-2ms(同机房)
- 支持业务数:理论上无限制(通过key设计)
适用场景
- 中小型系统:QPS < 5万
- 临时ID生成:会话ID、验证码等
- 多维度ID:需要按日期、业务等维度生成的ID
- 快速原型:快速实现分布式ID生成
注意:对于超高频ID生成场景(>10万QPS),建议采用号段模式或雪花算法,避免Redis成为瓶颈。
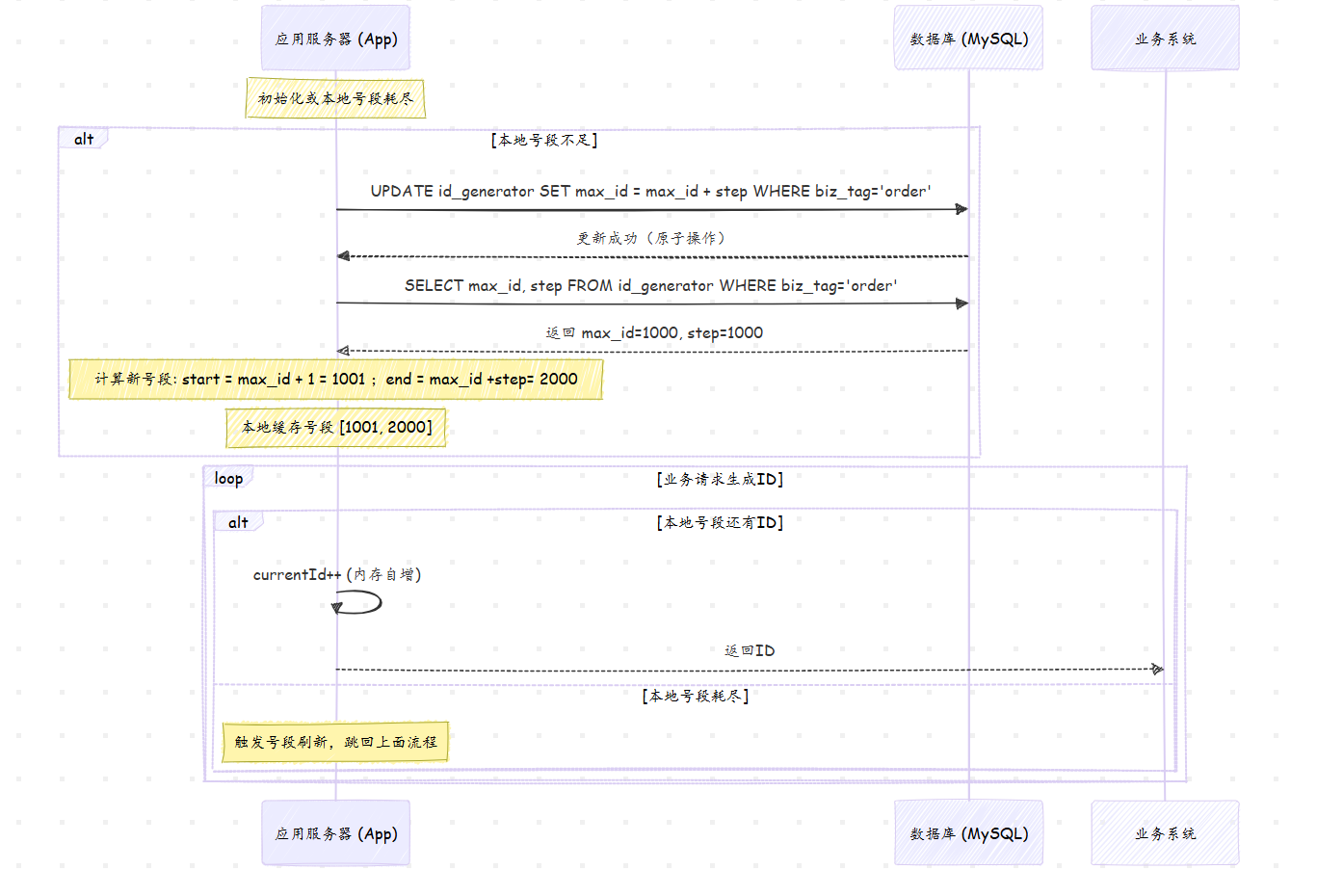
号段模式 (Segment)
号段模式(Segment)是一种批量预分配的ID生成方案,核心思想是:从数据库批量获取一段ID(如1001~2000),缓存在应用本地,然后逐个分配。这样将数据库的每次ID申请压缩为批量申请,极大减少数据库压力。
数据库设计
mysql
CREATE TABLE id_generator (
biz_tag VARCHAR(50) PRIMARY KEY COMMENT '业务标识',
max_id BIGINT NOT NULL COMMENT '当前已分配的最大ID',
step INT NOT NULL COMMENT '步长(每次分配的ID数量)',
version BIGINT NOT NULL DEFAULT 0 COMMENT '版本号(乐观锁)',
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB COMMENT='ID生成器配置表';字段说明:
biz_tag:业务类型(如'order'、'user'),唯一标识不同业务序列max_id:当前已分配的最大ID,下次分配从max_id+1开始step:步长,决定每次预分配的ID数量version:乐观锁版本,防止并发更新冲突
号段分配策略
1. 固定步长
根据业务量预估设置固定步长:
mysql
-- 高频业务:订单,步长10万
INSERT INTO id_generator (biz_tag, max_id, step) VALUES
('order', 0, 100000);
-- 低频业务:用户,步长1000
INSERT INTO id_generator (biz_tag, max_id, step) VALUES
('user', 0, 1000);2. 动态步长(智能调整)
根据历史消耗速率动态调整步长:
- 监控号段消耗速度
- 自动调整步长(如消耗快则增大步长)
- 避免频繁数据库访问,同时减少ID浪费
号段申请流程
步骤1:原子更新max_id
mysql
UPDATE id_generator
SET max_id = max_id + step,
version = version + 1,
update_time = NOW()
WHERE biz_tag = 'order'
AND version = #{oldVersion};并发控制:
- 使用乐观锁(version字段)避免更新冲突
- 更新失败时重试或等待
步骤2:查询分配的号段范围
mysql
SELECT max_id, step
FROM id_generator
WHERE biz_tag = 'order';假设查询结果:max_id = 100000, step = 100000
则分配的号段为:[100001, 200000]
步骤3:本地缓存与分配
java
public class SegmentIdGenerator {
private AtomicLong currentId; // 当前分配的ID
private Long maxId; // 当前号段最大值
public synchronized Long nextId() {
if (currentId.get() <= maxId) {
return currentId.getAndIncrement();
} else {
// 号段用完,申请新号段
allocateNewSegment();
return nextId();
}
}
private void allocateNewSegment() {
// 从数据库申请新号段
Segment segment = db.allocateSegment("order");
currentId.set(segment.getStartId()); // 100001
maxId = segment.getEndId(); // 200000
}
}号段模式流程示意图
优化方案
1. 双Buffer机制(Leaf方案)
问题:号段用尽时才申请新号段,导致请求阻塞。
解决方案:
- Buffer A:当前正在使用的号段
- Buffer B:预备号段(提前异步加载)
- 当Buffer A使用到阈值(如80%)时,异步加载Buffer B
- Buffer A用尽后无缝切换到Buffer B
2. 多级缓存
- L1:应用内存缓存(当前号段)
- L2:Redis缓存(备用号段)
- L3:数据库(持久化存储)
3. 监控与告警
- 监控号段消耗速率
- 预测号段用尽时间,提前预警
- 自动调整步长
优缺点分析
优点
- 高性能:99.9%的ID从内存分配,响应时间<1ms
- 高可用:数据库短暂不可用不影响ID生成(有缓存号段)
- 可扩展:水平扩展应用节点,数据库压力不增加
- 灵活配置:可按业务设置不同步长
缺点
- ID不连续:号段用尽时ID会有跳跃(如200000→300001)
- 数据库依赖:仍需数据库持久化,但压力大幅降低
- 重启丢号 :应用重启时未使用的缓存ID会丢失
- 解决方案:定期持久化已分配位置,或使用共享存储(Redis)
性能指标
- 单机QPS:10万+(纯内存操作)
- 数据库QPS:降低100-1000倍(取决于步长)
- 支持节点数:理论上无限制
- ID连续性:段内连续,段间不连续
适用场景
- 高频ID生成:电商订单、支付流水、日志ID
- 多业务隔离:不同业务需要独立ID序列
- 数据库压力敏感:需要减少数据库访问的场景
最佳实践:步长设置需要权衡,太小导致频繁访问数据库,太大导致ID浪费和重启丢失更多ID。建议根据业务QPS设置步长为5-10分钟的消耗量。
Leaf 分布式ID生成系统
Leaf 是美团开源的一套分布式ID生成系统,提供了Leaf-Segment 和Leaf-Snowflake两种模式,在实际生产环境中广泛应用。
系统架构
Leaf 采用 RESTful API 提供服务,支持以下特性:
- 高可用:多节点部署,无单点故障
- 高性能:单机QPS可达10万+
- 可监控:提供管理后台,实时监控ID生成状态
- 易扩展:支持水平扩展,动态调整节点
Leaf-Segment
核心改进
在基础号段模式上,Leaf-Segment 引入了以下优化:
1. 双Buffer机制
java
public class DoubleBuffer {
private SegmentBuffer currentBuffer; // 当前使用的Buffer
private SegmentBuffer nextBuffer; // 预备Buffer
public synchronized Long nextId() {
if (currentBuffer.hasId()) {
return currentBuffer.nextId();
}
if (nextBuffer != null && nextBuffer.isReady()) {
// 切换Buffer
currentBuffer = nextBuffer;
nextBuffer = null;
// 异步加载下一个Buffer
loadNextBufferAsync();
return currentBuffer.nextId();
}
// 两个Buffer都为空,等待加载
waitForBuffer();
return nextId();
}
private void loadNextBufferAsync() {
executor.submit(() -> {
Segment segment = db.allocateSegment(bizTag);
SegmentBuffer buffer = new SegmentBuffer(segment);
nextBuffer = buffer;
});
}
}工作流程:
- Buffer A 为当前使用Buffer
- 当Buffer A消耗到阈值(默认80%)时,由一个独立的线程去执行
loadNextBufferAsync() - Buffer A用尽后,无缝切换到Buffer B
- Buffer A用尽后,立即异步加载下一个Buffer
2. 动态步长调整
根据历史消耗速率自动调整步长:
- 监控最近N次号段消耗时间
- 计算平均消耗速率(ID/秒)
- 动态调整步长 = 平均速率 × 缓存时间(如10分钟)
3. 监控与告警
- 实时监控各业务号段消耗情况
- 预测号段用尽时间,提前告警
- 可视化配置管理界面
表结构设计
mysql
CREATE TABLE leaf_alloc (
biz_tag VARCHAR(128) NOT NULL PRIMARY KEY COMMENT '业务标识',
max_id BIGINT NOT NULL COMMENT '当前最大ID',
step INT NOT NULL COMMENT '步长',
description VARCHAR(256) COMMENT '业务描述',
update_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB;Leaf-Snowflake
Leaf-Snowflake 在原生雪花算法基础上,解决了时钟回拨 和机器ID分配两大痛点。
1. 机器ID动态分配
传统问题
- 手动配置机器ID,容易冲突
- 扩缩容需要重新配置
- 机器ID回收困难
Leaf解决方案:基于ZooKeeper的机器ID分配
java
public class WorkerIdAssigner {
private ZooKeeper zk;
public int assignWorkerId() {
// 1. 在ZooKeeper创建临时顺序节点
String path = zk.create("/leaf/snowflake/worker-",
null,
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// 2. 解析节点序号作为workerId
int workerId = parseWorkerId(path);
// 3. 注册监听,节点删除时重新分配
zk.exists(path, event -> {
if (event.getType() == EventType.NodeDeleted) {
reassignWorkerId();
}
});
return workerId;
}
}优势:
- 自动分配:节点启动时自动获取唯一workerId
- 自动回收:节点下线后workerId自动释放
- 容错处理:节点异常退出,临时节点自动删除
2. 时钟回拨处理
Leaf-Snowflake 采用多层次时钟回拨处理策略:
轻度回拨(< 100ms)
- 等待时钟追平
- 记录回拨事件,监控告警
中度回拨(100ms ~ 1s)
- 使用备用时间源(NTP服务器)校验
- 如果确认回拨,等待追平
- 如果备用时间源也回拨,进入重度处理
重度回拨(> 1s)
- 暂停服务:拒绝ID生成请求
- 告警升级:通知运维人员干预
- 人工处理:可能需要重启服务或修复时钟
代码实现
java
public class LeafSnowflakeIdGenerator {
private long lastTimestamp = -1L;
public synchronized long nextId() {
long timestamp = timeGen();
// 时钟回拨检测
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 100) {
// 轻度回拨:等待
waitUntilReach(lastTimestamp);
timestamp = timeGen();
} else if (offset <= 1000) {
// 中度回拨:校验备用时钟
if (checkBackupClock()) {
waitUntilReach(lastTimestamp);
timestamp = timeGen();
} else {
throw new ClockMovedBackwardsException("时钟回拨过大");
}
} else {
// 重度回拨:暂停服务
serviceStatus = ServiceStatus.SUSPENDED;
throw new ClockMovedBackwardsException("严重时钟回拨,服务暂停");
}
}
// ... 正常生成ID逻辑
}
}生产环境部署
1. 高可用架构
客户端 → 负载均衡器 → [Leaf节点1, Leaf节点2, Leaf节点3]
↓
[ZooKeeper集群] ←→ [MySQL集群]2. 监控指标
- QPS/TPS:ID生成速率
- 成功率:ID生成成功率
- 延迟:P50/P95/P99响应时间
- 号段水位:各业务号段使用比例
- 时钟状态:时钟回拨告警次数
3. 容灾方案
- 多机房部署:Leaf节点跨机房部署
- 数据库主从:MySQL主从复制,读写分离
- ZooKeeper集群:至少3节点,避免单点故障
- 客户端降级:ID生成失败时降级到本地模式
性能对比
| 特性 | Leaf-Segment | Leaf-Snowflake |
|---|---|---|
| QPS | 10万+ | 5万+ |
| 延迟 | <1ms | <2ms |
| 连续性 | 段内连续,段间跳跃 | 趋势连续 |
| 依赖 | MySQL | ZooKeeper + 时钟服务 |
| 适用场景 | 业务维度ID,高频生成 | 全局唯一ID,需要时间信息 |
总结
Leaf 系统将学术界分布式ID生成理论转化为工业级解决方案,主要贡献在于:
- 工程化实现:解决了原生算法的生产环境问题
- 高可用设计:多级容错,故障自动恢复
- 可观测性:完善的监控、告警、管理界面
- 易用性:提供RESTful API,客户端集成简单
GitHub地址:https://github.com/Meituan-Dianping/Leaf
生产建议:对于大多数互联网公司,Leaf-Segment方案已能满足90%以上的场景。如果对ID的时间信息有要求,或需要严格的全局递增,可以考虑Leaf-Snowflake。
方案对比与选择建议
方案对比总览
| 方案 | 唯一性 | 有序性 | 性能 | 可用性 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|---|
| UUID | 全局唯一 | 无序 | 极高 | 极高 | 极低 | 临时令牌、会话ID、不入库标识 |
| 数据库自增 | 单库唯一 | 严格递增 | 低(依赖DB) | 中(单点) | 低 | 单机应用、小型系统 |
| 数据库存根表 | 全局唯一 | 严格递增 | 中(依赖DB) | 中(单点) | 中 | 中小型分布式系统 |
| Redis原子计数 | 全局唯一 | 严格递增 | 高(依赖Redis) | 中(Redis集群) | 低 | 中小型系统,QPS<5万 |
| 雪花算法 | 全局唯一 | 趋势递增 | 极高(本地) | 高(依赖时钟) | 中 | 大型分布式系统,需要时间信息 |
| 号段模式 | 全局唯一 | 段内连续 | 极高(内存) | 高(依赖DB) | 中 | 高频ID生成,电商、支付 |
| Leaf-Segment | 全局唯一 | 段内连续 | 极高(内存) | 极高(高可用) | 高 | 生产环境,需要完善监控管理 |
| Leaf-Snowflake | 全局唯一 | 趋势递增 | 高(本地) | 极高(高可用) | 高 | 生产环境,需要时间信息 |
选择决策树
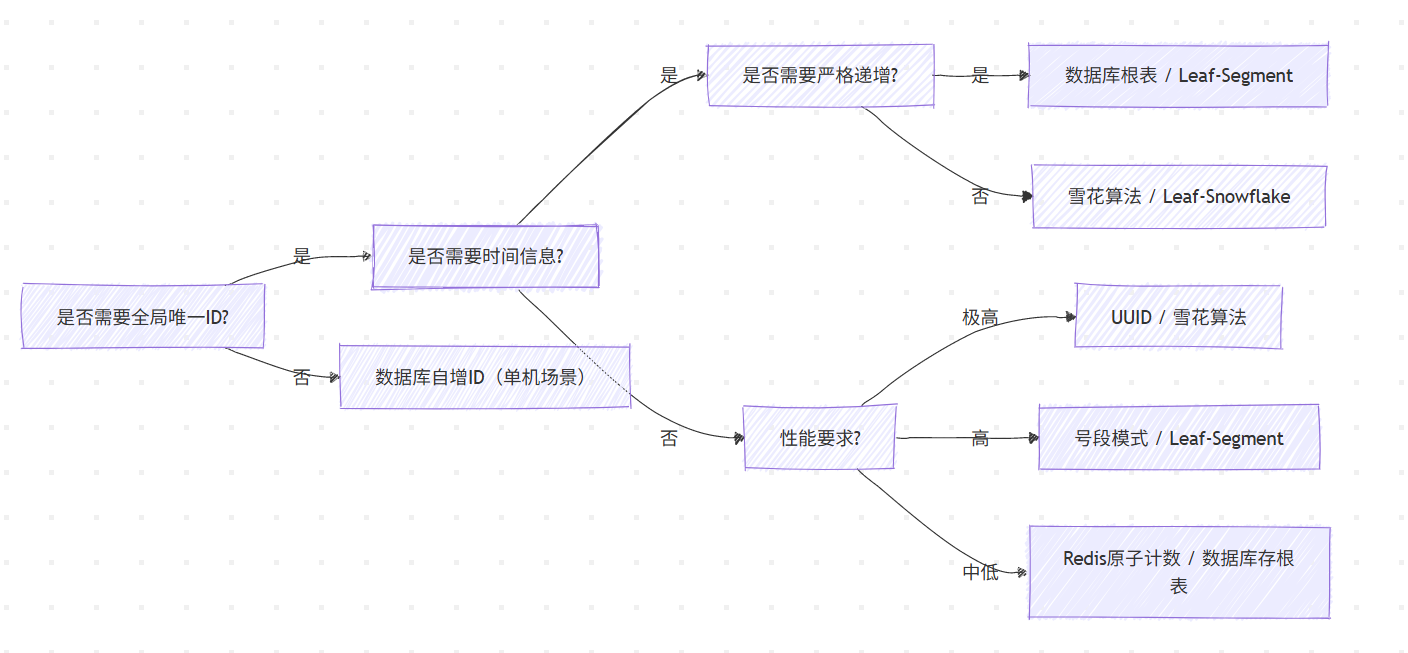
各场景推荐方案
1. 小型项目/创业初期
- 推荐:数据库自增ID 或 UUID
- 理由:实现简单,快速上线
- 注意:预留扩展空间,考虑未来迁移
2. 中型分布式系统(QPS < 1万)
- 推荐:Redis原子计数 或 数据库存根表
- 理由:平衡性能与复杂度
- 注意:Redis需要高可用部署
3. 大型电商/支付系统(QPS 1万~10万)
- 推荐:号段模式 或 Leaf-Segment
- 理由:高性能,可水平扩展
- 注意:需要监控号段消耗,合理设置步长
4. 需要时间信息的系统(如日志追踪)
- 推荐:雪花算法 或 Leaf-Snowflake
- 理由:ID携带时间信息,可反解析
- 注意:解决时钟回拨问题
5. 临时标识/不入库数据
- 推荐:UUID
- 理由:简单,无需存储
- 注意:不要作为数据库主键
性能优化建议
1. 分库分表场景
- 策略:在ID中嵌入分片信息
- 示例 :
[时间戳][分片ID][序列号] - 优点:避免跨分片查询,提升性能
2. 多数据中心场景
- 策略:在ID中嵌入数据中心ID
- 示例:雪花算法中分配几位作为数据中心ID
- 优点:支持多机房部署,容灾
3. ID压缩与传输
- 策略:将64位长整型转为更短字符串
- 示例:Base62编码,减少传输体积
- 优点:节省网络带宽,前端友好
监控与运维
关键监控指标
- ID生成速率:QPS/TPS,异常波动告警
- ID重复率:定期检查ID唯一性
- 服务可用性:成功率、错误率
- 资源使用:数据库连接、Redis内存
容量规划
- 预估业务增长:根据业务规划预估ID需求
- 设置合理步长:号段步长 = 预估QPS × 缓存时间(建议5-10分钟)
- 定期评估:每季度评估ID方案是否仍适用
迁移方案
从简单方案迁移到复杂方案时:
- 双写阶段:新旧方案同时生成ID,记录映射关系
- 数据迁移:逐步将历史数据关联新ID
- 读迁移:先读新ID,逐步切换
- 写迁移:最后切换到新ID生成方案
- 验证阶段:验证数据一致性和性能
总结
选择ID生成方案时,需要综合考虑:
- 业务规模:当前和未来的QPS需求
- 团队能力:运维复杂度与团队技能匹配
- 成本预算:硬件、运维成本
- 业务特性:是否需要时间信息、是否分库分表
黄金法则:没有最好的方案,只有最适合的方案。从小规模开始,随着业务增长逐步演进,避免过度设计。