Structured Over Scale: Learning Spatial Reasoning from Educational Video
Authors: Bishoy Galoaa, Xiangyu Bai, Sarah Ostadabbas
Deep-Dive Summary:
这篇文章名为《Structured Over Scale: Learning Spatial Reasoning from Educational Video》(结构胜于规模:从教育视频中学习空间推理),探讨了如何利用少儿教育视频中特有的教学结构来提升视觉语言模型(VLM)的空间推理能力。
| :--- | :--- | :--- | :--- |
| GPT-4V | 67.79 | 60.34 | 69.23 | 68.85 |
| Qwen3-VL-8B (基准) | 58.08 | 52.16 | 41.18 | 65.57 |
| Qwen3-VL-8B + GRPO | 67.98 | 62.50 | 59.62 | 72.13 |
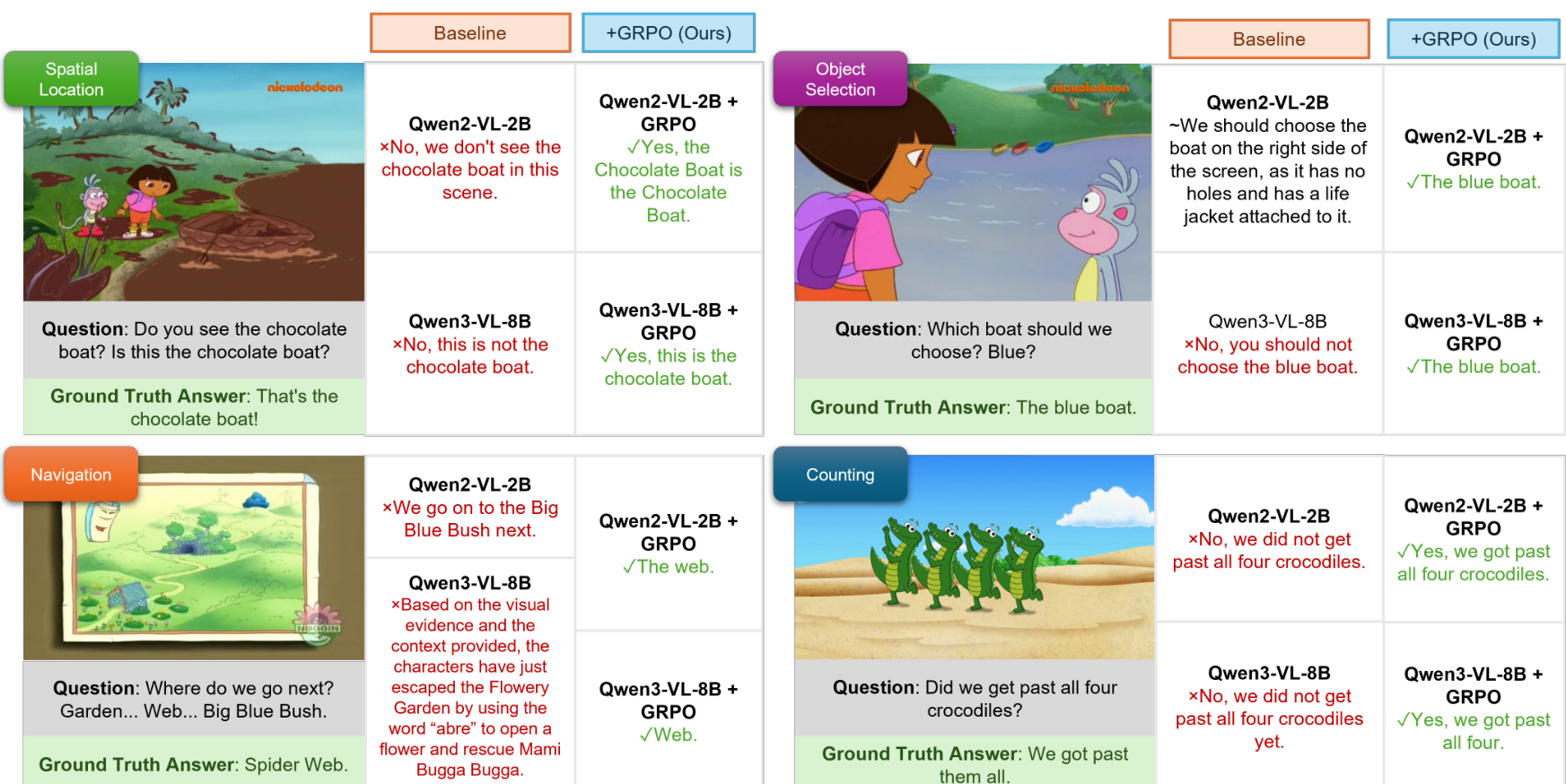
图 3. 定性结果对比 。GRPO 微调后的模型在识别迷彩物体、背景物体选择、序列导航推理以及高密度计数方面表现更优,而基准模型常出现幻觉或失败。
以下是该学术论文相关部分的详细中文摘要:
4.3. 跨基准迁移 (Cross-Benchmark Transfer)
表 2 的结果表明,在具有教学结构的内容上进行训练可以有效地迁移到各种视频理解基准测试中,而不仅限于训练数据的分布。尽管采用了零样本(zero-shot)评估,且仅使用了 5.3K 个问答对(相比之下,竞争方法使用了数百万个视频),所有模型在外部基准测试中均表现出持续的改进。
在 CVBench 上观察到的增益最为显著,该基准明确要求跨视频整合和知识迁移。其中,结构化知识召回表现得尤为有效:Qwen2-VL-2B 提升了 28.93 分,Qwen2-VL-7B 提升了 24.51 分,而 Qwen3-VL-8B 提升了 40.36 分,达到了 86.16 % 86.16\% 86.16% 的先进性能(SOTA)。强调因果和时间推理的 NExT-QA 也展现了强劲的迁移能力,分别提升了 20.26、12.46 和 19.70 分。Video-MME 在所有模型中也显示出适度但持续的增长(1.62-12.01 分)。这些结果共同证明,结构化的教学训练能够诱导推理能力,使其泛化到儿童教育内容之外的领域,为"结构优于规模"(structure-over-scale)的假设提供了实证支持。
4.4. 消融实验 (Ablation Studies)
研究人员在 DoraVQA 上对 Qwen2-VL-2B 模型进行了 100 个 epoch 的微调,并在 Video-MME、CVBench 和 NExT-QA 的 10 % 10\% 10% 随机采样测试子集上进行了训练策略和输入模态的消融研究。
表 2. 跨基准迁移评估,强调结构与规模。尽管仅在 5.3K 个问答对(38 小时)上进行训练,我们的模型与在海量数据上训练的模型相比,仍取得了极具竞争力或领先的结果。灰色行表示私有模型;黄色高亮表示 SOTA 结果;蓝色单元格强调了极小的微调规模。绿色表示相对于基线的改进。† 表示零样本评估;* 表示预训练期间见过训练集。基线"训练规模"指预训练数据;我们的 GRPO 模型使用相同的基座,但仅在 5.3K 个教学结构化问答对上进行微调。
|------------------------|--------|----------------|----------------|----------------|----------------|-----------------|
| Model | Params | Training Scale | DoraVQA | Video-MME | CVBench | NExT-QA |
| GPT-4V† | ~1.8T | ~10T tokens | 67.79 | 59.9 | 52.4 | 68.2 |
| Gemini-2.5-Pro† | - | - | 64.41 | 85.2 | 62.4 | 74.6 |
| Gemini-3.0-Flash† | - | - | 76.10 | 86.9 | 67.2 | 80.4 |
| InternVideo2.5-8B | 8B | 16M clips | 57.68 | 65.4 | 57.3† | 71.5* |
| LLaVA-Video-7B | 7B | 1.3M videos | 55.41 | 63.3 | 52.6† | 83.2* |
| Video-LLaVA-7B | 7B | 760K videos | 37.82 | 45.3 | 28.1† | 52.1* |
| Qwen2-VL-2B (baseline) | 2B | 1.2T tokens | 41.36 | 50.10 | 31.38 | 52.60 |
| Qwen2-VL-2B + GRPO† | 2B | 5.3K QA | 55.11 (+13.75) | 62.11 (+12.01) | 60.31 (+28.93) | 72.86 (+20.26) |
| Qwen2-VL-7B (baseline) | 7B | 1.2T tokens | 56.74 | 67.5 | 50.7 | 67.0 |
| Qwen2-VL-7B + GRPO† | 7B | 5.3K QA | 62.38 (+5.64) | 69.12 (+1.62) | 75.21 (+24.51) | 79.46 (+12.46) |
| Qwen3-VL-8B (baseline) | 8B | 1.0T tokens | 58.08 | 71.4 | 45.8 | 62.1 |
| Qwen3-VL-8B + GRPO† | 8B | 5.3K QA | 67.98 (+9.90) | 76.78 (+5.38) | 86.16 (+40.36) | 81.80† (+19.70) |
表 3. 训练方法的消融研究。我们将监督微调 (SFT) 与 GRPO 方法在域内 (DoraVQA) 和域外基准上进行了比较。
|---------------|-------|-----------|-------|-------|
| Method | Dora | Video-MME | CVB | NExT |
| No finetuning | 41.36 | 50.10 | 31.38 | 52.60 |
| + SFT | 3.56 | 53.33 | 43.56 | 66.63 |
| + GRPO | 55.11 | 55.40 | 60.31 | 72.86 |
训练方法: 目标是增强视觉语言模型(VLM)在通用领域的推理能力。如表 3 所示,基于强化学习的 GRPO 策略使 Qwen2-VL 能够将从生成自由回答中获得的知识迁移到离散选择任务中。相比之下,SFT 由于过拟合显著降低了模型的灵活性:在 DoraVQA 上,SFT 后的模型无法再进行选择,而只能产生自由回答。此外,GRPO 在各项指标上均优于 SFT,表明其具有更好的泛化能力。
上下文模态: 表 4 评估了不同输入模态对性能的影响。观察发现,模型从文本转录(transcripts)中学到的效果优于从视觉帧中学到的效果,这表明其文本处理组件比视觉组件更强。将两种模态结合可以带来适度的性能提升,证明了所提出的结构化学习格式和 DoraVQA 数据集的有效性。在问题前加入文本上下文可进一步增强性能,CVBench 在此项下提升了 7 % 7\% 7%,反映了其对连贯上下文信息的依赖。
表 4. 上下文模态的消融研究。评估了转录上下文、视觉帧及其组合对空间推理性能的影响。
|---------------------|-------|-----------|-------|-------|
| Context | Dora | Video-MME | CVB | NExT |
| Visual (V) only | 43.42 | 60.74 | 47.35 | 67.91 |
| Transcript (T) only | 50.95 | 60.00 | 50.38 | 70.48 |
| V+T, no Context (C) | 54.72 | 61.11 | 53.41 | 70.83 |
| Full (V+T+C) | 55.11 | 62.20 | 60.31 | 72.86 |
5. 结论 (Conclusion)
研究证明,教学结构化的教育视频为 VLM 的空间推理提供了有效的训练信号。通过使用 GRPO 在 DoraVQA 的 5.3K 个问答对上微调 Qwen2-VL 和 Qwen3-VL,在 CVBench 上实现了 SOTA 性能( 86.16 % 86.16\% 86.16%),并超越了在更大规模数据上训练的模型。这些结果验证了内容结构可以补偿内容的规模。未来的工作将结合视觉奖励模型以捕获教学停顿期间基于动作的信号,并扩展到更全面的教育内容(如 Blue's Clues、可汗学院等),构建跨多个推理领域的教学互动结构(PIS)数据集。
6. 影响声明 (Impact Statements)
本研究介绍了 DoraVQA 数据集及其在微调开源 VLM 中的应用。该数据集不重新发布任何视频帧、音频或原始剧集文件。所有视觉和音频内容仍由原始权利人托管,用户需自行获取访问权限。数据集仅包含剧集标识符、时间戳、加工后的问答注释和转录索引。由于素材来源于公开播出的儿童教育节目,该数据集不会引入新的隐私风险。DoraVQA 严格用于研究和评估目的。实验不涉及任何人类受试者。
Original Abstract: Vision-language models (VLMs) demonstrate impressive performance on standard video understanding benchmarks yet fail systematically on simple reasoning tasks that preschool children can solve, including counting, spatial reasoning, and compositional understanding. We hypothesize that the pedagogically-structured content of educational videos provides an ideal training signal for improving these capabilities. We introduce DoraVQA, a dataset of 5,344 question-answer pairs automatically extracted from 8 seasons of Dora the Explorer with precise timestamp alignment. Each episode follows a consistent \textit{context-question-pause-answer} structure that creates a self-contained learning environment analogous to interactive tutoring. We fine-tune both Qwen2 and Qwen3 using Group Relative Policy Optimization (GRPO), leveraging the clear correctness signals and structured reasoning traces inherent in educational content. Despite training exclusively on 38 hours of children's educational videos, our approach achieves improvements of 8-14 points on DoraVQA and state-of-the-art 86.16% on CVBench, with strong transfer to Video-MME and NExT-QA, demonstrating effective generalization from narrow pedagogical content to broad multimodal understanding. Through cross-domain benchmarks, we show that VLMs can perform tasks that require robust reasoning learned from structured educational content, suggesting that content structure matters as much as content scale.
PDF Link: 2601.23251v1
部分平台可能图片显示异常,请以我的博客内容为准
