一、 打破"最短路径"的迷思
在日常生活中,我们习惯了依赖商业地图软件提供的导航服务。这些软件背后的算法高度封装,通常只遵循一个铁律:效率至上。它们计算路径的核心逻辑是将距离或时间作为唯一的成本,试图用最短的时间把你从 A 点送到 B 点。然而,这种计算方式往往较为单一,无法涵盖更多的应用场景。这时候,商业软件往往束手无策。而这正是 R 语言大显身手的地方------它是一个强大的地理空间分析平台,能够在地理数据的基础上,赋予我们打破常规、重新定义路线规则的能力。
R 语言在处理地理数据方面拥有独特的优势,不同于普通的绘图软件只能展示静态的地图图片,R 能够深入理解地图背后的数据信息。我们将利用 R 语言,将 2015 Street Tree Census - Blockface Data 这一数据集作为示例,完成数据清洗、坐标投影转换,到构建空间网络图这些任务,最终实现基于自定义权重的路径搜索。以此深入了解 R 语言在地理数据集方面的应用价值,并探索其高级应用方法。
二、 Blockface 数据的清洗与投影转换
我们首先打开RStudio:
图1 找到RStudio并打开
将附件的数据集名字重命名为2015_Street_Tree_Census_Blockface.csv,然后将其粘贴到R的工作目录内。由于目前我们并不知道工作目录在哪,因此需要现在R studio中输入代码进行寻找:
R
getwd()输入后,便能够得到返回结果,找到当前的工作目录:

图2 返回的工作目录
将获得的地址粘贴到此电脑的地址栏中,回车进入:

图3 粘贴到地址栏回车进入目录
将示例数据集改名并粘贴到这一目录:

图4 改名并粘贴
在开始阶段,我们并不能马上开始规划路线。原始的地理数据包含了大量对于规划散步路线来说冗余的信息,且其坐标系统可能并不适合直接进行距离计算。在 R 语言中,我们主要依赖 sf 扩展包来处理这类工作。sf 包的强大之处在于,它将复杂的地图数据降维成了我们熟悉的表格形式,每一行代表一条街道,每一列代表一个属性,而特殊的 geometry 列则存储了街道的形状信息。这使得我们可以像处理 Excel 表格一样,轻松地对地图数据进行筛选和清洗。
首先,我们需要将数据读入 R 环境,并检查数据情况。复制并运行以下代码:
R
install.packages(c("sf", "dplyr"))
# 加载必要的空间分析与数据处理包
library(sf)
library(dplyr)
# 1. 读取 GeoJSON 数据
# st_read 函数会自动识别文件格式并将其转换为 sf 对象
raw_data <- st_read("2015_Street_Tree_Census_Blockface.geojson", quiet = TRUE)
# 查看所有列名
names(raw_data)
# 查看前几行数据的概览
head(raw_data)可以看到,结果已经输出了相关信息:
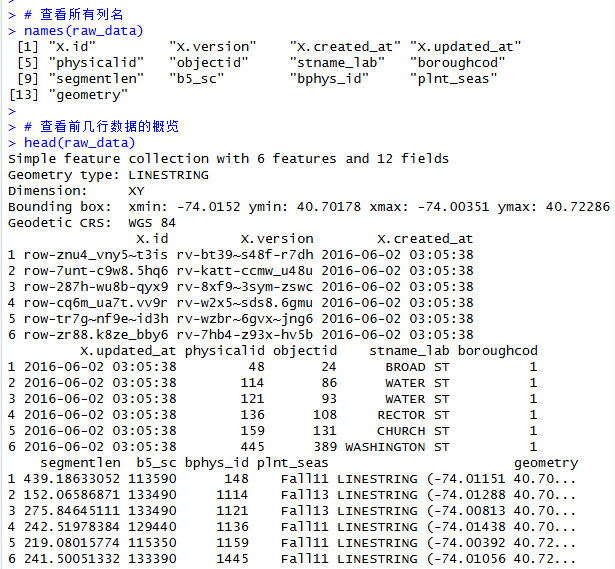
图5 数据结果
观察结果能够发现,当前加载的数据集不包含树木数量的列,而是包含物理街区几何数据与种植季节规划数据。这份数据提供了街道的形状和长度,但没有包含"这条街上有几棵树"的普查统计结果。我们可以利用 R 语言强大的数据处理能力,基于现有的数据模拟一个树木数量。根据街道的长度来生成树木数量:假设街道越长,树可能越多,并加入一些随机性。复制并粘贴运行以下代码:
R
library(sf)
library(dplyr)
# 1. 读取数据
raw_data <- st_read("2015_Street_Tree_Census_Blockface.geojson", quiet = TRUE)
# 2. 模拟数据与清洗
set.seed(123)
blockface_simulated <- raw_data %>%
mutate(
# 先将 segmentlen 强制转换为数字类型
# 这样计算机就能进行数学运算了
segmentlen_num = as.numeric(segmentlen),
# 使用转换后的 segmentlen_num 进行计算
simulated_count = (segmentlen_num / 50) + runif(n(), min = -5, max = 5),
# 取整并去除负数
tree_count = as.integer(pmax(0, simulated_count))
)
# 3. 筛选与投影
blockface_clean <- blockface_simulated %>%
select(tree_count, geometry) %>%
mutate(tree_count = ifelse(is.na(tree_count), 0, tree_count))
# 转换为 EPSG:2263 (New York Long Island)
blockface_projected <- st_transform(blockface_clean, crs = 2263)
# 4. 检查结果
print("数据处理成功!前几行数据如下:")
print(head(blockface_projected))
# 绘图检查
plot(blockface_projected["tree_count"],
main = "街道网络与模拟绿荫分布",
lwd = 0.5)运行代码后可以发现,已经成功输出了模拟的分布结果:
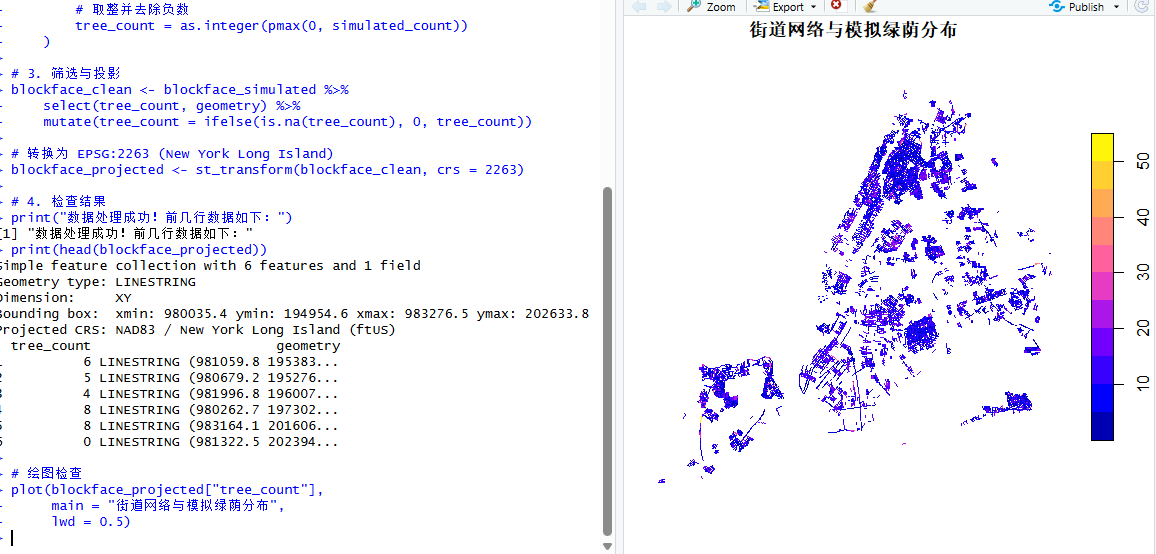
图6 模拟的分布结果图
通过这段代码,我们成功地将一份复杂的原始地理文件,转化为了一个干净、单位统一且适合数学计算的 R 对象,为接下来构建精确的空间网络奠定了坚实的基础。
三、 构建空间网络:从 sf 对象到 sfnetwork 图结构
经过清洗与投影,我们手中的 blockface_projected 对象虽然看起来已经很像一张地图了,但在计算机的眼里,它依然只是一堆毫无关联的线条集合。我们需要将这些独立的街道线条编织成一张互联互通的网。在数据科学中,这种结构被称为图,它由节点和边组成。
在 R 语言的生态系统中,sfnetworks 是一个革命性的扩展包。它巧妙地结合了处理空间几何的 sf 包和处理网络图论的 tidygraph 包。通过它,我们可以轻松地将地理空间数据转化为网络图结构。在这个过程中,sfnetworks 会自动识别每一条街道的起点和终点,将它们视为节点,并将街道本身视为连接这些节点的边。这样一来,原本孤立的线条就变成了具有拓扑关系的网络:计算机终于知道,当你走到某条街的尽头时,可以无缝地转向另一条街。
当我们把 sf 对象转换为 sfnetwork 对象时,原始数据中的属性(比如之前保留的 tree_count)会被自动附着在"边"上。这意味着网络中的每一条连接线不仅知道自己有多长,还知道自己上面长了多少棵树。这种带属性的边正是我们要实现导航规划的核心基础。复制并粘贴运行以下代码:
R
install.packages(c("sfnetworks", "tidygraph"))
library(sfnetworks)
library(tidygraph)
library(sf)
library(dplyr)
# 1. 检查当前的几何类型(这一步是为了验证问题,你会看到 MULTILINESTRING)
print("转换前的几何类型:")
print(unique(st_geometry_type(blockface_projected)))
# 2. 使用 st_cast 将 MULTILINESTRING 拆解为 LINESTRING
# 这一步会将那些由多段线组成的记录拆分成独立的行,属性(如 tree_count)会自动复制
blockface_lines <- st_cast(blockface_projected, "LINESTRING")
# 再次检查几何类型(现在应该是 LINESTRING 了)
print("转换后的几何类型:")
print(unique(st_geometry_type(blockface_lines)))
# --- 修正步骤结束 ---
# 3. 现在可以放心地构建网络了
street_net <- as_sfnetwork(blockface_lines, directed = FALSE)
# 4. 激活"边"数据并计算长度
street_net <- street_net %>%
activate("edges") %>%
mutate(edge_length = st_length(geometry))
# 5. 查看网络结构信息
print(street_net)
# 6. 可视化验证
# 由于网络可能很大,我们只画一部分或者简化绘制
plot(st_geometry(street_net, "edges"), col = "gray", lwd = 0.5, main = "构建完成的街道网络")完成运行后的结果如下图所示:
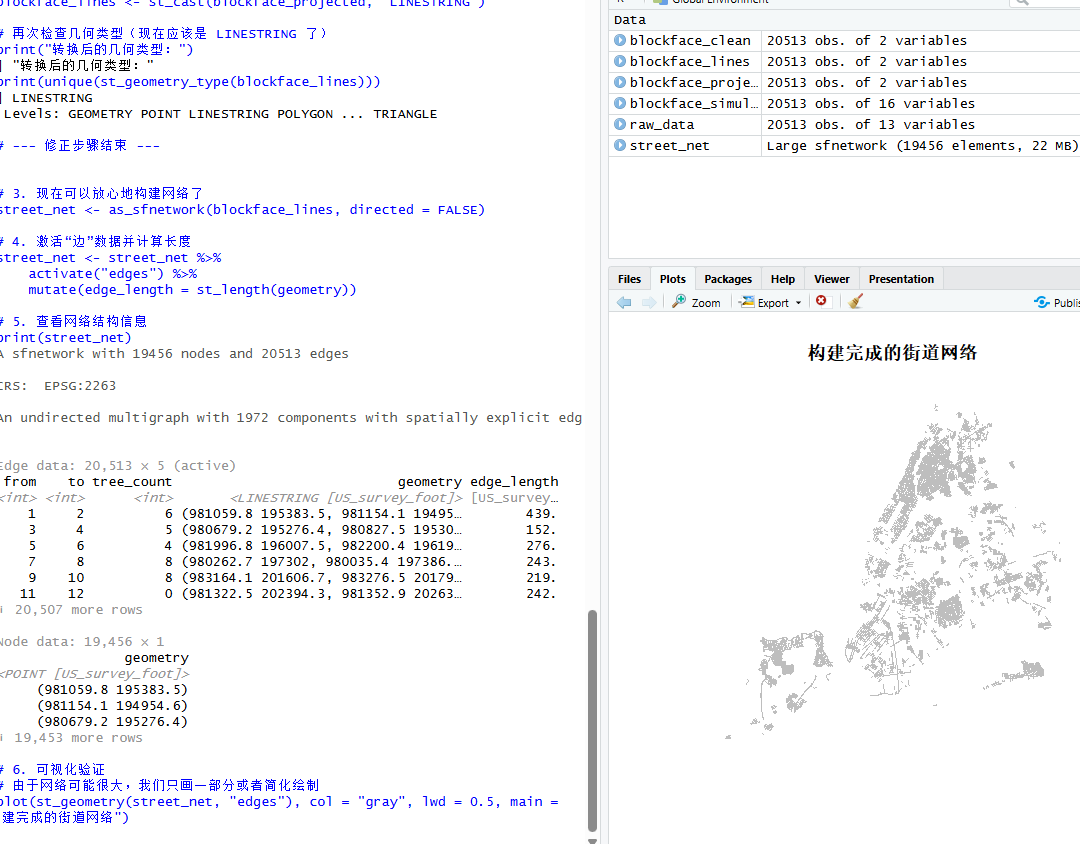
图7 完成运行后的结果
运行这段代码后,可以会发现 street_net 对象中多出了关于节点和边的统计信息。每一条街道都有了它的物理长度(edge_length)和生态属性(tree_count),这张网已经做好了被算法遍历的准备。不过,在正式开始导航之前,我们还需要解决现实数据中常见的一个棘手问题------网络中的断头路和孤岛。
四、 拓扑修复:处理网络断点与提取最大连通子图
在理想的数学模型中,所有的街道都是完美连接的。但在现实世界的地理数据里,情况往往没那么乐观。由于数字化过程中的微小误差,两条本该相交的街道可能在坐标上相差了几厘米,导致计算机认为它们处于断开状态;或者某些偏僻的社区道路可能完全独立于主干道网络之外,形成一个个孤岛。如果直接在这样的网络上规划路线,算法可能会报错,或者规划出一条根本无法到达终点的路径。因此,我们需要针对路径进行拓扑修复。
首先要解决伪断点问题。例如一个十字路口,四条街道本应汇聚于一点,但因为绘图误差,它们可能只是无限接近而没有真正重合。这会导致网络中出现大量不必要的节点,甚至造成路网中断。虽然 sfnetworks 在构建时会自动融合部分节点,但更稳妥的做法是提取网络中的最大连通子图。最大连通子图是这张网络中互相连通的那一部分,而且是包含节点数量最多的那一部分。在城市路网中,这通常对应着城市的主体交通网络。通过提取最大连通子图,我们可以自动剔除那些漂浮在主网之外的细碎孤岛(比如公园里封闭的环形跑道,或者数据错误的悬空路段),确保无论我们选择哪个起点和终点,它们之间都一定存在一条可达的路径。这不仅能提高算法的稳定性,还能大幅减少计算量。
利用 tidygraph 提供的图算法工具,我们可以轻松地给网络中的每个群组打上标签,然后筛选出成员最多的那个群组。复制并粘贴运行以下代码:
R
# 加载必要的包
library(sfnetworks)
library(tidygraph)
library(dplyr)
# 加载 igraph 包以使用 vcount 等底层图论函数
library(igraph)
# 1. 分析网络的连通性
# group_components() 会给网络中每一个独立的连通区域分配一个唯一的 ID
# 我们可以先看看网络被分成了多少个互不相连的"孤岛"
street_net_components <- street_net %>%
activate("nodes") %>%
mutate(component_id = group_components())
# 打印各连通子图的节点数量情况
# 你可能会发现有一个巨大的群组包含绝大多数节点,而其他群组只有寥寥几个节点
# as_tibble() 将结果转为表格以便查看
print(table(street_net_components %>% pull(component_id)))
# 2. 提取最大连通子图
# 我们的目标是只保留那个最大的网络,丢弃那些细碎的孤岛
street_net_connected <- street_net %>%
activate("nodes") %>%
mutate(component_id = group_components()) %>%
# 按照 component_id 分组,计算每个组的大小
group_by(component_id) %>%
mutate(component_size = n()) %>%
ungroup() %>%
# 筛选条件:只保留节点数最多的那个组
filter(component_size == max(component_size))
# 3. 清理与简化
# 提取完子图后,可能会残留一些不再使用的属性,我们可以整理一下
# 并再次激活 'edges' 模式,准备下一步的权重计算
final_street_net <- street_net_connected %>%
activate("edges")
# 4. 验证结果
# 使用 igraph::vcount() 获取节点数量
cat("原始网络节点数:", vcount(street_net), "\n")
cat("最大连通子图节点数:", vcount(final_street_net), "\n")
# 可视化修复后的主干网络
# 注意:如果网络依然很大,绘图可能需要几秒钟
plot(st_geometry(final_street_net, "edges"),
col = "darkgreen", lwd = 0.5,
main = "拓扑修复后的最大连通街道网络")输出结果会包含相应的内容:
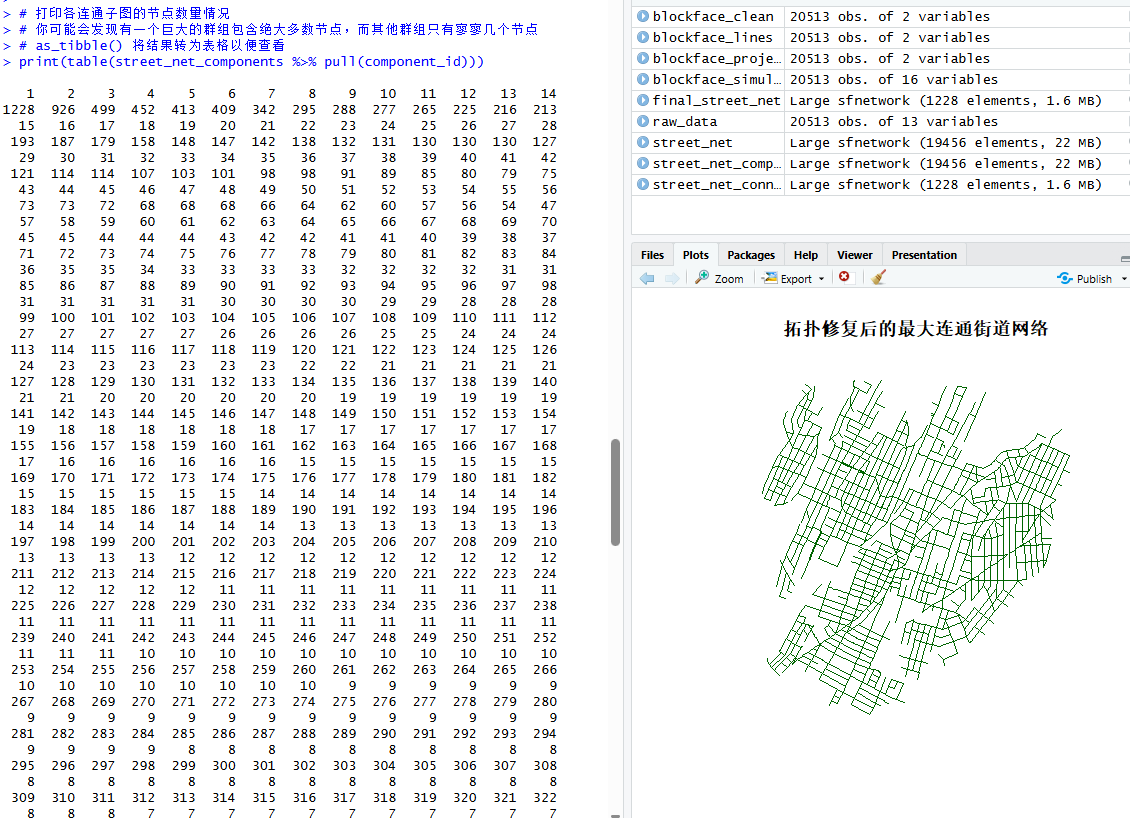
图8 获得的节点数与修复后的网络结果
经过这一步处理,final_street_net 变成了一个干净、紧密互联的网络对象。所有的死路和孤岛都被剥离,剩下的就是城市交通的坚实骨架。现在我们可以放心地在这个骨架上定义绿荫规则,开始规划那条散步路线了。
五、 定义阻抗函数:如何量化街道的"绿荫成本"
在传统的导航算法中,路径规划的核心依据是"阻抗",通常直接等同于距离或时间,即走过 100 米的路,成本就是 100。但在本次案例中,这个逻辑被颠覆了。我们认为走过一条光秃秃的 100 米街道,不仅身体疲惫,心情也烦躁,其实际心理成本可能高达 200;而走过一条绿树成荫的 100 米街道,微风拂面,心情舒畅,其实际心理成本可能只有 50。为了让计算机理解这种人类的感受,我们需要设计一个自定义阻抗函数,目标是创造一个新的权重指标,暂且称之为 green_cost(绿荫成本)。这个指标应该遵循以下逻辑:
1.基础成本是长度:无论风景多美,路毕竟是要一步步走的,所以物理长度仍然是基础。
2.树木是减速带:这里的减速是指减少阻力。树越多,阻力应该越小。
3.树木密度的概念:单纯看树木总数是不够的。一条 10 米长的路有 5 棵树,和一条 1000 米长的路有 5 棵树,绿化体验完全不同。因此,我们需要引入树木密度的概念,即每米长度上的树木数量。
基于上述逻辑,我们可以设计一个简单的公式:
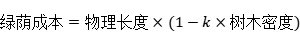
或者更简单直接一点,给每棵树设定一个折扣系数。但在实际操作中,为了避免出现负数成本,我们通常采用加权法:

其中,权重系数与树木密度成反比。如果某条路树很多,权重系数就接近 0.5(相当于距离打五折);如果没树,权重系数就是 1(原价);甚至可以惩罚无树路段,设为 1.5(加价)。
在 R 语言中,我们可以利用 mutate 函数轻松地将这个逻辑应用到网络的每一条边上。我们将计算每条街道的树木密度,并据此生成一个新的权重列 green_weight。复制并粘贴运行以下代码:
R
# 1. 计算树木密度与定义绿荫权重
final_street_net <- final_street_net %>%
activate("edges") %>%
mutate(
# 强制将 tree_count 转换为数值型
# 即使它已经是数字,这一步也是安全的;如果是字符,它会变成数字
tree_count = as.numeric(tree_count),
# 处理 length_val,剥离单位
length_val = as.numeric(edge_length),
# 再次检查是否有 NA 产生(防止转换过程中出现非数字字符变成 NA)
tree_count = ifelse(is.na(tree_count), 0, tree_count),
length_val = ifelse(is.na(length_val), 0.1, length_val), # 防止长度为NA,给个极小值
# 计算树木密度:每英尺有多少棵树
tree_density = tree_count / (length_val + 0.001),
# --- 定义核心阻抗函数 ---
# 逻辑:树越多,权重越小(路越"好走")
# 公式:weight = 1 / (1 + 因子 * 密度)
weight_factor = 1 / (1 + 50 * tree_density),
# 最终计算"绿荫成本"
green_cost = length_val * weight_factor
)
# 2. 查看计算结果
edge_preview <- final_street_net %>%
as_tibble() %>%
select(tree_count, length_val, tree_density, weight_factor, green_cost) %>%
arrange(desc(tree_density))
print("街道绿荫成本预览(前6行):")
print(head(edge_preview))
# 3. 检查数据类型
print(class(final_street_net %>% pull(tree_count)))
print(class(final_street_net %>% pull(length_val)))运行后,可以看到前六行的成本计算预览结果:
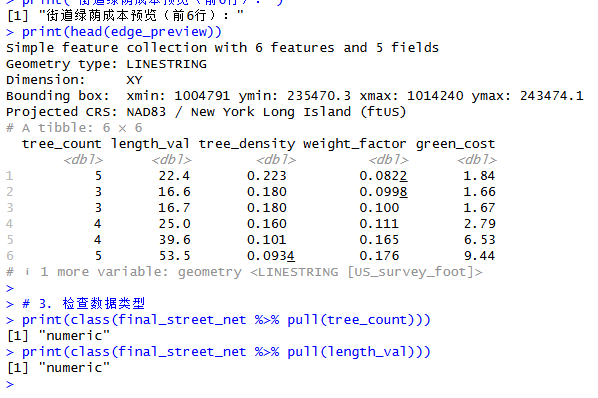
图9 获得的预览结果
通过这段代码,我们实际上完成了一次价值重估。在 green_cost 中,一条 500 米长的林荫大道,可能比一条 300 米长的暴晒小路还要短。计算机并不懂风景,但它懂数字,现在我们已经成功地把风景变成了数字,接下来我们就可以利用算法,开始规划路线。
六、 路径规划实战:基于自定义权重的最短路径算法
现在,我们的网络图 final_street_net 已经拥有了两套截然不同的成本体系:一套是物理距离,另一套是绿荫成本。接下来,我们将在地图上随机选取两个点------起点和终点,并分别命令计算机找出这两点之间的"最优解"。
在 R 语言的 sfnetworks 和 tidygraph 框架下,计算最短路径通常使用经典的 Dijkstra 算法 或 A 算法*。你不需要理解这些算法背后的复杂数学推导,只需要知道它们的作用是:在一个网络中,找到连接两个节点且总权重最小的那条线。我们将进行两次路径搜索:
1.传统模式:权重设为 edge_length。这就是普通地图软件给你的路线,追求物理上的最近。
2.绿荫模式:权重设为 green_cost。这是我们定制的路线,算法会为了降低"绿荫成本"而自动选择绕行那些树木茂密的街道,哪怕物理距离会远一点。
我们随机从网络中抽取两个节点作为起点和终点,复制并粘贴运行以下代码:
R
# 加载路径规划所需的包
library(sfnetworks)
library(tidygraph)
library(sf)
# 1. 确定起点和终点
# 为了演示,我们从网络中随机抽取两个节点 ID
# set.seed 确保每次运行结果一致,方便复现
set.seed(1234)
net_nodes <- st_as_sf(final_street_net, "nodes")
sample_indices <- sample(nrow(net_nodes), 2)
start_node_index <- sample_indices[1]
end_node_index <- sample_indices[2]
cat("起点索引:", start_node_index, " | 终点索引:", end_node_index, "\n")
# 2. 计算【最短路径】 (Shortest Path)
# 使用 st_network_paths 函数
# weights 参数指定为物理长度 edge_length
path_shortest <- st_network_paths(
final_street_net,
from = start_node_index,
to = end_node_index,
weights = "edge_length"
)
# 3. 计算【最绿路径】 (Greenest Path)
# 同样的函数,唯一的区别是 weights 参数改为我们自定义的 green_cost
# 算法会自动倾向于选择 green_cost 小的路段(即树多的路)
path_greenest <- st_network_paths(
final_street_net,
from = start_node_index,
to = end_node_index,
weights = "green_cost"
)
# 4. 提取路径几何形状
# st_network_paths 返回的是节点的索引,我们需要把它转换回具体的街道线条(geometry)
# 这是一个辅助函数,用于从网络中提取路径的几何信息
get_path_geometry <- function(net, path_indices) {
# 提取路径经过的节点索引
node_indices <- unlist(path_indices$node_paths)
# 利用 slice 提取这些节点,然后提取它们之间的边
# 注意:这里简化处理,直接提取节点连线可能不够精确,
# 更严谨的做法是提取 edge_paths
edge_indices <- unlist(path_indices$edge_paths)
net %>%
activate("edges") %>%
slice(edge_indices) %>%
st_as_sf()
}
# 获取两条路径的实际形状
geometry_shortest <- get_path_geometry(final_street_net, path_shortest)
geometry_greenest <- get_path_geometry(final_street_net, path_greenest)
# 5. 计算结果对比
# 让我们看看为了"绿",我们多走了多少路
length_shortest <- sum(geometry_shortest$edge_length)
length_greenest <- sum(geometry_greenest$edge_length)
cat("=== 路线对比 ===\n")
cat("匆忙的最短路线长度:", round(length_shortest, 2), "英尺\n")
cat("惬意的最绿路线长度:", round(length_greenest, 2), "英尺\n")
cat("为了风景多走的距离:", round(length_greenest - length_shortest, 2), "英尺 (+",
round((length_greenest - length_shortest)/length_shortest * 100, 1), "%)\n")
# 6. 简单绘图预览
# 绘制底图(灰色背景路网)
plot(st_geometry(final_street_net, "edges"), col = "gray90", lwd = 0.5, main = "路线对比")
# 绘制最短路径(红色)
# 使用 st_geometry 确保只绘制线条,避免属性列干扰
plot(st_geometry(geometry_shortest), col = "red", lwd = 2, add = TRUE)
# 绘制最绿路径(深绿色)
plot(st_geometry(geometry_greenest), col = "darkgreen", lwd = 2, add = TRUE)
# 绘制起点和终点(蓝色圆点)
# 使用 st_geometry() 包裹节点对象
# 这样 R 就只处理点的坐标,不会去查属性表,从而避免报错
start_end_points <- net_nodes[c(start_node_index, end_node_index), ]
plot(st_geometry(start_end_points), col = "blue", pch = 19, cex = 1.5, add = TRUE)
# 添加图例
legend("topright", legend = c("最短路线", "最绿路线", "起终点"),
col = c("red", "darkgreen", "blue"), lwd = c(2, 2, NA), pch = c(NA, NA, 19))运行结果后可以发现,路线已经完成了计算,并被标记在了处理过后的网络图之上:
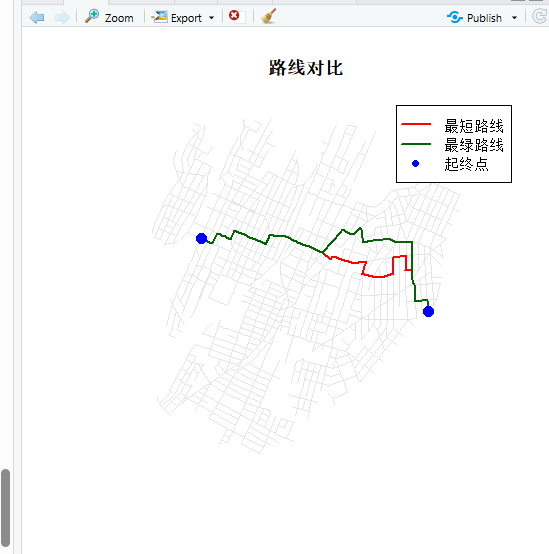
图10 完成计算后的预览图
七、 可视化对比:匆忙的"最短路线" 和 惬意的"最绿路线"
作为地理空间分析,没有什么比一张清晰的对比地图更有说服力了。我们需要验证:那条所谓的"最绿路线",是否真的避开了光秃秃的水泥路,穿过了树木茂密的街区?在这一部分,我们将不再满足于基础的 plot 绘图,而是引入 R 语言中专业的专题地图制作包 tmap。它采用图层叠加的语法逻辑,允许我们将街道背景、树木密度分布、以及两条截然不同的规划路线叠加在一起,制作出一张既美观又具分析价值的地图。我们将以树木密度作为背景底色,直观地展示城市绿肺的分布,并将两条路线高亮显示,从而一目了然地看到算法的决策逻辑。
复制并粘贴运行以下代码:
R
library(ggplot2)
library(sf)
library(dplyr)
# 1. 数据优化:引入"相对排名"
# 我们不直接画绝对密度,而是把所有街道按密度排队,分成 10 个等级 (Deciles)
# 这样保证了地图上一定有 10% 的最深绿,和 10% 的最浅灰
background_edges_viz <- st_as_sf(final_street_net, "edges") %>%
mutate(
# ntile 函数将数据分为 10 份,1 代表密度最低的 10%,10 代表密度最高的 10%
density_rank = ntile(tree_density, 10)
) %>%
arrange(density_rank) # 排序,确保深色的画在上面
# 2. 绘制分级可视化地图
viz_plot_final <- ggplot() +
# --- 图层 1:背景路网 (基于排名着色) ---
geom_sf(data = background_edges_viz,
aes(color = as.factor(density_rank)), # 将排名转为因子,变成离散颜色
size = 1.2,
alpha = 1) +
# 使用离散的渐变色板:从灰到绿
scale_color_manual(
values = colorRampPalette(c("gray90", "palegreen", "darkgreen"))(10),
name = "绿荫等级 (1-10级)",
guide = guide_legend(nrow = 1) # 图例横向排列
) +
# --- 图层 2:最短路径(红色) ---
geom_sf(data = geometry_shortest,
color = "red",
size = 1.5,
alpha = 0.9) +
# --- 图层 3:最绿路径(蓝色虚线) ---
geom_sf(data = geometry_greenest,
color = "blue",
size = 1.5,
linetype = "dashed",
alpha = 0.9) +
# --- 图层 4:起点和终点 ---
geom_sf(data = start_end_points,
color = "black",
fill = "yellow",
shape = 21,
size = 5,
stroke = 1.5) +
# --- 图层 5:美化 ---
labs(title = "路径规划对比:效率优先 vs 绿荫优先",
subtitle = "背景已按密度排名分级:等级越高,树木相对越密",
caption = "数据来源:2015 Street Tree Census") +
theme_void() +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
plot.subtitle = element_text(hjust = 0.5, size = 12),
legend.position = "bottom",
legend.title = element_text(size = 10),
legend.key.width = unit(1, "cm")
)
# 3. 输出最终地图
print(viz_plot_final)运行代码后,可以发现结果已经得到了输出:

图11 完成输出的结果
观察生成的地图,可以清晰地看到两条路线的差异逻辑:
1.红色路线(最短路径):红线径直连接了起点和终点。它毫不犹豫地穿过了地图中间颜色较浅(树木较少)的区域,因为它只在乎距离的缩短,不在乎头顶是否有烈日。
2.深蓝路线(最绿路径):这条虚线则显得更加蜿蜒。在某些路口,它明显偏离了直线方向,特意绕行到了旁边深绿色的街道上。虽然这让路线看起来稍微弯曲了一些,但它成功地将行人的大部分行程锁定在了高密度的绿荫之下。
通过这次实战,我们不仅学会了如何清洗地理数据、构建拓扑网络,更重要的是,我们掌握了利用 R 语言自定义成本的能力。这些技巧可以应用到地理数据的处理工作中,让 R 语言的作用得到充分的发挥。