文章目录
- [Hadoop 云网盘管理系统开发实践](#Hadoop 云网盘管理系统开发实践)
-
- 前言
- 一、项目概述
- 二、技术架构
-
- [2.1 技术栈选择](#2.1 技术栈选择)
- [2.2 技术选型理由](#2.2 技术选型理由)
- 三、数据库设计
-
- [3.1 ER 图](#3.1 ER 图)
- [3.2 核心表结构](#3.2 核心表结构)
- 四、核心功能实现
-
- [4.1 HDFS 集成](#4.1 HDFS 集成)
- [4.2 文件上传与大小计算](#4.2 文件上传与大小计算)
- [4.3 智能排序功能](#4.3 智能排序功能)
- [4.4 下载统计分析](#4.4 下载统计分析)
- 五、项目结构
- 六、部署与运维
-
- [6.1 环境要求](#6.1 环境要求)
- [6.2 数据库配置](#6.2 数据库配置)
- [6.3 测试账号](#6.3 测试账号)
- 七、总结与展望
-
- [7.1 项目收获](#7.1 项目收获)
- [7.2 待完善功能](#7.2 待完善功能)
- 参考资料
Hadoop 云网盘管理系统开发实践
基于 SSM 框架 + HDFS 分布式存储的企业级云盘系统
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!(有什么问题可以私信)前言
在日常工作和学习中,我们经常需要管理大量的文档资料。传统的本地存储方式存在诸多不便:文件分散难以统一管理、跨设备访问困难、数据安全性无法保障等。因此,我开发了 NetWorkBase ------ 一个基于云端的文档管理系统。
本文将详细介绍这个项目的设计思路、技术选型、核心功能实现以及踩坑经验,希望能为有类似开发需求的朋友提供一些参考。
一、项目概述
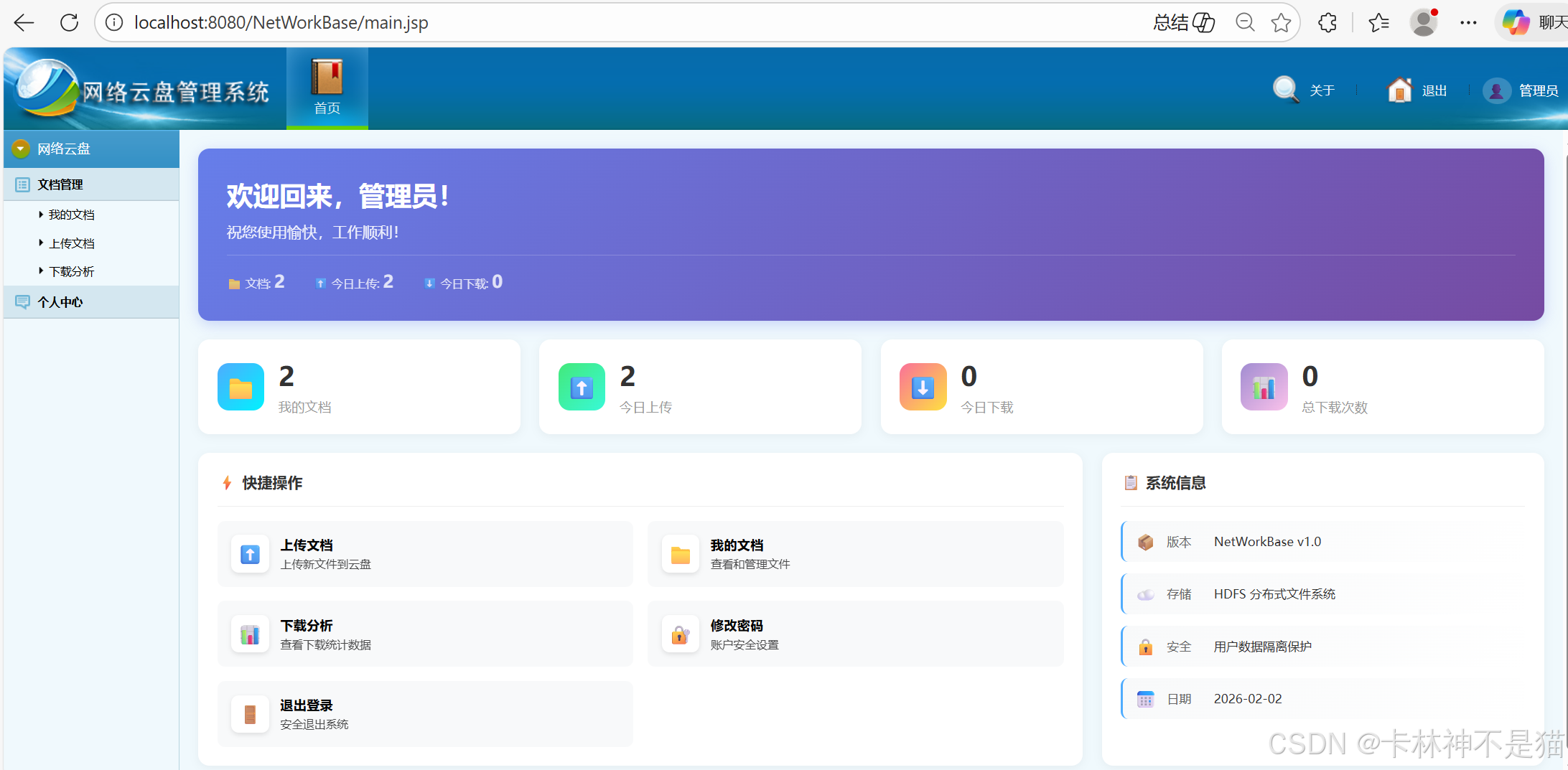
NetWorkBase 是一个面向个人和小型团队的云文档管理系统,主要特点包括:
-
云端存储 :采用 Hadoop HDFS 作为分布式存储后端,突破单机存储限制
-
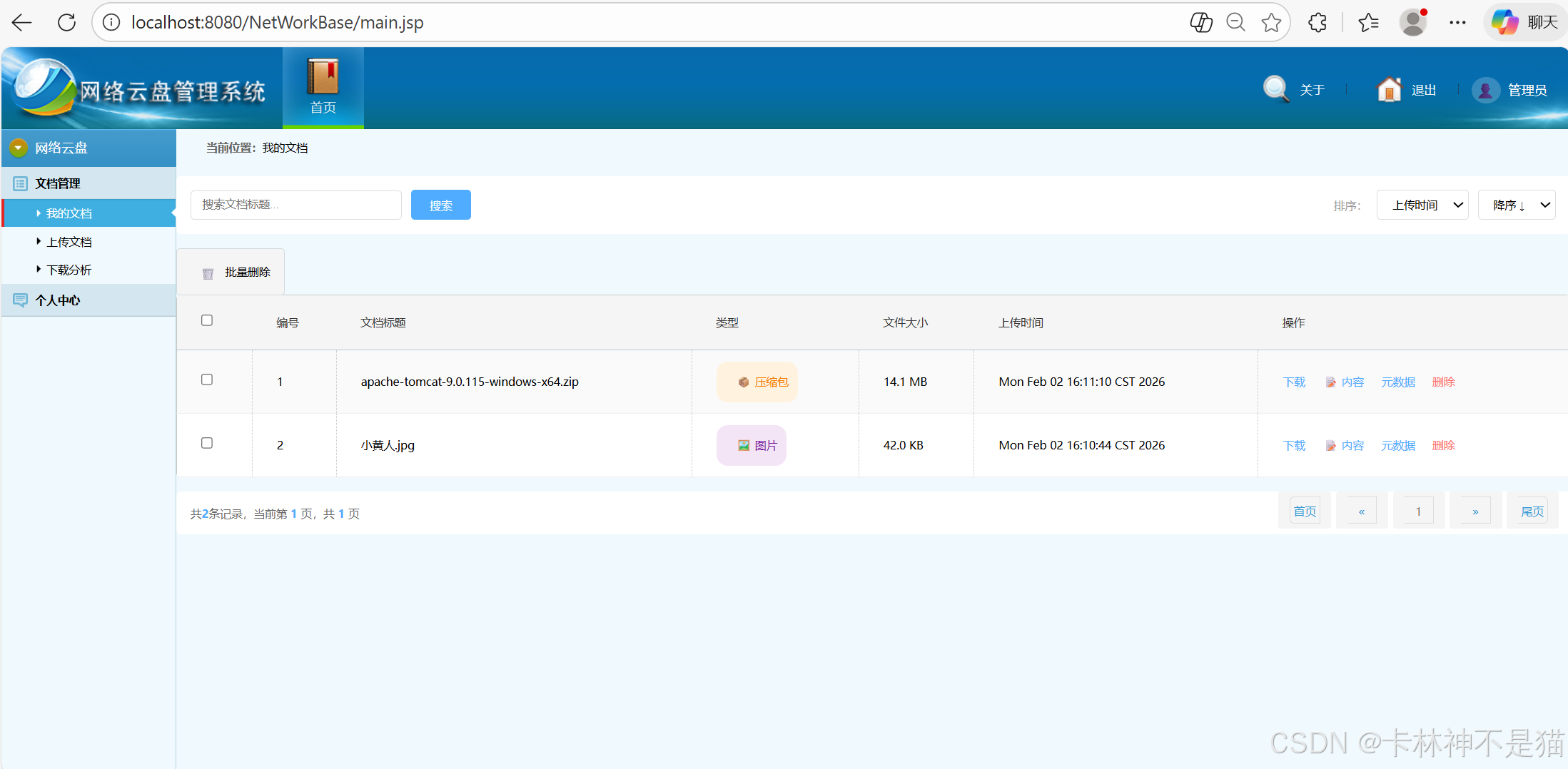
文档管理 :支持文件上传、下载、分类、搜索、排序等功能
-
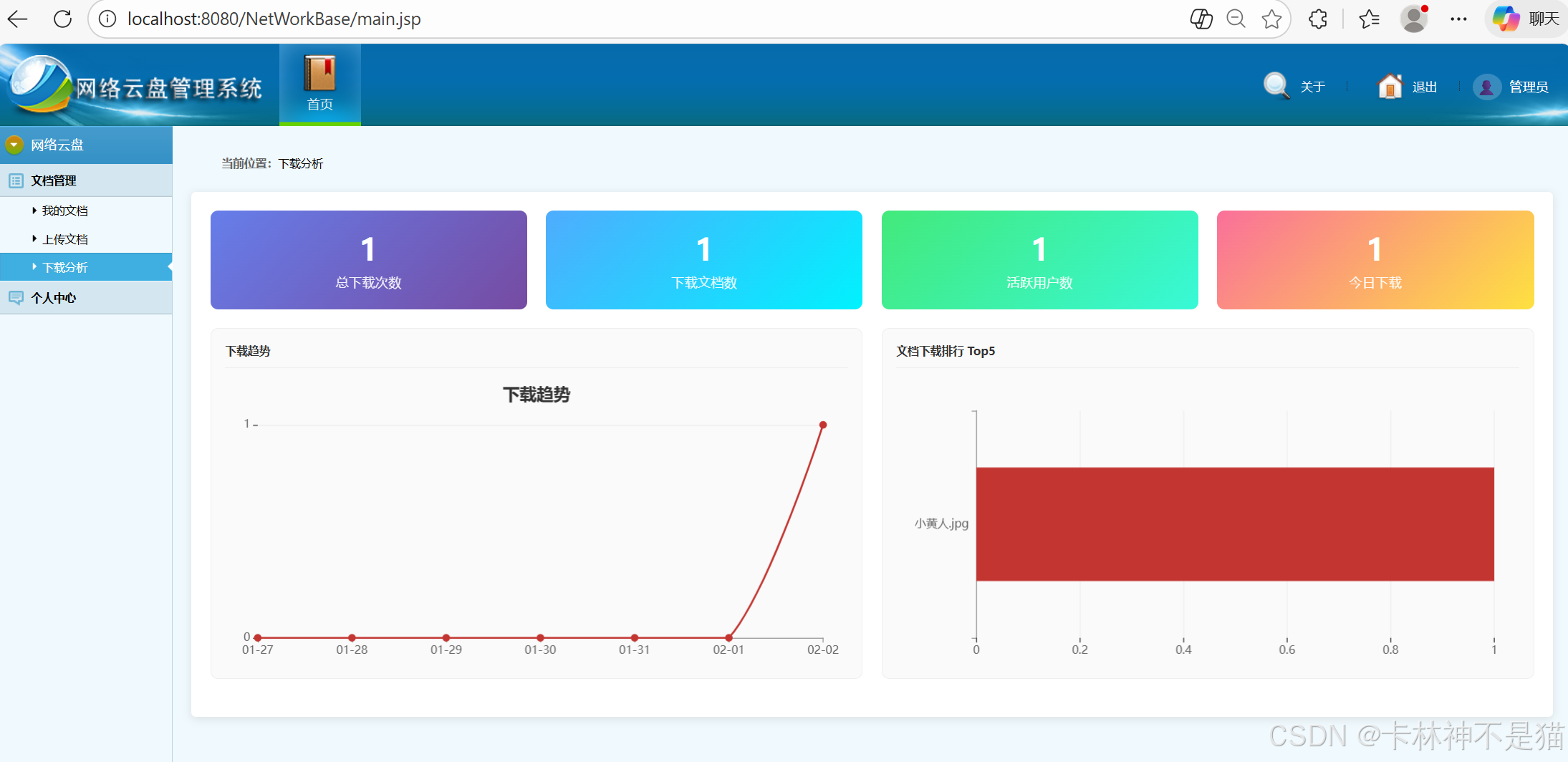
数据分析 :提供下载统计分析,包括趋势图和排行榜
-
简洁易用 :采用响应式设计,界面简洁直观
核心功能清单
| 功能模块 | 功能列表 |
|---|---|
| 用户管理 | 注册、登录、修改密码、头像设置 |
| 文档管理 | 上传、下载、搜索、排序、分类显示、批量删除 |
| HDFS 集成 | 分布式存储、目录管理、文件读写 |
| 数据统计 | 下载趋势、文档排行、用户活跃度 |
二、技术架构
2.1 技术栈选择
本项目采用经典的 SSM 架构,结合大数据组件进行扩展:
┌─────────────────────────────────────────────────────────┐
│ 前端层 │
│ JSP + jQuery + Bootstrap + ECharts │
├─────────────────────────────────────────────────────────┤
│ 控制层 │
│ Spring MVC (Controller) │
├─────────────────────────────────────────────────────────┤
│ 业务层 │
│ Spring Framework 5.2.8 │
├─────────────────────────────────────────────────────────┤
│ 持久层 │
│ MyBatis 3.5.19 + MySQL 8.0 │
├─────────────────────────────────────────────────────────┤
│ 存储层 │
│ Hadoop HDFS 3.3.0 + C3P0 连接池 │
└─────────────────────────────────────────────────────────┘2.2 技术选型理由
| 技术 | 选用理由 |
|---|---|
| Spring 5.2.8 | 成熟的 IOC/AOP 容器,管理对象生命周期 |
| MyBatis 3.5.19 | 灵活的 SQL 映射,学习成本低 |
| MySQL 8.0 | 支持 JSON、窗口函数等新特性 |
| Hadoop HDFS | 开源分布式存储,可靠性高 |
| ECharts | 图表丰富,文档完善 |
| PageHelper | 无侵入式分页,集成简单 |
三、数据库设计
3.1 ER 图
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ user │ │ docs │ │ downlog │
├──────────────┤ ├──────────────┤ ├──────────────┤
│ id │ │ id │ │ id │
│ zh (账号) │ │ title │ │ title │
│ mm (密码) │ │ type │ │ author │
│ name │ │ url │ │ downdate │
│ avatar │◄──────│ filesize │ │ num │
│ │ │ author ──────┼──────►│ │
│ │ │ createdate │ │ │
└──────────────┘ └──────────────┘ └──────────────┘3.2 核心表结构
sql
-- 用户表
CREATE TABLE `user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`zh` VARCHAR(50) NOT NULL COMMENT '账号',
`mm` VARCHAR(100) NOT NULL COMMENT '密码(MD5)',
`name` VARCHAR(50) DEFAULT NULL COMMENT '姓名',
`avatar` TEXT COMMENT '头像数据',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_zh` (`zh`)
);
-- 文档表
CREATE TABLE `docs` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`title` VARCHAR(200) NOT NULL COMMENT '文档标题',
`type` VARCHAR(50) DEFAULT NULL COMMENT '文档类型',
`url` VARCHAR(500) NOT NULL COMMENT 'HDFS路径',
`filesize` VARCHAR(50) DEFAULT NULL COMMENT '文件大小',
`author` VARCHAR(50) DEFAULT NULL COMMENT '作者',
`createdate` DATETIME DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
);
-- 下载日志表
CREATE TABLE `downlog` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`title` VARCHAR(200) DEFAULT NULL COMMENT '文档标题',
`author` VARCHAR(50) DEFAULT NULL COMMENT '下载用户',
`downdate` DATETIME DEFAULT NULL COMMENT '下载时间',
`num` INT(11) DEFAULT 1 COMMENT '下载次数',
PRIMARY KEY (`id`)
);四、核心功能实现
4.1 HDFS 集成
HDFSUtil 是连接 HDFS 的核心工具类:
java
@Service
public class HDFSUtil {
static Configuration conf;
static FileSystem fs;
static {
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://node1:9820");
System.setProperty("HADOOP_USER_NAME", "root");
fs = FileSystem.get(conf);
}
// 上传文件
public void upload(String fileName, InputStream in) {
FSDataOutputStream out = fs.create(new Path(fileName));
IOUtils.copy(in, out);
out.close();
}
// 下载文件
public InputStream down(String strPath) {
return fs.open(new Path(strPath));
}
// 创建用户目录
public void createDir(String dir) {
fs.mkdirs(new Path("/" + dir + "/"));
}
}关键点:
- 设置
HADOOP_USER_NAME确保权限 - 使用
IOUtils.copy()高效复制流 - 支持用户隔离,每个用户一个 HDFS 目录
4.2 文件上传与大小计算
java
@RequestMapping("upload")
public String upload(@RequestParam("myfile") MultipartFile multipartFile,
String title, String type, HttpSession session) {
String zh = (String) session.getAttribute("zh");
String fileName = multipartFile.getOriginalFilename();
// 自动计算文件大小
long size = multipartFile.getSize();
String fileSize = formatFileSize(size);
// 上传到 HDFS
String filePath = "/" + zh + "/" + fileName;
hdfsUtil.upload(filePath, multipartFile.getInputStream());
// 保存到数据库
docsService.insertDocs(title, type, filePath, fileSize, zh);
return "search";
}
// 格式化文件大小
private String formatFileSize(long size) {
if (size < 1024) return size + " B";
if (size < 1024 * 1024) return String.format("%.1f KB", size / 1024.0);
if (size < 1024 * 1024 * 1024) return String.format("%.1f MB", size / (1024.0 * 1024));
return String.format("%.1f GB", size / (1024.0 * 1024 * 1024));
}4.3 智能排序功能
按文件大小排序时,需要统一单位才能正确比较:
java
// MyBatis 动态 SQL
@Select("<script>" +
"SELECT * FROM docs WHERE author=#{author} " +
"<choose>" +
"<when test='sortBy == \"filesize\"'>" +
"ORDER BY CASE " +
" WHEN filesize LIKE '%GB' THEN CAST(REPLACE(filesize, 'GB', '') AS DECIMAL(10,2)) * 1024 * 1024 " +
" WHEN filesize LIKE '%MB' THEN CAST(REPLACE(filesize, 'MB', '') AS DECIMAL(10,2)) * 1024 " +
" WHEN filesize LIKE '%KB' THEN CAST(REPLACE(filesize, 'KB', '') AS DECIMAL(10,2)) " +
"END ${order}" +
"</when>" +
"<otherwise>ORDER BY createdate DESC</otherwise>" +
"</choose>" +
"</script>")
List<Docs> search(@Param("author") String author,
@Param("sortBy") String sortBy,
@Param("order") String order);前端排序下拉框:
jsp
<select name="sortBy" onchange="this.form.submit()">
<option value="createdate" ${sortBy == 'createdate' ? 'selected' : ''}>上传时间</option>
<option value="type" ${sortBy == 'type' ? 'selected' : ''}>文件类型</option>
<option value="filesize" ${sortBy == 'filesize' ? 'selected' : ''}>文件大小</option>
</select>
<select name="order" onchange="this.form.submit()">
<option value="desc" ${order == 'desc' ? 'selected' : ''}>降序 ↓</option>
<option value="asc" ${order == 'asc' ? 'selected' : ''}>升序 ↑</option>
</select>4.4 下载统计分析
使用 ECharts 展示下载趋势和排行:
javascript
// 加载7天下载趋势
$.ajax({
url: 'downTrend7Days',
success: function(data) {
trendChart.setOption({
xAxis: { data: data.dates },
series: [{ data: data.values, type: 'line' }]
});
}
});效果展示:
- 折线图:展示最近7天下载量变化趋势
- 柱状图:Top 5 下载排行文档
五、项目结构
src/main/java/com/mqmmw/
├── controller/ # 控制器层
│ ├── DocsController.java # 文档上传下载
│ ├── UserController.java # 用户登录注册
│ └── DownController.java # 下载统计
├── mapper/ # MyBatis 接口
│ ├── DocsMapper.java
│ ├── UserMapper.java
│ └── DownlogMapper.java
├── pojo/ # 实体类
│ ├── Docs.java
│ ├── User.java
│ └── Downlog.java
├── service/ # 业务逻辑
│ ├── DocsService.java
│ ├── UserService.java
│ ├── DownlogService.java
│ └── HDFSUtil.java # HDFS 操作工具
└── util/ # 工具类
└── StringUtil.java六、部署与运维
6.1 环境要求
| 软件 | 版本 |
|---|---|
| JDK | 1.8+ |
| MySQL | 8.0+ |
| Tomcat | 9.0+ |
| Hadoop | 3.3.0+ |
6.2 数据库配置
在 spring.xml 中配置:
xml
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.cj.jdbc.Driver" />
<property name="jdbcUrl" value="jdbc:mysql://node1:3306/doccloud" />
<property name="user" value="root" />
<property name="password" value="hadoop" />
</bean>6.3 测试账号
| 账号 | 密码 |
|---|---|
| admin | 123456 |
| test | 123456 |
七、总结与展望
7.1 项目收获
通过这个项目,我学习到了:
- SSM 框架整合:理解 Spring、Spring MVC、MyBatis 的协作方式
- Hadoop HDFS:掌握分布式存储的基本操作
- 前后端交互:AJAX 异步请求、JSON 数据处理
- 数据库设计:合理的表结构设计、索引优化
- 用户体验优化:排序、搜索、分页等交互设计
7.2 待完善功能
- 文件分享功能(生成链接)
- 文件夹管理(支持多级目录)
- 文件预览(在线查看文档)
- 移动端适配