使用 Ollama 将本地大型语言模型 (LLM) 集成到 Python 项目中,是提高隐私性、降低成本和构建可离线使用的 AI 应用的绝佳策略。
Ollama 是一个开源平台,可让您轻松地在本地计算机上运行现代线性模型 (LLM)。设置好 Ollama 并拉取所需模型后,即可使用ollama库从 Python 连接到这些模型。
在本教程中,使用 Ollama 平台及其 Python SDK 将本地 LLM 集成到 Python 项目中。
首先,设置 Ollama 并获取几个 LLM。然后,学习如何在 Python 代码中使用聊天、文本生成和工具调用功能。这些技能将能够构建本地运行的 AI 应用,从而提高隐私保护和成本效益。
先决条件
要完成本教程,需要以下资源和设置:
- Ollama 已安装并运行:需要Ollama才能使用本地 LLM。下一节将介绍如何安装和设置它。
- Python 3.8 或更高版本:使用 Ollama 的 Python 软件开发工具包 (SDK),该工具包需要 Python 3.8 或更高版本。
- 使用的模型 :本教程将使用
llama3.2:latest和codellama:latest这两个模型。在下一节中下载它们。 - 硬件要求:需要性能相对强大的硬件才能在本地运行 Ollama 的模型,因为它们可能需要大量的资源,包括内存、磁盘空间和 CPU 性能。本教程可能不需要 GPU,但如果您有 GPU,本地模型的运行速度会快得多。
具备这些先决条件后,就可以使用 Ollama 将本地模型连接到您的 Python 代码了。
步骤 1:设置 Ollama、模型和 Python SDK
在能够使用 Python 调用本地模型之前,需要运行 Ollama 并至少下载一个模型。在本步骤中,安装 Ollama,启动其后台服务,并拉取您在整个教程中将要使用的模型。
让ollama奔跑
首先,请访问 Ollama 的下载页面,并获取适用于您当前操作系统的安装程序。
在 Windows 系统中,Ollama 安装完成后会在后台运行,您可以使用其命令行界面 (CLI)。如果 Ollama 没有自动运行,请打开*"开始"*菜单,搜索 Ollama,然后运行该应用程序。
在 macOS 上,该应用程序管理 CLI 和设置详细信息,因此您只需启动Ollama.app即可。
如果您使用的是 Linux 系统,请使用以下命令安装 Ollama:
$ curl -fsSL https://ollama.com/install.sh | sh安装完成后,您可以通过运行以下命令来验证安装:
$ ollama -v如果此命令有效,则表示安装成功。接下来,运行以下命令启动 Ollama 服务:
$ ollama serve好了!现在你可以在本地计算机上开始使用 Ollama 了。在某些 Linux 发行版(例如 Ubuntu)中,可能不需要执行最后一条命令,因为 Ollama 可能会在安装完成后自动启动。在这种情况下,运行上述命令将会报错。
提取所需模型
Ollama 安装并运行后,即可下载所需的模型。您必须有足够的可用磁盘空间才能完成此过程。例如, llama3.2:latest模型需要 2.0 GB 的空间,而codellama:latest模型需要 3.8 GB 的空间。
要提取模型,请运行以下命令:
$ ollama pull llama3.2:latest
$ ollama pull codellama:latest这些命令需要一些时间才能完成,因为它们会将模型下载到您的本地驱动器。
**注意:**如果您熟悉Docker及其工作流程,就会发现 Ollama 的 CLI 工作方式与之类似。您可以像拉取 Docker 镜像一样拉取 模型,然后在本地运行它们。
模型下载完成后,您可以通过命令行进行尝试:
$ ollama run llama3.2:latest
>>> Explain what Python is in one sentence.
Python is a high-level, interpreted programming language known for its
simplicity, readability, and versatility, often used for web development,
data analysis, machine learning, automation, and more.如果成功运行了此提示符,则即可从 Python 连接。您可以按Ctrl + D退出聊天。
安装 Ollama 的 Python SDK
Ollama 提供了一个 Python 库,可以在 Python 应用程序和项目中使用本地模型。您可以使用以下命令从PyPI将该库安装到虚拟环境中:
(venv) $ python -m pip install ollama该库也称为 Ollama Python SDK(软件开发工具包),它提供了将 Python 项目与 Ollama 集成的推荐方法。
步骤 2:从 Python 生成文本和代码
Ollama Python 库提供了两个主要工具,用于从代码中与本地模型进行交互:
- **
ollama.chat()**用于基于角色的多轮对话。它非常适合构建具有多轮交互和上下文信息的助手。 - **
ollama.generate()**用于生成一次性提示。它适用于草稿撰写、重写、总结和代码生成。
在接下来的章节中,学习如何使用这些工具将本地LLM集成到您的 Python 应用程序和项目中。
与 Ollama 的聊天界面互动
以下是一个用 Python 编写的最小聊天示例,类似于上一节中的命令行示例:
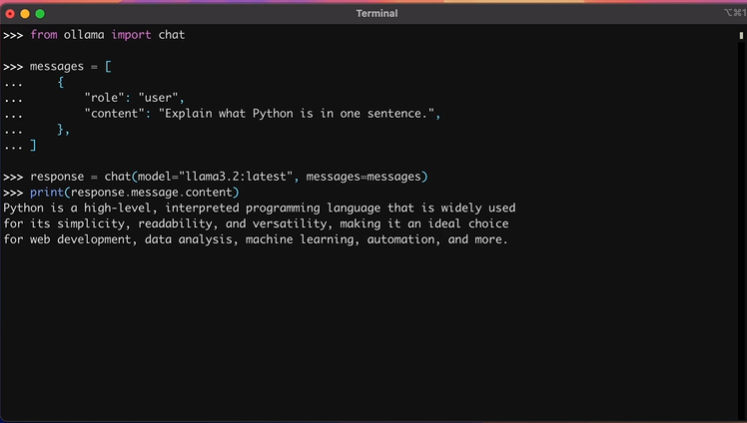
>>> from ollama import chat
>>> messages = [
... {
... "role": "user",
... "content": "Explain what Python is in one sentence.",
... },
... ]
>>> response = chat(model="llama3.2:latest", messages=messages)
>>> print(response.message.content)
Python is a high-level, interpreted programming language that is widely used
for its simplicity, readability, and versatility, making it an ideal choice
for web development, data analysis, machine learning, automation, and more.在这个例子中,你应该考虑以下几个关于消息的事项:
messages是一个字典列表,因为聊天界面是为多轮对话而设计的。- 每条消息都以 Python 字典的形式表示,其中包含
role和content键,以及相应的值。
调用chat()函数,并将模型和你的消息作为参数传递,会生成一个包含多个属性的ChatResponse对象。要获取生成的回复,你可以访问response.message.content属性。
为了保持当前对话的上下文,您可以附加模型的回复并提出后续问题。例如,您可以围绕 Python列表推导式展开对话:
>>> messages = [
... {"role": "system", "content": "You are an expert Python tutor."},
... {
... "role": "user",
... "content": "Define list comprehensions in a sentence."
... },
... ]
>>> response = chat(model="llama3.2:latest", messages=messages)
>>> print(response.message.content)
List comprehensions are a concise and expressive way to create new lists
by performing operations on existing lists or iterables, using a compact
syntax that combines conditional statements and iteration.
>>> messages.append(response.message) # Keep context
>>> messages.append(
... {
... "role": "user",
... "content": "Provide a short, practical example."
... }
... )
>>> response = chat(model="llama3.2:latest", messages=messages)
>>> print(response.message.content)
Here's an example of a list comprehension:
```python
numbers = [1, 2, 3, 4, 5]
double_numbers = [num * 2 for num in numbers if num % 2 == 0]
print(double_numbers) # Output: [2, 4, 6]
```在这个例子中,你要将numbers列表中的每个数字乘以 2,然后只保留原数字为偶数的结果。
在这里,你发起了一场关于 Python 列表推导式的对话。模型回复后,你将答案添加到消息列表中,以便模型将其用作上下文。接下来,你运行另一次聊天交互,并获取基于提供的上下文的响应。
如果您正在构建命令行界面 (CLI)和聊天应用程序,那么 chat streaming(聊天流)功能可以让模型响应更具交互性和流畅性。请参考以下脚本:
streams.py
from ollama import chat
stream = chat(
model="llama3.2:latest",
messages=[
{
"role": "user",
"content": "Explain Python dataclasses with a quick example."
}
],
stream=True,
)
for chunk in stream:
print(chunk.message.content, end="", flush=True)这段代码的关键在于stream参数。将其设置为True后, chat()函数会返回一个迭代器,该迭代器会在收到部分响应时将其返回。这样,你就可以逐步打印或渲染助手的消息,而无需等待完整的响应。
请从命令行运行该脚本,看看它是如何运行的!
使用 Ollama 的文本生成界面
如果您不需要保持对话的上下文,那么generate()函数非常适合您。此函数允许您对目标模型运行一次性提示。其工作原理如下:
>>> from ollama import generate
>>> response = generate(
... model="llama3.2:latest",
... prompt="Explain what Python is in one sentence."
... )
>>> print(response.response)
Python is a high-level, interpreted programming language known for its
simplicity, readability, and versatility. It is widely used in various
fields such as web development, data analysis, artificial intelligence,
and more.generate()函数对于一次性任务非常方便,例如文本的概括、重写或改写。
您还可以使用此函数生成 Python 代码。例如,假设您希望模型帮助您编写一个自定义函数来实现FizzBuzz挑战,其中需要遍历一系列数字并将某些值替换为单词,如下所示:
- **"Fizz"**表示3的倍数
- **"Buzz"**表示5的倍数
- **"FizzBuzz"**表示3和5的倍数。
以下提示要求模型生成此挑战的基本实现:
>>> from ollama import generate
>>> prompt = """
... Write a Python function fizzbuzz(n: int) -> List[str] that:
...
... - Returns a list of strings for the numbers 1..n
... - Uses "Fizz" for multiples of 3
... - Uses "Buzz" for multiples of 5
... - Uses "FizzBuzz" for multiples of both 3 and 5
... - Uses the number itself (as a string) otherwise
... - Raises ValueError if n < 1
...
... Include type hints compatible with Python 3.8.
... """
>>> response = generate(model="codellama:latest", prompt=prompt)
>>> print(response.response)
```
from typing import List
def fizzbuzz(n: int) -> List[str]:
if n < 1:
raise ValueError("n must be greater than or equal to 1")
result = []
for i in range(1, n+1):
if i % 3 == 0 and i % 5 == 0:
result.append("FizzBuzz")
elif i % 3 == 0:
result.append("Fizz")
elif i % 5 == 0:
result.append("Buzz")
else:
result.append(str(i))
return result
```在这个例子中,你使用了codellama:latest模型,该模型旨在根据自然语言提示词生成代码。
模型生成代码后,请检查代码并进行快速测试。将生成的代码复制到REPL会话中,并以整数作为参数调用它:
>>> from typing import List
>>> def fizzbuzz(n: int) -> List[str]:
... if n < 1:
... raise ValueError("n must be greater than or equal to 1")
... result = []
... for i in range(1, n+1):
... if i % 3 == 0 and i % 5 == 0:
... result.append("FizzBuzz")
... elif i % 3 == 0:
... result.append("Fizz")
... elif i % 5 == 0:
... result.append("Buzz")
... else:
... result.append(str(i))
... return result
...
>>> fizzbuzz(16)
['1', '2', 'Fizz', '4', 'Buzz', 'Fizz', ..., 'FizzBuzz', '16']不错!代码运行正常。您可以尝试其他提示词,并让模型构建辅助函数、类等等。
步骤 3:使用工具调用获取增强答案
工具调用(也称为函数调用)使模型能够调用 Python 函数,并将结果用作上下文信息,从而提供更优质的响应。这项技术可用于检索增强生成 (RAG) ,帮助您获得更准确、更及时、更贴合主题的响应。
了解工具调用工作流程
在尝试在代码中使用工具调用之前,请注意此功能取决于模型的自身功能。因此,请确保使用已知支持工具调用的模型。在本教程中,您使用的是llama3.2:latest模型,该模型支持此功能。
工具调用的高级流程大致如下:
- 将相关工具定义为 Python 函数。
- 将工具和提示词一起发送。
- 在代码中执行所选工具。
- 将工具执行结果作为**
role="tool"**消息附加。 - 使用工具的结果生成最终答案。
现在你已经了解了高级工作流程,你可以用 Python 实现工具调用,并通过一个完整的示例来逐步了解。
在 Python 中实现工具调用
要查看工具调用的实际效果,您可以定义一个简单的 Python 函数,并将其作为工具传递给模型。以下是使用square_root()函数的示例:
tool_calling.py
import math
from ollama import chat
# Define a tool as a Python function
def square_root(number: float) -> float:
"""Calculate the square root of a number.
Args:
number: The number to calculate the square root for.
Returns:
The square root of the number.
"""
return math.sqrt(number)
messages = [
{
"role": "user",
"content": "What is the square root of 36?",
}
]
response = chat(
model="llama3.2:latest",
messages=messages,
tools=[square_root] # Pass the tools along with the prompt
)
# Append the response for context
messages.append(response.message)
if response.message.tool_calls:
tool = response.message.tool_calls[0]
# Call the tool
result = square_root(float(tool.function.arguments["number"]))
# Append the tool result
messages.append(
{
"role": "tool",
"tool_name": tool.function.name,
"content": str(result),
}
)
# Obtain the final answer
final_response = chat(model="llama3.2:latest", messages=messages)
print(final_response.message.content)在定义工具时,清晰的文档字符串和类型提示可以帮助模型决定调用哪个工具以及如何调用。这就是为什么square_root()函数同时具备这两项功能的原因。
接下来,调用chat()函数,传入提示信息和工具列表。为了保持对话的上下文,应该将回复消息添加到消息列表中。然后,调用这些工具。在这个例子中,只有一个工具:square_root() 。结果应该添加到消息列表中,并将角色设置为"tool" 。
最后,再次调用chat()函数,并将messages提供的所有上下文信息传递给它。如果运行该脚本,得到类似如下的响应:
(venv) $ python tool_calling.py
The square root of 36 is 6.如您所见,该模型正确地利用了工具的结果,为原始问题提供了一个有理有据的答案。
如果没有看到任何输出,可能是模型决定直接给出答案,而没有调用工具。或者,它可能将工具调用以文本形式返回,而不是填充 .tool_calls属性。在这种情况下,请尝试使用更大的模型,例如llama3.1:8b ,或者调整提示词以鼓励模型使用工具。
结论
我们已在系统上安装了 Ollama,导入了几个语言模型,并通过ollama库将它们连接到 Python。也已经探索了聊天和文本生成界面,学习了如何维护对话上下文,以及如何流式传输回复以实现更流畅的用户体验。
在本地运行LLM对隐私、成本控制和离线可靠性至关重要。掌握这些技能,就可以开始设计原型、构建和发布AI驱动的应用程序,而无需依赖外部在线服务。
在本教程中,我们学习了如何:
- 安装并运行Ollama ,然后拉取模型以供本地使用。
- 使用**
chat()函数可以进行多轮对话,并设置 角色和上下文。** - 使用**
generate()进行一次性 文本和代码生成。** - 利用工具调用来获取基于自定义函数结果的响应。
掌握这些技能,我们就能构建注重隐私、经济高效的助手,而且这些助手完全运行在本地计算机上。你可以不断尝试使用提示、响应流和自定义工具,从而根据你的 Python 项目定制本地 LLM 工作流程。