Camera图像处理流
摘要:本文详细解析了Camera图像处理流程,涵盖从光信号转换为数字信号到最终生成可用图像的三个阶段:感知与传输、接口与缓冲、ISP处理。重点介绍了CMOS图像传感器的HDR和LFM特性,以及数据在SoC内部通过DDR多级缓存和处理的过程。同时阐述了高通CamX-Chi软件架构的分层设计,包括应用层、服务层、用户空间驱动层及内核空间驱动,并分析了AIS服务在汽车领域的快速启动和多客户端共享优势。最后概述了V4L2接口的视频采集标准流程及其在自动驾驶场景中的零拷贝优化实现。
从光信号 转换为数字信号 ,经过长距离传输 ,进入SoC(系统级芯片),并在芯片内部通过**DDR(内存)**进行多级缓存和处理,最终生成可供算法(AI)或人眼(Display)使用的图像的过程。
我们可以将其分为三个主要阶段:感知与传输阶段 、接口与缓冲阶段 、ISP处理阶段。
以下是针对你提供的流程节点的详细技术解析:
第一阶段:感知与传输 (Sensor & Transmission)
这一阶段在摄像头模组和传输线缆上完成。
1. CIS (CMOS Image Sensor, 图像传感器)
- 功能:光电转换。将光信号转换为模拟电信号,再通过内部ADC转换为数字信号。
- 自动驾驶特性 :
- HDR (高动态范围):通常输出多帧不同曝光的图像(如长曝光、短曝光、极短曝光)或使用大小像素技术,以应对出隧道、夜间对向来车等强光比场景。
- LFM (LED Flicker Mitigation):抑制由于LED车灯/红绿灯频闪导致的图像闪烁。
- Output :通常是 Raw Data (Bayer Pattern),数据量极大。
2. 加串器 (Serializer, Ser)
- 位置:摄像头模组内部,紧跟CIS。
- 功能:由于CIS输出的MIPI CSI信号传输距离很短(通常<30cm),无法直接拉到位于后备箱或仪表台的智驾域控制器。加串器将并行的MIPI信号转换成高速串行信号。
- 协议 :主要是 TI FPD-Link III/IV 或 Maxim(ADI) GMSL 2/3。
- 物理介质:同轴电缆 (Coax) 或 屏蔽双绞线 (STP)。
3. 解串器 (Deserializer, Des)
- 位置:域控制器(ECU)的主板上。
- 功能:接收来自摄像头的串行信号,将其恢复(解串)为SoC能识别的 MIPI CSI-2 信号。
- 特性:通常一个解串器芯片可以连接多个加串器(例如 4合1),实现多路摄像头汇聚。
第二阶段:SoC 接入与原始数据存储 (Input & Raw Dump)
这一阶段数据进入SoC芯片内部。
4. C-PHY (MIPI C-PHY)
- 功能:SoC 上的物理层接口硬件。
- 特点:相比传统的 D-PHY(有时钟线+数据线),C-PHY 不需要独立时钟线,使用3根线为一组(Trio)传输数据,编码效率更高,带宽更大。
- 作用:作为物理通道,接收解串器发来的高速差分信号。
5. Image Front End (IFE) / CSI Rx
- 功能:图像前端接收模块。
- 任务 :
- 解析 MIPI 协议包。
- 虚拟通道 (Virtual Channel, VC) 分离:如果多路摄像头通过同一个物理接口传输,IFE需要根据VC ID把不同摄像头的数据拆分开。
- CRC 校验:检查数据传输过程中是否有误码(功能安全关键点)。
6. Raw Dump Interface (RDI)
- 功能:直接内存写入接口。
- 机制 :通常通过 DMA (Direct Memory Access) 机制,不经过CPU,直接将 IFE 解析出的 原始 Raw 数据 搬运到内存地址中。
7. DDR (System Memory - 第1次读写)
- 存储内容 :Raw Data (未处理的拜耳阵列数据)。
- 为什么写入DDR?
- 解耦:传感器的输入速度和后端的ISP处理速度可能不匹配,DDR作为巨大的缓冲区。
- 多用途:这份Raw数据可能同时被送往ISP处理,也被保留用于数据回灌(Replay)测试,或者直接喂给某些端到端的AI模型。
第三阶段:ISP 图像信号处理 (Image Signal Processing)
这一阶段是典型的 Memory-to-Memory (M2M) 架构,数据在处理引擎和内存之间反复吞吐。
8. Bayer Processing Engine (BPE) / Pre-ISP / Raw Proc
- 输入:从 DDR 读取 Raw Data。
- 域 :Raw Domain (还在拜耳域,未转颜色)。
- 关键处理 :
- BLC (Black Level Correction):黑电平校正。
- DPC (Defective Pixel Correction):坏点校正。
- LSC (Lens Shading Correction):镜头阴影校正(解决四角发暗)。
- WB (White Balance):白平衡增益(在Raw域应用增益)。
- Raw Denoise:Raw域降噪。
9. DDR (System Memory - 第2次读写)
- 存储内容 :Pre-processed Raw (处理过的Raw数据)。
- 目的 :BPE处理完后,将干净的Raw数据写回DDR。
- 某些计算机视觉(CV)算法更喜欢使用经过降噪和校正但尚未去马赛克(Demosaic)的数据,以保留最大的原始信息量。
10. Image Processing Engine (IPE) / Full ISP / VISS
- 输入:从 DDR 读取 Pre-processed Raw。
- 域:从 Raw 转换到 RGB/YUV。
- 关键处理 :
- Demosaicing (去马赛克):将 Bayer 阵列(RGGB)插值还原为每个像素都有RGB全色信息。
- CCM (Color Correction Matrix):色彩校正矩阵,使颜色更准确。
- Gamma Correction:伽马校正,适配人眼或显示器的非线性亮度响应。
- CSC (Color Space Conversion):颜色空间转换,通常将 RGB 转换为 YUV (NV12/NV21),因为编码器和大多数AI模型使用YUV格式。
11. DDR (System Memory - 第3次读写)
- 存储内容 :YUV / RGB Image (最终图像)。
- 目的 :IPE处理完的图像写回DDR,供下游消费者使用:
- GPU/NPU 读取进行推理(目标检测、车道线识别)。
- Codec 读取进行H.264/H.265视频编码(用于行车记录仪)。
- Display Controller 读取用于中控屏显示。
关于 Post Processing (HDR等) 的位置修正
你流程中最后写的是 Post Processing(HDR等)。这里在实际架构中通常有两种理解,视具体SoC架构(如高通 vs TI vs 英伟达)而定:
-
HDR Merge 通常发生在较早阶段 (BPE 或 IPE 前端):
- HDR需要将长短曝光的两帧Raw数据合并成一帧高位宽(如20-bit或24-bit)的数据。这通常在 Bayer Processing Engine (BPE) 阶段或者 IPE 的最前端 完成。因为去马赛克(Demosaic)需要在合并后的完整线性数据上进行。
-
Post Processing 通常指 Tone Mapping (色调映射):
- 合并后的HDR图像位宽很高(20bit+),但内存存储(8bit/12bit)和显示器(8bit)无法显示。
- 因此在 IPE 的末端 或 Post Processing 阶段,会进行 LTM (Local Tone Mapping) 和 GTM (Global Tone Mapping),将高动态范围压缩到低动态范围,同时保留亮部和暗部的细节。
如果严格按照你提供的流程(放在最后):
这可能指的是 Vision Post Processing 或 LTM Block。此时DDR里的数据可能是高位宽的YUV/RGB,最后这一步把它"压"成适合人眼观看的图像,或者进行锐化(Sharpening)、去雾(De-fog)等操作。
总结:为什么有这么多 DDR 读写?
你可能会觉得:Raw -> BPE -> DDR -> IPE -> DDR 这样效率很低,为什么不直接 Raw -> BPE -> IPE -> DDR(即 On-the-Fly 模式)?
在自动驾驶的高端SoC(如高通 8155/8650, NVIDIA Orin)中,采用这种 Memory-to-Memory (M2M) 架构的原因是:
- 带宽峰值管理:摄像头数据量极大,OTF模式要求流水线每个环节都必须实时跟上输入速度。M2M允许各个引擎异步工作,平滑带宽峰值。
- 灵活性:中间存入DDR的数据(如Pre-processed Raw)可以被不同的消费者复用(例如:一路给机器视觉算法,一路给ISP做成人眼观看的图像),互不干扰。
- 多摄调度:智驾通常有10+个摄像头,硬件加速器(BPE/IPE)通常是分时复用的。DDR作为一个巨大的缓冲池,让多个摄像头的数据排队进入硬件加速器处理。
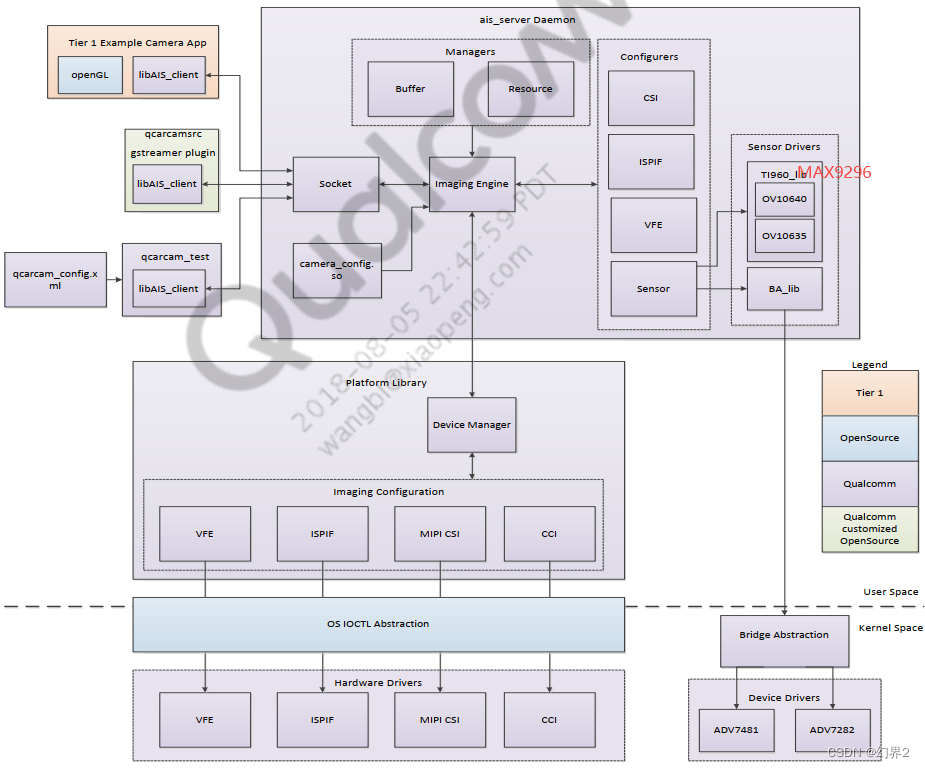
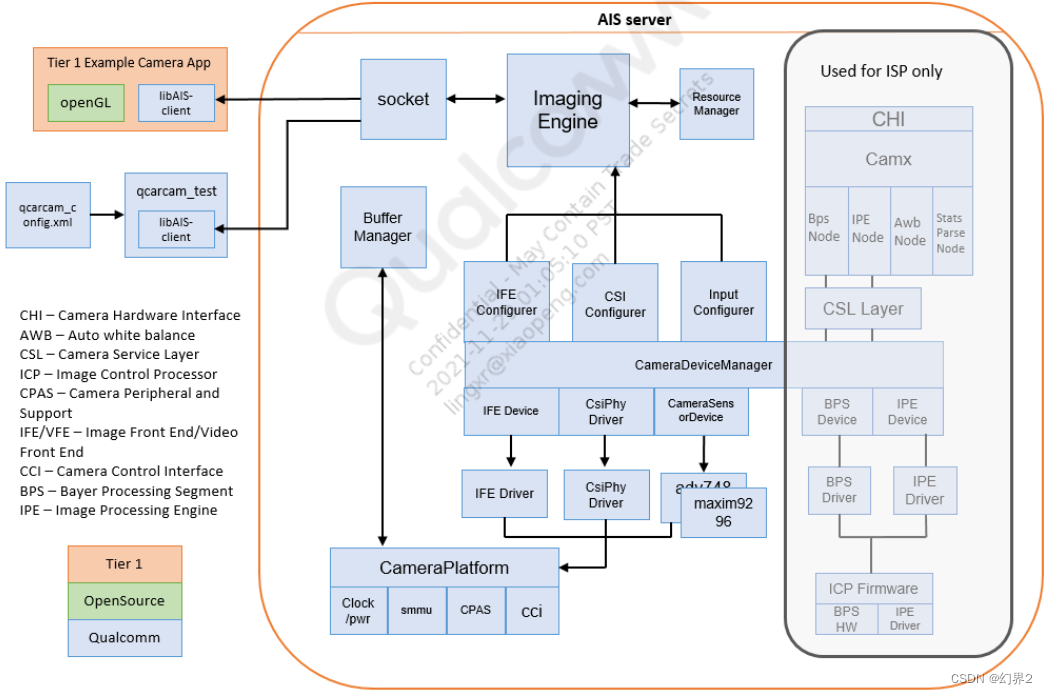
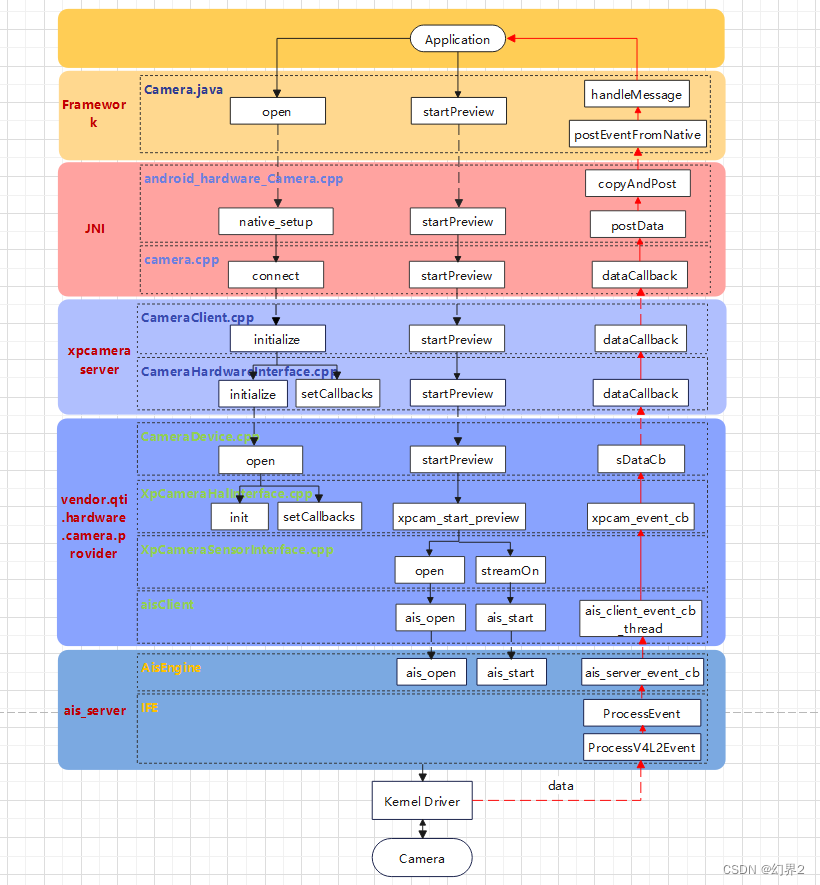
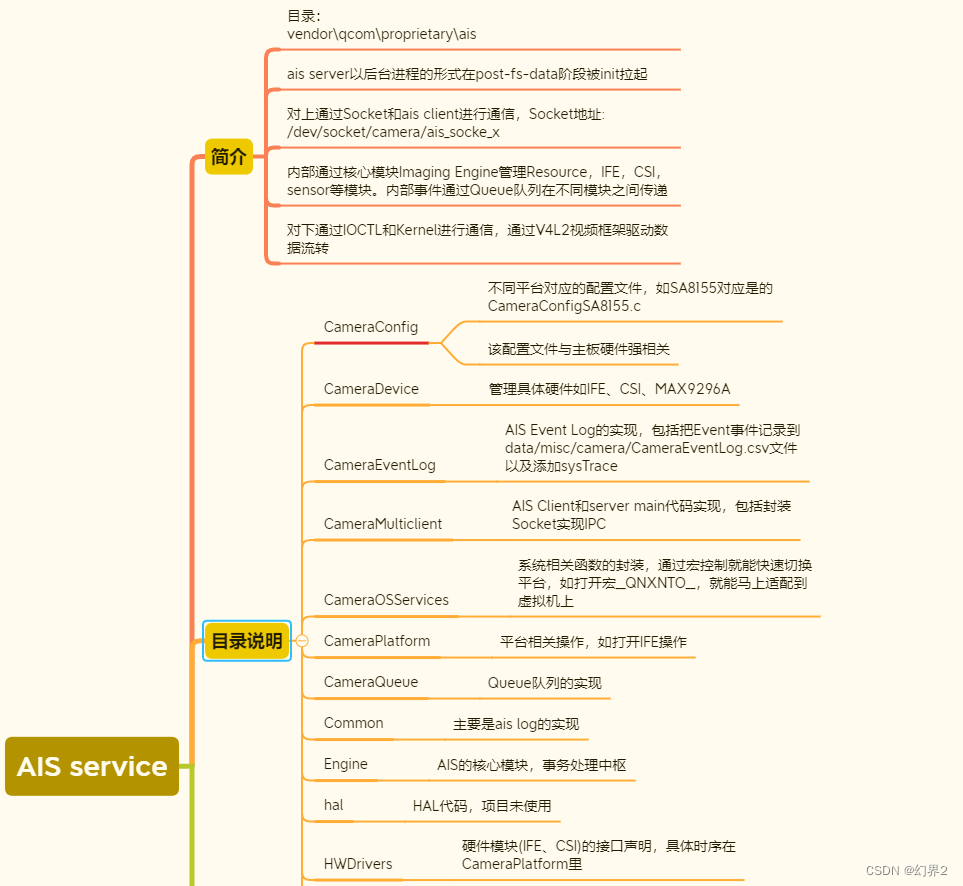
针对 Qualcomm(高通)的摄像头子系统(Camera Subsystem),特别是针对汽车(Automotive)领域的软件架构,其核心与移动端(Mobile)一脉相承,但增加了对虚拟化(Hypervisor) 、**功能安全(Safety)和多摄并发(Multi-camera concurrency)**的支持。
高通目前的摄像头软件架构被称为 CamX-Chi 架构。
以下是 High Level Software Block Diagram 的文本化描述及详细层级解析:
High-Level Software Block Diagram (从上至下)
mermaid
graph TD
%% Application Layer
App[Applications / ADAS Algorithms]
%% Framework Layer
subgraph Framework [OS Framework Layer]
AIS[Automotive Imaging Service / Android CameraService]
end
%% HAL / User Mode Driver Layer (The Core)
subgraph UMD [User Mode Driver - CamX/Chi Architecture]
HAL_If[Camera HAL Interface (Android HAL3 / QNX-Screen)]
subgraph Chi [Chi (Camera Hardware Interface) - Vendor Customization]
Chi_App[Chi Application / Context]
Chi_Node[Chi Nodes (Custom Algos / Topologies)]
Sensor_Driver[Sensor / Module Logic (Chi-CDK)]
end
subgraph CamX [CamX (Camera Experience) - Platform Logic]
CamX_Core[CamX Core Engine]
CamX_HwL[HWL (Hardware Layer - ISP Abstraction)]
CamX_SwL[SWL (Software Nodes - JPEG/Format Conv)]
end
end
%% Kernel Space
subgraph KMD [Kernel Mode Driver]
V4L2[V4L2 Video Nodes]
CamSS_Driver[CamSS / IFE / IPE Drivers]
CSID_Driver[CSID / PHY Drivers]
SMMU[SMMU / ION / DMA-Buf (Memory Mgmt)]
end
%% Hardware & Firmware
subgraph Hardware [Hardware & Firmware]
ISP[Spectra ISP (IFE / IPE / BPS)]
ADSP[Hexagon DSP (3A Algorithms / CV)]
Sensors[SerDes / CMOS Sensors]
end
%% Connections
App --> AIS
AIS --> HAL_If
HAL_If --> Chi_App
Chi_App -- Topology Definitions --> CamX_Core
Chi_Node -- Custom Processing --> CamX_Core
CamX_Core -- IOCTLs --> KMD
KMD -- Reg Writes/Interrupts --> Hardware
CamX_Core -- RPC --> ADSP详细架构层级解析
1. 应用层 (Application Layer)
在汽车环境中,消费者主要分为两类:
- IVI (车载娱乐系统):如倒车影像 (RVC)、环视 (SVM)、流媒体后视镜。这些应用通常运行在 Android 或 QNX 上,通过标准的 Camera API 获取图像流。
- ADAS (辅助驾驶系统):如车道保持、自动紧急制动。这些通常直接获取 Raw Data 或 YUV 数据,对延迟极为敏感。
2. 服务层 (Service Layer / Framework)
- Android环境 :使用的是标准的
CameraService。 - QNX/Linux环境 :高通通常提供
AIS(Automotive Imaging Service) 或QCARCAMAPI。这是一个针对汽车优化的轻量级服务,支持极快启动(Early Boot Video),确保在系统完全启动前就能显示倒车影像(通常要求 < 2秒)。
3. 用户空间驱动层 (UMD) - 核心架构: CamX-Chi
这是高通架构中最复杂也是最重要的部分,旨在将通用的平台逻辑 与厂商的定制逻辑解耦。
-
CamX (Camera Experience - 平台层):
- 角色 :这是高通提供的闭源(或部分开源)基础框架。它不知道具体的传感器型号,也不关心你想怎么处理图像,它只负责执行。
- 功能 :
- 管理 Session(会话)和 Pipeline(流水线)。
- 处理 Buffer 分配和流转。
- 将抽象的图像处理请求转化为 ISP 硬件能理解的配置(HWL - HardWare Layer)。
- 与 Kernel 进行交互 (KMD)。
-
Chi (Camera Hardware Interface - 定制层):
- 角色:这是 OEM(车企/Tier 1)或模组厂进行开发的地方。
- Chi-CDK (Camera Development Kit):用于编写传感器驱动。以前传感器驱动在 Kernel 里,现在高通架构将大部分传感器控制逻辑移到了用户空间的 Chi-CDK 中,通过 I2C/CCI 控制硬件。
- Topology (拓扑结构) :在 Chi 中定义数据流向。例如:
Sensor -> IFE -> IPE -> DDR。是一个有向无环图 (DAG)。 - Chi Nodes:如果需要在 ISP 流程中插入自定义算法(例如特殊的夜景算法),可以编写一个 Chi Node 插入到 CamX 的流水线中。
4. 算法与控制 (3A & DSP)
- 3A (AE/AF/AWB) :自动曝光、对焦、白平衡算法通常不运行在 CPU 上,而是运行在 Hexagon DSP (ADSP) 上,以降低 CPU 负载并利用 DSP 的向量计算能力。
- CamX 通过 RPC (Remote Procedure Call) 与 ADSP 通信,统计数据 (Stats) 从 ISP 出来后送往 ADSP,ADSP 计算出新的曝光参数,再写回 Sensor/ISP。
5. 内核空间 (Kernel Mode Driver - KMD)
在 CamX 架构下,Kernel 驱动变得相对"薄"了,主要负责资源调度和硬件保护,而不是复杂的逻辑。
- V4L2 (Video for Linux 2):Linux 标准视频设备接口。
- CamSS (Camera Subsystem Driver):控制电源、时钟、复位。
- SMMU (System Memory Management Unit):管理图像 buffer 的内存映射,确保 ISP 可以安全访问物理内存。
- CSID / PHY Drivers:配置 MIPI 接口和 C-PHY/D-PHY 物理层。
6. 虚拟化支持 (Hypervisor - Automotive 特有)
在像 Snapdragon 8155/8295 这样的座舱芯片上,通常运行着 Hypervisor (如 QNX Hypervisor 或 Google Gunyah)。
- PVM (Primary VM):通常拥有硬件的直接访问权。
- GVM (Guest VM):例如 Android IVI 系统。
- 机制 :GVM 中的 CamX 无法直接写硬件寄存器,它会通过 VirtIO 或高通私有的 BE/FE (Back-End/Front-End) 机制,将请求发送给 PVM,由 PVM 统一调度硬件资源。这保证了多个虚拟机同时使用 ISP 时不会冲突。
总结:数据流 vs 控制流
- 控制流 (Control Path) :
- App -> Framework -> Chi (选择拓扑) -> CamX (编译拓扑) -> KMD (提交请求) -> Hardware (寄存器配置)。
- 数据流 (Data Path) :
- Sensor -> SerDes -> CSID/IFE (硬件) -> DDR (SMMU映射) -> IPE (硬件) -> DDR -> App。
- 注意:图像数据主要在硬件和 DDR 之间搬运,极少经过 CPU,以保证高吞吐量。
关键词速查 (Key Terms)
- Usecase: 一个特定的相机场景(如:后视、前视+环视)。
- Session: CamX 中的一次活动连接。
- Node: 处理单元(如 IFE Node, IPE Node, Stats Node)。
- Link: Node 之间的连接(Buffer 传输通道)。
- Fence: 同步机制,用于 CPU/GPU/ISP 之间确认 Buffer 读写完成。
AIS (Automotive Imaging Service) 是 Qualcomm 专门为汽车行业设计的一套摄像头服务架构。它不同于消费级手机上的 Android CameraService,AIS 更加注重高可靠性、低延迟、多客户端共享 以及快速启动 (Early Boot)。
这套架构采用了经典的 C/S (Client-Server) 模式,即 AIS Server 和 AIS Client Lib。
以下是两者的详细分工与交互机制解析:
1. 架构总览图
mermaid
graph TD
subgraph "Application Layer (Client Process)"
App[RVC App / SVM App / CV App]
ClientLib[**AIS Client Lib** (libais_client.so)]
API[**QCarCam API**]
App --> API
API --> ClientLib
end
subgraph "System Layer (Server Process)"
IPC((IPC Channel))
Server[**AIS Server** (ais_server / qcarcam_server)]
ClientLib <== Control (IPC) ==> IPC
IPC <== Control (IPC) ==> Server
ClientLib -.-> |Shared Memory / Buffers| .- Server
end
subgraph "Driver & Hardware Layer"
CamX[CamX / Chi (UMD)]
KMD[Kernel Drivers]
HW[Camera Hardware]
Server --> CamX
CamX --> KMD
KMD --> HW
end2. AIS Server (服务端)
AIS Server 是摄像头系统的"大管家",通常作为一个守护进程(Daemon)运行在后台。
-
核心职责:
- 硬件所有权 (Hardware Ownership):它是唯一直接与底层 CamX/Chi 驱动交互的进程。这避免了多个应用同时操作寄存器导致的冲突。
- 资源管理:管理 ISP 带宽、摄像头路数、内存池 (Buffer Pools)。
- 生命周期管理:负责摄像头的上电(Power On)、初始化、数据流开启(Streaming)和关闭。
- 广播与分发 (Broadcasting):如果多个应用需要同一个摄像头的画面(例如:仪表盘显示后视,同时 IVI 中控屏也显示后视),Server 负责从硬件获取一份数据,然后分发给多个 Client,无需硬件重复工作。
- Early Boot (快速启动) :
- 这是 AIS Server 最重要的特性。
- 在 Android/QNX 操作系统内核加载初期,AIS Server 就会启动(远早于 Android SurfaceFlinger 或 SystemServer)。
- 它能迅速初始化倒车摄像头,直接将画面送往屏幕显示控制器(Display Controller),确保车辆点火 2秒内 看到倒车影像,满足法规要求。
-
运行环境:
- 在 QNX 中,通常是一个 Resource Manager。
- 在 Linux/Android 中,是一个 Native Service Daemon (
qcarcam_server)。
3. AIS Client Lib (客户端库)
AIS Client Lib 是提供给应用开发者使用的动态链接库(如 libais_client.so 或 libqcarcam.so)。应用(App)通过加载这个库来与摄像头打交道。
- 核心职责 :
- API 暴露 :它向应用层暴露了 QCarCam API。这是一套高通定义的汽车专用 API,比 Android Camera2 API 更精简、更底层。
- IPC 通信 :它封装了复杂的进程间通信逻辑。当 App 调用
QCarCamOpen()时,Client Lib 会将请求打包,通过 IPC(Binder, Socket, 或 QNX MsgSend)发送给 AIS Server。 - 共享内存映射 (Buffer Mapping) :
- 图像数据量巨大(例如 4路 2MP 30fps),通过 IPC 拷贝数据是不可能的。
- Client Lib 负责将 Server 分配的图像缓冲区(DMA-Buf / ION Buffer)映射到 App 的虚拟地址空间。
- Zero-Copy(零拷贝):App 读取图像数据时,直接读的是物理内存,没有 CPU 拷贝过程,效率极高。
4. 关键交互流程 (Workflow)
场景:App 请求打开摄像头并获取预览流
- Open : App 调用
QCarCamOpen(id).- Client Lib 发送 IPC 消息给 Server。
- Server 检查权限,初始化对应的 CamX Session。
- Buffer Request : App 请求 5 个 Buffer。
- Server 通过 PMEM/ION 分配 5 块物理连续内存。
- Server 将 Buffer 的句柄(File Descriptor)传回给 Client Lib。
- Client Lib 做
mmap,让 App 能看到这些内存。
- Start : App 调用
QCarCamStart().- Server 指令 ISP 开始出图。
- Streaming (循环) :
- 硬件将图像写入 Buffer A。
- Server 通过 IPC 通知 Client Lib:"Buffer A 好了"。
- App 读取/显示 Buffer A。
- App 用完后调用
QCarCamReleaseFrame()。 - Client Lib 通知 Server:"Buffer A 用完了,还给你"。
- 硬件再次向 Buffer A 写入新一帧。
5. AIS Server/Client 架构的优势
- 安全性 (Security):应用层无法直接接触硬件驱动,必须通过 Server 校验权限。
- 跨进程共享:一个 Server 可以服务多个 Client(例如:ADAS 算法进程和 UI 显示进程)。
- 稳定性:如果某个 App(Client)崩溃了,Server 依然在运行,不会导致摄像头硬件状态错乱,Server 可以回收资源给其他 App 使用。
- 解耦:App 不需要关心底层是用 CamX 还是其他架构,只需要调用标准的 QCarCam API。
使用 V4L2 (Video for Linux 2) 接口采集视频数据是 Linux 下最标准的做法。无论是在通用的 Linux 系统,还是在 Android/QNX 的底层(虽然 Android 上层封装了 HAL,但底层很多还是基于 V4L2 节点),流程基本一致。
整个采集过程可以概括为:打开设备 -> 设置参数 -> 申请内存 -> 内存映射 -> 入队 -> 开始采集 -> (循环:出队-处理-入队) -> 停止采集 -> 释放资源。
以下是详细的步骤解析和相关的 ioctl 命令:
1. 核心流程图
mermaid
graph TD
A[Open Device] --> B[Query Capability]
B --> C[Set Format (S_FMT)]
C --> D[Request Buffers (REQBUFS)]
D --> E[Query Buffer & mmap]
E --> F[Queue Buffers (QBUF)]
F --> G[Stream On (STREAMON)]
subgraph "Capture Loop (Polling)"
H[Wait for Data (select/poll)]
I[Dequeue Buffer (DQBUF)]
J[Process Data (Display/Save)]
K[Queue Buffer (QBUF)]
G --> H
H --> I
I --> J
J --> K
K --> H
end
J -- Stop Signal --> L[Stream Off (STREAMOFF)]
L --> M[munmap & Close]2. 详细步骤说明
第一步:打开设备 (Open)
通常摄像头设备节点是 /dev/video0, /dev/video1 等。
C
int fd = open("/dev/video0", O_RDWR);第二步:查询能力 (Query Capabilities)
确认该设备是否是视频采集设备,以及是否支持流 IO (Streaming)。
- Command :
VIDIOC_QUERYCAP - Check :
V4L2_CAP_VIDEO_CAPTURE(是否支持采集),V4L2_CAP_STREAMING(是否支持流传输)。
第三步:设置图像格式 (Set Format)
告诉驱动你需要什么样的图像数据(分辨率、像素格式)。
- Command :
VIDIOC_S_FMT - Struct :
v4l2_format - Key Fields :
width,height: 1920x1080 等。pixelformat:V4L2_PIX_FMT_YUYV,V4L2_PIX_FMT_MJPEG,V4L2_PIX_FMT_NV12等。
第四步:申请缓冲区 (Request Buffers)
向驱动申请用于存放视频帧的内存块数量。这是最关键的一步,决定了内存管理模式。
- Command :
VIDIOC_REQBUFS - Struct :
v4l2_requestbuffers - Memory Type :
V4L2_MEMORY_MMAP: 最常用。驱动在内核空间分配内存,应用层通过 mmap 映射。V4L2_MEMORY_USERPTR: 应用层分配内存,指针传给驱动(较少用)。V4L2_MEMORY_DMABUF: 高性能场景(如自动驾驶/手机)。内存由外部分配器(如 ION/DMA-BUF heap)分配,驱动只拿句柄。实现 CPU 零拷贝 (Zero-copy),直接给 GPU 或 Encoder 用。
第五步:内存映射 (Query & Mmap) - 针对 MMAP 模式
既然驱动在内核里分配了空间(例如申请了 4 个 Buffer),应用层需要知道每个 Buffer 的物理信息并映射到自己的虚拟地址空间。
- Command :
VIDIOC_QUERYBUF(传入 index 0~3,查询每个 Buffer 的偏移量 offset 和长度 length)。 - Syscall :
mmap()(根据 offset 将内核内存映射到用户空间指针)。
第六步:缓冲区入队 (Queue Buffers - QBUF)
刚申请的缓冲区是空的。必须先把所有空的 Buffer 全部交给驱动(放入"输入队列"),驱动才有地方写数据。
- Command :
VIDIOC_QBUF - Action : 将所有
mmap好的 Buffer index 依次入队。
第七步:开始采集 (Stream On)
告诉 ISP/DMA 引擎开始工作。
- Command :
VIDIOC_STREAMON - 此时,硬件开始将摄像头数据写入排在队列最前面的 Buffer。
第八步:循环采集 (The Loop)
这是一个典型的生产者-消费者模型。
- Wait : 使用
select()或poll()监听fd。当硬件写满一个 Buffer 后,fd变为可读。 - Dequeue (DQBUF) : 从"完成队列"中取出一个填满数据的 Buffer。
- Command :
VIDIOC_DQBUF - 此时驱动会把 Buffer 的使用权交给应用层。
- Command :
- Process : 应用层处理数据(显示、编码、CV算法)。
- 注意:处理速度必须快于帧率,否则会丢帧。
- Re-Queue (QBUF) : 处理完后,必须把这个 Buffer 马上还给驱动(放回"输入队列"),以便驱动写下一帧。
- Command :
VIDIOC_QBUF
- Command :
第九步:停止与释放 (Stop & Clean)
- Stream Off :
VIDIOC_STREAMOFF(停止硬件写入)。 - Unmap :
munmap()(解除内存映射)。 - Close :
close(fd)。
3. 代码片段示例 (C语言)
C
struct v4l2_buffer buf;
struct v4l2_requestbuffers req;
enum v4l2_buf_type type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
// 1. 申请 4 个缓冲区
memset(&req, 0, sizeof(req));
req.count = 4;
req.type = type;
req.memory = V4L2_MEMORY_MMAP;
ioctl(fd, VIDIOC_REQBUFS, &req);
// 2. 映射 (简化版,实际需要循环映射所有buffer)
// ... (mmap loop here) ...
// 3. 开始采集
ioctl(fd, VIDIOC_STREAMON, &type);
// 4. 采集循环
while(is_running) {
// 监听是否有数据
select(fd + 1, &fds, NULL, NULL, &tv);
// 取出填充好的 Buffer (DQBUF)
memset(&buf, 0, sizeof(buf));
buf.type = type;
buf.memory = V4L2_MEMORY_MMAP;
if (ioctl(fd, VIDIOC_DQBUF, &buf) < 0) {
perror("DQBUF failed");
break;
}
// --- 此时 buffers[buf.index].start 就是图像数据 ---
process_image(buffers[buf.index].start, buf.bytesused);
// 用完后放回驱动 (QBUF)
if (ioctl(fd, VIDIOC_QBUF, &buf) < 0) {
perror("QBUF failed");
break;
}
}4. 进阶:自动驾驶场景中的不同点
在你之前提到的 Qualcomm AIS / 自动驾驶 场景中,虽然底层原理类似,但通常不会直接使用标准的 open/read 或简单的 mmap:
- V4L2 节点 :在 Qualcomm 平台上,
/dev/videoX可能对应的是 IFE (Image Front End) 的输出或 IPE 的输出。 - DMA-BUF 机制 :
- 为了实现 Zero-Copy (零拷贝) ,通常使用
V4L2_MEMORY_DMABUF。 - AIS Server 或 CamX 分配 ION 内存(DMA-BUF)。
- V4L2 驱动通过
VIDIOC_QBUF接收这些 DMA-BUF 的 fd(文件描述符),直接将 ISP 数据写入物理内存。 - 然后这个 fd 可以直接传递给 GPU (OpenGL/OpenCL) 或 视频编码器 (Venus),完全不经过 CPU 的
memcpy。
- 为了实现 Zero-Copy (零拷贝) ,通常使用