
请君浏览
-
- 前言
- 一、什么是库?动静态库的核心差异
- 二、静态库:制作与使用(一步到位)
-
- 2.1、静态库的工作原理(编译链接流程)
- 2.2、静态库制作步骤
-
- [1. 编写源文件与头文件](#1. 编写源文件与头文件)
- [2. 编译生成目标文件(.o)](#2. 编译生成目标文件(.o))
- [3. 用 ar 命令打包为静态库](#3. 用 ar 命令打包为静态库)
- [4. 整理库文件](#4. 整理库文件)
- 2.3、静态库使用方法
- [核心原因:C 标准库是编译器 / 系统的 "内置标配"](#核心原因:C 标准库是编译器 / 系统的 “内置标配”)
- 2.4、静态库的优缺点
- [三、动态库:制作、使用与 "找不到" 问题](#三、动态库:制作、使用与 “找不到” 问题)
-
- 3.1、什么是动态库
- 3.2、动态库制作步骤
-
- [1. 编译生成位置无关目标文件(PIC)](#1. 编译生成位置无关目标文件(PIC))
- [2. 链接生成动态库](#2. 链接生成动态库)
- [3.2 动态库的使用](#3.2 动态库的使用)
- [3.3 动态库的优缺点](#3.3 动态库的优缺点)
- [3.4 动态库 vs 静态库的核心区别与补充](#3.4 动态库 vs 静态库的核心区别与补充)
- [四、ELF 格式:链接与加载的核心](#四、ELF 格式:链接与加载的核心)
-
- [4.1 ELF 的核心结构](#4.1 ELF 的核心结构)
- [4.2 多个ELF的.o形成可执行](#4.2 多个ELF的.o形成可执行)
- [4.3 平坦模式编址](#4.3 平坦模式编址)
-
- [4.3.1 先搞懂:平坦模式编址是什么?](#4.3.1 先搞懂:平坦模式编址是什么?)
- [4.3.2 平坦模式编址的好处](#4.3.2 平坦模式编址的好处)
- [五、链接与加载:从.o 到运行的完整流程](#五、链接与加载:从.o 到运行的完整流程)
-
- [5.1 静态链接:编译时合并与地址重定位](#5.1 静态链接:编译时合并与地址重定位)
- [5.2 动态链接:运行时加载与延迟绑定](#5.2 动态链接:运行时加载与延迟绑定)
-
- [5.2.1 可执行程序的初始化](#5.2.1 可执行程序的初始化)
- [5.2.2 程序和动态库的映射](#5.2.2 程序和动态库的映射)
- [5.2.3 全局偏移量表GOT(global offset table)](#5.2.3 全局偏移量表GOT(global offset table))
- [5.2.4 库间依赖和延迟绑定](#5.2.4 库间依赖和延迟绑定)
- 六、核心总结与适用场景
- 尾声
前言
在 Linux 开发中,"库" 是绕不开的核心概念 ------ 它是封装好的可复用代码,让开发者无需从零实现基础功能,大幅提升开发效率。但你是否好奇:静态库(.a)和动态库(.so)有何区别?动态库为什么会出现 "找不到" 的报错?可执行程序是如何加载库并运行的?ELF 文件又藏着怎样的底层秘密?
今天,我们就从 "库的制作与使用" 入手,一步步深入到 ELF 格式、链接加载机制,带你吃透 Linux 库与程序运行的完整逻辑。
一、什么是库?动静态库的核心差异
库是写好的现有的,成熟的,可以复⽤的代码,例如我们在C语言中使用的printf、scanf等函数就被称为库函数,它们的实现在C标准库中,因此我们可以直接去使用这些函数。库是二进制形式的可复用代码,本质是编译后的目标文件(.o)的集合。
现实中每个程序都要依赖很多基础的底层库,不可能每个⼈的代码都从零开始,因此库的存在意义非同寻常。下面先让我们来看一看Linux下的C标准库:

Linux 下库分为两类,核心差异在于 "链接时机" 和 "资源占用":
| 类型 | 后缀(Linux) | 核心特点 | 优势 | 劣势 |
|---|---|---|---|---|
| 静态库 | .a | 编译链接时,库代码直接合并到可执行程序,运行时无需依赖库文件 | 运行独立、无需额外依赖 | 可执行文件体积大、库更新需重新编译 |
| 动态库 | .so | 编译仅记录函数入口地址,运行时才加载库代码,多程序可共享同一份库内存 | 文件体积小、库更新无需重编 | 运行依赖库文件、加载有轻微开销 |
windows下静态库后缀为
.lib,动态库后缀为.dll
举个直观例子:用静态库编译的a.out,大小可能有 10MB(包含库代码);用动态库编译的a.out可能仅 1MB(仅包含库引用),但运行时必须找到对应的.so文件。
二、静态库:制作与使用(一步到位)
静态库是一组预先编译好的二进制目标代码(.o/.obj 文件) 的打包集合,里面包含了可复用的函数、数据或类的实现。你可以把它理解成一个 "代码工具箱":在程序编译的链接阶段,编译器会把你用到的静态库中的代码直接复制到最终生成的可执行文件里,适合无需频繁更新的基础功能封装。这也对应其名字中"静态"二字。
- 核心特征:静态库的代码是一次性嵌入到可执行文件中的,最终的可执行文件不依赖外部库文件就能独立运行。
2.1、静态库的工作原理(编译链接流程)
要理解静态库,先看完整的编译链接流程(以 C 语言为例):
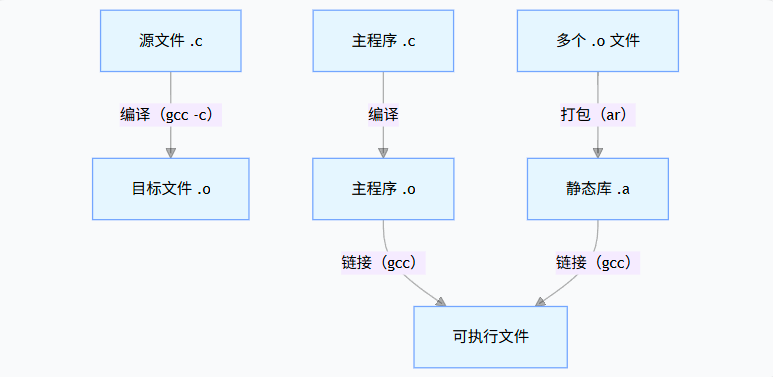
关键步骤:
- 编译:把单个源文件编译成目标文件(.o)(只编译不链接,生成二进制机器码)。
- 打包:用工具(如 Linux 的
ar)把多个目标文件打包成静态库。 - 链接:编译器将主程序的目标文件和静态库中的相关代码复制并合并,生成最终的可执行文件。
一旦链接完成,静态库就和可执行文件 "解绑" 了 ------ 即使删除静态库,可执行文件依然能正常运行。
2.2、静态库制作步骤
假设我们有两个源文件my_stdio.c(封装文件 IO)和my_string.c(封装字符串函数),要制作成静态库libmystdio.a:
1. 编写源文件与头文件
- 头文件
my_stdio.h/my_string.h:声明库函数(如mfopen、my_strlen); - 源文件
my_stdio.c/my_string.c:实现库函数。
2. 编译生成目标文件(.o)
将源文件编译为可重定位目标文件(不链接,仅编译):
bash
gcc -c my_stdio.c my_string.c # 生成 my_stdio.o 和 my_string.o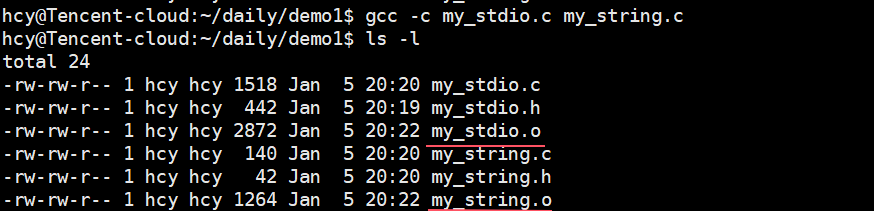
3. 用 ar 命令打包为静态库
如何将多个.o文件打包成静态库呢?Linux下我们可以用ar命令来完成:
ar:Linux 下的归档工具,用于将多个.o文件打包成静态库(.a文件),核心参数:
r:替换 / 添加文件到归档库中。c:创建归档库(若不存在则新建)。s:生成索引(提高链接效率)。
bash
ar -rc libmystdio.a my_stdio.o my_string.o # 生成静态库 libmystdio.a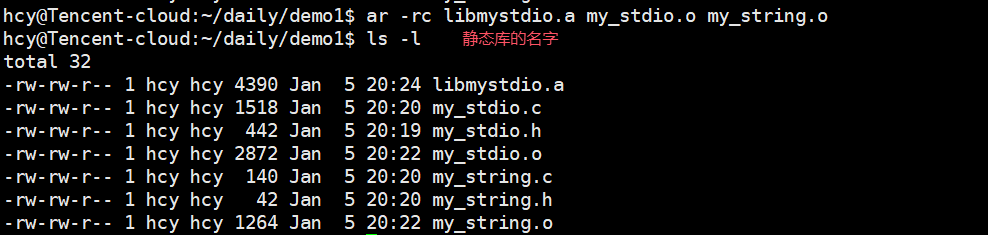
这里有两点需要注意:
对于静态库和动态库来说,我们保存的名字都是以
lib+库名+后缀构成的,也就是说,对于静态库libc.a来说,它的库名就是c,这也就是我们说的C标准库,同理对于动态库libc.so.6来说,它的库名也是c,后面的.6是版本号。这些库名在我们使用动静态时有它们的作用。上面我们使用ar工具归档时只有两个
.o文件,写的时候还很简单;但如果我们要归档一百甚至一千个.o文件呢?如果一个个的把文件名写上去就太麻烦了,我们可以使用Makefile来帮助我们进行归档,可以大大简化我们的工作:
makefile# 1. 定义变量(便于维护,修改时只需改这里) # 编译器 CC = gcc # 编译选项(-Wall显示警告,-O2优化,-fPIC生成位置无关代码) CFLAGS = -Wall -O2 -fPIC # 要生成的静态库名(格式:lib[库名].a) LIB_NAME = libmylib.a # 源文件列表(自动匹配当前目录下所有.c文件) SRC_FILES = $(wildcard *.c) # 目标文件列表(将所有.c替换为.o) OBJ_FILES = $(patsubst %.c, %.o, $(SRC_FILES)) # 2. 默认目标(执行make时优先执行) # 先编译.o文件,再归档成.a库 all: $(LIB_NAME) # 3. 归档规则:将所有.o文件打包成静态库 $(LIB_NAME): $(OBJ_FILES) ar rcs $@ $^ # $@代表目标文件(LIB_NAME),$^代表依赖文件(OBJ_FILES) # 4. 编译规则:将.c文件编译为.o文件(模式规则,匹配所有.c) %.o: %.c $(CC) $(CFLAGS) -c $< -o $@ # 5. 清理规则:删除生成的.o和.a文件 clean: rm -rf $(OBJ_FILES) $(LIB_NAME) # 声明伪目标(避免与同名文件冲突) .PHONY: all clean
验证静态库内容:
bash
ar -tv libmystdio.a # 列出库中的.o文件,t=列表,v=详细信息
4. 整理库文件
通常将头文件和库文件分类存放,方便他人使用:
bash
mkdir -p stdc/include stdc/lib
cp *.h stdc/include # 头文件放入include
cp *.a stdc/lib # 库文件放入lib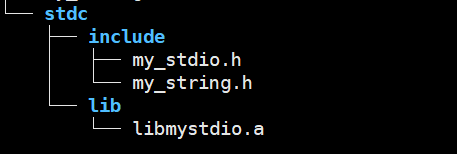
2.3、静态库使用方法
当我们使用静态库时,需告诉编译器 "头文件在哪"、"库文件在哪"、"库名是什么":
bash
# 场景1:头文件和库文件在当前目录
gcc main.c -lmystdio # -l后接库名(去掉lib前缀和.a后缀)
# 场景2:头文件在./stdc/include,库文件在./stdc/lib
gcc main.c -I./stdc/include -L./stdc/lib -lmystdio-I:指定头文件搜索路径;-L:指定库文件搜索路径;-l:指定库名(核心规则:libxxx.a→ 库名xxx)。
那么为什么当我们使用 C 标准库(比如
stdio.h、stdlib.h对应的库)时却不需要告诉编译器这些消息呢?核心原因:C 标准库是编译器 / 系统的 "内置标配"
简单来说,C 标准库是 C 语言生态的基础组成部分,编译器和操作系统在设计时就已经将它的相关信息内置为默认配置,而自定义静态库是你自己新增的、编译器 "不认识" 的资源,因此需要手动告知。
关键特性:编译后生成的可执行程序可独立运行,删除静态库不影响(库代码已合并)。
2.4、静态库的优缺点
优点:
- 独立运行:可执行文件不依赖外部库,部署时无需附带库文件,移植性强。
- 运行速度快:代码直接嵌入可执行文件,无需运行时加载外部库,减少了动态链接的开销。
- 版本稳定:编译时确定了库的版本,不会出现 "库版本不兼容" 的问题。
缺点:
- 可执行文件体积大:每个使用静态库的程序都会复制一份库代码,多个程序同时运行会占用更多内存。
- 更新麻烦:如果静态库有 bug 或需要升级,必须重新编译所有使用该库的程序。
- 编译时间长:链接阶段需要复制库代码,大型项目编译耗时增加。
⼀个可执⾏程序可能⽤到许多的库,这些库运⾏有的是静态库,有的是动态库,⽽我们的编译默认为动态链接库,只有在该库下找不到动态
.so的时候才会采⽤同名静态库。这时我们也可以使⽤gcc的-static强转设置链接静态库。
三、动态库:制作、使用与 "找不到" 问题
要理解动态库(也叫 "共享库"),可以先和之前的静态库对比:静态库是编译时把代码复制到程序里 ,而动态库是运行时才加载到内存、多个程序共享同一份代码------ 这是它的核心特点。
3.1、什么是动态库
动态库是一组预先编译好的二进制代码集合,动态库的核心是 "运行时加载":
- 程序编译链接阶段,不会把动态库的代码复制到可执行文件中,只会记录 "需要用到哪个动态库的哪些函数";
- 程序运行时,由操作系统的 "动态链接器" 负责将动态库加载到内存,程序再从内存中调用动态库的代码;
- 多个程序可以共享同一份加载到内存的动态库(因此也叫 "共享库")。
制作时需生成位置无关码(PIC),使用时需解决 "动态库查找路径" 问题,适合频繁更新或多程序共享的功能。
在Windows中动态库的后缀是
.dll(Dynamic Link Library),同时会生成对应的导入库(.lib) (注意:Windows 的.lib可能是静态库,也可能是动态库的导入库,需区分)
动态库的流程和静态库核心差异在 "链接时机" 和 "代码复用方式":
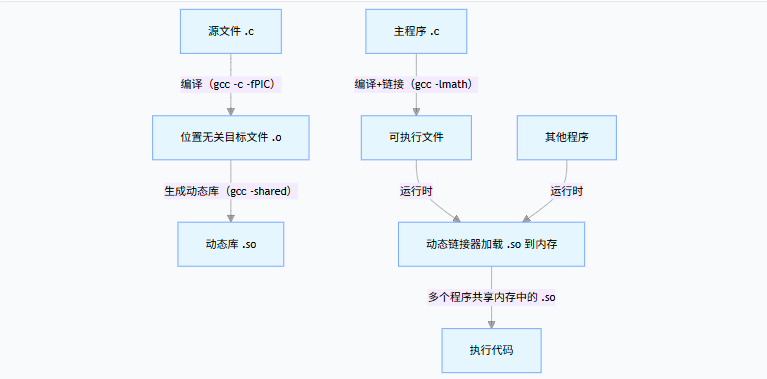
关键细节:
- 位置无关代码(PIC):动态库必须编译为 "位置无关代码",这样加载到内存任意地址都能正常运行(静态库不需要);
- 运行时加载 :可执行文件仅包含动态库的 "引用信息",运行时动态链接器(如 Linux 的
ld-linux.so)才会找到并加载动态库到内存; - 内存共享:同一份动态库在内存中只加载一次,多个程序共享这一份代码,操作系统用 "引用计数" 管理(加载一次计数 + 1,所有程序退出后计数为 0,才释放内存)。
至于为什么要有位置无关码PIC我们后面再说。
3.2、动态库制作步骤
我们基于上面静态库同样的源文件,制作动态库libmystdio.so:
1. 编译生成位置无关目标文件(PIC)
在制作动态库时,我们在编译生成.o文件时需要加上-fPIC选项生成位置无关码,确保库可加载到任意内存地址:
bash
gcc -fPIC -c my_stdio.c my_string.c # 生成 PIC 格式的.o文件2. 链接生成动态库
在制作静态库时我们需要使用了ar工具,制作动态库时我们可以使用gcc,带上-shared选项指定生成共享库格式:
bash
gcc -o libmystdio.so my_stdio.o my_string.o -shared # 生成动态库 libmystdio.so
3.2 动态库的使用
需要注意的是,当我们存在同名静态库和动态库时,gcc默认链接动态库:
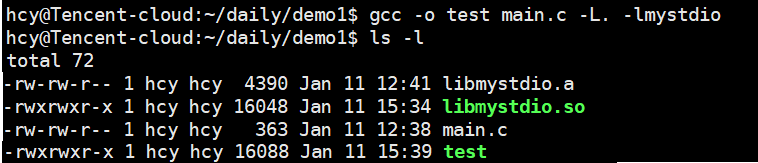
我们可以使用ldd命令查看当前可执行程序依赖的动态库:

但是我们可以发现我们对应的mystdio库后面对应的是not found,与标准库后对应的不同,这是为什么呢?我们明明在链接时指定了对应库文件的路径。接下来先让我们运行一下可执行程序来看一下:

可以看到,虽然说我们链接时没有出错,但程序运行时却发生找不到文件的报错,这是因为系统默认只在/usr/lib等目录找动态库,当前目录的libmystdio.so不在搜索路径里。解决这个问题方法有 3 种:
-
临时设置环境变量(仅当前终端有效):
bashexport LD_LIBRARY_PATH=./ # 告诉系统在当前目录找动态库 -
将动态库复制到系统库目录或者在系统的库目录建立软链接(需 root 权限):
bashsudo cp libmath.so /usr/lib -
修改配置文件永久生效:在
/etc/ld.so.conf.d/下新建配置文件(如mylib.conf),写入动态库所在路径,然后执行sudo ldconfig更新缓存。
这里我们就通过设置环境变量的方式来解决问题:

之后再运行程序就能正常运行了:

为什么使用静态库时不需要这么复杂呢?这就在于使用静态库是在链接时将对应的代码从静态库中拷贝到我们的最后的可执行程序中,而动态库则是在我们运行可执行文件时才会去链接对应的动态库,至于它们是如何链接的我们后面再说。
3.3 动态库的优缺点
优点:
- 可执行文件体积小:仅记录动态库引用,不复制代码,程序安装包更轻便;
- 内存共享:同一份动态库在内存中只加载一次,多个程序共享,节省内存资源;
- 更新维护方便:只需替换动态库文件,无需重新编译所有依赖它的程序;
- 版本灵活 :可通过 "版本号后缀"(如
libmath.so.1)实现多版本共存。
缺点:
- 依赖问题:程序运行时必须找到对应的动态库,否则会报错("找不到 xxx.dll" 是 Windows 常见问题);
- 运行时开销:动态链接器加载库、解析函数地址需要额外时间,比静态库启动稍慢;
- 版本兼容风险:若动态库更新后接口变化(如函数参数修改),依赖它的程序可能崩溃("DLL 地狱" 问题)。
动态库是 "运行时共享" 的二进制代码包,核心优势是节省内存、便于更新,适合多程序复用、需频繁迭代的场景;但要注意处理依赖问题和版本兼容。
3.4 动态库 vs 静态库的核心区别与补充
| 维度 | 静态库(.a/.lib) | 动态库(.so/.dll) |
|---|---|---|
| 链接时机 | 编译时链接(代码复制) | 运行时链接(仅引用) |
| 可执行文件体积 | 大(包含库代码) | 小(仅含引用) |
| 内存占用 | 多程序复用重复占用 | 多程序共享同一份,占用少 |
| 部署方式 | 无需带库,独立运行 | 需附带库文件,依赖路径 |
| 更新成本 | 需重新编译所有程序 | 替换库文件即可 |
在Linux中gcc/g++等编译器默认使用动态库,如果非要使用静态库在链接时需要加上-static选项,当然,若是只有静态库时不需要加-static选项也会链接静态库。
四、ELF 格式:链接与加载的核心
上面我们了解了动静态库的制作以及使用,那么它们具体是如何链接到我们的可执行程序上的呢?这里有一个关键的概念:ELF文件。下面让我们来认识一下什么是ELF文件。
无论是.o文件、可执行程序,还是.so动态库,本质都是ELF(Executable and Linkable Format)文件------ 它是 Linux 下统一的二进制文件格式,决定了文件如何被链接和加载。
下面是ELF文件 的四种类型
- 可重定位文件(.o):编译后的目标文件,需链接合并为可执行程序;
- 可执行文件(a.out):可直接运行,包含完整的程序逻辑和加载信息;
- 共享目标文件(.so):动态库,运行时被加载到内存;
- 核心转储(core):进程崩溃时的内存快照,用于调试。
我们可以用file命令辨识⽂件类型:

4.1 ELF 的核心结构
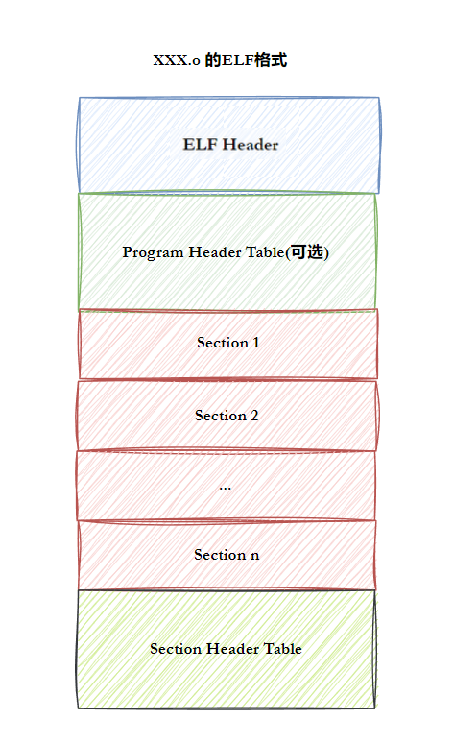
ELF 文件由四部分组成,关键是 "链接视图" 和 "执行视图":
- ELF 头(ELF Header):文件开头,记录文件类型、机器架构、入口地址、程序头表 / 节头表位置;
- 程序头表(Program Header Table):执行视图(加载时用),描述如何将文件加载到内存(合并节为段);
- 节头表(Section Header Table) :链接视图(编译链接时用),描述文件中的节(如
.text代码节、.data数据节); - 节(Section) :文件的基本单位,核心节包括:
.text:存储机器指令(只读);.data:已初始化的全局变量 / 静态变量;.bss:未初始化的全局变量 / 静态变量(仅占地址,不占文件空间);.symtab:符号表(函数名、变量名与地址的映射);.reloc:重定位表(记录需修正地址的符号)。
ELF的结构如下图所示:
4.2 多个ELF的.o形成可执行
我们的.o文件是EFL,又多个.o形成的可执行文件也是ELF,也就是说,其实多个.o文件链接形成可执行文件实际上就是多个ELF合并为一个ELF,如下图所示:
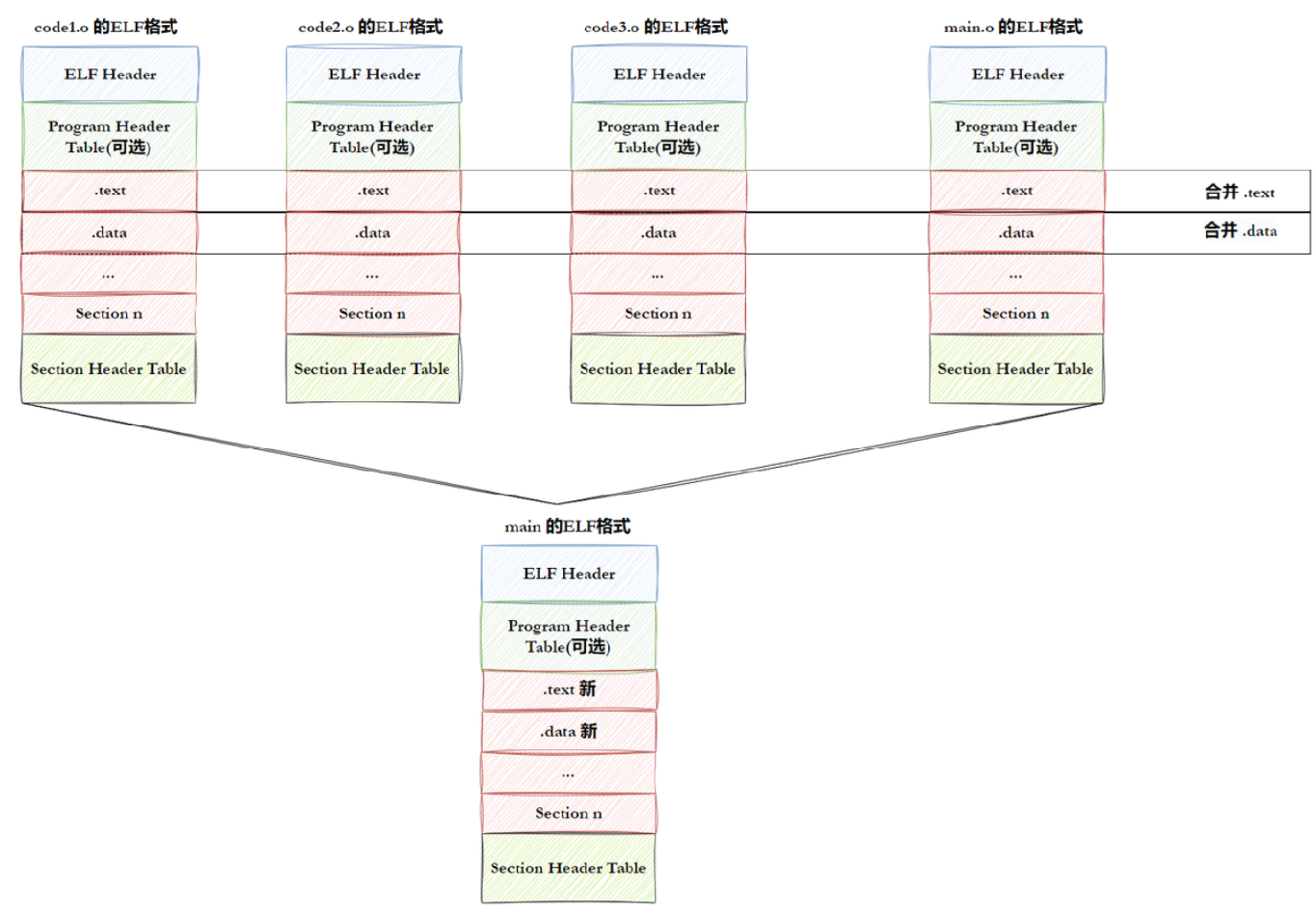
每个 .o 文件包含多个节(.text、.data、.bss、.rodata 等),链接器会将所有 .o 中 同类型、同属性的节合并成一个大节:
- 所有
.o的.text(机器码)→ 可执行文件的.text; - 所有
.o的.data(已初始化全局变量)→ 可执行文件的.data; - 所有
.o的.bss(未初始化全局变量)→ 可执行文件的.bss; - 所有
.o的.rodata(只读数据,如字符串常量)→ 可执行文件的.rodata。
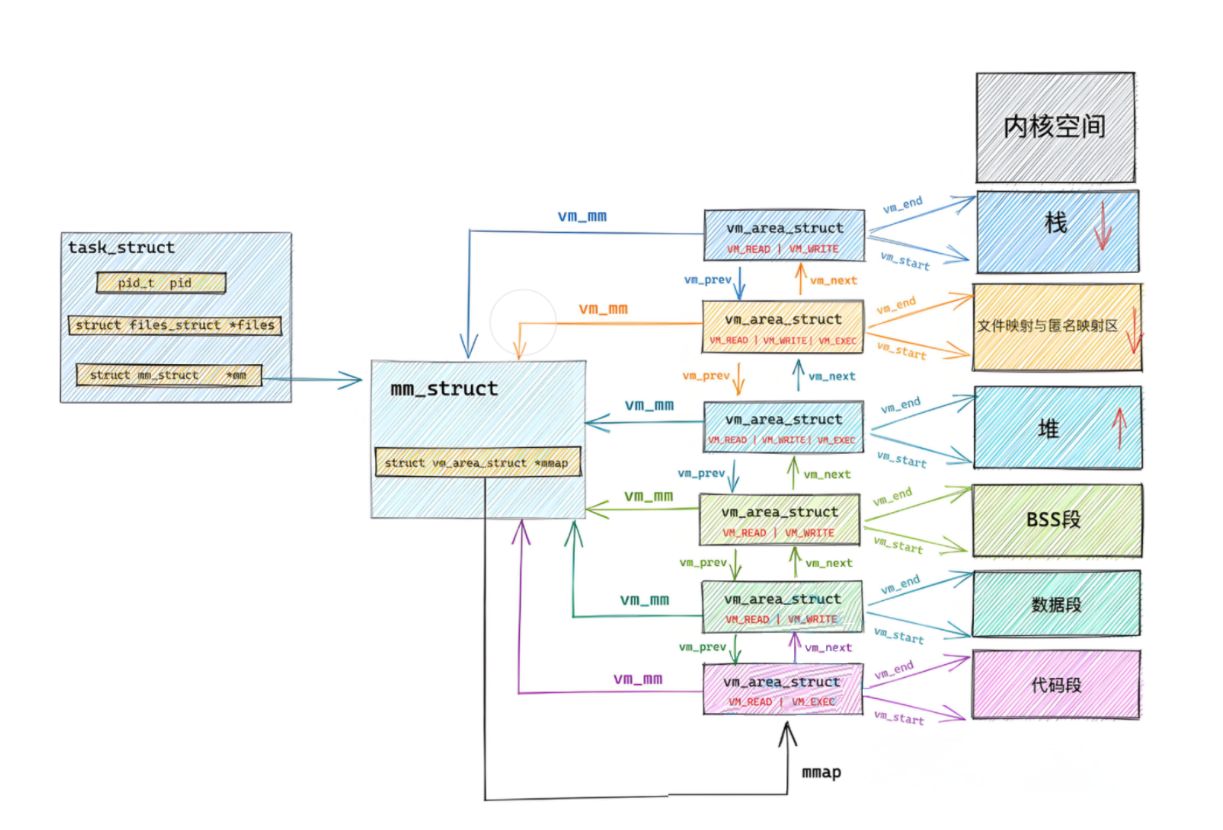
合并后的每个节都有访问属性 (比如可读、可写、可执行),链接器会把属性兼容的多个节打包成一个段(Segment),生成 "程序头表(Program Header Table)" 描述这些段 ------ 这是生成可执行文件的核心一步。而这些段也就是我们经常说的代码段、数据段等等。
段是加载器的最小操作单位,加载器会按段的属性把对应的节加载到内存的指定区域。
我们可以用readelf命令查看EFL文件的信息:
bash
# 查看ELF头
readelf -h a.out
# 查看程序头表(加载视图)
readelf -l a.out
# 查看节头表(链接视图)
readelf -S a.out我们可以查看一下可执行文件的程序头表和节头表,下面是可执行程序中的段:
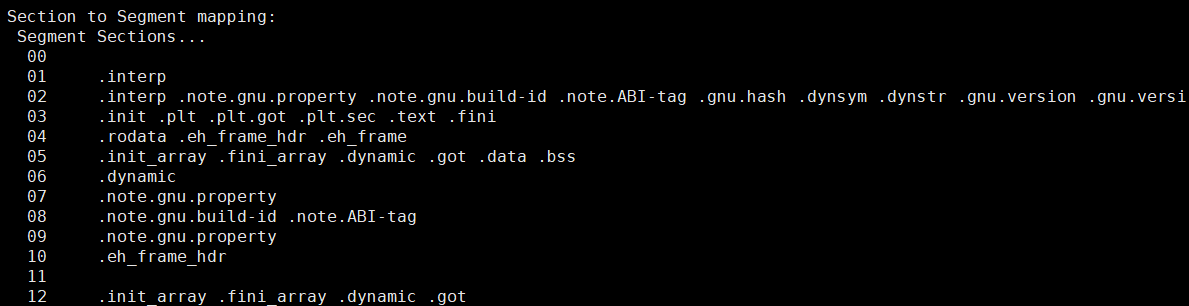
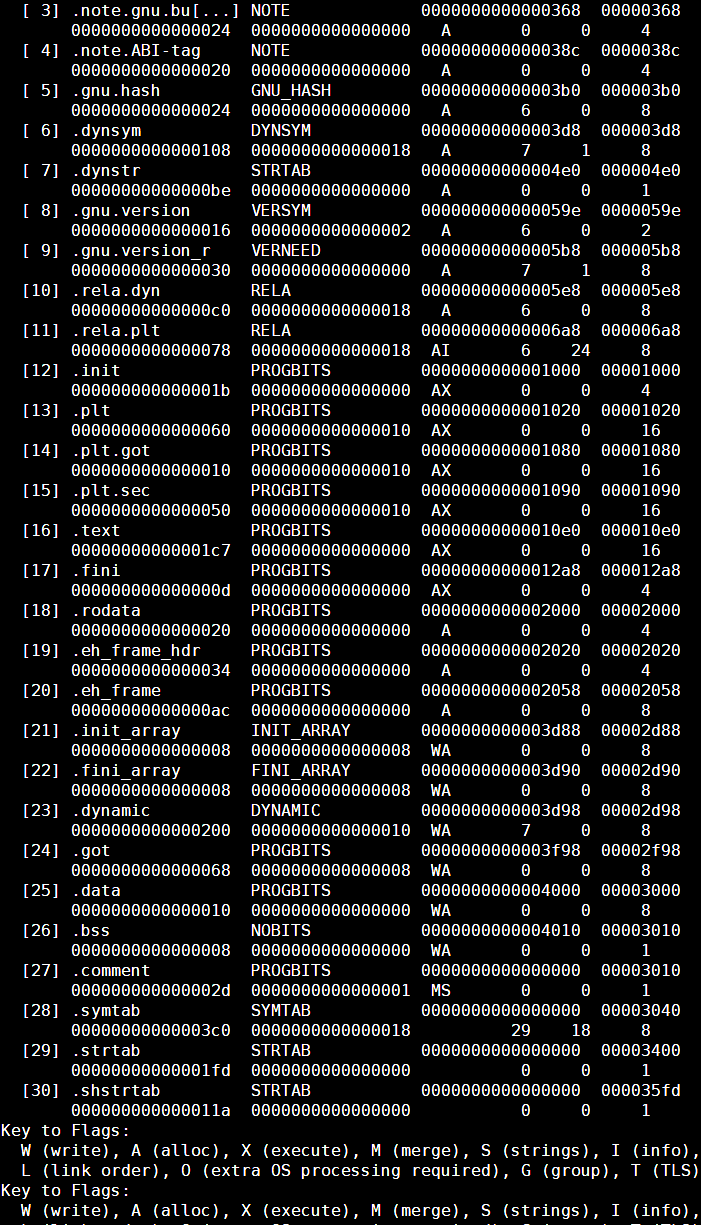
可以看到在我们的可执行程序中一共有13个段,每一个段后面是该段中包含的节;下面是我们可执行程序中的节:
这个合并⼯作也已经在形成ELF的时候,合并⽅式已经确定了,具体合并原则被记录在了ELF的 程序头表(Program header table) 中
那么为什么要将类似的节合并为段呢?
Section合并的主要原因是为了减少⻚⾯碎⽚,提⾼内存使⽤效率。如果不进⾏合并,假设⻚⾯⼤⼩为4096字节(内存块基本⼤⼩,加载,管理的基本单位),如果.text部分为4097字节,.init部分为512字节,那么它们将占⽤3个⻚⾯,⽽合并后,它们只需2个⻚⾯。- 此外,操作系统在加载程序时,会将具有相同属性的
section合并成⼀个⼤的segment,这样就可以实现不同的访问权限,从⽽优化内存管理和权限访问控制。
对于程序头表 和节头表⼜有什么⽤呢,ELF⽂件提供了2个不同的视图(视角)来让我们理解这两个部分:
- 链接视图(Linking view) - 对应节头表
Section header table:⽂件结构的粒度更细,将⽂件按功能模块的差异进⾏划分,静态链接分析的时候⼀般关注的是链接视图,能够理解 ELF ⽂件中包含的各个部分的信息。 - 执⾏视图(execution view) - 对应程序头表
Program header table:告诉操作系统如何加载可执⾏⽂件,完成进程内存的初始化。⼀个可执⾏程序的格式中,⼀定有program header table。 - 说⽩了就是:⼀个在链接时作⽤,⼀个在运⾏加载时作⽤。
我们可以在 ELF Header 中找到⽂件的基本信息,以及可以看到 ELF Header 是如何定位程序头表和节头表的: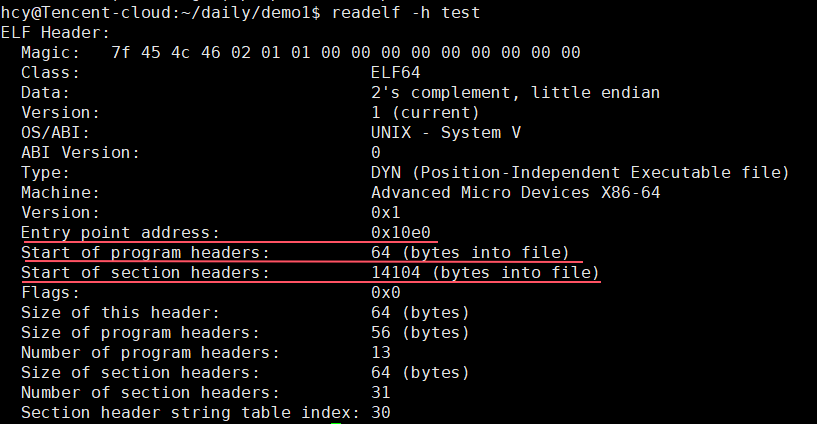
4.3 平坦模式编址
平坦模式编址(Flat Memory Model)是现代操作系统(如 Linux/Unix)最核心的内存编址方式,也是 ELF 可执行文件能被简单加载、运行的关键基础。
4.3.1 先搞懂:平坦模式编址是什么?
平坦模式编址是一种内存地址管理方式 ,核心特征是:整个进程的虚拟地址空间是一个单一、连续、无分段的线性地址空间,CPU 访问内存时只需使用一个 "绝对的线性地址",无需通过 "段基址 + 偏移量" 的方式拼接地址(对比早期的 "分段编址模式")。
简单比喻:
- 分段模式:内存像多本分开的书,找内容需要先指定 "哪本书(段)"+"第几页(偏移)";
- 平坦模式:内存像一本完整的大书,找内容只需指定 "全局第几页(单一地址)"。
4.3.2 平坦模式编址的好处
平坦模式下,链接器生成可执行文件时,就已经按 "最终要加载到内存的虚拟地址空间" 分配了所有节(.text/.data 等)的虚拟地址 (比如 0x401000),这些地址直接写在 ELF 文件中。加载时,加载器只需把 ELF 的代码 / 数据 "映射" 到这些预设的虚拟地址,无需修改文件中的任何地址(即无运行时重定位)
平坦模式让可执行文件在磁盘上就 "自带" 加载后的虚拟地址,加载时只需直接映射到这些虚拟地址,无需修改地址本身,仅需完成虚拟→物理的硬件映射,加载效率拉满。
而在ELF Header中存储的Entry point address存储的是:可执行文件加载到内存后,CPU 开始执行第一条指令的「虚拟地址」(平坦模式下的绝对线性地址)。简单来说:它是操作系统加载完 ELF 文件后,"告诉 CPU 该从哪里开始干活" 的地址 ------ 就像一本书的 "正文第一页页码",CPU 拿到这个地址就直接跳过去执行指令。
要注意的是它不是
main()函数的地址(核心误区)你写的
main()函数是程序的 "业务入口",但不是 CPU 执行的 "第一个入口":
- Entry point address 指向的是编译器自动插入的启动函数 (x86_64 Linux 下是
_start,x86 是_start/_entry);- 这个启动函数(
_start)负责:初始化进程运行环境(设置栈、传递命令行参数 / 环境变量、初始化全局变量)→ 调用main()函数 →main()执行完后,处理退出逻辑(调用exit())。
当然,它仅对 "可执行文件" 有意义:
- 对于
.o目标文件:e_entry值为 0(因为.o无法直接运行,无执行入口); - 对于共享库(
.so):e_entry通常也为 0(共享库是被其他程序加载的,无独立执行入口); - 仅对于 ELF 可执行文件(
ET_EXEC类型):e_entry是有效的、非 0 的虚拟地址。
下面是一个ELF可执行程序加载到内存的过程:
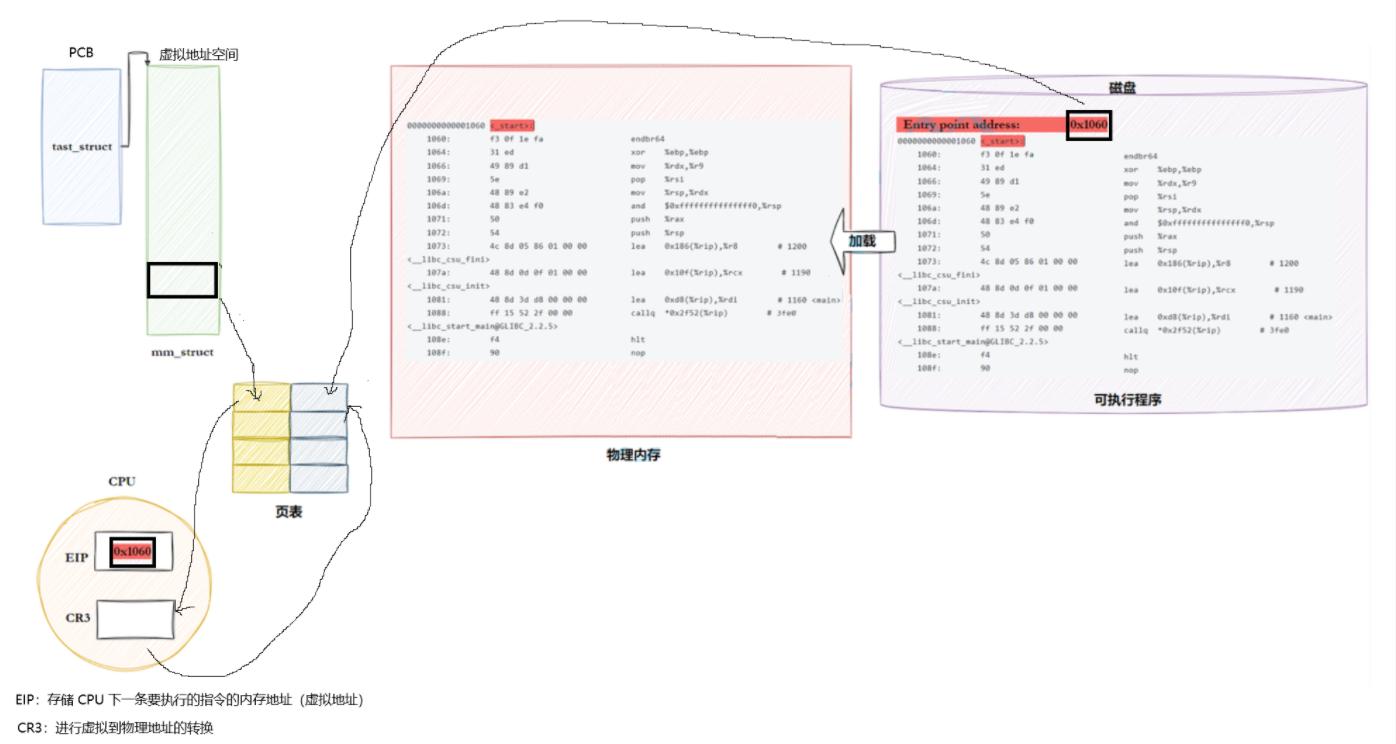
在操作系统中我们所使用的地址都是虚拟地址,操作系统会通过CR3寄存器进行虚拟地址到物理地址的转换。
操作系统加载可执行程序时,先为进程创建 PCB(进程控制块),再在 PCB 中初始化mm_struct(内存管理结构体),接着基于 ELF 文件的 LOAD 段信息,通过mm_struct构建进程的虚拟地址空间(包括页表):
五、链接与加载:从.o 到运行的完整流程
理解了 ELF,就能搞懂 "编译链接→加载运行" 的核心逻辑,分为静态链接和动态链接两种场景。
5.1 静态链接:编译时合并与地址重定位
⽆论是⾃⼰的.o, 还是静态库中的.o,本质都是把.o⽂件进⾏链接的过程,所以:研究静态链接,本质就是研究.o是如何链接的。
我们可以用objdump命令查看编译后的.o⽬标⽂件 :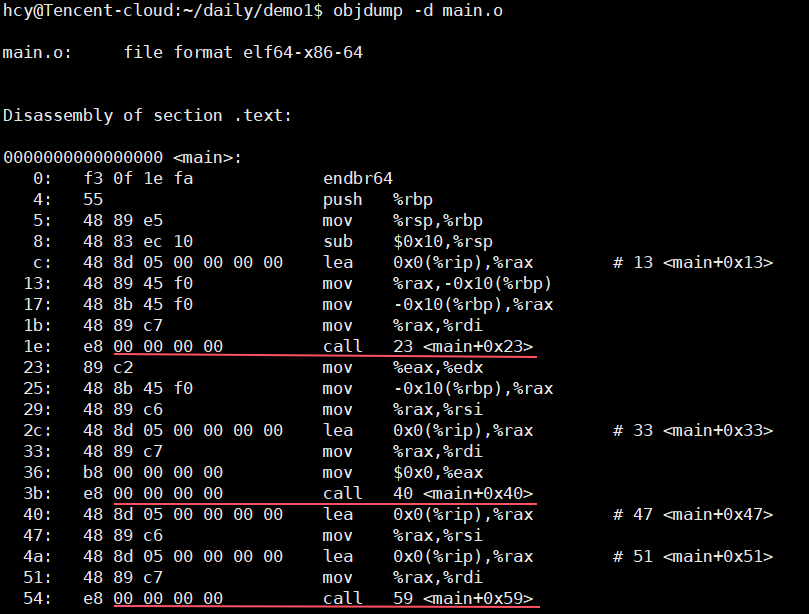
我们可以看到这⾥的call指令,它们对应之前调⽤的函数,但是你会发现他们的跳转地址都被设成了0。那这是为什么呢? 其实就是在编译 main.c 的时候,编译器是完全不知道我们使用的函数的存在的,⽐如他们位于内存的哪个区块,代码⻓什么样都是不知道的。因此,编辑器只能将这两个函数的跳转地址先暂时设为0。
那么这个地址会在什么时候被修正?链接的时候!为了让链接器将来在链接时能够正确定位到这些被修正的地址,在代码块(.data)中还存在⼀个重定位表,这张表将来在链接的时候,就会根据表⾥记录的地址将其修正。
静态链接是将多个.o文件(包括静态库中的.o)合并为一个可执行文件的过程:
- 合并节 :将所有
.text节合并为一个总.text节,.data节同理; - 符号解析 :查找所有未定义的符号(如函数调用、全局变量),匹配其他
.o中的定义; - 地址重定位 :修正符号的跳转地址(比如
.o中函数调用地址为 0,链接时替换为合并后的实际地址)。
所以链接其实就是将编译之后的所有⽬标⽂件连同⽤到的⼀些静态库运⾏时库组合,拼装成⼀个独⽴的可执⾏⽂件。其中就包括我们之前提到的地址修正,当所有模块组合在⼀起之后,链接器会根据我们的.o⽂件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从⽽修正它们的地址。这其实就是静态链接的过程。
所以,链接过程中会涉及到对.o中外部符号进⾏地址重定位,这也就是为什么.o文件被叫做可重定位文件。
5.2 动态链接:运行时加载与延迟绑定
动态链接避免了静态链接的文件体积过大问题,核心是 "运行时加载库并动态修正地址"。
动态链接其实远⽐静态链接要常⽤得多。⽐如我们查看下test这个可执⾏程序依赖的动态库,会发现它就⽤到了⼀个C动态链接库:

这⾥的 libc.so是C语⾔的标准库,⾥⾯提供了常⽤的标准输⼊输出、⽂件、字符串处理等等这些功能。 那为什么编译器默认不使⽤静态链接呢?
静态链接会将编译产⽣的所有⽬标⽂件,连同⽤到的各种库,合并形成⼀个独⽴的可执⾏⽂件,它不需要额外的依赖就可以运⾏。照理来说应该更加⽅便才对是吧?
静态链接最⼤的问题在于⽣成的⽂件体积⼤,并且相当耗费内存资源。随着软件复杂度的提升,我们的操作系统也越来越臃肿,不同的软件就有可能都包含了相同的功能和代码,显然会浪费⼤量的硬盘空间。
这个时候,动态链接的优势就体现出来了,我们可以将需要共享的代码单独提取出来,保存成⼀个独⽴的动态链接库,等到程序运⾏的时候再将它们加载到内存,这样不但可以节省空间,因为同⼀个模块在内存中只需要保留⼀份副本,可以被不同的进程所共享。那么动态链接到底是如何⼯作的?
⾸先要交代⼀个结论,动态链接实际上将链接的整个过程推迟到了程序加载的时候。⽐如我们去运⾏⼀个程序,操作系统会⾸先将程序的数据代码连同它⽤到的⼀系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,操作系统会根据当前地址空间的使⽤情况为它们动态分配⼀段内存。当动态库被加载到内存以后,⼀旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。
5.2.1 可执行程序的初始化
我们知道,在C/C++程序中,当程序开始执⾏时,它会跳转到_start函数,这是⼀个由C运⾏时库(通常是glibc)或链接器(如ld)提供的特殊函数。 在 _start 函数中,会执⾏⼀系列初始化操作,这些操作包括:
-
设置堆栈:为程序创建⼀个初始的堆栈环境。
-
初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段。
-
**动态链接:**这是关键的⼀步,
_start函数会调⽤动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调⽤和变量访问能够正确地映射到动态库中的实际地址。动态链接器:
- 动态链接器(如
ld-linux.so)负责在程序运⾏时加载动态库。 - 当程序启动时,动态链接器会解析程序中的动态库依赖,并加载这些库到内存中。
环境变量和配置⽂件:
- Linux系统通过环境变量(如LD_LIBRARY_PATH)和配置⽂件(如
/etc/ld.so.conf及其⼦配置⽂件)来指定动态库的搜索路径。 - 这些路径会被动态链接器在加载动态库时搜索。
缓存⽂件:
- 为了提⾼动态库的加载效率,Linux系统会维护⼀个名为
/etc/ld.so.cache的缓存⽂件。 - 该⽂件包含了系统中所有已知动态库的路径和相关信息,动态链接器在加载动态库时会⾸先搜索这个缓存⽂件。
- 动态链接器(如
-
调⽤
__libc_start_main:⼀旦动态链接完成,_start函数会调⽤__libc_start_main(这是glibc提供的⼀个函数)。__libc_start_main函数负责执⾏⼀些额外的初始化⼯作,⽐如设置信号处理函数、初始化线程库(如果使⽤了线程)等。 -
调⽤
main函数:最后,__libc_start_main函数会调⽤程序的main函数,此时程序的执⾏控制权才正式交给⽤⼾编写的代码。 -
处理
main函数的返回值:当main函数返回时,__libc_start_main会负责处理这个返回值,并最终调⽤ _exit 函数来终⽌程序。
上述过程描述了C/C++程序在 main 函数之前执⾏的⼀系列操作,但这些操作对于⼤多数程序员来说是透明的。我们通常只需要关注 main 函数中的代码,⽽不需要关心底层的初始化过程。然⽽,了解这些底层细节有助于我们更好地理解程序的执⾏流程和调试问题。
5.2.2 程序和动态库的映射
动态库为了随时进⾏加载,为了⽀持并映射到任意进程的任意位置,对动态库中的⽅法也采用平坦模式编址,因此动态库文件也是ELF文件。
动态库也是⼀个⽂件,要访问也是要被先加载,要加载也是要被打开的,让我们的进程找到动态库的本质:也是⽂件操作,不过我们访问库函数,通过虚拟地址进⾏跳转访问的,所以需要把动态库映射到进程的地址空间中,如下图所示:
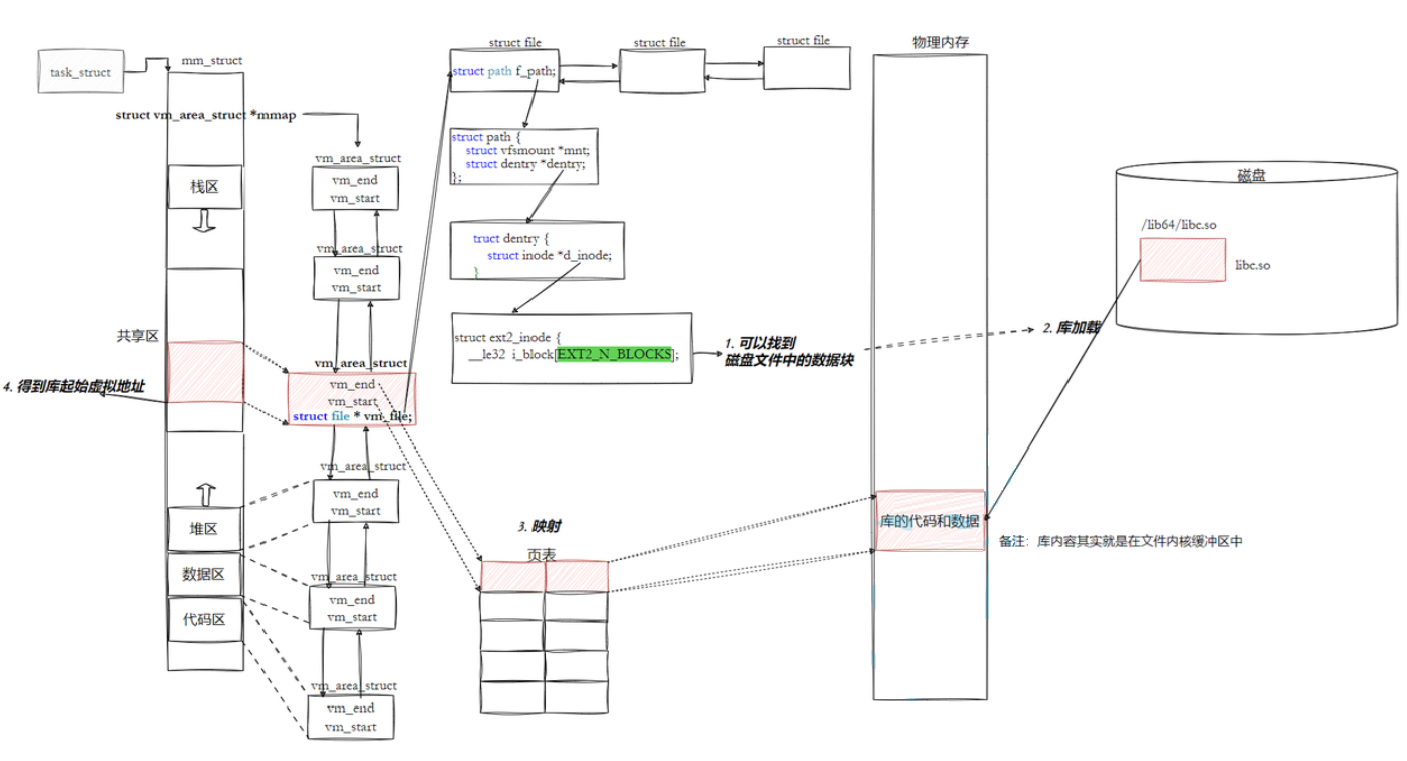
库已经被我们映射到了当前进程的地址空间中,所以:访问库中任意⽅法,只需要知道库的起始虚拟地址(加载基址)+⽅法偏移量即可定位库中的⽅法,库的虚拟起始地址和库中每一个方法的偏移量()我们都知道了,而且整个调⽤过程,是从代码区跳转到共享区,调⽤完毕在返回到代码区,整个过程完全在进程地址空间中进⾏的。
动态库编译时采用PIC(位置无关代码) ,所有内部符号(如printf)都以 "相对偏移" 存储,而非固定绝对地址 ------ 这是为了适配 "加载基址不固定" 的特点:
- 不同进程加载同一个
libc.so时,分配的加载基址可能不同(比如进程 A 是0x7f8a9b700000,进程 B 是0x7f9c8d100000); - 但
printf的相对偏移量始终是0x554c0,只需用 "当前进程的加载基址 + 固定偏移",就能得到正确的绝对地址; - 平坦模式的大地址空间保证了每个进程都能找到空闲区间作为加载基址,且不会冲突。
5.2.3 全局偏移量表GOT(global offset table)
也就是说,我们的程序运⾏之前,先把所有库加载并映射,所有库的起始虚拟地址都应该提前知道,然后对我们加载到内存中的程序的库函数调⽤进⾏地址修改,在内存中⼆次完成地址设置(这个叫做加载地址重定位),但是我们知道代码区的内容在进程中是只读的,不可以进行修改,所以:动态链接采⽤的做法是在 .data (可执⾏程序或者库⾃⼰)中专⻔预留⼀⽚区域⽤来存放函数的跳转地址,它也被叫做全局偏移表GOT,表中每⼀项都是本运⾏模块要引⽤的⼀个全局变量或函数的地址。
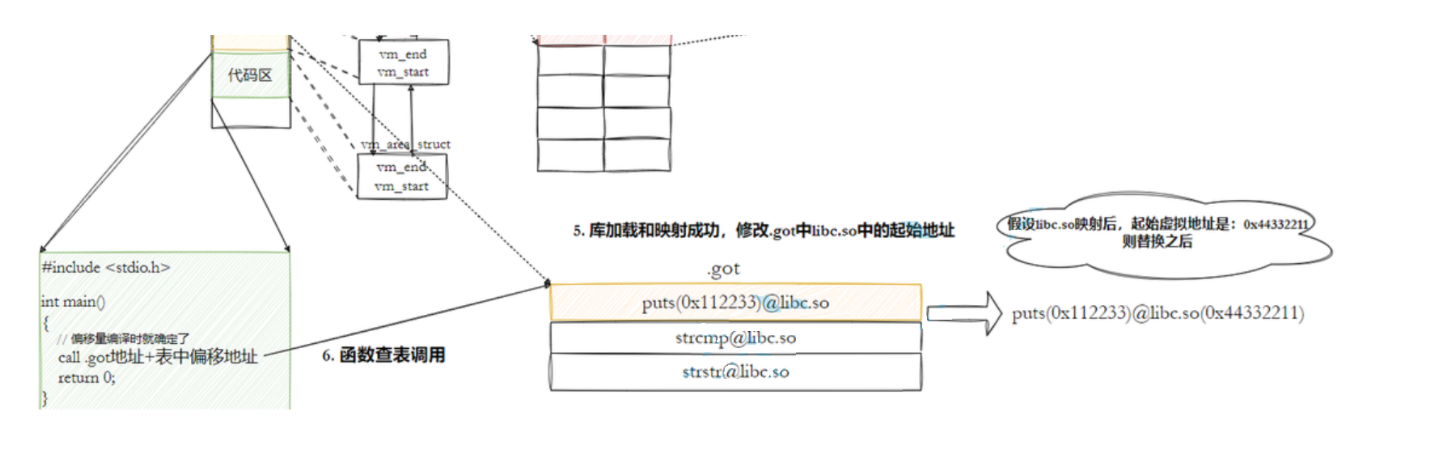
由于代码段只读,我们不能直接修改代码段。但有了GOT表,代码便可以被所有进程共享。但在不同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到GOT表上,就是每个进程的每个动态库都有独⽴的GOT表,所以进程间不能共享GOT表。
在调⽤函数的时候会⾸先查表,然后根据表中的地址来进⾏跳转,这些地址在动态库加载的时候会被修改为真正的地址。
这种⽅式实现的动态链接就被叫做 PIC 。换句话说,我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运⾏,并且能够被所有进程共享,这也是为什么之前我们给编译器指定-fPIC参数的原因,PIC=相对编址+GOT。
5.2.4 库间依赖和延迟绑定
不仅仅有可执⾏程序调⽤库,库也会调⽤其他库!库之间是有依赖的,如何做到库和库之间互相调⽤也是与地址⽆关的呢?和可执⾏⼀样,库中也有GOT表!这也就是为什么⼤家为什么都是ELF的格式!
由于动态链接在程序加载的时候需要对⼤量函数进⾏重定位,这⼀步显然是⾮常耗时的。为了进⼀步降低开销,我们的操作系统还做了⼀些其他的优化,⽐如延迟绑定,或者也叫PLT(过程连接表(Procedure Linkage Table))。与其在程序⼀开始就对所有函数进⾏重定位,不如将这个过程推迟到函数第⼀次被调⽤的时候,因为绝⼤多数动态库中的函数可能在程序运⾏期间⼀次都不会被使⽤到。
思路是:GOT中的跳转地址默认会指向⼀段辅助代码,它也被叫做桩代码/stup。在我们第⼀次调⽤函数的时候,这段代码会负责查询真正函数的跳转地址,并且去更新GOT表。于是我们再次调⽤函数的时候,就会直接跳转到动态库中真正的函数实现。
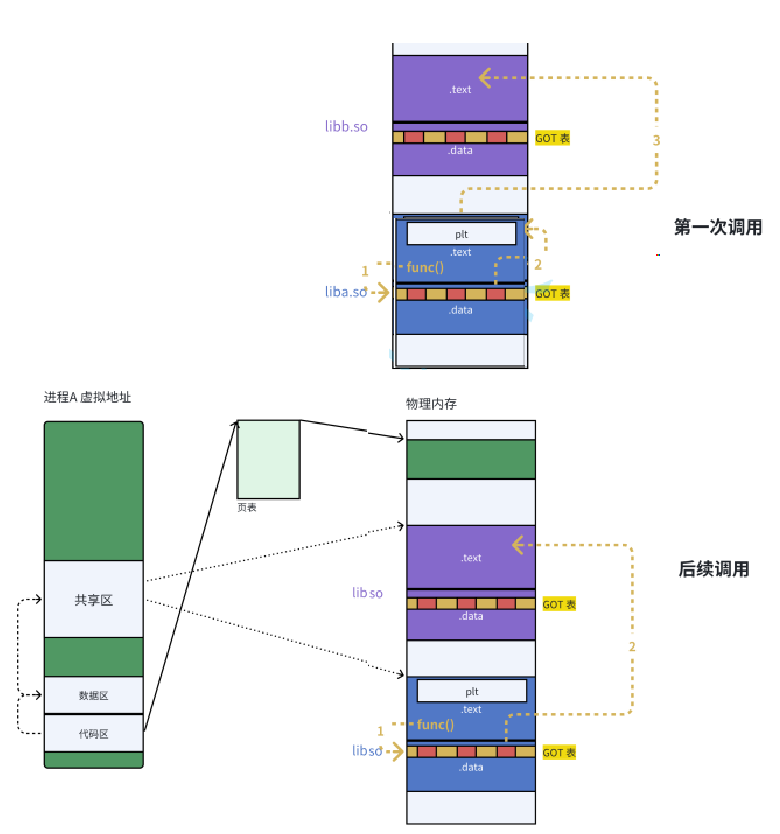
- GOT:存储符号的实际地址(位于可读写的
.data节,可动态修改); - PLT:避免直接修改只读的
.text节,第一次调用函数时,通过 PLT 触发动态链接器解析符号地址,更新到 GOT,后续调用直接从 GOT 获取地址(延迟绑定)。
六、核心总结与适用场景
动静态库选择建议
- 用静态库:程序需独立运行(无依赖)、库功能稳定不更新(如基础工具库);
- 用动态库:多程序共享库(节省内存)、库需频繁更新(如业务逻辑库)、可执行文件体积敏感。
核心知识点梳理
- 库的本质:二进制可复用代码,静态合并、动态加载;
- ELF 格式:链接与加载的基础,区分链接视图(节)和执行视图(段);
- 链接:静态重定位(编译时)、动态重定位(运行时,GOT/PLT);
- 加载:ELF 映射到虚拟地址空间,动态链接器解析依赖库,最终调用
main。
实用命令附录
| 功能 | 命令 |
|---|---|
| 制作静态库 | ar -rc libxxx.a xxx.o yyy.o |
| 制作动态库 | gcc -fPIC -shared -o libxxx.so xxx.o |
| 查看 ELF 头 | readelf -h xxx.o/a.out/libxxx.so |
| 查看动态库依赖 | ldd a.out |
| 反汇编代码节 | objdump -d a.out |
| 更新动态库缓存 | sudo ldconfig |
通过本文,你不仅掌握了动静态库的制作与使用,更理解了从编译链接到加载运行的底层逻辑。库与 ELF 是 Linux 开发的基础,吃透这些知识,能帮你解决大部分 "链接错误""库找不到""加载失败" 等问题,为后续深入内核、驱动开发打下基础。
尾声
本章讲解就到此结束了,若有纰漏或不足之处欢迎大家在评论区留言或者私信,同时也欢迎各位一起探讨学习。感谢您的观看!