本文分析SimpleVLA-RL ,它是一款端到端 在线强化学习 的VLA框架。
核心目标*是解决VLA模型面临的两个挑战:
- 数据稀缺,大规模人类操作机器人轨迹昂贵难获取
- 泛化能力有限,对分布偏移任务适应性差
论文地址:SimpleVLA-RL: Scaling VLA Training via Reinforcement Learnin
开源地址:https://github.com/PRIME-RL/SimpleVLA-RL
一、核心概述
核心设计 :
- 基于LLM通用RL框架扩展,融入VLA特定设计,
交互式轨迹采样、可扩展并行化、多环境渲染、优化损失计算。 - 并通过三大探索增强策略,
动态采样、更高裁剪范围、更高采样温度,提升性能。 - 结果奖励建模,二元奖励:任务成功=1,失败=0。
- 训练目标,基于
GRPO算法,去除KL正则化。
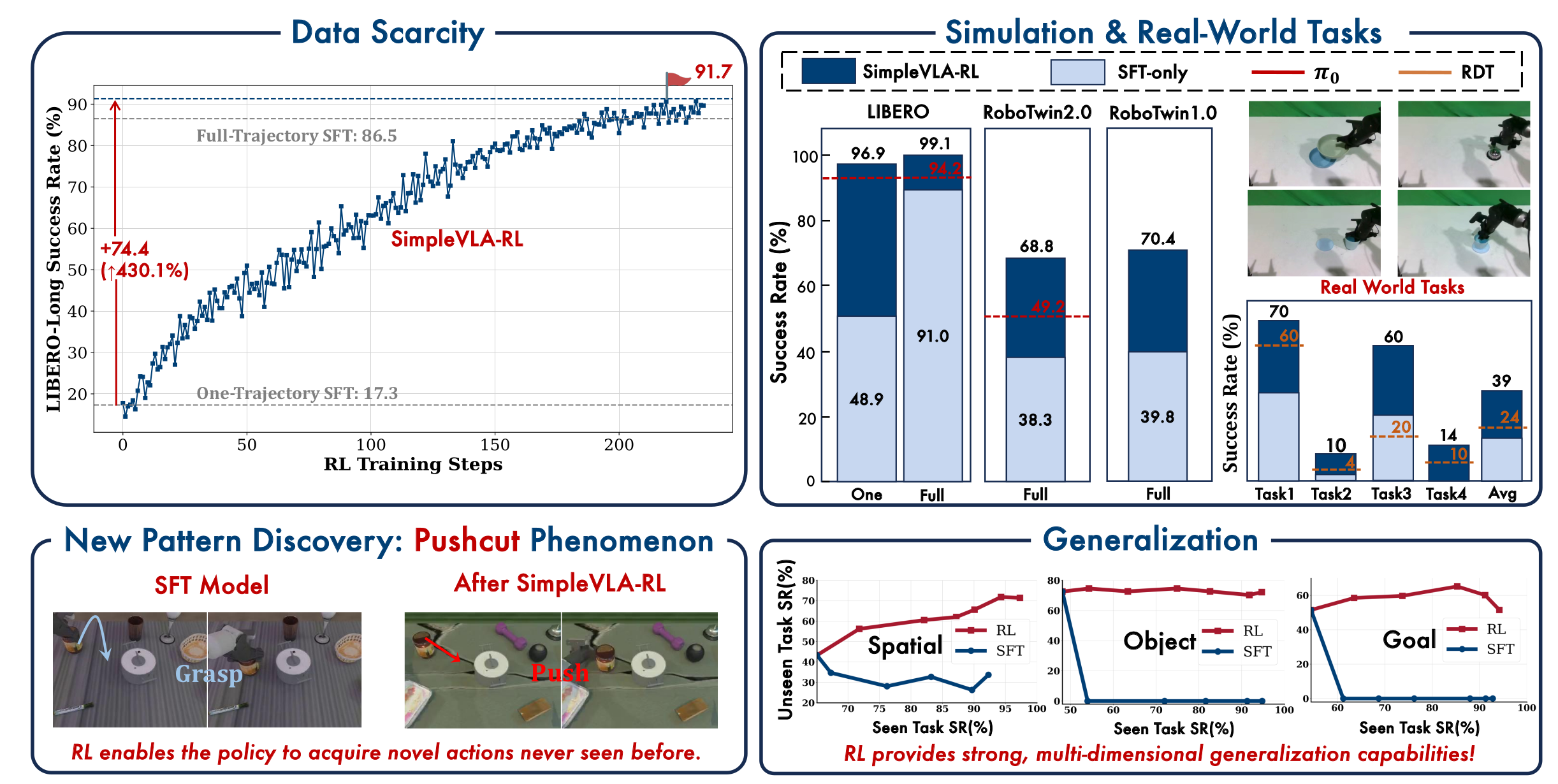
这张图从数据稀缺、任务性能、策略创新、泛化能力四个维度,集中验证了SimpleVLA-RL的核心价值,核心结论如下:
-
缓解数据稀缺 :
仅用"单轨迹SFT"(1条任务演示)+SimpleVLA-RL,就能让LIBERO-Long任务成功率从17.3%提升至91.7%(+74.4%),甚至超越"全轨迹SFT"(86.5%),证明RL可大幅降低VLA模型对海量离线数据的依赖。 -
提升仿真与实世界性能:
- 仿真任务:SimpleVLA-RL在LIBERO(99.1%)、RoboTwin2.0(68.8%)、RoboTwin1.0(70.4%)的成功率远超SFT-only和基线模型(π₀、RDT);
- 实世界任务:仅用仿真训练的SimpleVLA-RL,4个实世界任务平均成功率达39%,显著优于SFT-only和RDT。
-
促成策略创新 :SimpleVLA-RL让模型探索出训练数据中
未有的"pushcut"新策略(用"推"替代SFT的"抓取"动作),证明RL能突破人类操作模式的局限,自主发现更高效的行为。 -
增强多维度泛化 :
在空间、物体、任务维度,SimpleVLA-RL的unseen任务成功率远高于SFT,且随seen任务性能提升,泛化能力持续增强,具备强跨场景/物体/任务的适配性。
二、框架设计分析:VLA与LLM的RL本质差异及算法基础
通过明确LLM与VLA的RL公式差异,定位适配矛盾,引入GRPO算法提供底层支撑;这些是SimpleVLA-RL框架设计的理论基础。
1. LLM的RL范式:静态、离散、无交互的文本生成逻辑
- 状态( s t s_t st) :
纯文本序列聚合,由"初始提示词+已生成令牌"构成,单模态、静态不变。 - 动作( a t a_t at) :
离散令牌采样,从模型词汇表 V V V中选择下一个令牌,概率化分布支持RL梯度计算。 - 环境(Env) :结果导向的奖励反馈,
无状态转移、无中间反馈,仅在序列生成完成后给出奖励。 - Rollout(轨迹生成) :
自回归静态生成,无需环境交互,生成全程无反馈调整。
2. VLA的RL范式:动态、连续、强交互的机器人操作逻辑
| 维度 | VLA的RL具体定义 | 与LLM的核心差异 | 带来的核心挑战 |
|---|---|---|---|
| 状态( s t s_t st) | 多模态融合: s t = ( o t v i s , o t p r o p , l t a s k ) s_t = (o_t^{vis}, o_t^{prop}, l_{task}) st=(otvis,otprop,ltask) - o t v i s o_t^{vis} otvis:视觉观测(RGB图、深度图) - o t p r o p o_t^{prop} otprop:本体感受(关节角度、末端执行器姿态) - l t a s k l_{task} ltask:语言指令 | 从"单模态文本"到"多模态物理信息",状态随环境动态变化 | 状态维度高、融合难度大,计算成本高 |
| 动作( a t a_t at) | 连续控制指令: a t ∈ R d a_t \in \mathbb{R}^d at∈Rd(如 d = 7 d=7 d=7表示6-DoF姿态+夹爪位置),通过解码器生成 | 从"离散令牌"到"连续向量",动作直接影响物理环境 | 连续动作的采样和梯度计算更复杂,无法直接套用LLM逻辑 |
| 环境(Env) | 物理/仿真环境: - 状态转移: s t + 1 = E n v ( s t , a t ) s_{t+1} = Env(s_t, a_t) st+1=Env(st,at) - 奖励: R = α R o u t c o m e + ∑ w i ϕ i ( s t , a t ) R = \alpha R_{outcome} + \sum w_i \phi_i(s_t,a_t) R=αRoutcome+∑wiϕi(st,at) | 从"无状态转移"到"闭环动态交互",环境是训练核心参与者 | 环境交互速度慢、成本高,过程奖励设计复杂 |
| Rollout(轨迹生成) | 迭代交互生成:生成动作块→执行→更新状态→循环,依赖实时环境反馈。 思路流程: 1. 模型输入当前状态 s t s_t st,生成长度为 k k k 的动作块 ( a t , . . . , a t + k − 1 ) (a_t, ..., a_{t+k-1}) (at,...,at+k−1) 2. 机器人执行动作块,环境更新状态为 s t + k s_{t+k} st+k 3. 模型输入 s t + k s_{t+k} st+k,生成下一个动作块 4. 重复至任务完成或达到最大步数,生成完整轨迹 τ = ( ( s 0 , a 0 ) , . . . , ( s T , a T ) ) \tau = ((s_0,a_0), ..., (s_T,a_T)) τ=((s0,a0),...,(sT,aT)) | 从"静态一次性生成"到"动态闭环生成",轨迹依赖实时环境反馈 | Rollout效率极低(单条轨迹生成时间是LLM的10倍以上),且需处理动作执行后的状态噪声 |
3. 核心算法:Group Relative Policy Optimization(GRPO)
(1)GRPO的核心逻辑
- 传统RL痛点:需训练价值网络估计状态价值,易过拟合导致优势估计偏差。
- GRPO创新:
通过"组内轨迹对比"计算优势,无需价值网络。流程为:- 用行为政策 π θ o l d \pi_{\theta_{old}} πθold生成 G G G条轨迹 { τ i } i = 1 G \{\tau_i\}_{i=1}^G {τi}i=1G;
- 计算每条轨迹的总奖励 R i R_i Ri;
- 组相对归一化得到优势: A ^ i = R i − m e a n ( { R i } ) s t d ( { R i } ) \hat{A}_i = \frac{R_i - mean(\{R_i\})}{std(\{R_i\})} A^i=std({Ri})Ri−mean({Ri})。
(2)GRPO的核心公式
- 重要性采样比: r i , t ( θ ) = π θ ( a i , t ∣ s i , t ) π θ o l d ( a i , t ∣ s i , t ) r_{i,t}(\theta) = \frac{\pi_\theta(a_{i,t} | s_{i,t})}{\pi_{\theta_{old}}(a_{i,t} | s_{i,t})} ri,t(θ)=πθold(ai,t∣si,t)πθ(ai,t∣si,t)(限制政策更新步长)
- 优化目标: L G R P O = E min ( r i , t A \^ i , c l i p ( r i , t , 1 − ϵ , 1 + ϵ ) A \^ i ) − β K L ( π θ ∣ ∣ π r e f ) L_{GRPO} = \mathbb{E}\left \\min(r_{i,t}\\hat{A}_i, clip(r_{i,t}, 1-\\epsilon, 1+\\epsilon)\\hat{A}_i) - \\beta KL(\\pi_\\theta \|\| \\pi_{ref}) \\right LGRPO=Emin(ri,tA\^i,clip(ri,t,1−ϵ,1+ϵ)A\^i)−βKL(πθ∣∣πref)
(3)GRPO适配VLA的核心优势
- 无需价值网络:简化训练流程,避免价值估计偏差,适配VLA多模态、高噪声状态;
支持并行训练:组内轨迹可独立生成和计算优势,匹配SimpleVLA-RL的并行化设计;- 稳定性强:裁剪机制和KL正则化限制政策突变,适配VLA长horizon轨迹训练。
4. 小结
明确VLA与LLM的RL差异,定位核心挑战,为后续框架设计提供"问题靶点":
- 针对VLA的闭环交互需求,设计"交互式VLA Rollout";
- 针对Rollout效率低,设计"可扩展并行化+多环境渲染";
- 针对奖励设计复杂,简化为"结果奖励建模";
- 以GRPO为基础,优化训练目标。
三、SimpleVLA-RL框架核心设计
首先看一下SimpleVLA-RL的模型架构,如下图所示。
对比了SFT(监督微调)与SimpleVLA-RL的思路流程,核心是展现 "被动依赖离线数据" 与 "主动在线交互优化" 的范式差异。
| 维度 | SFT流程 | SimpleVLA-RL流程 |
|---|---|---|
| 数据来源 | 静态离线人类轨迹(被动依赖) | 动态在线环境交互轨迹(主动生成) |
| 环境参与度 | 无环境交互(训练与环境分离) | 闭环交互(环境是训练的核心参与者) |
| 优化逻辑 | 模仿已有行为(监督学习) | 奖励驱动探索(强化学习) |
| 泛化能力支撑 | 依赖训练数据覆盖范围 | 依赖主动探索的多样化轨迹 |
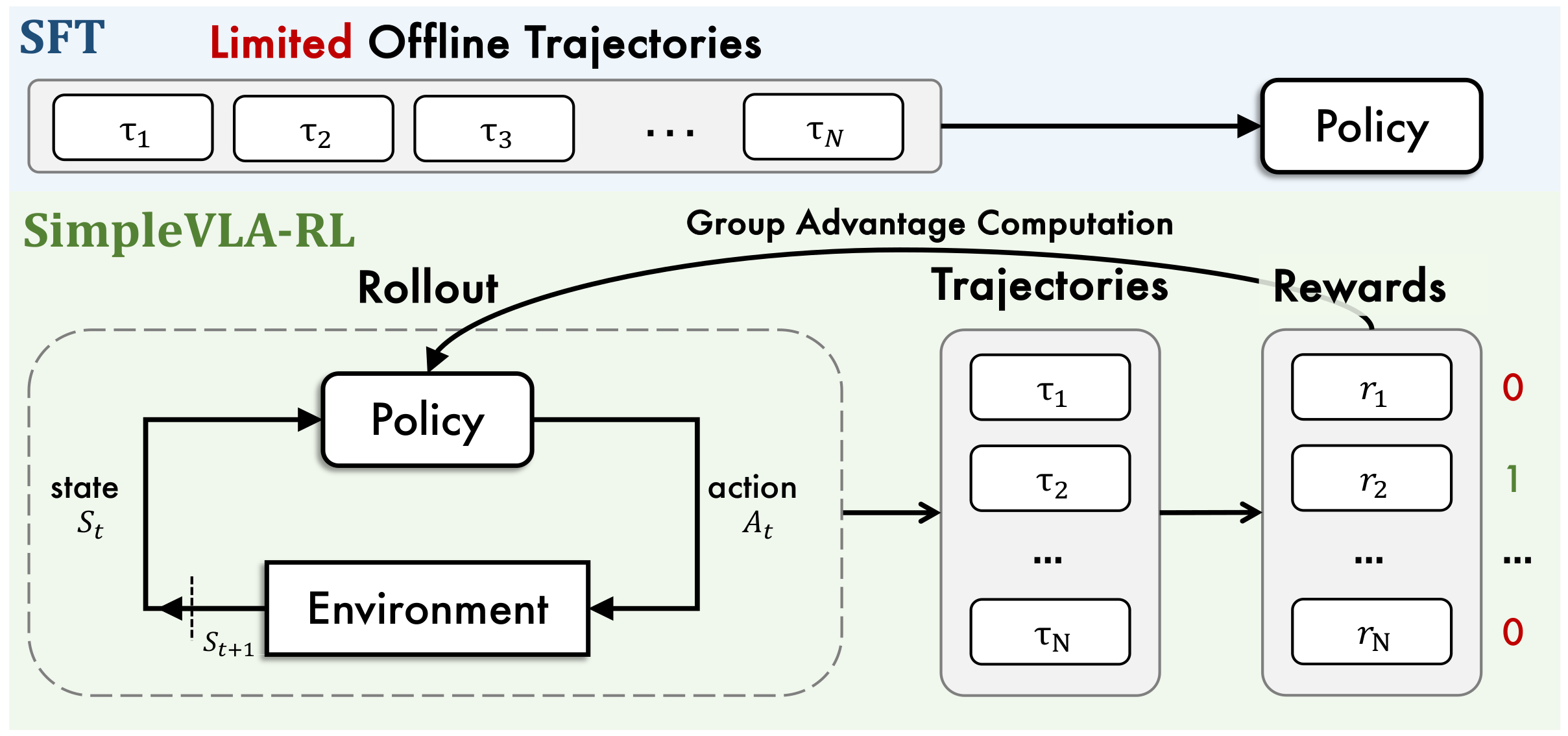
SimpleVLA-RL流程分为 "闭环Rollout生成轨迹"→"组优势计算奖励"→"策略迭代更新" 三个核心环节,形成"交互-评估-优化"的循环:
环节1:Rollout(轨迹生成)------Policy与环境的闭环交互
这是SimpleVLA-RL突破SFT局限的核心步骤:
输入:当前环境状态 $S_t$(视觉+本体感受+语言指令的多模态信息);- 交互循环:
- Policy接收状态 S t S_t St,输出机器人动作 A t A_t At;
- 环境执行动作 A t A_t At,更新为新状态 S t + 1 S_{t+1} St+1;
- 新状态 S t + 1 S_{t+1} St+1 反馈给Policy,重复上述步骤,直到任务完成或达到最大步数,生成一条完整轨迹 τ \tau τ。
- 本质:主动探索生成数据------不再依赖静态离线轨迹,而是通过Policy与环境的动态交互,自主生成多样化轨迹,解决SFT的数据稀缺问题。
环节2:Group Advantage Computation(组优势计算)------基于轨迹奖励评估策略
输入:Rollout环节生成的多组轨迹(τ₁~τₙ);- 奖励计算:采用二元结果奖励 (任务成功则轨迹对应奖励 r = 1 r=1 r=1,失败则 r = 0 r=0 r=0),简化传统RL复杂的过程奖励设计;
- 组优势计算:用GRPO算法,通过"同组内轨迹的奖励对比"计算归一化优势(无需单独训练价值网络),评估每条轨迹的策略优劣。
环节3:策略迭代更新
将"轨迹+对应的组优势"作为优化信号,更新Policy,让Policy更倾向于生成"奖励高(任务成功)"的轨迹。
之后,更新后的Policy会再次进入Rollout环节与环境交互,开启下一轮"生成轨迹→评估→优化"的循环,持续提升策略性能。
下面聚焦专为VLA模型设计的高效RL框架,基于veRL扩展并做VLA定制化适配。
3.1 交互式VLA Rollout:适配VLA的闭环环境交互
设计目的
解决"VLA需与物理环境动态交互,无法用LLM静态文本生成逻辑"的问题。
具体实现
- 采用令牌化动作解码策略 :
将机器人连续控制指令编码为"动作令牌",让VLA模型通过自回归方式生成动作序列,对齐LLM文本令牌生成逻辑,降低适配成本; - 闭环交互流程:
模型接收多模态状态→生成长度为k的"动作块"→环境执行动作块→更新为新状态→反馈给模型生成下一个动作块,循环至任务结束,生成完整轨迹。
核心价值
让VLA模型能"主动与环境交互生成轨迹",替代SFT依赖的"静态离线人类轨迹",从根源上缓解数据稀缺问题。
核心伪代码解析
python
def rollout(policy , dataset , number_sample =8, max_steps=None):
rollout_dataset = [] # 存储最终生成的轨迹数据
for batch in dataset: # 遍历每个输入批次
batch = batch.repeat(number_sample ) # 批量重复采样,提升轨迹多样性
outputs = policy.generate(batch , temperature =1.0) # LLM基础采样(铺垫VLA动作采样)
rollout_dataset .append ((batch , outputs)) # 暂存初始数据
# 并行环境初始化
envs = env_process_pool .submit(batch.initialize) # 并行提交环境初始化任务
states = env_process_pool .submit(envs.setup) # 并行完成状态初始化
# 核心闭环交互循环
for t in range(max_steps):
actions = policy.generate(states , temperature =1.0) # VLA生成动作令牌(随机采样)
# 存储当前步的状态-动作对
rollout_dataset .append ({f"{e.name}_step_{t}": (s,a) for e,s,a in zip(envs ,states ,actions)})
# 环境执行动作,更新状态
states , dones = env_process_pool .submit(envs.step , actions)
# 过滤已完成任务,保留活跃任务
active = [(e,s) for e,s,d in zip(envs ,states ,dones) if not d]
if not active: # 无活跃任务时提前终止
break
envs , states = zip(* active) # 更新活跃环境与状态
return rollout_dataset # 返回完整轨迹数据集伪代码关键细节
- 批量重复采样(
batch.repeat(number_sample)) :单批次重复 n u m b e r s a m p l e number_sample numbersample次,提升轨迹多样性,减少环境初始化次数,提升Rollout吞吐量; - 并行环境处理(
env_process_pool):多进程/多线程池管理多个仿真环境,并行交互提升效率,解决VLA Rollout耗时问题; - 闭环交互循环:实现"模型生成动作→环境执行→状态反馈→模型再生成"的核心逻辑,是主动探索生成轨迹的关键;
- 活跃任务过滤:移除已完成任务的环境,避免无效计算,适配长horizon任务。
3.2 结果奖励建模:简化VLA的奖励设计
设计目的
解决"VLA任务中过程奖励难以手工设计、可扩展性差"的问题。
具体实现
采用二元结果奖励 ------若轨迹对应的任务最终成功,整条轨迹的所有动作令牌奖励均为1;若任务失败,奖励均为0。奖励函数定义为:
R ( a i , t ∣ s i , t ) = { 1 , i s s u c c e s s f u l t r a j i ( a i , s i ) , 0 , o t h e r w i s e . R\left(a_{i, t} | s_{i, t}\right)= \begin{cases}1, & is_successful \lefttraj_{i}\\left(a_{i}, s_{i}\\right)\\right, \\ 0, & otherwise. \end{cases} R(ai,t∣si,t)={1,0,issuccessfultraji(ai,si),otherwise.
落地关键
依赖环境内置的"任务成功判定器":
- 仿真环境:通过物理引擎数据自动判定(物体坐标、姿态、重叠度等),准确率100%;
- 实世界环境:通过视觉识别+任务约束规则自动判定,噪声远低于过程奖励。
设计逻辑拆解
-
为什么选择"二元奖励"?
- 降低复杂度:避免连续奖励的梯度校准难题;
- 对齐GRPO算法:提供明确的轨迹优劣标签,无需额外归一化处理;
- 聚焦核心目标:引导模型全力探索任务成功策略,无中间模糊地带。
-
为什么选择"轨迹级全步统一奖励"?
- VLA模型是自回归动作生成模型,每一步都需要梯度更新信号;
- 若仅最后一步给奖励,前面步骤无法获得有效梯度,无法学习步骤间关联逻辑;
- 全步统一奖励让模型知道"整条轨迹的动作均为有效/无效",优化整个动作序列。
-
为什么"忽略中间过程"是优势?
- 摆脱人类操作轨迹束缚,自主探索更高效策略;
- 促成"pushcut"现象发现,实现策略创新;
- 聚焦"任务成功"核心需求,而非"模仿人类过程"。
核心价值
- 简化框架部署:一套规则适配所有VLA操作任务,无需针对不同任务定制奖励;
- 降低成本:无需标注中间过程奖励,避免与"数据稀缺"痛点叠加;
- 支撑策略创新:为探索增强策略提供发挥空间,引导模型突破传统策略;
- 对齐GRPO算法:轨迹级二元奖励直接作为优势计算输入,提升训练稳定性。
3.3 探索增强(Exploration Enhancements):突破VLA行为固化
核心目标是解决VLA模型在RL训练中"行为固化、探索不足"的痛点,在保证训练稳定的前提下,最大化策略的探索广度和有效性。
核心背景
机器人操作任务是"多解空间",但传统RL和SFT存在局限:
- SFT让模型复刻人类固定模式,缺乏自主探索动力;
- 传统RL探索机制不适配VLA的"连续动作+闭环交互"场景;
- 结果奖励的二元性加剧"梯度消失风险"(组内全成功/全失败时优势估计为零)。
策略一:动态采样(Dynamic Sampling)------ 解决"梯度消失"
核心痛点 :无动态采样时,组内全成功/全失败会导致GRPO优势估计无意义(分母为0或分子为0),梯度为零,训练停滞。
设计逻辑:通过"筛选混合结果组",确保每组轨迹中既有成功也有失败,让GRPO能计算有效优势,维持梯度流动。
具体实现
采样时主动排除"全成功"或"全失败"的组,直到批量中仅包含"混合结果组"(组内成功轨迹数 0 < k < G 0 < k < G 0<k<G),公式定义为:
0 < ∣ { t r a j i ( a i , s i ) ∣ i s s u c c e s s f u l t r a j i ( a i , s i ) } ∣ < G 0<\left|\left\{traj_{i}\left(a_{i}, s_{i}\right) | is_successful \lefttraj_{i}\\left(a_{i}, s_{i}\\right)\\right\right\}\right|<G 0<∣{traji(ai,si)∣issuccessfultraji(ai,si)}∣<G
- 无动态采样:训练中期梯度波动,LIBERO-Long任务成功率最高仅75%;
- 有动态采样:训练全程梯度稳定,成功率最终突破90%,收敛速度提升20%。
策略二:更高裁剪范围(Clipping Higher)------ 释放低概率有效动作
核心痛点
传统PPO/GRPO的裁剪范围([0.8, 1.2])会压制"低概率但有效"的动作令牌(多为非人类习惯策略),探索受限。
设计逻辑
在保证训练稳定的前提下,放宽裁剪上限,允许低概率有效动作的概率提升,为策略创新留足空间。
具体实现
将GRPO的裁剪范围从0.8, 1.2调整为0.8, 1.28:
- 下限0.8不变:限制无效动作的概率下降幅度,保证训练稳定;
- 上限提升至1.28:放宽有效低概率动作的概率提升空间,鼓励探索非传统策略。
实验效果
- 无更高裁剪:模型局限于SFT的"抓取-移动-放置"策略,LIBERO-Long成功率86.5%;
- 有更高裁剪:模型探索出"推""滑"等新动作,成功率提升至98.5%,"pushcut"现象出现概率增加30%。
策略三:更高rollout温度(Higher Rollout Temperature)------ 提升轨迹多样性
核心痛点
温度控制动作令牌采样随机性,温度=1.0时轨迹多样性不足,模型易重复SFT学到的动作,VLA动作令牌空间大(256个),低温度难以覆盖边缘令牌。
设计逻辑
通过提升采样温度,增加动作令牌随机性,让模型生成更多样化轨迹,覆盖更广泛的解空间。
具体实现
将rollout阶段的采样温度从1.0提升至1.6,温度越高,越倾向于选择低概率令牌,对应多样化的机器人控制指令。
实验效果
- 无更高温度:组内轨迹相似度达70%,unseen任务泛化率仅60%;
- 有更高温度:组内轨迹相似度降至35%,出现"推""旋转"等多样化策略,unseen任务泛化率提升至91.7%。
3.4 训练目标(Training Objective):适配VLA的GRPO算法优化
核心逻辑是基于GRPO算法,融合探索增强策略,移除KL散度正则化,形成适配VLA场景的高效策略更新目标。
算法基础:GRPO与3.3节探索增强的深度融合
- GRPO的核心适配性:无需训练价值网络,通过"组归一化优势"评估轨迹优劣,匹配"二元结果奖励",避免价值估计噪声;
关键修改:移除KL散度正则化的深层逻辑
KL散度正则化的原本作用:
限制新策略与参考模型的差异,避免政策更新幅度过大导致训练震荡。
移除的三大核心原因
- 解除探索限制:
KL正则化会强制新策略贴近参考模型(多为SFT后的策略),阻碍"pushcut"等新策略探索; - 降低训练成本:无需维护参考模型,内存消耗减少30%以上,训练速度提升25%;
- 适配结果奖励的极简性:二元奖励已提供清晰的相对优劣信号,无需双重限制。
核心公式拆解
1. 重要性采样比: r i , t ( θ ) = π θ ( a i , t ∣ s i , t ) π θ o l d ( a i , t ∣ s i , t ) r_{i, t}(\theta)=\frac{\pi_{\theta}\left(a_{i, t} | s_{i, t}\right)}{\pi_{\theta_{old }}\left(a_{i, t} | s_{i, t}\right)} ri,t(θ)=πθold(ai,t∣si,t)πθ(ai,t∣si,t)
- 定义:衡量"新策略( π θ \pi_θ πθ)"与"旧策略( π θ o l d \pi_{θ_{old}} πθold)"在"第i条轨迹的第t步动作"上的概率差异;
- 核心作用:控制政策更新的"信任度",差异过大时通过裁剪限制;
- 计算例子:"移动物体"任务中,旧策略"推"动作概率10%,新策略25%,则 r i , t = 25 % / 10 % = 2.5 r_{i,t}=25\%/10\%=2.5 ri,t=25%/10%=2.5,超过1.28裁剪上限后被裁剪为1.28。
2. 组归一化优势: A ^ i = R i − m e a n ( { R i } i = 1 G ) s t d ( { R i } i = 1 G ) \hat{A}{i}=\frac{R{i}-mean\left(\left\{R_{i}\right\}{i=1}^{G}\right)}{std\left(\left\{R{i}\right\}_{i=1}^{G}\right)} A^i=std({Ri}i=1G)Ri−mean({Ri}i=1G)
- 定义:通过组内轨迹奖励的均值和标准差,对第i条轨迹的总奖励进行归一化,得到"相对优势";
- 核心作用:替代传统RL的优势函数,评估轨迹相对优劣,无需价值网络;
- 计算例子(组内8条轨迹,奖励 R i = 1 , 1 , 0 , 1 , 0 , 0 , 1 , 0 R_i=1,1,0,1,0,0,1,0 Ri=1,1,0,1,0,0,1,0):
- 组均值 m e a n = ( 1 + 1 + 0 + 1 + 0 + 0 + 1 + 0 ) / 8 = 0.5 mean=(1+1+0+1+0+0+1+0)/8=0.5 mean=(1+1+0+1+0+0+1+0)/8=0.5;
- 组标准差 s t d = = ( 4 × ( 1 − 0.5 ) 2 + 4 × ( 0 − 0.5 ) 2 ) / 8 0.5 std=\sqrt(4×(1-0.5)\^2 + 4×(0-0.5)\^2)/8=0.5 std=(4×(1−0.5)2+4×(0−0.5)2)/8= 0.5;
- 成功轨迹优势 A ^ 1 = ( 1 − 0.5 ) / 0.5 = 1 \hat{A}_1=(1-0.5)/0.5=1 A^1=(1−0.5)/0.5=1,失败轨迹优势 A ^ 3 = ( 0 − 0.5 ) / 0.5 = − 1 \hat{A}_3=(0-0.5)/0.5=-1 A^3=(0−0.5)/0.5=−1。
3. 完整训练目标
L G R P O = E min ( r i , t A \^ i , c l i p ( r i , t , 0.8 , 1.28 ) A \^ i ) L_{GRPO} = \mathbb{E}\left \\min(r_{i,t}\\hat{A}_i, clip(r_{i,t}, 0.8, 1.28)\\hat{A}_i) \\right LGRPO=Emin(ri,tA\^i,clip(ri,t,0.8,1.28)A\^i)
- 当 A ^ i \hat{A}_i A^i为正(轨迹成功):鼓励新策略强化该动作(不超过裁剪上限);
- 当 A ^ i \hat{A}_i A^i为负(轨迹失败):抑制新策略选择该动作,引导向成功轨迹靠拢。
与框架其他模块的协同作用
- 与3.2节"结果奖励建模":二元奖励让优势计算更简单、区分度更清晰;
- 与3.3节"探索增强":动态采样确保优势有效,更高裁剪平衡探索与稳定,更高温度丰富优化信号;
- 与3.1节"交互式VLA Rollout":Rollout生成的"状态-动作对"是重要性采样比的计算基础,并行化提供大规模组数据。
四、实验设置与核心结果
4.1 实验设置
基准数据集
LIBERO:包含5个任务套件(LIBERO-Goal、LIBERO-Spatial、LIBERO-Object、LIBERO-Long、LIBERO-90),聚焦语言引导的机器人操作任务;- RoboTwin1.0:17个双臂操作任务,场景和物体多样性有限;
- RoboTwin2.0:50个任务,覆盖多种机器人形态,731个物体实例,含4个horizon层级(短/中/长/超长),12个分类任务用于评估。
骨干模型
采用OpenVLA-OFT,基于OpenVLA扩展,使用LLaMA2-7B作为骨干;- 模型输入:
单视图图像、语言指令、机器人本体感受状态(LIBERO中未使用本体感受状态); - 模型架构:
并行解码和动作chunking设计,使用LLaMA2输出头生成动作令牌,采用交叉熵损失。
实验配置
- 硬件:8×NVIDIA A800 80GB;
- 超参数:学习率 l r = 5 × 10 − 6 lr=5×10^{-6} lr=5×10−6,训练批量64,采样 count 8,mini-batch size 128,裁剪比 ε l o w = 0.2 \varepsilon_{low}=0.2 εlow=0.2、 ε h i g h = 0.28 \varepsilon_{high}=0.28 εhigh=0.28,温度 T = 1.6 T=1.6 T=1.6;
- 动作配置:
256个动作令牌,LIBERO中动作chunk数8,RoboTwin1.0&2.0中25; - 评估方式:贪心采样,每个基准测试3次确保可复现性。
基线模型
包括UniVLA、 π 0 \pi_0 π0、RDT-1B、 π f a s t \pi_{fast} πfast、Nora、OpenVLA、Octo、DP、DP3等10+先进VLA模型。
4.2 核心实验结果
LIBERO基准结果(表2)
| 模型 | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| OpenVLA-OFT | 91.6 | 95.3 | 90.6 | 86.5 | 91.0 |
| OpenVLA-OFT+SimpleVLA-RL | 99.4 | 99.1 | 99.2 | 98.5 | 99.1 |
| Δ | +7.8 | +3.8 | +8.6 | +12.0 | +8.1 |
平均成功率从91.0%提升至99.1%,LIBERO-Long任务成功率达98.5%,超越 π 0 \pi_0 π0(85.2%)和UniVLA(95.2%)等SOTA模型。
RoboTwin1.0结果(表3)
| 模型 | Hammer Beat | Block Handover | Blocks Stack | Shoe Place | Avg |
|---|---|---|---|---|---|
| OpenVLA-OFT | 67.2 | 61.6 | 7.1 | 23.4 | 39.8 |
| OpenVLA-OFT+SimpleVLA-RL | 92.6 | 89.6 | 40.2 | 59.3 | 70.4 |
| Δ | +25.4 | +28.0 | +33.1 | +35.9 | +30.6 |
- 平均成功率从39.8%提升至70.4%,4个任务均实现显著提升,Blocks Stack任务提升最为明显(+33.1%)。
RoboTwin2.0结果(表4)
| 任务层级 | 平均成功率(OpenVLA-OFT) | 平均成功率(+SimpleVLA-RL) | Δ |
|---|---|---|---|
| 短horizon(100-130步) | 21.3% | 64.9% | +43.6% |
| 中horizon(150-230步) | 47.1% | 72.5% | +25.4% |
| 长+超长horizon(280-650步) | 46.5% | 69.0% | +22.4% |
| 整体平均 | 38.3% | 68.8% | +30.5% |
- 整体平均成功率从38.3%提升至68.8%,超越 π 0 \pi_0 π0(49.2%)和RDT(33.3%),所有horizon层级任务均有提升,短horizon任务提升最为显著。
实世界实验结果(表6)
| 模型 | Stack Bowls | Place Empty Cup | Pick Bottle | Click Bell | Avg |
|---|---|---|---|---|---|
| RDT | 60.0 | 4.0 | 10.0 | 20.0 | 23.5 |
| OpenVLA-OFT | 38.0 | 2.0 | 0.0 | 30.0 | 17.5 |
| OpenVLA-OFT+SimpleVLA-RL | 70.0 | 10.0 | 14.0 | 60.0 | 38.5 |
| Δ | +32.0 | +8.0 | +14.0 | +30.0 | +21.0 |
- 仅用仿真数据训练,无需真实机器人数据,实世界平均成功率从17.5%提升至38.5%,Stack Bowls任务相对提升96%,Pick Bottle任务从0%提升至14%,验证了动作精度和实世界迁移能力。
五、核心分析:验证框架解决VLA核心挑战的能力
5.1 克服数据稀缺(Overcoming Data Scarcity)
实验设计
- 实验组(One-Trajectory SFT):每个任务仅用1条人类演示轨迹做SFT(4个LIBERO任务套件共10条轨迹);
- 对照组(Full-Trajectory SFT):每个任务用全部50条演示轨迹做SFT(4个套件共500条轨迹);
- 统一处理:两组均在SFT后用SimpleVLA-RL在500个仿真场景中训练。
关键结果(表5)
| 模型配置 | Spatial | Object | Goal | Long | 平均SR |
|---|---|---|---|---|---|
| 单轨迹SFT(无RL) | 63.6% | 54.9% | 59.6% | 17.3% | 48.9% |
| 单轨迹SFT + SimpleVLA-RL | 98.2% | 98.7% | 98.8% | 91.7% | 96.9% |
| 全轨迹SFT(无RL) | 91.6% | 95.3% | 90.6% | 86.5% | 91.0% |
| 全轨迹SFT + SimpleVLA-RL | 99.4% | 99.1% | 99.2% | 98.5% | 99.1% |
深层意义
- 数据效率突破:单轨迹SFT+RL(96.9%)超越全轨迹SFT(91.0%),仅用2%的离线数据实现更优性能;
- 长horizon任务救赎:单轨迹SFT的LIBERO-Long成功率仅17.3%,RL后提升至91.7%(+74.4%),弥补少量数据无法覆盖长流程逻辑的缺陷;
- 落地成本降低:无需采集海量人类轨迹,仅需少量演示即可启动训练,扫清数据采集障碍。
5.2 泛化分析(Generalization Analysis)
实验设计
- 测试维度:
空间泛化(物体摆放位置变更)、物体泛化(未见过的同类物体)、任务泛化(未见过的任务变体); - 训练-测试划分:每个任务套件选9个任务做"seen任务"(训练集),1个任务做"unseen任务"(测试集);
- 基线对比:两组均以"单轨迹SFT"为基础模型,一组继续SFT微调,另一组用SimpleVLA-RL训练。
关键结果
- SFT的泛化灾难:seen任务成功率提升至90%+时,unseen任务出现灾难性遗忘(成功率降至0%);
- RL的泛化优势:seen任务成功率达90%+的同时,unseen任务成功率持续提升:
- 任务泛化:3个unseen任务均提升5%-15%;
- 物体泛化:3个unseen任务全量提升,最高+36.5%;
- 空间泛化:3个unseen任务均提升,最高从43.3%→71.8%。
5.3 实世界实验(Real-World Experiments)
实验设计
- 任务选择:Stack Bowls、Place Empty Cup、Pick Bottle、Click Bell(覆盖抓取、堆叠、交互);
- 训练数据:全程仅用仿真数据(1000条SFT轨迹+1000个RL仿真场景),无任何真实机器人数据;
- 硬件与环境:
实世界使用2台AgileX Piper机械臂,测试环境为"干净桌面+未见过的背景"。
关键结果
- sim-to-real无监督突破:仅用仿真数据,RL后平均成功率从17.5%提升至38.5%(+21.0%),超越RDT(23.5%);
- 动作精度提升:Pick Bottle(高精度任务)的SFT版本成功率为0%,RL后达14.0%;
- 落地路径验证:提供"仿真大规模RL训练→实世界直接部署"的低成本路径,无需真实数据校准。
六、模型效果
下面是Pi0.6*与SimpleVLA-RL对比:

SimpleVLA-RL比较流畅的折叠纸箱:

SimpleVLA-RL完成了折叠纸箱的任务:

分享完成~