直观上看,神经网络越深,其表达能力就越强。然而实践中发现,当网络深度增加到一定程度后,模型效果反而会明显下降。这种下降不仅体现在测试集上,在训练集上同样存在,这说明问题并非由过拟合引起,而是网络本身难以被有效优化。
这被称为深层网络的退化问题。随着网络不断加深,误差信息在反向传播过程中难以有效传递,参数更新受阻。在这一背景下,ResNet 提出了一种新的网络结构,使深层网络的训练变得更加容易,在当年的ILSVRC 2015竞赛中获得冠军
1. Residual block
残差块的思想是,不让网络只沿着逐层变换的单一路径传播,而是额外提供一条直通路径 。输入特征x一方面经过若干卷积、归一化和激活函数,形成一个非线性变换 F(x);另一方面,输入通过一条 shortcut 连接直接保留下来。在输出端,这两个高宽和通道数均一样的特征图逐元素相加融合,相加之后再经过激活函数,得到最终输出。
梯度在反向传播时可以绕过中间的非线性变换,直接传回到更浅的层。保留一条直接通路,从而避免深层网络中梯度逐层衰减的问题。
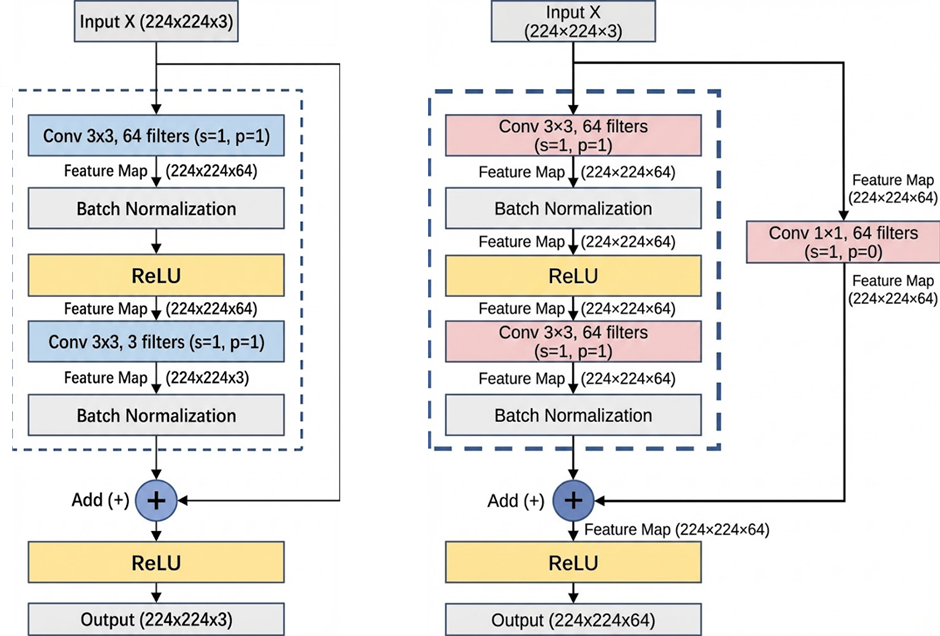
对一般的残差块,如左图
卷积层1:输入224 × 224 × 3,卷积核3 × 3 × 3× 64,步幅为 1,填充为 1,输出224 × 224 × 64,经过BN、ReLu后尺寸和通道数保持不变,仍为 224 × 224 × 64
卷积层2:输入224 × 224 × 64,卷积核3 × 3 × 64× 3,步幅为 1,填充为 1,输出224 × 224 × 3
与初始输入224 × 224 × 3逐元素相加,最终经过ReLu层输出
如果想改变通道数,需要引入一个1×1卷积层,如右图,最终输出大小224 × 224 × 64
2. Batch Normalization
Batch Normalization是对每一批数据进行归一化的操作。在每一批次数据内,对输入进行标准化处理,使其均值接近零、方差接近一,然后再通过可学习的缩放k和偏移b参数恢复网络的表达能力。
标准化:
缩放与偏移:
BN可以在网络中任意一层进行归一化处理。
3. ResNet网络结构及代码
HaoYuanxinn/ResNet_FashionMNIST: 用 PyTorch 复现 ResNet,使用FashionMNIST 数据集
网络结构如下图所示:
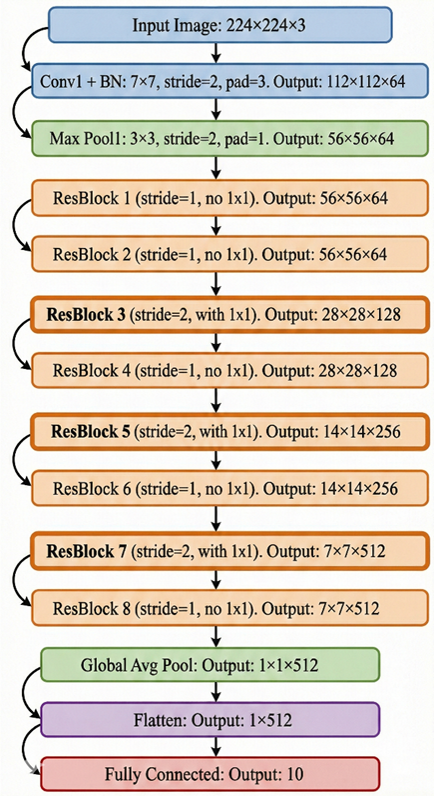
卷积层1:输入224×224×3,卷积核7×7×3×64;stride=2,padding=3。输出112×112×64。 进入BN层
最大池化1:输入112×112×64, 池化核3×3,stride=2 ,padding=1,输出56×56×64
通过一个sequence实现:
self.b1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))残差块
不同类型的 ResNet 残差块在结构上是一致的,差异仅体现在通道数、步幅以及是否引入 1×1 卷积进行维度匹配。因此,可以通过参数化的方式将不同残差块统一封装为一个 Residual 模块
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1conv=False, strides=1):
super(Residual, self).__init__()
self.ReLU = nn.ReLU()
self.conv1 = nn.Conv2d(in_channels=input_channels, out_channels=num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(in_channels=num_channels, out_channels=num_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
if use_1conv:
self.conv3 = nn.Conv2d(in_channels=input_channels, out_channels=num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
def forward(self, x):
y = self.ReLU(self.bn1(self.conv1(x)))
y = self.bn2(self.conv2(y))
if self.conv3:
x = self.conv3(x)
y = self.ReLU(y+x)
return y残差块1:输入为56×56×64,stride=1,输出56×56×64,无1×1 卷积
残差块2:输入为56×56×64,stride=1,输出56×56×64,无1×1 卷积
残差块3:输入为56×56×64,stride=2,输出28×28×128,有1×1 卷积
残差块4:输入为28×28×128,stride=1,输出28×28×128,无1×1 卷积
残差块5:输入为28×28×128,stride=2,输出14×14×256,有1×1 卷积
残差块6:输入为14×14×256,stride=1,输出14×14×256,无1×1 卷积
残差块7:输入为14×14×256,stride=2,输出7×7×512,有1×1 卷积
残差块8:输入为7×7×512,stride=1,输出7×7×512,无1×1 卷积
全局平均池化:输入为7×7×512。 输出1×1×512
Flatten 层:输入1×1×512, 输出1×512
线性全连接层:输入1×512。 神经元个数10。
在ResNet中逐层依次写出:
import torch
from torch import nn
from torchsummary import summary
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1conv=False, strides=1):
super(Residual, self).__init__()
self.ReLU = nn.ReLU()
self.conv1 = nn.Conv2d(in_channels=input_channels, out_channels=num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(in_channels=num_channels, out_channels=num_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
if use_1conv:
self.conv3 = nn.Conv2d(in_channels=input_channels, out_channels=num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
def forward(self, x):
y = self.ReLU(self.bn1(self.conv1(x)))
y = self.bn2(self.conv2(y))
if self.conv3:
x = self.conv3(x)
y = self.ReLU(y+x)
return y
class ResNet18(nn.Module):
def __init__(self, Residual):
super(ResNet18, self).__init__()
self.b1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b2 = nn.Sequential(Residual(64, 64, use_1conv=False, strides=1),
Residual(64, 64, use_1conv=False, strides=1))
self.b3 = nn.Sequential(Residual(64, 128, use_1conv=True, strides=2),
Residual(128, 128, use_1conv=False, strides=1))
self.b4 = nn.Sequential(Residual(128, 256, use_1conv=True, strides=2),
Residual(256, 256, use_1conv=False, strides=1))
self.b5 = nn.Sequential(Residual(256, 512, use_1conv=True, strides=2),
Residual(512, 512, use_1conv=False, strides=1))
self.b6 = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 10))
def forward(self, x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
x = self.b6(x)
return x
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNet18(Residual).to(device)
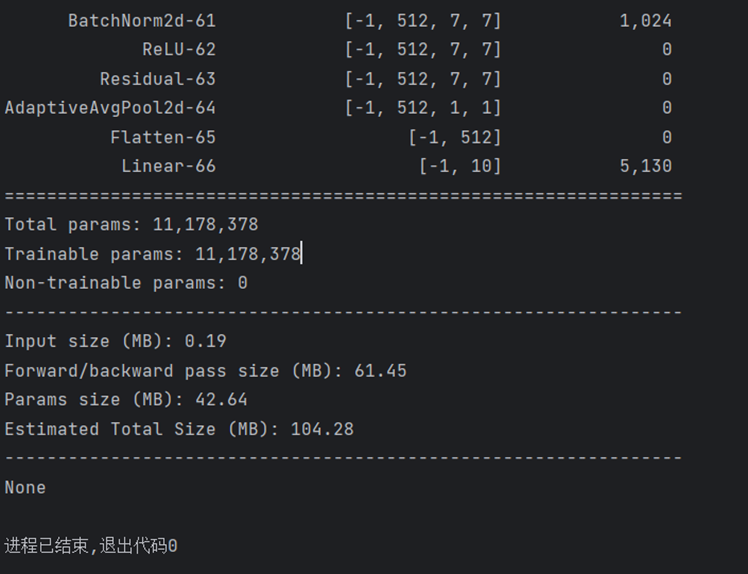
print(summary(model, (1, 224, 224)))运行