精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、选题背景意义
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
本系统是一套围绕道路交通事故数据展开的深度分析平台,核心技术栈采用Hadoop生态体系完成海量数据的存储与计算,上层借助Spark进行高效的数据处理与挖掘,最终通过可视化技术将分析结果直观呈现。系统并非简单的数据展示工具,而是从时间规律、司机画像、环境因素、事故严重程度、车辆状况以及事故成因这六个相互关联的维度切入,构建了一套完整的分析闭环。比如你能看到一周之内哪天最容易出事、一天当中哪个时段是事故高峰,也能深挖不同年龄段的司机各自容易因为什么而出事故,甚至能分析出下雨天路面湿滑时哪类碰撞最为致命。所有分析都基于真实的事故数据集,经过数据清洗、特征提取、聚合计算等一系列处理后,最终以动态图表、热力图、趋势曲线等形式输出,让原本枯燥的数字变成一眼就能看懂的决策依据。整个系统的价值在于用大数据的思维和方法,把零散的事故记录转化为有规律的洞察,为交通管理和安全防控提供数据支撑,同时也充分展现了从原始数据到价值信息的完整处理链路。
二、选题背景意义
这几年道路上的车越来越多,交通事故也随之成为大家日常关注的社会问题。不管是上下班通勤还是长途出行,交通安全始终牵动着每个普通人的神经。现实中交通管理部门手里其实积累了大量的事故记录,包括出事的时间地点、天气怎么样、司机什么状况、车子有没有问题等等,但这些数据往往躺在数据库里没发挥太大作用。传统的人工统计方式效率低不说,也很难从这么多维度里找出规律。与此同时,大数据技术这几年在各行各业都开始落地,用Hadoop、Spark这类工具处理海量数据已经不是什么新鲜事,成本也比以前低了很多。所以怎么把交通事故数据用大数据技术盘活起来,从中挖掘出有价值的信息,成了一个既接地气又有技术含量的方向。这正是本课题想要探索和解决的现实问题。
做这个系统的实际意义可以从几个方面来看。对交通管理部门来说,系统能帮他们从堆积如山的事故记录里快速定位问题,比如哪个路口老出事、什么天气最危险,这样安排警力和改善设施就更有针对性,不用再凭经验拍脑袋。对司机群体来说,通过分析不同年龄、驾龄人群的事故规律,可以做出更贴近实际的安全提醒和培训内容,比笼统地说"注意安全"管用得多。从技术学习的角度来说,整套系统覆盖了数据采集、清洗、存储、计算、可视化这一完整链条,对于想掌握大数据开发流程的学生是个不错的练手项目,能把课本上的HDFS、MapReduce、Spark这些概念真正跑起来。当然,这只是一个毕业设计,规模和深度都有限,做不到实时接入全城数据,分析模型也比较基础,主要目的是把技术栈串起来、把业务流程跑通,为以后更复杂的企业级应用打个底。即便如此,完成这样一个从0到1的系统,对理解大数据项目的开发逻辑还是很有帮助的。
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
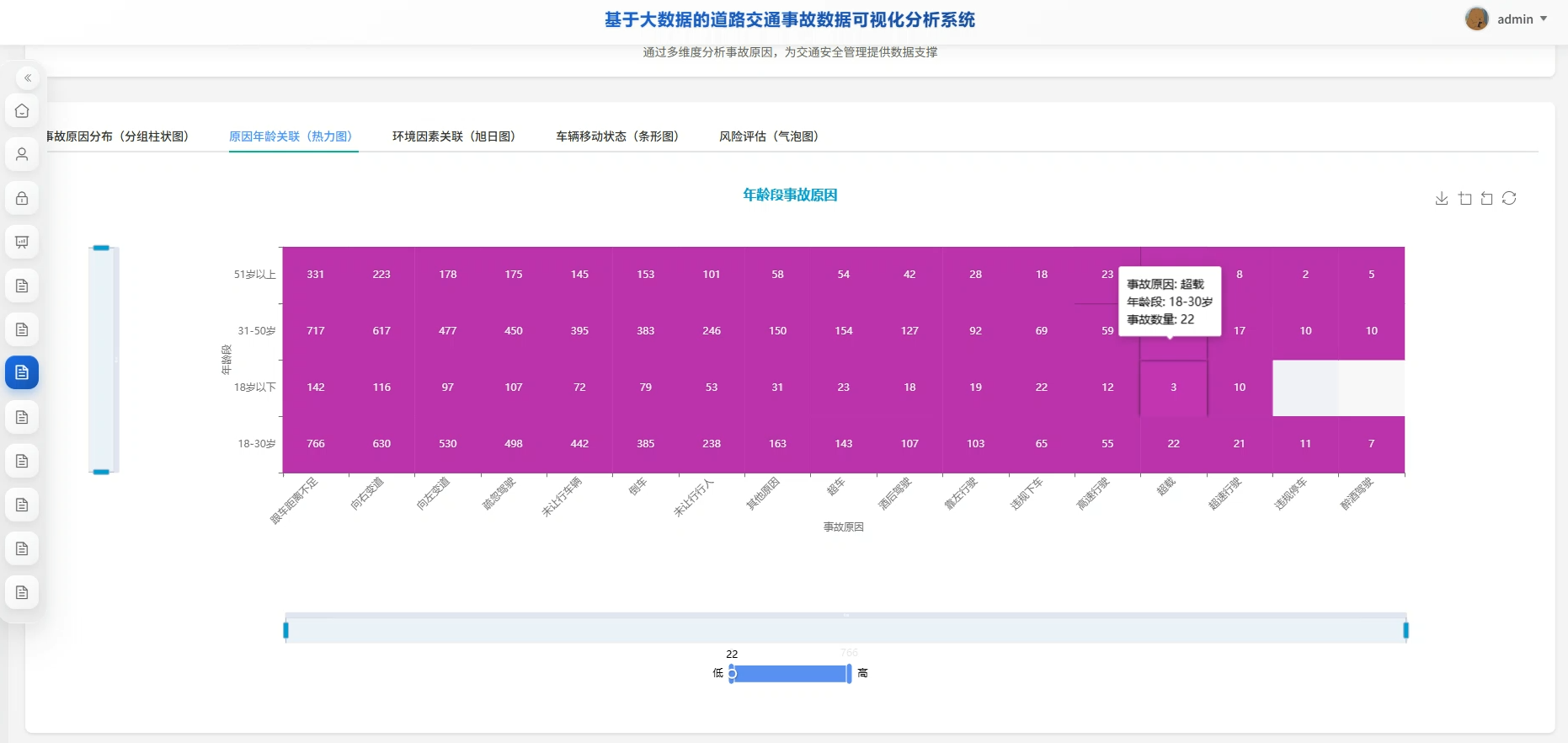
四、系统展示
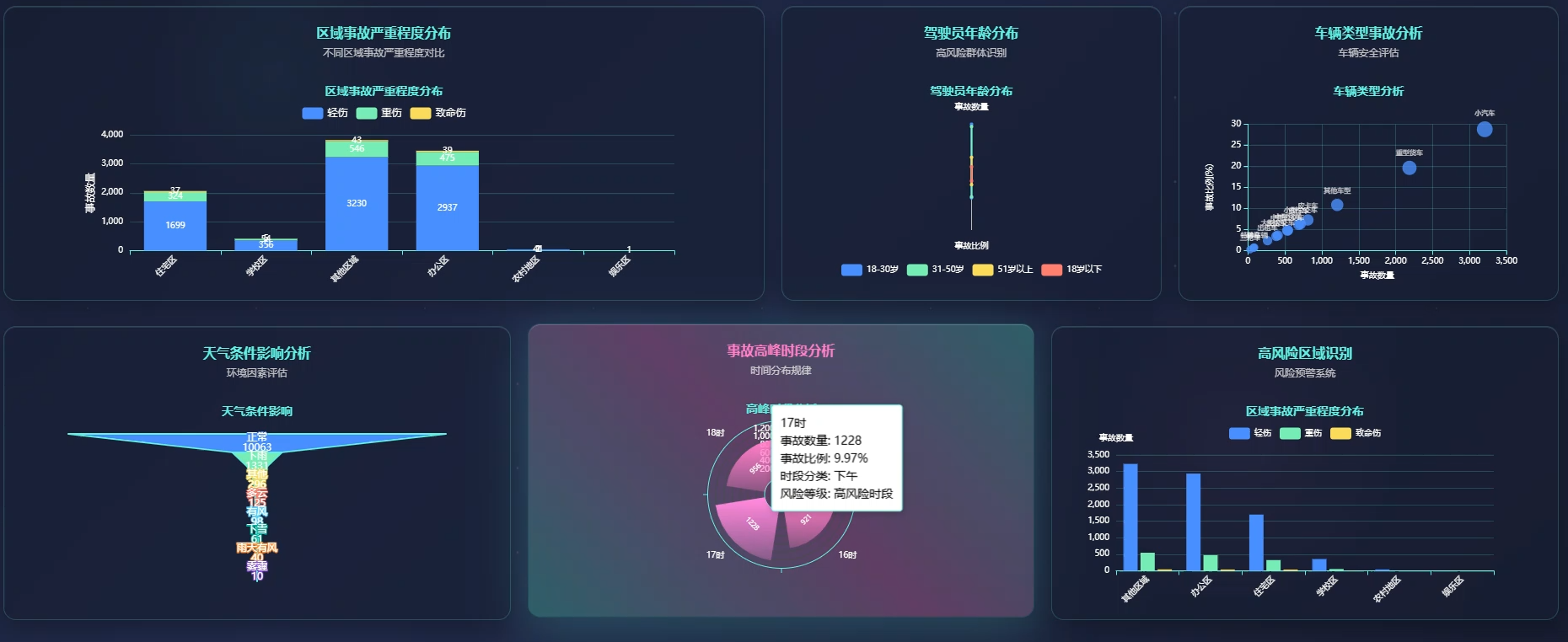
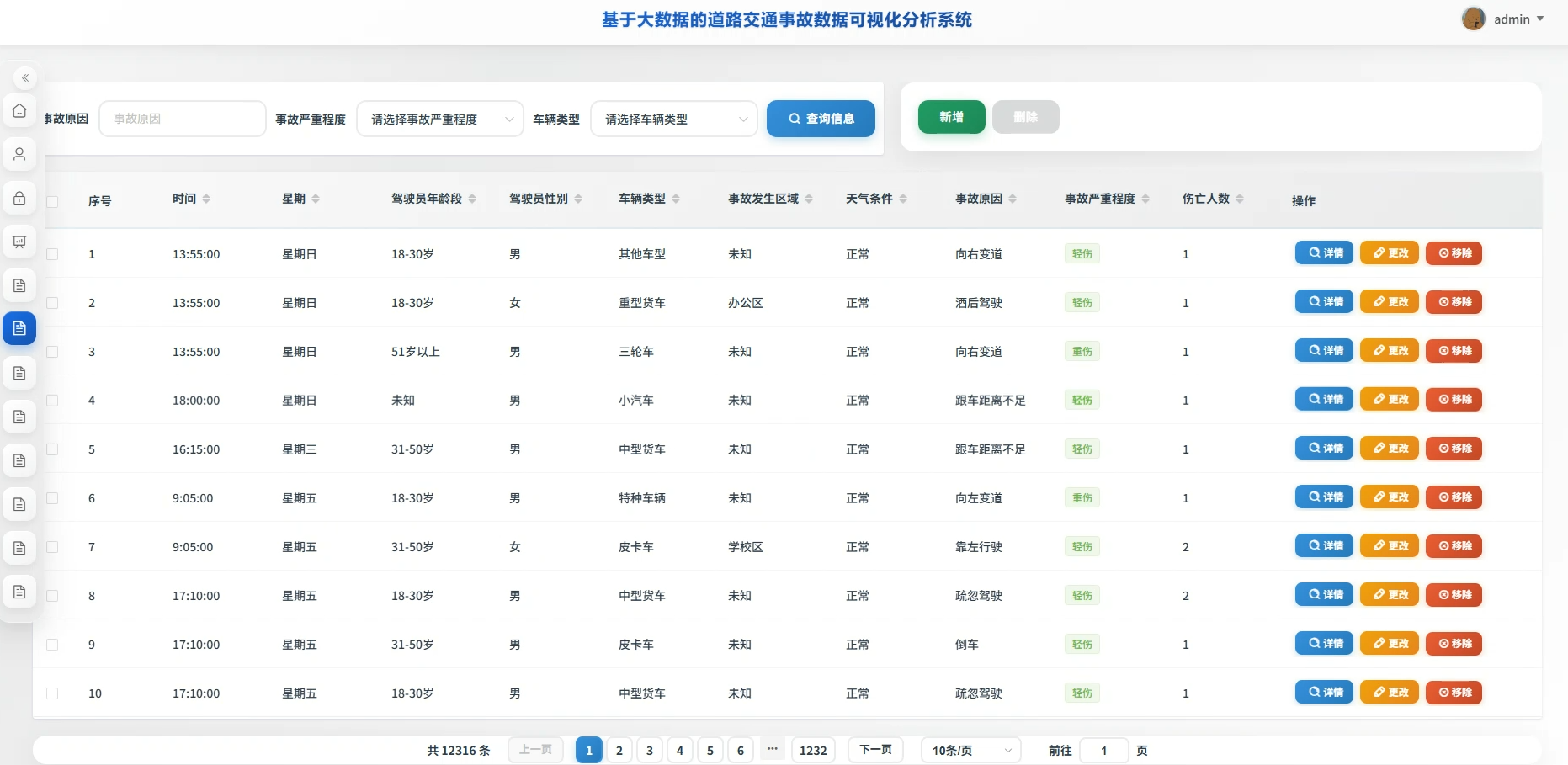
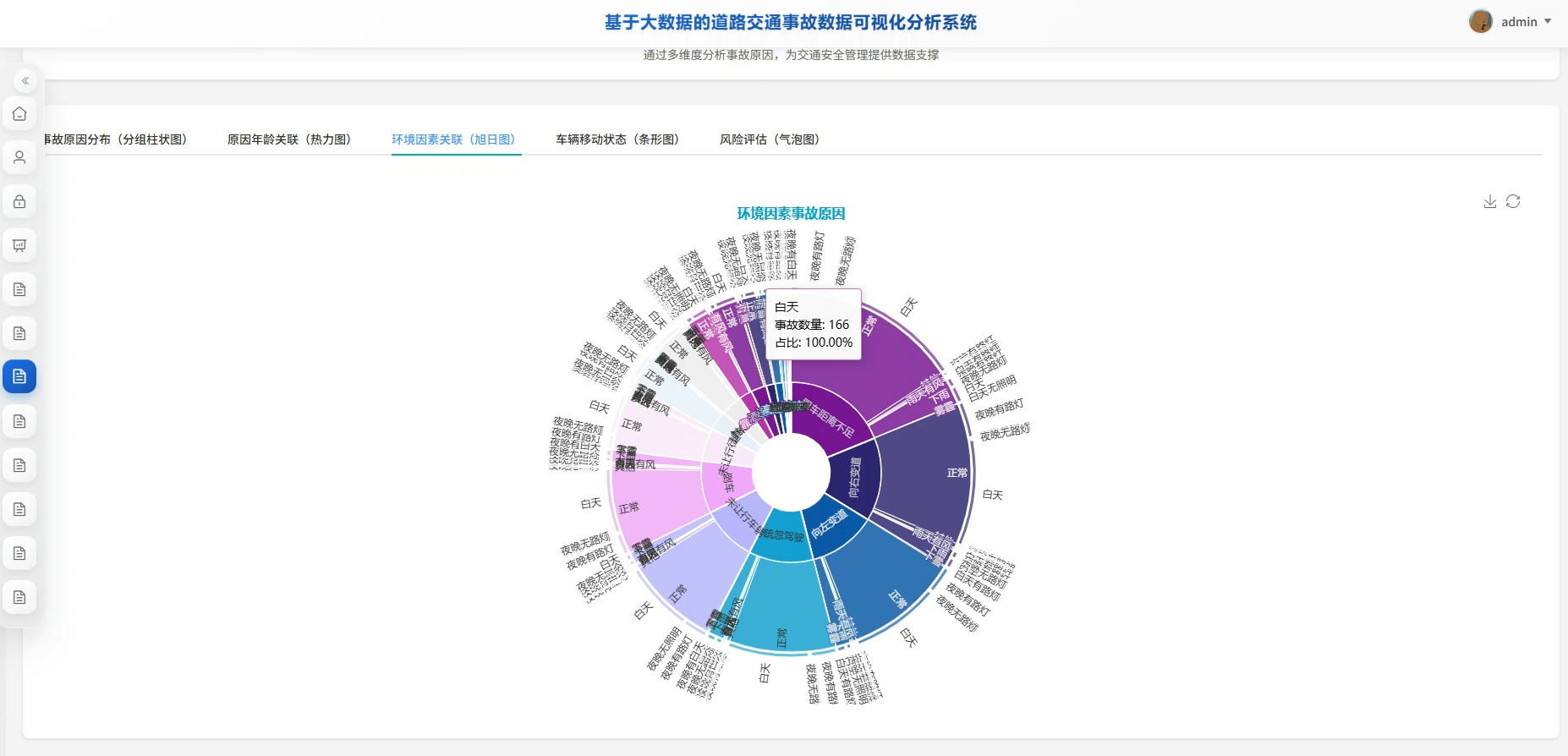
系统页面模块展示:
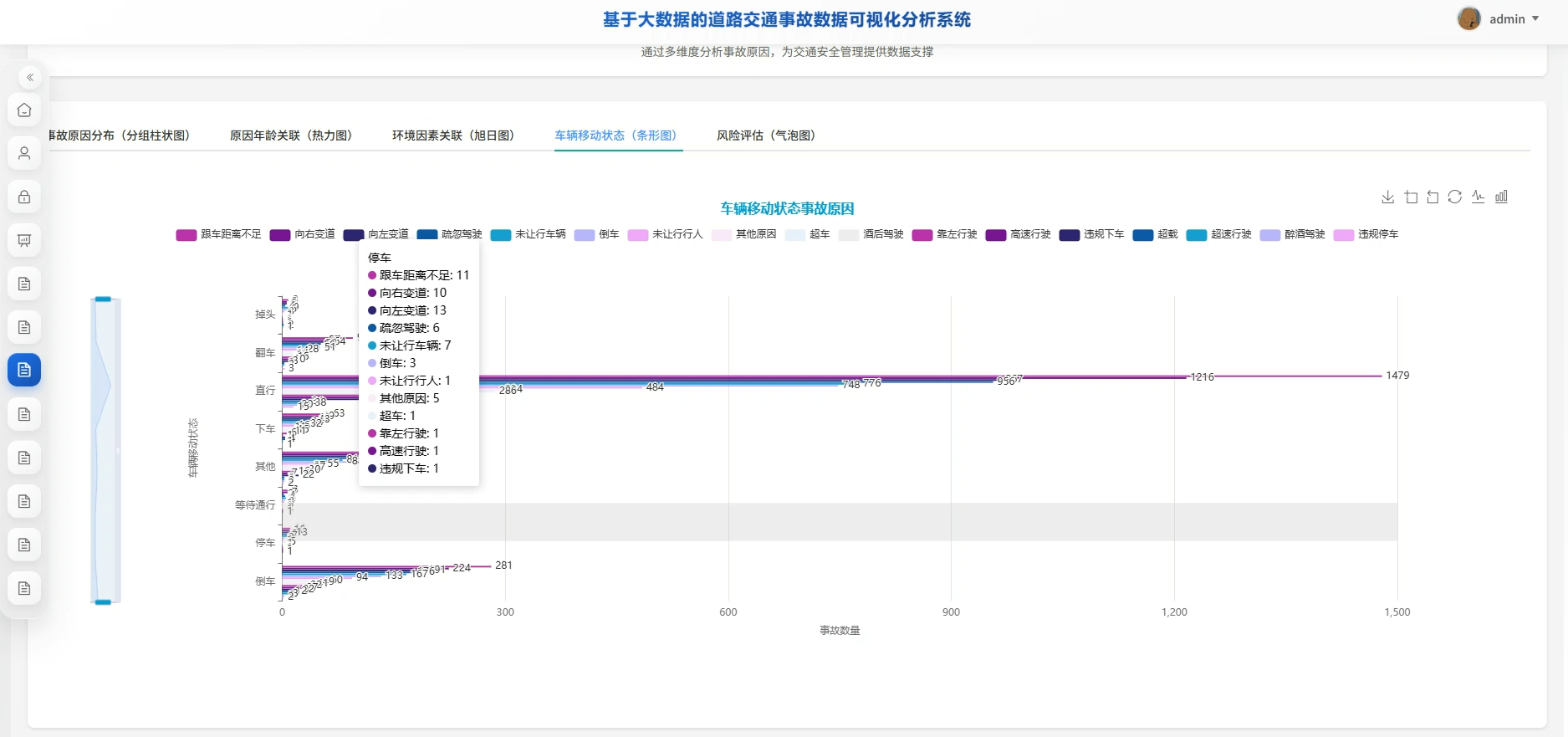
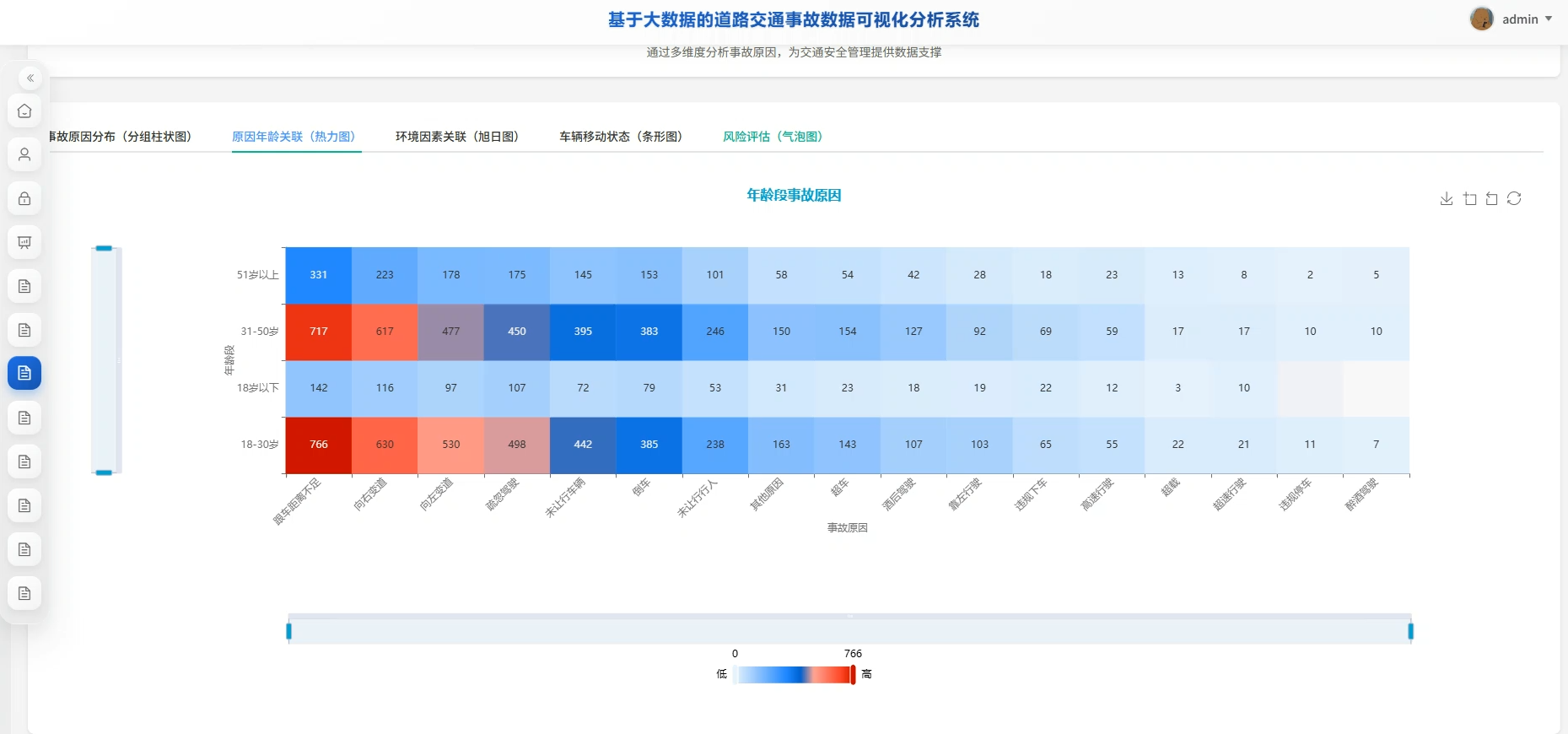
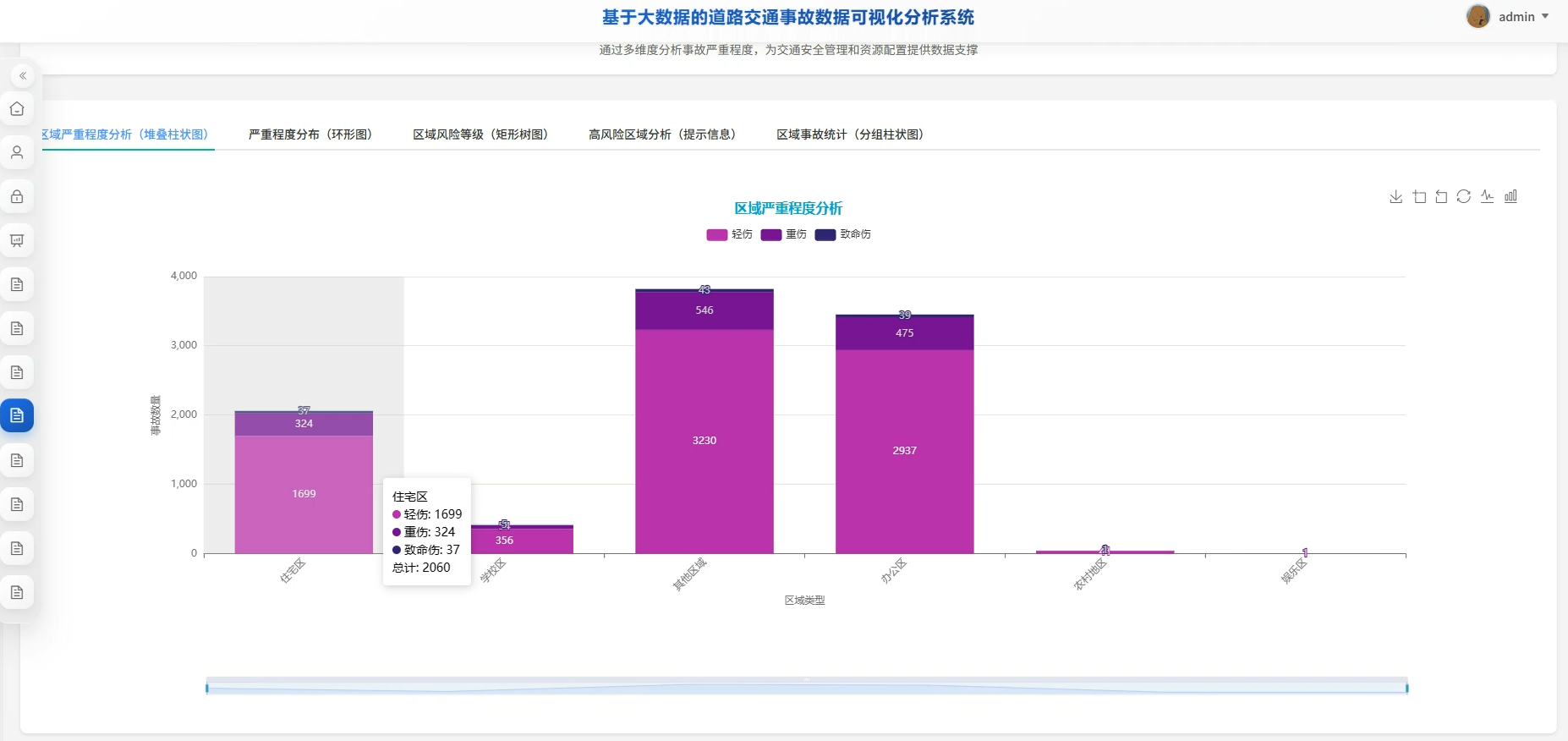
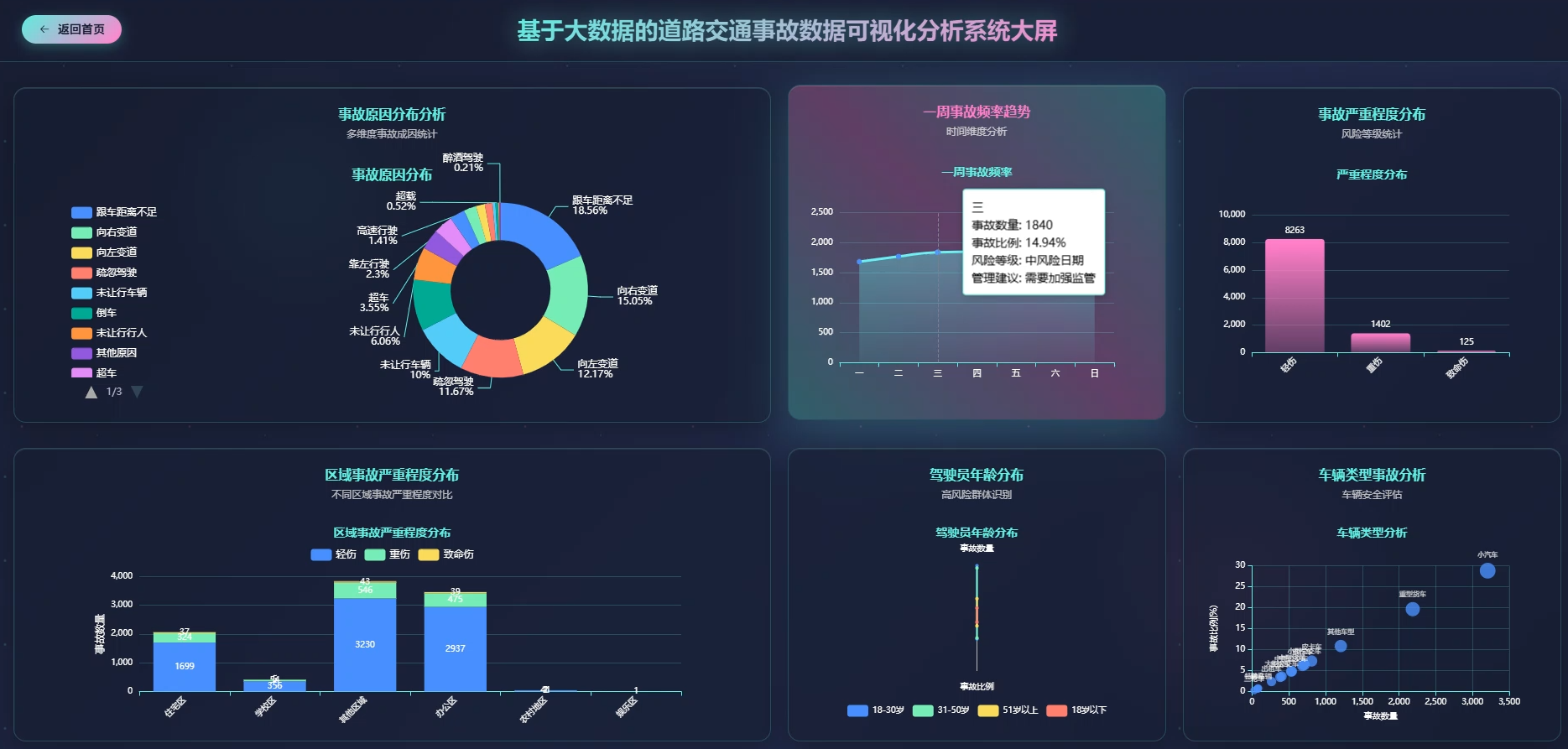
五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, when, avg, hour, dayofweek, substring
spark = SparkSession.builder.appName("TrafficAccidentAnalysis").master("local[*]").config("spark.sql.warehouse.dir", "/tmp/spark-warehouse").getOrCreate()
df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/user/hadoop/accident_data.csv")
df_clean = df.filter(col("Time").isNotNull() & col("Accident_severity").isNotNull())
df_time = df_clean.withColumn("hour_of_day", hour(substring(col("Time"), 1, 5)))
hourly_accident = df_time.groupBy("hour_of_day").agg(count("*").alias("accident_count")).orderBy("hour_of_day")
hourly_accident.write.mode("overwrite").csv("hdfs://localhost:9000/output/hourly_analysis")
df_age = df_clean.filter(col("Age_band_of_driver").isNotNull())
age_accident = df_age.groupBy("Age_band_of_driver").agg(count("*").alias("accident_count"), avg(when(col("Accident_severity") == "Fatal", 1).otherwise(0)).alias("fatal_rate"))
age_cause = df_age.filter(col("Cause_of_accident").isNotNull()).groupBy("Age_band_of_driver", "Cause_of_accident").agg(count("*").alias("cause_count"))
age_accident.write.mode("overwrite").csv("hdfs://localhost:9000/output/age_analysis")
age_cause.write.mode("overwrite").csv("hdfs://localhost:9000/output/age_cause_analysis")
df_weather = df_clean.filter(col("Weather_conditions").isNotNull() & col("Accident_severity").isNotNull())
weather_severity = df_weather.groupBy("Weather_conditions").agg(count("*").alias("total_accidents"), avg(when(col("Accident_severity") == "Serious Injury", 3).when(col("Accident_severity") == "Slight Injury", 2).when(col("Accident_severity") == "Fatal", 4).otherwise(1)).alias("avg_severity_score"), count(when(col("Accident_severity") == "Fatal", 1)).alias("fatal_count"))
weather_collision = df_weather.filter(col("Type_of_collision").isNotNull()).groupBy("Weather_conditions", "Type_of_collision").agg(count("*").alias("collision_count"))
weather_severity.write.mode("overwrite").csv("hdfs://localhost:9000/output/weather_severity_analysis")
weather_collision.write.mode("overwrite").csv("hdfs://localhost:9000/output/weather_collision_analysis")六、项目文档展示

七、项目总结
回顾整个项目的开发过程,从最初确定用大数据技术做交通事故分析这个方向,到最后把六个维度的分析功能全部跑通,中间踩了不少坑也学到了不少东西。最开始的难点在于数据,找到一份字段完整、质量过关的事故数据集并不容易,后来只能基于开源数据做清洗和规整,这个过程让我深刻体会到实际项目中数据预处理往往比算法本身更耗时间。技术选型上定了Hadoop+Spark的路线,存储用HDFS,计算用Spark SQL和DataFrame API,既保证了能处理一定规模的数据,又不用写太复杂的MapReduce代码,对毕业设计来说是个比较务实的选择。六个分析维度里头,时间维度和司机特征维度相对直观,环境因素和事故原因的关联分析更有挑战,需要多表 join 和复杂的聚合逻辑。可视化部分虽然没有用特别花哨的前端框架,但把Spark计算好的结果导出来用图表展示,也算是完成了从数据到洞察的闭环。整个系统谈不上多创新,技术深度也有限,但好歹把大数据处理的完整流程走了一遍,从数据接入、清洗转换、分析计算到结果输出,每个环节都亲自动手实现了。这对于理解企业级大数据项目的开发模式很有帮助,也为以后深入学习实时计算、机器学习这些进阶内容打了个基础。总的来说,这个项目算是达到了毕业设计的预期目标,既解决了实际问题,也锻炼了技术能力。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖