欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
LangChain4j实战全系列链接
- 准备工作
- 极速开发体验
- 细说聊天API
- 集成到spring-boot
- 图像模型
- 聊天记忆,低级API版
- 聊天记忆,高级API版
- 响应流式传输
- 高级API(AI Services)实例的创建方式
- 结构化输出之一,用提示词指定输出格式
- 结构化输出之二,function call
- 结构化输出之三,json模式
- 函数调用,低级API版本
- 函数调用,低级API版本
- RAG (检索增强生成),Easy RAG
- RAG (检索增强生成),Naive RAG
本篇概览
- 本文是RAG系列的第二篇,前文体验了LangChain4j提供的最简版本RAG,知道了RAG的作用,但由于Easy RAG强调的是简洁,所以当时未能了解RAG细节
- 所以今天继续深入学习RAG,目标是Naive RAG,即通过LangChain4j提供的API来实现RAG索引功能
- 具体要写什么代码才能实现RAG索引呢?为了便于理解,这里整理出详细的时序图
无 EasyRAG 的"一键魔法",全程手动:加载 → 解析 → 切分 → 嵌入 → 存库。
控制台 EmbeddingStore (InMemory/Qdrant) EmbeddingStoreIngestor EmbeddingModel (AllMiniLm) DocumentSplitter (Recursive) DocumentParser (ApacheTika) FileSystemDocumentLoader 应用启动代码 控制台 EmbeddingStore (InMemory/Qdrant) EmbeddingStoreIngestor EmbeddingModel (AllMiniLm) DocumentSplitter (Recursive) DocumentParser (ApacheTika) FileSystemDocumentLoader 应用启动代码 loop 每个文件 loop 每批 segment 1. 手动创建各组件 1 2. loadDocuments(path, parser) 2 3. 解析为Document 3 4. 返回Document 4 5. List<Document> 5 6. splitAll(documents) 6 7. List<TextSegment> 7 8. ingest(segments) 8 9. 生成Embedding 9 10. List<Embedding> 10 11. 写入(segment, embedding) 11 12. 打印进度 12 13. 索引完成 13
- 由上可见,Naive RAG的重点是索引,至于检索并没有什么要关注的地方,依旧是高级API的调用
- 好了,开始编码吧,注意重点是配置类中的索引部分,另外本次实战所用数据与前文相同,依旧是基于维基百科大幅度删减的文本文件,内容如下图

源码下载(觉得作者啰嗦的,直接在这里下载)
- 如果您只想快速浏览完整源码,可以在GitHub下载代码直接运行,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
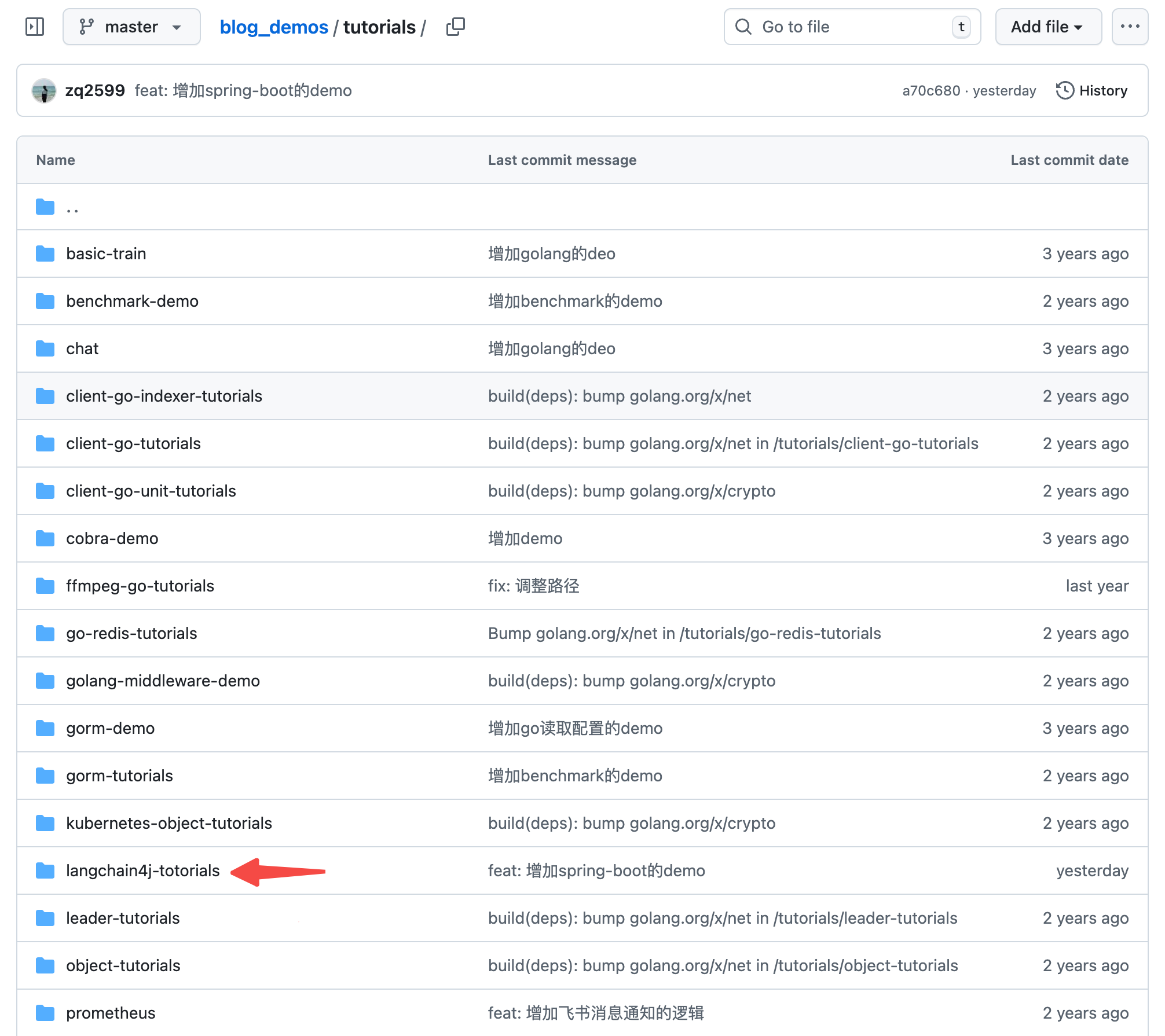
- 这个git项目中有多个文件夹,本篇的源码在langchain4j-tutorials文件夹下,如下图红色箭头所示:
编码:父工程调整
- 《准备工作》中创建了整个《LangChain4j实战》系列代码的父工程,本篇实战会在父工程下新建一个子工程,所以这里要对父工程的pom.xml做少量修改
-
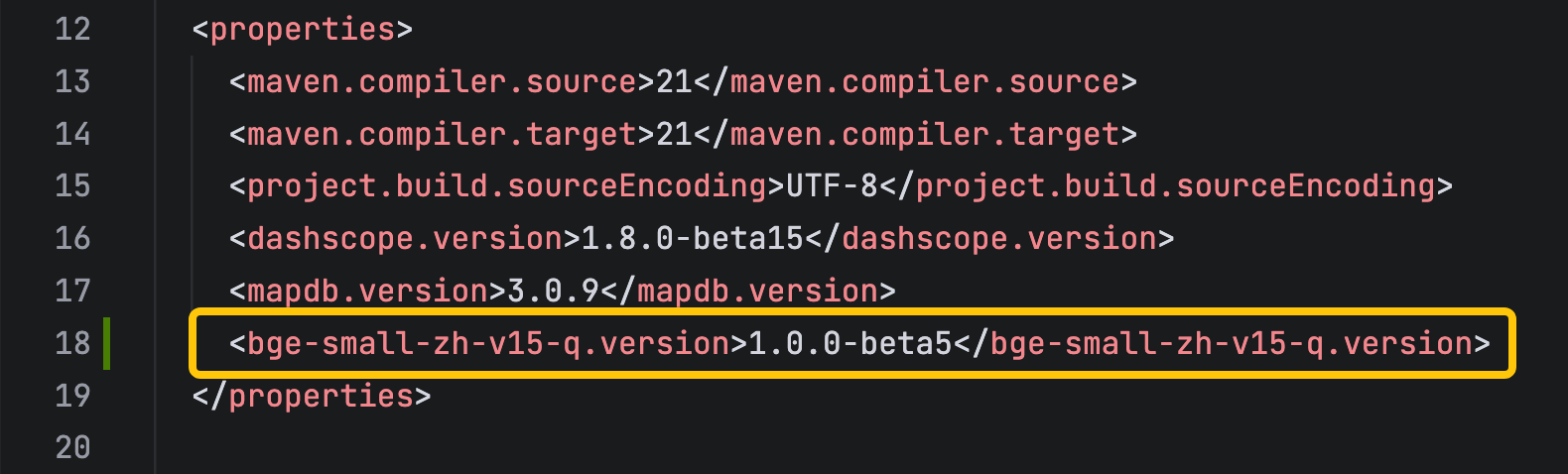
增加一个参数定义,这是后面文本转向量时要用到的模型版本
-
增加上述模型库的依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-bge-small-zh-v15-q</artifactId>
<version>${bge-small-zh-v15-q.version}</version>
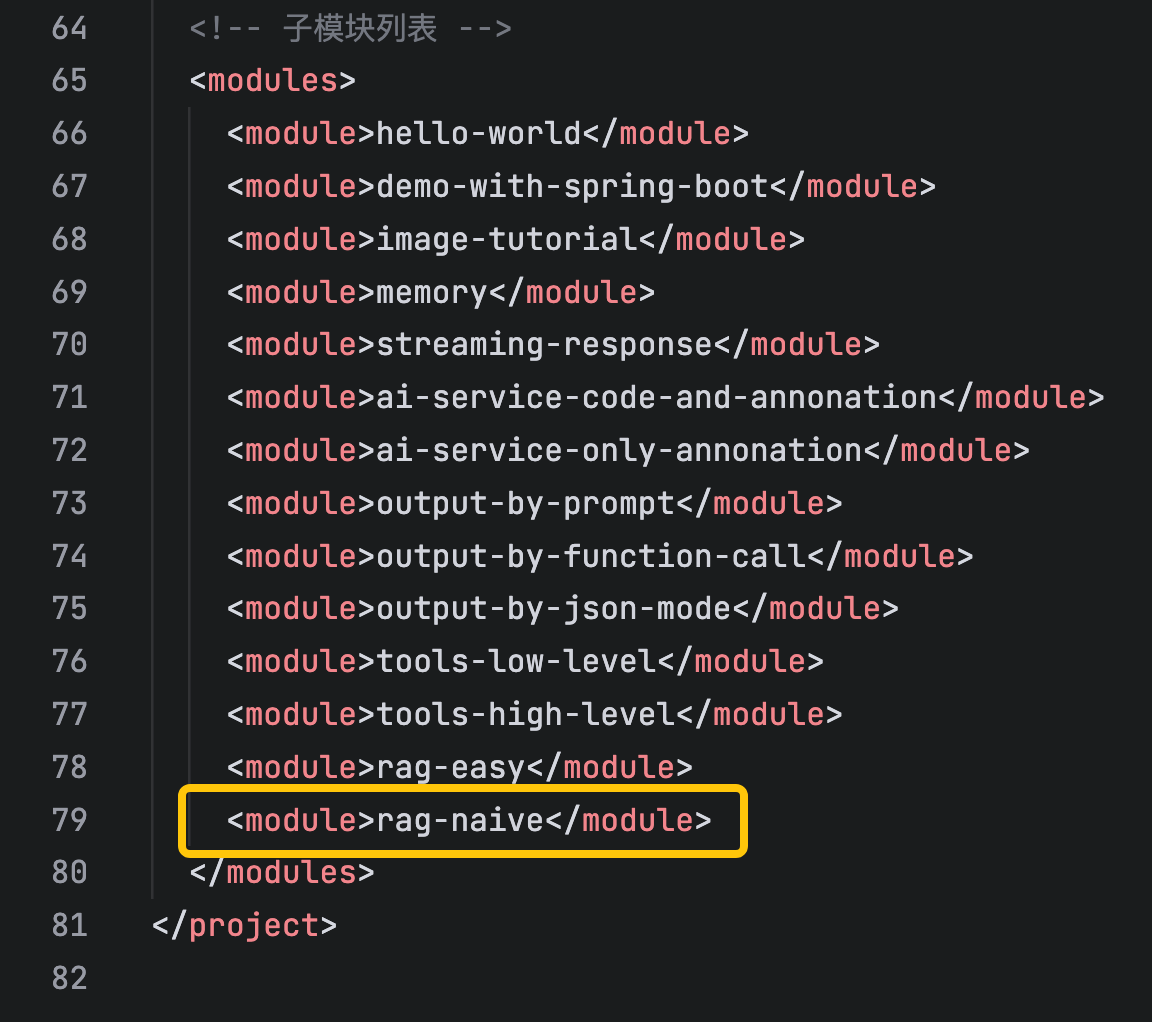
</dependency>- modules中增加一个子工程,如下图黄框所示
编码:新增子工程
- 新增名为rag-naive的子工程
- langchain4j-totorials目录下新增名为rag-naive的文件夹
- rag-naive文件夹下新增pom.xml,内容如下
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.bolingcavalry</groupId>
<artifactId>langchain4j-totorials</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<!-- 配置编译编码 -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.encoding>UTF-8</maven.compiler.encoding>
</properties>
<artifactId>rag-naive</artifactId>
<packaging>jar</packaging>
<dependencies>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot Test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- JUnit Jupiter Engine -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<scope>test</scope>
</dependency>
<!-- Mockito Core -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<scope>test</scope>
</dependency>
<!-- Mockito JUnit Jupiter -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-junit-jupiter</artifactId>
<scope>test</scope>
</dependency>
<!-- LangChain4j Core -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-core</artifactId>
</dependency>
<!-- LangChain4j OpenAI支持(用于通义千问的OpenAI兼容接口) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<!-- 官方 langchain4j(包含 AiServices 等服务类) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-bge-small-zh-v15-q</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Spring Boot Maven Plugin -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>3.3.5</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
<configuration>
<jvmArguments>-Dfile.encoding=UTF-8 -Dsun.stdout.encoding=UTF-8 -Dsun.stderr.encoding=UTF-8</jvmArguments>
</configuration>
</plugin>
<!-- Maven Resources Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<configuration>
<encoding>UTF-8</encoding>
<propertiesEncoding>UTF-8</propertiesEncoding>
</configuration>
</plugin>
<!-- Maven Compiler Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.13.0</version>
<configuration>
<source>21</source>
<target>21</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
<!-- 确保资源文件使用UTF-8编码 -->
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>
</project>- 在langchain4j-totorials/rag-naive/src/main/resources新增配置文件application.properties,内容如下,主要是三个模型的配置信息,记得把your-api-key换成您自己的apikey,rag.file.path是存放本地文档的目录(就是前面维基百科那个文件)
properties
# Spring Boot 应用配置
server.port=8080
server.servlet.context-path=/
# LangChain4j 使用OpenAI兼容模式配置通义千问模型
# 注意:请将your-api-key替换为您实际的通义千问API密钥
langchain4j.open-ai.chat-model.api-key=your-api-key
# 通义千问模型名称
langchain4j.open-ai.chat-model.model-name=qwen3-max
# 阿里云百炼OpenAI兼容接口地址
langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
# 日志配置
logging.level.root=INFO
logging.level.com.bolingcavalry=DEBUG
logging.pattern.console=%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
# 日志编码配置,解决中文乱码问题
logging.charset.console=UTF-8
logging.charset.file=UTF-8
# 应用名称
spring.application.name=rag-naive
# rag文件路径
rag.file.path=/home/will/temp/202601/15/zhwiki_txt- 新增启动类,依旧平平无奇
java
package com.bolingcavalry;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* Spring Boot应用程序的主类
*/
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}- 由于本篇是高级API,所以增加一个自定义接口用于对话
java
package com.bolingcavalry.service;
public interface Assistant {
/**
* 通过提示词range大模型返回JSON格式的内容
*
* @param userMessage 用户消息
* @return 助手生成的回答
*/
String byRagNaive(String userMessage);
}- 接着是本篇的重点代码:配置类,有几处重点稍后会说明
java
package com.bolingcavalry.config;
import java.util.ArrayList;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.bolingcavalry.service.Assistant;
import dev.langchain4j.agent.tool.ToolExecutionRequest;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.listener.ChatModelErrorContext;
import dev.langchain4j.model.chat.listener.ChatModelListener;
import dev.langchain4j.model.chat.listener.ChatModelRequestContext;
import dev.langchain4j.model.chat.listener.ChatModelResponseContext;
import dev.langchain4j.model.chat.response.ChatResponse;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.embedding.onnx.bgesmallenv15q.BgeSmallEnV15QuantizedEmbeddingModel;
import dev.langchain4j.model.embedding.onnx.bgesmallzhv15q.BgeSmallZhV15QuantizedEmbeddingModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
@Configuration
public class LangChain4jConfig {
private static final Logger logger = LoggerFactory.getLogger(LangChain4jConfig.class);
@Value("${langchain4j.open-ai.chat-model.api-key}")
private String apiKey;
@Value("${langchain4j.open-ai.chat-model.model-name:qwen-turbo}")
private String modelName;
@Value("${langchain4j.open-ai.chat-model.base-url}")
private String baseUrl;
@Value("${rag.file.path}")
private String ragFilePath;
@Bean
public OpenAiChatModel chatModel() {
ChatModelListener listener = new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext reqCtx) {
// 1. 拿到 List<ChatMessage>
List<ChatMessage> messages = reqCtx.chatRequest().messages();
logger.info("发到LLM的请求: {}", messages);
}
@Override
public void onResponse(ChatModelResponseContext respCtx) {
// 2. 先取 ChatModelResponse
ChatResponse response = respCtx.chatResponse();
// 3. 再取 AiMessage
AiMessage aiMessage = response.aiMessage();
// 4. 工具调用
List<ToolExecutionRequest> tools = aiMessage.toolExecutionRequests();
for (ToolExecutionRequest t : tools) {
logger.info("LLM响应, 执行函数[{}], 函数入参 : {}", t.name(), t.arguments());
}
// 5. 纯文本
if (aiMessage.text() != null) {
logger.info("LLM响应, 纯文本 : {}", aiMessage.text());
}
}
@Override
public void onError(ChatModelErrorContext errorCtx) {
errorCtx.error().printStackTrace();
}
};
return OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName(modelName)
.baseUrl(baseUrl)
.listeners(List.of(listener))
.build();
}
@Bean
public Assistant assistant() {
ContentRetriever contentRetriever = createContentRetriever(ragFilePath);
return AiServices.builder(Assistant.class)
.chatModel(chatModel())
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(contentRetriever)
.build();
}
private static ContentRetriever createContentRetriever(String ragFilePath) {
// DocumentParser的作用是把磁盘上的文件转为Document对象,以便后面的分块处理,
// TextDocumentParser处理文本类文件,如txt、md等,如果要处理更多类型,可以用ApacheTikaDocumentParser,代价是包更大,启动更慢
DocumentParser documentParser = new TextDocumentParser();
long start = System.currentTimeMillis();
logger.info("开始加载索引文件:{}", ragFilePath);
List<Document> documents = FileSystemDocumentLoader.loadDocuments(ragFilePath, documentParser);
logger.info("加载索引文件完成,耗时: {}毫秒, 文件数量: {}",
(System.currentTimeMillis() - start), documents.size());
start = System.currentTimeMillis();
logger.info("开始对文档分块,共{}个文档", documents.size());
List<TextSegment> segments = new ArrayList<>();
// 每个文档分块
for (Document document : documents) {
// 文档分块, 每个分块300个字符, 重叠0个字符
DocumentSplitter splitter = DocumentSplitters.recursive(300, 0);
segments.addAll(splitter.split(document));
}
logger.info("文档分块完成,共{}个分块,耗时: {}毫秒", segments.size(), (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
logger.info("开始将文档分块转为向量");
// 每个分块创建嵌入向量,模型是智源 bge-small-zh-v1.5 量化版,中文 C-MTEB 第一梯队
EmbeddingModel embeddingModel = new BgeSmallZhV15QuantizedEmbeddingModel();
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings, segments);
logger.info("文档分块转为向量完成,共{}个向量,耗时: {}秒", embeddings.size(), (System.currentTimeMillis() - start) / 1000);
// 创建内容检索器
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(2) // 每个查询返回2个最相关的分块
.minScore(0.5) // 每个分块的相似度阈值
.build();
return contentRetriever;
}
}- 建议配合前面的时序图来看配置类代码,重点在createContentRetriever方法:
- 用FileSystemDocumentLoader加载文件,对于入参,如果您的文件是txt,markdown这样的文本类,用TextDocumentParser最合适,如果是其他高级文档(例如PDF),那么用ApacheTikaDocumentParser,
- 加载后进行分割,也就是所有的文档最终转成了segment对象
- 文本转为向量的时候使用了BgeSmallZhV15QuantizedEmbeddingModel,这是智源 bge-small-zh-v1.5 量化版,中文 C-MTEB 第一梯队
- 在创建查询工具ContentRetriever的时候,还可以通过maxResults方法设置返回结果的数量,以及minScore方法设置相似度阈值
-
其实以上代码就是今天的核心了,可见LangChain4j提供了详细的API和参数给我们使用
-
接下来是服务类,按部就班调用自定义接口即可
java
package com.bolingcavalry.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* 通义千问服务类,用于与通义千问模型进行交互
*/
@Service
public class QwenService {
private static final Logger logger = LoggerFactory.getLogger(QwenService.class);
@Autowired
private Assistant assistant;
/**
* 通过提示词range大模型返回JSON格式的内容
*
* @param prompt
* @return
*/
public String byRagNaive(String prompt) {
String answer = assistant.byRagNaive(prompt);
logger.info("响应:" + answer);
return answer + "[from byRagNaive]";
}
}- 最后是controller类,这里准备个http接口响应,用来调用前的服务类的功能
java
package com.bolingcavalry.controller;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.bolingcavalry.service.QwenService;
import lombok.Data;
/**
* 通义千问控制器,处理与大模型交互的HTTP请求
*/
@RestController
@RequestMapping("/api/qwen")
public class QwenController {
private final QwenService qwenService;
/**
* 构造函数,通过依赖注入获取QwenService实例
*
* @param qwenService QwenService实例
*/
public QwenController(QwenService qwenService) {
this.qwenService = qwenService;
}
/**
* 提示词请求实体类
*/
@Data
static class PromptRequest {
private String prompt;
private int userId;
}
/**
* 响应实体类
*/
@Data
static class Response {
private String result;
public Response(String result) {
this.result = result;
}
}
/**
* 检查请求体是否有效
*
* @param request 包含提示词的请求体
* @return 如果有效则返回null,否则返回包含错误信息的ResponseEntity
*/
private ResponseEntity<Response> check(PromptRequest request) {
if (request == null || request.getPrompt() == null || request.getPrompt().trim().isEmpty()) {
return ResponseEntity.badRequest().body(new Response("提示词不能为空"));
}
return null;
}
@PostMapping("/rag/naive")
public ResponseEntity<Response> byRagNaive(@RequestBody PromptRequest request) {
ResponseEntity<Response> checkRlt = check(request);
if (checkRlt != null) {
return checkRlt;
}
try {
String response = qwenService.byRagNaive(request.getPrompt());
return ResponseEntity.ok(new Response(response));
} catch (Exception e) {
// 捕获异常并返回错误信息
return ResponseEntity.status(500).body(new Response("请求处理失败: " + e.getMessage()));
}
}
}- 至此代码就全部写完了,现在把工程运行起来试试,在rag-easy目录下执行以下命令即可启动服务
bash
mvn spring-boot:run- 启动日志如下,同一份本地文档,在前文用Easy RAG转向量时用了25秒,而这次只用了12秒,实测发现向量模型对耗时影响较大(改为BgeSmallEnV15QuantizedEmbeddingModel耗时就超过了20秒)
- 要是用完整维基百科来索引其耗时应该难以接受(真要是索引全部维基百科,就必须用单独的服务将向量数据做持续化存储,而非启动时在内存中存储)
shell
08:08:00.731 [main] INFO c.b.config.LangChain4jConfig - 开始加载索引文件:/home/will/temp/202601/15/zhwiki_txt
08:08:00.753 [main] INFO c.b.config.LangChain4jConfig - 加载索引文件完成,耗时: 22毫秒, 文件数量: 1
08:08:00.754 [main] INFO c.b.config.LangChain4jConfig - 开始对文档分块,共1个文档
08:08:00.793 [main] INFO c.b.config.LangChain4jConfig - 文档分块完成,共233个分块,耗时: 39毫秒
08:08:00.793 [main] INFO c.b.config.LangChain4jConfig - 开始将文档分块转为向量
08:08:05.315 [main] INFO ai.djl.util.Platform - Found matching platform from: jar:file:/home/will/.m2/repository/ai/djl/huggingface/tokenizers/0.31.1/tokenizers-0.31.1.jar!/native/lib/tokenizers.properties
08:08:05.340 [main] WARN a.d.h.t.HuggingFaceTokenizer - maxLength is not explicitly specified, use modelMaxLength: 512
08:08:13.349 [main] INFO c.b.config.LangChain4jConfig - 文档分块转为向量完成,共233个向量,耗时: 12秒- 用vscode的 REST Client插件发起http请求,参数如下,和前文用提示词指定JSON不同,这里并没有要求LLM返回JSON格式
bash
### 用提示词实现json格式的输出
POST http://localhost:8080/api/qwen/rag/naive
Content-Type: application/json
Accept: application/json
{
"prompt": "一百字介绍完顏陳和尚"
}- 收到响应如下,可见LLM的回复内容是基于本地文档整理而成
bash
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Date: Fri, 16 Jan 2026 08:07:42 GMT
Connection: close
{
"result": "完顏陳和尚,本名彝,字良佐,金末名將,豐州(今內蒙古呼和浩特東)人,為蕭王完顏秉德後裔。他通曉《孝經》《左傳》,擅寫細字,有儒將之風。曾於大昌原之役等戰役中屢敗蒙古軍,展現卓越軍事才能。[from byRagNaive]"
}-
再看日志,可见这次本地只检索到一条与提示词有关的结果(向量查询,如果把向量模型改为BgeSmallEnV15QuantizedEmbeddingModel就会查出两条),这些结果被送到LLM,再由LLM返回最终结果
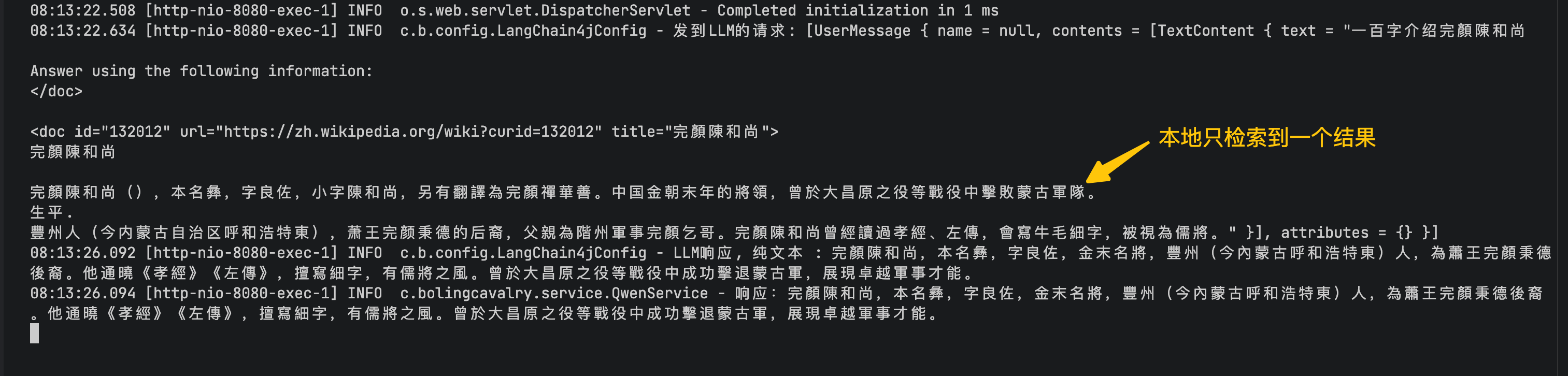
-
至此,Naive RAG就完成了,相比前文,在索引的时候咱们可以根据业务情况做更详细的设置,还有检索工具也能通过API做一些设置,这比Easy RAG就有了更多的自由度
有个问题
- 至此,咱们可以通过LangChain4j实现RAG业务了,不过聪明的您应该也发现了以下问题:
- 五百行的文本,转为向量需要十多秒,那整个维基百科转为向量岂不是要等很久?
- 当前的方案是把向量保存在内存中的,文本要是多的话,内存不够用咋办?
- 要是进程出问题了向量就丢了,所以每次启动都要重新加载吗?
- 以上都是很现实的问题,不解决的话如何用在生产环境?所以下一篇文章咱们就来解决这些问题吧