写在前面:本博客全部基于知乎的大模型课程所做的笔记和整以及和在实操过程中遇到的问题和处理方法,(老师们讲的都很好,解答的也很细致)博主也正在学习中,如果有错误的地方期待和我沟通。大多代码都来自于上课的资料,加入了一些注释和梳理,或者对我没有跑通的代码做了一些修改让他符合我的需求。
langchain:开发框架
---langchain是什么?
它提供了一套工具、接口和组件,简化了创建LLM应用的过程
由多个组件组成(工具箱的合集),包括:
- models:模型(gpt-4o、deepseek etc)
- prompts:提示(提示管理、提示优化、提示序列化)
- memory:记忆(保存和模型交互时的上下文)
- indexes:索引(结构化文档,方便和模型交互)有时也可以称为rag,构建自己的知识库要对文档加载转化、长文本切割、文本向量计算、向量索引存储查询等
- chains:链(对组件的调用)(工作流)
- agents:代理(决定模型采取哪些行动,执行并观察流程,直到完成)
langchain改版了?改啥了?
langchain目前从0.3x到1.x发生了结构性变化(不兼容)
1、包结构完全重构
langchain-corn:只放抽象基类与langchain expression language(LCEL)语言更加简洁,更加凝结,所有第三方集成都不直接依赖完整langchain。
langchain-community:和第三方合作,社区维护的几十种loader、retriever、tool等实现。合作伙伴包独立成库,例如langchain-openai,体积更小升级更灵活。
2、新增官方子项目
langgraph:用图编排workflow,代替过去靠多重chain嵌套的写法
langserve:搭建对外的接口,一键把链/代理封装成REST API,自带/invoke、/stream、/batch端点与swagger页面。
langsmith:可视化调试。回归测试、在线监控平台。
3、API风格全面转向LCEL(链式表达式)
鼓励用 | 运算符把组件拼成runnable,串联到一起。
langchain整体架构
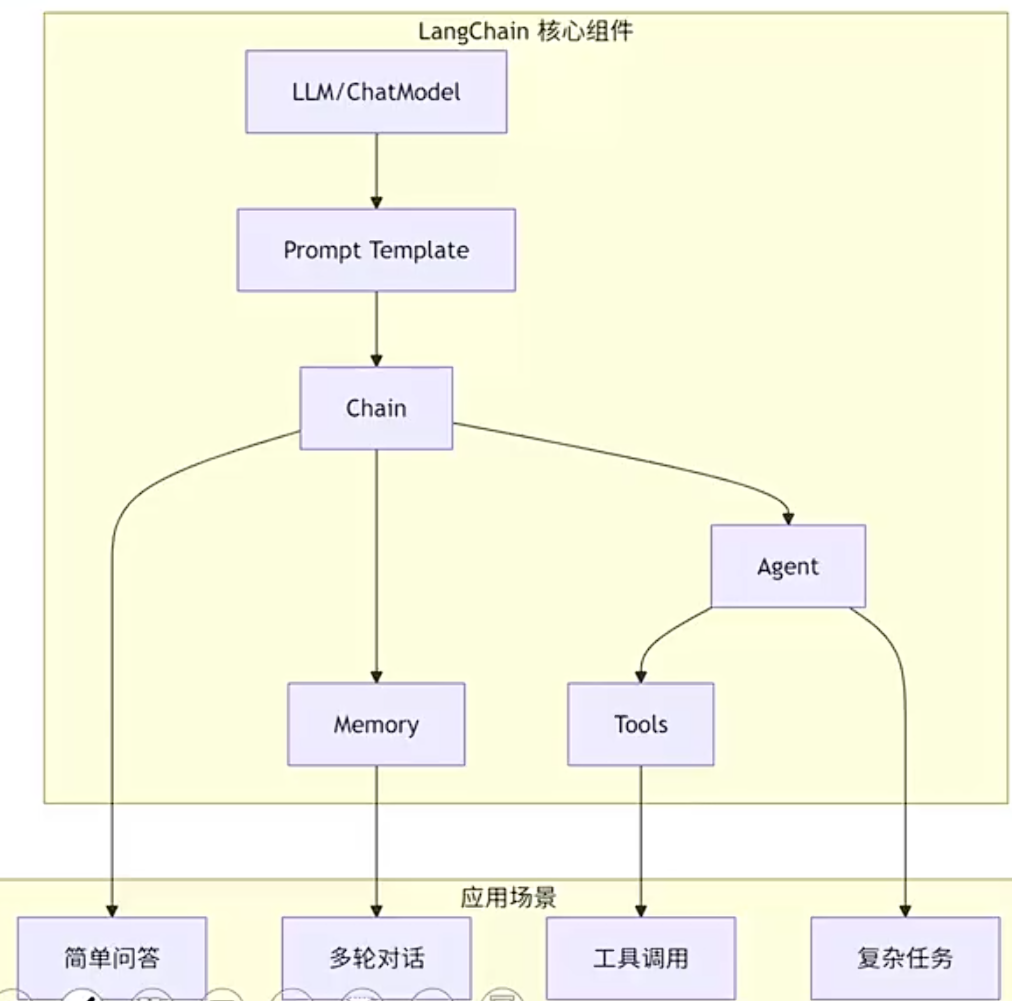
LLM(用于文本补全)/chatmodel(用于对话、支持tool calling):大模型语言的封装
prompt template:提示词模板,支持变量替换
chain:串联多个组件,例如prompt | llm,数据依次流经各组件
agent:智能代理
tools:工具集,扩展agent能力(搜索、计算、数据库查询等)
memory:记忆组件,多轮对话
实践一:使用langchain
代码是这样的:
python
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi # 导入通义千问Tongyi模型
import dashscope
import os
#若使用方法三必须加的一段,加载了才能get
import dotenv
#默认加载.env文件中的环境变量
dotenv.load_dotenv()
#方法一:api_key等于百炼云平台的api_key
api_key='你自己的apikey'
dashscope.api_key = api_key
# 方法二:从环境变量获取 dashscope 的 API Key(本地)
api_key = os.getenv('DASHSCOPE_API_KEY')
dashscope.api_key = api_key
#方法三:从.env环境变量获取dashscope
#代码和方法二一模一样,在项目里创建一个文件env,在其中加入apikey的值
# 加载 Tongyi 模型
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=api_key) # 使用通义千问qwen-turbo模型
# 创建Prompt Template
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
# 新推荐用法:将 prompt 和 llm 组合成一个"可运行序列"
chain = prompt | llm
# 使用 invoke 方法传入输入
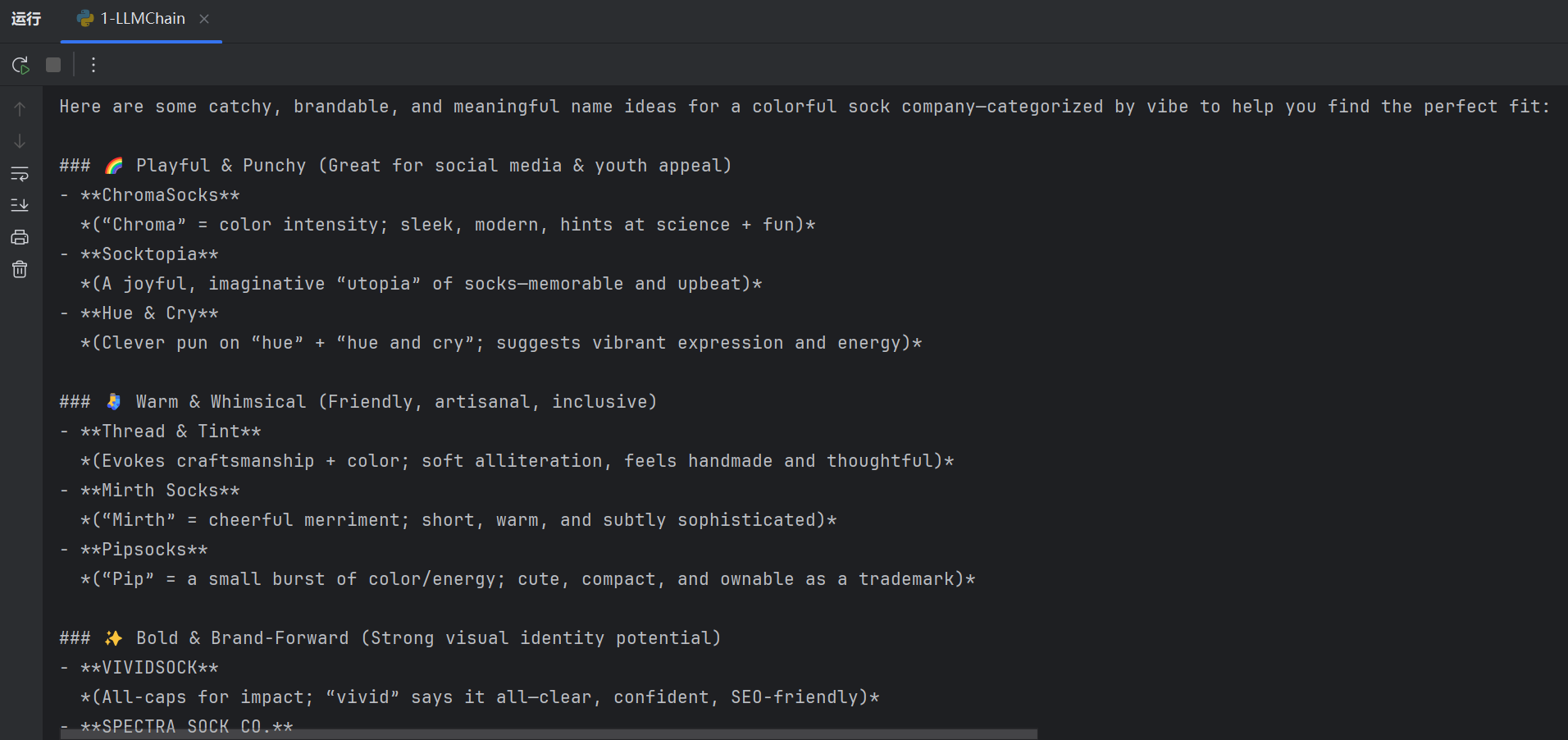
result1 = chain.invoke({"product": "colorful socks"})
print(result1)
result2 = chain.invoke({"product": "广告设计"})
print(result2)我们一步步来看。
安装
为代码文件配置了虚拟编译器之后,就会出现venv文件,相当于一套比较纯净独立的Python解释器,每个项目的编辑器独立,不会受其他的影响。
按照requirements的版本进行库的安装,包括dashscope、langchain-community等
安装出了一些错误,采用了国内镜像源,跳过缓存,加快了下载速度,避免了下载超时。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=100
安装成功。
每个模块的作用
- 创建 Prompt 模板
python
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes
{product}?",
)- 加载 LLM
python
from langchain_community.llms import Tongyi
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=api_key)3.使用管道符 | 组合成 Chain(链式连接了提示词prompt和大模型llm)
python
chain = prompt | llm4.调用invoke执行
python
result = chain.invoke({"product": "colorful socks"})到这里整个代码的逻辑是非常清楚的,有一个问题,怎么加载大模型llm,或者说怎么将大模型的api_key导入进来。
获取大模型api_key的方法(第三方服务的权限认证)
python
#若使用方法三必须加的一段,加载了才能get
import dotenv
#默认加载.env文件中的环境变量
dotenv.load_dotenv()
#方法一:api_key等于百炼云平台的api_key(注册获取)
api_key='sk-........'
dashscope.api_key = api_key
# 方法二:从环境变量获取 dashscope 的 API Key(本地)
api_key = os.getenv('DASHSCOPE_API_KEY')
dashscope.api_key = api_key
#方法三:从.env环境变量获取dashscope
#代码和方法二一模一样,在项目里创建一个文件env,在其中加入apikey的值
# 加载 Tongyi 模型
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=api_key) # 使用通义千问qwen-turbo模型第二种本地配置长这样
最后我们调用大模型成功,成功输出。
Agent的作用
这里科普一下,agent相当于一个管家(代理人)。众所周知,大模型只会说不会做,谁来承担这个动作在我们运用ai中变的更为重要。agent通过调用大模型和其他的识图、音频、定位等多类相关功能插件,在事先既定好的工作流里按序执行,从而完成我们想要的任务,这就是最常见的一类agent,我们叫做workflow agent。如果某类agent在此基础上可以进行推理尝试反馈,并循环这个流程,我们叫他react agent。
langchain对agent的官方定义:
they use an LLM to determine which actions to take(决定动作) and in what order(决定顺序). An action can either be using a tool(使用工具) and observing its output, or returning to the user(结果反馈).
当一个agent里集成了常用的诸多tools,这个时候,用户放出请求,大模型可以思考选择适配的工具来满足用户的需求。
需要调用一些api,比如surpapi可以搜索很多网址的api(像Google)。
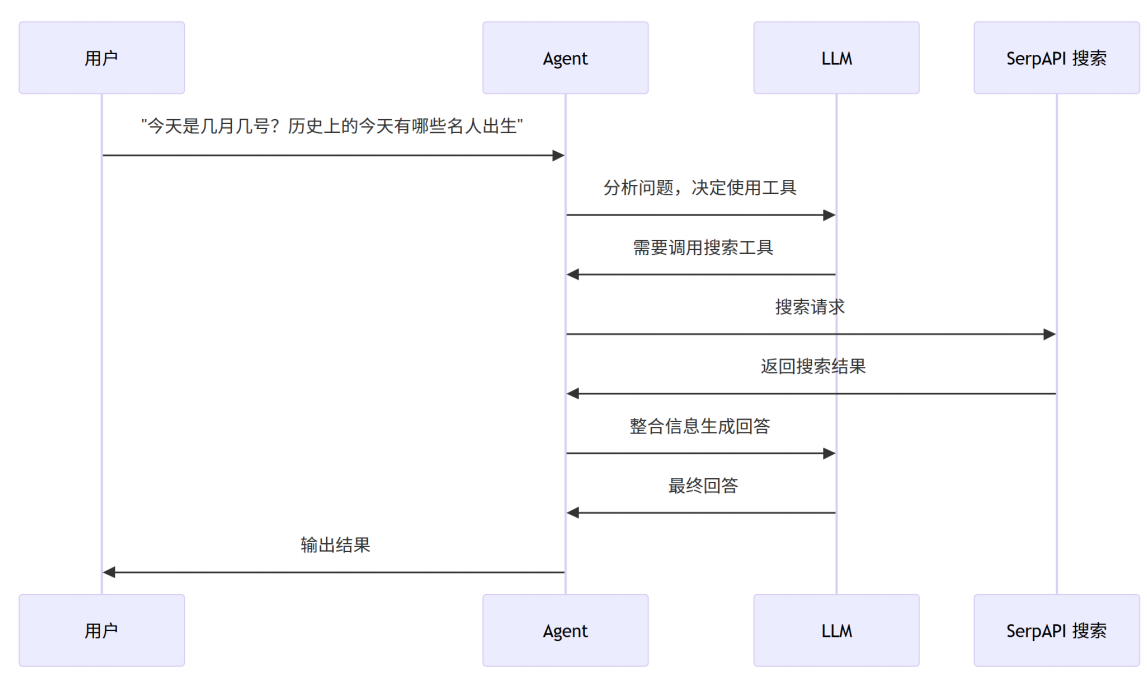
我们也可以使用多个tools,来自定义工具。
@tool 装饰器将函数转为 LangChain 工具
docstring(注释)非常重要,函数定义下方的 """...""" 三引号字符串就是 docstring,Agent 通过它判断何时使用该工具。
实践二:agent+自定义工具
python
import os
from langchain_community.agent_toolkits.load_tools import load_tools
from langchain_community.chat_models import ChatTongyi
from langchain.agents import create_agent
from langchain_core.tools import tool
import dashscope
# 从环境变量获取 dashscope 的 API Key
api_key = os.getenv('DASHSCOPE_API_KEY')
dashscope.api_key = api_key
# 加载模型 (使用 ChatModel 以支持 tool calling)
llm = ChatTongyi(model_name="deepseek-v3", dashscope_api_key=api_key)
# 自定义数学计算工具 (替代已废弃的 llm-math)
@tool
def calculator(expression: str) -> str:
"""计算数学表达式。只接受数字和运算符,例如: 2+2, 100/4, 32*1.8+32。不要使用变量名或占位符。"""
# 只允许数字、运算符和括号
import re
if not re.match(r'^[\d\s\+\-\*\/\.\(\)]+$', expression):
return f"错误: 表达式 '{expression}' 包含无效字符。请只使用数字和运算符(+,-,*,/)"
return str(eval(expression))
# 加载 serpapi 工具 + 自定义计算器
serpapi_tools = load_tools(["serpapi"])
tools = serpapi_tools + [calculator]
# LangChain 1.x 新写法
agent = create_agent(llm, tools)
# 运行 agent
result = agent.invoke({"messages": [("user", "当前北京的温度是多少华氏度?这个温度的1/4是多少")]})
print(result["messages"][-1].content)Memory
Chains 和 Agent之前是无状态的,他只会针对你当下的问题作出反应,如果你想让他能记住之前的交互,就需要引入内存。可以让LLM拥有短期记忆。
对话过程中,记住用户的input 和 中间的output。
在LangChain中提供了几种短期记忆的方式:
• BufferMemory :将之前的对话完全存储下来,传给LLM
• BufferWindowMemory :最近的K组对话存储下来,传给LLM
• ConversionMemory :对对话进行摘要,将摘要存储在内存中,相当于将压缩过的历史对话传递给LLM
• VectorStore-backed Memory :将之前所有对话通过向量存储到VectorDB(向量数据库)中*(像小型的rag)*,每次对话,会根据用户的输入信息,匹配向量数据库中最相似的K组对话
实践三:带记忆的对话链
python
import os
from langchain_community.chat_models import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
import dashscope
# 从环境变量获取 dashscope 的 API Key
api_key = os.getenv('DASHSCOPE_API_KEY')
dashscope.api_key = api_key
# 加载模型
llm = ChatTongyi(model_name="qwen-turbo", dashscope_api_key=api_key)
# 创建带历史记录(history)的 prompt、管理对话
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
MessagesPlaceholder(variable_name="history"),#历史消息占位符
("human", "{input}")
])
# 创建 chain
chain = prompt | llm
# 存储会话历史(session定位对话在历史中的位置,维护对话)
store = {}
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 创建带记忆的对话链
conversation = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history"
)
# 使用 session_id 区分不同会话
config = {"configurable": {"session_id": "default"}}
# 第一轮对话
output = conversation.invoke({"input": "Hi there!"}, config=config)
print(output.content)
# 第二轮对话 (会记住上一轮)
output = conversation.invoke({"input": "I'm doing well! Just having a conversation with an AI."}, config=config)
print(output.content)MessagesPlaceholder 用于在 Prompt 中插入历史消息
RunnableWithMessageHistory 自动管理消息历史
session_id 用于区分不同用户/会话
运行结果:

实践四:动手搭建本地知识智能客服
llm怎么变成agent?
AGENT_TMPL = """按照给定的格式回答以下问题。你可以使用下面这些工具:
{tools}
回答时需要遵循以下用---括起来的格式:
Question: 我需要回答的问题
Thought: 回答这个上述我需要做些什么
Action: "{tool_names}" 中的一个工具名
Action Input: 选择这个工具所需要的输入
Observation: 选择这个工具返回的结果
...(这个 思考/行动/行动输入/观察 可以重复N次)
Thought: 我现在知道最终答案
Final Answer: 原始输入问题的最终答案
现在开始回答,记得在给出最终答案前,需要按照指定格式
进行一步一步的推理。
Question: {input}
{agent_scratchpad}
"""
ai在chain链中进行自我思考的过程:thought、action、action input。
实践四:
python
import os
import textwrap
import time
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
from langchain_core.prompts import PromptTemplate
from langchain.agents import create_agent
# 定义了LLM的Prompt Template
CONTEXT_QA_TMPL = """
根据以下提供的信息,回答用户的问题
信息:{context}
问题:{query}
"""
CONTEXT_QA_PROMPT = PromptTemplate(
input_variables=["query", "context"],
template=CONTEXT_QA_TMPL,
)
# 输出结果显示,每行最多60字符,每个字符显示停留0.1秒(动态显示效果)
def output_response(response: str) -> None:
if not response:
exit(0)
for line in textwrap.wrap(response, width=60):
for word in line.split():
for char in word:
print(char, end="", flush=True)
time.sleep(0.1)
print(" ", end="", flush=True)
print()
print("----------------------------------------------------------------")
# 从环境变量获取 API Key
api_key = os.getenv('DASHSCOPE_API_KEY')
# 定义LLM
llm = ChatTongyi(model_name="qwen-turbo", dashscope_api_key=api_key)
# 工具1:产品描述
@tool
def find_product_description(product_name: str) -> str:
"""通过产品名称找到产品描述。输入产品名称如 Model 3, Model Y, Model X"""
print('product_name=', product_name)
product_info = {
"Model 3": "具有简洁、动感的外观设计,流线型车身和现代化前脸。定价23.19-33.19万",
"Model Y": "在外观上与Model 3相似,但采用了更高的车身和更大的后备箱空间。定价26.39-36.39万",
"Model X": "拥有独特的翅子门设计和更加大胆的外观风格。定价89.89-105.89万",
}
return product_info.get(product_name, "没有找到这个产品")
# 工具2:公司介绍
@tool
def find_company_info(query: str) -> str:
"""当用户询问公司相关的问题时使用。输入用户的问题"""
context = """
特斯拉最知名的产品是电动汽车,其中包括Model S、Model 3、Model X和Model Y等多款车型。
特斯拉以其技术创新、高性能和领先的自动驾驶技术而闻名。公司不断推动自动驾驶技术的研发,并在车辆中引入了各种驾驶辅助功能,如自动紧急制动、自适应巡航控制和车道保持辅助等。
"""
prompt = CONTEXT_QA_PROMPT.format(query=query, context=context)
response = llm.invoke(prompt)
return response.content
# 定义工具集
tools = [find_product_description, find_company_info]
# 创建 Agent
agent = create_agent(llm, tools)
if __name__ == "__main__":
# 主过程:可以一直提问下去,直到Ctrl+C
while True:
user_input = input("请输入您的问题:")
result = agent.invoke({"messages": [("user", user_input)]})
response = result["messages"][-1].content
output_response(response)让LLM能使用tools,按照规定的prompt执行,在这个prompt中,不断的:
Thought => Action, Action Input => Observation
直到Thought: 我现在知道最终答案
Final Answer: 原始输入问题的最终答案
react范式
我们之前在agent里面有提到react agent,就是这种思考>行动>观察,再循环的流程,(一步步拆解)将推理和动作相结合,克服LLM胡言乱语的问题,(加入thinking)同时提高了结果的可解释性和可信赖度。
有的时候我们也称之为CoT(chain of thought),思维链,复杂问题拆解成不同的步骤。
总结一下
Agent 的核心是把 LLM 当作推理引擎,让它能使用外部工具,以及自己的长期记忆,从而完
成灵活的决策步骤,进行复杂任务。
LangChain 里的 Chain 的概念,是由人来定义的一套流程步骤来让 LLM 执行,可以看成是把
LLM 当成了一个强大的多任务工具。
典型的 Agent 逻辑(比如 ReAct):
• 由 LLM 选择工具
• 执行工具后,将输出结果返回给 LLM
• 不断重复上述过程,直到达到停止条件,通常是 LLM 自己认为找到答案了
工具链组合设计
langchain的好处就是我们可以构造自己的工具链,把这个链给到ai,ai可以把复杂多样的功能和需求串联,结合多个工具,逐步处理复杂的问题。
像langchain中的工具加载和组合,这里加载了搜索引擎工具(serpapi)和数学计算工具(llm-math),并将其与语言模型(LLM)组合使用,以处理需要搜索和计算的任务。
python
from langchain.agents import load_tools
from langchain.llms import OpenAI
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=DASHSCOPE_API_KEY)
tools = load_tools(["serpapi", "llm-math"], llm=llm)实践五:工具链组合
假设我们要组合三个工具:文本分析工具(分析内容、统计信息和情感倾向)、数据转换工具(支持JSON和CSV格式互换)、文本处理工具(统计行数、查找文本和替换文本)。
要实现的功能:
1、分析以下文本的情感倾向,并统计其中的行数:'这个产品非常好用,我很喜欢它的设计,使用体验非常棒!\n价格也很合理,推荐大家购买。\n客服态度也很好,解答问题很及时。'(\n表示换行)
2、将以下CSV数据转换为JSON格式:'name,age,comment\n张三,25,这个产品很好\n李四,30,服务态度差\n王五,28,性价比高'
3、分析以下文本,找出所有包含'好'的行,然后将结果转换为JSON格式:'产品A:质量好,价格合理\n产品B:外观好,但价格贵\n产品C:性价比好,推荐购买'
这里主要是五个@tool,自定义了五个工具来满足这个链的需要,然后将它们构成一条链,行程agent之后和用户的输入参数绑定(process_task函数),之后再示例中给出用户输入,运行这个agent,测试输出结果。
python
from langchain_core.tools import tool
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
import json
import os
import dashscope
# 从环境变量获取 dashscope 的 API Key
api_key = os.environ.get('DASHSCOPE_API_KEY')
dashscope.api_key = api_key
# 自定义工具1:文本分析工具
@tool
def text_analysis(text: str) -> str:
"""分析文本内容,提取字数、字符数和情感倾向
参数:
text: 要分析的文本
返回:
分析结果
"""
# 简单的文本分析示例
word_count = len(text.split())
char_count = len(text)
# 简单的情感分析(示例)
positive_words = ["好", "优秀", "喜欢", "快乐", "成功", "美好"]
negative_words = ["差", "糟糕", "讨厌", "悲伤", "失败", "痛苦"]
positive_count = sum(1 for word in positive_words if word in text)
negative_count = sum(1 for word in negative_words if word in text)
sentiment = "积极" if positive_count > negative_count else "消极" if negative_count > positive_count else "中性"
return f"文本分析结果:\n- 字数: {word_count}\n- 字符数: {char_count}\n- 情感倾向: {sentiment}"
# 自定义工具2:数据转换工具
@tool
def data_conversion(input_data: str, input_format: str, output_format: str) -> str:
"""在不同数据格式之间转换,如JSON、CSV等
参数:
input_data: 输入数据
input_format: 输入格式
output_format: 输出格式
返回:
转换后的数据
"""
try:
if input_format.lower() == "json" and output_format.lower() == "csv":
# JSON到CSV的转换示例
data = json.loads(input_data)
if isinstance(data, list):
if not data:
return "空数据"
# 获取所有可能的列
headers = set()
for item in data:
headers.update(item.keys())
headers = list(headers)
# 创建CSV
csv = ",".join(headers) + "\n"
for item in data:
row = [str(item.get(header, "")) for header in headers]
csv += ",".join(row) + "\n"
return csv
else:
return "输入数据必须是JSON数组"
elif input_format.lower() == "csv" and output_format.lower() == "json":
# CSV到JSON的转换示例
lines = input_data.strip().split("\n")
if len(lines) < 2:
return "CSV数据至少需要标题行和数据行"
headers = lines[0].split(",")
result = []
for line in lines[1:]:
values = line.split(",")
if len(values) != len(headers):
continue
item = {}
for i, header in enumerate(headers):
item[header] = values[i]
result.append(item)
return json.dumps(result, ensure_ascii=False, indent=2)
else:
return f"不支持的转换: {input_format} -> {output_format}"
except Exception as e:
return f"转换失败: {str(e)}"
# 自定义工具3:文本处理工具 - 统计行数
@tool
def count_lines(content: str) -> str:
"""统计文本内容的行数
参数:
content: 文本内容
返回:
行数统计结果
"""
return f"文本共有 {len(content.splitlines())} 行"
# 自定义工具4:文本处理工具 - 查找文本
@tool
def find_text(content: str, search_text: str) -> str:
"""在文本内容中查找指定文本
参数:
content: 文本内容
search_text: 要查找的文本
返回:
查找结果
"""
if not search_text:
return "请提供要查找的文本"
lines = content.splitlines()
matches = []
for i, line in enumerate(lines):
if search_text in line:
matches.append(f"第 {i+1} 行: {line}")
if matches:
return f"找到 {len(matches)} 处匹配:\n" + "\n".join(matches)
else:
return f"未找到文本 '{search_text}'"
# 自定义工具5:文本处理工具 - 替换文本
@tool
def replace_text(content: str, old_text: str, new_text: str) -> str:
"""在文本内容中替换指定文本
参数:
content: 文本内容
old_text: 要替换的旧文本
new_text: 替换后的新文本
返回:
替换结果
"""
if not old_text:
return "请提供要替换的文本"
new_content = content.replace(old_text, new_text)
count = content.count(old_text)
return f"替换完成,共替换 {count} 处。\n新内容:\n{new_content}"
# 创建工具链
def create_tool_chain():
"""创建工具链"""
# 组合工具
tools = [
text_analysis,
data_conversion,
count_lines,
find_text,
replace_text
]
# 初始化语言模型(使用 ChatModel 以支持 tool calling)
llm = ChatTongyi(model_name="qwen-turbo", dashscope_api_key=api_key)
# 创建Agent(LangChain 1.x 新写法)
agent = create_agent(llm, tools)
return agent
# 示例:使用工具链处理任务
def process_task(task_description):
"""
使用工具链处理任务
参数:
task_description: 任务描述
返回:
处理结果
"""
try:
#用chain连接构成这个agent
agent = create_tool_chain()
#调用agent,输入用户的提问参数
result = agent.invoke({"messages": [("user", task_description)]})
return result["messages"][-1].content # 从返回的字典中提取输出
except Exception as e:
return f"处理任务时出错: {str(e)}"
# 示例用法
if __name__ == "__main__":
# 示例1: 文本分析与处理
task1 = "分析以下文本的情感倾向,并统计其中的行数:'这个产品非常好用,我很喜欢它的设计,使用体验非常棒!\n价格也很合理,推荐大家购买。\n客服态度也很好,解答问题很及时。'"
print("任务1:", task1)
print("结果:", process_task(task1))
# 示例2: 数据格式转换
task2 = "将以下CSV数据转换为JSON格式:'name,age,comment\n张三,25,这个产品很好\n李四,30,服务态度差\n王五,28,性价比高'"
print("\n任务2:", task2)
print("结果:", process_task(task2))运行结果:
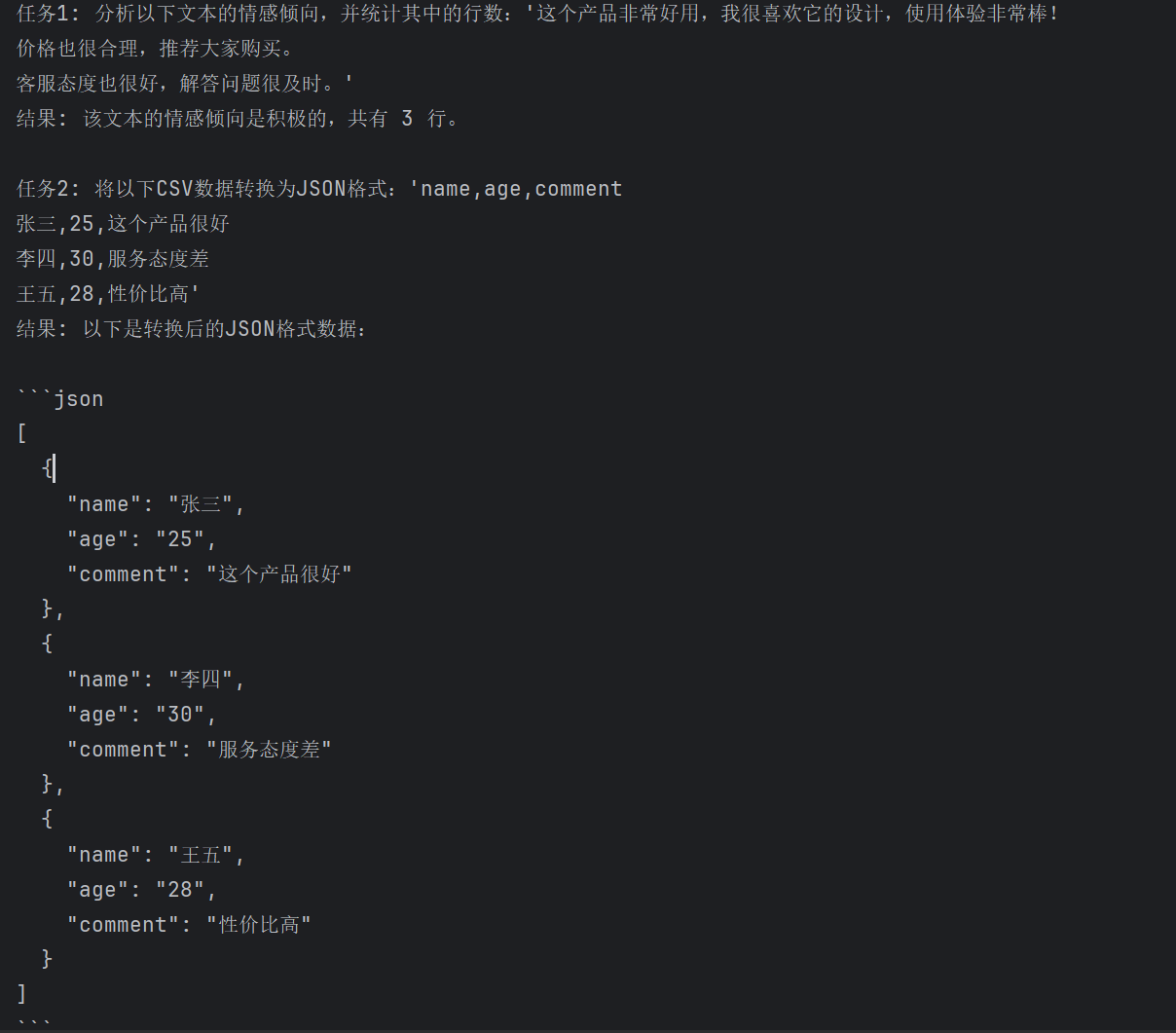
agent的思路是什么样的?
Thinking:整体的工作流程是怎样的?
Step1, 用户提交任务描述
Step2, Agent分析任务,决定使用哪些工具
Step3, Agent通过ReAct框架调用相应工具
Step4, 系统整合各工具结果,生成最终回答
工具链是怎么创建出来的呢?
create_tool_chain() 函数负责初始化各工具并组合成一个完整的工具链:
def create_tool_chain():
创建工具实例
text_analysis = TextAnalysisTool()
data_conversion = DataConversionTool()
text_processing = TextProcessingTool()
将工具包装为LangChain工具格式
tools = Tool(...), Tool(...), Tool(...)
初始化语言模型
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=DASHSCOPE_API_KEY)
创建提示模板
prompt = PromptTemplate.from_template(...)
创建代理
agent = create_react_agent(llm, tools, prompt)
创建代理执行器
agent_executor = AgentExecutor.from_agent_and_tools(...)
return agent_executor
提示词模版是怎样的?
你是一个有用的AI助手,可以使用以下工具:
{tools}
可用工具名称: {tool_names}
使用以下格式:
问题: 你需要回答的问题
思考: 你应该始终思考要做什么
行动: 要使用的工具名称
行动输入: 工具的输入
观察: 工具的结果
... (这个思考/行动/行动输入/观察可以重复多次)
回答: 对原始问题的最终回答
开始!
问题: {input}
思考: {agent_scratchpad}
在 LangChain 中,{agent_scratchpad} 是一个重要的占位符变量,用于在智能体(Agent)运行过程中临时存储和传递中间步骤的信息(比如思考过程、工具调用记录等)。它的作用类似于一个"草稿本"。
create_react_agent 是 LangChain 中自定义 ReAct 智能体的底层方法。它允许你自定义提示词(Prompt),并将工具链、推理流程等信息以变量的形式插入到提示词中。当你用 PromptTemplate 创建提示词时,LangChain 会自动把 {tools}、{tool_names} 替换为实际内容。
工具注册和调用
每个工具需要以特定格式注册,包括名称、描述和执行函数:
python
Tool(
name=tool_instance.name,
func=tool_instance.run,
description="工具描述..."
)内存与上下文
系统使用 ConversationBufferMemory 存储对话历史,使代理能够参考之前的交互 memory=ConversationBufferMemory(memory_key="chat_history")。
拓展:实践六:做一个ai小助手(减少agent的误解)
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.llms import Tongyi # 导入通义千问Tongyi模型
from langchain_core.output_parsers import StrOutputParser
import dashscope
import os
# 从环境变量获取 dashscope 的 API Key
api_key = os.environ.get('DASHSCOPE_API_KEY')
dashscope.api_key = api_key
# stream=True 让LLM支持流式输出
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=api_key, stream=True)
# 定义三个子任务:翻译->处理->回译
translate_to_en = ChatPromptTemplate.from_template("Translate this to English: {input}") | llm | StrOutputParser()
process_text = ChatPromptTemplate.from_template("Analyze this text: {text}") | llm | StrOutputParser()
translate_to_cn = ChatPromptTemplate.from_template("Translate this to Chinese: {output}") | llm | StrOutputParser()
# 组合成多任务链
workflow = {"text": translate_to_en} | process_text | translate_to_cn
#workflow.invoke({"input": "北京有哪些好吃的地方,简略回答不超过200字"})
# 使用stream方法,边生成边打印
for chunk in workflow.stream({"input": "北京有哪些好吃的地方,简略回答不超过200字"}):
print(chunk, end="", flush=True)
print() # 换行执行的功能很简单,但这里和我们的预期出了一些偏差。
我的本意是想获得北京的好吃地方,结果第一遍我的输出是这样的:
本文是一份精心打造、兼具实用性与文化深度的北京美食指南,专为追求地道、多元饮食体验的旅行者量身定制。以下为其分层解析:
**1. 编写目的与目标读者**
**核心目标**:提供一份简明扼要、可即刻付诸实践的用餐行程指南------巧妙融合必尝的经典名店、深藏街巷的在地宝藏,以及切实可行的实用建议。
**目标读者**:具备文化好奇心、中高参与度的旅行者(而非仅走马观花的普通游客),他们珍视真实感、渴望深度融入本地生活,并重视饮食的多样性(包括素食等特定膳食需求)。
**2. 整体结构与修辞策略**
**地理脉络 × 主题逻辑并重**:行文依循由表及里、由古至今的认知节奏------从享誉中外的代表性老字号(全聚德、仿膳饭庄)→ 承载历史记忆的胡同深处 → 人气鼎沸的街头美食地标(王府井、东华门)→ 充满活力的现代都市片区(三里屯、鼓楼)→ 富有精神意蕴的素食空间(广化寺)。这一布局恰如一位深思熟虑的旅行者探索北京的路径:层层展开帝国气象、市井传统、都市脉搏与静心选择。
**指令性动词的策略性运用**:"务必尝试......""细细品味......""切莫错过......""深入探访......""不妨一试......"------营造出充满活力又亲切鼓励的语调,在激发行动力的同时,避免生硬说教之感。
**感官体验与文化锚点并重**:精准嵌入具体菜名(煎饼、炸酱面、冰糖葫芦)及情境化描述("宫廷风味""胡同小吃""大胆新奇的味觉冒险"),不仅标示地点,更唤起味觉、触感、历史纵深与现场氛围。
**3. 文化与烹饪的深层肌理**
- **真实性层级的自觉建构**:清晰区分四类饮食形态:
• *标志性机构菜系*(如全聚德、大董的北京烤鸭------强调历史传承与精湛技艺);
• *日常民间饮食*(胡同小吃、王府井街头食摊------凸显可及性与本地生活节律);
• *历史场景再现*(仿膳饭庄的宫廷宴饮------依托表演性文化遗产,活化历史记忆);
• *当代创意演绎*(三里屯、鼓楼区域的"现代诠释"------承认并呈现北京饮食身份的动态演进)。
**包容性呈现**:明确提及素食选项------非作为边缘补充,而是作为根植于本土传统的宝贵选择("素食选择蓬勃兴盛"),有力印证其文化正当性(佛教寺院素斋在北京历史上具有重要地位)。
**隐含的社会认知智慧**:推荐"顾客熙攘、本地人常光顾的摊位",而非游客扎堆的"网红点"------这一看似细微的提示实则蕴含深厚在地经验:在北京,高本地客流往往比招牌或表面洁净度更能可靠反映食材新鲜度与经营信誉,体现了对食品安全语境的深刻理解。
**4. 核心优势与隐性专业素养**
**精当取舍的策展能力**:全篇控制在6--7个聚焦推荐,覆盖各类别,且每项均附清晰理据(例如:为何仿膳代表"宫廷风味",为何东华门适合"勇于尝鲜"的食客),避免信息过载。
**伦理化的卫生指引**:结尾提示"优先关注卫生与新鲜度......选择顾客众多、深受本地人青睐的摊位",务实而不危言耸听,尊重而不贬抑------既赋予读者自主判断力,亦维护了街头饮食文化的尊严。
**语言使用的精准平衡**:恰当使用中文原名(如*煎饼*、*炸酱面*),并紧随简洁英文释义------既便于初来者理解,亦郑重保留语言本真性。
**5. 可进一步优化之处(供参考)**
可简要标注季节性或时效性信息(例如:东华门夜市的营业时段;部分胡同摊贩仅限清晨出摊)。
可温和提醒辣度差异或常见致敏原(如黄豆酱中的麸质、街头腌料中可能含有的味精),以提升对敏感食客的友好度。
"三里屯或鼓楼的高端餐饮场所"虽具画面感,若能列举1--2个标杆实例(如以精致烤鸭见长的京雅堂,或主打高端素食的福和慧),将显著增强实用性与可信度。
**结语**:
这堪称目的地美食写作的典范之作------篇幅凝练却内涵丰盈,权威专业而温润亲和,深深扎根于北京多重叠合的城市身份(帝国遗韵、民居烟火、商业前沿、精神场域)。它不止于罗列餐厅名录,更是以食物为经纬,编织出一条穿越时间、空间与社会实践的"味觉旅程",让饮食本身成为理解这座城市的最真切透镜。尤为适配旅行类App内容、精品导览手册或行前知识准备材料------当真实性、实用性与文化共鸣成为核心诉求时,此指南无疑极具价值。
很明显,这并不是最终的答案,这像是一个方法论,那问题出在了哪呢,ai并不能很清晰的理解你所说的中译英译中的流程,在process_text处理阶段,Analyze this text: {text}的需求是很模糊的,
- 模型把我们的问题文本当成了「要分析的写作样本」,而不是「要回答的用户提问」;
- 多链的翻译环节把中文变成英文,进一步让模型误判任务是文本分析而非问答;
- 提示词没有明确必须出现具体餐厅 / 街区、字数上限、实用建议这几个约束条件。
于是我修改了这一行,给他加了更多的限制,引导ai给出结果的输出。
python
# 仅修改中间的process_text行,其他结构不变
process_text=ChatPromptTemplate.from_template(
"Answer this question with specific restaurant/street names, dishes, under 200 words, practical tip: {text}"
) | llm | StrOutputParser()最后的答案是这样的,很显然满足我的需求。
北京美食推荐:
• 东华门夜市(王府井附近)------品尝烤蝎子与羊肉串;
• 王府井小吃街(王府井大街)------必尝冰糖葫芦与臭豆腐。
• 北京烤鸭推荐:全聚德(前门店)或大董(国贸店)。
• 牛街("牛街"即"Ox Street",回民聚居区)------老张饺子馆(牛街西大街)提供手擀现包的饺子;悦盛餐厅(牛街中街)则以软嫩入味的牛肉面著称。
• 朝阳区三里屯------时尚咖啡馆云集,如西单赛萨咖啡(新源南路);胡同深处亦藏有宝藏:四季民福(什刹海店)以酥脆可口的烤鸭闻名,喜茶(南锣鼓巷店)则主打清甜芒果绿茶。
• 中关村鼎好面馆(中关村大街)------学生价享浓香地道的炸酱面;
• 西单嘉茂美食广场(西单北大街)------热闹非凡,肉夹馍与麻辣馄饨香气四溢。
**实用小贴士:**
• 避开冷清摊位,优先选择顾客排长队、现场操作卫生可见的摊主;
• 夜市就餐请务必选择现点现做的热食(如滋滋作响的烤串),切勿食用已预先炸好、长时间裸露摆放的熟食;
• 随身携带免洗洗手液与瓶装饮用水,保障饮食卫生安全。
最后大家可以尝试用一些ai编程工具来实现需求,我也正在试着用他们解决问题,有好用的请交出(感谢! )
)
实在写不动了,基本学明白了,下课。
纯粹课堂笔记,有任何侵权,联系我,马上删。