09_为什么Dropout能防止过拟合?正则化的本质
本章目标:理解过拟合的本质。为什么"随机关掉一部分神经元"(Dropout)这种看似破坏性的操作,反而能让模型变得更强?从集成学习(Ensemble Learning)的角度揭开 Dropout 的面纱。
📖 目录
- 什么是过拟合?(Overfitting)
- Dropout:训练时的"捣乱分子"
- [核心原理:集成学习 (Ensemble) 的视角](#核心原理:集成学习 (Ensemble) 的视角)
- [Inverted Dropout:为什么 PyTorch 这么实现?](#Inverted Dropout:为什么 PyTorch 这么实现?)
- [实战:PyTorch 中 Dropout 的正确用法](#实战:PyTorch 中 Dropout 的正确用法)
1. 什么是过拟合?(Overfitting)
想象你为了应付考试,把历年真题的答案全部死记硬背下来。
- 在做真题(训练集)时,你拿了满分。
- 在做新题(测试集)时,你直接挂科。
这就是过拟合:模型太强了,把数据的噪声也当成了规律。 神经网络因为参数极多,天然容易过拟合。
解决办法:
- 更多数据:从根源解决(通常最贵)。
- 正则化 (Regularization) :强行限制模型的能力,让它没法死记硬背。
- Image Augmentation:数据增强(旋转、裁剪)。
- Weight Decay:L2 正则化。
- Dropout:本章主角。
2. Dropout:训练时的"捣乱分子"
2012 年,Hinton 团队提出了 Dropout。核心思想极端简单:在训练时,随机"关掉"一部分神经元。
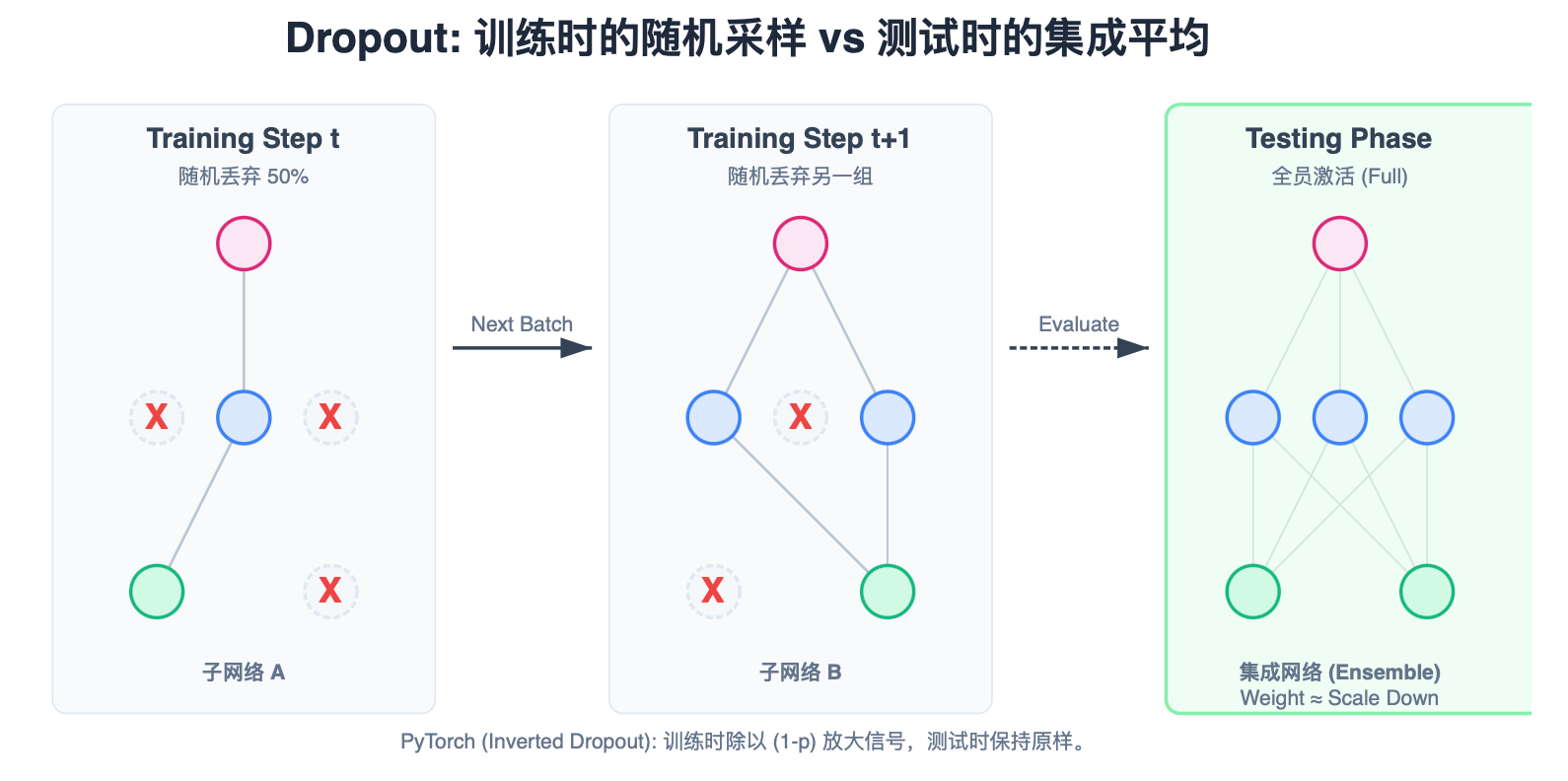
- 训练 (Training) :
- 对于每一次 Iteration(一个 Batch),抛硬币决定每个神经元是否工作。
- 假设 Dropout Rate p = 0.5 p=0.5 p=0.5,意味着平均有一半的神经元"罢工"了(输出强制为 0)。
- 前向传播 时它不传值,反向传播时它不更新梯度。
- 测试 (Testing) :
- 所有神经元全部回归岗位。
- 火力全开 (Full Capacity),不做任何丢弃。
为什么有效?防止共适应 (Co-adaptation)
- 想象一个项目组,如果大家都知道"大神 A"会搞定所有难题,其他人就会偷懒(权重趋近于 0)。
- Dropout 就像是这公司规定:每天随机有一半人(包括大神 A)必须请假。
- 结果:每个人都必须时刻准备着独当一面。神经元被迫学习更加鲁棒(Robust)、独立的特征,而不是依赖于某个特定的队友。
3. 核心原理:集成学习 (Ensemble) 的视角
Dropout 远不止是"捣乱"。它其实是在训练指数级数量的子网络。
- 子网络 :假设一层有 N N N 个神经元。每个神经元有 开/关 2 种状态。总共有 2 N 2^N 2N 种可能的网络结构。
- 共享权重 :虽然子网络结构不同,但它们共享同一个完整的权重矩阵 W W W。
- 训练 :每次 Iteration,我们其实是在训练这 2 N 2^N 2N 个子网络中的某一个。
- 测试 :我们在测试时使用全量网络,这在数学上等价于把这 2 N 2^N 2N 个子网络的预测结果取平均(Ensemble Average)。
众所周知,多模型集成 (Ensemble) 的效果总是优于单个模型。Dropout 是一种极其聪明的、低成本的集成学习实现方式。
4. Inverted Dropout:为什么 PyTorch 这么实现?
这就涉及到一个能量守恒的问题。
- 训练时 :假设 p = 0.5 p=0.5 p=0.5,只有一半神经元工作。总信号强度是 E x = 0.5 × Full Ex = 0.5 \times \text{Full} Ex=0.5×Full。
- 测试时 :所有神经元工作。总信号强度是 E x = 1.0 × Full Ex = 1.0 \times \text{Full} Ex=1.0×Full。
如果什么都不做,测试时的输出值会比训练时大一倍!这会导致网络崩溃。
方案 A:传统 Dropout
- 训练:正常算。
- 测试:手动把所有权重乘以 p p p (缩放)。
- 缺点:测试阶段需要修改计算逻辑,且迁移模型时容易忘。
方案 B:Inverted Dropout (PyTorch 方案)
- 为了让测试代码更简单,我们在训练时 把没被丢弃的元素除以 ( 1 − p ) (1-p) (1−p) 进行放大。
- 训练: y = 1 1 − p ∑ w i x i y = \frac{1}{1-p} \sum w_i x_i y=1−p1∑wixi。这样训练时的期望值就和全量网络一致了。
- 测试:什么都不用做!直接用!
5. 实战:PyTorch 中 Dropout 的正确用法
在 PyTorch 中,nn.Dropout(p=0.5) 的 p p p 是被丢弃的概率(Probability of being zeroed)。
python
import torch
import torch.nn as nn
class RobustNet(nn.Module):
def __init__(self):
super(RobustNet, self).__init__()
self.fc1 = nn.Linear(100, 50)
# Dropout 通常放在激活函数之后
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
# 训练时:随机置0,并放大剩余值 ( x / 0.5 )
# 测试时:不做任何操作
x = self.dropout(x)
x = self.fc2(x)
return x
model = RobustNet()
# ============================
# 演示:train() 和 eval() 的区别
# ============================
input_data = torch.randn(1, 100) # 一个样本
# 1. 训练模式
model.train()
output_train_1 = model(input_data)
output_train_2 = model(input_data)
# 你会发现这两次输出是不一样的!因为每次丢弃的神经元不同。
print(f"Train Run 1 vs Run 2 Equal? {torch.equal(output_train_1, output_train_2)}")
# -> False
# 2. 测试模式
model.eval()
output_test_1 = model(input_data)
output_test_2 = model(input_data)
# 这一步非常关键!如果不调 eval(),测试结果会很差且不稳定。
print(f"Eval Run 1 vs Run 2 Equal? {torch.equal(output_test_1, output_test_2)}")
# -> True避坑指南 (Cheat Sheet)
- 必须切换模式 :训练前调用
model.train(),验证/测试前调用model.eval()。 - Dropout 位置 :标准顺序是
Linear -> BatchNorm -> Activation -> Dropout。- (注:关于 BN 和 Dropout 的顺序有争议,虽然现代网络更倾向于把 Dropout 放在最后,或者干脆不用 Dropout 而只用 BN,见第10章。)
- p 值选择:隐藏层通常用 0.5,输入层通常用 0.2(或者不用)。