前言:
根据之前我关于YOLOv5的文章总结,本章我开始对YOLOv8进行原理->实践,从整体流程到单步流程。从前处理,网络结构到后处理正样本的筛选,函数的损失等一步一步来剖析目标检测算法YOLOv8的神秘面纱。
⭐深度学习之目标检测yolo算法Ⅲ-YOLOv5(1)-CSDN博客
⭐深度学习之目标检测yolo算法Ⅳ-YOLOv5(2)_yolo-parseq-CSDN博客
YOLOv8的创新
YOLOv5的创新有三个核心点
引入C3模块
Mosaic数据增强
自适应锚框
YOLOv8是基于YOLOv5的升级版本,属于集大成者
- 用C2f替代C3模块(更高效的特征融合)
- Anchor-Free + Anchor-Point
- 解耦头(分类与回归分开)
- TAL(任务对齐学习)让分类和回归的损失更匹配,提升精度
YOLOv8的模型结构
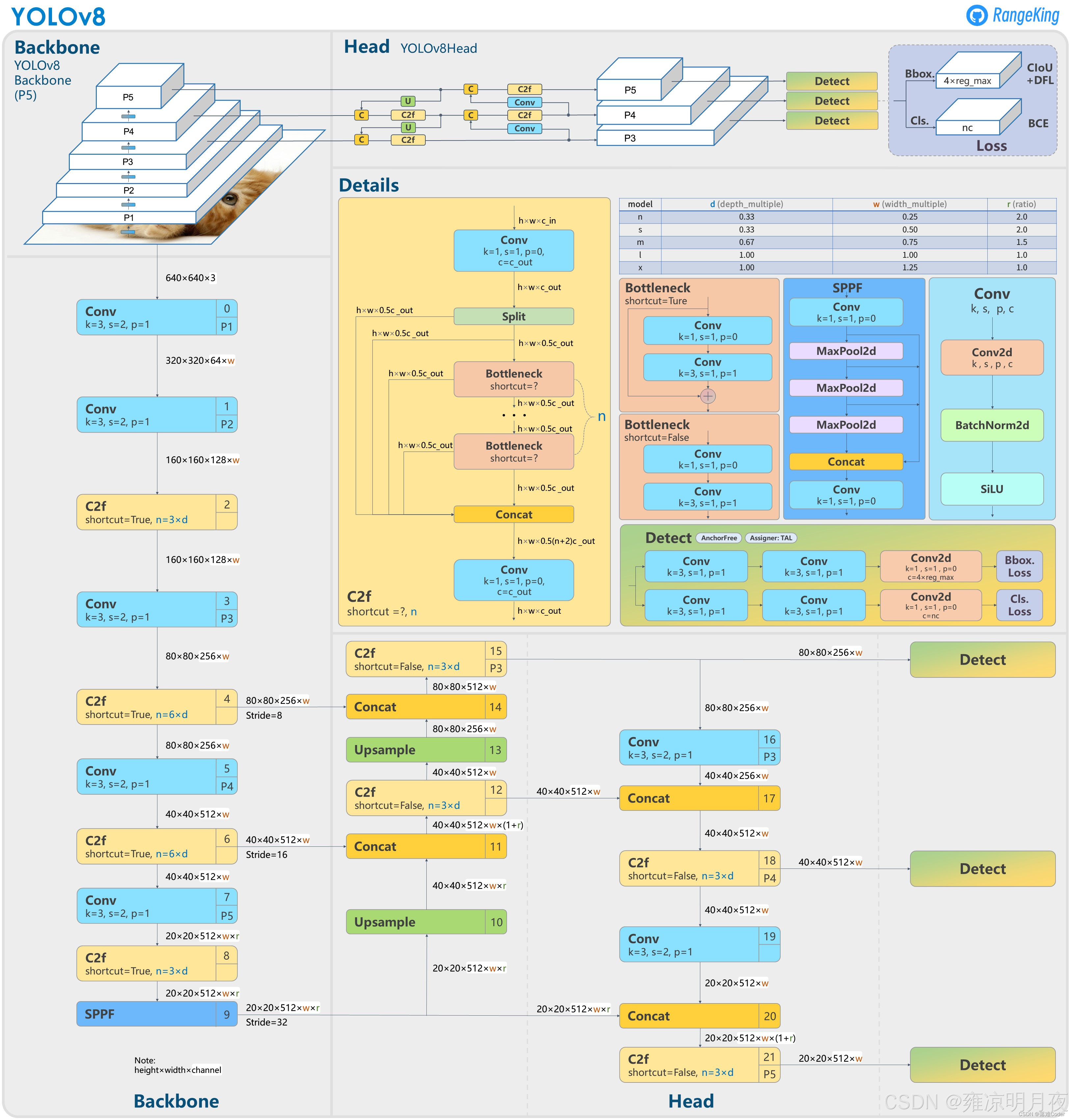
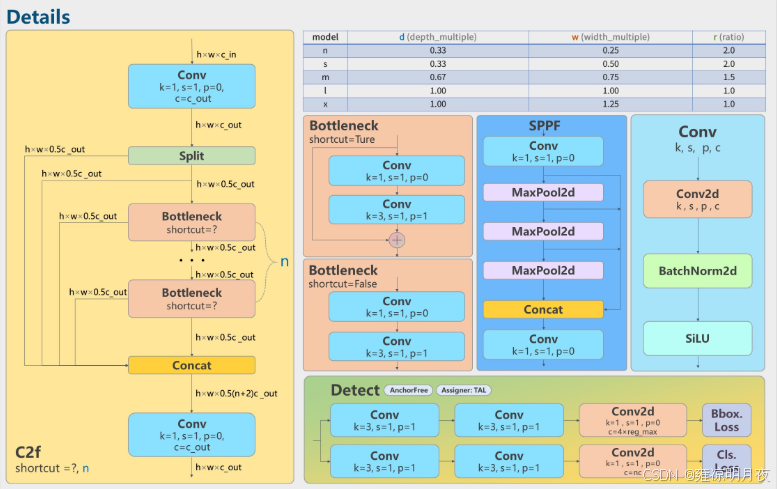
重要模块:
网络架构
⭐Backbone:特征提取的 "核心引擎"
1.c2f:特征分流+多径聚合。
源码路径(ultralytics/ultralytics/nn/modules/block.py)中的cf2模块
2.SPPF模块:空间金字塔池化,不同尺度特征融合,解决不同大小目标检测。
- C2f : "分成两部分 + shortcut 拼接" 是核心逻辑,补充:C2f 是对 YOLOv5 C3 模块的轻量化改进,用Split(拆分)+ Concat(拼接) 替代了 C3 的 Bottleneck 串联结构,残差分支是多个Bottleneck2d(轻量残差块),相比 C3,在参数量 / 计算量增加有限的前提下,残差连接更密集,特征复用性更强,这也是其特征提取能力提升的关键。
- SPPF :SPPF 是SPP 的快速优化版 (Spatial Pyramid Pooling Fast),用连续的 5×5 最大池化替代了 SPP 的 5×5、9×9、13×13 池化,实现了和 SPP 完全一致的多尺度特征融合效果,但计算效率大幅提升,这是 YOLOv5/8 保留 SPPF 而非原始 SPP 的原因。
Neck:特征融合的 "中转站"
1.FPN: 自顶向下,将高层的语义特征传递到底层。
2.PAN: 自底向上,把底层的几何特征传递到高层。
FPN+PAN =》同时让模型具备"识别目标"+"精准定位"的能力。
YOLOv8 去掉了 YOLOv5 中 Neck 部分上采样后的卷积连接层,进一步精简了参数量
Head:检测结果的 "输出端"(YOLOv8 最大创新之一)
**1.解耦头输出:**将分类任务和回归任务分为两个独立的分支,避免任务之间的相互干扰。
**2.Anchor-Free:**不预设锚框,直接中心点坐标 + l,t,r,b + 置信度,适配不同尺寸/比例目标
**3.TAL:**任务对齐学习,让分类分数与回归精度对齐。提升最终的mAP。
损失函数
YOLOv8 的损失由三部分组成:
- 分类损失:BCEWithLogitsLoss(二分类交叉熵,适配多标签检测);
- 回归损失:CIoULoss(考虑框的重叠面积、中心点距离、宽高比例,比 IoU Loss 更精准);
TAL(任务对齐学习):无单独损失,通过动态调整分类/回归损失的权重,让两者优化目标对齐,提升检测精度。
回归损失 :并非纯 CIoULoss ,YOLOv8 采用的是 CIoULoss + DFL(分布焦点损失) 组合!
- CIoULoss:如你所说,考虑了框的重叠面积、中心点距离、宽高比例,解决了纯 IoULoss 在框无重叠时梯度消失的问题;
- DFL(Distribution Focal Loss):把边界框的坐标回归转化为 "分布预测",用离散的概率分布拟合坐标的连续值,解决了传统回归对边界框精细定位的不足,让框的回归精度更高。
对于YOLOv8的源码分析,其主要结构与V5类似,我们首先从推理阶段入手,准备好任何一个best.pt和一张需要处理的图片(640x640),我们就能够模拟完成推理阶段的代码实现。准确的讲我们以检测流程(推理阶段)进行深入剖析,之后再分析网络结构和损失函数等核心步骤。
YOLOv8推理阶段源码解析
推理阶段(Detect):(Head + 解码) +后处理
1.YOLOv8 Detect Head+解码
问题产生:
在我的初始认知里,神经网络的输入和输出都应该为Tensor才正常,但是在实际操作过程中,我发现我Detect阶段中的Head部分代码中将1张640x640的图片输入后经过前向传播(forward)输出的结果居然不是Tensor,而是一个Tuple。
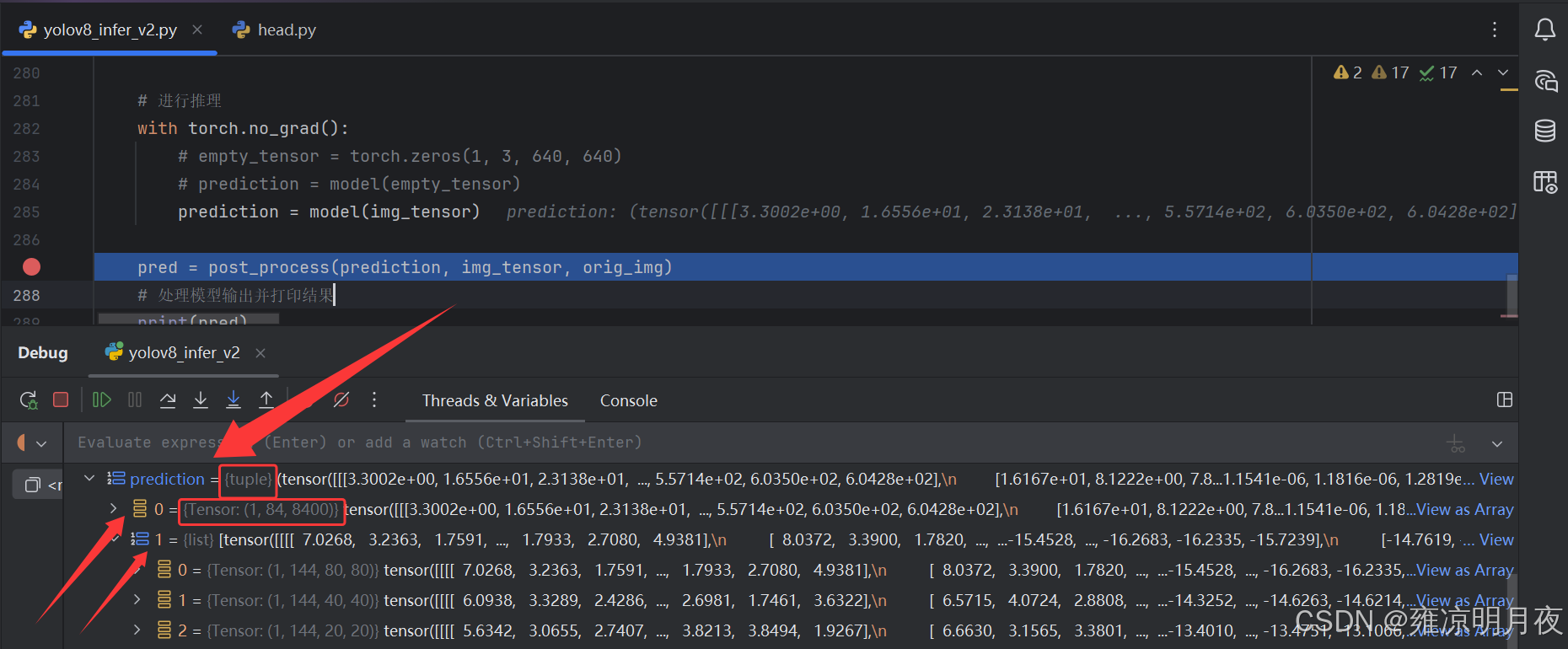
拆解 tuple 的两个部分:
- 第一部分:1x84x8400 的 tensor(concat 后的输出):
- 维度解释:(batch×(num_classes+4)×h×w),COCO 是 80 类,这里要注意,**(我们将位置预测的 80 类概率的最大值作为该框的置信度,所以这里没有添加置信度,仅有84个值)**YOLOv8 的 8400 是 640 输入时:80×80=6400,40×40=1600,20×20=400,总和 8400)。
- 作用:推理时直接对这个 tensor 做解码(将特征值转成检测框坐标、置信度、类别),方便后处理(NMS)。
- 第二部分:包含三个头的 list:
- 三个list的含义
- 第一个 Tensor(
1,144,80,80):对应大尺度特征图(80×80) → 负责检测小目标; - 第二个 Tensor(
1,144,40,40):对应中尺度特征图(40×40) → 负责检测中目标; - 第三个 Tensor(
1,144,20,20):对应小尺度特征图(20×20) → 负责检测大目标。
我在head.py阶段代码中的forward的源码中发现了这一判断,如果是训练阶段进行前向传播则直接返回3个list用于计算损失及其后续内容。
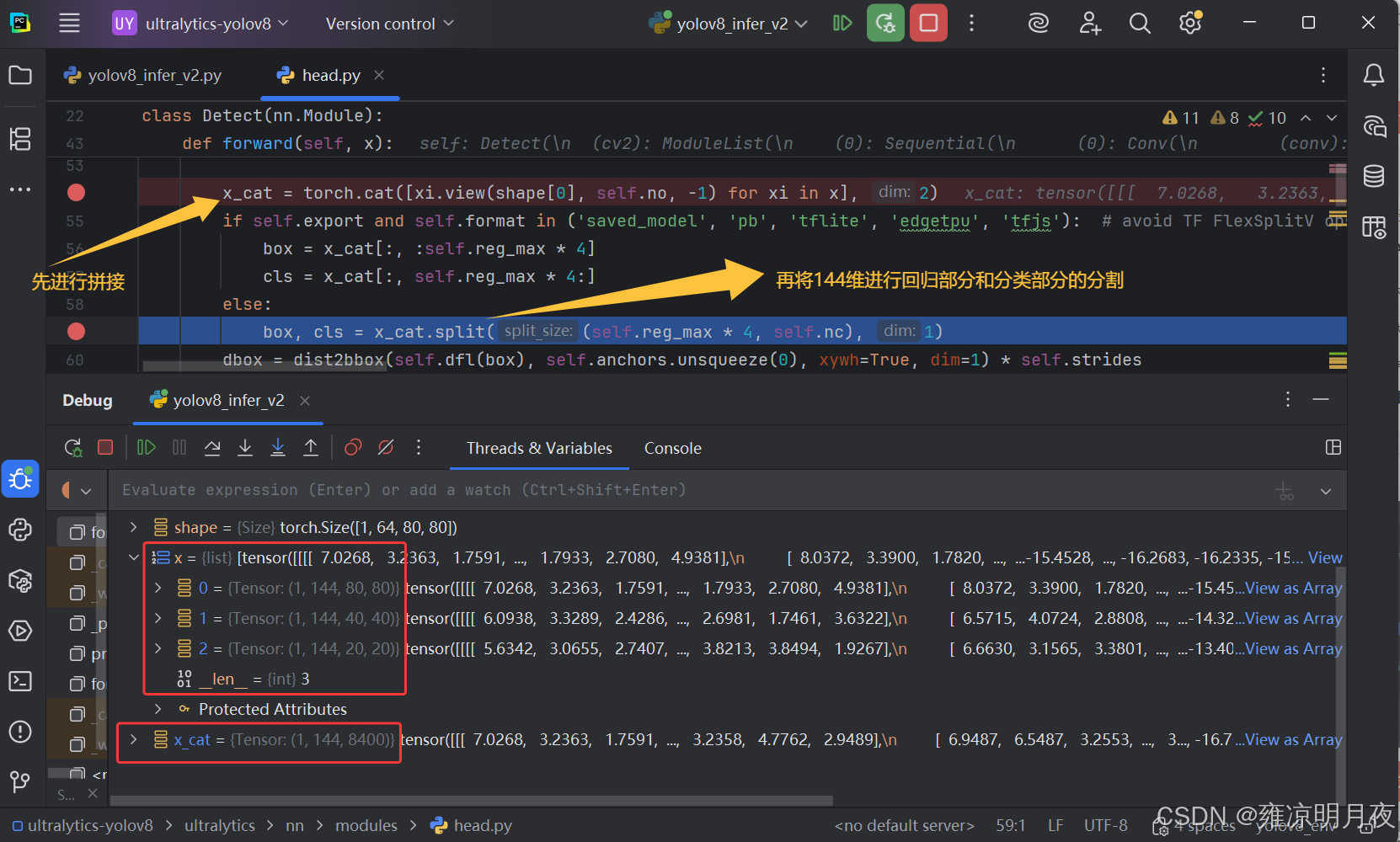
由于此时是detect阶段,继续向下的代码实现了进一步的拼接和分割实现
⭐⭐⭐
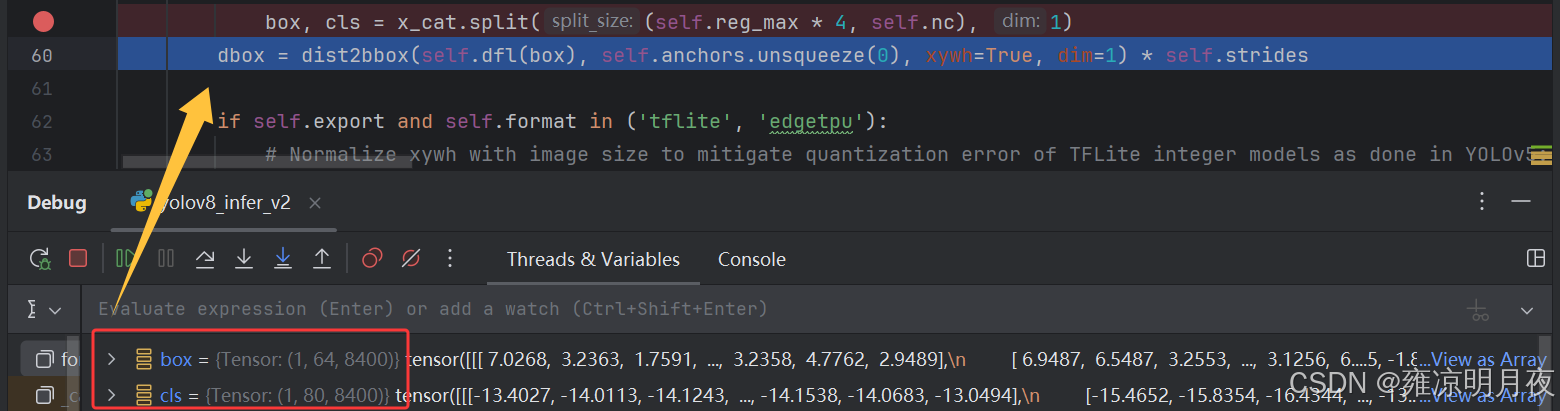
回归的box_Tensor = (1,64,8400):一张图片有8400个bbox,每个bbox用64个数表示其位置,其本质是 「概率分布特征」,64个特征经过分布解码(加权求和)后得到ltrb,代表bbox相对于网格中心点(v8的锚点)的偏移。
分类的cls_Tensor = (1,80,8400):一张图片有8400个预测位置,每个预测位置用80个数表示分类原始特征值,经过Sigmoid激活后转化为(0-1)的类别概率,每个值代表对应类别的概率。
解码分两步骤:
1.概率分布->ltrb距离,16个数->1个数
2.ltrb->xywh/xyxy
回归的dbox经过解码,归一化处理后从64维变成4维,同时对分类的cls_tensor进行Sigmoid处理后两者合并得到(1x84x8400)
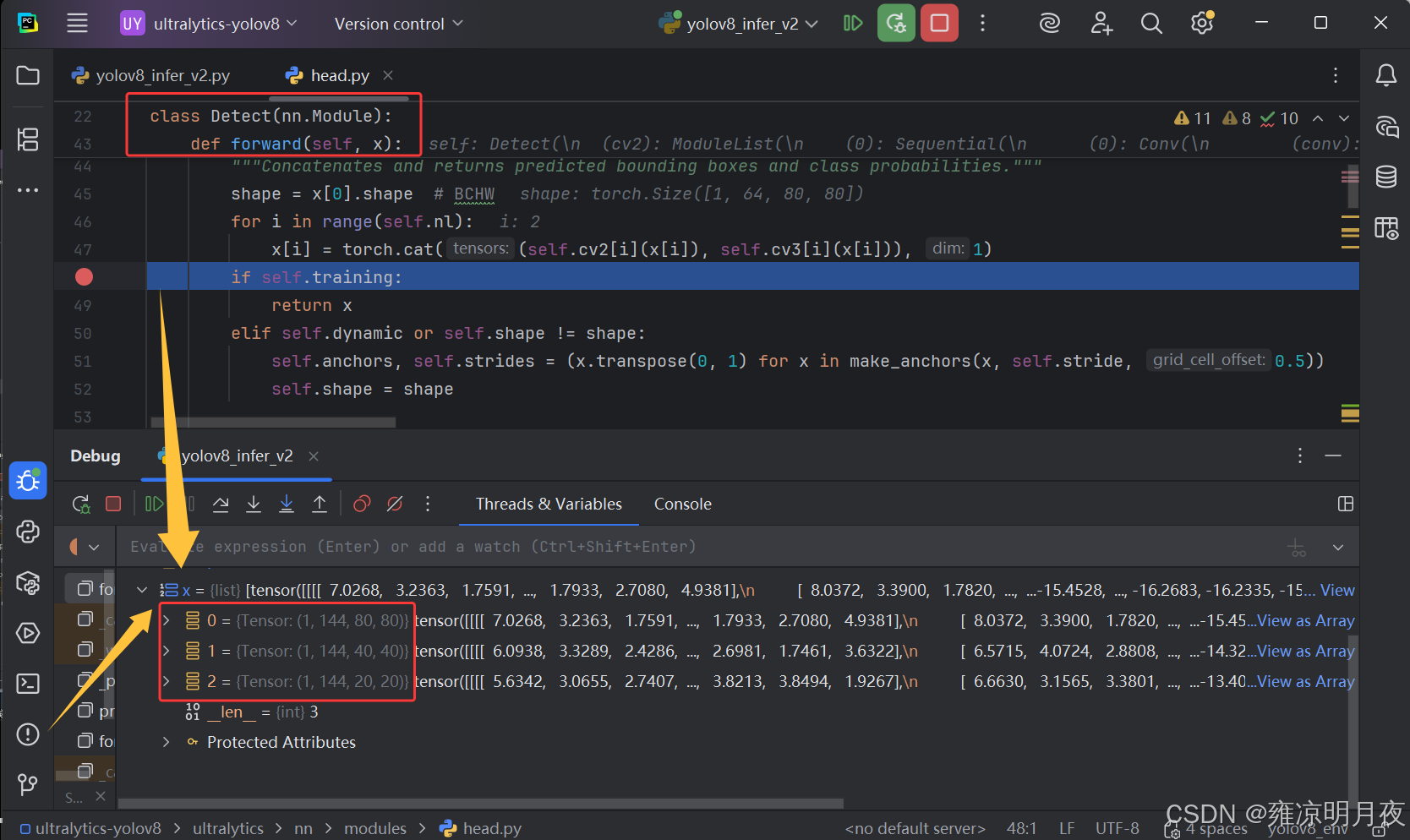
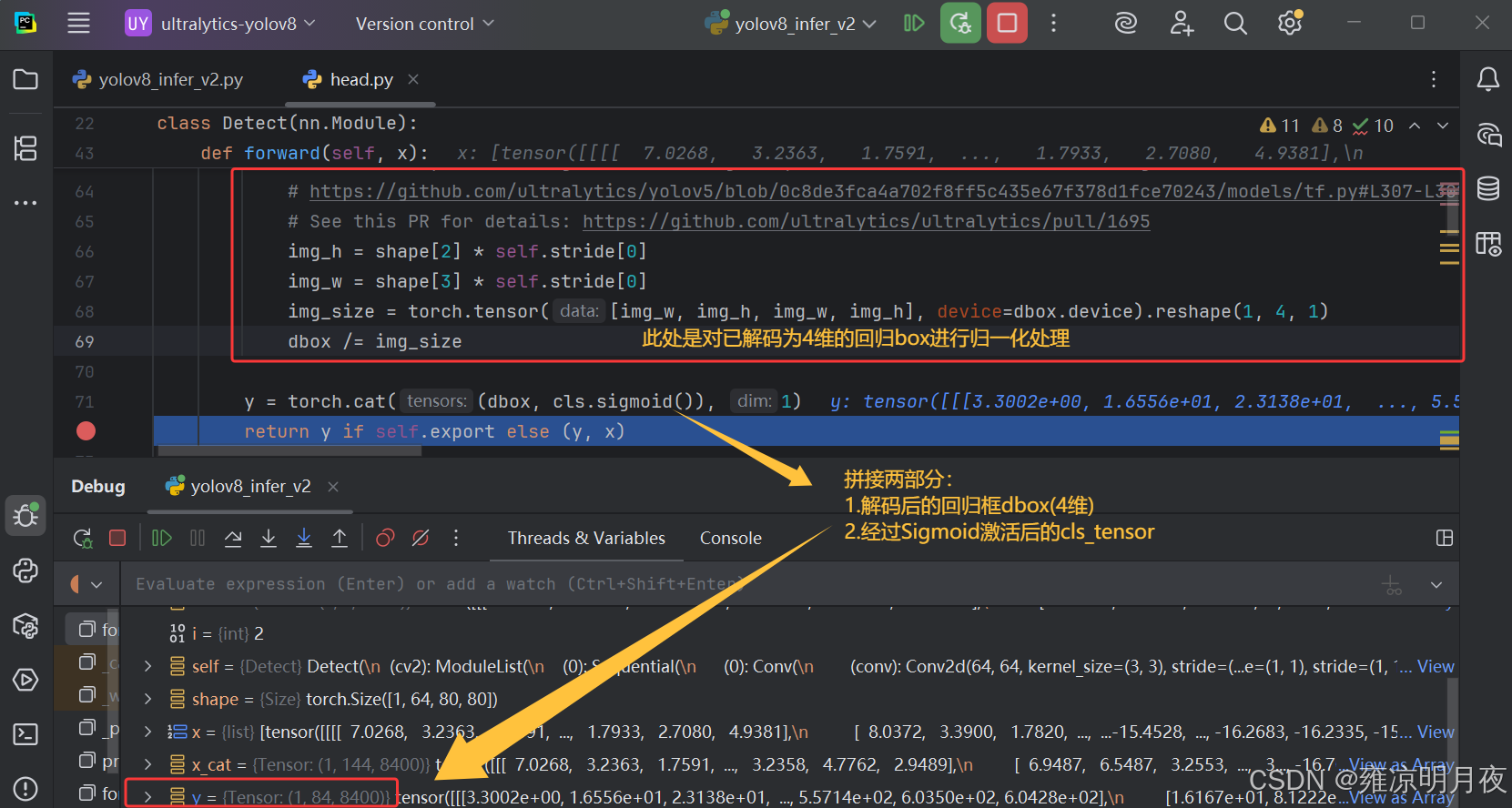
⭐基于Detect阶段中得到的1x84x8400的Tensor结果,此时仅完成了Head的前向传播+内部解码。
84 的本质:4(解码后的 xyxy 绝对坐标) + 80(Sigmoid 激活后的类别概率)
⭐⭐⭐yolov8和yolov5的区别(2点)
- 分类方式不同
- YOLOv5:用 Softmax 做互斥多分类(一个框仅属于一类)
- YOLOv8:用 Sigmoid 做多标签非互斥分类(一个框可属于多类,更贴合实际场景)
- 回归方式不同
- YOLOv5:直接回归 x/y/w/h 偏移量(直接回归)
- YOLOv8:用 DFL(分布焦点损失)建模坐标的概率分布,加权求和得到坐标(分布回归
回归分支解码(框架内部,基于Head原始144维输出):
Head原始输出(1×144×8400)的前64维是「DFL回归特征值」(4个坐标×reg_max=16)
解码逻辑:
生成 DFL 的候选坐标值(默认 reg_max=16,对应 0~15 的整数);
对每个坐标的16个bin特征值做 softmax,得到每个候选值的权重;
加权求和得到「偏移量」(dx, dy, dw, dh);
结合网格坐标+步长,计算实际框的 x/y/w/h:
x = (grid_x + sigmoid(dx)) × 步长
y = (grid_y + sigmoid(dy)) × 步长
w = exp(dw) × 步长
h = exp(dh) × 步长
注:代码中grid_xy已提前乘以步长,因此x = grid_xy:,0 + sigmoid(dx),无需重复乘步长。 5. 格式转换:xywh → LTRB → xyxy(最终84维的前4维)。
源码步骤实现:
同时注意下述代码中的init中这16个值的权重是不更新梯度的,其值保持为0-15。
python
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)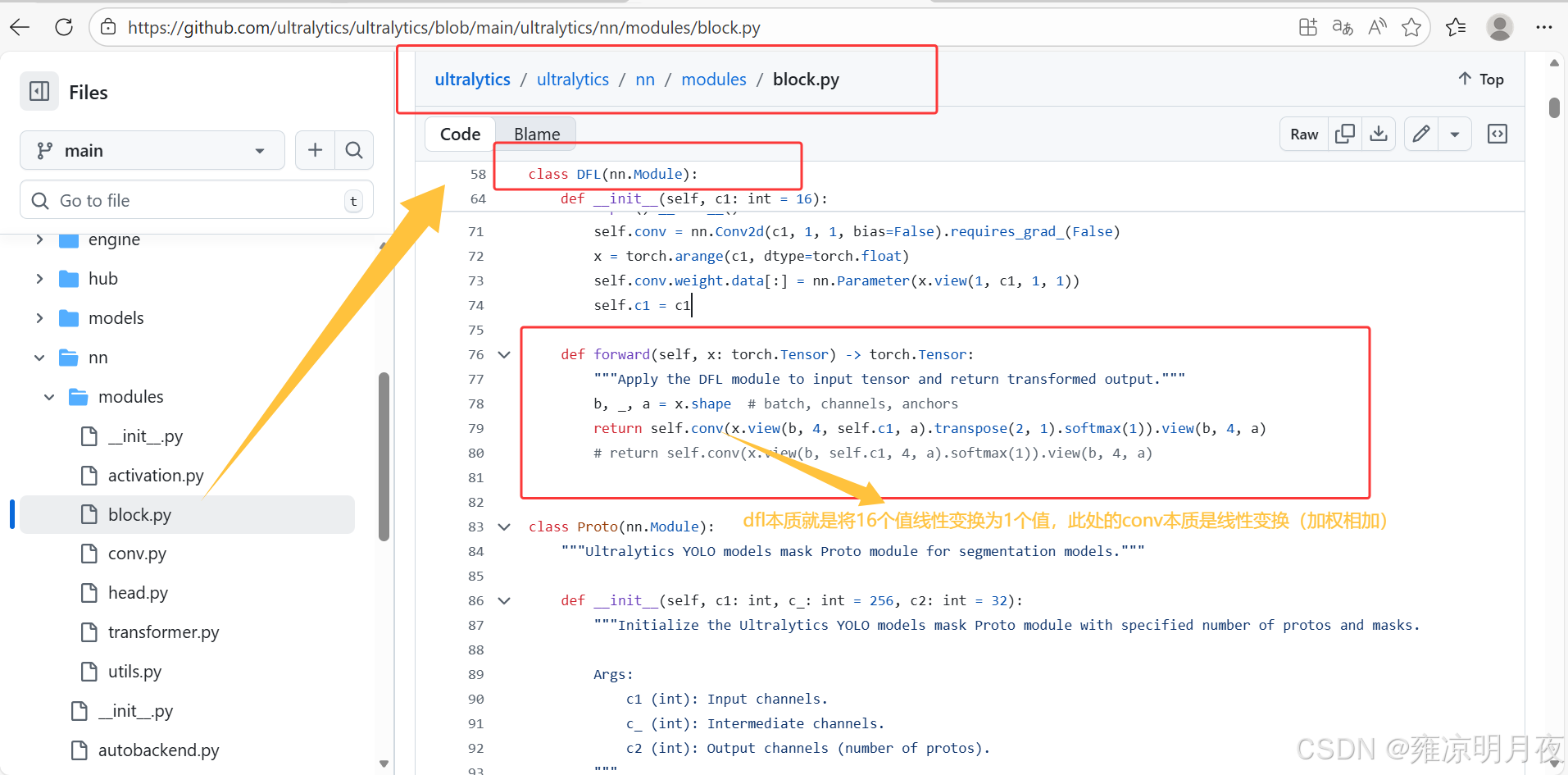
分类分支解码(框架内部):
Head原始输出(1×144×8400)的后80维是「分类原始特征值」
解码逻辑:
对80维特征值做Sigmoid归一化,得到0-1的类别概率(非互斥);
取最大值作为该框的置信度,最大值对应的索引为类别ID。
python
import torch
# ===================== 1. 模拟Head原始输出(1×144×8400) =====================
batch_size = 1
num_classes = 80 # COCO数据集
reg_max = 16 # YOLOv8默认reg_max
# Head原始输出:64维回归(4×16) + 80维分类 = 144维
pred_raw = torch.randn(batch_size, reg_max*4 + num_classes, 8400) # 1×144×8400
# ===================== 2. 生成8400个位置的网格坐标+步长 =====================
strides = torch.tensor([8, 16, 32]) # 80×80/40×40/20×20对应的步长
grid_sizes = [80, 40, 20] # 3个尺度的网格尺寸
grids = []
for i, (size, stride) in enumerate(zip(grid_sizes, strides)):
grid_y, grid_x = torch.meshgrid(torch.arange(size), torch.arange(size), indexing='ij')
grid = torch.stack([grid_x, grid_y], dim=-1).reshape(-1, 2) * stride # 乘以步长得到原图坐标
grids.append(grid)
grid_xy = torch.cat(grids, dim=0) # 8400×2 (x, y)
# ===================== 3. 回归分支解码(DFL) =====================
# 提取64维回归特征(4×16×8400),reshape为(4, 16, 8400)
reg_pred = pred_raw[:, :reg_max*4, :].reshape(batch_size, 4, reg_max, -1) # 1×4×16×8400
# 步骤3.1:生成DFL候选值(0~15)
range_tensor = torch.arange(reg_max, device=reg_pred.device) # [0,1,...,15]
# 步骤3.2:对每个坐标的16个bin做softmax,得到权重
reg_softmax = torch.softmax(reg_pred, dim=2) # 1×4×16×8400
# 步骤3.3:加权求和得到偏移量dx, dy, dw, dh(4×8400)
dxdy_dwdh = torch.matmul(reg_softmax, range_tensor).squeeze(0) # 4×8400
# 步骤3.4:计算实际坐标(x/y/w/h)
# 按尺度分配步长(8400个框对应8/16/32步长)
stride_tensor = strides.repeat_interleave([80*80, 40*40, 20*20]) # 8400×1
x = grid_xy[:, 0] + torch.sigmoid(dxdy_dwdh[0]) # grid_xy已乘步长,无需重复乘
y = grid_xy[:, 1] + torch.sigmoid(dxdy_dwdh[1])
w = torch.exp(dxdy_dwdh[2]) * stride_tensor
h = torch.exp(dxdy_dwdh[3]) * stride_tensor
# 转成xyxy格式(最终84维的前4维)
x1 = x - w / 2
y1 = y - h / 2
x2 = x + w / 2
y2 = y + h / 2
boxes_xyxy = torch.stack([x1, y1, x2, y2], dim=-1) # 8400×4(xyxy绝对坐标)
# ===================== 4. 分类分支解码 =====================
# 提取80维分类特征,做Sigmoid得到类别概率
cls_pred = pred_raw[:, reg_max*4:, :] # 1×80×8400
cls_probs = torch.sigmoid(cls_pred).squeeze(0).T # 8400×80(0~1的类别概率)
# 计算置信度和类别ID
confidence = cls_probs.max(dim=1)[0] # 8400×1(每个框的最高置信度)
class_ids = cls_probs.max(dim=1)[1] # 8400×1(每个框的类别ID)
# ===================== 5. 拼接成解码后的84维Tensor(1×84×8400) =====================
# 前4维:xyxy坐标;后80维:类别概率
pred_decoded = torch.cat([boxes_xyxy.T, cls_probs.T], dim=0).unsqueeze(0) # 1×84×8400
# ===================== 6. 解码结果输出 =====================
print("解码后的84维Tensor形状:", pred_decoded.shape) # torch.Size([1, 84, 8400])
print("解码后的检测框坐标(前5个):\n", boxes_xyxy[:5])
print("解码后的类别概率(第一个框前5类):\n", cls_probs[0, :5])
print("解码后的置信度(前5个):\n", confidence[:5])
print("解码后的类别ID(前5个):\n", class_ids[:5])
# 注:官方输出的1×84×8400就是上述pred_decoded,无需再做任何解码,直接用于后处理(NMS)。核心原理:
**训练阶段:**Detect 头输出3 个尺度的 list(1,144,80,80/40,40/20,20) → 分尺度计算总损失【分类损失(Focal Loss) + 回归损失(DFL损失 + CIoU损失)】;
**推理阶段:**Detect头输出3个尺度的list(1,144,80,80/40,40/20,20)→ 框架内部拼接展平(1×144×8400)→ 内部解码(DFL转坐标 + Sigmoid转类别概率)→ 官方默认输出1×84×8400 Tensor → 取类别概率最大值作为置信度 → 后处理(NMS);
注:DFL 解码直接得到 dx/dy/dw/dh 偏移量 → 先转 xywh(中心坐标 + 宽高) → 再转 ltrb(可选) → 最终转 xyxy;官方输出的 84 维前 4 维已是 xyxy 绝对坐标。
2.YOLOv8 Detect 后处理
基于上述解码完成后得到 8400 个框(包含大量低置信度 / 重复框),下一步就是非极大值抑制(NMS)
python
# 后处理核心目标:过滤低置信度框 + 去除重复框(NMS)
conf_thres = 0.25 # 低置信度阈值(低于此值的框直接丢弃)
iou_thres = 0.45 # NMS的IoU阈值(高于此值的重复框仅保留最高分)
# 1. 过滤低置信度框(关键:boxes需用解码后的xyxy格式)
mask = confidence > conf_thres
boxes_filtered = boxes_xyxy[mask] # 用boxes_xyxy(而非boxes),对应前面解码的xyxy坐标
cls_probs_filtered = cls_probs[mask]
confidence_filtered = confidence[mask]
class_ids_filtered = class_ids[mask]
# 2. 执行NMS(注:YOLOv8实际用batched_nms,支持多类别;以下是简化版单类别NMS)
# 关键要求:boxes_filtered必须是xyxy格式,且与confidence_filtered数据类型一致(如float32)
boxes_filtered = boxes_filtered.float() # 补充:确保数据类型正确
confidence_filtered = confidence_filtered.float()
indices = torch.ops.torchvision.nms(boxes_filtered, confidence_filtered, iou_thres)
# 3. 最终有效框(仅保留NMS筛选后的结果)
final_boxes = boxes_filtered[indices]
final_conf = confidence_filtered[indices]
final_cls = class_ids_filtered[indices]
print("\nNMS后剩余的有效框数量:", len(final_boxes))
print("最终有效框坐标:\n", final_boxes)3.推理阶段的总结+知识补充
| 阶段 | 输入 | 输出 | 关键说明 |
|---|---|---|---|
| Detect Head(推理) | 3 个尺度特征图 | 1×84×8400(4+80 维) | 框架自动完成 "前向传播 + 拼接展平 + 解码",输出为解码后的结果:4 个 xyxy 绝对坐标 + 80 个 Sigmoid 类别概率;144 维原始特征仅出现在训练阶段,对用户不可见 |
| 后处理(NMS) | 1×84×8400(xyxy + 概率) | 少量有效框(如 10×4+10×1) | 取 80 类概率的最大值作为置信度,过滤低置信度框,再做 NMS 去重,保留高置信度、非重复框 |
重点知识补充:IOU系列和DFL和Focal Loss的区别和联系
- 三者均为目标检测训练阶段的损失组件,推理阶段均不参与,最终模型总损失 = **BCEWithLogitsLoss(YOLOv8默认分类损失,等价于Sigmoid+BCE)** + 加权系数 ×(CIoU + DFL)(回归)
- IoU 系列与 DFL 为回归分支强协同关系,无互斥性,二者结合实现 "精准找坐标(DFL)+ 标准画框(IoU)" 的 1+1>2 效果。
- Focal Loss 与 IoU/DFL 为任务分工关系,分别负责 "认对目标" 和 "框准目标",共同支撑模型检测性能。
训练阶段的 DFL(DFL Loss)+ CIoU,和推理阶段解码中的 DFL,虽然都基于「DFL 离散分布」的核心思想,但作用、场景、目标完全不同。
维度 训练阶段(DFL Loss + CIoU) 推理阶段(解码中的 DFL) 核心作用 约束模型学习,让模型输出的离散分布逼近真实值 还原连续坐标,把模型输出的特征值转成实际偏移量 场景 反向传播,计算损失值(标量),更新模型参数 正向推理,纯计算(无参数更新),生成检测框 输入 模型输出的 **144 维中 64 维 DFL 特征**(4×16) + 真实框坐标 模型输出的 **144 维中 64 维 DFL 特征**(4×16)(框架内部处理,用户不可见) 输出 损失值(标量,用于反向传播) 连续偏移量 dx/dy/dw/dh(用于计算实际框坐标) 与 CIoU 的关系 CIoU 是主回归损失,DFL Loss 是辅助优化 无 CIoU 参与,纯 DFL 解码逻辑
本质差异:
- 训练 DFL:是「损失函数」,作用是 "约束模型学习"(反向传播);
- 推理 DFL:是「解码逻辑」,作用是 "还原连续坐标"(正向计算);
小小的注意点:
我们团队在实验过程中发现有两种不同的情况,在阈值都一样的情况下输出的结果有些许不同,经过分析后发现不同的数据前处理过程的算法也会造成不同的影响。我们最后分析得到最有可能的情况是resize使用的算法不同(Pil算法和Cv2算法)导致其结果不同。

YOLOv8前向传播源码解析
总共两个逻辑
1.YOLOv8.yaml->self.model
2.For self.model
YOLOv8的前向传播算子的yolov8.yaml文件,每一层的算子意义是:
输入来源索引, 重复次数, 算子类别, 模块参数
第一个值(如
-1、6、4) :这不是 "输入通道",而是输入来源的层索引 。-1表示直接来自上一层;6表示来自配置文件中第 6 层的输出;[15,18,21]表示来自第 15、18、21 层的多输入。⭐第二个值(如
1、3) :这是模块的重复次数(循环次数) 比如3代表这个模块会被连续执行 3 次。(注意:不同的算子其第二个值含义不一样,普通算子确实是模块执行次数,而像c2f等特殊算子:parse_model 会只创建 1 个 C2f 模块,但把第二个值3传入 C2f 的初始化参数,作为其内部 bottleneck 的数量。)第三个值(如
nn.Upsample、C2f、Concat、Detect) :这是算子 / 模块的类别第四个值(如
[None, 2, "nearest"]、[512]、[1]、[nc]) :这是模块的参数列表 ,不是统一的 "输出通道"。
- 对
C2f、Conv这类卷积模块,参数里的数字是输出通道数(如[512]代表输出通道为 512)。- 对
nn.Upsample,参数是上采样倍数和插值方式(如[None, 2, "nearest"]代表 2 倍上采样,用 nearest 插值)。- 对
Concat,参数是拼接维度(如[1]代表在通道维度拼接)。- 对
Detect,参数是类别数[nc]。
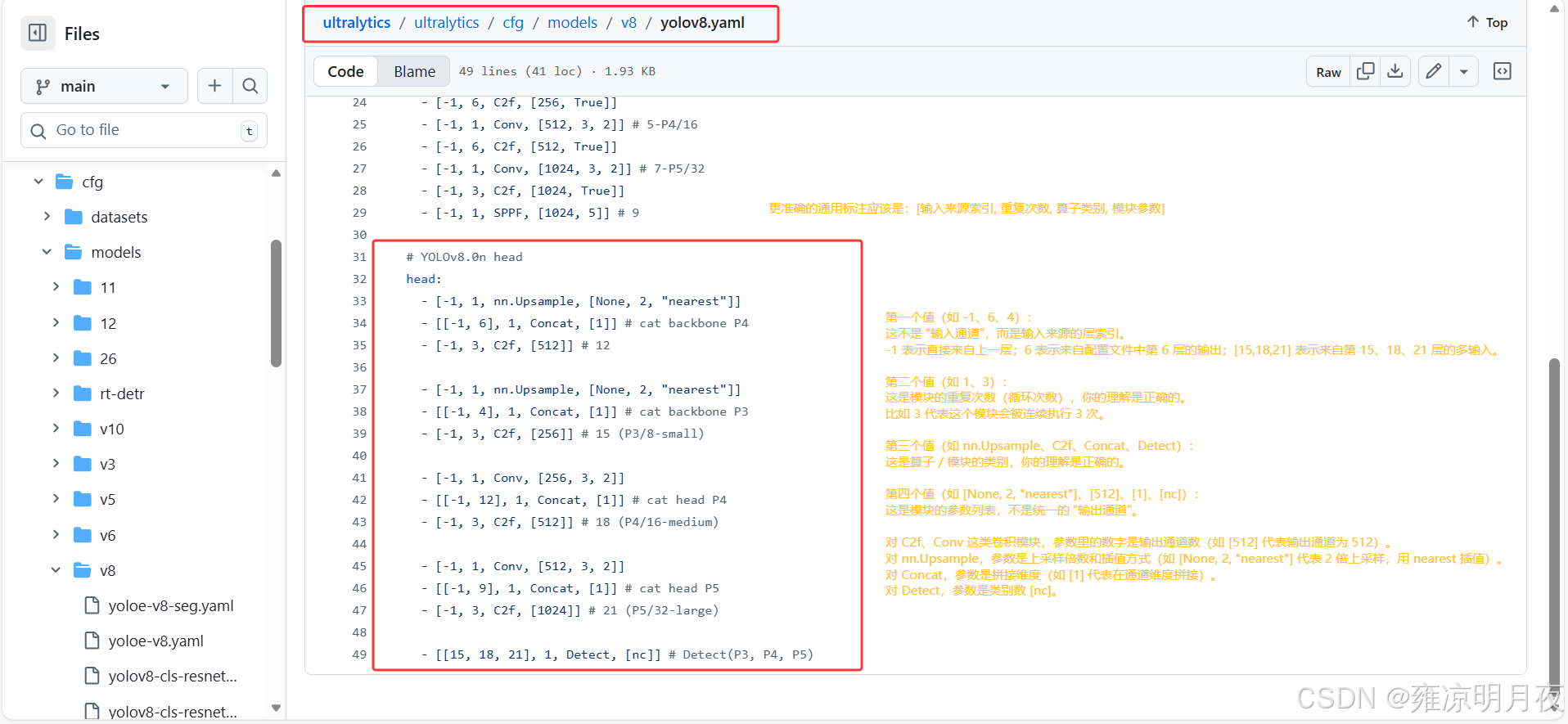
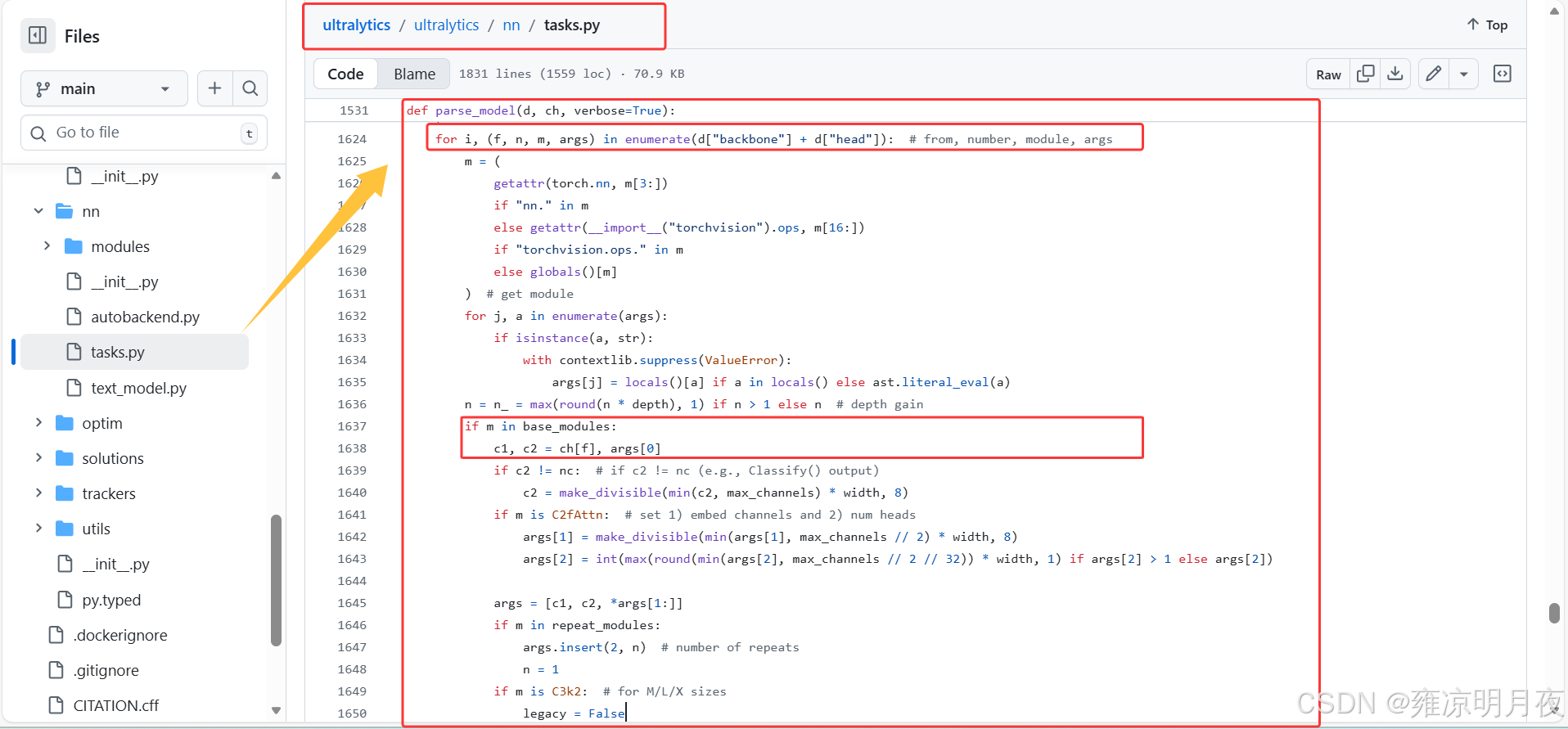
1.YOLOv8.yaml->self.model
该阶段属于模型构建阶段:
- 加载 YOLOv8.yaml 配置文件 → 转成字典格式
- 调用
parse_model函数 → 把 yaml 字典解析成nn.Module列表- 赋值给
self.model→ 完成 "yaml→self.model"
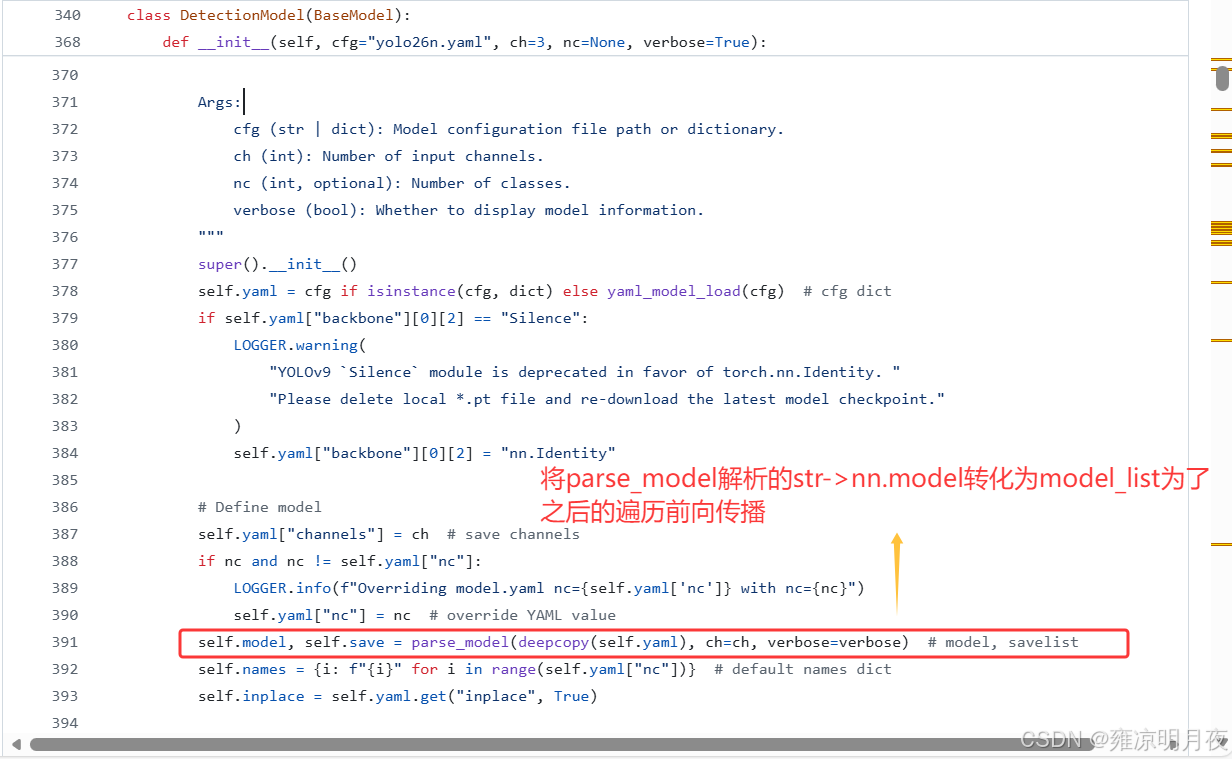
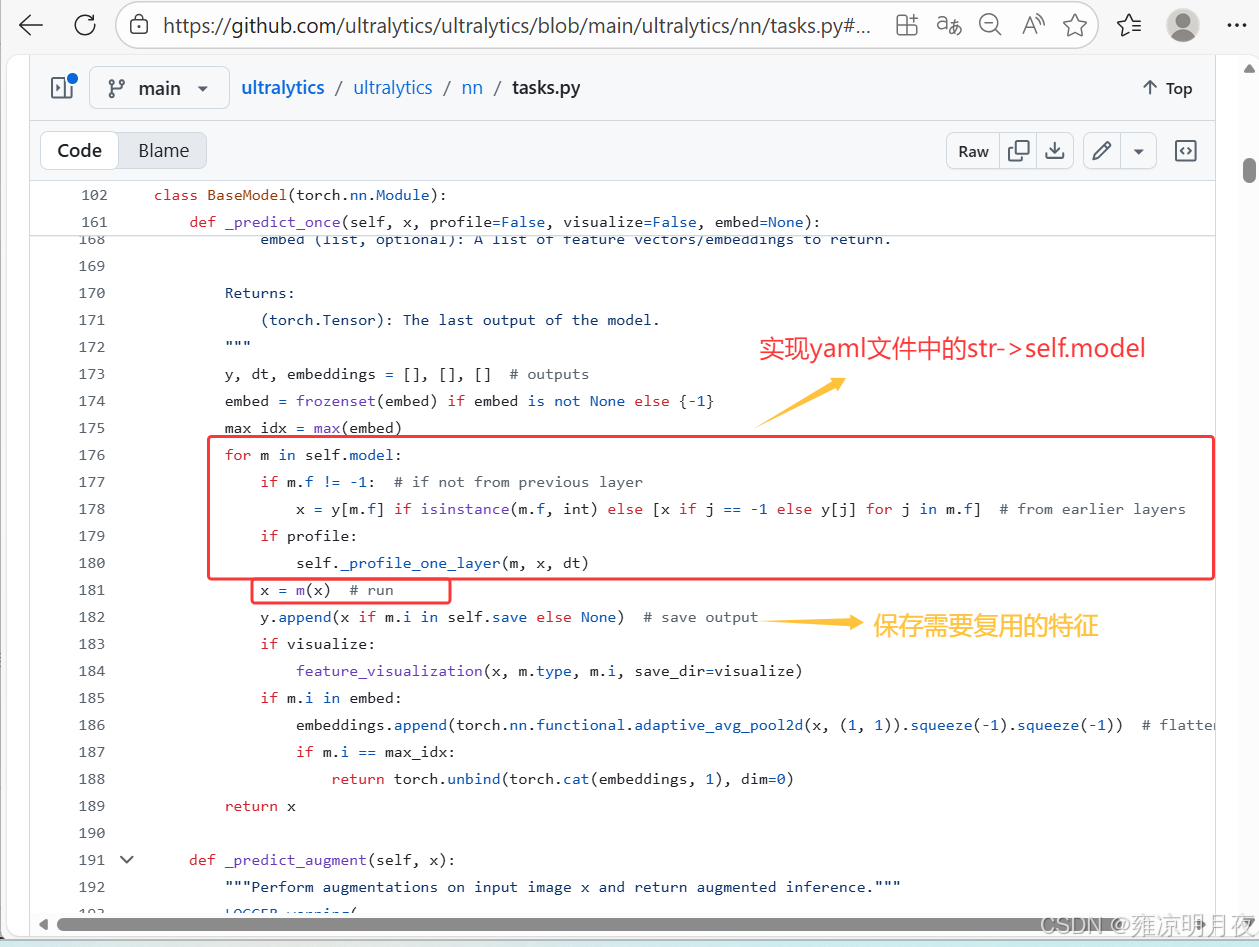
2.For self.model
前向传播阶段 :你图中的这段代码(
_predict_once/_forward_once方法),是遍历已经构建好的self.model模块列表,逐层执行前向计算
小小注意点:如果不指定相应的参数则其默认执行n模型
YOLOv8正样本选择+损失函数解析
我们的核心目的是训练神经网络找到所需的预测框 Pre_box,好的网络效果是 Pre_box 和图像中真实的 gt_box 一致或误差极小,此时网络收敛、效果最优。
YOLOv8 的网络输出为 1×84×8400,其输出并非简单的 Pre_box 坐标,而是包含坐标预测、类别预测、置信度预测的融合特征,只有框回归、分类、置信度三类损失均收敛,Pre_box 才是 "又准又对" 的。因此正样本的选择尤为重要,YOLOv5 与 YOLOv8 的正样本选择及损失函数设计差异显著,核心总结如下:
1. 正样本的选择差异
知识回顾:YOLOv5(Anchor-Based + 静态匹配)
YOLOv5 的前向传播结果是 1×85×25200:
- 特征层:3 个尺度(80×80、40×40、20×20);
- 锚框设计:每个特征层的每个网格点预设 3 个锚框(anchor);
- 总预测框数:80×80×3 + 40×40×3 + 20×20×3 = 25200;
- 维度含义:85 = 4(坐标)+ 1(独立置信度)+ 80(COCO 类别)。
YOLOv5 的正样本选择(静态锚框匹配):
- 先将 gt_box 的宽高与预设锚框的宽高计算比值,匹配 "最接近" 的锚框,锁定锚框类型;
- 找到 gt_box 中心点落在的网格点,该网格点的匹配锚框为核心正样本;
- 为增加正样本比例加快收敛,将该网格点上下左右相邻网格点(通常 3 个)的同类型锚框也作为正样本;
- 最终每个 gt_box 匹配多个预测框 作为正样本,核心是人为增加样本数量。
YOLOv8(Anchor-Free + 动态匹配,核心:TAL 任务对齐分配器)
核心修改:Anchor-free + 动态匹配,输出维度与正样本选择逻辑完全重构。
(1)YOLOv8 的输出维度(1×84×8400)
- 特征层:与 v5 一致,3 个尺度(80×80、40×40、20×20);
- 无锚框设计:每个网格点仅预测 1 个框,无需预设锚框;
- 总预测框数:80×80×1 + 40×40×1 + 20×20×1 = 8400;
- 维度含义:84 = 4(坐标)+ 80(COCO 类别),置信度融合到分类分支,无独立维度;
- 补充:框回归的 Box 分支实际输出64 通道(4 坐标维度 ×16 个离散锚点),为 DFL 离散分布预测做准备。
(2)YOLOv8 的正样本选择(粗筛→精选→确认,三层动态匹配)
并非直接全局 IoU 匹配,而是以 Task-Aligned Assigner(TAL)为核心的最优匹配,步骤如下:
步骤 1:初选(粗筛候选框,减少计算量)
- 目标:快速排除无关预测框,仅保留 "有潜力" 的候选;
- 操作:筛选出中心点落在 gt_box 内部的 Pre_box 作为候选样本;
- 逻辑:中心不在 gt_box 内的 Pre_box 大概率是背景,无需参与后续精细匹配。
步骤 2:复选(TAL 任务对齐,精选 top-K 最优候选)
核心筛选环节,结合分类 + 定位双维度评分,避免单维度最优的无效样本:
- 计算对齐分数:对齐分数分类置信度(默认 α=1,β=6);
- 分类置信度:Pre_box 预测对应 gt 类别的概率;
- IoU:Pre_box 与 gt_box 的重叠度;
- 筛选 top-K 候选:对每个 gt_box,按对齐分数排序,取前 K 个(默认 K=10)作为 "准正样本";
- 冲突处理:若 1 个 Pre_box 被多个 gt_box 选中,仅保留与该 Pre_box IoU 最大的匹配关系。
步骤 3:全局 IoU 双向匹配(最终确认正样本)
基于复选后的候选框,通过 IoU 矩阵完成精准匹配:
- 构建 IoU 矩阵:行 = gt_box,列 = 候选 Pre_box,值 = 两者 IoU;
- 单向匹配:
- 按行找最大:每个 gt_box 选该行 IoU 最大的 Pre_box(gt 的 "最优匹配框");
- 按列找最大:每个 Pre_box 选该列 IoU 最大的 gt_box(Pre_box 的 "最优匹配 gt");
- 双向匹配:仅当 "gt 选的 Pre_box,恰好也选了该 gt" 时,该 Pre_box 才定为该 gt 的正样本;
- 兜底规则:若某个 gt 的最大 IoU 低于阈值(如 0.2),直接选取 gt 中心点所在特征层网格对应的 Pre_box 作为正样本,避免无匹配。
2. 损失函数(YOLOv8:多任务加权求和,与正样本强绑定)
YOLOv8 的损失函数为多任务损失的加权求和,核心目标是让预测框坐标贴近 gt、类别预测准确、能精准区分前景 / 背景,最终通过最小化总损失推动网络收敛。
总损失公式
TotalLoss = λbox × (CIoULoss+DFLLoss) + λcls×ClassLoss + λobj×ObjLoss
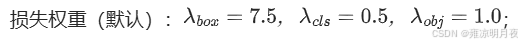
- 核心规则:仅正样本参与 BoxLoss 和 ClassLoss 计算,所有 8400 个预测框参与 ObjLoss 计算。
(1)BoxLoss(框回归损失):CIoU Loss + DFL Loss(二者权重均为 1)
YOLOv8 的框回归为离散分布预测,DFL 与 CIoU 协同工作,过程监督 + 结果监督双重保障:
- CIoU Loss :结果监督,衡量预测框与 gt_box 的重叠度、中心点距离、长宽比偏差,让预测框整体贴合 gt;
- DFL Loss(分布焦点损失) :过程监督,监督框坐标的离散分布预测,让模型更精准回归框的边界坐标;
YOLOv8 框回归完整流程(DFL+CIoU):
- 网络输出 Box 分支特征(64 通道):4 坐标维度 ×16 个离散锚点;
- 对 Box 分支做 softmax,得到 16 个锚点的概率分布(和为 1);
- 计算分布的数学期望,得到最终的预测坐标(x1/y1/x2/y2);
- 计算 DFL Loss:用真实坐标构建二值离散标签,监督预测分布与真实标签的偏差;
- 计算 CIoU Loss:用步骤 3 的最终预测坐标,与 gt_box 计算 CIoU Loss;
- 求和得到 BoxLoss:BoxLoss=CIoULoss+DFLLoss。
(2)ClassLoss(分类损失):BCEWithLogitsLoss
- 核心原理:采用带 sigmoid 激活的二元交叉熵损失,适配多标签分类逻辑,数值稳定性更高;
- 计算对象:仅正样本,预测类别概率(未激活)vs 真实类别 one-hot 编码;
- 公式:BCELoss=−y×log(p)+(1−y)×log(1−p)(y=1 为真实类别,p 为预测概率)。
(3)ObjLoss(置信度损失):BCEWithLogitsLoss
- 核心原理:YOLOv8 无独立置信度分支,取分类分支所有类别概率的最大值作为置信度预测值,本质是区分 "有物体" 和 "无物体";
- 标签设计:正样本置信度标签 = 1,负样本 = 0;
- 计算对象:所有 8400 个预测框(正 + 负);
- 核心目标:让正样本置信度趋近 1,负样本趋近 0,避免模型预测大量无效空框。
知识补充:
1.YOLOv5 vs YOLOv8 核心差异
| 对比维度 | YOLOv5(Anchor-Based) | YOLOv8(Anchor-Free) |
|---|---|---|
| 匹配规则 | 静态:锚框匹配 + 相邻网格点(人为增样本) | 动态:初选 + TAL 复选 + 全局 IoU 双向匹配(数据选最优) |
| 正样本数量 | 每个 gt 匹配多个正样本(3 个左右) | 每个 gt 匹配 1 个最优正样本(少数兜底 1 个) |
| 输出维度 | 1×85×25200(3 特征层 × 每网格 3 锚框) | 1×84×8400(3 特征层 × 每网格 1 框) |
| BoxLoss 设计 | 单一 CIoU/MSE Loss(直接预测连续坐标) | CIoU Loss+DFL Loss(离散分布预测坐标) |
| 置信度分支 | 独立置信度分支(占 1 维) | 融合到分类分支(取类别概率最大值) |
| 核心目标 | 靠增加样本数量加快收敛 | 靠选 "分类 + 定位双优" 样本提升精度 |
| 核心优势 | 训练速度快,对固定宽高比目标适配性好 | 框回归精度高,对宽高比 / 尺度多变目标适配性好 |
适用场景选择
- 优先选 YOLOv5 :目标宽高比相对固定、对训练速度要求高、场景简单(如固定视角的目标检测);
- 优先选 YOLOv8 :目标宽高比多变、尺度差异大(如小目标 + 大目标混合)、对检测精度要求高、场景复杂(如户外通用目标检测)。
2.自定义数据增强
在yolo算法训练的过程中,数据增强是最常用的手段之一。现在补充一下自定义数据增强的方法。
1.新增增强类: 在
ultralytics/data/augment.py中实现你的自定义增强逻辑2.新增超参数: 在
hyp.yaml中添加增强的开关 / 权重参数3.集成到增强的流水线: 在
build_transforms中初始化并添加你的增强
案例:
1.新增增强类: 在 ultralytics/data/augment.py 中实现你的自定义增强逻辑
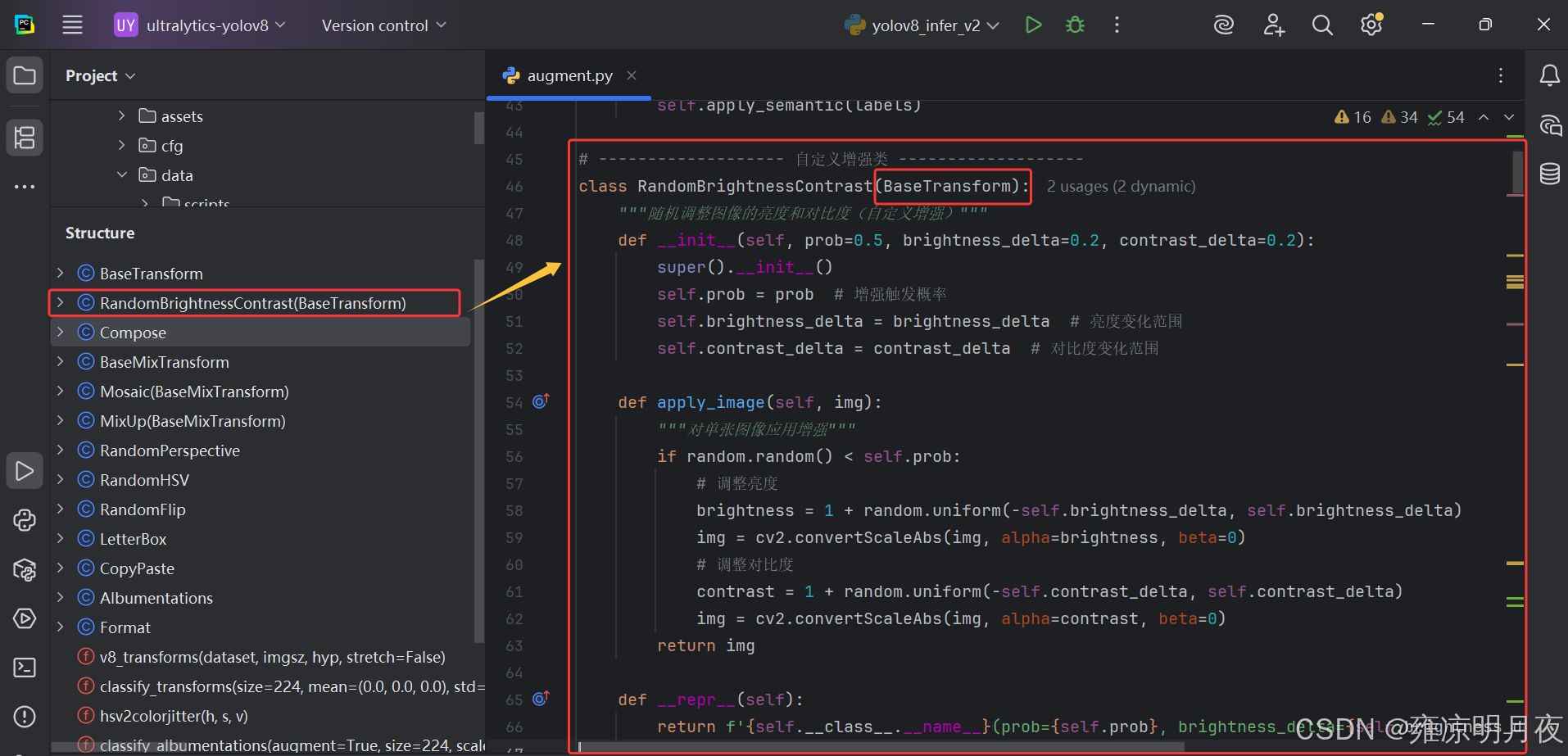
python
# ------------------- 自定义增强类 -------------------
class RandomBrightnessContrast(BaseTransform):
"""随机调整图像的亮度和对比度(自定义增强)"""
def __init__(self, prob=0.5, brightness_delta=0.2, contrast_delta=0.2):
super().__init__()
self.prob = prob # 增强触发概率
self.brightness_delta = brightness_delta # 亮度变化范围
self.contrast_delta = contrast_delta # 对比度变化范围
def apply_image(self, img):
"""对单张图像应用增强"""
if random.random() < self.prob:
# 调整亮度
brightness = 1 + random.uniform(-self.brightness_delta, self.brightness_delta)
img = cv2.convertScaleAbs(img, alpha=brightness, beta=0)
# 调整对比度
contrast = 1 + random.uniform(-self.contrast_delta, self.contrast_delta)
img = cv2.convertScaleAbs(img, alpha=contrast, beta=0)
return img
def __repr__(self):
return f'{self.__class__.__name__}(prob={self.prob}, brightness_delta={self.brightness_delta}, contrast_delta={self.contrast_delta})'2.新增超参数: 在 hyp.yaml 中添加增强的开关 / 权重参数
打开训练用的
hyp.yaml(通常在ultralytics/cfg/default.yaml或你的自定义配置文件),在augmentation部分添加。
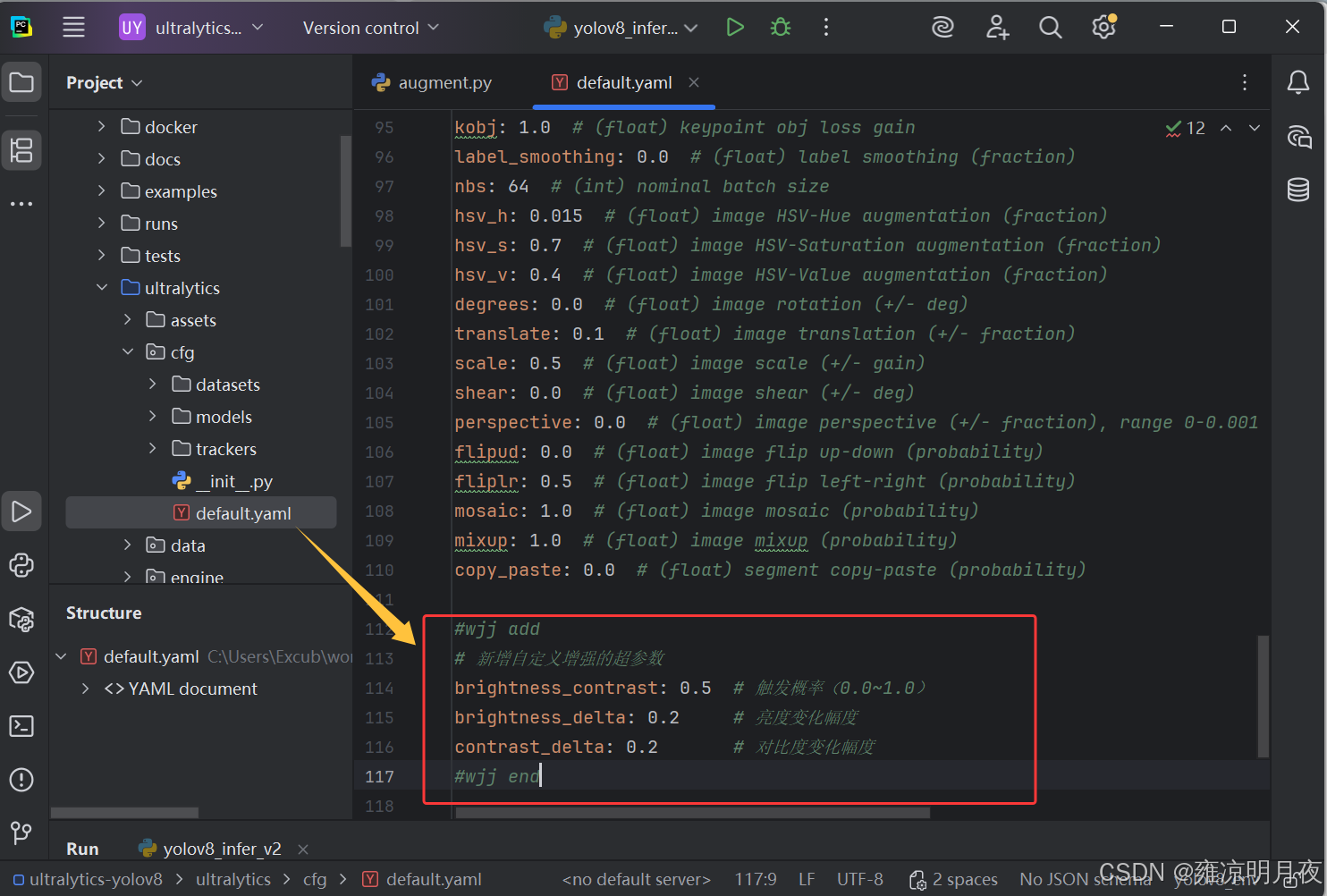
python
# 新增自定义增强的超参数
brightness_contrast: 0.5 # 触发概率(0.0~1.0)
brightness_delta: 0.2 # 亮度变化幅度
contrast_delta: 0.2 # 对比度变化幅度3.集成到增强的流水线: 在 build_transforms 中初始化并添加你的增强
python
# ------------------- 新增:添加自定义增强 -------------------
from .augment import RandomBrightnessContrast
if hyp.get('brightness_contrast', 0.0) > 0.0:
transforms.append(
RandomBrightnessContrast(
prob=hyp.brightness_contrast,
brightness_delta=hyp.get('brightness_delta', 0.2),
contrast_delta=hyp.get('contrast_delta', 0.2)
)
)
# ----------------------------------------------------------总结:
本章笔者主要总结了我学习yolov8时的一些知识笔记,和学习源码的一些小细节,以及一些小技巧,希望给大家带来帮助。