一、前言
在现在的日常工作、校园管理、企业员工关怀甚至社区服务里,心理健康已经不再是一个遥远、专业的话题,而是实实在在每天都要面对的需求。不管是企业想提前了解员工的精神压力状态,学校要对学生进行心理普查,还是个人想自我监测情绪变化,都需要一套科学、标准、好用的评估工具。
SCL-90 症状自评量表,就是目前国内最常用、最成熟、认可度最高的心理健康筛查量表之一。但传统方式要么是纸质填表、人工统计,效率低、容易出错;要么是简单的电子表单,只能算分,不能给出专业解读,普通人根本看不懂数据背后的意义。
为了解决这个痛点,我们把SCL-90 标准化量表、前端交互展示、后端自动计算、大模型智能分析整合在一起,做了一套真正能落地使用的心理评估系统。它既能保证量表的专业性和规范性,又能让用户在做完评估后,立刻拿到清晰、通俗、有指导意义的分析报告。

二、核心基础
1. SCL-90 症状自评量表
1.1 SCL-90 核心概念
SCL-90 症状自评量表(Symptom Checklist 90)是由最成熟、认可度最高的心理健康测评工具,包含 90 个项目,涵盖:
- **9个核心因子:**躯体化、强迫症状、人际关系敏感、抑郁、焦虑、敌对、恐怖、偏执、精神病性;
- **1个附加因子:**睡眠饮食。
每个项目采用 5 级评分制(1 = 无,2 = 轻度,3 = 中度,4 = 偏重,5 = 严重),通过量化评分反映测试者的心理症状分布与严重程度。
1.2 SCL-90 的应用价值
- 临床诊断辅助:精神科医生快速筛查患者症状类型与严重程度
- 心理健康普查:企业、学校等群体心理健康状况评估
- 干预效果跟踪:心理治疗前后症状变化对比分析
- 科研数据采集:心理健康相关研究的标准化数据来源
1.3 SCL-90 评分规则说明
- **1. 因子分计算:**每个因子包含若干项目,如躯体化包含 1、4、12、27、40、42、48、49、52、53、56、58 共 12 项,因子分 = 该因子所有项目得分之和/项目数
- **2. 总症状指数:**所有90项得分之和/90
- **3. 阳性项目数:**得分≥2 的项目数量,反映有症状的项目占比
- **4. 阳性症状均分:**阳性项目得分之和/阳性项目数,反映症状平均严重程度
1.4 SCL-90 评分计算原理
1.4.1 因子分计算:
其中:
为第 i 个因子的得分,
1.4.2 总症状指数:
其中: 为第 k 个项目的得分
1.4.3 阳性项目数与均分
其中:I(⋅)为指示函数,条件满足时为 1,否则为 0
1.5 SCL-90 成人常模数据
| 因子 | 常模均值 ± 标准差 | 因子 | 常模均值 ± 标准差 |
|---|---|---|---|
| 躯体化 | 1.37±0.48 | 焦虑 | 1.39±0.43 |
| 强迫症状 | 1.62±0.58 | 敌对 | 1.46±0.55 |
| 人际关系敏感 | 1.65±0.61 | 恐怖 | 1.23±0.41 |
| 抑郁 | 1.50±0.59 | 偏执 | 1.43±0.57 |
| 精神病性 | 1.29±0.42 | 睡眠饮食 | 1.48±0.55 |
对比逻辑:
- 得分>均值 + 1 个标准差:轻度异常,需关注
- 得分>均值 + 2 个标准差:中度异常,建议专业咨询
- 得分>均值 + 3 个标准差:重度异常,建议临床评估
2. 大模型在心理评估中的应用
2.1 大模型核心概念
大模型是基于 Transformer 架构、通过海量文本数据训练的深度学习模型,具备自然语言理解、自然语言生成、知识推理等能力。在心理评估场景中,大模型可实现:
- 结构化量表数据的自然语言解读
- 个性化的评估结果分析与建议生成
- 专业心理学术语的通俗化转换
- 多维度的症状模式识别与风险预警
2.2 心理评估场景下技术体现
-
- 上下文理解能力:结合 SCL-90 各因子间的关联性,分析症状背后的心理机制
-
- 领域适配能力:通过心理学科研文献、临床指南微调,提升专业分析准确性
-
- 生成可控性:确保输出内容符合心理评估伦理规范,避免误导性结论
-
- 解释性:清晰说明评估结论的依据,增强用户对分析结果的理解
3. 基础技术架构
3.1 前端技术基础
- HTML5:构建量表展示的结构化页面,实现 90 个评估项目的有序呈现
- CSS3/TailwindCSS:设计符合心理评估场景的视觉界面,保证操作舒适性
- JavaScript/Vue3:实现量表评分的交互逻辑、数据校验与结果提交
- ECharts:可视化展示各因子得分分布、与常模数据的对比分析
3.2 后端、大模型交互技术
- Python FastAPI:构建前后端交互的 API 接口,处理量表数据接收与校验
- OpenAI API、国产大模型 API:实现评估数据的专业分析请求与结果返回
- 数据存储:使用 SQLite/MySQL 存储评估记录,支持历史数据对比分析
- 数据安全:实现用户评估数据的加密存储与访问权限控制
4. 大模型分析的基础原理
4.1 提示词工程原理
有效的 SCL-90 分析提示词需包含:
- 角色定义:"你是一名资深临床心理学家,擅长使用 SCL-90 量表进行心理评估分析"
- **数据输入:**结构化的因子得分、常模对比结果、用户基本信息
- 分析要求:"基于提供的 SCL-90 评估数据,按照以下维度进行分析:①各因子得分解读 ②症状模式分析 ③可能的心理状态评估 ④个性化建议 ⑤专业帮助指引"
- 输出格式:"使用通俗易懂的语言,分点说明,避免专业术语堆砌,结论需客观中立,不做确诊性判断"
- 伦理约束:"不提供药物建议,不做精神疾病诊断,所有分析仅供参考,最终需以专业医师诊断为准"
4.2 大模型响应生成原理
- **语义理解:**解析输入的结构化数据,识别关键得分信息与异常指标
- 知识检索:从训练数据中调取 SCL-90 相关的专业知识与临床解读规则
- 逻辑推理:分析各因子间的关联性,如抑郁与焦虑的共现性
- **自然语言生成:**按照提示词要求,生成结构清晰、专业且易懂的分析内容
- **质量控制:**检查输出内容是否符合伦理规范,是否存在误导性表述
三、整体执行流程
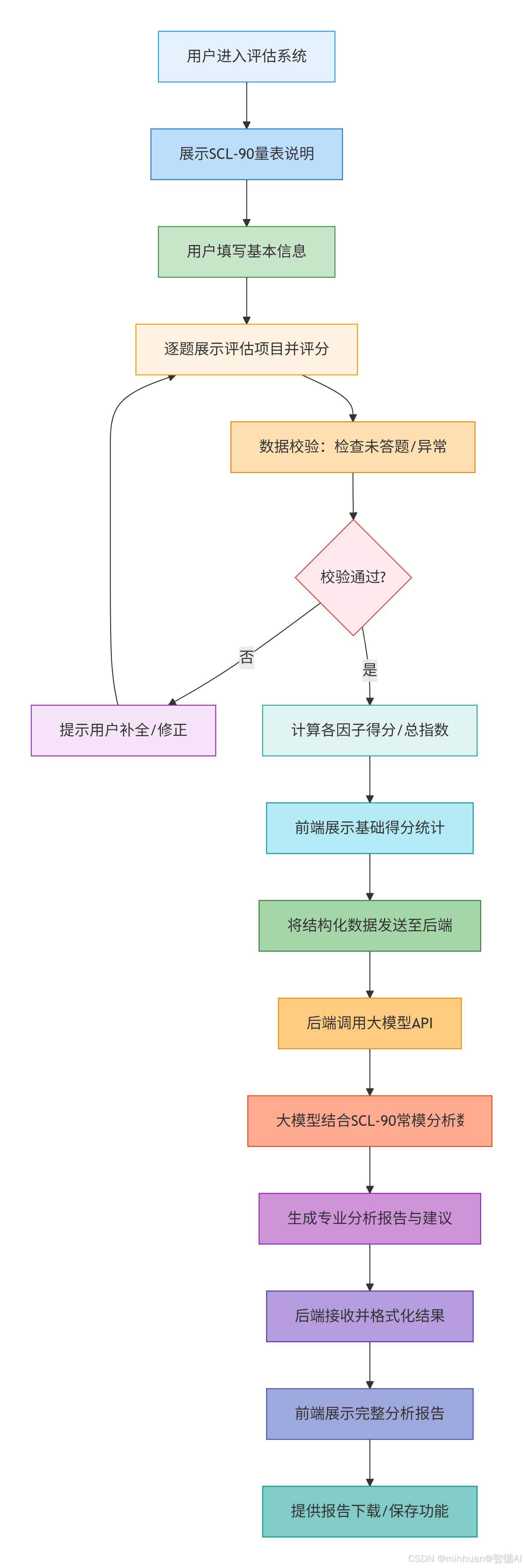
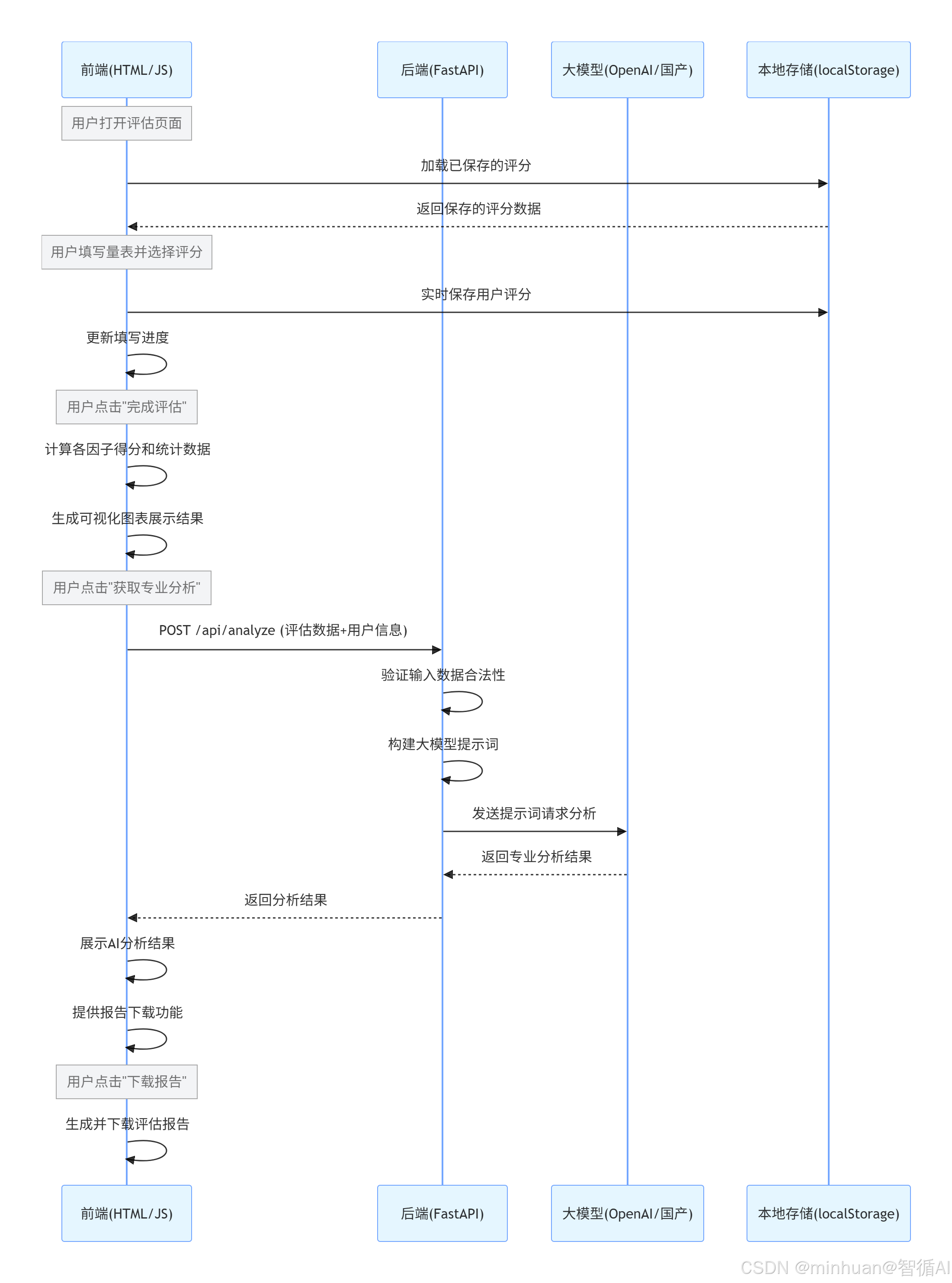
流程重要环节详细说明:
- 1. 量表填写环节
- 分页展示 90 个评估项目,每屏展示 10 题,降低用户填写压力
- 实时保存已填写答案,防止页面刷新导致数据丢失
- 提供 "暂存" 功能,支持用户分多次完成评估
- 填写进度可视化,显示已完成、剩余题目数量
- 2. 数据计算环节
- 前端实时计算因子分,确保数据准确性
- 内置 SCL-90 常模数据,前端可实时对比展示
- 异常值检测:识别得分过高、过低的因子,标记需重点关注的维度
- 3. 大模型分析环节
- 数据格式化:将原始得分转换为大模型易理解的结构化描述
- 提示词工程:构建专业的心理评估分析提示词,引导大模型输出规范内容
- 结果后处理:对大模型输出进行结构化解析,提取核心结论与建议
- 多轮交互:支持用户针对评估结果向大模型提问,获取进一步解答
四、系统实现
1. 前端界面实现
示例代码是一个完整的、单文件的 SCL-90 症状自评量表Web前端应用。集成了问卷展示、本地存储、统计计算、数据可视化(ECharts)以及完整的AI分析功能,我们拆解其中的几个核心功能模块讲解主要逻辑;
1.1 核心数据配置模块
作用:定义量表的骨架。包含90道题目、10个心理因子的题目索引映射、以及用于对比的中国成人常模数据。这是所有计算的基础。
html
// **************************
// 核心数据定义
// **************************
// SCL-90题目数据(完整版90题)
// 结构:content(题目内容), factor(所属心理因子)
const SCL90_QUESTIONS = [
{ content: '头痛', factor: '躯体化' },
{ content: '神经过敏,心中不踏实', factor: '焦虑' },
{ content: '头脑中有不必要的想法或字句盘旋', factor: '强迫症状' },
// ... (此处省略中间题目,实际代码包含90条)
{ content: '感到自己的脑子有毛病', factor: '精神病性' }
];
// 因子配置(各因子对应的题目索引)
// 关键逻辑:SCL-90的每个因子由特定的题目组成,这里通过数组索引精确映射
const FACTOR_CONFIG = {
'躯体化': [0, 3, 8, 11, 38, 40, 45, 47, 50, 52, 53, 71],
'强迫症状': [2, 9, 37, 44, 46, 60],
'人际关系敏感': [5, 20, 34, 36, 37, 41, 65, 79],
'抑郁': [4, 13, 14, 19, 25, 29, 30, 31, 32, 42, 54, 59, 66, 68, 77],
'焦虑': [1, 16, 22, 33, 55, 57, 72, 74, 78],
'敌对': [7, 10, 23, 58, 61, 63, 75],
'恐怖': [12, 24, 33, 47, 51, 64, 70, 76],
'偏执': [6, 18, 21, 43, 62, 73, 80],
'精神病性': [15, 35, 49, 56, 67, 81, 83],
'睡眠饮食': [44, 59, 60, 61]
};
// 中国成人常模数据
// 用途:在图表中作为"标准线"与用户得分进行对比,判断是否异常
const NORM_DATA = {
'躯体化': 1.37,
'强迫症状': 1.62,
'人际关系敏感': 1.65,
'抑郁': 1.50,
'焦虑': 1.39,
'敌对': 1.46,
'恐怖': 1.23,
'偏执': 1.43,
'精神病性': 1.29
};
// 全局状态变量
let userScores = new Array(90).fill(null); // 存储用户每题的得分 (1-5)
let assessmentResult = null; // 存储计算后的最终结果重点说明:
- FACTOR_CONFIG 是最关键的映射表。SCL-90 的算法不是简单的总分,而是看特定维度的平均分。例如,"抑郁"因子只计算第 5, 14, 15... 题的平均分。
- NORM_DATA 提供了心理学统计学的基准线。如果用户得分显著高于此数值,通常意味着存在该方面的心理困扰。
1.2 界面初始化与交互模块
作用:负责将数据渲染为 HTML,监听用户点击,并利用 localStorage 实现断点续测,刷新页面也不会丢失进度。
html
// 初始化题目展示
function initQuestions() {
const container = document.getElementById('questions-container');
SCL90_QUESTIONS.forEach((question, index) => {
const questionDiv = document.createElement('div');
questionDiv.className = 'question-container';
// 动态生成每一题的HTML结构:题目文本 + 5个评分按钮
questionDiv.innerHTML = `
<div class="question-title">${index + 1}. ${question.content}</div>
<div class="score-options">
<button class="score-btn" data-score="1" data-index="${index}">1分 - 无</button>
<button class="score-btn" data-score="2" data-index="${index}">2分 - 轻度</button>
<button class="score-btn" data-score="3" data-index="${index}">3分 - 中度</button>
<button class="score-btn" data-score="4" data-index="${index}">4分 - 偏重</button>
<button class="score-btn" data-score="5" data-index="${index}">5分 - 严重</button>
</div>
`;
container.appendChild(questionDiv);
// 【关键点】如果本地有保存的分数,恢复选中状态
if (userScores[index] !== null) {
const scoreBtn = questionDiv.querySelector(`.score-btn[data-score="${userScores[index]}"]`);
if (scoreBtn) scoreBtn.classList.add('selected');
}
});
}
// 保存评分到本地存储 (实现断点续测)
function saveScores() {
localStorage.setItem('scl90_user_scores', JSON.stringify(userScores));
}
// 加载本地存储的评分
function loadSavedScores() {
const saved = localStorage.getItem('scl90_user_scores');
if (saved) {
userScores = JSON.parse(saved);
updateProgress(); // 加载后更新进度条
}
}
// 更新进度显示与提交按钮状态
function updateProgress() {
const completed = userScores.filter(score => score !== null).length;
const progressText = document.getElementById('progress-text');
const submitBtn = document.getElementById('submit-btn');
progressText.textContent = `进度:${completed}/90`;
// 只有当90题全部做完,才激活"完成评估"按钮
if (completed === 90) {
submitBtn.classList.remove('btn-disabled');
submitBtn.classList.add('btn-primary');
submitBtn.disabled = false;
} else {
submitBtn.classList.add('btn-disabled');
submitBtn.classList.remove('btn-primary');
submitBtn.disabled = true;
}
}重点说明:
- 动态渲染:避免了写90遍重复的 HTML 代码,通过循环 SCL90_QUESTIONS 生成。
- 状态持久化:saveScores 和 loadSavedScores 利用浏览器本地存储。用户每选一个选项就保存一次,意外关闭网页后重新打开,进度和选择都在。
- 防错机制:updateProgress 强制要求完成所有 90 题才能提交,防止数据不完整导致计算错误。
1.3 统计算法核心模块
作用:执行 SCL-90 的标准计分规则,计算因子分、总分、阳性项目数等关键指标。
html
// 计算评估结果
function calculateResults() {
// 1. 计算各因子得分
const factorScores = {};
Object.keys(FACTOR_CONFIG).forEach(factor => {
const indices = FACTOR_CONFIG[factor];
// 过滤掉"睡眠饮食"等非标准核心因子(根据具体需求可选)
if (['睡眠饮食'].includes(factor)) return;
// 核心算法:(该因子下所有题目得分之和) / 题目数量
const sum = indices.reduce((total, index) => {
return total + (userScores[index] || 0);
}, 0);
factorScores[factor] = (sum / indices.length).toFixed(2); // 保留两位小数
});
// 2. 计算总症状指数 (Global Severity Index)
// 公式:所有90题得分总和 / 90
const totalSum = userScores.reduce((sum, score) => sum + score, 0);
const totalIndex = (totalSum / 90).toFixed(2);
// 3. 计算阳性项目数和均分
// 阳性项目:得分 >= 2 的题目(表示有症状)
const positiveScores = userScores.filter(score => score >= 2);
const positiveCount = positiveScores.length;
// 阳性症状均分:阳性项目的平均分
const positiveMean = positiveCount > 0
? (positiveScores.reduce((sum, score) => sum + score, 0) / positiveCount).toFixed(2)
: '0.00';
// 组装结果对象
assessmentResult = {
factorScores,
totalIndex,
positiveCount,
positiveMean,
rawScores: userScores
};
// 将结果也存入本地,方便后续查看
localStorage.setItem('scl90_assessment_result', JSON.stringify(assessmentResult));
// 触发结果展示
showResults();
}重点说明:
- 因子分计算:这是 SCL-90 的核心。它不是看总分,而是看"躯体化"、"抑郁"等维度的平均分。如果某因子分 > 2(或超过常模),则提示该维度可能存在心理问题。
- 阳性指标:positiveCount 告诉用户有多少个项目出现了症状(哪怕很轻),positiveMean 反映了这些症状的平均严重程度。
- 数据清洗:使用 .toFixed(2) 确保显示的专业性和美观度。
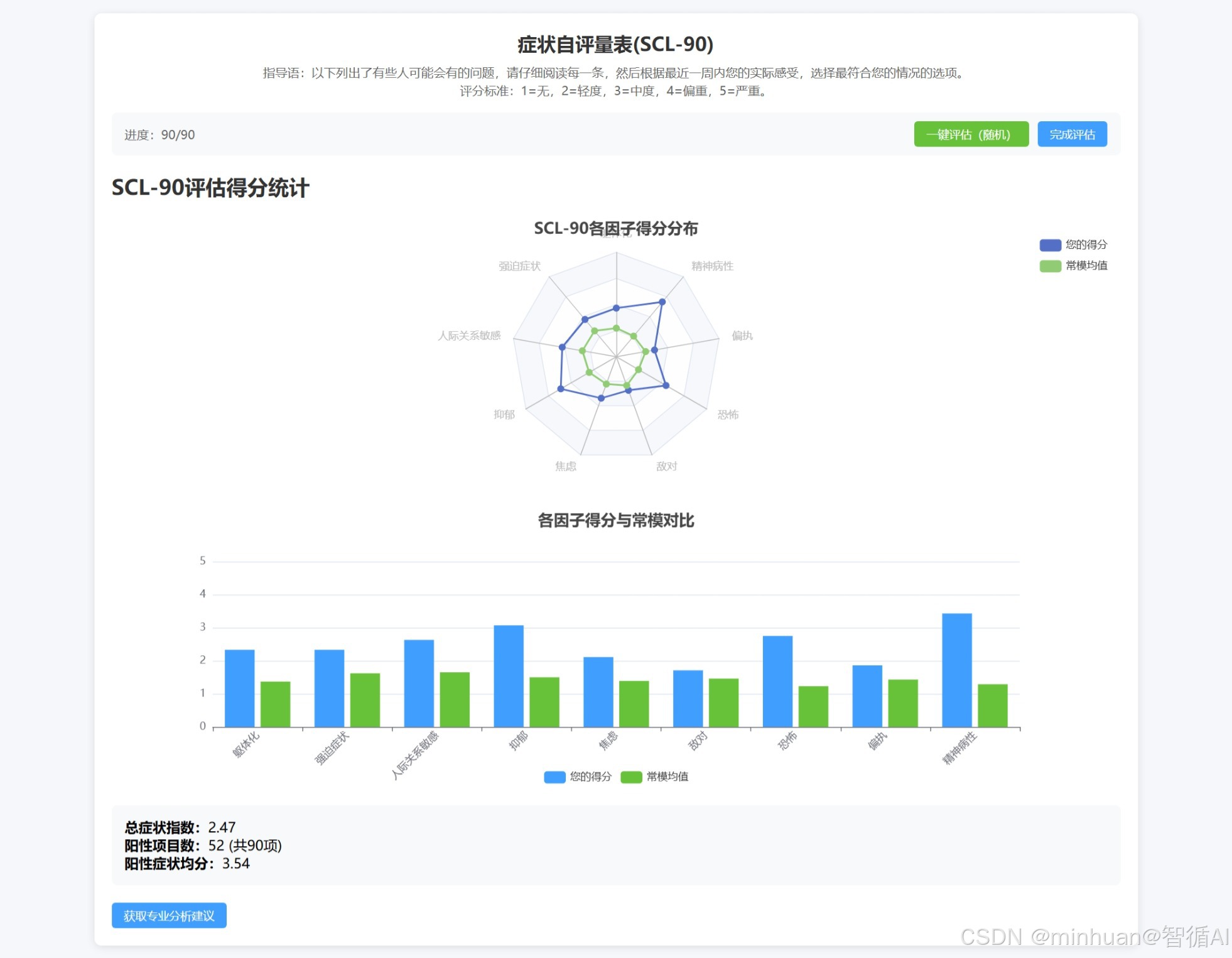
1.4 数据可视化模块 (ECharts)
作用:将枯燥的数字转化为直观的雷达图和柱状图,对比用户得分与常模。
html
// 初始化可视化图表
function initCharts() {
// 1. 雷达图 (Radar Chart) - 多维度能力/状态分析
const radarChart = echarts.init(document.getElementById('radar-chart'));
const factorNames = Object.keys(assessmentResult.factorScores);
// 提取用户得分和常模得分,转为数字数组
const userFactorScores = factorNames.map(factor => parseFloat(assessmentResult.factorScores[factor]));
const normFactorScores = factorNames.map(factor => NORM_DATA[factor] || 0);
radarChart.setOption({
title: { text: 'SCL-90各因子得分分布', left: 'center' },
tooltip: { trigger: 'item' },
legend: { orient: 'vertical', right: 10, top: 20 },
radar: {
// 动态生成雷达图的顶点(每个因子一个顶点)
indicator: factorNames.map(name => ({ name, max: 5 })),
shape: 'polygon',
splitNumber: 4
},
series: [{
name: '得分对比',
type: 'radar',
data: [
{ value: userFactorScores, name: '您的得分', itemStyle: { color: '#409eff' } },
{ value: normFactorScores, name: '常模均值', itemStyle: { color: '#67c23a' } }
]
}]
});
// 2. 柱状图 (Bar Chart) - 直观对比高低
const barChart = echarts.init(document.getElementById('bar-chart'));
barChart.setOption({
title: { text: '各因子得分与常模对比', left: 'center' },
tooltip: { trigger: 'axis' },
legend: { data: ['您的得分', '常模均值'], bottom: 0 },
xAxis: {
type: 'category',
data: factorNames,
axisLabel: { rotate: 45 } // 标签倾斜防止重叠
},
yAxis: { type: 'value', min: 0, max: 5 },
series: [
{
name: '您的得分',
type: 'bar',
data: userFactorScores,
itemStyle: { color: '#409eff' }
},
{
name: '常模均值',
type: 'bar',
data: normFactorScores,
itemStyle: { color: '#67c23a' }
}
]
});
// 响应式处理:窗口大小改变时重绘图表
window.addEventListener('resize', function() {
radarChart.resize();
barChart.resize();
});
}重点说明:
- 双图联动:雷达图适合看整体轮廓,标记哪里突出,柱状图适合精确对比数值高低。
- 常模对比:代码中将 userFactorScores 和 normFactorScores 放在同一个系列中,用户一眼就能看出自己的得分(蓝色)是否超过了标准线(绿色)。
- 自适应:resize 监听确保了在手机旋转屏幕或调整浏览器窗口时,图表不会变形。
1.5 AI 分析与报告导出模块
作用:模拟后端交互获取专业建议,并允许用户下载报告文件。
html
// 获取AI分析结果,调用后端 API
function getAIAnalysis() {
const loading = document.querySelector('.loading');
const analysisSection = document.getElementById('analysis-section');
loading.style.display = 'block'; // 显示加载中
// 构造发送给后端的数据包
const requestData = {
data: assessmentResult, // 包含所有计算好的分数
userInfo: {
age: 30,
gender: '未知',
occupation: '未知'
}
};
// 发送 POST 请求
fetch('http://localhost:8000/api/analyze', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(requestData)
})
.then(response => {
if (!response.ok) throw new Error('请求失败');
return response.json();
})
.then(data => {
loading.style.display = 'none';
analysisSection.style.display = 'block';
// 【关键点】使用 marked 库将后端返回的 Markdown 文本解析为 HTML
const analysisContent = document.getElementById('analysis-content');
analysisContent.innerHTML = marked.parse(data.analysis);
})
.catch(error => {
loading.style.display = 'none';
showToast('获取分析结果失败:' + error.message, 'error');
console.error('Error:', error);
});
}
// 下载评估报告
function downloadReport() {
const analysisContent = document.getElementById('analysis-content').textContent;
// 拼接报告文本
let reportContent = `
症状自评量表(SCL-90)评估报告
==============================
生成时间:${new Date().toLocaleString()}
一、基础评估数据
总症状指数:${assessmentResult.totalIndex}
阳性项目数:${assessmentResult.positiveCount} (共90项)
阳性症状均分:${assessmentResult.positiveMean}
二、各因子得分
${Object.entries(assessmentResult.factorScores).map(([factor, score]) => `${factor}:${score}`).join('\n')}
三、专业分析与建议
${analysisContent}
------------------------------
重要提示:本报告仅为参考,不能替代专业医师的诊断。
`;
// 创建 Blob 对象并触发下载
const blob = new Blob([reportContent], { type: 'text/plain;charset=utf-8' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = `SCL-90评估报告_${new Date().toLocaleDateString()}.txt`;
a.click();
URL.revokeObjectURL(url); // 释放内存
}重点说明:
- 前后端分离模拟:getAIAnalysis 展示了标准的前端请求流程:构造 JSON -> fetch 发送 -> 接收 JSON -> 解析 Markdown。实际使用时只需替换 URL 即可接入真实的 AI 服务。
- Markdown 渲染:利用 marked.parse() 将后端返回的结构化文本(如 ## 建议, - 列表)直接转换成漂亮的 HTML 样式,无需前端硬编码分析逻辑。
- 文件生成:downloadReport 使用 Blob 技术在前端直接生成文件,无需服务器参与,保护用户隐私且响应速度快。
前端页面展示效果:
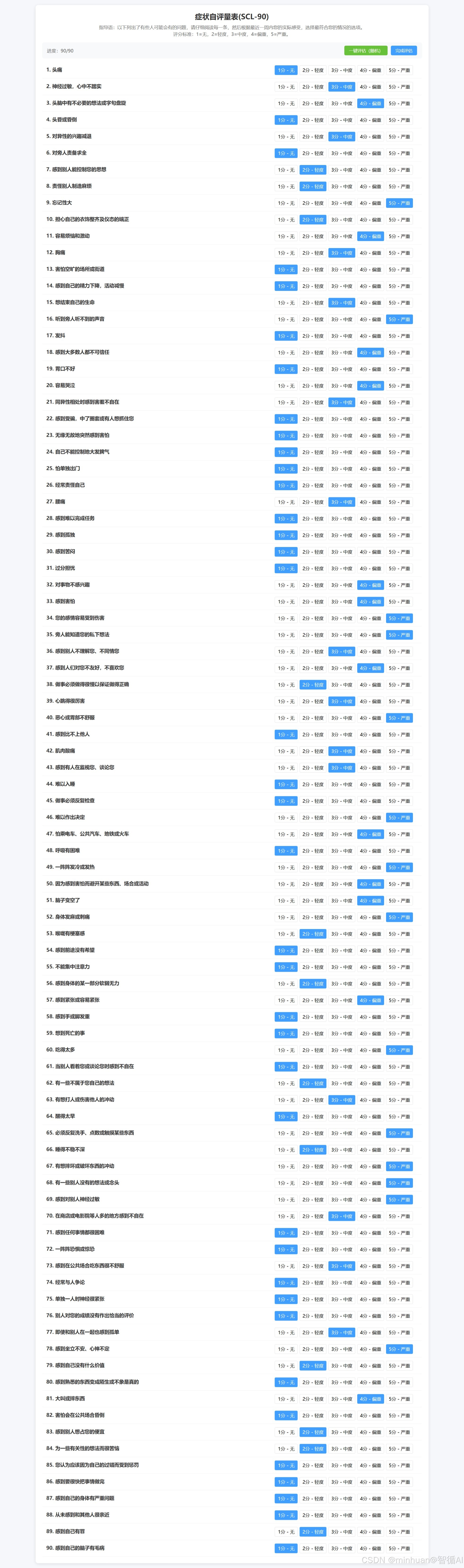
自适应适配移动端显示:
评估完成后结果展示:
调用大模型获取专业建议:
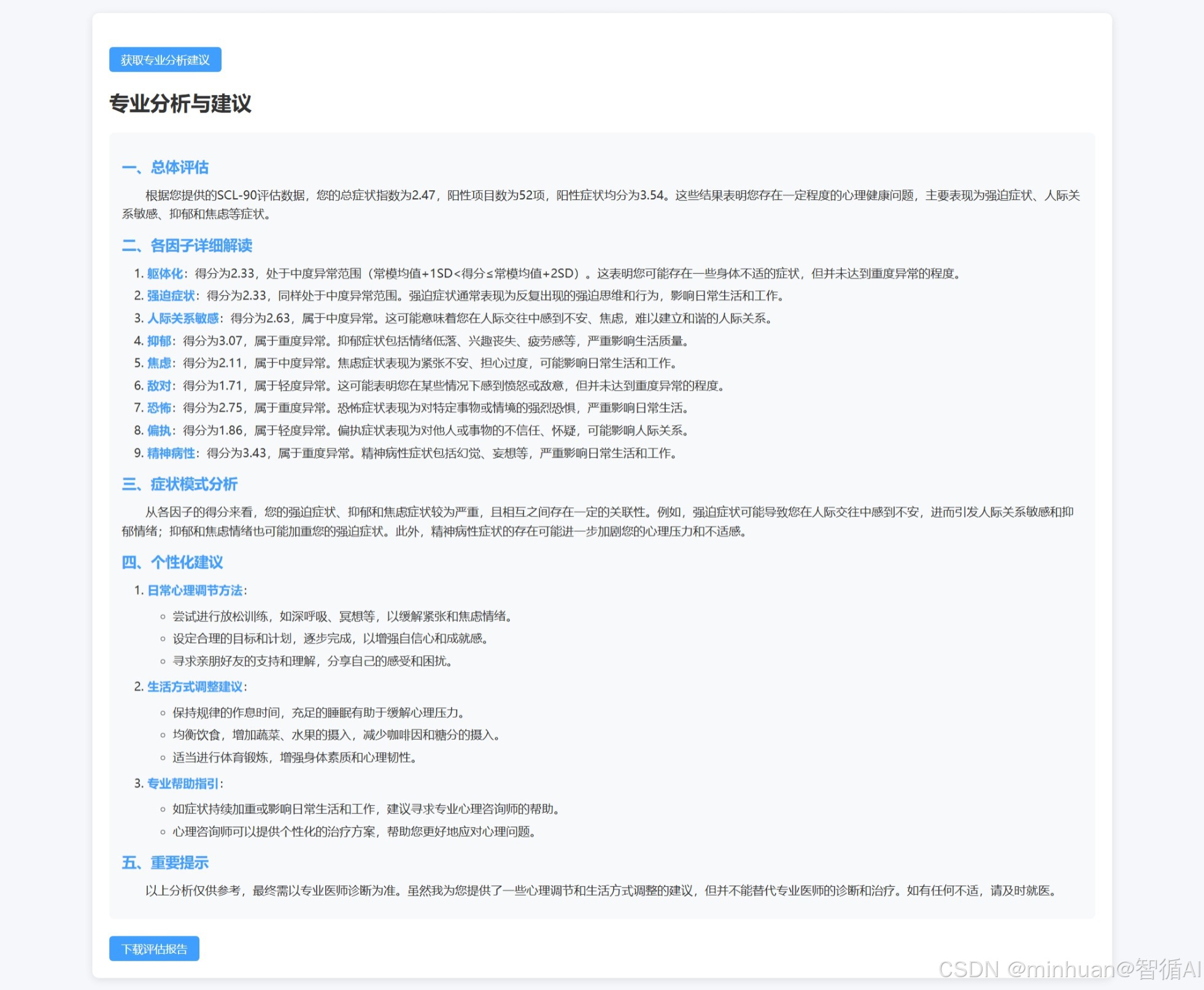
2. 后端API实现
后端代码构建了一个基于 FastAPI 和 腾讯混元大模型 的 SCL-90 心理评估分析后端服务。它接收前端的评分数据,结合心理学常模进行预处理,然后调用 AI 生成个性化的专业报告。
2.1 基础架构与数据模型定义
作用:搭建 Web 服务框架,配置跨域访问CORS,并严格定义前后端交互的数据结构Pydantic Models,确保数据类型的准确性和安全性。
python
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, Field
from openai import OpenAI
import os
from typing import Dict, List, Optional, Any
# ========================
# 初始化配置
# ========================
app = FastAPI(title="SCL-90评估分析API", version="1.0")
# 配置跨域(解决前端跨域问题,允许前端页面调用此 API)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境应指定具体域名,如 ["http://localhost:8080"]
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 配置腾讯混元大模型客户端
# 注意:实际部署时 API Key 应通过环境变量注入,不要硬编码
api_key = os.getenv("TENCENT_API_KEY", "sk-bWlJPKjB------e")
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1", # 腾讯混元兼容 OpenAI 协议
)
# ========================
# 数据模型定义 (Pydantic)
# ========================
class UserInfo(BaseModel):
"""用户基本信息模型"""
age: int = Field(..., description="用户年龄")
gender: str = Field(..., description="用户性别")
occupation: Optional[str] = Field(None, description="用户职业")
class FactorScores(BaseModel):
"""SCL-90 各因子得分模型,强制要求包含所有核心因子"""
躯体化: float = Field(..., description="躯体化因子得分")
强迫症状: float = Field(..., description="强迫症状因子得分")
人际关系敏感: float = Field(..., description="人际关系敏感因子得分")
抑郁: float = Field(..., description="抑郁因子得分")
焦虑: float = Field(..., description="焦虑因子得分")
敌对: float = Field(..., description="敌对因子得分")
恐怖: float = Field(..., description="恐怖因子得分")
偏执: float = Field(..., description="偏执因子得分")
精神病性: float = Field(..., description="精神病性因子得分")
class SCL90Data(BaseModel):
"""完整的 SCL-90 评估数据模型"""
factorScores: FactorScores = Field(..., description="各因子得分")
totalIndex: float = Field(..., description="总症状指数")
positiveCount: int = Field(..., description="阳性项目数")
positiveMean: float = Field(..., description="阳性症状均分")
rawScores: List[int] = Field(..., description="原始90题得分")
class AnalysisRequest(BaseModel):
"""API 请求体模型"""
data: SCL90Data = Field(..., description="SCL-90评估数据")
userInfo: UserInfo = Field(..., description="用户基本信息")重点说明:
- FastAPI + CORS:CORSMiddleware 是必须的,因为前端(通常在 8080 端口或本地文件)和后端(8000 端口)不同源,没有它浏览器会拦截请求。
- Pydantic 模型:BaseModel 不仅定义了数据结构,还自动完成了数据验证,例如确保 age 是整数,factorScores 必须包含所有指定的因子。如果前端传来的数据缺失或类型错误,API 会自动返回清晰的 422 错误,无需手动写 if/else 判断。
- OpenAI 兼容客户端:腾讯混元等大模型通常提供兼容 OpenAI 协议的接口,因此可以直接使用 openai 库,只需修改 base_url 和 api_key。
2.2 心理学逻辑与提示词工程
作用:这是系统的决策大脑。它不仅仅是把数据丢给 AI,而是先利用心理学常模(Norm Data)和标准差(SD)在本地计算出严重程度,然后将这些结构化信息组装成专业的 Prompt,引导 AI 生成高质量报告。
python
# ========================
# 核心常量 (心理学常模)
# ========================
NORM_DATA = {
"躯体化": 1.37, "强迫症状": 1.62, "人际关系敏感": 1.65,
"抑郁": 1.50, "焦虑": 1.39, "敌对": 1.46,
"恐怖": 1.23, "偏执": 1.43, "精神病性": 1.29
}
STD_DATA = {
"躯体化": 0.48, "强迫症状": 0.58, "人际关系敏感": 0.61,
"抑郁": 0.59, "焦虑": 0.43, "敌对": 0.55,
"恐怖": 0.41, "偏执": 0.57, "精神病性": 0.42
}
SEVERITY_LEVELS = {
"normal": "正常范围(得分≤常模均值)",
"mild": "轻度异常(常模均值<得分≤常模均值+1SD)",
"moderate": "中度异常(常模均值+1SD<得分≤常模均值+2SD)",
"severe": "重度异常(得分>常模均值+2SD)"
}
def get_severity_level(score: float, factor: str) -> str:
"""
【核心算法】根据常模和标准差判断严重程度
逻辑:得分 > 均值 + 2倍标准差 -> 重度; > 均值 + 1倍 -> 中度; 以此类推
"""
norm = NORM_DATA[factor]
std = STD_DATA[factor]
if score <= norm:
return SEVERITY_LEVELS["normal"]
elif score <= norm + std:
return SEVERITY_LEVELS["mild"]
elif score <= norm + 2*std:
return SEVERITY_LEVELS["moderate"]
else:
return SEVERITY_LEVELS["severe"]
def build_prompt(request: AnalysisRequest) -> str:
"""
【提示词构建】将数据转化为大模型能理解的专业指令
"""
factor_scores = request.data.factorScores.dict()
total_index = request.data.totalIndex
positive_count = request.data.positiveCount
user_info = request.userInfo
# 预计算异常因子列表,减少 AI 的幻觉风险
abnormal_factors = []
for factor, score in factor_scores.items():
severity = get_severity_level(score, factor)
if "异常" in severity:
abnormal_factors.append({
"name": factor, "score": score,
"norm": NORM_DATA[factor], "severity": severity
})
# 构建结构化 Prompt
prompt = f"""
你是一位资深的临床心理学家,拥有丰富的SCL-90量表解读经验。请根据以下用户的SCL-90评估数据,提供专业、客观、易懂的分析报告。
# 用户基本信息
- 年龄:{user_info.age}岁
- 性别:{user_info.gender}
- 职业:{user_info.occupation or '未填写'}
# 评估核心数据
1. 总症状指数:{total_index}(正常值参考范围:1.00-2.00)
2. 阳性项目数:{positive_count}项(共90项)
3. 阳性症状均分:{request.data.positiveMean}
# 各因子得分详情 (已结合中国成人常模计算)
{chr(10).join([f"- {factor}:{score}(常模均值:{NORM_DATA[factor]},{get_severity_level(score, factor)})"
for factor, score in factor_scores.items()])}
# 异常因子识别 (重点关注)
{chr(10).join([f"- {item['name']}:得分{item['score']},{item['severity']}" for item in abnormal_factors]) if len(abnormal_factors) > 0
else "未发现明显异常因子"}
# 分析要求
1. 语言风格:通俗易懂,避免过度术语,保持建设性态度。
2. 分析维度:总体状态、因子解读(重点分析异常)、症状关联模式、个性化建议。
3. 安全限制:**不做确诊性判断**,不提供药物建议,必须标注"仅供参考"。
# 输出格式 (Markdown)
## 一、总体评估
## 二、各因子详细解读
## 三、症状模式分析
## 四、个性化建议
## 五、重要提示
"""
return prompt重点说明:
- 统计学预处理:代码没有让 AI 自己去查常模,AI可能会记错或幻觉,而是先在 Python 层利用 NORM_DATA 和 STD_DATA 算出每个因子是"轻度"还是"重度"。这保证了分析的科学准确性。
- Prompt 结构化:通过 f-string 将计算好的严重程度直接填入 Prompt。明确告诉 AI 哪些是异常因子,让它集中精力分析这些问题,而不是泛泛而谈。
- 安全围栏:在 Prompt 中显式加入"不做确诊"、"不推荐药物"的指令,符合医疗伦理和合规要求。
2.3 大模型调用与降级策略
作用:负责与腾讯混元 API 通信,并设计了完善的异常处理机制。即使 AI 服务挂了或网络超时,系统也能返回一个基础的静态分析报告,保证用户体验不中断。
python
def call_llm(prompt: str) -> str:
"""
【LLM 调用】调用腾讯混元大模型,含异常降级处理
"""
try:
response = client.chat.completions.create(
model="hunyuan-lite", # 选择具体的模型版本
messages=[
{"role": "system", "content": "你是专业的临床心理学家,擅长SCL-90量表解读"},
{"role": "user", "content": prompt}
],
temperature=0.7, # 平衡创造性与稳定性
max_tokens=2000, # 限制输出长度,防止过长
timeout=30 # 30秒超时,防止长时间阻塞
)
return response.choices[0].message.content.strip()
except Exception as e:
# 【降级策略】当 AI 不可用时,返回基于规则的基礎分析
error_msg = f"大模型调用失败:{str(e)}"
print(error_msg)
# 注意:这里需要访问外部变量,实际生产中建议将数据作为参数传入
# 为演示逻辑,此处假设能访问到 request 中的数据 (实际代码需调整作用域或传参)
# 下面是一个简化的降级模板逻辑示意:
basic_analysis = f"""
## 一、总体评估
您的SCL-90总症状指数为 {request.data.totalIndex if 'request' in locals() else '未知'}。
由于智能分析服务暂时不可用,以下为基础数据解读:
## 二、各因子简要解读
系统检测到以下因子得分情况(基于常模对比):
(此处略去详细循环,实际会列出所有因子及之前计算的严重程度)
## 三、通用建议
1. 保持规律作息,避免熬夜。
2. 适度运动,如慢跑、瑜伽。
3. 若情绪困扰持续超过两周,请务必前往医院心理科就诊。
## 四、重要提示
当前为系统自动生成的基础报告,缺乏深度上下文分析。请以专业医师诊断为准。
"""
return basic_analysis重点说明:
- 异步与超时:设置 timeout=30 防止因网络波动导致接口一直挂起。
- Try-Except 降级:这是生产级代码的关键。如果模型调用接口报错,如 Key 过期、配额用完、网络断开,except 块会捕获异常,并返回一段硬编码的、基于规则的基础报告。
- 用户体验:用户不会看到红色的报错代码,而是依然能拿到一份虽然简单但包含核心数据和通用建议的报告,保证了服务的高可用性。
2.4 API 接口暴露与服务启动
作用:定义 HTTP 路由,进行最终的业务逻辑校验,并将结果返回给前端。同时包含服务启动入口。
python
# ========================
# API接口定义
# ========================
@app.post("/api/analyze", summary="分析SCL-90评估数据")
async def analyze_scl90(request: AnalysisRequest):
"""
主接口:接收数据 -> 校验 -> 构建Prompt -> 调用AI -> 返回结果
"""
try:
# 1. 业务逻辑校验 (Pydantic 已完成类型校验,此处做数值范围校验)
if not (1 <= request.data.totalIndex <= 5):
raise HTTPException(status_code=400, detail="总症状指数超出有效范围(1-5)")
if len(request.data.rawScores) != 90:
raise HTTPException(status_code=400, detail="原始得分数量必须为90项")
# 2. 构建提示词
prompt = build_prompt(request)
# 3. 调用大模型 (含降级逻辑)
analysis_result = call_llm(prompt)
# 4. 返回标准化响应
return {
"code": 200,
"message": "分析成功",
"analysis": analysis_result # Markdown 格式的文本
}
except HTTPException as e:
raise e # 透传业务错误
except Exception as e:
# 捕获未知错误,返回 500
raise HTTPException(status_code=500, detail=f"服务器内部错误:{str(e)}")
@app.get("/health", summary="健康检查")
async def health_check():
"""用于负载均衡器或监控系统检查服务状态"""
return {"status": "healthy", "service": "SCL-90 Analysis API", "version": "1.0"}
# ========================
# 主函数 (启动入口)
# ========================
if __name__ == "__main__":
import uvicorn
# 启动 Uvicorn 服务器
# host="0.0.0.0" 允许外部访问,port=8000 指定端口
uvicorn.run(
app="main:app", # 假设文件名为 main.py
host="0.0.0.0",
port=8000,
reload=True, # 开发模式下,代码修改自动重启
log_level="info"
)重点说明:
- 双重校验:虽然 Pydantic 校验了类型,但 analyze_scl90 函数内还校验了业务逻辑,如总分是否在 1-5 之间,题目数是否够 90 题,防止逻辑错误的数据进入 AI 流程。
- 标准化响应:返回统一的 JSON 格式 {code, message, analysis},方便前端统一处理成功和失败状态。
- Health Check:/health 接口是微服务架构的标准配置,用于 Docker 容器或云服务商判断服务是否存活。
- Uvicorn 启动:使用 uvicorn.run 直接启动 ASGI 服务器,reload=True 极大方便了开发调试。
服务启动:
3. 数据交互流程
3.1 完整交互流程图
3.2 数据格式说明
3.2.1 前端提交的数据格式
javascript
{
"data": {
"factorScores": {
"躯体化": 1.37,
"强迫症状": 1.62,
// ... 其他因子
},
"totalIndex": 1.45,
"positiveCount": 20,
"positiveMean": 2.10,
"rawScores": [1,2,1,2,...] // 90个评分
},
"userInfo": {
"age": 30,
"gender": "男",
"occupation": "程序员"
}
}3.2.2 后端返回的数据格式
javascript
{
"code": 200,
"message": "分析成功",
"analysis": "## 一、总体评估...(详细分析内容)"
}五、总结
咱们这套 SCL-90 心理评估项目,核心就是把专业的心理量表落地成能直接用、好用的系统,完美解决了传统评估效率低、解读难的痛点,再结合大模型做专业分析,从头到尾实现了全流程自动化。重点再后端接收前端提交的评分数据,先做数据校验,确保没错之后,就调用大模型生成专业分析报告。这里重点做了提示词优化,让大模型像专业心理医生一样,用通俗的话解读得分,还会给个性化的调节建议,不搞专业术语堆砌,普通人都能看明白。
实际应用里,不管是企业员工关怀、学校学生心理普查,还是个人自我情绪监测,这套系统都能直接用。不用人工统计、不用专业人员手动解读,既节省了人力成本,又让专业的心理评估变得普惠。而且还支持报告下载,方便留存和后续跟踪,安全性也做到位了,用户数据加密存储,隐私有保障。简单说,这是一套能直接落地、解决实际心理健康评估需求的完整方案,让专业心理服务变得更高效、更接地气。