大模型内部原理详解
一、从输入 Prompt 到输出 Token 的完整流程
- Tokenization(分词)
输入的句子首先进行 Tokenization,将句子切分为一个个 Token。 - Embedding 查表
通过 Embedding Table 矩阵(每一行对应一个 Token),将 Token 转换为对应的向量(Token Embedding)。
💡 注意:Embedding Table = LM Head(Unembedding 时使用的矩阵) - 多层神经网络处理
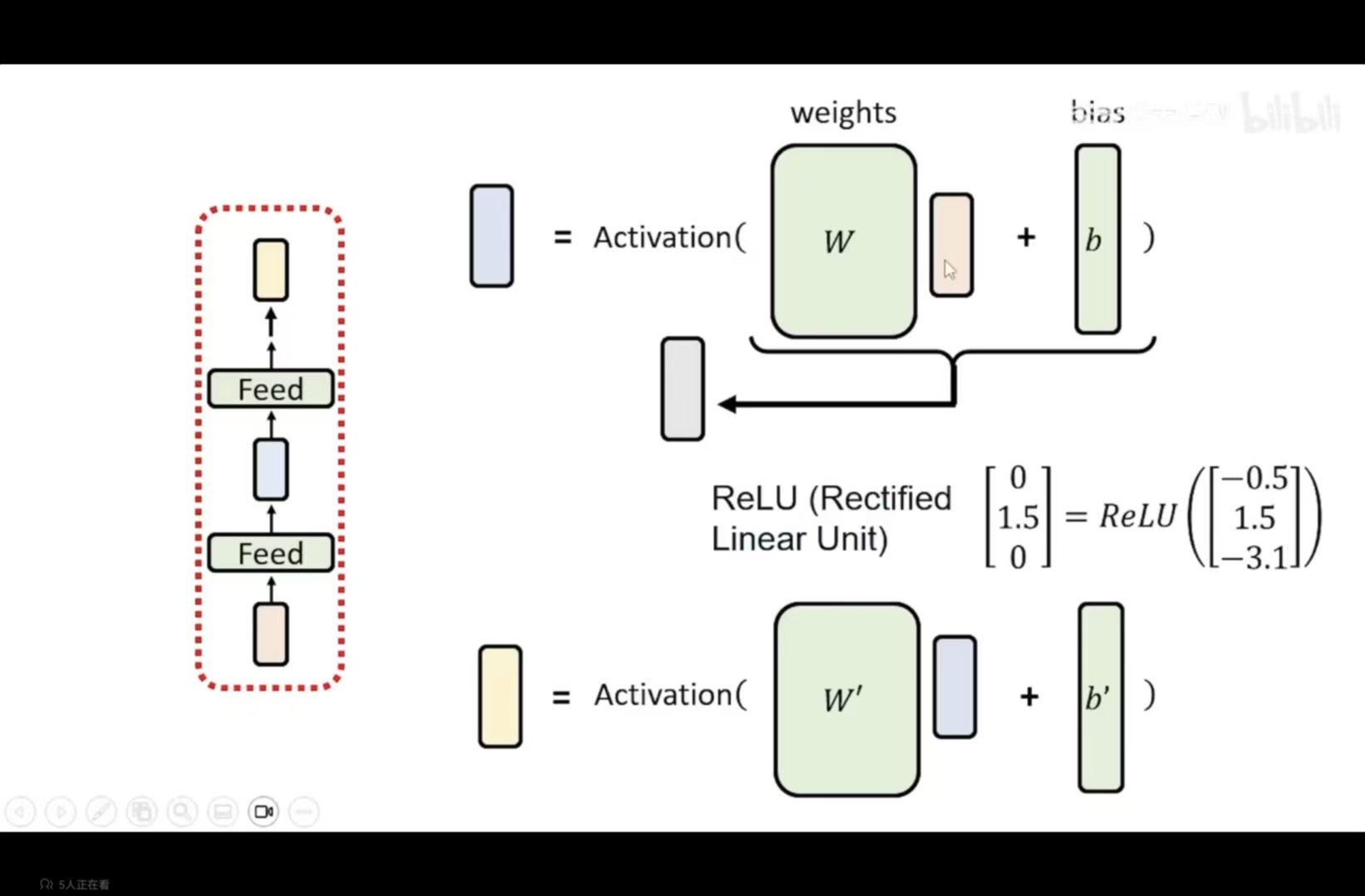
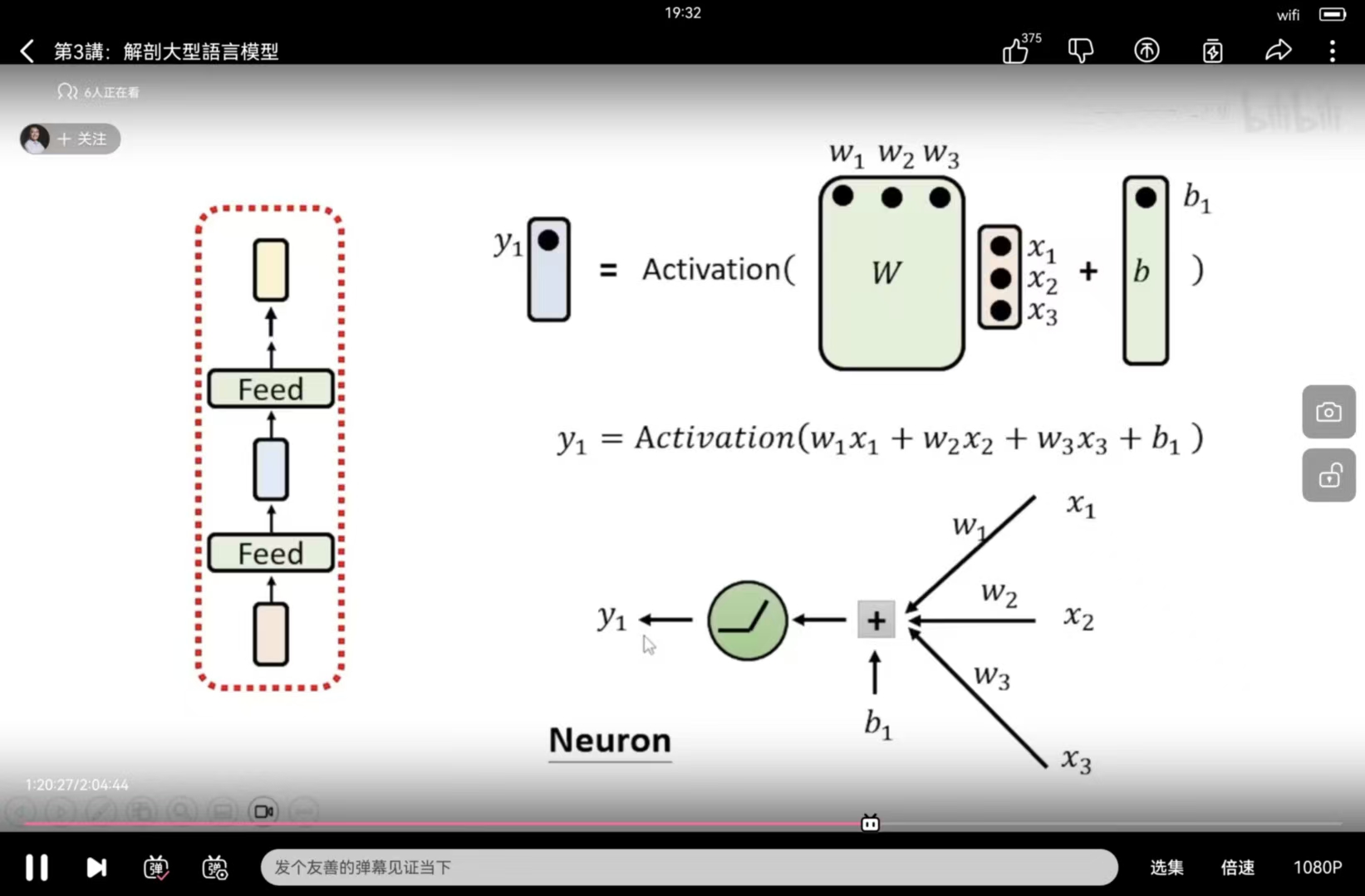
输入进入第一层 Layer 1,内部包含多个矩阵参数
根据输入产生新的 Embedding(已考虑上下文信息)
经过多层深度学习网络逐层处理 - Unembedding 与输出
取出最后一层输出的最后一个向量
与 LM Head 矩阵做 点积(Dot Product) → 得到 Logits
对 Logits 应用 Softmax → 得到概率分布
根据概率采样生成下一个 Token
二、Softmax 原理详解
Softmax 函数将一个实数向量
z=z1,z2,...,zn \mathbf{z} = z_1, z_2, ..., z_n z=z1,z2,...,zn
转换为一个概率分布向量
\\sigma(\\mathbf{z}) : \\sigma(\\mathbf{z})_i = \\frac{e^{z_i}}{\\sum_{j=1}^{n} e\^{z_j}} 其中 其中 其中 i = 1, 2, ..., n
计算步骤分解
以输入向量
z=2.0,1.0,0.1 \mathbf{z} = 2.0, 1.0, 0.1 z=2.0,1.0,0.1
为例:
步骤 1:指数化
对每个元素计算
ezi e^{z_i} ezi
:
| z_i | e\^{z_i} |
|---|---|
| 2.0 | e\^{2.0} \\approx 7.389 |
| 1.0 | e\^{1.0} \\approx 2.718 |
| 0.1 | e\^{0.1} \\approx 1.105 |
步骤 2:求和
计算所有指数值的总和:
Sum=7.389+2.718+1.105=11.212 \text{Sum} = 7.389 + 2.718 + 1.105 = 11.212 Sum=7.389+2.718+1.105=11.212
步骤 3:归一化
每个元素除以其总和,得到概率:
σ(z)1=7.38911.212≈0.659 \sigma(\mathbf{z})_1 = \frac{7.389}{11.212} \approx 0.659 σ(z)1=11.2127.389≈0.659
σ(z)2=2.71811.212≈0.243 \sigma(\mathbf{z})_2 = \frac{2.718}{11.212} \approx 0.243 σ(z)2=11.2122.718≈0.243
σ(z)3=1.10511.212≈0.098 \sigma(\mathbf{z})_3 = \frac{1.105}{11.212} \approx 0.098 σ(z)3=11.2121.105≈0.098
验证
所有输出之和为
0.659+0.243+0.098=1.0✓ 0.659 + 0.243 + 0.098 = 1.0 ✓ 0.659+0.243+0.098=1.0✓
关键特性
-
概率分布:输出值在 (0, 1) 之间,且总和为 1.0
-
放大差异 :
指数函数会放大输入值之间的差异(2.0比1.0大1倍,但e2.0是e1.0的约2.7倍) 指数函数会放大输入值之间的差异( 2.0 比 1.0 大 1 倍,但 e^{2.0} 是 e^{1.0} 的约 2.7 倍) 指数函数会放大输入值之间的差异(2.0比1.0大1倍,但e2.0是e1.0的约2.7倍) -
保持顺序:输入越大,对应的输出概率也越大
三、看看每一层的输出
Token Embedding 特性
- 相同 Token → 相同的 Token Embedding
- 意思相近的 Token → 相近的 Embedding
- 不同上下文 → 相同 Token 获得不同 Embedding
- 语义方向性:特定方向有特定含义(如:某个方向代表"中英翻译")
分析方法
- 降维可视化:将高维向量投射到低维空间观察
- 干预技术:从某层提取向量并修改,可影响模型输出(如:让模型拒绝回答原本会回答的问题)
- Logit Lens:对每一层进行 Unembedding,观察模型在各层的"思考过程"
Patchscopes:用于让单个向量包含完整语义:
1. 将目标语句输入模型,从某层提取向量
2. 构造新输入(如:"请简单介绍【x】")
3. 在新输入传递到对应层时,替换为之前提取的向量
4. 模型即处理完整的语义内容【x】四、每一层内部如何运行
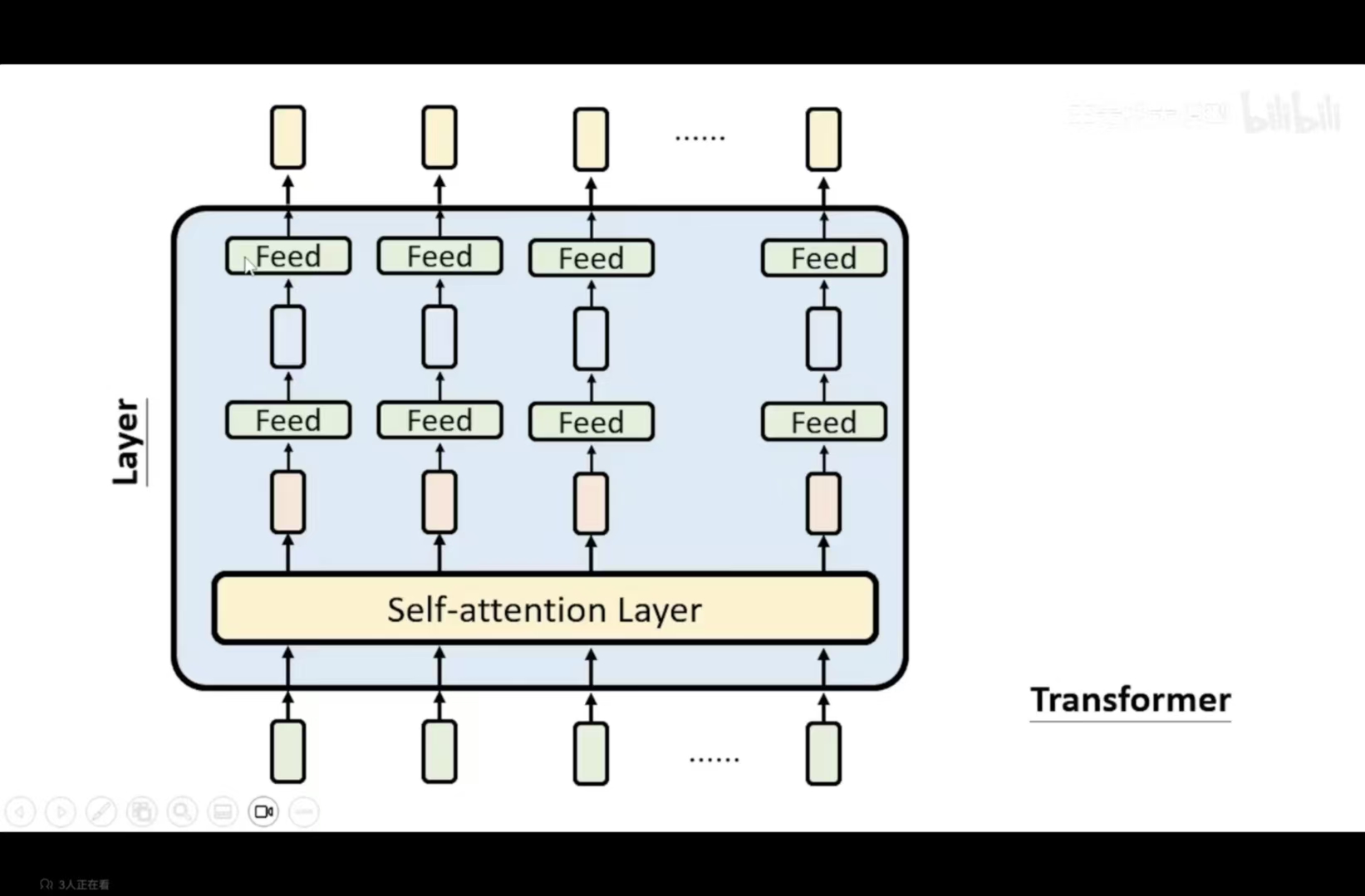
这里以transformer为例子进行分析
4.1 Self-Attention 层(第一层)
核心功能:考虑所有输入 Token 的关系,实现上下文理解
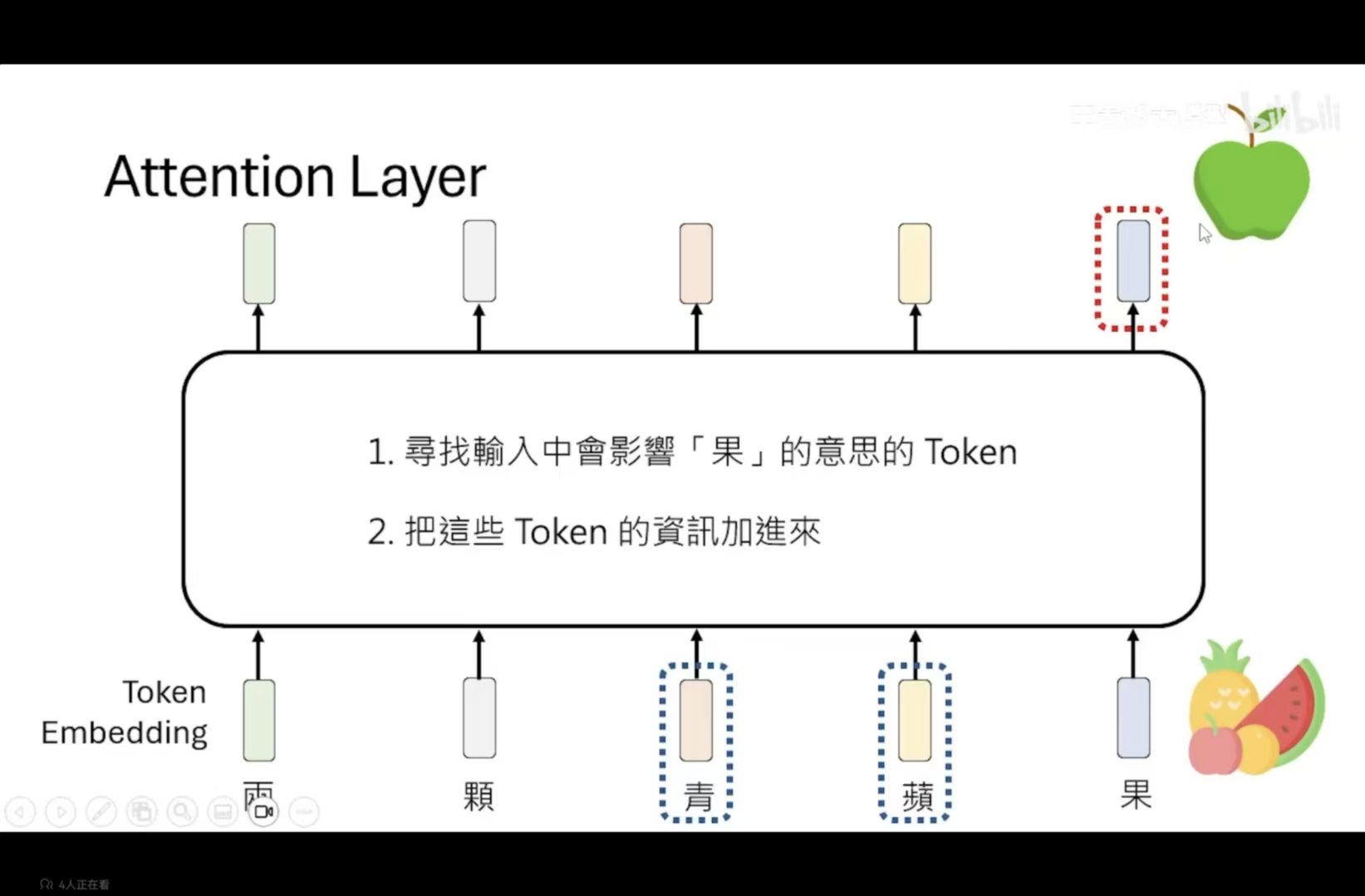
Attention层具体运作原理:
1、寻找与当前输入有关系的token
2、将这些有关系的token的信息加入
第一步的详细步骤:
将每一个token都考虑一下相关度,先乘上一个矩阵,得到key向量,随后在于query直接dot product,算出的结果越大,就证明关联性越强。
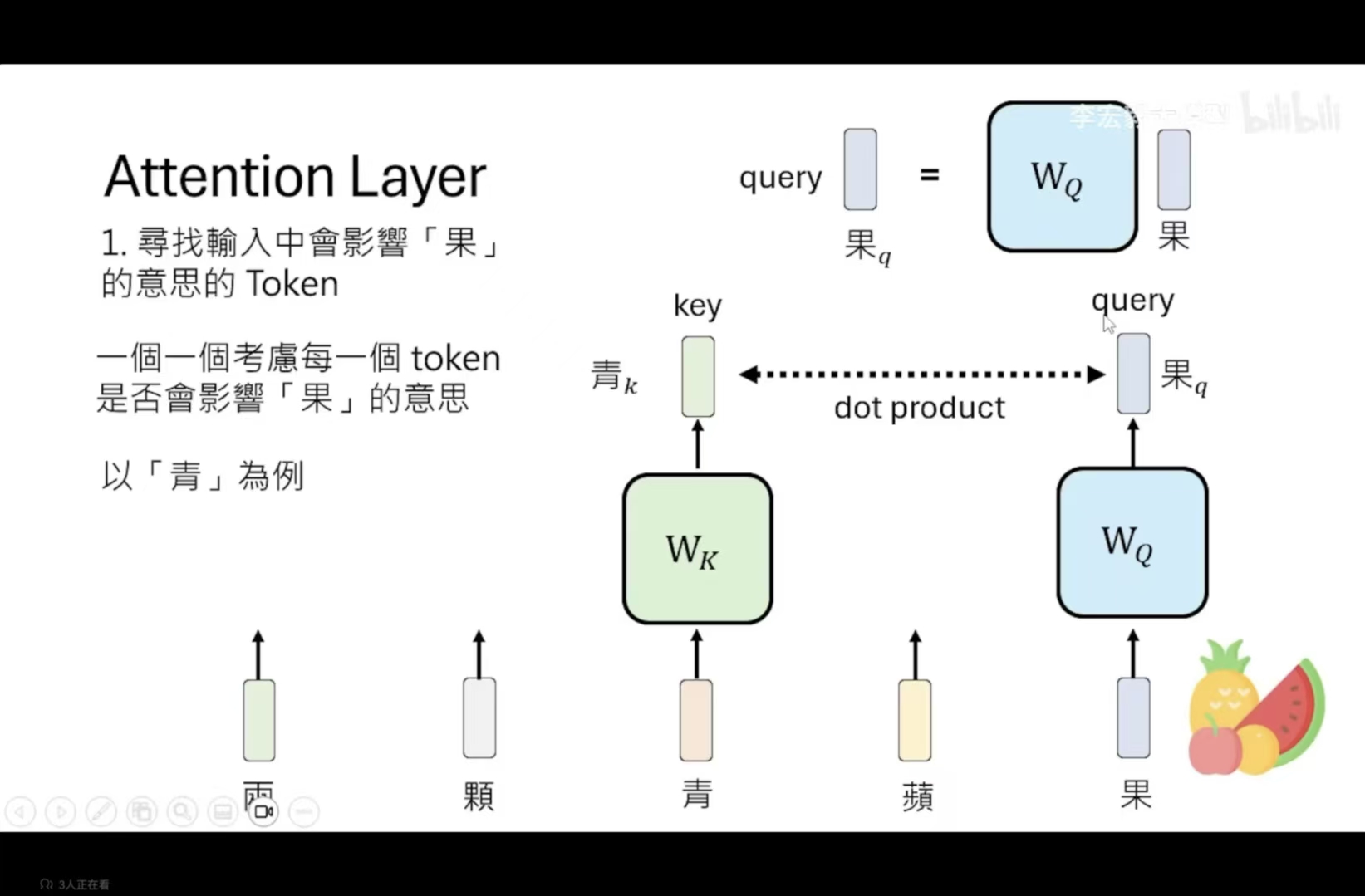
但是有一个问题:这里只是对于单个输入的考虑,并没有 考虑到上下文,相当于抠字眼。没有考虑俩个token直接的距离,一个方法就是positional embedding,记录位置信息 ,token加这个相对应位置的向量,例如p3 + 青俩个向量同时处理 。
我们获得到每一个token与当前token的相关性,再进行了softmax操作
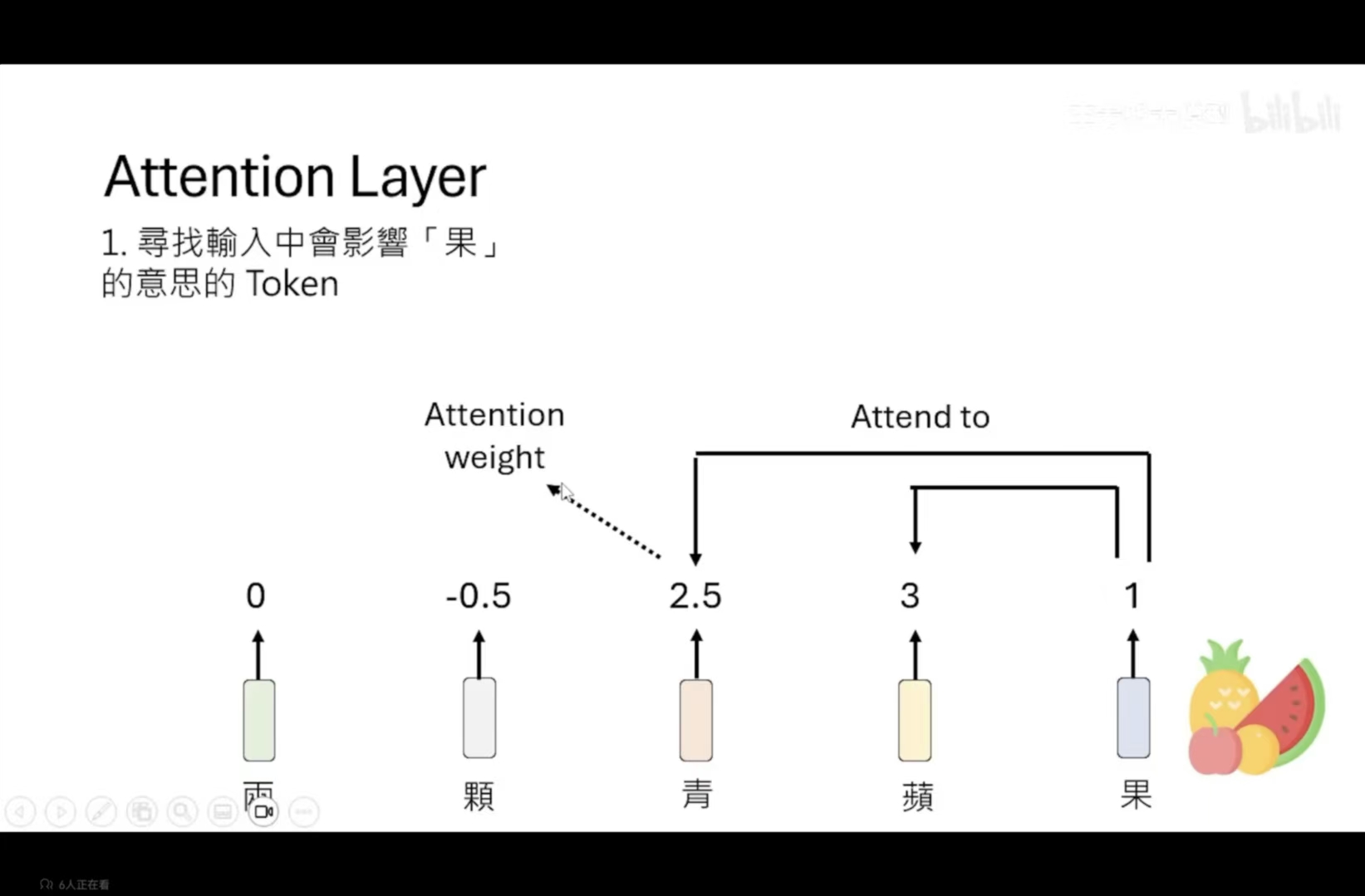
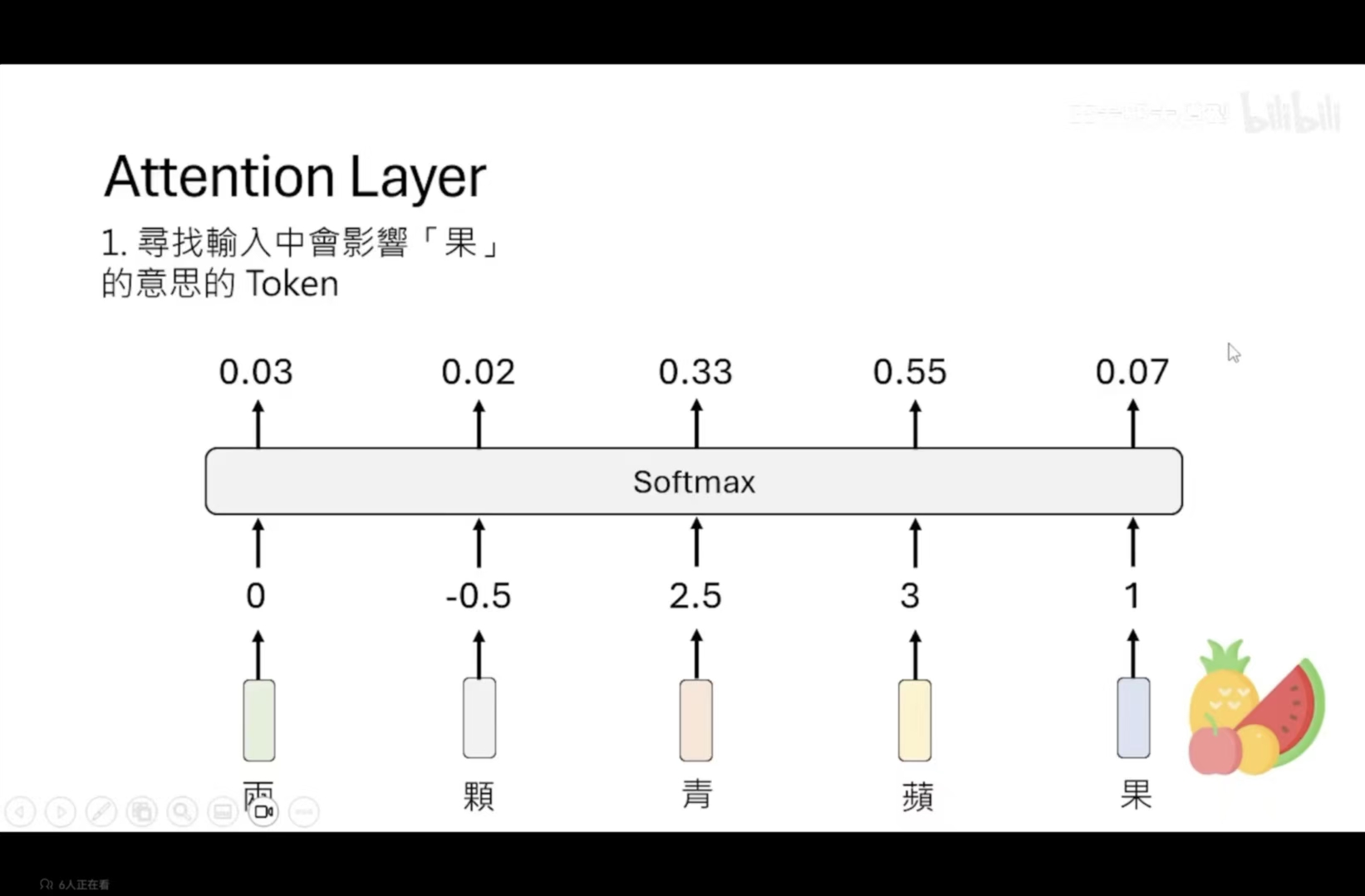
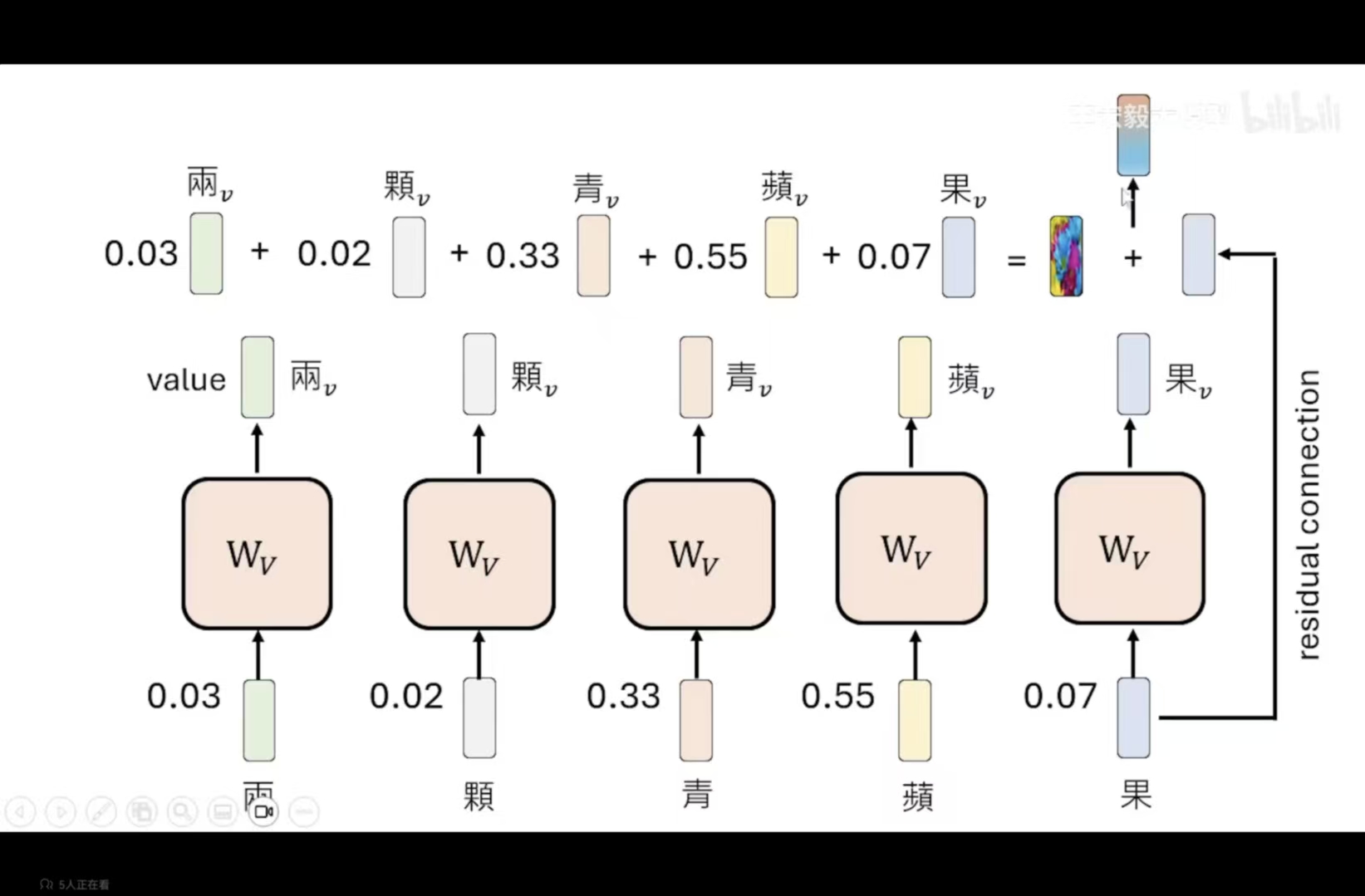
第二步:把这些token的信息加入进来
先获取value,再根据相关性进行加权处理,加起来后得到一个新的向量。residual connection会将当前token加进来,以防止模型忘记当前token
但是,我们注意到第一步骤,是找会影响当前token的其他token,但是影响的具体方面是很多的,所以通常很有多组attention (multi-head attention),例如某一层就是找形容词,某一层是找量词的。
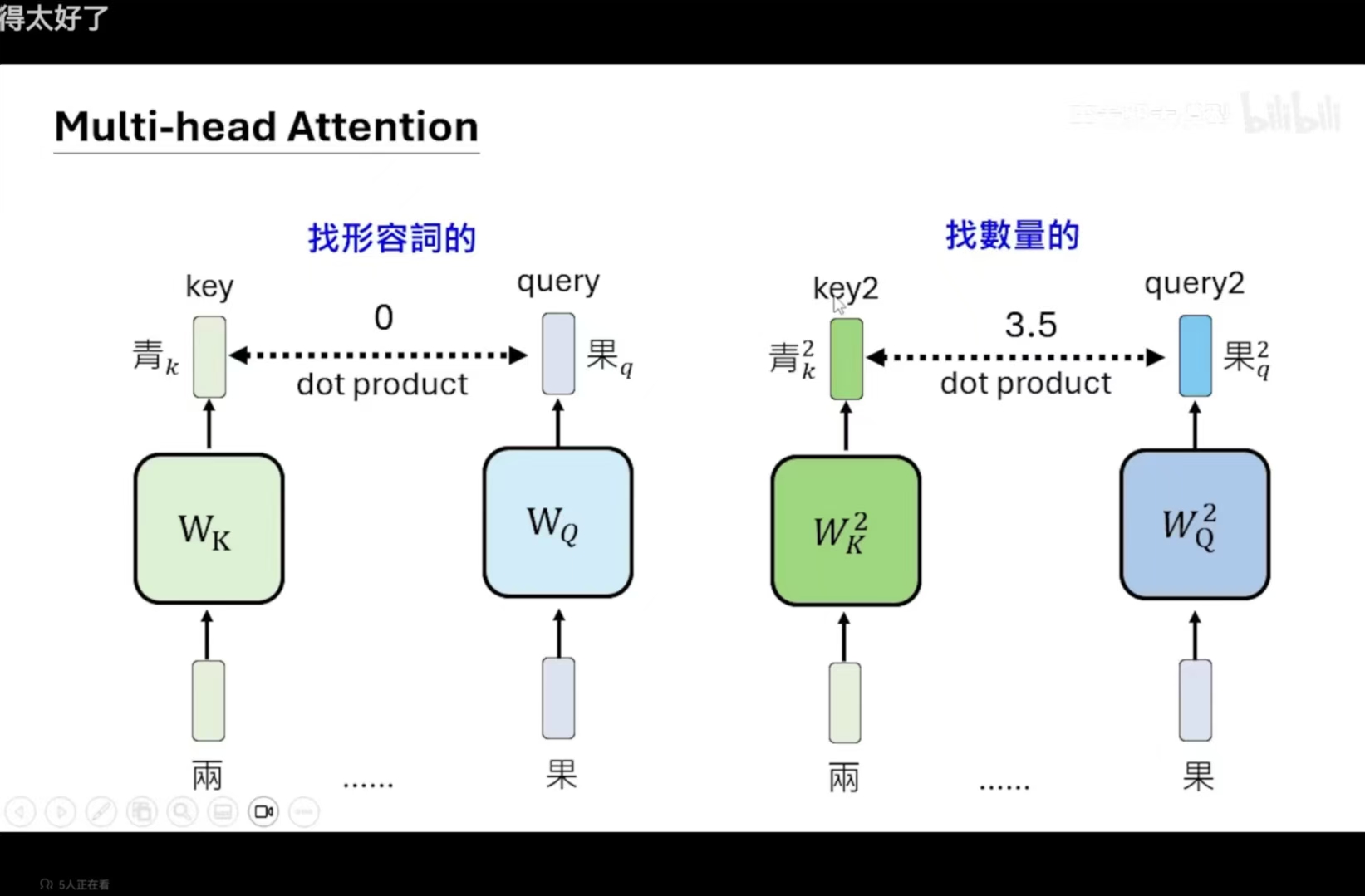
所以,有多层attention层,那就会有多个结果向量,我们需要将这些向量组合起来,变成一个向量
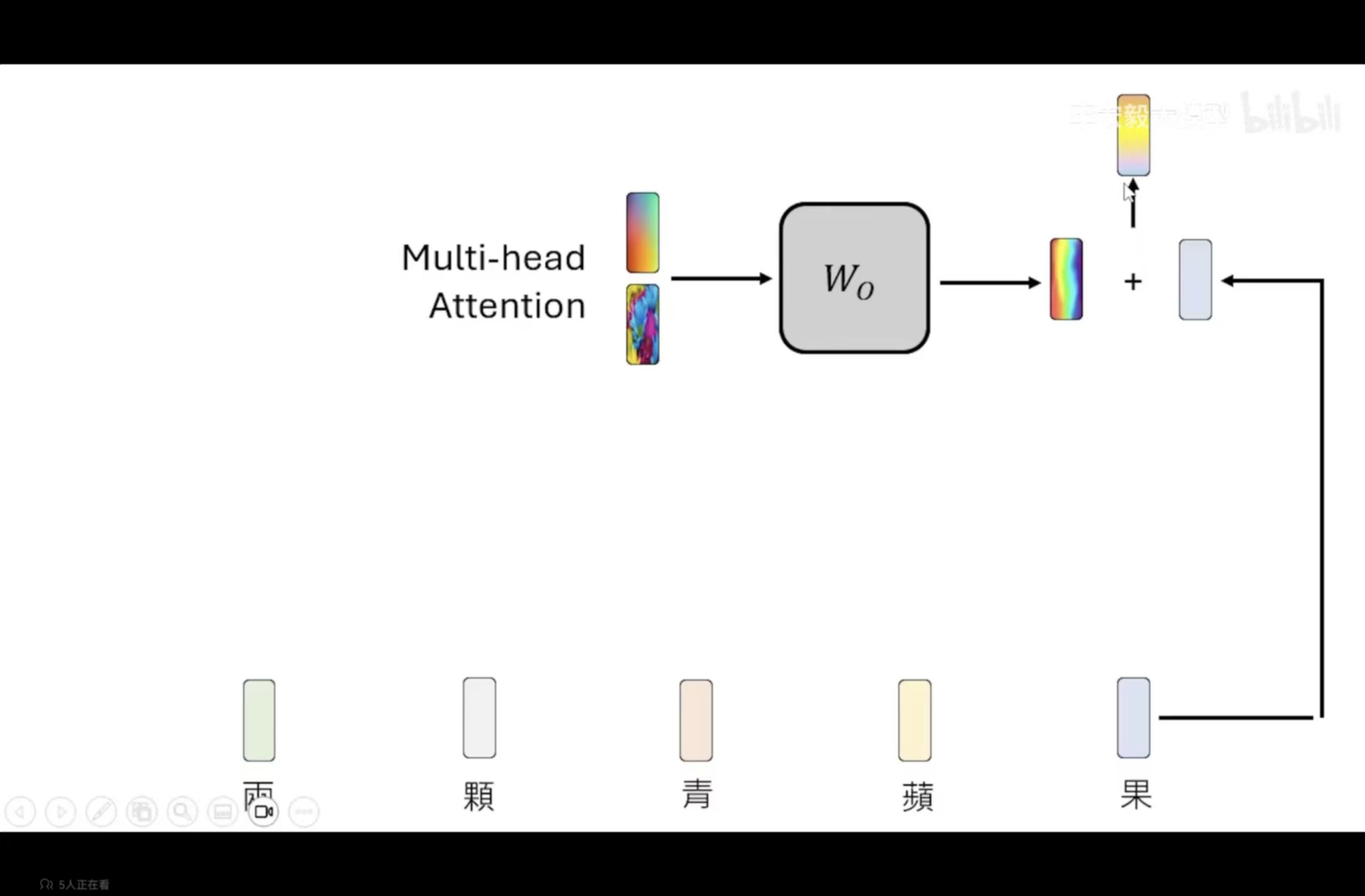
结果:输入越长,运算量就越大。为了解决这个问题,可以去查询相关资料。
并且在实际操作过程中,我们的attention层,每一个token考虑相关性的时候,只会考虑在其左边的token(causal attention)
4.2 Feed-Forward 层(Attention 层之后)