目录
[1. 优化思路](#1. 优化思路)
[2. Naive 版本](#2. Naive 版本)
[3. 优化版本](#3. 优化版本)
[4. 惰性分配(Lazy Allocation)](#4. 惰性分配(Lazy Allocation))
[1. 优化起点](#1. 优化起点)
[2. 常用优化策略](#2. 常用优化策略)
[Auto Tuning 技术](#Auto Tuning 技术)
[1. Triton 语言介绍](#1. Triton 语言介绍)
[2. 核心抽象概念](#2. 核心抽象概念)
[3. 九齿](#3. 九齿)
本文将重点讲解内存管理优化、算子层面优化、Auto Tuning 和代码生成四个核心内容。
内存管理优化
1. 优化思路
-
• 调整分配和释放的时间点和次数,减少运行时的内存分配和释放开销。
-
• 优化分配过程:减少总的内存占用。
2. Naive 版本
运行到算子时即时申请内存,结束即释放,导致频繁的系统调用。
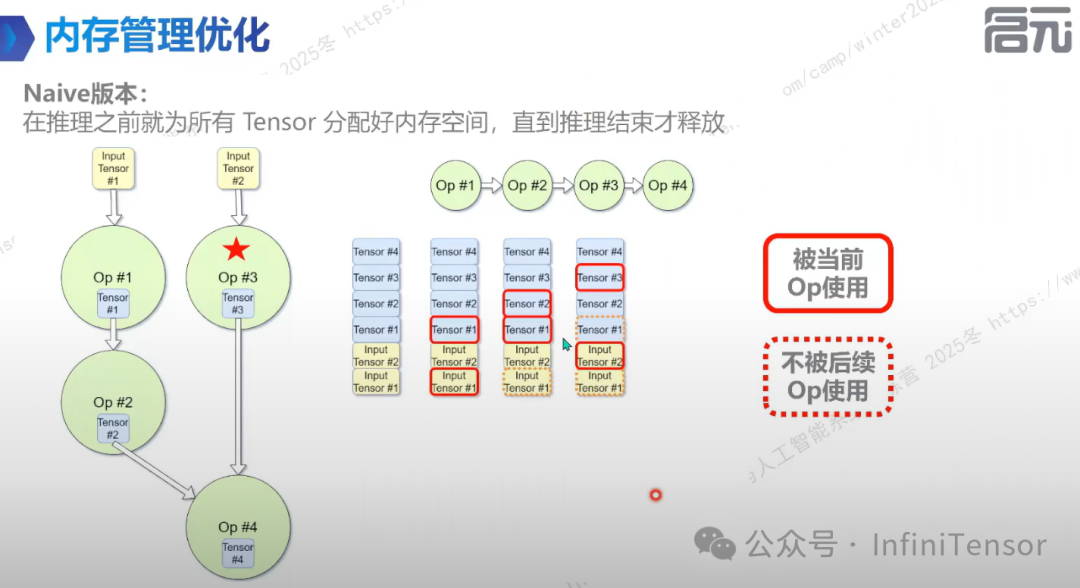
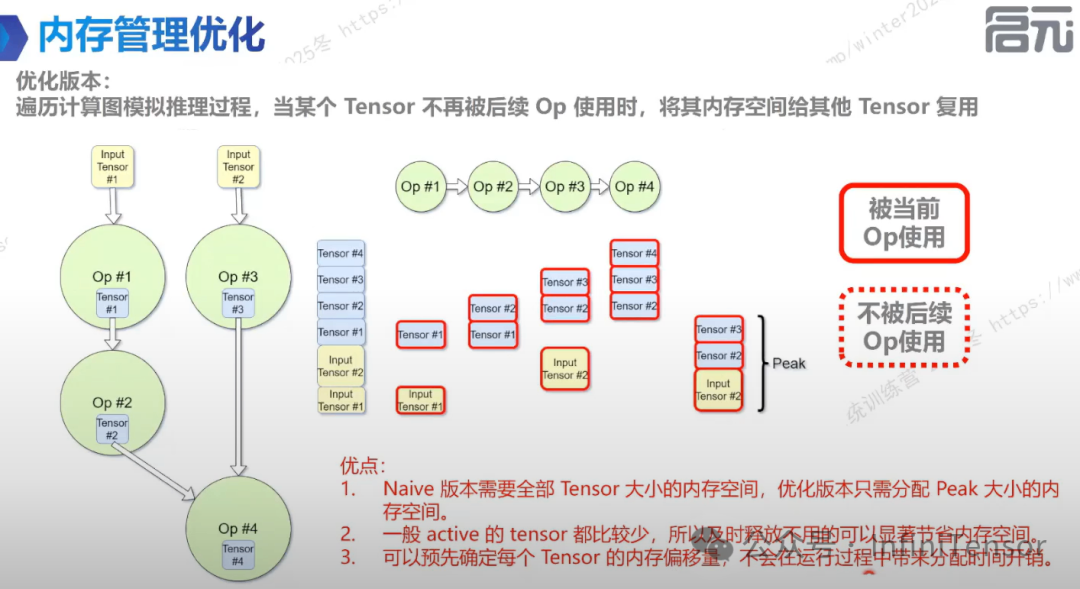
3. 优化版本
-
• 根据拓扑排序确定 OP 执行顺序。
-
• 模拟执行过程,计算内存峰值。
-
• 按需分配和释放内存,利用引用计数机制判断 Tensor 是否可释放。
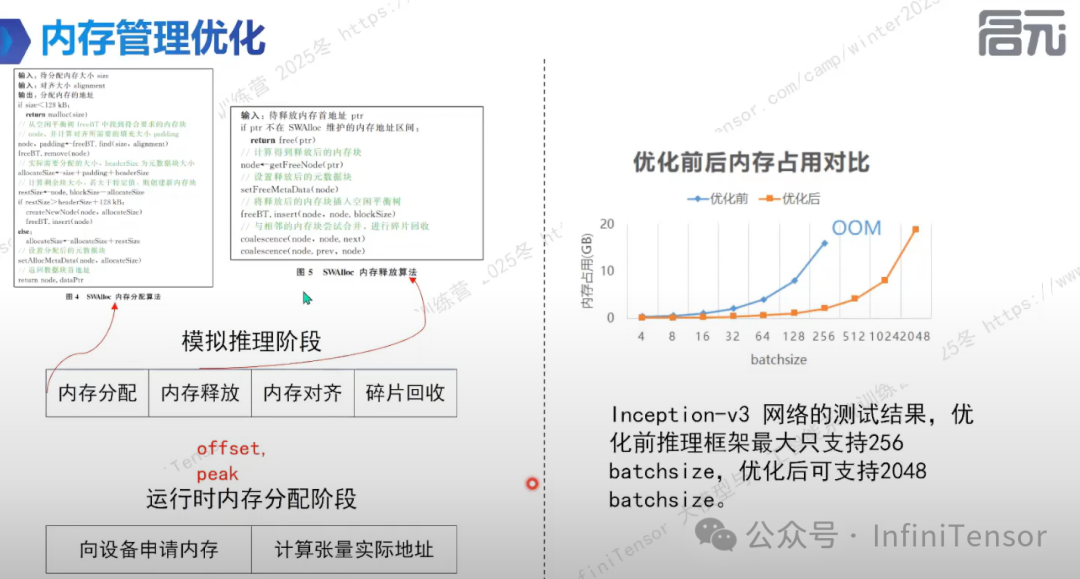
4. 惰性分配(Lazy Allocation)
算子层面优化
1. 优化起点
-
• 理解瓶颈:区分计算密集型和访存密集型任务。
-
• 诊断工具:使用 Roofline 模型确定优化方向。
2. 常用优化策略
(1)循环优化
-
• 循环分块:将大循环分解成小块,提升数据局部性。
-
• 循环展开:增加单次循环迭代内执行的操作次数,减少循环控制开销。
-
• 循环重排:改变循环顺序,匹配数据存储顺序,提升缓存利用率。
-
• 循环融合:合并具有相同迭代范围和遍历顺序的独立循环,减少循环控制开销,提升数据局部性。
-
• 循环拆分:将复杂循环拆分成多个简单循环,消除依赖,允许并行执行。
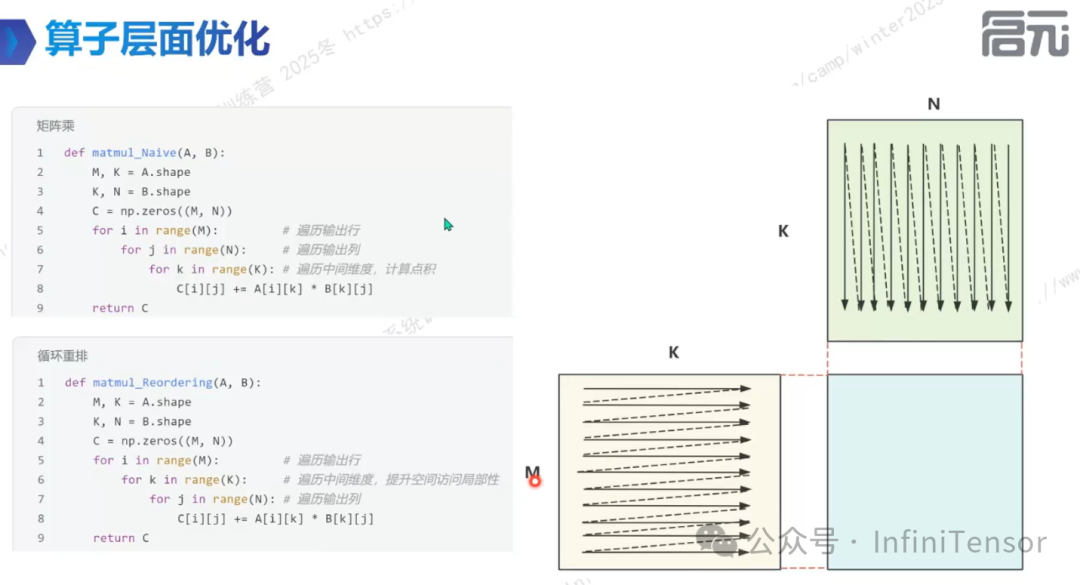
矩阵乘法优化示例

Softmax 算法
(2)指令优化
-
• 向量化指令:
-
• SSE:128-bit 寄存器,4×float32
-
• AVX / AVX-512:提供 256-bit / 512-bit 向量指令支持,可在合适的硬件与算子条件下显著提升数据并行吞吐率。
-
• ARM NEON:128-bit SIMD
-
-
• 张量化指令:
-
• NVIDIA Tensor Core:专用矩阵乘加单元
-
• MMA 指令格式
-
(3)内存优化
-
• 预取:提前加载数据到高速缓存,隐藏内存访问延迟。
-
• 双缓冲:通过计算与数据传输的流水线并行,隐藏或降低 IO 等待带来的性能损失。
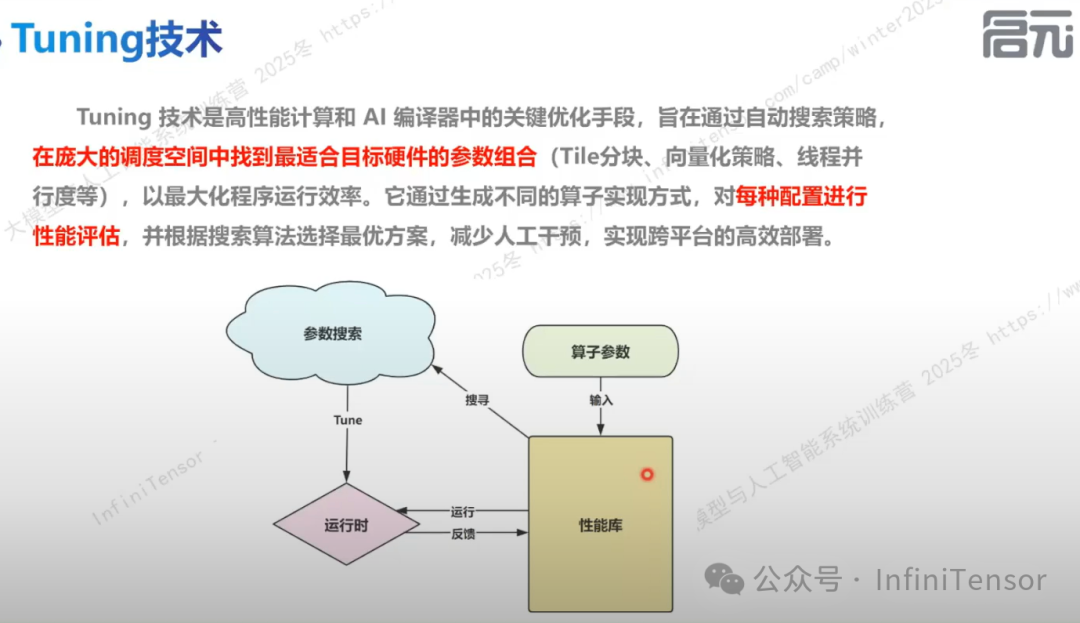
Auto Tuning 技术
代码生成
1. Triton 语言介绍

2. 核心抽象概念
(1)Layout: 描述张量元素如何映射到计算资源和内存单元上。
(2)编译器优化: 自动进行内存访问合并、延迟掩盖、数据重排等优化。
3. 九齿
-
• 简化 Triton 编程接口
-
• 自动处理 PID 等底层细节
-
• 提升开发效率,降低 CUDA 编程门槛

总结
本文讲述了内存管理优化、算子层面优化、Auto Tuning 和代码生成四个核心领域的关键技术和实践方法。