一、神经网络处理回归问题
上文我们介绍了神经网络不仅能做分类还能进行回归,比如人脸关键点的识别。
已经介绍了图片的加载和图片的预处理
和分类的时候一样有训练集和测试集训练函数,这里测试函数我们不再是用正确率了,而是用损失值。损失值和r的平方都是回归的评估方式。
python
# 训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1 # 统计训练的batch数量
for X, y in dataloader:
X, y = X.to(device), y.to(device) # 把训练数据集和标签传入cpu或GPU
pred = model.forward(X) # 前向计算
loss = loss_fn(pred, y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
loss_value = loss.item()
if batch_size_num %1==0:
print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
def test(dataloader, model, loss_fn):
model.eval()
test_loss = 0
total_samples = 0
with torch.no_grad():
for X, y in dataloader:
# 确保X和y不为空
if X.size(0) == 0: # 检查batch是否为空
continue
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item() * X.size(0)
total_samples += X.size(0)
if total_samples == 0:
print("警告:测试集为空!")
avg_loss = float('inf') # 或者返回一个很大的数表示无效
# 或者:avg_loss = 0.0 # 根据你的需求选择
else:
avg_loss = test_loss / total_samples
print(f"Avg loss: {avg_loss:.4f}")
return avg_loss然后就是我们最重要的神经网络的搭建,这里要和前面图片输入大小一致,参考上文,知道我们图片传入模型的大小是64x64
conv1:64*64*16 ------>> pool1: 32*32*16 ------>> conv2: 32*32*32 ------>>
pool2: 16*16*128 ------>> conv3: 16*16*128 ------>> out: 128*16*16
到后面就是一个全连接层,十个坐标对应十个神经元。
python
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 128, 5, 1, 2),
nn.ReLU(),
)
self.dropout = nn.Dropout(0.3)
self.out = nn.Linear(128 * 16* 16, 10) #10
def forward(self, x): #前向传播
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output然后就开始图片加载,设备初始化,注意这里我们使用的损失函数是L1损失函数
关于损失函数,用于分类常见的有:
- CrossEntropyLoss - 多分类(最常用)
- BCELoss - 二分类
- NLLLoss - 对数似然损失
回归常见的有:
- MSELoss - 均方误差(最常用)
- L1Loss - 绝对误差(MAE)
- SmoothL1Loss - Huber损失
其他基本上都是没变的,既然我们使用的评估是损失值,那保存最优模型自然就不是像正确率越高越优,损失值而是越小越好。
python
# 数据加载
training_data = ren_dataset(file_path=r".\renlian\train_ren.txt", transform=data_transforms['train'])
test_data = ren_dataset(file_path=r".\renlian\test_ren.txt", transform=data_transforms['test'])
train_dataloader = DataLoader(training_data, batch_size=1, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=1, shuffle=True)
# 设备设置和模型初始化
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else 'cpu'
model = CNN().to(device)
print(model)
# 损失函数
loss_fn = nn.L1Loss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
#学习率调度器
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)
# 训练循环
best_loss = float('inf')
epochs =50
for t in range(epochs):
print(f"Epoch{t + 1}\n------")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step()
current_loss = test(test_dataloader, model, loss_fn)
if current_loss < best_loss:
best_loss = current_loss
torch.save(model.state_dict(), 'cnn_ren_model_da.pth')
print(f'cnn人脸关键点最小损失模型:损失值为{best_loss:.2f}')
print("Dnoe!")
print(f'cnn人脸关键点最小损失模型:损失值为{best_loss:.2f}')二、自然语言处理
自然语言处理实际上就是让机器学会人类的语言,根据之前的学习我们知道机器只能处理数值,文字对于他来说没有任何意义,那该怎么让他学会人类的语言呢?就是把人类的语言转化为机器所熟悉的数据。人理解词语的意思是根据词的含义,而对于不同的词机器要区别他们的含义,就是把各种词转为为向量,每个词对应一个向量,相同含义意义的词向量基本重合,这就是机器学人类语言的方式也就是自然语言处理。
在之前我们机器学习的过程中有提到过自然语言处理有两种词向量转化的方法
第一种:传统方法,统计,规则(例如TF-IDF,朴素贝叶斯)
第二种:深度学习的方法,使用神经网络(如CBOW,LSTM,Transformer)
关于传统的方法我们早在机器学习的时候就已经学习,后面我们将会学习神经网络的方法进行词向量的转化。
1.One-hot编码和词嵌入
只是对词进行索引编码,给神经网络提供原始输入
具体什么情况呢?

在之前机器学习的词向量转化学习中我们知道一行向量代表的是一句话(或者是一篇文章),这里我们的一句话是有多个向量进行表示的(这个取决于我们有多少个分词)。就比如说这里我们分词分了四个,那我们这句话的矩阵就是4x4的。
相比于之前我们得到的矩阵更稀疏了。现在我们只是分了四个词,当我们遇到文本更大的词向量转化,那维度将会很大,浪费计算资源;矩阵乘法大部分是0*权重=0,只有一个位置有效,其他无效,计算效率低。新词出现又要增加维度,无法从已知词中推断新词语语义,无法泛化;而且矩阵过于疏松会导致语义缺失,毕竟有句话叫做浓缩的才是精华。
解决这个问题我们使用词嵌入,就是把高纬度的词向量转化为低纬度的词向量。
一般情况下我们分词m个,那我们得到的词向量矩阵大小就是mxm。例如我们分词分了5000个词,得到的矩阵大小就是5000x5000,词嵌入就可以把矩阵压缩为5000x300,这样我们的矩阵就不会很稀疏了
2.词向量转化模型
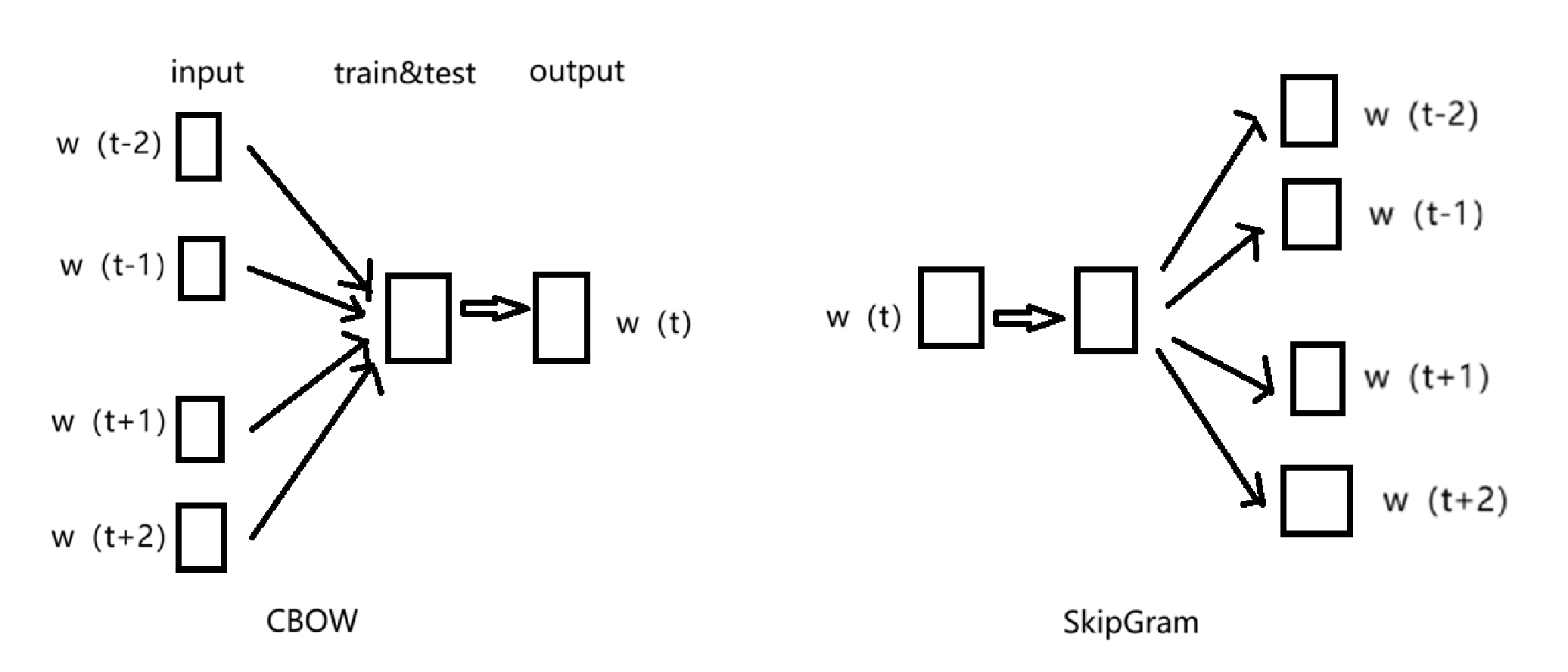
训练词向量的模型有两个:CBOW和SkipGram
CBOW:以上下词汇预测当前词,就是预测词wt,用已知的前n个词和后n个词,相当于我们学习英语的时候做完形填空。
SkipGram:根据当前词汇预测其上下文词汇,已知wt,预测上文词和下文词汇
3.模型的训练过程
- 1)当前词的上下文词语的one-hot编码输入到输入层
- 2)这些词分别乘以同一个矩阵W(v*n)后分别得到各自的1*n向量
- 3)将多个这些1*n向量取平均,最后得到一个1*n向量
- 4)将这个1*n向量乘矩阵W'(v*n),变成一个1*v向量
- 5)将一个1*v向量softmax归一化后输出取每个词的概率向量1*v
- 6)将概率值最大的数对应的词作为预测词
- 7)将预测的结果1*v向量和真实标签1*v向量(真实标签中的v个值中有一个是1,其他是0)计算误差
- 8)在每次前向传播之后反向传播误差,不断调整W(v*n)和W'(v*n)矩阵的值
CBOW:最终我们需要的是W(v*n)
4.CBOW自然语言处理(部分)
tqdm模块是进度条,可以记录我们训练进度,这个进度条可以加在有for循环的地方
python
import torch
import torch.nn as nn#神经网络模块
import torch.nn.functional as F#函数式神经网络操作
import torch.optim as optim#优化器
from tqdm import tqdm,trange#显示训练进度条
import numpy as npcontext_size是我们设置的利用前n个词和后n个词的个数。这里就是我们预测某个词的时候,拿前两个和后两个词来预测这个词。
raw_text是我们的正文,后面用了split,是把文章内容根据空格进行划分
python
CONTEXT_SIZE=2#设置上下文窗口大小,关键参数,左右各取两个词,共四个。
raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells.""".split()#语料库下面就是raw_text的内容

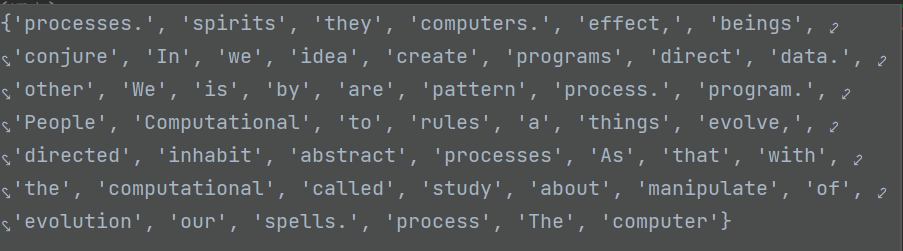
这里我们的正文是英文,如果是中文,分词还是分字都是可以的,进行分词之后,只是把文章中的词给单独分出来,一篇文章中会有重复的词,所以下面我们就要创建集合,数学中集合的特点就是其中元素不重复,都是独一无二的。vocab_size是对vocab集合中元素个数进行统计,这里个数为49。
然后就给集合中的元素,也就是各个词进行分配索引编号。
然后根据这个索引编号创建字典(映射)
python
# 中文的语句,可以选择分词,也可以选择分字
vocab = set(raw_text) # 集合。词库,里面内容独一无二
vocab_size = len(vocab)#词库大小
#创建单词到索引的映射(词表)
word_to_idx = {word: i for i, word in enumerate(vocab)} # for循环的复合写法,第1次循环,i得到的索引号,word_第1个单词
#创建索引到单词的映射
idx_to_word = {i: word for i, word in enumerate(vocab)}vocab内容:
word_to_idx:

idx_to_word:

获取上下文词,把上下文词作为输入训练模型。
创建一个列表data
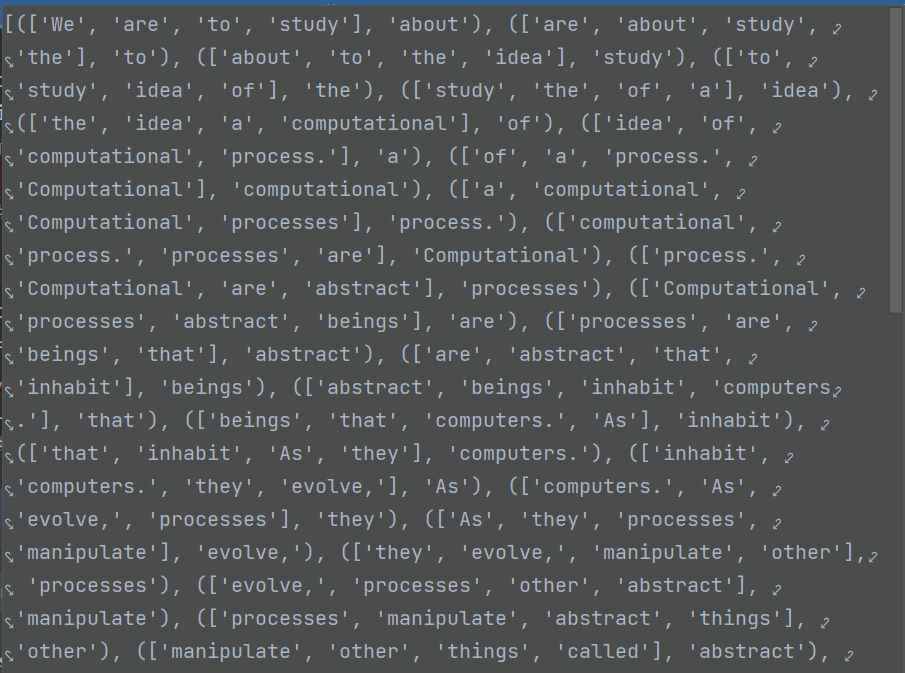
range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE),当我们要你预测某个词的时候,给很具我们设置的context_size大小要确保我们要预测的这个词有context_size个词。所以我们预测的时候要从(contex_size+1)个词开始才能预测,结尾和开头一样,能预测的截止到(总词数-context_size)个。注意这里的总词数不是集合的总词数,而是原文章的词数,我们要在原文章中从第三个词开始获取,因为训练模型就是能让他做'完形填空',在某种意义上理解文章,所以我们要给他的就是原文章。
data最后内容就是每个能预测的词的前两个和后两个(因为我们这里context_size设置的是2)
python
data = [] # 获取上下文词,将上下文词作为输入,目标词作为输出。构建训练数据集。
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):#(2,60),从第三个值开始预测
context = (
[raw_text[i - (2 - j)] for j in range(CONTEXT_SIZE)]#目前要预测的这个字前面的俩和后面的俩作为列表相加
+ [raw_text[i + j + 1] for j in range(CONTEXT_SIZE)]
) # 获取上下文词
target = raw_text[i] # 获取目标词,也就是要预测的词前俩和后俩
data.append((context, target)) # 将每个要预测的词的上下文词和目标词保存到data中data:四个词组成一个列表和对应的中间词组成一个元祖,所以data列表中元素都是元组,而且有58个这样的元组。因为原文章词数为62个,能进行预测的词数为62-2-2=58。这个是和我们设置的context_size大小有关的。
关于CBOW自然语言处理剩下部分会在下一篇博客中继续分析。