目录
- 前言
- [一、zip/unzip 指令 + 批量操作](#一、zip/unzip 指令 + 批量操作)
- [二、tar 和 file 指令](#二、tar 和 file 指令)
- [三、scp 指令](#三、scp 指令)
- [四、bc 指令](#四、bc 指令)
- [五、uname -r 指令](#五、uname -r 指令)
-
- [5.1 从 x86_64 读懂芯片与体系架构演进](#5.1 从 x86_64 读懂芯片与体系架构演进)
- 六、Linux中的常用热键
- [七、history 指令](#七、history 指令)
- 八、关机
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、zip/unzip 指令 + 批量操作
在Windows当中,就会有各种各样打包压缩的工具或软件
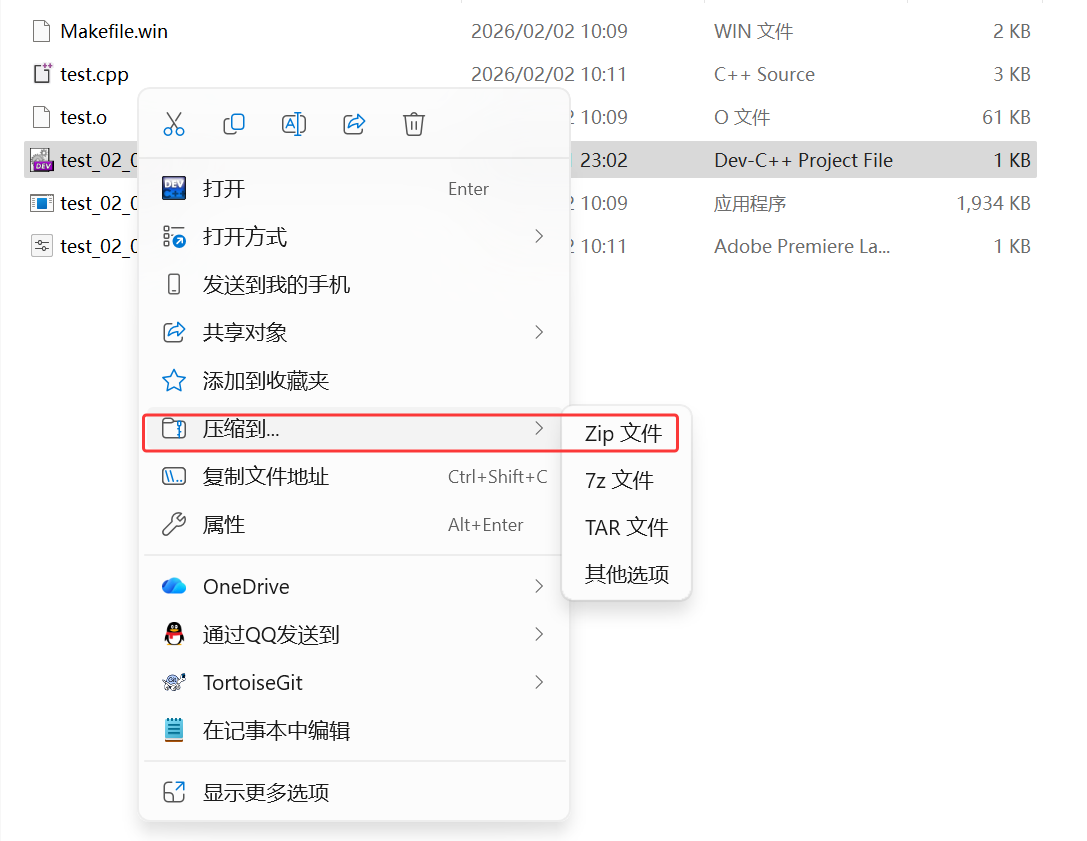
打包与压缩
一、核心定义:两个独立动作
1. 打包(归档)
- 核心逻辑 :
多变一→ 将多个分散的文件、文件夹,合并成一个单独的归档文件(比如.tar格式的包)。 - 关键特点:打包过程不会改变文件的总大小,只是把零散文件整合为一个整体,本质是 "整理收纳"。
- 核心作用:解决多文件传输 / 存储时容易丢失、混乱的问题
2. 压缩
- 核心逻辑 :
大变小→ 通过特定压缩算法(如gzip、bzip2),对文件(包括打包后的归档文件)进行处理,减小体积。 - 关键特点:压缩会改变文件大小,是 "用时间换空间" 的权衡 ------ 高压缩率的算法通常需要更长的压缩 / 解压时间,反之则更快
二、两者的关系:常结合为 "一套动作"
打包和压缩是两个独立的技术动作,但实际使用中通常会结合成 "先打包、再压缩" 的流程:
- 先把零散文件打包成一个归档文件,再对这个归档文件进行压缩。
- 这样既解决了多文件管理的问题,又通过压缩提升了传输、存储的效率,这也是软件领域分发文件时的标准做法
三、为什么要做打包压缩
- 避免文件丢失:网络传输或存储时,单个归档文件比多个零散文件更不容易丢失、遗漏,在软件分发、部署中非常常见。
- 提升效率:压缩后的文件体积更小,能减少网络传输的带宽占用、加快传输速度,同时也能节省磁盘存储空间。
- 时间与空间的权衡:不同压缩算法在压缩率和耗时上有差异,需要根据场景在 "空间节省" 和 "时间成本" 之间做选择。
打包压缩的算法种类特别多(Zip文件,TAR文件...),一般看压缩方式就是看压缩包的后缀,虽然Linux不看后缀,不代表所用的压缩工具不看后缀
本文主要讲两种最常见的压缩方式,一种是.zip的方式,另一种是.tgz的方式,.tgz 其实等于 .tar.gz,前一种方式是后一种方式的简写,若是见到本文这两种方式之外的其他后缀,可以直接拿着后缀作为关键词,使用搜索引擎或AI "帮我形成Linux指令,解压和解包.XXX的文件,只需要一条简单的指令即可"
这里顺便介绍一个骚操作,历史上形成过一次大文件,但是忘记当时是如何形成的时候,就可以使用CTRL + R,这是一个热键,其可对历史的内容作搜索,只记得是个while循环,直接输入while


可以看到,这里自动的将刚才的命令调出来了,此时直接回车即可


该大文件是10w零1行,进行打包压缩实验需要大量的文件,再介绍一个touch指令的用法
touch test{1..100}.c,其作用就是创建一批文件,这批文件的文件名前缀是test,后缀是.c,1-100会被依次展开
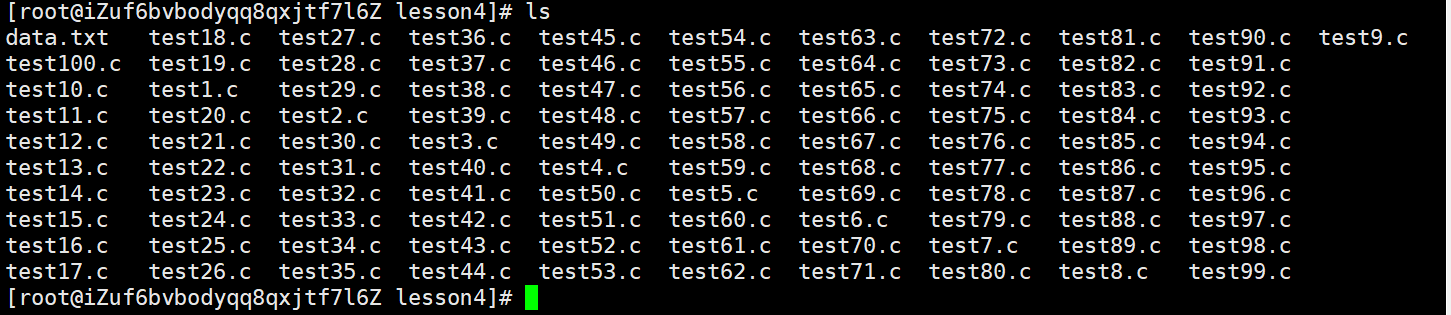
这么多文件也有对应的批量删除方法
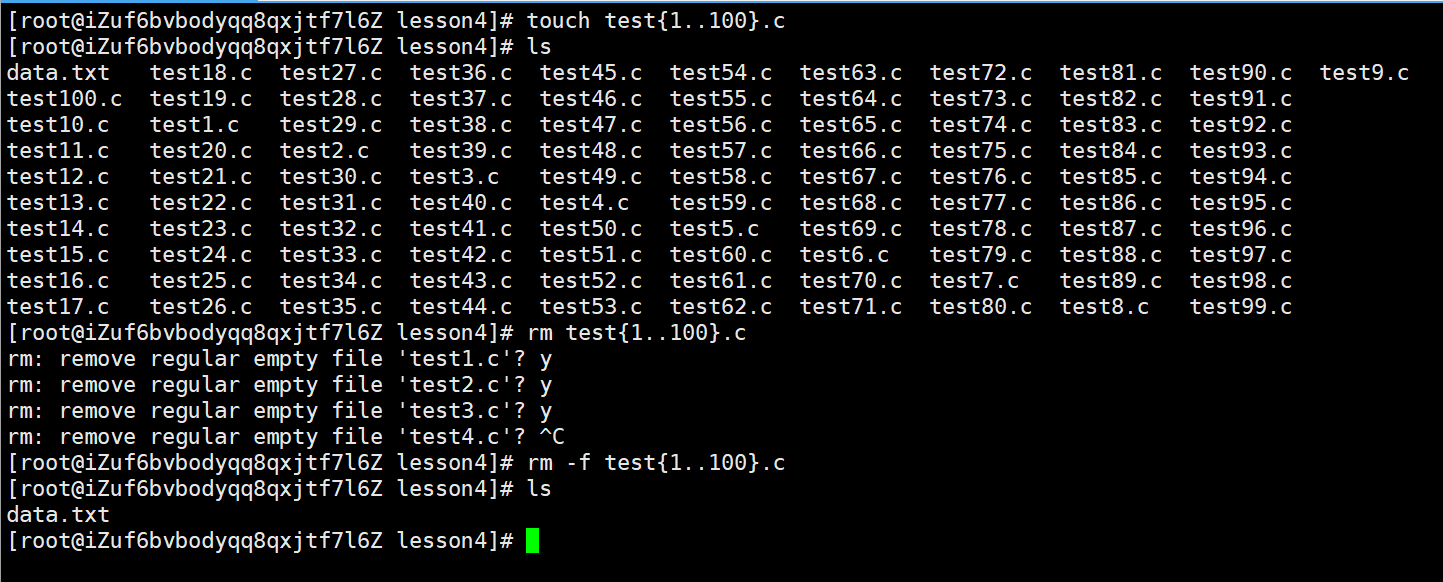
使用rm test{1..100}.c会每次询问,使用rm -f test{1..100}.c可以不经询问,直接删除,还可以使用通配符*删除
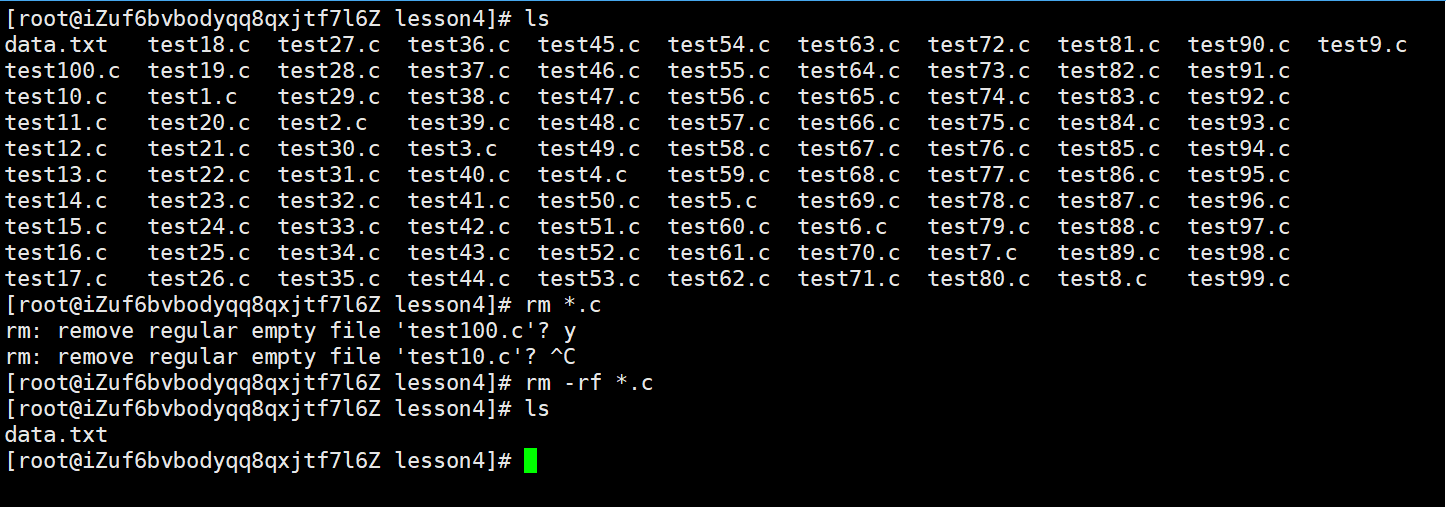
这种批量操作还有很多玩法,可以自己尝试
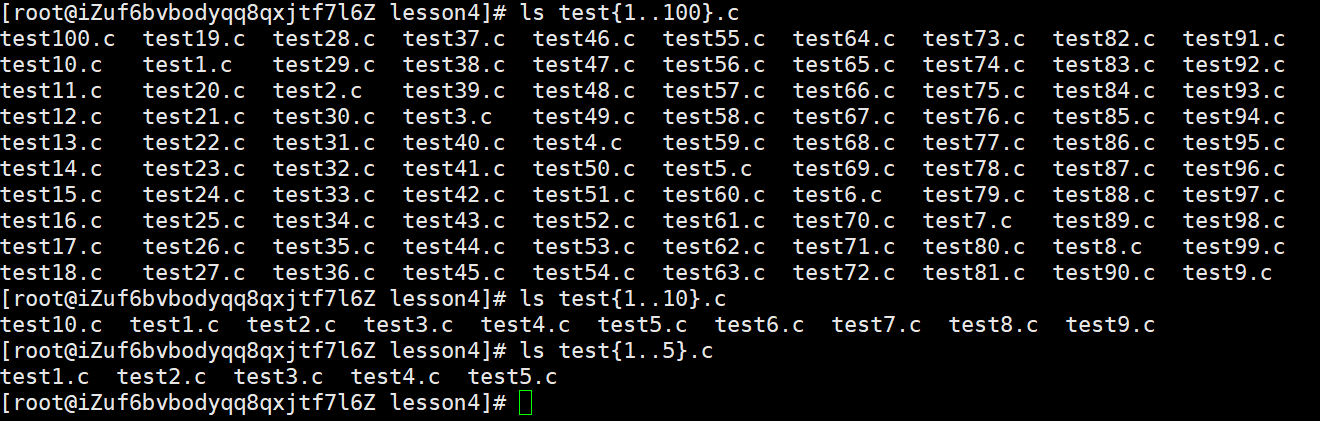
zip / unzip指令
语法 :zip压缩文件.zip目录或文件
功能:将目录或文件压缩成zip格式
bash
zip test2.zip test2/*这里就是将后者压缩成前者,前者的名字可以随便起,但是前者后缀必须是.zip结尾
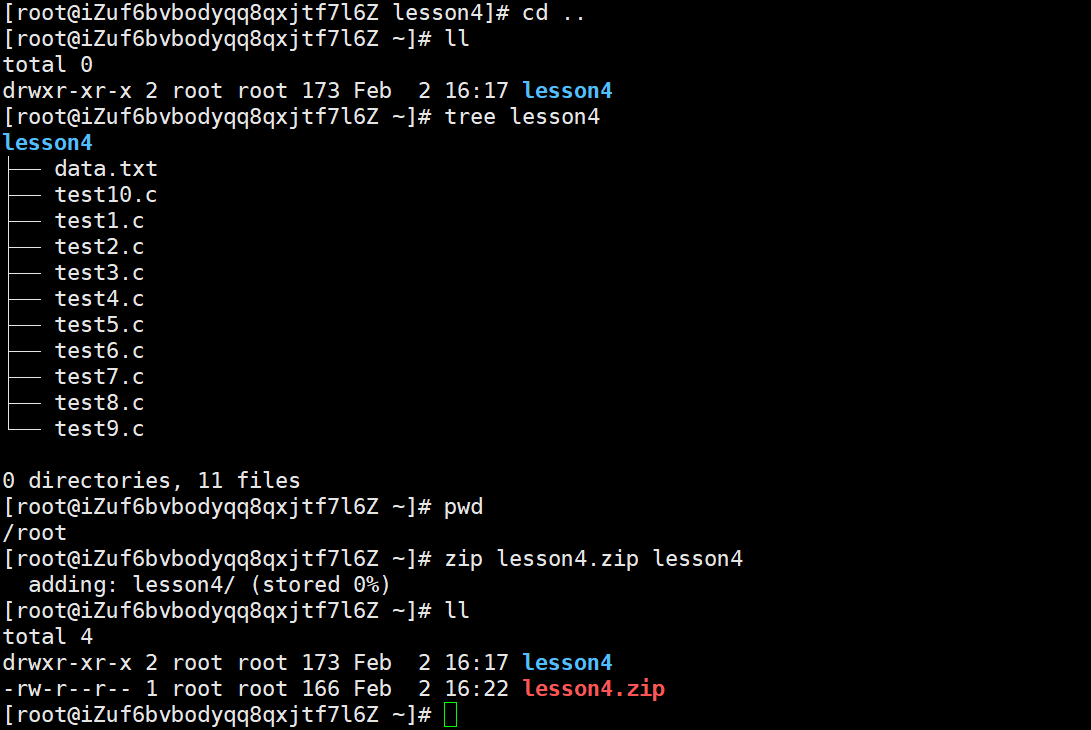
这里和windows一样,会额外形成一个压缩包文件
图中解压的指令是upzip lesson4.zip。默认解压到当前路径
按照windows的理解,解压之后的文件就可以使用tree,ls列出文件内容了,但是实际上是空的
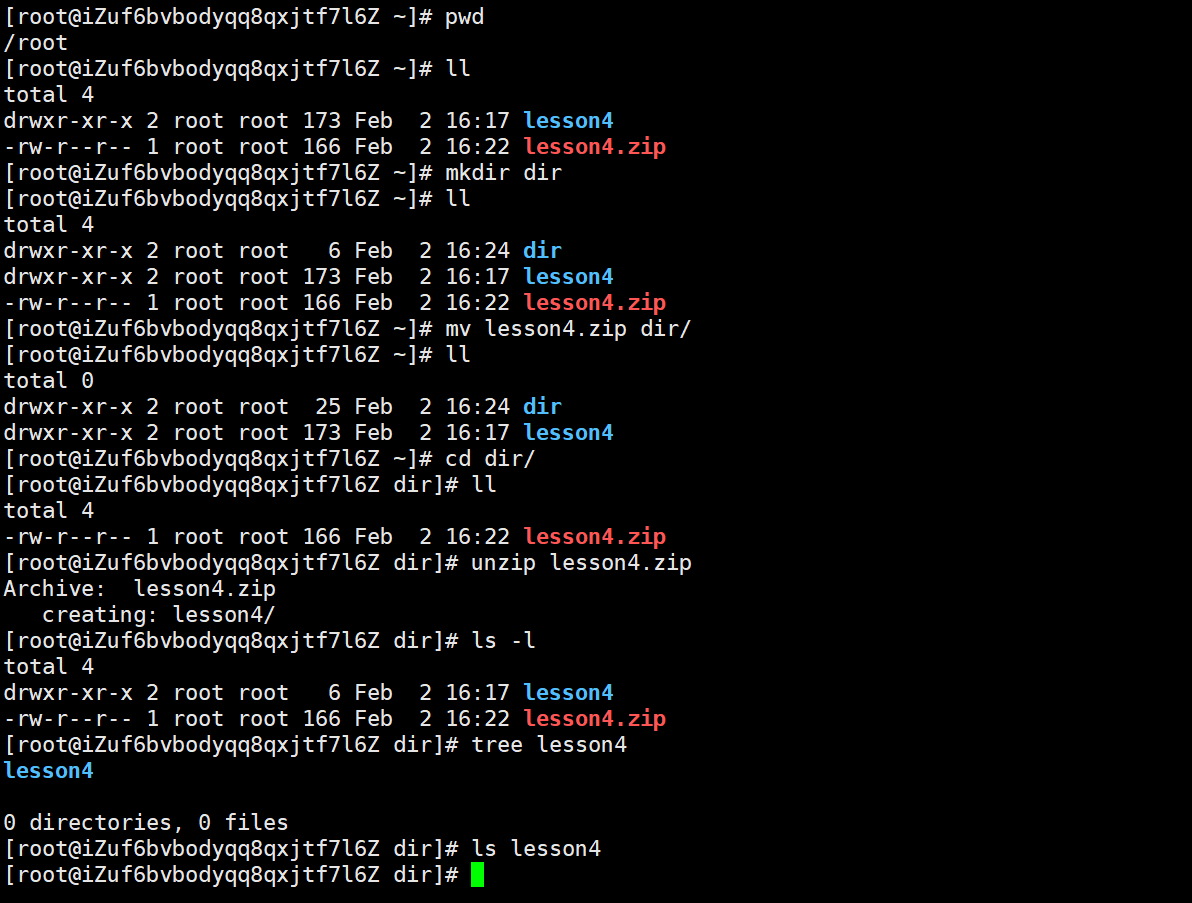
这是因为在前面打包压缩的过程就出现了问题,因为前面打包的是一个目录,打包普通文件用前面的做法是没有问题的
rm * -rf是将当前目录的内容全部删掉
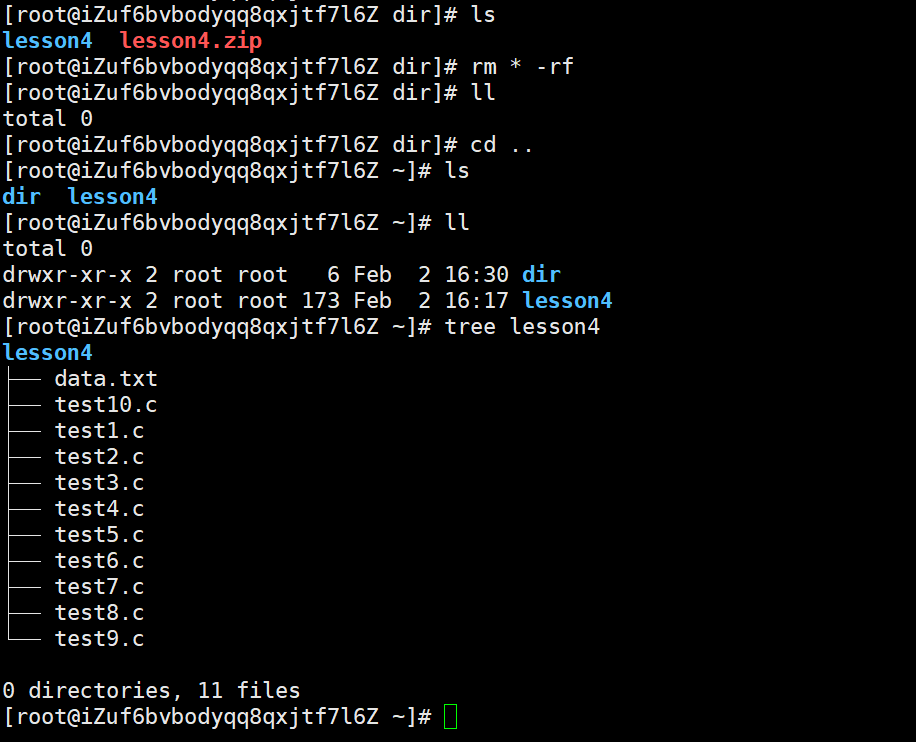
常用选项
- -r:递归处理,将指定目录下的所有文件和子目录一并处理
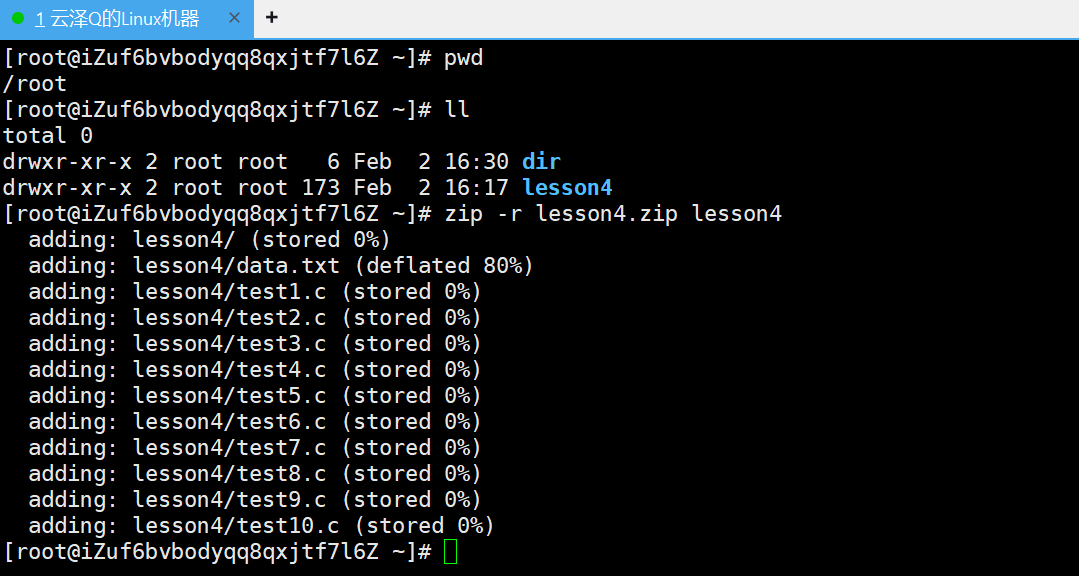
除了data.txt,其他文件都是空文件,所以压缩率为0,data的压缩率为百分之80
补充:zip和unzip指令并不一定是你Linux系统自带的命令,下面下载指令自取
cpp
//CentOS下
yum install zip unzip
//Ubuntu下
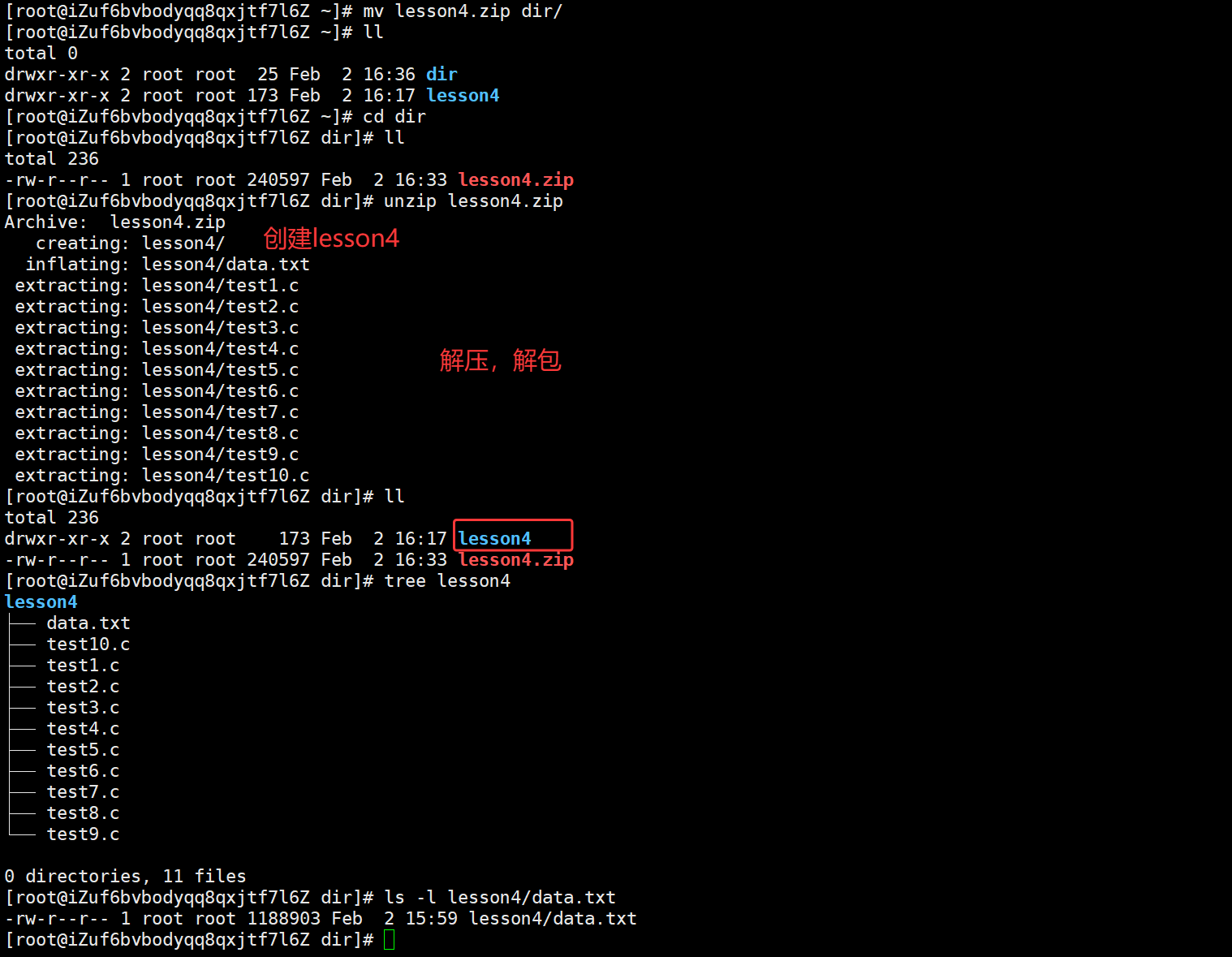
apt install zip unzip继续前面的内容,解压的时候会把所解压文件解压到当前路径上,若需要解压到指定路径,还需要一个参数-d
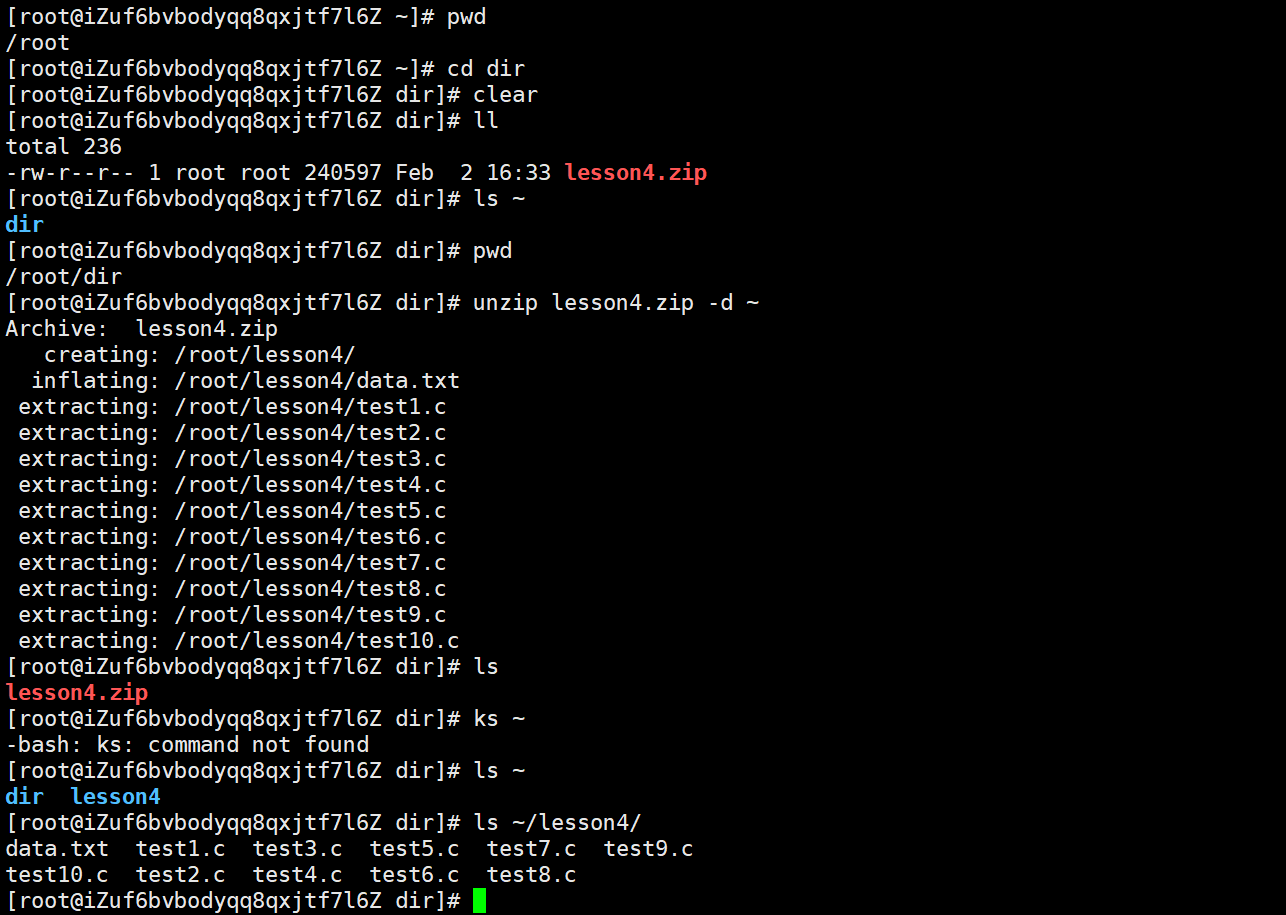
bash
unzip XXX.zip -d YYYY --- 指定路径解包解压打包压缩最重要的是打包压缩的时候是需要通过网络传递对应的压缩包,接下来说一下压缩包,怎么跨主机传输的问题(Windows 和 Linux 传递)以及 Linux 到 Linux之间传递压缩包的问题
场景:我现在远程连接的是上海的云服务器,在Windows上通过Xshell通过网络远程连接使用,现在的压缩包在云服务器上,现在要做的是将云服务器上的压缩包克隆拷贝到Windows上
这就要借助一个指令 sz lesson4.zip(可以理解为send的意思),
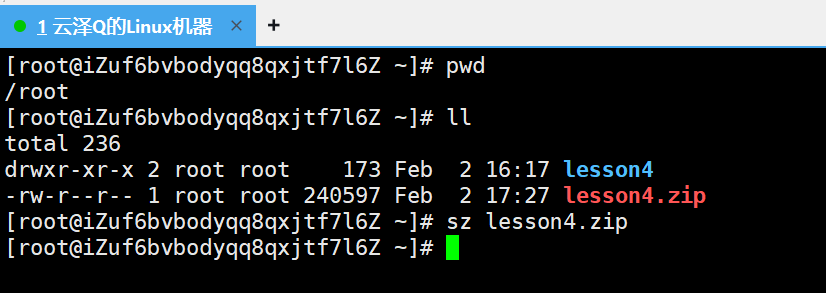
回车后Xshell会自动弹出本地Windows的窗口
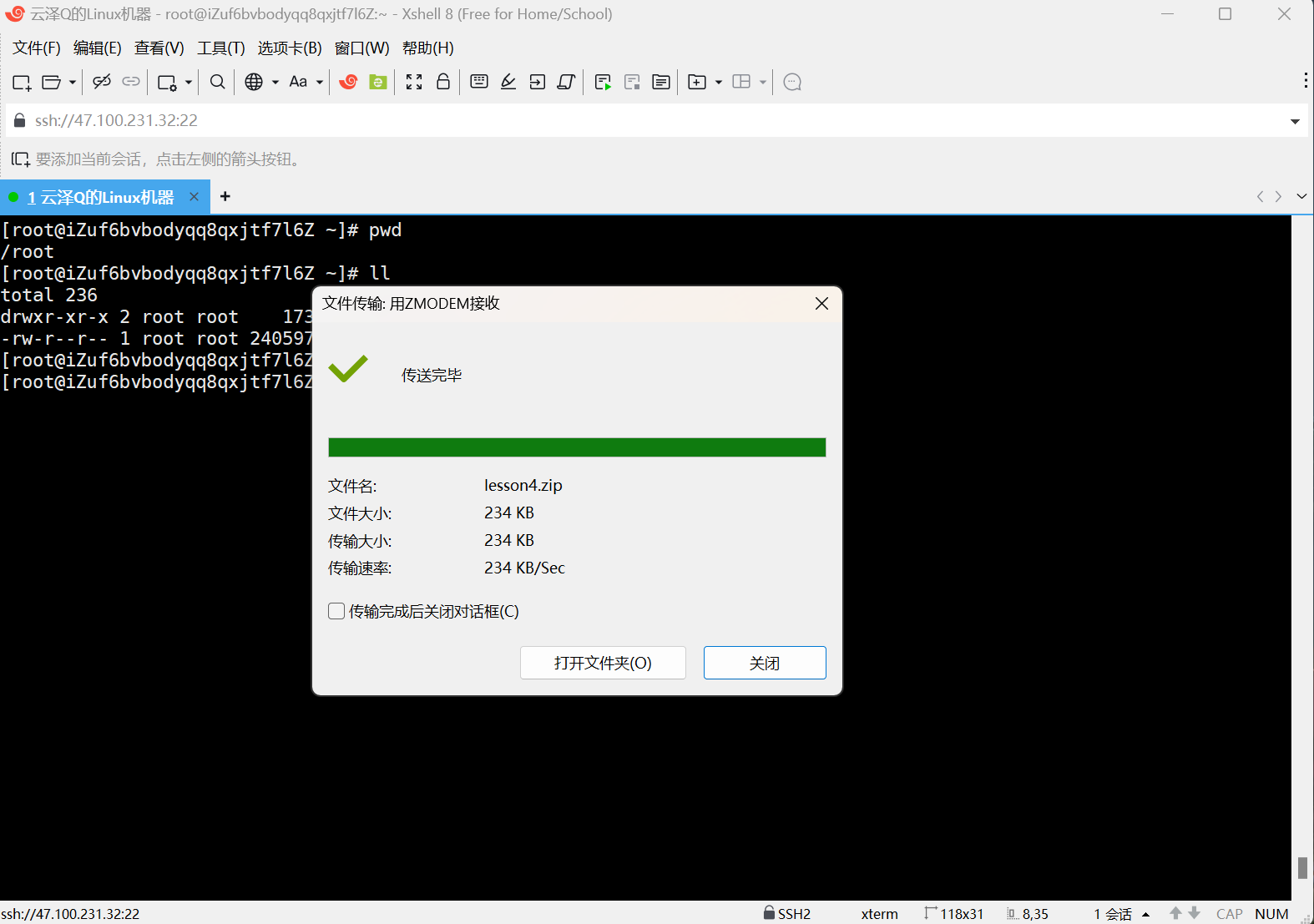
我这里选择桌面,点击确定后,Linux上指定的压缩包就传输到了Windows上,此时就可以在桌面上看到指定的文件了
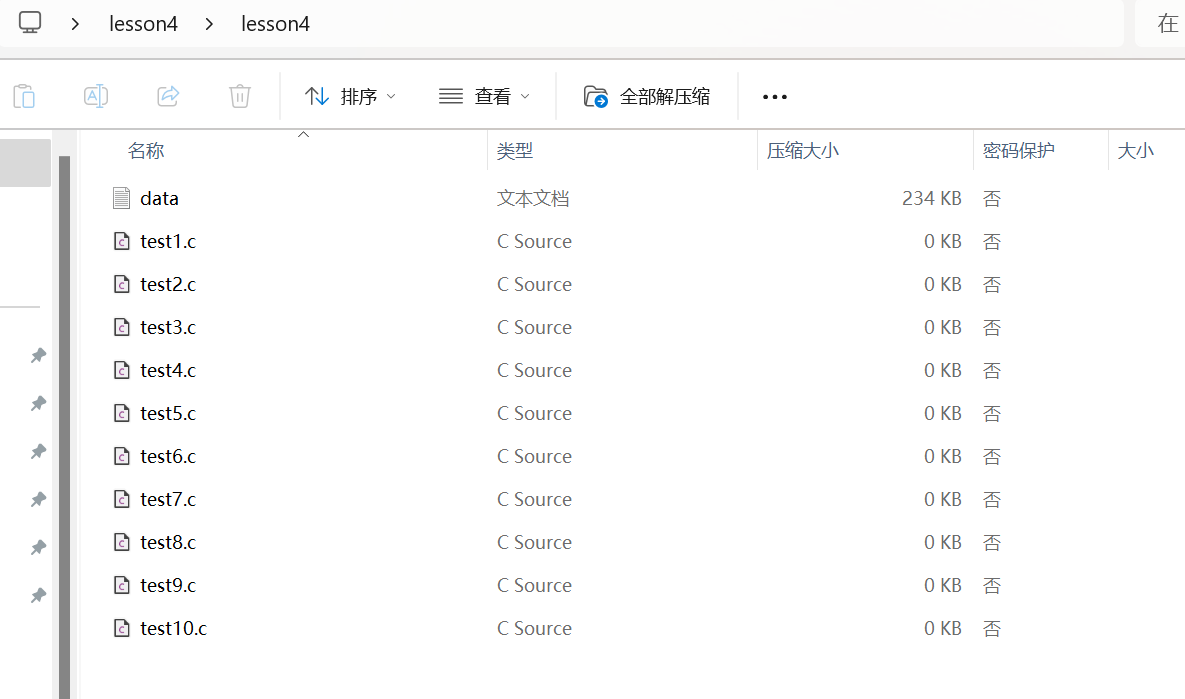
且Windows可以识别这个zip文件,现在的各种压缩包软件支持各种解压和算法,打开之后可以看到非常完美
回车后若显示command not found,则是系统未安装lrzez工具包,需要的兄弟下面指令自取
cpp
//CentOS
yum install -y lrzsz
//Ubuntu
apt install -y lrzsz文件传输工具 lrzsz 命令sz [文件名]:将指定文件从 Linux 服务器发送(下载)到本地客户端。
下面将Windows的压缩包传到Linux下,方法不仅一种
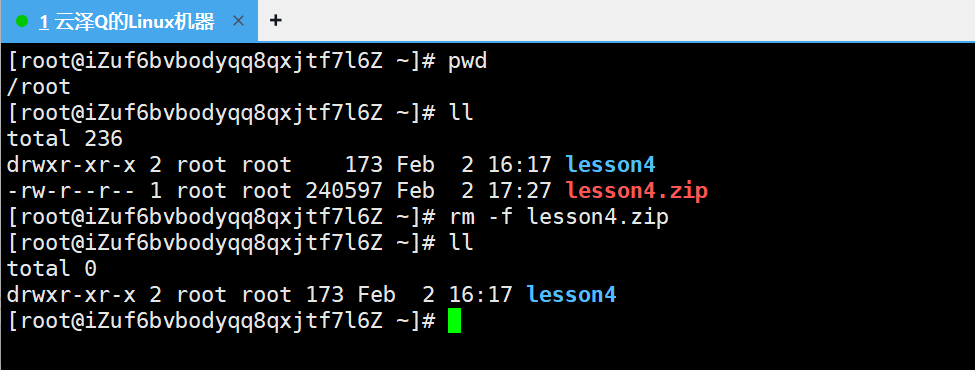
第一:直接拖拽
可以看到自动就将对应的压缩包文件传上来了,若是想使用指令操作,就是图中的rz -E,此时会弹出一个窗口,选择对应的文件打开即可
传二进制文件(.zip就是一种二进制文件)建议带上-E,若是乱码了就直接拖拽文件,Linux会自动选择选项
二、tar 和 file 指令
在介绍 tar 指令之前先介绍 file 指令,file 指令的作用是查看一个文件的更详细内容
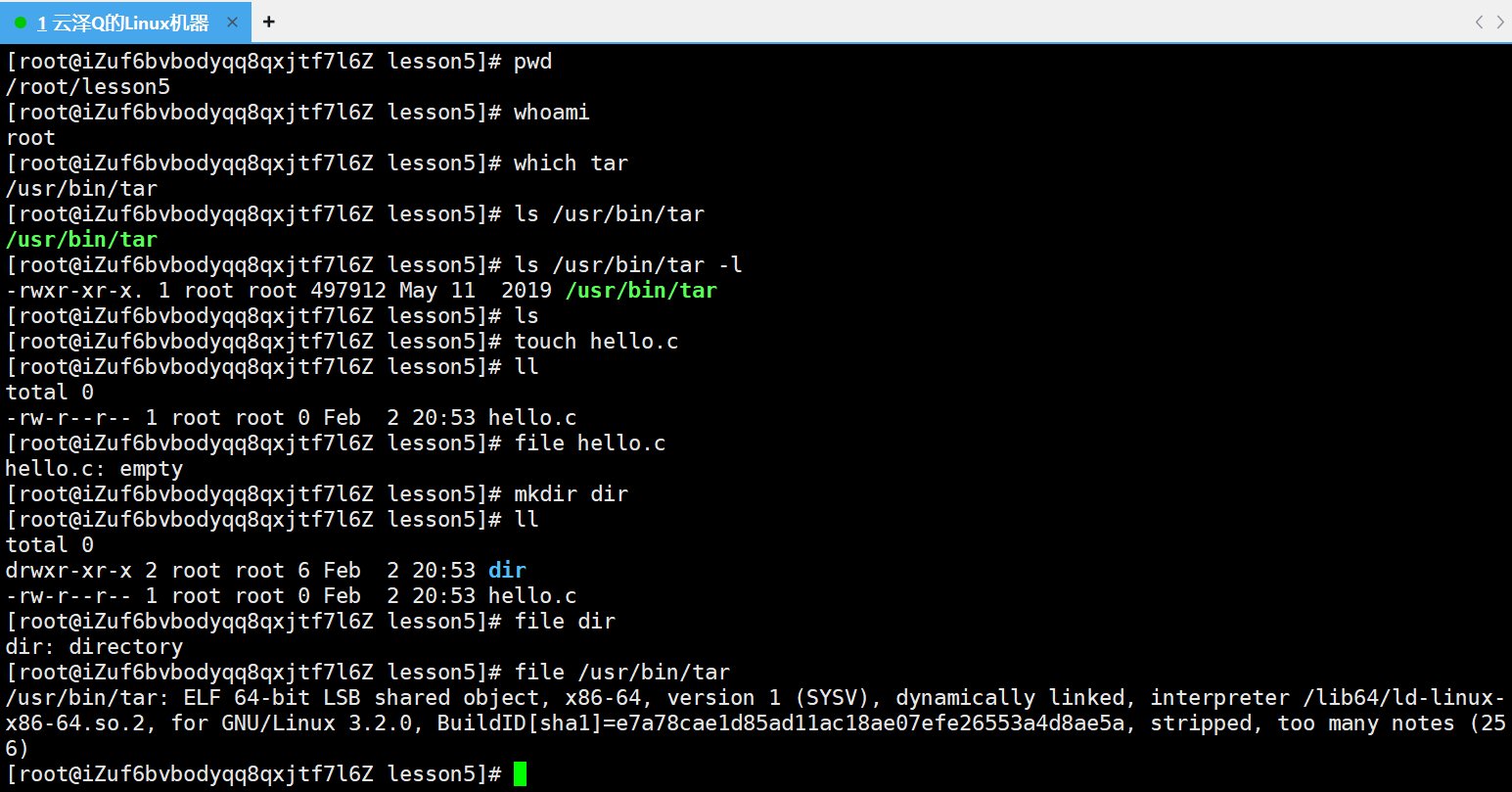
可以看到tar是一个X86 - 64位下的可执行程序(executable),也就是说该指令就是用C写的二进制可执行程序,我们平时自己编译形成的二进制程序用file命令查也是一个可执行程序,后面的一些信息在后续文章中都会顺带介绍
file指令就可以用来查一个文件是二进制程序,Linux下百分之90的命令都是用C/C++写的,但确实存在一些命令是脚本类的命令,还有例如yum就是用Python写的

tar 是 Linux 系统中最核心、最常用的归档(打包)工具 ,全称 Tape Archive,原生仅做打包(将多文件 / 目录整合为单个.tar文件,不压缩),但可配合 gzip 压缩算法实现打包 + 压缩一体化 ,生成 .tgz(即原.tar.gz)格式包 ------ 这是 Linux 最主流的压缩归档格式,比 zip 更适配 Linux 文件属性(权限、用户组等)保留。
.tgz 是 .tar.gz 的简写 / 缩写形式,二者完全等价 。Linux 系统会自动识别这两种后缀的文件为「tar 打包 + gzip 压缩」的归档包,使用上无任何区别 ,.tgz 仅为了书写便捷(少输入一个字符),实际工作中服务器上两种后缀都能见到,可随意替换使用。
一、核心基础
1. 核心定位
纯打包:将零散文件 / 目录整合为单个 .tar 归档文件,文件总大小基本不变 ;
打包 + gzip 压缩:在打包基础上调用 gzip 算法,生成 .tgz 压缩包,大幅减小体积(最常用);
解压:将 .tgz/.tar 包还原为原始文件 / 目录,支持指定解压路径。
2. 核心语法
tar 参数分必选主参数 (定义核心动作,三选一)和可选辅助参数(按需组合),语法格式:
cpp
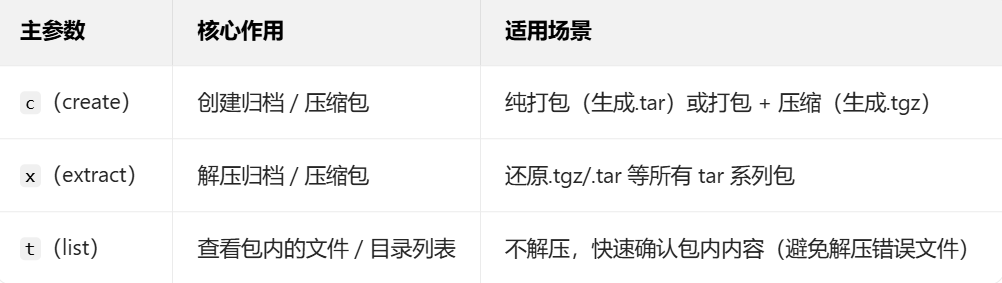
tar [主参数] [辅助参数] 生成的包名 要打包/解压的文件/目录二、必选主参数(核心动作,三选一)
tar 的核心功能由 3 个主参数定义,一次只能使用一个 ,是指令的基础:
三、高频辅助参数(按需组合,覆盖所有常用场景)
cpp
辅助参数 核心作用 搭配说明
f(file) 指定包名 必须跟在所有参数最后,紧跟生成 / 要解压的包名(最易踩坑点,记死!)
v(verbose) 压缩 / 解压过程中显示文件详情(如文件名、进度),日常交互场景常用;但不建议在后台执行(加&)时使用,否则会产生大量输出占用终端日志 带-v:交互执行时可直观看到处理过程,排错方便
不带-v:静默模式(在解压解包的过程中不会显示任何内容),无任何输出,适合后台执行、脚本自动化场景
z(gzip) 调用 gzip 算法压缩 / 解压 生成 / 解压.tgz格式(核心参数,必加)
C(directory) 指定解压目录 仅配合x使用,将包解压到指定路径(目录需提前存在)
--exclude 排除指定文件 / 目录 打包时跳过无关文件(如日志、临时文件)四、tar 经典高频用法
tar 最常用的是主参数 + 辅助参数 的固定组合,优先掌握 .tgz 格式(Linux 主流),以下按「打包 + 压缩、查看包内容、解压」分类,所有示例均基于 lesson5 目录,操作与原.tar.gz 完全一致。
场景 1:打包 + gzip 压缩(最常用,生成.tgz)
核心组合:tar zcvf 包名.tgz 要打包的文件/目录(z=gzip 压缩,c = 创建,v = 显示过程,f = 指定包名)
cpp
# 示例1:交互模式 - 将lesson5目录打包并压缩为lesson5.tgz,显示详细过程
tar zcvf lesson5.tgz lesson5
# 示例2:后台静默模式 - 后台打包lesson5目录,不显示过程(适合大文件/脚本执行)
tar zcf lesson5.tgz lesson5 &场景 2:查看.tgz 包内内容(不解压,生成 / 解压前确认)
核心组合:tar tvf 包名.tgz(自动识别压缩格式,无需额外加参数,直接查看)
cpp
# 示例:查看lesson5.tgz内的所有文件/目录及属性(权限、大小、时间)
tar tvf lesson5.tgz扩展:该命令也可直接查看纯打包的.tar 包,无需改参数,通用所有 tar 系列包。
场景 3:解压.tgz 包(分「默认路径」和「指定路径」,均为高频)
(1)解压到当前目录
核心组合:tar xvf 包名.tgz(新版 tar 自动识别 gzip 压缩,无需加 z,一键解压)
cpp
# 示例1:交互模式 - 解压lesson5.tgz到当前目录,显示解压过程
tar xvf lesson5.tgz
# 示例2:后台静默模式 - 后台解压lesson5.tgz,不显示过程
tar xf lesson5.tgz &(2)解压到指定目录(实用,避免覆盖当前文件)
核心组合:tar xvf 包名.tgz -C 目标目录(-C 必须大写,目标目录需提前用mkdir创建)
cpp
# 步骤1:创建目标解压目录(/tmp/lesson5,-p自动创建多级目录)
mkdir -p /tmp/lesson5
# 步骤2:交互模式 - 将lesson5.tgz解压到/tmp/lesson5目录,显示过程
tar xvf lesson5.tgz -C /tmp/lesson5
# 步骤3:后台静默模式 - 后台解压到指定目录,不显示过程
tar xf lesson5.tgz -C /tmp/lesson5 &五、tar 实用扩展用法(解决高频实际需求)
1. 打包压缩时排除指定文件 / 目录
核心参数:--exclude=要排除的内容,适合打包项目时跳过日志、临时文件、缓存等无用内容,减小包体积
cpp
# 示例:打包lesson5目录为lesson5.tgz,排除其中的log日志目录和*.tmp临时文件
tar zcvf lesson5.tgz lesson5 --exclude=lesson5/log --exclude=*.tmp2. 仅解压.tgz 包内指定的单个文件 / 目录
语法:tar xvf 包名.tgz 包内的文件/目录路径(路径需和包内一致,可先用tar tvf查看确认)
cpp
# 步骤1:先查看包内内容,确认目标文件的完整路径
tar tvf lesson5.tgz
# 步骤2:仅解压包内的lesson5/test.sh脚本到当前目录
tar xvf lesson5.tgz lesson5/test.sh六、新手必避 3 个核心坑
- f参数必须放最后 :f是指定包名的参数,必须跟在所有参数末尾 ,否则直接报错(如
tar zcfv xxx.tgz错误,正确是tar zcvf xxx.tgz); - 后台执行时避免用
-v:-v会产生大量输出,后台运行时建议使用静默模式(不带-v),避免日志溢出或终端阻塞; - -C指定解压目录时,目录需提前存在 :如果目标目录不存在,解压会直接失败,需先用
mkdir -p创建(-p表示自动创建多级目录,如/tmp/a/b/c)。
前面是实现.zip包在Linux和Windows之间互传,.tgz包也同样是可以的,且方式一样
现在的目标是将Linux中的压缩包传递到另一台Linux机器,这就要借助一个名为scp(远程拷贝)的指令了
三、scp 指令
如图现在有两台机器,左边这一台白色的是ubuntu的机器,右边黑色的是centos的机器
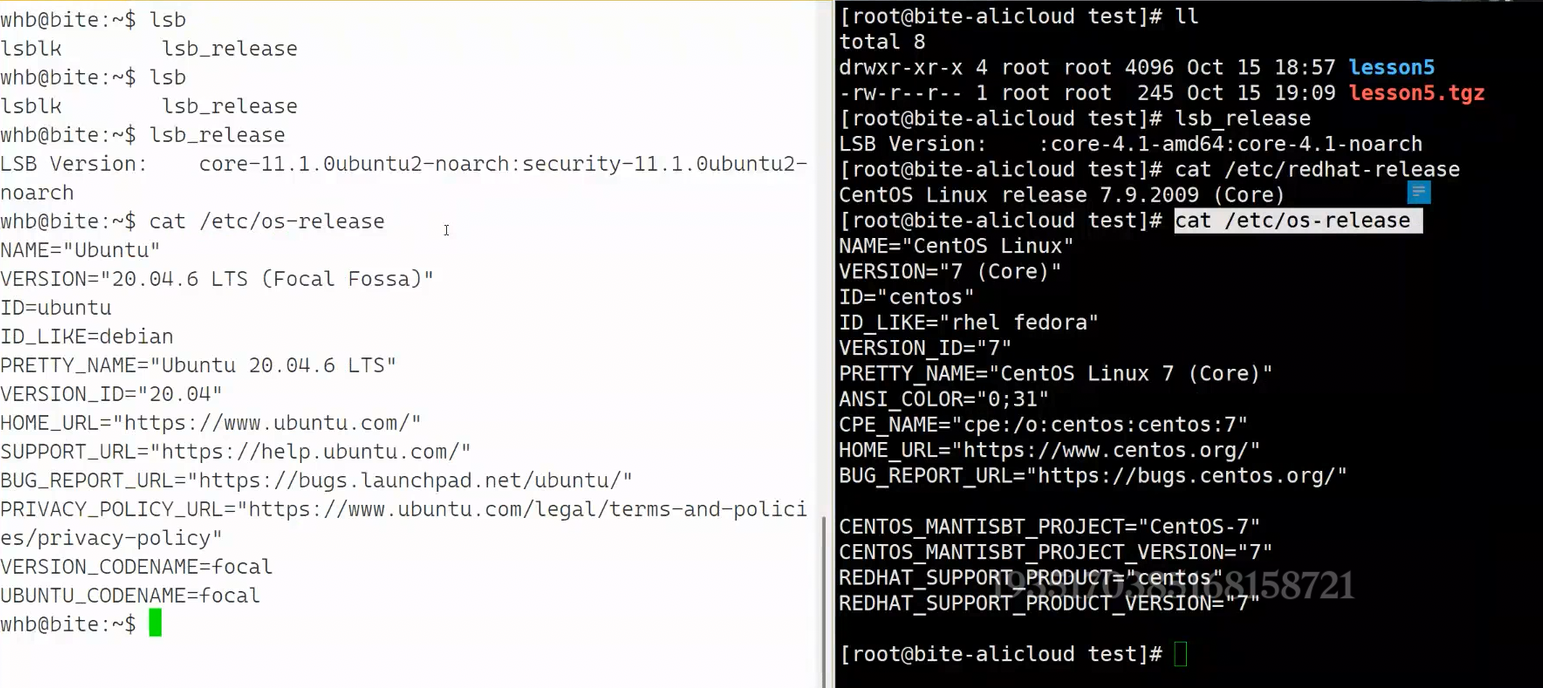
在Linux中,要看自己机器具体的发行版本,可以使用cat /etc/os-release这条通用指令,os-release是个小的配置文件,既然是个文件就可以用cat命令将该文件的内容输出,它里面记录了这台Linux机器用的哪个发行版
左边centos是超级用户,右边ubuntu是普通用户,现在要做的是将左边lesson5的压缩包,从IP地址为120...的机器拷贝到右边IP地址为8.137...的机器的图示目录下
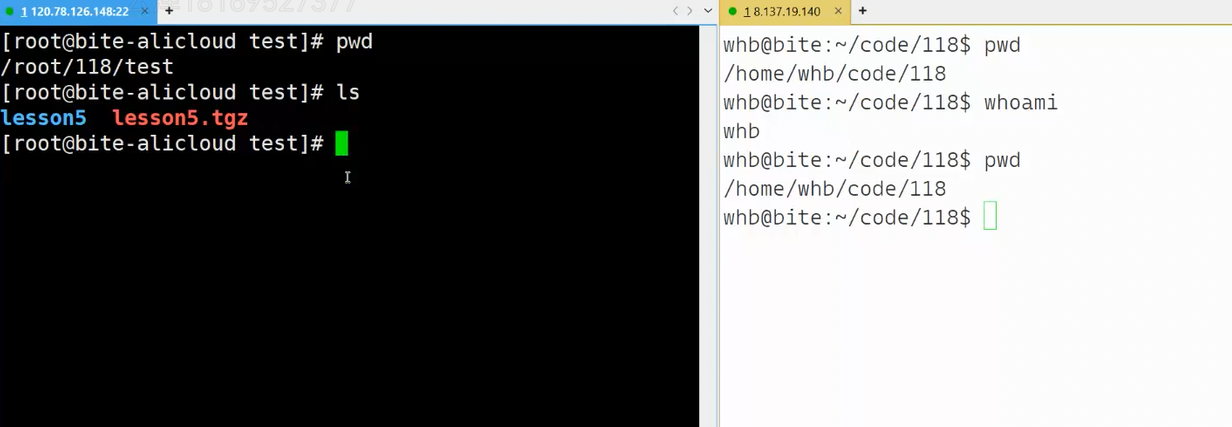
scp(Secure Copy)是基于 SSH 协议的安全文件传输工具,用于在 Linux 服务器之间传输文件。scp的命令很简单,就是从src拷贝到dst,现在src就是centos当前目录下的lesson5.tgz,dst是另一台ubuntu机器的公网IP
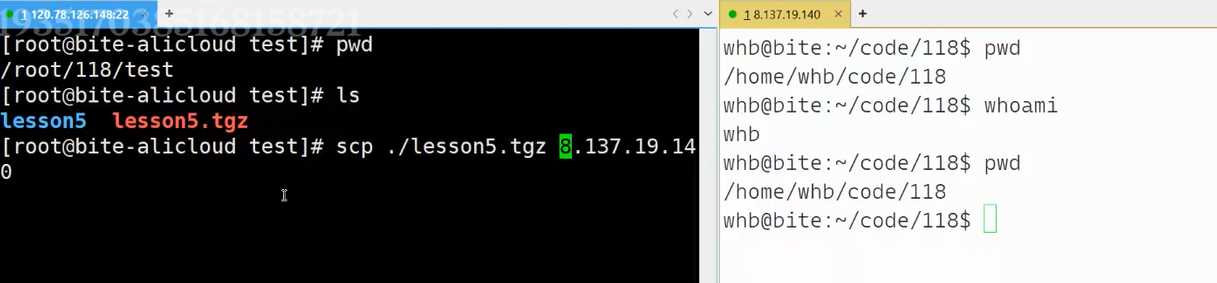
若是如图这样直接拷贝就是默认以左边机器的管理员身份去右边机器拷贝,省略目标登录用户,scp 会默认使用本地当前登录的用户名(左侧终端是 root)作为目标主机的登录用户。
若使用scp ./lesson5.tgz whb@8.137.19.140:/home/whb/code/118,以 whb 身份(指的是目标服务器(IP 为 8.137.19.140)上的系统用户)登录目标主机,向 /home/whb/code/118 写入文件。由于目标路径是 whb 的个人目录,whb 默认拥有写入权限,传输成功率最高。
若使用scp ./lesson5.tgz root@8.137.19.140:/home/whb/code/118明确指定目标登录用户为 root(这个 root 和左侧终端的 root是两个独立的用户,它们分别属于不同的服务器,只是名称相同),用最高权限用户登录目标主机,日常不建议,原因如下:
- 登录风险:生产环境中,为了安全,通常会禁止 root 用户直接通过 SSH 登录,所以这条指令在规范的生产环境里大概率会直接失败。
- 权限混乱:用 root 传输文件时,写入的文件默认会属于 root 用户,而不是目标路径的所有者 whb,这会导致 whb 后续无法正常读写这个文件,破坏了目录的权限结构。
上面只是拷贝过去了,还没有指定路径,所以后续还要跟个:指定目标机器的路径

之后回车就要输入目标机器的登陆密码,如图此时就完成了百分之百的拷贝
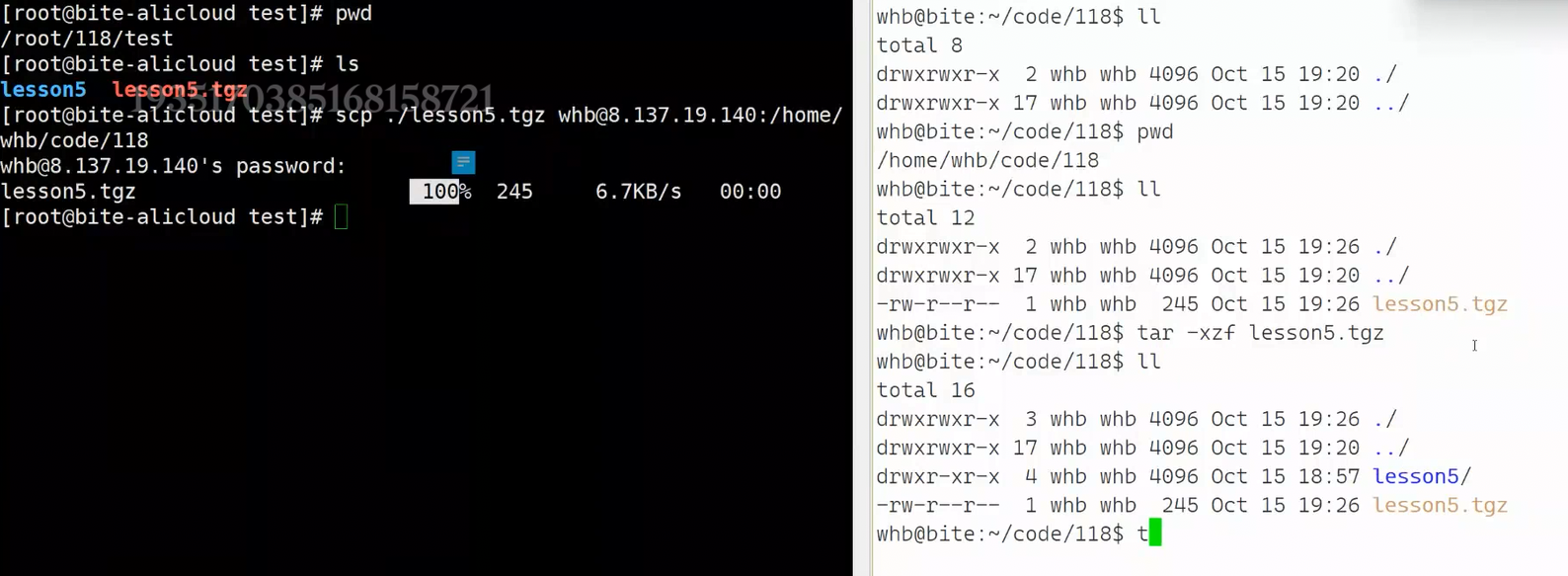
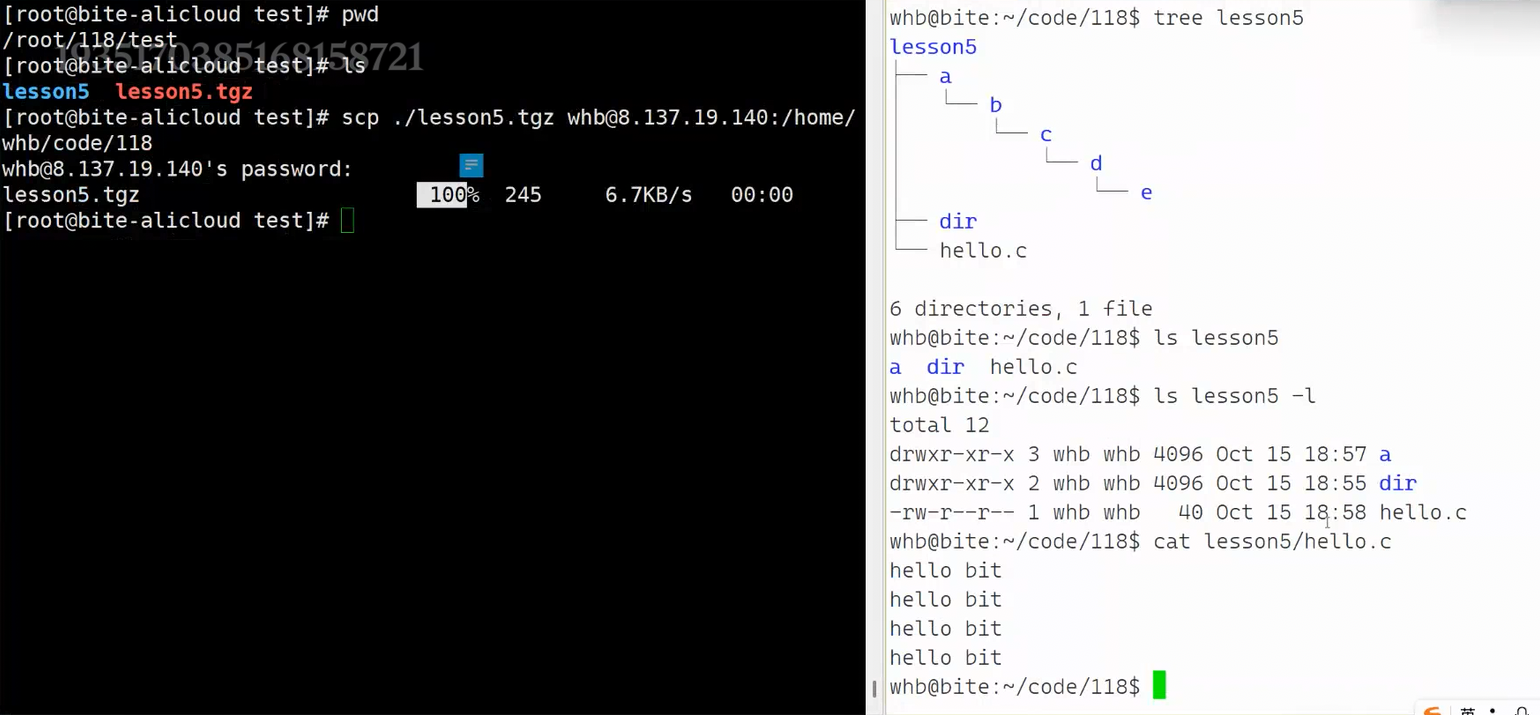
补充一个细节:
在Linux中输入密码是不会回显的(为了保护密码的安全),即从键盘输入的信息不会显示在显示器上,在我们平时写程序时 scnaf("%d", &a),当从键盘输入数据是把数据输入到C程序内部,然后顺便回显到显示器上
四、bc 指令
bc指令简单理解就是Linux中的计算器 ,bc 默认识别十进制 ,可通过参数配置输入 / 输出进制(2-16 进制为主),默认做整数运算 ,需手动设置小数位数才能实现浮点数精确计算,整体使用灵活,支持交互式 和非交互式两种运行方式。
- 交互式运行(手动输入计算式)
直接在终端输入 bc 即可进入交互式计算界面,输入表达式后按回车出结果,支持连续输入多个计算式,退出方式:quit 或 Ctrl+D。
cpp
bc # 进入交互式界面
bc 1.07.1
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
1+2*3 # 输入计算式,支持四则运算优先级
7
10/3 # 默认scale=0,整数除法,取整
3
quit # 退出- 非交互式运行(管道 / 重定向传参)
通过echo 计算式 | bc管道传参,或通过文件重定向(bc < 计算文件),适合单次快速计算,是最常用的方式。
cpp
# 单次快速计算
echo "10+20*5" | bc
110关键内置参数(核心)
bc 的核心能力由内置参数控制,需在计算式中显式声明(交互式)或随管道传入(非交互式),最常用的是 scale、ibase、obase。
cpp
参数 作用 默认值 注意事项
scale=n 设置浮点数保留的小数位数,n 为非负整数 0 scale=0 时做整数运算(除法取整)
ibase=n 设置输入数据的进制,n 取值 1-16(1 等价于 10) 10 输入超过进制的数字会报错
obase=n 设置输出结果的进制,n 取值 2-999(常用 2/8/10/16) 10 obase 会受 ibase 影响,需先设 ibase核心参数使用示例
cpp
# 1. scale:设置小数位数(浮点数运算核心)
echo "scale=2; 10/3" | bc # 保留2位小数
3.33
echo "scale=5; (2.5+3.8)*1.2" | bc # 复杂浮点数运算
7.56000
# 2. ibase+obase:进制转换(重点:先设ibase,再设obase)
echo "ibase=2; obase=10; 1010" | bc # 二进制1010转十进制
10
echo "ibase=10; obase=16; 255" | bc # 十进制255转十六进制
FF
echo "ibase=2; obase=8; 110101" | bc # 二进制110101转八进制
65这个指令日常中很少使用,这里点到为止
五、uname -r 指令
语法:uname【选项】
功能:uname用来获取电脑和操作系统的相关信息
补充说明:uname可显示Linux主机所用的操作系统的版本、硬件的名称等基本信息
常用选项:
- -a 或 -all 详细输出所有信息,依次为内核名称,主机名,内核版本号,内核版本,硬件名,处理器类型,硬件平台类型,操作系统名称
- lsb_release -a:查看操作系统版本
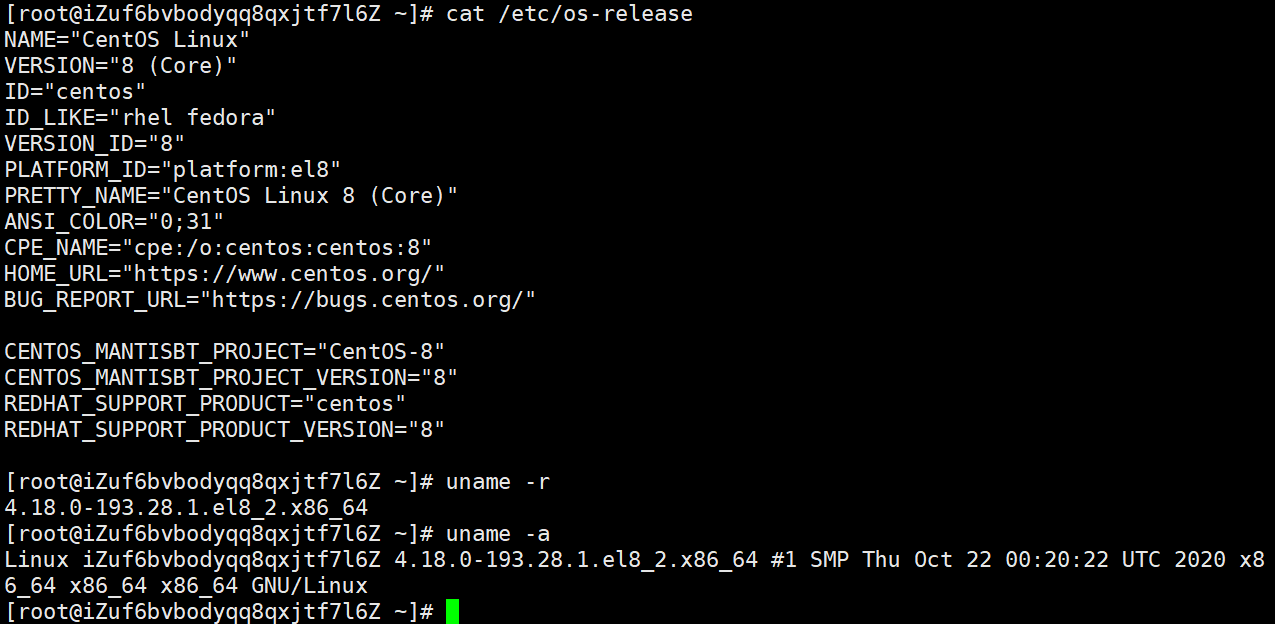
uname -r:精准定位内核版本与硬件架构,以图中4.18.0-193.28.1.el8_2.x86_64为例
-
4.18.0:内核的主版本。次版本。修订版
-
-193.28.1:发行商的补丁版本号(CentOS 等发行版对上游内核的定制更新批次)
-
el8_2:发行版的版本标识,el8:代表 CentOS/RHEL 8 系列,_2:CentOS 8 的第 2 个小版本更新
-
x86_64:硬件架构标识,这是最关键的信息:x86是 32 位指令集的统称,_64表示扩展到 64 位,也叫AMD64(因为是 AMD 率先推出的 64 位扩展,Intel 后来兼容并改名为EM64T,最终统一叫x86_64)。
uname -a:系统 "全量身份卡",一次性输出内核、硬件、主机名等所有关键信息,是远程登录服务器、排查兼容性问题时的 "第一命令"。
以图中Linux iZuf6bvbodyqq8qxjftf7l6Z 4.18.0-193.28.1.el8_2.x86_64 #1 SMP Thu Oct 22 00:20:22 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux为例
cpp
Linux:内核名称(表明这是 Linux 内核,而非 FreeBSD、Solaris 等其他 Unix-like 内核)
iZuf6bvbodyqq8qxjftf7l6Z:主机名(云服务器默认生成的随机名称,可通过hostname命令修改)
4.18.0-193.28.1.el8_2.x86_64:内核版本(和uname -r完全一致)
#1 SMP Thu Oct 22 00:20:22 UTC 2020:内核编译信息
#1:该内核版本的编译次数
SMP:表示内核支持对称多处理(多 CPU / 多核)
Thu Oct 22 00:20:22 UTC 2020:内核编译的时间(UTC 时区)
x86_64:硬件架构(CPU 指令集)
x86_64:硬件平台(主板等底层硬件的平台类型)
x86_64:处理器类型(CPU 的具体指令集兼容类型)
GNU/Linux:操作系统名称(表明是 "GNU 工具链 + Linux 内核" 的完整系统,而非纯内核)cat /etc/os-release:最稳妥的发行版查询命令,直接读取系统的发行版配置文件,输出发行版的名称、版本、标识等信息,是脚本中判断发行版的 "黄金标准"。
cpp
NAME="CentOS Linux":发行版的友好名称
VERSION="8 (Core)":发行版的版本描述(Core表示基础版,还有Server、Workstation等变体)
ID="centos":发行版的短标识(脚本判断的核心变量,比如if [ "$ID" = "centos" ]; then yum install ...; fi)
ID_LIKE="rhel fedora":兼容的发行版(CentOS 基于 RHEL,RHEL 和 Fedora 同属红帽生态)
VERSION_ID="8":版本号的数字标识(脚本中用于版本判断,比如if [ "$VERSION_ID" -ge 8 ]; then ...)
PLATFORM_ID="platform:el8":平台标识(el8代表 RHEL 8 兼容平台,用于软件仓库配置)
PRETTY_NAME="CentOS Linux 8 (Core)":终端显示用的友好名称
HOME_URL/BUG_REPORT_URL:官方网站和 bug 提交地址(用于问题反馈)5.1 从 x86_64 读懂芯片与体系架构演进
基于以上内容,再补充一些历史知识:
在指令里反复看到的 x86_64 不只是一串字符,它背后藏着整个电脑芯片从 8 位到 64 位的 "内存突围战"。早在上世纪 70 年代,Intel 8080 这类 8 位芯片只能处理少量数据,内存最多几 KB,用在早期计算器和游戏机上;到 1978 年,Intel 推出 8086 芯片,这就是 x86 架构的起点,16 位的处理能力让内存支持到 1MB,直接奠定了 PC 的硬件基础;1985 年 32 位的 80386 芯片登场,内存上限一举突破到 4GB,Windows 95、XP 这些我们熟悉的系统都是 32 位的,这时 AMD 也开始做兼容 x86 的芯片,正式和 Intel 拉开竞争。
真正的转折点在 2003 年:32 位系统最多只能用 4GB 内存,满足不了大型软件和服务器的需求。AMD 率先推出 x86_64(AMD64)架构解决了这个痛点,而 Intel 原本想推自己的 Itanium 架构(IA-64),却因为生态不成熟没人买账,最后只能兼容 AMD 的 x86_64(改名叫 EM64T),这才有了现在统一的 64 位标准。
说到这里就不得不提 Intel 和 AMD 这对 "相爱相杀" 的老对手:Intel1968 年成立,靠 8086、80386 成为 PC 芯片霸主,后来的 "奔腾" 系列家喻户晓,2006 年推出的 "酷睿" 系列至今仍是主流;AMD1969 年成立,早期给 Intel 做代工,后来转向兼容 x86 芯片,2003 年的 x86_64 打了 Intel 一个措手不及,2017 年 "锐龙" 系列发布后性能更是追上甚至反超 Intel,现在两家在桌面和服务器芯片上的竞争还在持续。
聊完电脑芯片,再看手机端,这里是 ARM 架构的 "低功耗逆袭" 主场。ARM 架构 1985 年诞生于英国,主打低功耗,早期用在功能机和 PDA 上,比如诺基亚的 Symbian 系统就基于它。进入智能手机时代后,高通骁龙基于 ARM 公版架构定制,从 MSM 系列到现在的 8 Gen 系列统治了安卓高端市场;苹果 A 系列从 A4(iPhone 4)到 A17 Pro,靠自研架构(基于 ARM)性能吊打同期安卓芯片;华为麒麟从 K3V2 到麒麟 9000,也是自研 + 公版的路线,后来受制裁影响暂时停更;联发科天玑则从低端崛起,现在天玑 9300 等高端芯片已经能和骁龙抗衡。2011 年 ARM 推出 64 位的 ARMv8 架构,2014 年苹果率先在 A7 芯片(iPhone 5s)上用上 64 位,倒逼安卓阵营跟进,现在手机芯片已经全面进入 64 位时代。
芯片升级了,软件也得跟着跑,这就像一场 "程序员接力赛"。电脑端从 16 位到 32 位,DOS 是 16 位,Windows 95 开始支持 32 位,早期 32 位系统还能兼容 16 位程序;从 32 位到 64 位时,64 位软件能利用更大内存,比如游戏、视频剪辑这类吃资源的应用,但早期很多 32 位软件没适配,所以系统都留了兼容层,现在新软件基本都是 64 位的。手机端从 32 位到 64 位,安卓从 5.0 开始支持,2019 年谷歌要求新应用必须支持 64 位;苹果更干脆,从 iOS 11 开始只支持 64 位应用。核心逻辑很简单:芯片升级到 64 位后,软件必须编译成 64 位才能发挥性能,否则只能在兼容层里 "降速运行"。
六、Linux中的常用热键
一、终端效率热键
- Ctrl + C
✅ 作用:强制终止当前卡住或异常运行的命令 / 程序。
💡 场景:比如执行了无限循环的脚本、下载进度停滞的命令时,按这个组合键可以立即中断操作,回到命令行。 - Ctrl + R
✅ 作用:反向搜索历史命令,输入关键词就能快速定位之前用过的命令。💡 场景:忘记完整命令但记得关键词时,按 Ctrl+R 后输入关键词,会自动匹配最近的历史命令,按回车直接执行,按 Ctrl+G 可退出搜索。 - Ctrl + D
✅ 作用:优雅退出当前登录会话或交互式终端(效果和输入 exit 一致)。
💡 场景:远程 SSH 登录服务器后,按这个键可直接断开连接;断开连接后再按这个键就会关闭Xshell - Tab 键
✅ 作用:命令 / 路径自动补全,是终端里最常用的效率热键。
💡 场景:输入命令前几个字符(如 yum in)按 Tab,会自动补全为 yum install;输入路径前几个字符(如 /et)按 Tab,会补全为 /etc。如果有多个匹配项,按两次 Tab 会列出所有选项。
七、history 指令
✅ 核心作用:查看、搜索、重复执行历史命令,Linux 默认保存最近 1000 条记录(可通过环境变量修改),历史命令存储在用户家目录的 ~/.bash_history 文件中。
基础用法
cpp
history # 显示所有历史命令(带序号)
history 10 # 只显示最近10条历史命令
history | grep "yum" # 搜索包含"yum"的历史命令八、关机
首先要明确一个核心要点:云服务器 的核心特性就是 7×24 小时永不关机 。我们日常能随时随地刷视频、逛淘宝、使用各类网络服务,本质就是因为各大互联网公司的后台服务器,始终保持 7×24 小时 的运行状态。一般企业花十几万采购一台物理服务器 后,只要完成上电启动,原则上这台服务器在其整个硬件生命周期内,都会保持永不断电、永不关机 的状态,而这类服务器搭载的操作系统几乎都是 Linux------ 究其原因,正是依托 Linux 开源、稳定、高可靠 的强大特性,它的无故障运行周期能以年为单位,这一点是 Windows 系统 完全做不到的,也正因如此,Linux 才成为云服务器、企业后台服务器的首选系统,支撑起持续不断的网络服务需求。
我们平时操作云服务器,只是通过 Xshell 这类远程连接工具实现远程操控,当我们用完服务器、关掉 Xshell 这个远程连接设备时,云服务器本身并不会停止运行 ;就像我们不刷抖音、不看短视频时,那些视频内容依然存储在字节跳动的服务器上,服务器会持续为所有用户提供访问服务。
只有针对本地的 Linux 机器 ,比如 Windows 上安装的 Linux 虚拟机 、企业本地部署无需 7×24 运行的物理 Linux 服务器,才会用到关机操作。如果是带图形化界面 的 Linux 虚拟机 / 物理机,在 Linux 系统下也能像 Windows 一样,直接用鼠标完成关机操作;而不带图形化界面的 Linux 系统,关机则完全依靠指令实现。Linux 中的关机指令主要有两个,一个是 halt,另一个是 shutdown,需要注意的是,关机属于系统核心操作,必须拥有最高管理员权限 ,只有 root 账号才能执行关机指令,普通账号没有权限进行该操作。
其实在 Windows 系统中,也能通过命令行实现关机操作,在 cmd 命令窗口 中,Windows 的关机指令同样是 shutdown,我们可以输入shutdown /?查看该指令的手册,手册里会列出该指令的各类可选参数,满足不同的关机需求,和 Linux 的关机指令形成了有趣的同名差异。
这里必须重点强调:如果把部署在云服务器上的 Linux 系统关机,是绝对无法通过 Linux 指令实现开机 的 ------ 因为所有 Linux 指令的运行,都建立在操作系统正常启动、运行 的基础上,操作系统关机后,指令失去运行环境,自然无法执行。而我们采购的云服务器属于远程服务器 ,一旦手动关机,想要再次开机,就必须进入对应云厂商的云服务器管理后台 ,通过厂商提供的远程控制功能,借助网络完成开机操作,这是远程云服务器独有的开关机逻辑。
语法 :shutdown【选项】
常见选项:
-h:将系统的服务停掉后,立即关机-r:在将系统的服务停掉之后就重新启动-t sec:-t后面加描述,亦即 过几秒关机 的意思
结语
