Redis

一 关系型数据库和 NoSQL 数据库
1.1 数据库主要分为两大类:关系型数据库与 NoSQL 数据库
关系型数据库,是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库中的数据主流的 MySQL、Oracle、MS SQL Server 和 DB2 都属于这类传统数据库。
NoSQL 数据库,全称为 Not Only SQL,意思就是适用关系型数据库的时候就使用关系型数据库,不适用的时候也没有必要非使用关系型数据库不可,可以考虑使用更加合适的数据存储。主要分为临时性键值存储(memcached、Redis)、永久性键值存储(ROMA、Redis)、面向文档的数据库(MongoDB、CouchDB)、面向列的数据库(Cassandra、HBase),每种 NoSQL 都有其特有的使用场景及优点。
1.2 为什么还要用 NoSQL 数据库呢?
主要是由于随着互联网发展,数据量越来越大,对性能要求越来越高,传统数据库存在着先天性的缺陷,即单机(单库)性能瓶颈,并且扩展困难。这样既有单机单库瓶颈,却又扩展困难,自然无法满足日益增长的海量数据存储及其性能要求,所以才会出现了各种不同的 NoSQL 产品,NoSQL 根本性的优势在于在云计算时代,简单、易于大规模分布式扩展,并且读写性能非常高
1.3 RDBMS和NOSQL的特点及优缺点:
1.4 总结
(1)数据库分类概述
⭐ 关系型数据库(RDBMS)
-
建立在关系模型基础上,使用集合代数等数学概念处理数据
-
主流产品:MySQL、Oracle、MS SQL Server、DB2
⭐ NoSQL 数据库(Not Only SQL)
-
含义:适用关系型数据库时用关系型,不适用时选择更合适的存储方案
-
分类:
-
临时性键值存储:memcached、Redis
-
永久性键值存储:ROMA、Redis
-
面向文档的数据库:MongoDB、CouchDB
-
面向列的数据库:Cassandra、HBase
-
(2)为什么要使用 NoSQL? ⭐⭐
🔴 传统关系型数据库的痛点:
-
单机性能瓶颈:数据量增大后,单台服务器性能达到上限
-
🔴 扩展困难:纵向扩展(升级硬件)成本高,横向扩展(分布式)技术复杂
⭐⭐ NoSQL 的核心优势:
-
简单、易于大规模分布式扩展
-
读写性能非常高
-
适应云计算时代需求
💡 生活例子:就像一家小餐馆,生意好了之后,传统做法是把厨房设备全换成顶级的(纵向扩展),但成本高且总有上限;而 NoSQL 的做法是开连锁店,每个店负责一片区域,客人去哪都很快(横向扩展),既便宜又能无限扩张。
(3)RDBMS 与 NoSQL 详细对比
🔴🔴 特点对比
| 维度 | 关系型数据库 | NoSQL 数据库 |
|---|---|---|
| 数据模型 | ⭐ 基于关系模型,结构化存储,有完整性约束 | 非结构化存储 |
| 存储方式 | 基于二维表及表间联系,需连接、并、交、差、除等操作 | 基于多维关系模型 |
| 查询语言 | ⭐ 采用SQL(结构化查询语言) | 各产品语法不统一 |
| 一致性要求 | 🔴 需要事务 甚至是强一致性 | 各有特色使用场景 |
💡 生活例子(二维表 vs 多维模型):
关系型数据库就像 Excel 表格,学生信息一个表、课程一个表、成绩一个表,要查"张三的高数成绩"需要用 VLOOKUP 把三个表连起来(JOIN 操作)。
NoSQL就像微信收藏夹,一条收藏里可以同时包含文字、图片、链接、位置,所有信息都在一个"文档"里,不需要连表。
⭐⭐ 优点对比
| 关系型数据库 | NoSQL 数据库 |
|---|---|
| ⭐ 保持数据一致性(事务处理 ACID) | ⭐⭐ 高并发、大数据下读写能力强 |
| ⭐ 支持 JOIN 等复杂查询 | ⭐⭐ 基本支持分布式,易于扩展、可伸缩 |
| ⭐ 通用化,技术成熟 | ⭐ 简单,弱结构化存储 |
💡 生活例子(事务一致性) : 银行转账是典型的关系型数据库场景------A 转 1000 元给 B,必须保证 A 扣钱和 B 加钱同时成功或同时失败 。就像你去超市买东西,付钱和拿商品必须一起完成,不能只付钱不拿货,也不能只拿货不付钱。这就是 ACID 事务。
💡 生活例子(高并发读写): 双十一零点,几亿人同时抢购,就像春运火车站突然涌入几万人。关系型数据库像只有一个售票窗口,大家必须排队(锁机制);而 Redis 这样的 NoSQL 像开了 100 个窗口,大家分散买票,速度自然快得多。
🔴🔴🔴 缺点对比
| 关系型数据库 | NoSQL 数据库 |
|---|---|
| 🔴 数据读写必须经过 SQL 解析,大数据、高并发下性能不足 | 🔴 JOIN 等复杂操作能力弱 |
| 🔴 读写或修改结构时需要加锁,影响并发 | 🔴🔴 事务支持较弱(BASE 理论) |
| 🔴 无法适应非结构化存储 | 🔴 通用性差 |
| 🔴🔴 扩展困难 | 🔴🔴 无完整约束,复杂业务场景支持差 |
| 🔴 昂贵、复杂 |
💡 生活例子(加锁机制): 关系型数据库修改数据就像图书馆借书,管理员每次只允许一个人进书库(加锁),其他人必须等着。如果借书人动作慢,后面就排长队。而 NoSQL 像开放式书架,大家可以同时拿书,但可能两个人同时想拿最后一本,需要额外机制解决冲突。
💡 生活例子(事务支持弱) : 用 MongoDB 记录朋友圈点赞,100 个人同时点赞,可能最后显示 99 个或 101 个(偶尔不一致),但刷新一下就对了。这就是 最终一致性------不像银行转账那样严格,但换来了极高的性能。就像网红奶茶店,排队人太多时,店员先收钱后做奶茶,偶尔可能漏单,但重新点一下就好,总比让大家排队排到崩溃强。
💡 生活例子(扩展困难 vs 易于扩展):
关系型数据库扩展像搬家:家具(数据)太多,只能换更大的房子(更贵服务器),或者把家具拆开分散放,但用起来很不方便(分库分表复杂)。
NoSQL 扩展像乐高积木:数据多了就加一块积木(加服务器),系统自动把数据分散存放,对外看起来还是一个整体。
(4)🔴🔴🔴 核心难点:CAP 定理(扩展知识)
分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance) 三者不可兼得,最多满足两项。
| 数据库类型 | 选择 | 说明 |
|---|---|---|
| 关系型数据库 | CP | 保证一致性和分区容错,可能牺牲可用性 |
| NoSQL(如 Cassandra) | AP | 保证可用性和分区容错,牺牲强一致性 |
💡 生活例子: 疫情期间小区封控(网络分区):
CP(关系型):大门锁死,谁也不许进出,保证小区内部信息绝对准确(一致性),但完全不可用。
AP(NoSQL):大门开着,大家能正常进出(可用性),但可能有人没登记(暂时不一致),等解封后再核对(最终一致)。
(5)⭐ 选型建议
| 场景 | 推荐数据库 |
|---|---|
| 金融交易、库存管理、订单系统 | ⭐ 关系型数据库(MySQL、Oracle) |
| 缓存、会话存储、排行榜 | ⭐⭐ Redis |
| 内容管理、用户资料、日志存储 | ⭐⭐ MongoDB |
| 大数据分析、时序数据 | ⭐⭐ HBase、Cassandra |
| 社交网络、推荐系统 | ⭐⭐ 图数据库(Neo4j) |
(6)🔴 记忆口诀
关系型 :结构化、强事务、Join 强、扩展难 NoSQL:高并发、易扩展、弱事务、结构活

二 redis简介
中文官网
2.1 什么是redis
Redis (Remote Dictionary Server)
在2009年发布,开发者是意大利的萨尔瓦多·桑菲利波普(Salvatore Sanfilippo),他本想为自己的公司开发一个用于替换MySQL的产品Redis,但是没有想到他把Redis开源后大受欢迎,短短几年,Redis就有了很大的用户群体,目前国内外使用的公司众多,比如:阿里,百度,新浪微博,知乎网,GitHub,Twitter 等 Redis是一个开源的、遵循BSD协议的、基于内存的而且目前比较流行的键值数据库(key-value database),是一个非关系型数据库,redis 提供将内存通过网络远程共享的一种服务,提供类似功能的还有memcached,但相比memcached,redis还提供了易扩展、高性能、具备数据持久性等功能。Redis 在高并发、低延迟环境要求比较高的环境使用量非常广泛
2.2 Redis特性
-
速度快: 10W QPS,基于内存,C语言实现
-
单线程
-
持久化
-
支持多种数据结构
-
支持多种编程语言
-
功能丰富: 支持Lua脚本,发布订阅,事务,pipeline等功能
-
简单: 代码短小精悍(单机核心代码只有23000行左右),单线程开发容易,不依赖外部库,使用简单
-
主从复制
-
支持高可用和分布式

单线程为何如此快?
-
纯内存
-
非阻塞
-
避免线程切换和竞态消耗
2.3 Redis应用场景
-
Session 共享:常见于web集群中的Tomcat或者PHP中多web服务器session共享
-
缓存:数据查询、电商网站商品信息、新闻内容
-
计数器:访问排行榜、商品浏览数等和次数相关的数值统计场景
-
微博/微信社交场合:共同好友,粉丝数,关注,点赞评论等
-
消息队列:ELK的日志缓存、部分业务的订阅发布系统
-
地理位置: 基于GEO(地理信息定位),实现摇一摇,附近的人,外卖等功能
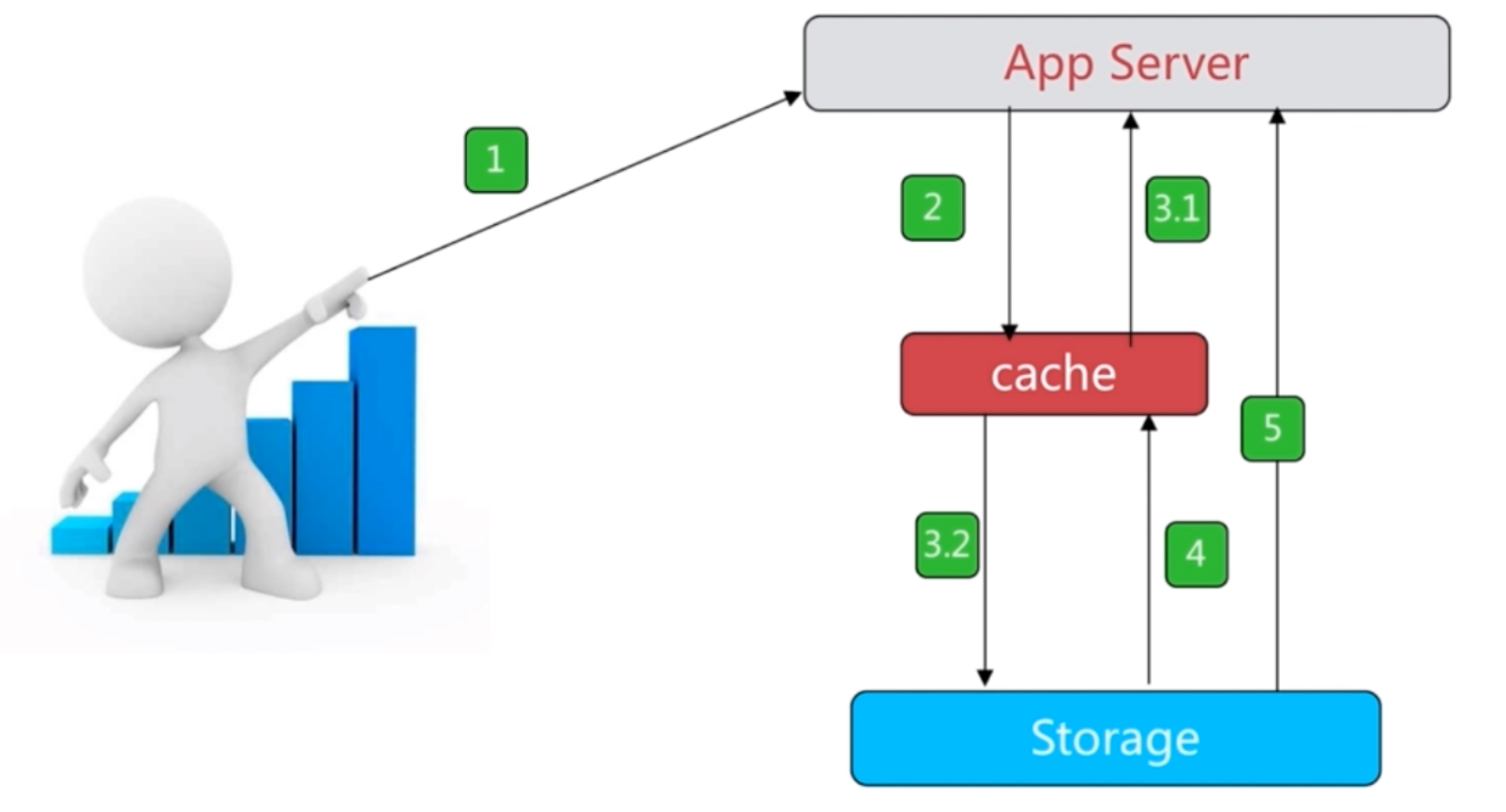
2.4 缓存的实现流程
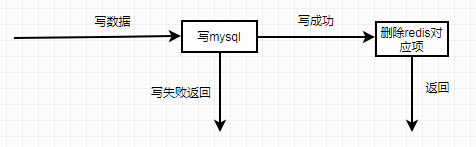
数据更新操作流程
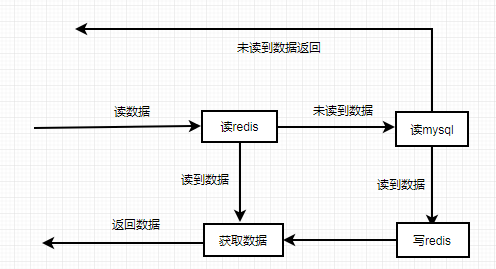
数据读操作流程
2.5 总结
(1)什么是 Redis ⭐⭐
Redis (Remote Dictionary Server) ------ 远程字典服务器
-
诞生时间:2009 年
-
🔴 作者 :意大利开发者 Salvatore Sanfilippo(萨尔瓦多·桑菲利波普)
-
初衷:本想替换 MySQL,开源后意外大受欢迎
-
⭐ 本质 :开源、遵循 BSD 协议、基于内存 的 键值数据库(Key-Value Database)
-
定位:非关系型数据库(NoSQL)
⭐⭐ 核心功能:将内存通过网络远程共享,提供高性能数据存储服务
💡 生活例子 :Redis 就像一个超级快的便签本。传统数据库(MySQL)像图书馆的档案室,存取资料要走流程、花时间;而 Redis 像你把常用电话号码写在便利贴上贴在电脑边,随手就能看,速度极快。但便利贴空间有限(内存),重要资料还是要归档到档案室(持久化到磁盘)。
(2)⭐⭐⭐ Redis vs Memcached
| 特性 | Memcached | ⭐⭐⭐ Redis |
|---|---|---|
| 数据结构 | 简单的 Key-Value | ⭐⭐ 支持多种数据结构(String、List、Set、Hash、ZSet 等) |
| 持久化 | ❌ 不支持 | ⭐⭐⭐ 支持数据持久化(RDB、AOF) |
| 扩展性 | 一般 | ⭐⭐ 易扩展 |
| 性能 | 高 | ⭐⭐⭐ 高性能 |
💡 生活例子:Memcached 像只能存文字的记事本,Redis 像多功能瑞士军刀------既能当记事本,又能当计算器、日历、闹钟,还能把记录拍照存档(持久化)。
(3)⭐⭐⭐ Redis 特性详解
| 特性 | 说明 | 重要性 |
|---|---|---|
| ⭐⭐⭐ 速度快 | 10W QPS(每秒10万次查询),基于内存,C语言实现 | 核心优势 |
| 🔴🔴🔴 单线程 | 单线程处理所有命令 | 架构特色 |
| ⭐⭐⭐ 持久化 | 支持 RDB 快照和 AOF 日志 | 数据安全 |
| ⭐⭐ 多种数据结构 | String、List、Set、Hash、Sorted Set、Bitmap、HyperLogLog、GEO 等 | 功能丰富 |
| ⭐⭐ 多语言支持 | Java、Python、PHP、Go、Node.js 等 | 生态完善 |
| ⭐⭐ 功能丰富 | Lua脚本、发布订阅、事务、Pipeline 流水线 | 高级特性 |
| ⭐ 简单 | 核心代码仅 23000行 左右,不依赖外部库 | 易于维护 |
| ⭐⭐ 主从复制 | 支持数据冗余和读写分离 | 高可用基础 |
| ⭐⭐⭐ 高可用与分布式 | Sentinel 哨兵、Cluster 集群模式 | 企业级应用 |
(4)🔴🔴🔴 单线程为何如此快?(核心难点)
这是 Redis 最反直觉的特点:单线程居然能做到 10W QPS?
⭐⭐⭐ 三大原因:
| 原因 | 解释 |
|---|---|
| 🔴 纯内存操作 | 所有数据在内存中,读写速度接近硬件极限(纳秒级) |
| 🔴 非阻塞 I/O | 使用 I/O 多路复用(epoll/kqueue),单线程同时处理多个连接 |
| 🔴🔴 避免线程切换和竞态消耗 | 无锁编程,没有线程上下文切换开销,没有锁竞争 |
💡 生活例子(餐厅版):
多线程传统模型:餐厅有 100 个服务员(线程),每个服务员服务一桌客人。客人点菜时服务员等着(阻塞),服务员之间还要抢厨房资源(锁竞争),换来换去很累(上下文切换)。
Redis 单线程模型:只有一个超级高效的服务员,但客人点菜不用等------点完菜拿号去休息(非阻塞 I/O),菜好了叫号(事件通知)。这个服务员从不闲着,一直在处理最紧急的事,而且不用和同事抢资源,反而更快!
💡 生活例子(收银台版) : 想象超市收银:多线程像开 10 个收银台,但每个收银员动作慢,还要互相协调谁用哪个扫码枪(锁竞争);Redis 单线程像只有一个收银台,但收银员是闪电侠------扫码、算账、找零一气呵成,而且顾客提前把商品摆好(Pipeline 批量处理),反而比 10 个慢收银员更快!
(5)⭐⭐⭐ Redis 应用场景
| 场景 | 具体应用 | 使用技术 |
|---|---|---|
| ⭐⭐⭐ Session 共享 | Web 集群中多台 Tomcat/PHP 服务器共享用户登录状态 | String |
| ⭐⭐⭐ 缓存 | 商品信息、新闻内容、热点数据查询 | String、Hash |
| ⭐⭐ 计数器 | 访问排行榜、商品浏览数、点赞数 | String(INCR/DECR) |
| ⭐⭐ 社交网络 | 共同好友、粉丝数、关注列表、点赞评论 | Set、Sorted Set |
| ⭐⭐ 消息队列 | ELK 日志缓存、订阅发布系统 | List、Pub/Sub |
| ⭐⭐ 地理位置 | 摇一摇、附近的人、外卖配送范围 | ⭐⭐ GEO 数据结构 |
💡 生活例子(Session 共享): 你登录淘宝,第一次请求到了北京服务器,第二次刷新跳到了上海服务器。如果没有 Redis,上海服务器会问"你是谁?"让你重新登录;有了 Redis,两台服务器都问同一个 Redis"这人登录了吗?",就像全国连锁店的会员卡,哪家店都能用。
💡 生活例子(计数器) : 微博点赞数、视频播放量,如果用 MySQL,每点一次赞都要锁行更新,几万人同时点赞就卡死了。Redis 的 INCR 命令像自动计数器,按一下加一,内部原子操作,10万人同时按也能准确计数。
💡 生活例子(排行榜) : 游戏全服排行榜用 Redis 的 Sorted Set ,就像老师排成绩------插入一个新分数自动排序,随时能取前 100 名,比 MySQL 的ORDER BY快 100 倍。
(6)🔴🔴🔴 缓存实现流程(核心难点)
⭐⭐⭐ 数据更新操作流程(写操作)
写数据 → 写 MySQL → 写成功 → 删除 Redis 对应项 → 返回
↓
写失败 → 直接返回失败🔴🔴 关键策略:先更新数据库,再删缓存(Cache Aside 模式)
⭐⭐⭐ 为什么删除而不是更新缓存?
-
避免并发更新导致的数据不一致
-
删除更简单,下次读时自然回填最新数据
💡 生活例子: 你修改了微信昵称(更新数据库),微信不会立即把新昵称推给所有好友的缓存(更新缓存),而是让好友下次打开聊天窗口时重新拉取(删除缓存)。这样即使有 1000 个好友,也不会因为同时更新缓存而卡顿。
⭐⭐⭐ 数据读操作流程(读操作)
读数据 → 读 Redis → 读到数据 → 返回数据
↓
未读到数据 → 读 MySQL → 读到数据 → 写 Redis → 返回数据
↓
未读到数据 → 返回空🔴🔴 关键策略:先读缓存,未命中再读数据库并回填
💡 生活例子(书店找书):
读缓存:先看桌上有没有这本书(Redis),有就直接看(命中)。
缓存未命中:桌上没有,去图书馆书架找(MySQL),找到了拿回来放桌上(写 Redis),下次再看就不用去书架了。
缓存穿透 :书架也没有这本书(数据库也没有),有人恶意一直问这本书,你每次都要去书架确认。解决办法:在桌上贴个条"此书不存在"(缓存空值),或者查之前先问管理员"我们有这本书吗?"(布隆过滤器)。
(7)🔴🔴🔴 缓存常见问题(扩展难点)
| 问题 | 现象 | 解决方案 |
|---|---|---|
| 🔴🔴 缓存穿透 | 查询不存在的数据,绕过缓存直达数据库 | 布隆过滤器、缓存空值 |
| 🔴🔴 缓存击穿 | 热点 Key 过期,瞬间大量请求打到数据库 | 互斥锁、逻辑过期 |
| 🔴🔴🔴 缓存雪崩 | 大量 Key 同时过期,数据库瞬间崩溃 | 随机过期时间、多级缓存、熔断降级 |
💡 生活例子(缓存雪崩) : 双十一零点,所有商品缓存同时过期,几百万用户同时查数据库,MySQL 直接宕机。就像超市促销,所有商品标签同时撕掉,顾客全涌到服务台问价格,服务台挤爆了。解决办法:标签分批次撕(随机过期时间),或者提前贴新标签(提前刷新),或者先让顾客看电子屏(多级缓存)。
(8)⭐⭐ Redis 数据结构速查
| 数据结构 | 适用场景 | 生活类比 |
|---|---|---|
| ⭐⭐⭐ String | 缓存、计数器、分布式锁 | 便利贴(写啥都行) |
| ⭐⭐ List | 消息队列、时间线 | 排队队列 |
| ⭐⭐ Set | 共同好友、标签 | 集合(无序不重复) |
| ⭐⭐ Hash | 对象存储(用户信息) | 表格(多字段) |
| ⭐⭐⭐ Sorted Set | 排行榜、延时队列 | 成绩单(带分数排序) |
| ⭐ Bitmap | 签到统计、在线状态 | 考勤打卡表 |
| ⭐ HyperLogLog | UV 统计(去重计数) | 估算人数(不精确但省空间) |
| ⭐⭐ GEO | 地理位置、附近的人 | 地图坐标 |
(9)🔴 记忆口诀
Redis 快 :内存操作单线程,IO多路复用行 缓存策 :更新先写库,读取先找缓存 三大坑:穿透击穿雪崩,布隆锁随机来防
三 Redis的安装
官方下载地址:http://download.redis.io/releases/
3.1 rpm包方式安装
bash
[root@redis-node1 ~]# dnf install redis -y
正在更新 Subscription Management 软件仓库。
无法读取客户身份
This system is not registered with an entitlement server. You can use "rhc" or "subscription-manager" to register.
上次元数据过期检查:0:01:14 前,执行于 2024年08月05日 星期一 13时30分23秒。
依赖关系解决。
=================================================================================================================
软件包 架构 版本 仓库 大小
=================================================================================================================
安装:
redis x86_64 6.2.7-1.el9 AppStream 1.3 M
事务概要
=================================================================================================================
安装 1 软件包
总计:1.3 M
安装大小:4.7 M3.2 源码安装
!WARNING
在一台主机中不能即用rpm安装也用源码安装
bash
#解压源码包
[root@redis-node1 ~]# tar zxf redis-7.4.0.tar.gz
[root@redis-node1 ~]# ls
redis-7.4.0 redis-7.4.0.tar.gz
#安装编译工具
[root@redis-node1 redis-7.4.0]# dnf install make gcc initscripts-10.11.6-1.el9.x86_64 -y
#执行编译命令
[root@redis-node1 redis-7.4.0]# make
[root@redis-node1 redis-7.4.0]# make install
#启动Redis
[root@redis-node1 redis-7.4.0]# cd utils/
[root@redis-node1 utils]# ./install_server.sh
Welcome to the redis service installer
This script will help you easily set up a running redis server
This systems seems to use systemd. #提示系统使用的是systemd的初始化方式
Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!
[root@redis-node1 utils]# vim install_server.sh #解决报错问题
#bail if this system is managed by systemd
#_pid_1_exe="$(readlink -f /proc/1/exe)"
#if [ "${_pid_1_exe##*/}" = systemd ]
#then
# echo "This systems seems to use systemd."
# echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"
# exit 1
#fi
[root@redis-node1 utils]# ./install_server.sh
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379] #端口号
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf] #配置文件
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log] #日志
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379] #数据目录
Selected default - /var/lib/redis/6379
Please select the redis executable path [/usr/local/bin/redis-server] #命令路径
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!
#配置redis
[root@redis-node1 utils]# vim /etc/redis/6379.conf
bind * -::*
[root@redis-node1 utils]# /etc/init.d/redis_6379 restart
Stopping ...
Redis stopped
Starting Redis server...
[root@redis-node1 utils]# netstat -antlpe | grep redis
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 0 67267 38417/redis-server
tcp6 0 0 :::6379
#查看信息
[root@redis-node1 utils]# redis-cli
127.0.0.1:6379> inforedis安装:
bash
[root@rd1 ~]# vmset.sh eth0 172.25.254.60 rd1
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:21:cf:ef brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.60/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe21:cfef/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd1
[root@rd1 ~]# dnf install make gcc initscripts -y # 使用 dnf 包管理器安装编译必需工具:make(构建工具)、gcc(C编译器)、initscripts(初始化脚本支持),-y 自动确认安装
[root@rd1 ~]# wget https://download.redis.io/releases/redis-7.4.8.tar.gz # 从官方源下载 Redis 7.4.8 版本的源码压缩包
[root@rd1 ~]# tar zxf redis-7.4.8.tar.gz # 解压 .tar.gz 文件,生成 redis-7.4.8 源码目录
[root@rd1 ~]# cd redis-7.4.8/ # 进入 Redis 源码根目录
[root@rd1 redis-7.4.8]# make && make install # 直接运行 make 编译源码,成功后执行 make install 安装到系统默认路径(通常是 /usr/local/bin)
[root@rd1 redis-7.4.8]# cd utils/ # 进入 Redis 源码包中的工具脚本目录
[root@rd1 utils]# vim install_server.sh # 编辑自动安装脚本(目的是注释掉检测 systemd 的代码,使其能在现代系统运行)
76 ##bail if this system is managed by systemd # [已注释] 原意:如果系统由 systemd 管理则中止;双井号可能是误触或强调已禁用
77 #_pid_1_exe="$(readlink -f /proc/1/exe)" # [已注释] 原意:获取 PID 1 进程的真实路径
78 #if [ "${_pid_1_exe##*/}" = systemd ] # [已注释] 原意:判断进程名是否为 systemd
79 #then # [已注释] 原意:如果是 systemd 则进入分支
80 # echo "This systems seems to use systemd." # [已注释] 原意:提示用户系统使用 systemd
81 # echo "Please take a look at the provided example service unit files in thi s directory, and adapt and install them. Sorry!" # [已注释] 原意:建议用户手动配置 systemd 服务文件并退出
82 # exit 1 # [已注释] 原意:退出脚本,阻止安装继续
[root@rd1 utils]# ./install_server.sh # 执行修改后的安装脚本(因为跳过了 systemd 检测,脚本得以继续运行)
Welcome to the redis service installer # 脚本欢迎信息
This script will help you easily set up a running redis server # 脚本功能说明
Please select the redis port for this instance: [6379] # 交互式提问:选择 Redis 端口(默认 6379)
Selecting default: 6379 # 用户直接回车,使用默认端口
Please select the redis config file name [/etc/redis/6379.conf] # 交互式提问:选择配置文件路径
Selected default - /etc/redis/6379.conf # 使用默认配置文件路径
Please select the redis log file name [/var/log/redis_6379.log] # 交互式提问:选择日志文件路径
Selected default - /var/log/redis_6379.log # 使用默认日志路径
Please select the data directory for this instance [/var/lib/redis/6379] # 交互式提问:选择数据存放目录
Selected default - /var/lib/redis/6379 # 使用默认数据目录
Please select the redis executable path [/usr/local/bin/redis-server] # 交互式提问:选择 redis-server 可执行文件路径
Selected config: # 显示最终确认的配置汇总
Port : 6379 # 端口:6379
Config file : /etc/redis/6379.conf # 配置文件路径
Log file : /var/log/redis_6379.log # 日志文件路径
Data dir : /var/lib/redis/6379 # 数据目录路径
Executable : /usr/local/bin/redis-server # 可执行文件路径
Cli Executable : /usr/local/bin/redis-cli # 客户端工具路径
Is this ok? Then press ENTER to go on or Ctrl-C to abort. # 确认提示:回车继续,Ctrl-C 取消
Copied /tmp/6379.conf => /etc/init.d/redis_6379 # 脚本将生成的配置复制为 SysVinit 风格的启动脚本 (/etc/init.d/...)
Installing service... # 开始注册系统服务
Successfully added to chkconfig! # 成功添加到 chkconfig 管理(用于控制开机自启,SysVinit 时代的标准)
Successfully added to runlevels 345! # 成功设置运行级别 3,4,5 下开机自启(多用户模式)
Starting Redis server... # 尝试立即启动 Redis 服务
Installation successful! # 安装过程结束,提示成功
[root@rd1 utils]# systemctl daemon-reload # 【关键步骤】重新加载 systemd 配置管理器,使其识别新生成的 init.d 脚本
[root@rd1 utils]# systemctl status redis_6379.service # 查看服务状态(此时显示 inactive/dead,因为还没真正启动或刚加载)
○ redis_6379.service - LSB: start and stop redis_6379 # 服务名称及描述(LSB 表示它是兼容 Linux Standard Base 的旧式脚本)
Loaded: loaded (/etc/rc.d/init.d/redis_6379; generated) # 加载来源:由 /etc/init.d/redis_6379 自动生成 service 单元
Active: inactive (dead) # 当前状态:未运行
Docs: man:systemd-sysv-generator(8) # 文档参考:systemd 如何兼容 SysVinit 脚本
[root@rd1 utils]# systemctl start redis_6379.service # 手动启动 Redis 服务
[root@rd1 utils]# systemctl status redis_6379.service # 再次查看状态,确认是否启动成功
● redis_6379.service - LSB: start and stop redis_6379 # 服务状态图标变为实心圆点(●),表示运行中
Loaded: loaded (/etc/rc.d/init.d/redis_6379; generated) # 加载信息不变
Active: active (exited) since Sun 2026-03-15 15:16:39 CST; 1s ago # 状态:active (exited)。注意:对于 SysVinit 脚本转换的服务,启动成功后通常显示 exited,因为主进程是后台守护进程,init 脚本本身已退出
Docs: man:systemd-sysv-generator(8) # 文档参考
Process: 35759 ExecStart=/etc/rc.d/init.d/redis_6379 start (code=exited, stat> # 显示执行启动命令的进程 ID 和结果
CPU: 2ms # 占用 CPU 时间极短
Mar 15 15:16:39 rd1 systemd[1]: Starting LSB: start and stop redis_6379... # 日志:systemd 开始启动服务
Mar 15 15:16:39 rd1 redis_6379[35759]: /var/run/redis_6379.pid exists, process is> # 日志:检测到 PID 文件存在(可能是刚才安装脚本里已经启动过一次,或者残留文件,但服务依然正常接管了)
Mar 15 15:16:39 rd1 systemd[1]: Started LSB: start and stop redis_6379. # 日志:服务启动完成
[root@rd1 utils]# netstat -antulpe | grep redis # 使用 netstat 命令查看网络连接,筛选包含 "redis" 的行,确认 Redis 是否正在监听端口
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 0 64648 35673/redis-server
# ^ ^ ^ ^ ^ ^ ^ ^
# | | | | | | | └─ [进程信息] 进程ID(PID)=35673, 进程名=redis-server
# | | | | | | └──────────── [inode] Socket 的 inode 编号 (64648),用于内核追踪
# | | | | | └─────────────────────── [队列] 接收队列长度 (0表示没有待处理连接)
# | | | | └────────────────────────────────── [状态] LISTEN (监听中,等待客户端连接)
# | | | └──────────────────────────────────────────────────────── [远程地址] 0.0.0.0:* (因为是监听状态,表示接受来自任何IP和端口的连接请求)
# | | └───────────────────────────────────────────────────────────────────────────────── [本地地址] 127.0.0.1:6379 (仅监听 IPv4 本地回环地址,外部无法直接访问)
# | └──────────────────────────────────────────────────────────────────────────────────────── [接收队列] 当前积压的未处理数据包数 (0表示正常)
# └───────────────────────────────────────────────────────────────────────────────────────────────── [协议] tcp (IPv4 TCP协议)
tcp6 0 0 ::1:6379 :::* LISTEN 0 64649 35673/redis-server
# ^ ^ ^ ^ ^ ^ ^ ^
# | | | | | | | └─ [进程信息] 同一个进程 (PID 35673) 同时监听了 IPv6
# | | | | | | └──────────── [inode] IPv6 Socket 的 inode 编号 (64649)
# | | | | | └─────────────────────── [队列] 接收队列长度
# | | | | └────────────────────────────────── [状态] LISTEN
# | | | └──────────────────────────────────────────────────────── [远程地址] :::* (IPv6 任意地址)
# | | └───────────────────────────────────────────────────────────────────────────────── [本地地址] ::1:6379 (仅监听 IPv6 本地回环地址 localhost)
# | └──────────────────────────────────────────────────────────────────────────────────────── [接收队列]
# └───────────────────────────────────────────────────────────────────────────────────────────────── [协议] tcp6 (IPv6 TCP协议)
1.监听地址安全性 (127.0.0.1 和 ::1):
Redis 默认只监听 本地回环地址 (Localhost)。
127.0.0.1 是 IPv4 的本地地址。
::1 是 IPv6 的本地地址。
含义:这意味着只有本机可以连接这个 Redis 服务。外部服务器(即使在同一局域网)无法直接通过 IP 连接它。这是 Redis 默认的安全配置,防止未授权访问。如果需要外网访问,需修改配置文件 bind 参数。
2.端口 (6379):
Redis 的默认标准端口,确认服务已正确加载默认配置。
3.进程一致性 (35673/redis-server):
两行记录(IPv4 和 IPv6)显示的 PID 都是 35673,说明这是同一个 Redis 进程在同时处理两种网络协议的请求。
4.状态 (LISTEN):
明确表示服务已启动并正在等待客户端连接,没有报错或僵死。
5.关于 netstat 的参数 -antulpe:
-a: 显示所有 sockets(包括监听和非监听)。
-n: 以数字形式显示 IP 和端口(不解析域名,速度更快)。
-t: 仅显示 TCP 连接。
-u 显示 UDP 连接。
-l: 仅显示监听状态 (Listening) 的 sockets。
-p: 显示占用该端口的进程 PID 和名称 (需要 root 权限)。
-e: 显示扩展信息(如本例中的 inode 和用户ID,虽然在某些版本输出不明显,但在 CentOS/RHEL 中常用于配合 -p 显示更多细节)。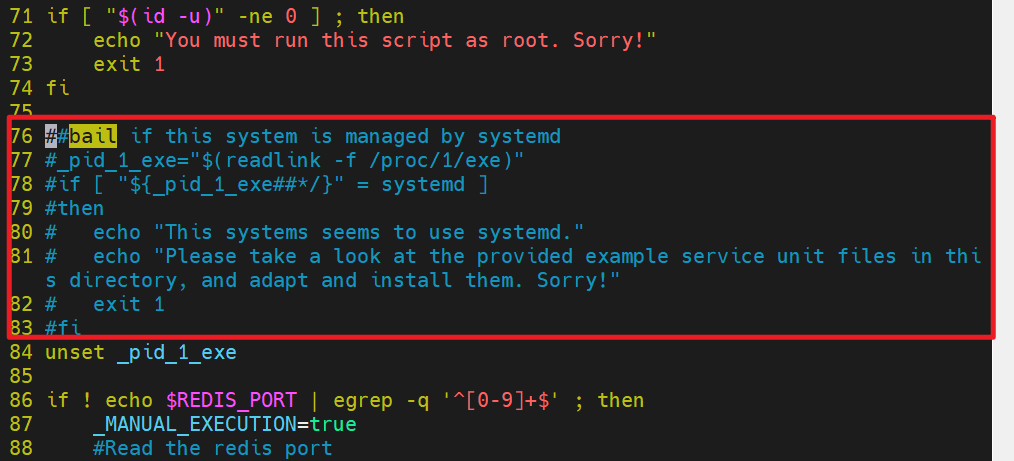
3.3 总结
(1)⭐⭐⭐ 安装方式概述
| 安装方式 | 适用场景 | 特点 |
|---|---|---|
| ⭐ RPM 包安装 | 快速部署、测试环境 | 简单快捷,版本较旧 |
| ⭐⭐⭐ 源码编译安装 | 生产环境、定制需求 | 版本新、性能优化、可控性强 |
🔴🔴 重要警告 :一台主机不能同时用 RPM 安装和源码安装! 会冲突!
💡 生活例子:就像你不能在同一台电脑上同时安装两个杀毒软件(360 和 腾讯管家),它们会互相冲突。Redis 的 RPM 版和源码版也会"打架",只能二选一。
(2)⭐ RPM 包方式安装(简单版)
# 直接安装(以 CentOS/RHEL 9 为例)
[root@redis-node1 ~]# dnf install redis -y⭐ 特点:
-
自动解决依赖
-
版本较旧(如示例中的 6.2.7)
-
适合快速体验
💡 生活例子:RPM 安装像去快餐店买汉堡------快、方便、标准化,但你不能指定面包要烤多焦、酱料要多放少放。
(3)🔴🔴🔴 源码编译安装(生产环境推荐)
⭐⭐⭐ 安装步骤详解
| 步骤 | 命令 | 说明 |
|---|---|---|
| 1. 下载源码 | wget https://download.redis.io/releases/redis-7.4.8.tar.gz |
从官网下载 |
| 2. 解压 | tar zxf redis-7.4.8.tar.gz |
解压源码包 |
| 3. 安装依赖 | dnf install make gcc initscripts -y |
⭐⭐⭐ 编译工具三件套 |
| 4. 编译 | make |
编译源码 |
| 5. 安装 | make install |
安装到系统 |
| 6. 配置服务 | ./install_server.sh |
初始化服务配置 |
| 7. 修改监听 | 编辑 bind * -::* |
允许远程连接 |
🔴🔴🔴 关键难点:解决 systemd 冲突
问题现象:
This systems seems to use systemd.
Please take a look at the provided example service unit files in this directory,
and adapt and install them. Sorry!🔴🔴 原因 :新版 Linux(CentOS 7+/RHEL 9+)使用 systemd 管理服务,而 install_server.sh 脚本是为旧版 SysVinit 设计的,检测到 systemd 会直接退出。
⭐⭐⭐ 解决方案:注释检测代码
[root@rd1 utils]# vim install_server.sh
# 注释掉以下 systemd 检测代码(约 76-82 行):
##bail if this system is managed by systemd
#_pid_1_exe="$(readlink -f /proc/1/exe)"
#if [ "${_pid_1_exe##*/}" = systemd ]
#then
# echo "This systems seems to use systemd."
# echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"
# exit 1
#fi💡 生活例子:就像新小区用智能门禁(systemd),但老门卫(install_server.sh)只会用钥匙开门,看到智能门禁就说"我不会用,不干了!"。解决办法是告诉门卫"别管什么门禁,直接按老规矩办事"(注释检测代码),或者教他用新门禁(手动配置 systemd 服务文件)。
(4)⭐⭐⭐ install_server.sh 交互配置详解
执行脚本后会依次询问以下配置:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| Port | 6379 | ⭐⭐⭐ Redis 默认端口,标志性端口 |
| Config file | /etc/redis/6379.conf |
配置文件路径 |
| Log file | /var/log/redis_6379.log |
日志文件路径 |
| Data dir | /var/lib/redis/6379 |
⭐⭐⭐ 持久化数据存放目录 |
| Executable | /usr/local/bin/redis-server |
服务端程序路径 |
| Cli Executable | /usr/local/bin/redis-cli |
客户端程序路径 |
🔴 注意 :直接回车使用默认即可,最后确认按 ENTER 继续。
💡 生活例子:这就像装修房子时设计师问你------"客厅刷什么颜色?(默认白色)"、"卧室地板用什么?(默认木地板)"。专业人士已经给了合理默认值,你直接点头就行,除非有特殊需求。
(5)🔴🔴🔴 服务管理:systemd 与 SysVinit 兼容
⭐⭐⭐ 关键操作命令
# 重新加载 systemd 配置(必须执行!)
[root@rd1 utils]# systemctl daemon-reload
# 查看服务状态
[root@rd1 utils]# systemctl status redis_6379.service
# 启动服务
[root@rd1 utils]# systemctl start redis_6379.service
# 停止服务
[root@rd1 utils]# systemctl stop redis_6379.service
# 开机自启
[root@rd1 utils]# systemctl enable redis_6379.service🔴🔴 状态解读
| 状态 | 含义 | 说明 |
|---|---|---|
inactive (dead) |
未运行 | 服务已加载但未启动 |
active (exited) |
运行中(已退出) | ⭐⭐⭐ 特殊状态:SysVinit 脚本转换的服务,启动脚本本身已退出,但后台进程在运行 |
failed |
失败 | 启动出错,需查看日志 |
💡 生活例子 :
active (exited)像自动售货机------你按按钮(启动脚本),货出来了(Redis 进程运行),按钮弹回去了(脚本退出),但机器还在正常工作。别看到"exited"就以为失败了!
(6)⭐⭐⭐ 网络验证:netstat 命令详解
[root@rd1 utils]# netstat -antlpe | grep redis参数拆解:
| 参数 | 含义 |
|---|---|
-a |
显示所有 socket |
-n |
数字显示 IP 和端口(不解析域名) |
-t |
仅显示 TCP |
-l |
仅显示监听状态 |
-p |
显示进程名和 PID(需 root) |
-e |
显示扩展信息 |
🔴🔴🔴 输出结果解读
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 0 64648 35673/redis-server
tcp6 0 0 ::1:6379 :::* LISTEN 0 64649 35673/redis-server| 字段 | 值 | 含义 |
|---|---|---|
| 协议 | tcp / tcp6 |
IPv4 / IPv6 |
| 本地地址 | 127.0.0.1:6379 / ::1:6379 |
⭐⭐⭐ 仅监听本地回环(安全默认) |
| 状态 | LISTEN |
监听中,等待连接 |
| PID | 35673 |
进程 ID,两行为同一进程 |
🔴🔴🔴 安全提示 :默认 bind 127.0.0.1 只允许本机访问!如需远程连接,需修改配置文件:
[root@rd1 utils]# vim /etc/redis/6379.conf
# 修改 bind 参数
bind * -::* # 监听所有地址(IPv4 和 IPv6)
# 重启生效
[root@rd1 utils]# systemctl restart redis_6379.service💡 生活例子 :默认配置像小区保安只认业主(本机),外来人员一律不让进。
bind *像把门禁改成"来者不拒",方便但危险!生产环境应该配置密码(requirepass)或防火墙白名单,像 VIP 包厢------门开着,但只有知道密码的人才能进。
(7)⭐⭐⭐ 连接测试与基础命令
# 进入 Redis 客户端
[root@rd1 utils]# redis-cli
127.0.0.1:6379>
# 查看服务器信息
127.0.0.1:6379> info
# 测试连通性
127.0.0.1:6379> ping
PONG
# 设置键值
127.0.0.1:6379> set name "redis"
OK
# 获取键值
127.0.0.1:6379> get name
"redis"(8)🔴 安装常见问题速查
| 问题 | 原因 | 解决 |
|---|---|---|
make 报错 |
缺少 gcc/make | dnf install make gcc -y |
install_server.sh 退出 |
检测到 systemd | 注释脚本内检测代码 |
| 无法远程连接 | 默认只监听 127.0.0.1 | 修改 bind 配置 |
| 端口被占用 | 6379 被其他进程占用 | netstat -tlnp 查看并停止 |
| 权限不足 | 非 root 用户 | 使用 sudo 或切换 root |
(9)🔴 记忆口诀
安装三步走 :下载解压装依赖,make编译install安 systemd冲突 :脚本检测要注释,daemon-reload不能忘 网络看状态 :netstat查端口,127.0.0.1是本地 远程要开放:bind改星号,密码防火墙要跟上
(10)⭐⭐⭐ 安装方式选择建议
| 场景 | 推荐方式 | 理由 |
|---|---|---|
| 学习测试 | RPM 安装 | 5分钟搞定,快速体验 |
| 生产环境 | ⭐⭐⭐ 源码安装 | 版本可控、性能优化、安全加固 |
| 容器化部署 | Docker 官方镜像 | 隔离性好,易于扩展 |
| 云平台 | 云厂商托管服务 | 免运维,高可用自动保障 |
四 Redis的基本操作
4.1 基本操作
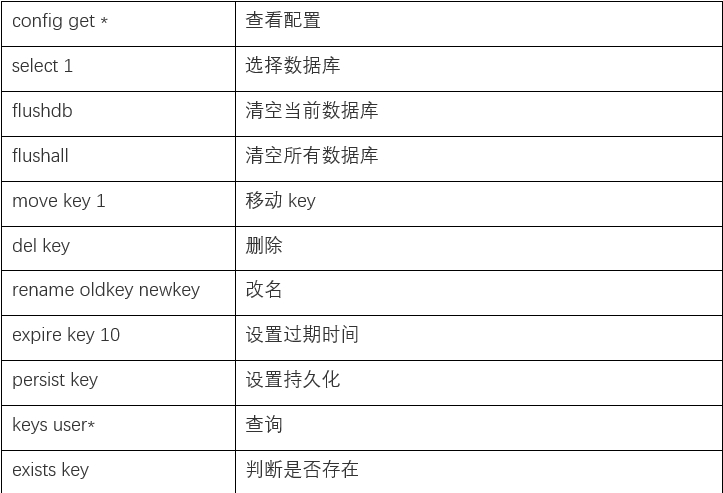
示例:
bash
#查看配置
127.0.0.1:6379[1]> CONFIG GET bind
1) "bind"
2) "* -::*"
127.0.0.1:6379[1]> CONFIG GET *
#写入和读取数据
127.0.0.1:6379> SET name lee
OK
127.0.0.1:6379> GET name
"lee"
127.0.0.1:6379> set name lee ex 5
OK
127.0.0.1:6379> get name
"lee"
127.0.0.1:6379> get name
"lee"
127.0.0.1:6379> get name
"lee"
127.0.0.1:6379> get name
"lee"
127.0.0.1:6379> get name
(nil)
#如果没有设定数据过期时间会一直存在, /var/lib/redis/6379/dump.rdb内存快照中
127.0.0.1:6379> set name lee
OK
127.0.0.1:6379> KEYS * #查看所有key
1) "name"
#选择数据库 redisa中有0-15个数据库
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> get name
(nil)
127.0.0.1:6379> select 0
127.0.0.1:6379[1]> select 16
(error) ERR DB index is out of range
#移动数据
127.0.0.1:6379> set name lee
OK
127.0.0.1:6379> MOVE name 1
(integer) 1
127.0.0.1:6379> GET name
(nil)
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> get name
"lee"
#改变键名
127.0.0.1:6379[1]> RENAME name id
OK
127.0.0.1:6379[1]> get name
(nil)
127.0.0.1:6379[1]> get id
"lee"
#设定数据过期时间
127.0.0.1:6379> set name lee ex 10000
OK
127.0.0.1:6379> get name
"lee"
127.0.0.1:6379> EXPIRE name 3
(integer) 1
127.0.0.1:6379> get name
"lee"
127.0.0.1:6379> get name
(nil)
#删除
127.0.0.1:6379> set name lee
OK
127.0.0.1:6379> get name
"lee"
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
#持久化保存
127.0.0.1:6379> PERSIST name
(integer) 0
#判断key是否存在
127.0.0.1:6379> EXISTS name
(integer) 1
127.0.0.1:6379> EXISTS lee
(integer) 0
#清空当前库
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> GET name
(nil)
#清空所有库
127.0.0.1:6379[1]> FLUSHALL
OK4.2 总结
(1)⭐⭐⭐ 连接与基础配置
⭐ 启动客户端
[root@redis-node1 ~]# redis-cli
127.0.0.1:6379>⭐⭐ 查看配置命令
| 命令 | 作用 | 示例 |
|---|---|---|
CONFIG GET 配置项 |
查看指定配置 | CONFIG GET bind |
CONFIG GET * |
⭐⭐⭐ 查看所有配置 | 显示全部配置参数 |
127.0.0.1:6379[1]> CONFIG GET bind
1) "bind"
2) "* -::*"💡 生活例子 :
CONFIG GET像查看手机设置------可以看 Wi-Fi 密码(具体配置),也可以恢复出厂设置时看所有选项(*)。Redis 的配置就像手机的"开发者选项",专业用户需要知道怎么调。
(2)⭐⭐⭐ 核心数据结构:String(字符串)
⭐⭐⭐ 基础读写操作
| 命令 | 作用 | 返回值 |
|---|---|---|
SET key value |
设置键值对 | OK |
GET key |
获取键值 | 值内容或 (nil) |
SET key value EX 秒数 |
⭐⭐⭐ 设置带过期时间的键值 | OK |
127.0.0.1:6379> SET name lee
OK
127.0.0.1:6379> GET name
"lee"
127.0.0.1:6379> SET name lee EX 5 # 5秒后自动删除
OK
127.0.0.1:6379> GET name # 5秒内查询
"lee"
127.0.0.1:6379> GET name # 5秒后查询
(nil) # 已过期,返回空🔴🔴 过期时间机制详解
-
不设置过期时间 :数据永久存在 ,保存到
/var/lib/redis/6379/dump.rdb(持久化文件) -
设置过期时间(EX):到期后自动删除,内存自动回收
💡 生活例子 :Redis 像酒店房间------
SET是开房入住,不设置 EX 就像买了房(永久拥有),设置EX 5就像钟点房(5小时后自动退房清场)。酒店前台(Redis)会自动回收房间(删除 key),不需要你手动退房。
💡 生活例子(缓存应用) :微博热搜榜单用 Redis 存,设置EX 300(5分钟过期)。就像超市促销海报,贴5小时后自动撕掉换新的,既保证信息新鲜,又不占用墙面(内存) forever。
(3)🔴🔴🔴 多数据库机制
⭐⭐⭐ 核心概念
| 特性 | 说明 |
|---|---|
| 数据库数量 | 16 个(编号 0-15) |
| 默认数据库 | 0 号库 |
| 切换命令 | SELECT 编号 |
127.0.0.1:6379> SELECT 1 # 切换到 1 号库
OK
127.0.0.1:6379[1]> GET name # 1 号库没有 name
(nil)
127.0.0.1:6379[1]> SELECT 0 # 切回 0 号库
OK
127.0.0.1:6379> SELECT 16 # 超出范围!
(error) ERR DB index is out of range🔴🔴 重要特性:数据库相互隔离
-
每个数据库是独立的命名空间
-
0 号库的
name和 1 号库的name完全不同 -
适合业务隔离(如 0 号库存用户,1 号库存商品)
💡 生活例子 :Redis 的 16 个数据库像一栋 16 层的办公楼,每层房间号可以重复(1层101和2层101是不同的房间)。
SELECT像按电梯楼层,去不同楼层找不同的人。你不能去 16 层(不存在),但可以在 0-15 层自由切换。
💡 生活例子(业务隔离):0 号库像公司前台(存用户登录态),1 号库像仓库(存商品库存),2 号库像财务室(存订单数据)。虽然都是 Redis,但数据互不干扰,清空前台不会影响仓库。
(4)⭐⭐⭐ 数据移动与重命名
⭐⭐ 移动数据(MOVE)
127.0.0.1:6379> SET name lee
OK
127.0.0.1:6379> MOVE name 1 # 将 name 移动到 1 号库
(integer) 1 # 返回 1 表示成功
127.0.0.1:6379> GET name
(nil) # 0 号库已不存在
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> GET name
"lee" # 在 1 号库找到🔴 注意 :MOVE 是剪切操作,不是复制!
💡 生活例子 :
MOVE像搬家------你把东西从 A 房子(0 号库)搬到 B 房子(1 号库),A 房子就空了。不是复印一份,而是整体迁移。
⭐⭐ 重命名(RENAME)
127.0.0.1:6379[1]> RENAME name id # 将 key "name" 改名为 "id"
OK
127.0.0.1:6379[1]> GET name
(nil) # 旧名已不存在
127.0.0.1:6379[1]> GET id
"lee" # 新名存在💡 生活例子 :
RENAME像改微信昵称------改完后别人搜旧昵称找不到你,搜新昵称才能找到。数据内容不变,只是换个名字。
(5)⭐⭐⭐ 过期时间精细控制
| 命令 | 作用 | 示例 |
|---|---|---|
EXPIRE key 秒数 |
给已存在的 key 设置过期时间 | EXPIRE name 3 |
TTL key |
查看剩余生存时间(秒) | TTL name |
PERSIST key |
⭐⭐⭐ 移除过期时间,永久保存 | PERSIST name |
127.0.0.1:6379> SET name lee EX 10000 # 先设置10000秒过期
OK
127.0.0.1:6379> EXPIRE name 3 # 改为3秒过期
(integer) 1
127.0.0.1:6379> GET name # 3秒内
"lee"
127.0.0.1:6379> GET name # 3秒后
(nil)🔴🔴 PERSIST 命令详解:
127.0.0.1:6379> PERSIST name
(integer) 0 # 返回 0 表示 key 不存在或没有设置过期时间💡 生活例子 :
EXPIRE像给食物贴保质期标签------本来能放很久的面包,你贴上"3天后过期",3天后自动扔掉。PERSIST像撕掉保质期标签------变成永久保存的罐头,不会过期。
💡 生活例子(续租场景) :租房合同快到期了(TTL 剩 3 天),你可以EXPIRE续签 30 天,也可以PERSIST买断房子(永久拥有)。
(6)⭐⭐ 删除与存在判断
⭐⭐ 删除(DEL)
127.0.0.1:6379> SET name lee
OK
127.0.0.1:6379> DEL name # 删除 key
(integer) 1 # 返回 1 表示删除成功
127.0.0.1:6379> GET name
(nil) # 已删除🔴 注意 :DEL 是立即删除,不同于过期!
💡 生活例子 :
DEL像手动扔垃圾------立刻消失。EXPIRE像定时垃圾桶------到点才自动清理。
⭐⭐ 存在判断(EXISTS)
127.0.0.1:6379> EXISTS name # 判断 name 是否存在
(integer) 1 # 1 表示存在
127.0.0.1:6379> EXISTS lee # 判断 lee 是否存在
(integer) 0 # 0 表示不存在💡 生活例子 :
EXISTS像查快递------输入单号,返回 1 表示"在途中",返回 0 表示"无此单号"。
(7)🔴🔴🔴 危险命令:清空数据库
| 命令 | 作用 | 危险等级 |
|---|---|---|
FLUSHDB |
⭐⭐⭐ 清空当前数据库 | 🔴🔴🔴 极高 |
FLUSHALL |
⭐⭐⭐ 清空所有 16 个数据库 | 🔴🔴🔴🔴🔴 灾难级 |
127.0.0.1:6379> FLUSHDB # 清空当前 0 号库
OK
127.0.0.1:6379> GET name
(nil) # 数据全没了
127.0.0.1:6379[1]> FLUSHALL # 清空所有库(0-15)
OK # 生产环境绝对禁止!🔴🔴🔴 生产环境防护措施
| 措施 | 配置方法 |
|---|---|
| 重命名危险命令 | rename-command FLUSHALL ""(禁用) |
| 配置验证 | 设置 requirepass 密码 |
| 备份策略 | 定期 RDB/AOF 备份 |
💡 生活例子 :
FLUSHDB像清空当前楼层(还能去其他楼层找资料),FLUSHALL像炸掉整栋楼(16层全毁)。生产环境用FLUSHALL就像在生产车间按核按钮------绝对禁止!通常要重命名这个命令,让"按钮"失效。
💡 生活例子(误操作场景) :新手运维想清空测试环境(SELECT 1+FLUSHDB),结果忘了切库,直接在 0 号库执行FLUSHALL,用户数据全没了------这就是"从删库到跑路"的典故。
(8)⭐⭐⭐ Key 查询命令
| 命令 | 作用 | 示例 |
|---|---|---|
KEYS * |
⭐⭐⭐ 查看所有 key (生产禁用!) | KEYS * |
KEYS pattern |
按模式匹配查询 | KEYS user* |
127.0.0.1:6379> KEYS * # 查看所有 key
1) "name"
2) "age"
3) "user:1001"🔴🔴 KEYS 命令的危险性
-
时间复杂度 O(N) :数据量大时阻塞整个 Redis
-
生产环境替代方案 :使用
SCAN命令渐进式遍历
💡 生活例子 :
KEYS *像让图书馆管理员把所有书 搬到前台给你看------书少时很快,书多时要搬几天(阻塞服务)。SCAN像分批搬,每次搬 10 本,搬完一批休息下,不影响其他人借书。
(9)🔴 命令速查表
| 命令 | 作用 | 记忆技巧 |
|---|---|---|
SET key value |
存数据 | 设置(Set) |
GET key |
取数据 | 获取(Get) |
SELECT n |
切数据库 | 选择(Select)第 n 层 |
MOVE key n |
移动数据 | 搬家到 n 层 |
RENAME old new |
重命名 | 改名 |
EXPIRE key sec |
设过期时间 | 到期(Expire) |
PERSIST key |
永久保存 | 坚持(Persist)持久 |
DEL key |
删除 | 删除(Delete) |
EXISTS key |
是否存在 | 存在(Exists) |
FLUSHDB |
清当前库 | 冲洗(Flush)数据库 |
FLUSHALL |
清所有库 | 冲洗全部 |
KEYS * |
查所有 key | 钥匙(Keys)开门 |
(10)🔴 记忆口诀
读写数据 :SET 存 GET 取,EX 过期自动除 切库移动 :SELECT 切楼层,MOVE 搬家不留 改名持久 :RENAME 换门牌,PERSIST 撕标签 删除危险 :DEL 单删可恢复,FLUSH 全家桶要防住 查询慎用:KEYS * 生产禁,SCAN 分批才安心
五 Redis 主从复制
5.1 环境配置
redis-node1 master
redis-node2 slave
redis-node3 slave
!NOTE
在配置多台redis时建议用复制的方式节省编译时间
5.2 配置主从同步
1.修改mastser节点的配置文件
bash
[root@redis-node1 & node2 & node3 ~]# vim /etc/redis/6379.conf
protected-mode no #关闭protected模式
[root@redis-node1 &node2 & node3 ~]# /etc/init.d/redis_6379 restart
Stopping ...
Redis stopped
Starting Redis server...2.配置slave节点
bash
[root@redis-node2 & 3 ~]# vim /etc/redis/6379.conf
replicaof 172.25.254.100 6379
[root@redis-node2 & 3 ~]# /etc/init.d/redis_6379 restart
Stopping ...
Waiting for Redis to shutdown ...
Redis stopped
Starting Redis server...3.测试效果
bash
#在mastser节点
[root@redis-node1 ~]# redis-cli
127.0.0.1:6379> set name lee
OK
#在slave节点查看
[root@redis-node2 ~]# redis-cli
127.0.0.1:6379> get name
"lee"5.3 主从同步过程
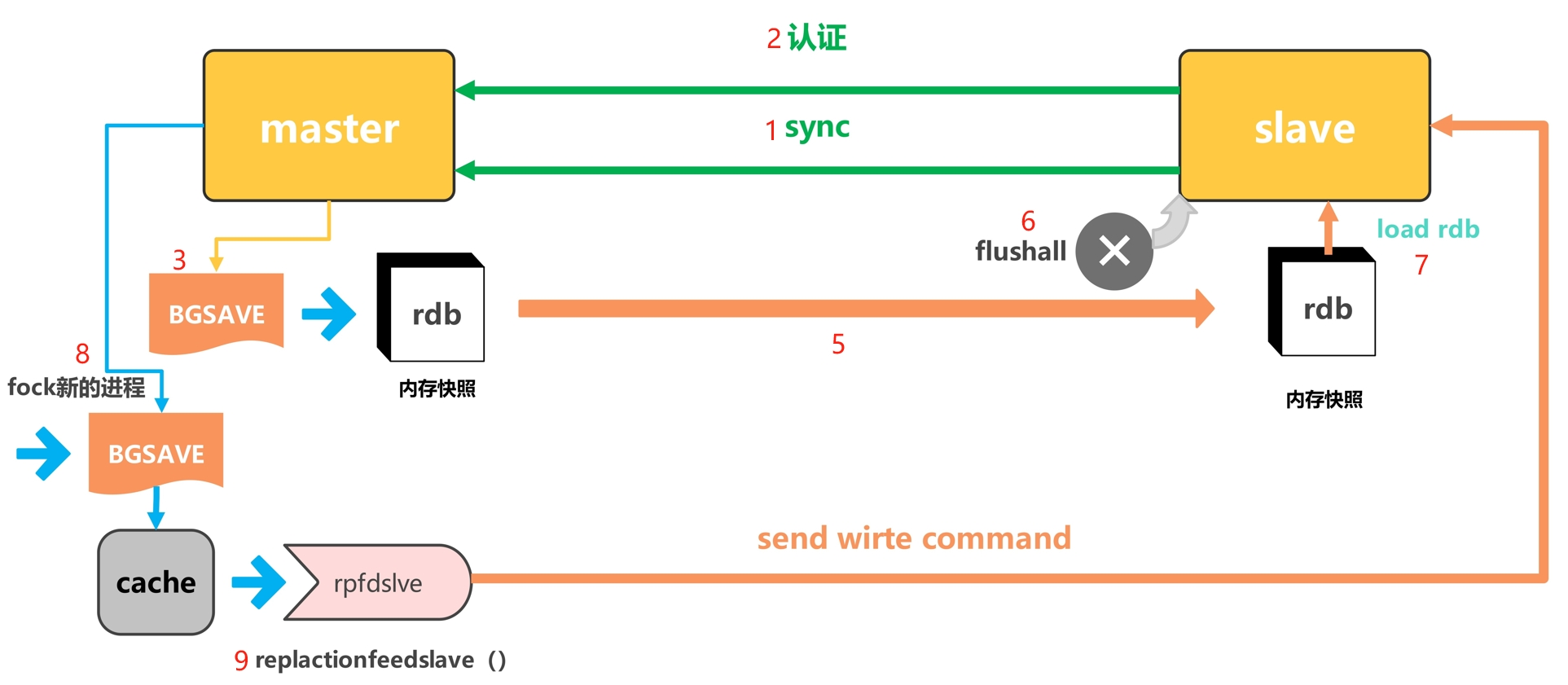
-
slave节点发送同步亲求到master节点
-
slave节点通过master节点的认证开始进行同步
-
master节点会开启bgsave进程发送内存rbd到slave节点,在此过程中是异步操作,也就是说master节点仍然可以进行写入动作
-
slave节点收到rdb后首先清空自己的所有数据
-
slave节点加载rdb并进行数据恢复
-
在master和slave同步过程中master还会开启新的bgsave进程把没有同步的数据进行缓存
-
然后通过自有的replactionfeedslave函数把未通过内存快照发动到slave的数据一条一条写入到slave中
redis主从复制:
bash
#先把当前配置好的rd1给克隆为rd2和rd3,然后再更改IP即可;
#rd2:
[root@rd2 ~]# vmset.sh eth0 172.25.254.70 rd2
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:75:4d:0e brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.70/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe75:4d0e/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd2
#rd3:
[root@rd3 ~]# vmset.sh eth0 172.25.254.80 rd3
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:62:4a:1e brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.80/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe62:4a1e/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd3
#Redis主节点配置
[root@rd1 ~]# vim /etc/redis/6379.conf # 使用 vim 编辑器打开位于 /etc/redis/ 目录下的 Redis 配置文件,端口为 6379
#bind 127.0.0.1 -::1 # 【已注释】这是默认配置,表示 Redis 只监听本地回环地址(IPv4 的 127.0.0.1 和 IPv6 的 ::1),即只允许本机访问
bind * -::* # 【新配置】修改为监听所有网络接口。* 代表所有 IPv4 地址,-::* 代表所有 IPv6 地址。这使得其他服务器可以连接到此 Redis 实例。
... # ... 表示省略了中间的其他配置项
#protected-mode yes # 【已注释】这是默认的安全模式。当 Redis 绑定到非本地地址且没有设置密码时,此模式会阻止外部连接。
# 在这里被注释掉,因为下一行明确设置了 protected-mode no。
protected-mode no # 【新配置】关闭保护模式。由于上面已经配置了 bind *,允许外部访问,所以必须关闭保护模式,否则外部连接会被拒绝。
# 【注意】在生产环境中,关闭 protected-mode 的同时,强烈建议通过 requirepass 指令设置访问密码。
[root@rd1 ~]# systemctl restart redis_6379.service # 使用 systemd 重启名为 redis_6379.service 的服务,使上述配置更改生效。 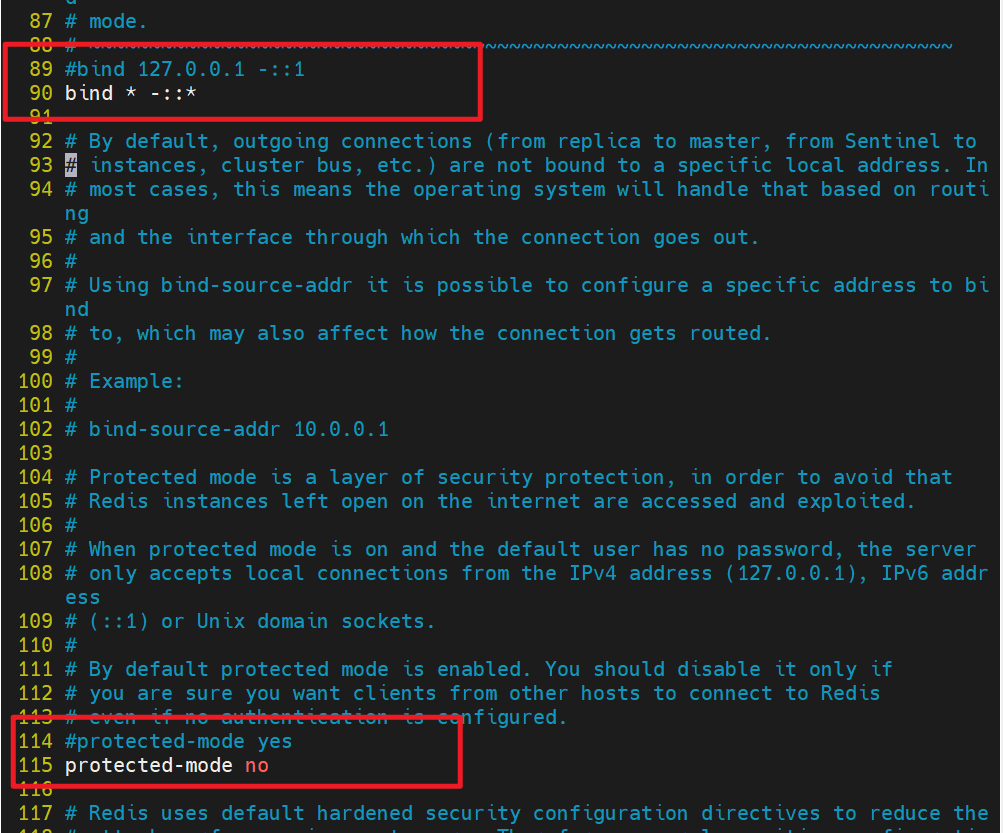
bash
#Redis从节点配置
[root@rd2/3 ~]# vim /etc/redis/6379.conf # 在这台新的服务器上,同样编辑 Redis 的配置文件
#bind 127.0.0.1 -::1 # 【已注释】同样,注释掉默认的只监听本地的配置
bind * -::* # 【新配置】同样设置为监听所有网络接口,以便主节点可以向它推送数据,并且它也可以被其他潜在的从节点连接。
protected-mode no # 【配置】同样关闭保护模式,原因同上。
replicaof 172.25.254.60 6379 # 【核心配置】这是设置主从关系的关键指令。
# 它告诉当前的 Redis 实例:"请成为 IP 地址为 172.25.254.60、端口为 6379 的那个 Redis 实例的从节点"。
# 这个 IP 地址 (172.25.254.60) 应该就是第一张图中服务器 rd1 的 IP 地址。
... # ... 省略其他配置
#protected-mode yes # 【已注释】这里再次出现了被注释掉的默认配置,可能是为了清晰起见或者编辑时的残留,实际生效的是上面的 protected-mode no。
[root@rd2/3 ~]# systemctl restart redis_6379.service # 重启这台服务器上的 Redis 服务,使"成为从节点"的配置生效。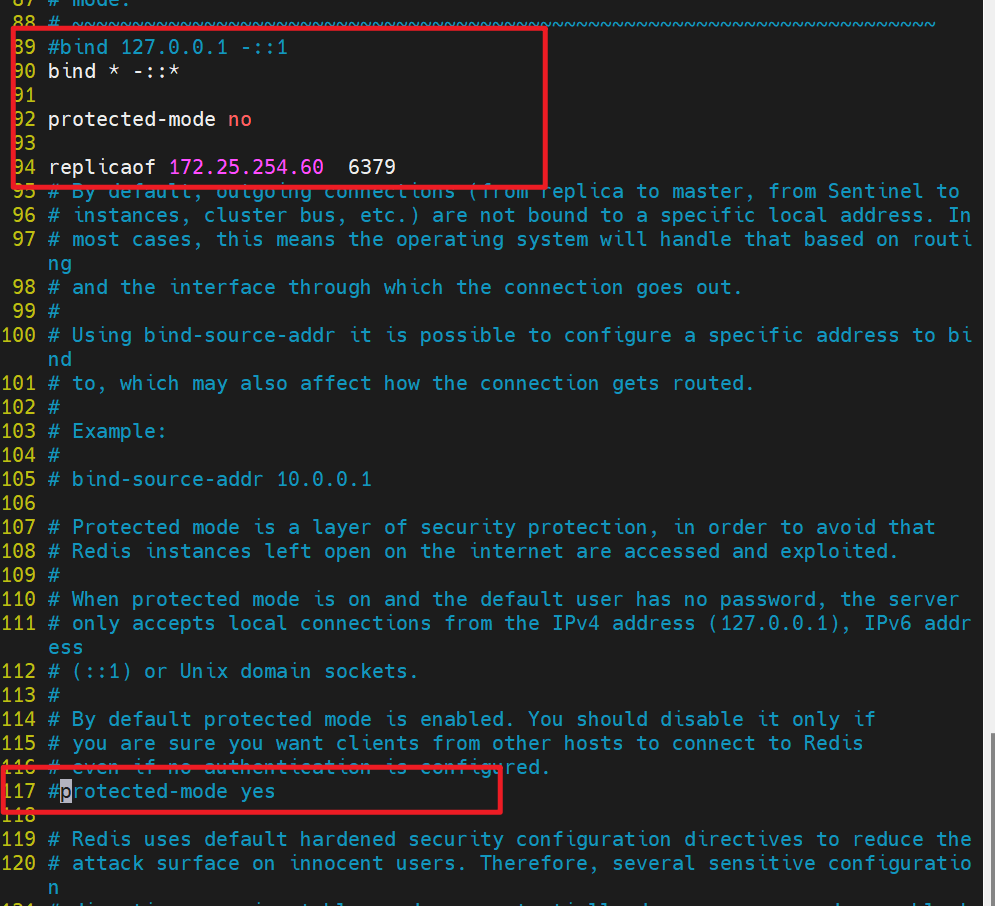
bash
#查看状态
#rd1
[root@rd1 ~]# redis-cli info replication # 在 rd1 服务器上执行命令,查看其复制角色和状态信息
# Replication # 以下是关于"复制"部分的详细信息
role:master # 【角色】当前实例的角色是"主节点"(master)。
connected_slaves:2 # 【连接的从节点数】当前有 2 个从节点成功连接到此主节点。
slave0:ip=172.25.254.70,port=6379,state=online,offset=658,lag=0 # 【从节点0信息】
# - ip/port: 从节点的地址和端口。
# - state=online: 表示该从节点在线且正常。
# - offset=658: 从节点已同步到的数据偏移量。
# - lag=0: 延迟为0,表示从节点与主节点几乎完全同步,没有积压的命令。
slave1:ip=172.25.254.80,port=6379,state=online,offset=658,lag=1 # 【从节点1信息】
# - 信息与 slave0 类似。
# - lag=1: 表示有1个字节的命令还未被该从节点处理,存在极小的延迟,这是正常现象。
master_failover_state:no-failover # 【故障转移状态】当前没有进行主从故障转移。
master_replid:37aff4ba50bd9d5f46cd10724b744a6fb3e9b45c # 【主节点复制ID】这是主节点的唯一标识符,用于在故障转移后识别新的主节点。
master_replid2:0000000000000000000000000000000000000000 # 【旧的复制ID】如果此节点曾是从节点,这里会保存它之前所属主节点的ID。全0表示它一直是主节点或这是它的第一个身份。
master_repl_offset:658 # 【主节点复制偏移量】主节点自己产生的数据流的总字节数。两个从节点的 offset 应该接近这个值。
second_repl_offset:-1 # 【第二个复制偏移量】通常为-1,除非在特定故障转移场景下。
repl_backlog_active:1 # 【复制积压缓冲区激活】值为1表示复制积压缓冲区已启用。这是一个环形缓冲区,用于在主从短暂断连后进行增量同步。
repl_backlog_size:1048576 # 【复制积压缓冲区大小】缓冲区的大小为 1MB (1024 * 1024 字节)。
repl_backlog_first_byte_offset:1 # 【缓冲区起始偏移量】缓冲区中第一个字节的偏移量。
repl_backlog_histlen:658 # 【缓冲区历史长度】缓冲区中当前存储的有效数据长度。
#rd2
[root@rd2 ~]# redis-cli info replication # 在 rd2 服务器上执行命令
# Replication
role:slave # 【角色】当前实例的角色是"从节点"(slave)。
master_host:172.25.254.60 # 【主节点主机】它所连接的主节点的 IP 地址。这与第一张图中的主节点 IP 一致。
master_port:6379 # 【主节点端口】它所连接的主节点的端口。
master_link_status:up # 【主从连接状态】值为 "up" 表示与主节点的连接是正常的、健康的。如果是 "down" 则表示连接断开。
master_last_io_seconds_ago:6 # 【上次IO时间】距离上一次与主节点进行通信已经过去了6秒。
master_sync_in_progress:0 # 【同步进行中】值为0表示当前没有在进行全量数据同步。如果为1,表示正在从主节点拉取快照(RDB文件)。
slave_read_repl_offset:644 # 【从节点读取偏移量】从节点已经从主节点接收并放入接收缓冲区的数据量。
slave_repl_offset:644 # 【从节点复制偏移量】从节点已经实际处理并应用到自身数据集的数据量。通常这两个值会非常接近。
slave_priority:100 # 【从节点优先级】用于 Sentinel 或 Cluster 进行故障转移时选举新主节点的优先级。数值越小,优先级越高。
slave_read_only:1 # 【只读模式】值为1表示此从节点处于只读模式,不能接受写操作(除了少数管理命令)。
replica_announced:1 # 【副本已宣告】表示此从节点已向主节点宣告自己的存在。
connected_slaves:0 # 【连接的从节点数】因为自己是 slave,所以它下面没有连接其他 slave,故为0。
master_failover_state:no-failover # 【故障转移状态】同主节点,表示没有故障转移发生。
master_replid:37aff4ba50bd9d5f46cd10724b744a6fb3e9b45c # 【主节点复制ID】与主节点的 master_replid 完全相同,证明它连接的是正确的主节点。
... (以下 repl_backlog 相关参数为从节点自身的积压缓冲区信息)
#rd3
[root@rd3 ~]# redis-cli info replication # 在 rd3 服务器上执行命令
# Replication
role:slave # 【角色】从节点。
master_host:172.25.254.60 # 【主节点主机】同样连接到 IP 为 172.25.254.60 的主节点。
master_port:6379 # 【主节点端口】
master_link_status:up # 【主从连接状态】连接正常。
master_last_io_seconds_ago:9 # 【上次IO时间】距离上次通信9秒。
master_sync_in_progress:0 # 【同步进行中】未在进行全量同步。
slave_read_repl_offset:630 # 【从节点读取偏移量】
slave_repl_offset:630 # 【从节点复制偏移量】
slave_priority:100 # 【从节点优先级】
slave_read_only:1 # 【只读模式】
replica_announced:1 # 【副本已宣告】
connected_slaves:0 # 【连接的从节点数】
master_failover_state:no-failover
master_replid:37aff4ba50bd9d5f46cd10724b744a6fb3e9b45c # 【主节点复制ID】与主节点和其他从节点的 ID 一致,确认了它们在同一个复制组中。
... (以下 repl_backlog 相关参数)
#测试数据同步性
# rd1
[root@rd1 ~]# redis-cli # 在 rd1 (主节点) 上启动 Redis 命令行客户端。
127.0.0.1:6379> set name h # 【写操作】执行 SET 命令,创建一个键为 "name",值为 "h" 的数据。
OK # Redis 返回 "OK",表示写入成功。此时,数据已经存储在主节点的内存中。
127.0.0.1:6379> get name # 【读操作】执行 GET 命令,读取刚才写入的 "name" 键的值,以确认写入成功。
"h" # Redis 返回 "h",证实数据已正确写入。
127.0.0.1:6379> quit # 退出 Redis 命令行客户端。
#rd2
[root@rd2 ~]# redis-cli # 在 rd2 (从节点) 上启动 Redis 命令行客户端。
127.0.0.1:6379> get name # 【读操作】尝试读取键为 "name" 的值。注意,这个节点本身没有执行过 SET 命令。
"h" # Redis 返回了 "h"。这证明了数据已经从主节点 `rd1` 成功复制到了这个从节点 `rd2`。
127.0.0.1:6379> quit # 退出 Redis 命令行客户端。
#rd3
[root@rd3 ~]# redis-cli get name # 这条命令略有不同,它直接在 shell 中调用 redis-cli 并执行 "get name" 命令,效果等同于先进入客户端再执行命令。
"h" # 同样,Redis 返回了 "h"。这表明第二个从节点 `rd3` 也成功地从主节点 `rd1` 同步了数据。5.4 总结
(1)⭐⭐⭐ 主从复制架构概述
| 角色 | 节点 | IP 地址 | 职责 |
|---|---|---|---|
| ⭐⭐⭐ Master(主节点) | redis-node1 / rd1 | 172.25.254.60 | 负责写操作,数据源头 |
| ⭐⭐ Slave(从节点) | redis-node2 / rd2 | 172.25.254.70 | 负责读操作,复制主节点数据 |
| ⭐⭐ Slave(从节点) | redis-node3 / rd3 | 172.25.254.80 | 负责读操作,复制主节点数据 |
⭐⭐⭐ 架构特点 :一主二从,读写分离,数据冗余备份
💡 生活例子 :主从复制像出版社和书店的关系------出版社(Master)负责出书写书(写操作),书店(Slave)负责卖书给读者(读操作)。出版社出一本新书,所有书店都会进货(数据同步)。读者去任何一家书店都能买到同样的书,但只能买不能写(从节点只读)。
(2)⭐⭐⭐ 环境配置建议
🔴 重要提示 :配置多台 Redis 时,建议用复制虚拟机的方式节省编译时间!
# 步骤:配置好一台 rd1 后,直接克隆为 rd2、rd3,然后修改 IP 即可
[root@rd2 ~]# vmset.sh eth0 172.25.254.70 rd2 # 修改 rd2 IP
[root@rd3 ~]# vmset.sh eth0 172.25.254.80 rd3 # 修改 rd3 IP💡 生活例子:就像烘焙蛋糕,与其每次从头和面、打蛋(重新编译安装),不如一次性烤好一个完美蛋糕,然后复制两份,分别插上不同的蜡烛(修改 IP)------省时省力且保证一致性。
(3)🔴🔴🔴 主从配置详解
⭐⭐⭐ Master 节点配置(rd1)
[root@rd1 ~]# vim /etc/redis/6379.conf
# 修改以下关键配置:
bind * -::* # ⭐⭐⭐ 监听所有网络接口(允许远程连接)
protected-mode no # ⭐⭐⭐ 关闭保护模式(必须配合 bind 使用)🔴🔴 安全警告 :生产环境应设置密码 requirepass,不能单纯依赖 protected-mode no!
💡 生活例子 :
bind *像把家门从"只让家人进"改成"谁都能敲门",protected-mode no像把门上的防盗链拆掉。方便客人(从节点)进来,但也让小偷(攻击者)有机可乘。所以生产环境要加把锁(密码),而不是完全敞开门。
⭐⭐⭐ Slave 节点配置(rd2、rd3)
[root@rd2/3 ~]# vim /etc/redis/6379.conf
# 修改以下关键配置:
bind * -::* # 监听所有网络接口
protected-mode no # 关闭保护模式
replicaof 172.25.254.60 6379 # ⭐⭐⭐⭐⭐ **核心配置:指定主节点地址和端口**🔴🔴🔴 核心命令解析:
-
replicaof 172.25.254.60 6379:声明"我是 172.25.254.60:6379 的复制品(从节点)" -
Redis 5.0+ 使用
replicaof,旧版本使用slaveof(功能相同)
💡 生活例子 :
replicaof像认大哥 ------rd2 和 rd3 对 rd1 说:"以后你就是我大哥(Master),你写的东西我全盘复制,你让我读我就读,绝不抢你写数据的活儿!"这是一种单向的、自动的追随关系。
(4)🔴🔴🔴 主从同步过程详解(核心难点)
根据流程图,同步分为 9 个步骤:
┌─────────┐ ┌─────────┐
│ master │◄──────1 sync───────│ slave │
│ (主) │◄──────2 认证───────│ (从) │
└────┬────┘ └────┬────┘
│ │
3 BGSAVE 6 flushall
│ │
▼ ▼
┌─────┐ 5 传输RDB ┌─────┐
│ rdb │───────────────────────►│ rdb │
│快照 │ │快照 │
└─────┘ └──┬──┘
│ │
8 fork新进程 7 load rdb
│ │
▼ ▼
┌─────┐ 9 replication ┌─────┐
│cache│──►replicationfeedslave──►│slave│
│缓存 │ 发送写命令 │ │
└─────┘ └─────┘| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | sync |
从节点发送同步请求 |
| 2 | 认证 | 主节点验证从节点身份 |
| 3 | BGSAVE |
⭐⭐⭐ 主节点后台生成 RDB 快照 |
| 4-5 | 传输 RDB | 主节点将内存快照发送给从节点 |
| 6 | flushall |
⭐⭐⭐ 从节点清空自身所有数据 |
| 7 | load rdb |
从节点加载 RDB 恢复数据 |
| 8 | fork 新进程 | 主节点开启新 BGSAVE 缓存未同步数据 |
| 9 | replicationfeedslave |
⭐⭐⭐ 持续同步增量数据 |
🔴🔴🔴 关键机制解析
⭐⭐⭐ BGSAVE(后台保存):
-
非阻塞操作 :主节点在生成 RDB 时,仍然可以处理写请求
-
Copy-On-Write:fork 子进程复制内存页,不影响主进程
⭐⭐⭐ 全量同步 vs 增量同步:
-
全量同步:首次连接时,传输整个 RDB 文件(像整本书复印)
-
增量同步 :后续通过
replicationfeedslave函数,逐条发送写命令(像后续每期杂志补寄)
💡 生活例子(出版社模型):
步骤 3-5:出版社(Master)把现有所有书籍打包成快递(RDB 快照),发给书店(Slave)。
步骤 6 :书店收到快递前,先把店里旧书全扔了(
flushall),确保和出版社完全一致。步骤 8:出版社在打包期间又出了新书(新写操作),不会等下一批快递,而是单独发顺丰(增量同步)。
步骤 9:以后出版社每出一本新书,就立即给所有书店发一本(实时复制),保证全网同步。
💡 生活例子(班级抄笔记):
学霸(Master)有一本完整笔记,学渣(Slave)请假没来上课。
学霸说:"我把笔记复印一份给你(BGSAVE 生成 RDB)"。
学渣拿到复印件前,先把自己原来的破烂笔记撕了(
flushall),然后誊抄学霸的(load rdb)。以后学霸每写一行新笔记,就立即拍照发给学渣(
replicationfeedslave),保证两人笔记实时一致。
(5)⭐⭐⭐ 状态验证命令
⭐⭐⭐ Master 节点查看(rd1)
[root@rd1 ~]# redis-cli info replication
role:master # ⭐⭐⭐ 角色:主节点
connected_slaves:2 # ⭐⭐⭐ 已连接从节点数:2个
slave0:ip=172.25.254.70... # 从节点1:rd2
slave1:ip=172.25.254.80... # 从节点2:rd3
master_repl_offset:658 # ⭐⭐⭐ 主节点复制偏移量(数据流字节数)
repl_backlog_active:1 # 复制积压缓冲区已启用⭐⭐⭐ Slave 节点查看(rd2、rd3)
[root@rd2 ~]# redis-cli info replication
role:slave # ⭐⭐⭐ 角色:从节点
master_host:172.25.254.60 # ⭐⭐⭐ 主节点 IP
master_port:6379 # 主节点端口
master_link_status:up # ⭐⭐⭐ **连接状态:up(正常)/ down(断开)**
master_replid:37aff4ba... # ⭐⭐⭐ 主节点复制 ID(唯一标识)
slave_read_only:1 # ⭐⭐⭐ **只读模式:1(开启)/ 0(关闭)**🔴🔴 关键指标解读
| 指标 | 正常值 | 含义 |
|---|---|---|
master_link_status |
up |
主从连接正常 |
master_last_io_seconds_ago |
< 10 | 上次通信时间,越小越好 |
slave_repl_offset |
≈ master_repl_offset |
同步偏移量,差距越小同步越实时 |
lag |
0-1 | 延迟秒数,0 表示完全同步 |
💡 生活例子 :
master_link_status:up像微信显示"对方正在输入...",表示连接畅通;slave_read_only:1像群聊里的"仅查看"权限------你能看到群主(Master)发的所有消息,但不能发言(写操作)。
(6)⭐⭐⭐ 数据同步测试
# 1. 在 Master 写入数据
[root@rd1 ~]# redis-cli
127.0.0.1:6379> SET name h
OK
# 2. 在 Slave 读取数据(自动同步)
[root@rd2 ~]# redis-cli
127.0.0.1:6379> GET name
"h" # ⭐⭐⭐ 数据已同步!
[root@rd3 ~]# redis-cli get name
"h" # 所有从节点数据一致🔴🔴 重要特性:
-
主节点写,从节点读 :实现读写分离
-
自动同步:主节点写入后,自动推送到所有从节点
-
从节点只读:尝试在从节点写入会报错
💡 生活例子 :就像微信公众号------号主(Master)发文,所有关注者(Slave)自动收到推送。关注者只能看不能改,但可以去任何关注者手机里看同样的内容(读负载均衡)。
(7)🔴🔴🔴 主从复制的核心机制
⭐⭐⭐ 复制 ID(Replication ID)
master_replid:37aff4ba50bd9d5f46cd10724b744a6fb3e9b45c-
每个主节点有唯一的复制 ID
-
从节点的
master_replid必须与主节点一致,证明复制关系正常 -
故障转移后 ,新的主节点会继承旧 ID(
master_replid2)
💡 生活例子 :复制 ID 像组织关系证明 ------每个党支部(Master)有唯一编号,党员(Slave)必须持有相同的组织编号才承认关系。如果支部撤销、党员转组织,会保留原编号记录(
master_replid2)以备查。
⭐⭐⭐ 复制积压缓冲区(Replication Backlog)
repl_backlog_active:1 # 缓冲区激活
repl_backlog_size:1048576 # 缓冲区大小:1MB
repl_backlog_histlen:658 # 当前积压数据长度🔴🔴 作用 :当从节点短暂断线后重连,主节点不需要重新发送整个 RDB,只需发送缓冲区内的增量数据。
💡 生活例子 :像快递代收点------你(Slave)出差几天没拿快递,回来后快递员(Master)不需要把之前所有包裹重新发一遍,只需从代收点(Backlog)拿这几天积压的包裹给你。
(8)🔴 主从复制的优缺点
| 优点 | 说明 |
|---|---|
| ⭐⭐⭐ 数据冗余 | 多份数据备份,防止单点故障 |
| ⭐⭐⭐ 读写分离 | 主写从读,提升并发性能 |
| ⭐⭐ 负载均衡 | 读请求分散到多个从节点 |
| ⭐⭐ 高可用基础 | 为 Sentinel 哨兵、Cluster 集群提供基础 |
| 缺点 | 说明 |
|---|---|
| 🔴 手动故障转移 | 主节点挂了需要人工切换(需配合 Sentinel) |
| 🔴 写性能瓶颈 | 所有写操作集中在主节点 |
| 🔴 数据一致性延迟 | 主从同步存在毫秒级延迟 |
(9)🔴 常用命令速查
| 命令 | 作用 | 使用场景 |
|---|---|---|
info replication |
⭐⭐⭐ 查看复制状态 | 排查主从关系 |
replicaof IP 端口 |
设置主节点 | 配置从节点 |
replicaof no one |
取消复制,变为主节点 | 故障转移时手动提升 |
slaveof IP 端口 |
旧版设置主节点(Redis < 5.0) | 兼容旧版本 |
(10)🔴 记忆口诀
主从复制 :一主二从读写分,replicaof 认大哥 同步过程 :BGSAVE 拍快照,flushall 清旧料 增量同步 :replfeedslave 实时推,offset 对齐不丢失 状态查看:info replication 看角色,link_status 验连接
六 Redis的哨兵(高可用)
实验环境:我们用主两从来实现Redis的高可用架构
6.1 Redis哨兵
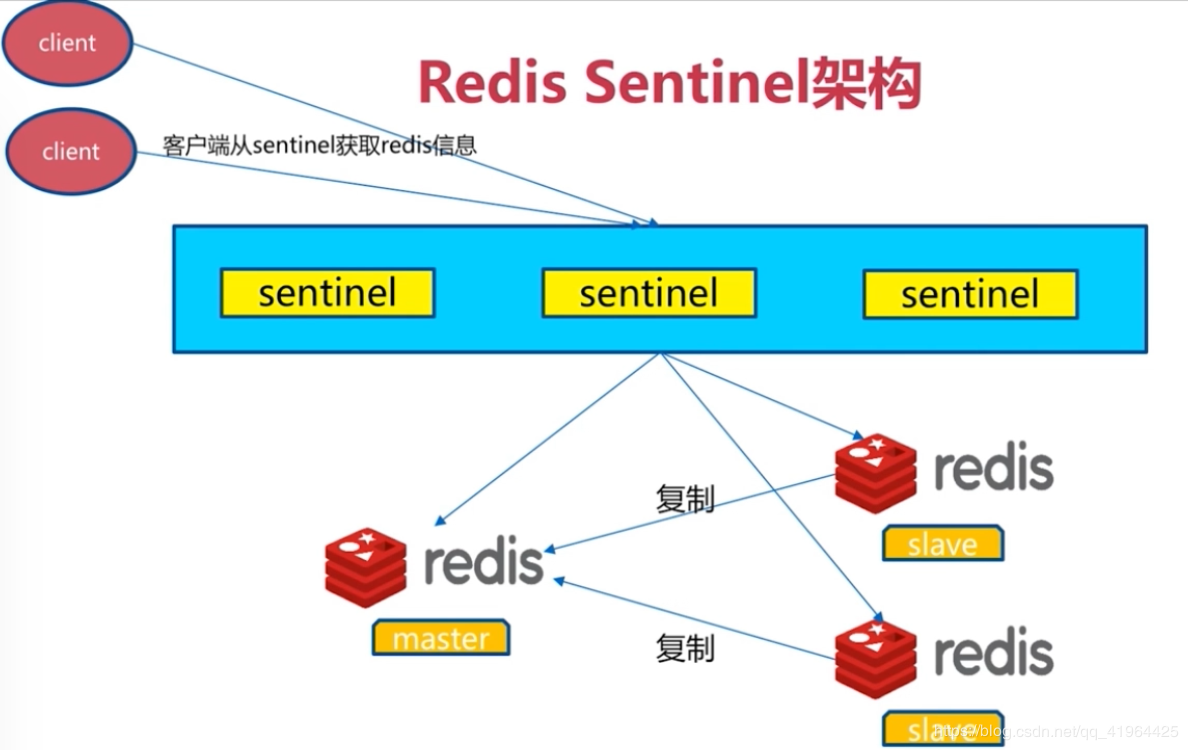
Sentinel 进程是用于监控redis集群中Master主服务器工作的状态,在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用,此功能在redis2.6+的版本已引用,Redis的哨兵模式到了2.8版本之后就稳定了下来。一般在生产环境也建议使用Redis的2.8版本的以后版本
每个哨兵(Sentinel)进程会向其它哨兵(Sentinel)、Master、Slave定时发送消息,以确认对方是否"活"着,如果发现对方在指定配置时间(此项可配置)内未得到回应,则暂时认为对方已离线,也就是所谓的"主观认为宕机" (主观:是每个成员都具有的独自的而且可能相同也可能不同的意识),英文名称:Subjective Down,简称SDOWN
有主观宕机,对应的有客观宕机。当"哨兵群"中的多数Sentinel进程在对Master主服务器做出SDOWN 的判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,这种方式就是"客观宕机"(客观:是不依赖于某种意识而已经实际存在的一切事物),英文名称是:Objectively Down, 简称 ODOWN
通过一定的vote算法,从剩下的slave从服务器节点中,选一台提升为Master服务器节点,然后自动修改相关配置,并开启故障转移(failover)
Sentinel 机制可以解决master和slave角色的自动切换问题,但单个 Master 的性能瓶颈问题无法解决,类似于MySQL中的MHA功能
Redis Sentinel中的Sentinel节点个数应该为大于等于3且最好为奇数
sentinel中的三个定时任务
-
每10秒每个sentinel对master和slave执行info
-
发现slave节点
-
确认主从关系
-
-
每2秒每个sentinel通过master节点的channel交换信息(pub/sub)
-
通过sentinel__:hello频道交互
-
交互对节点的"看法"和自身信息
-
-
每1秒每个sentinel对其他sentinel和redis执行pi
6.2 哨兵的实验过程
在所有阶段中关闭 protected-mode no
1.在master节点中
bash
#编辑配置文件
[root@redis-node1 ~]# cd redis-7.4.0/
[root@redis-node1 redis-7.4.0]# cp sentinel.conf /etc/redis/
[root@redis-node1 redis-7.4.0]# vim /etc/redis/sentinel.conf
protected-mode no #关闭保护模式
port 26379 #监听端口
daemonize no #进入不打如后台
pidfile /var/run/redis-sentinel.pid #sentinel进程pid文件
loglevel notice #日志级别
sentinel monitor mymaster 172.25.254.100 6379 2 #创建sentinel监控监控master主机,2表示必须得到2票
sentinel down-after-milliseconds mymaster 10000 #master中断时长,10秒连不上视为master下线
sentinel parallel-syncs mymaster 1 #发生故障转移后,同时开始同步新master数据的slave数量
sentinel failover-timeout mymaster 180000 #整个故障切换的超时时间为3分钟
####复制配置文件到其他阶段
[root@redis-node1 redis-7.4.0]# scp /etc/redis/sentinel.conf root@172.25.254.201:/etc/redis/
root@172.25.254.201's password:
sentinel.conf 100% 14KB 9.7MB/s 00:00
[root@redis-node1 redis-7.4.0]# scp /etc/redis/sentinel.conf root@172.25.254.200:/etc/redis/
root@172.25.254.200's password:
sentinel.conf
2 启动服务
bash
[root@redis-node1 redis-7.4.0]# redis-sentinel /etc/redis/sentinel.conf
39319:X 05 Aug 2024 20:53:16.807 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
39319:X 05 Aug 2024 20:53:16.807 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
39319:X 05 Aug 2024 20:53:16.807 * Redis version=7.4.0, bits=64, commit=00000000, modified=0, pid=39319, just started
39319:X 05 Aug 2024 20:53:16.807 * Configuration loaded
39319:X 05 Aug 2024 20:53:16.808 * Increased maximum number of open files to 10032 (it was originally set to 1024).
39319:X 05 Aug 2024 20:53:16.808 * monotonic clock: POSIX clock_gettime
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis Community Edition
.-`` .-```. ```\/ _.,_ ''-._ 7.4.0 (00000000/0) 64 bit
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 39319
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | https://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
39319:X 05 Aug 2024 20:53:16.810 * Sentinel new configuration saved on disk
39319:X 05 Aug 2024 20:53:16.810 * Sentinel ID is e568add863fd7c132e03f7a6ce2c5ef367d3bdae
39319:X 05 Aug 2024 20:53:16.810 # +monitor master mymaster 172.25.254.100 6379 quorum 2
39319:X 05 Aug 2024 20:53:16.811 * +slave slave 172.25.254.201:6379 172.25.254.201 6379 @ mymaster 172.25.254.100 6379
39319:X 05 Aug 2024 20:53:16.812 * Sentinel new configuration saved on disk
39319:X 05 Aug 2024 20:53:16.812 * +slave slave 172.25.254.200:6379 172.25.254.200 6379 @ mymaster 172.25.254.100 6379
39319:X 05 Aug 2024 20:53:16.813 * Sentinel new configuration saved on disk
39319:X 05 Aug 2024 20:53:41.769 * +sentinel sentinel 4fe1dcbe25a801e75d6edfc5b0a8517bfa7992c3 172.25.254.200 26379 @ mymaster 172.25.254.100 6379
39319:X 05 Aug 2024 20:53:41.771 * Sentinel new configuration saved on disk
39319:X 05 Aug 2024 20:53:57.227 * +sentinel sentinel 83f928aafe317a5f9081eea8fc5c383ff31c55ef 172.25.254.201 26379 @ mymaster 172.25.254.100 6379
39319:X 05 Aug 2024 20:53:57.229 * Sentinel new configuration saved on disk
!WARNING
/etc/redis/sentinel.conf 文件在用哨兵程序调用后会更改其配置文件,如果需要重新做需要删掉文件重新编辑
测试:
bash
在开一个master节点终端
[root@redis-node1 ~]# redis-cli
127.0.0.1:6379> SHUTDOWN
[root@redis-node2 ~]# redis-cli
127.0.0.1:6379> info replications
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.25.254.201,port=6379,state=online,offset=211455,lag=1
slave1:ip=172.25.254.100,port=6379,state=online,offset=211455,lag=1
master_failover_state:no-failover
master_replid:d42fd72f3dfae94c84ca722ad1653417495ef4fd
master_replid2:290c3407108cc6120086981b7149a6fa377594c4
master_repl_offset:211598
second_repl_offset:185931
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:150986
repl_backlog_histlen:606136.3. 在整个架构中可能会出现的问题
问题:
在生产环境中如果master和slave中的网络出现故障,由于哨兵的存在会把master提出去
当网络恢复后,master发现环境发生改变,master就会把自己的身份转换成slave
master变成slave后会把网络故障那段时间写入自己中的数据清掉,这样数据就丢失了。
解决:
master在被写入数据时会持续连接slave,mater确保有2个slave可以写入我才允许写入
如果slave数量少于2个便拒绝写入
bash
#在matster中设定
[root@redis-node2 ~]# redis-cli
127.0.0.1:6379> CONFIG GET min-slaves-to-write
1) "min-slaves-to-write"
2) "0"
127.0.0.1:6379> CONFIG set min-slaves-to-write 2
OK
127.0.0.1:6379> CONFIG GET min-slaves-to-write
1) "min-slaves-to-write"
2) "2"
#如果要永久保存写到配置文件中/etc/redis/6379.conf哨兵模式:
bash
[root@rd1 ~]# cd redis-7.4.8/
# 【切换目录】进入 Redis 7.4.8 的源代码或安装包目录。
[root@rd1 redis-7.4.8]# cp -p sentinel.conf /etc/redis/
# 【复制配置文件】将示例的 sentinel.conf 文件复制到 Redis 的标准配置目录 /etc/redis/ 下。
# -p 参数表示保留原文件的修改时间、访问权限等属性。
[root@rd1 redis-7.4.8]# vim /etc/redis/sentinel.conf
# [编辑配置文件] 使用 vim 编辑器打开并修改 sentinel.conf 文件。
92 #sentinel monitor mymaster 127.0.0.1 6379 2
# [已注释的旧配置] 这是示例文件中的默认行,已被注释掉,不再生效。
93 sentinel monitor mymaster 172.25.254.60 6379 2
# [修正后的核心配置] 这是关键的修改!将主节点的 IP 从错误的 172.25.254.100 改为了正确的 172.25.254.60 (即 rd1 的 IP)。
...
134 #sentinel down-after-milliseconds mymaster 30000
# [已注释的旧配置] 示例文件中的默认值(30秒),已被注释。
135 sentinel down-after-milliseconds mymaster 10000
# [自定义配置] 设置主观下线时间为 10000 毫秒(10秒)。如果 Sentinel 在 10 秒内联系不上主节点,就认为它可能出问题了。
...
210 sentinel parallel-syncs mymaster 1
# [并行同步数] 故障转移后,限制最多只有 1 个从节点可以同时向新主节点同步数据,避免网络风暴。
...
235 sentinel failover-timeout mymaster 180000
# [故障转移超时] 设置故障转移相关的超时时间为 180000 毫秒(3分钟)。
[root@rd1 ~]# scp /etc/redis/sentinel.conf root@172.25.254.70:/etc/redis/
# [分发配置文件 (1)] 将修正后的配置文件通过 scp 命令发送到第二个节点 rd2 (172.25.254.70)。
sentinel.conf 100% 14KB 7.9MB/s 00:00
# [传输成功] 显示文件已成功传输。
[root@rd1 ~]# scp /etc/redis/sentinel.conf root@172.25.254.80:/etc/redis/
# [分发配置文件 (2)] 同样地,将配置文件发送到第三个节点 rd3 (172.25.254.80)。
sentinel.conf 100% 14KB 13.6MB/s 00:00
# [传输成功] 显示文件已成功传输。现在三台机器的初始配置都一致且正确了。
[root@rd1/2/3 ~]# systemctl restart redis_6379.service
# [重启 Redis 服务] 在三台机器上重启 Redis 主从服务,确保其处于最佳状态。
[root@rd1/2/3 ~]# redis-sentinel /etc/redis/sentinel.conf
# [启动 Sentinel] 在三台机器上同时执行此命令,以前台模式启动 Sentinel 服务。
2582:X 15 Mar 2026 21:14:43.588 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
2582:X 15 Mar 2026 21:14:43.588 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2582:X 15 Mar 2026 21:14:43.588 * Redis version=7.4.8, bits=64, commit=00000000, modified=0, pid=2582, just started
2582:X 15 Mar 2026 21:14:43.588 * Configuration loaded
2582:X 15 Mar 2026 21:14:43.589 * Increased maximum number of open files to 10032 (it was originally set to 1024).
2582:X 15 Mar 2026 21:14:43.589 * monotonic clock: POSIX clock_gettime
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis Community Edition
.-`` .-```. ```\/ _.,_ ''-._ 7.4.8 (00000000/0) 64 bit
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 2582
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | https://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
2582:X 15 Mar 2026 21:14:43.593 * Sentinel new configuration saved on disk
2582:X 15 Mar 2026 21:14:43.593 * Sentinel ID is 033a4111d25ab829645e8189e9ac82817119a77e
2582:X 15 Mar 2026 21:14:43.593 # +monitor master mymaster 172.25.254.60 6379 quorum 2
2582:X 15 Mar 2026 21:14:43.594 * +slave slave 172.25.254.70:6379 172.25.254.70 6379 @ mymaster 172.25.254.60 6379
2582:X 15 Mar 2026 21:14:43.598 * Sentinel new configuration saved on disk
2582:X 15 Mar 2026 21:14:43.598 * +slave slave 172.25.254.80:6379 172.25.254.80 6379 @ mymaster 172.25.254.60 6379
2582:X 15 Mar 2026 21:14:43.601 * Sentinel new configuration saved on disk
2582:X 15 Mar 2026 21:14:52.554 * +sentinel sentinel e28c0f0db6354edb4b3ad08e5e315003a6975ed3 172.25.254.70 26379 @ mymaster 172.25.254.60 6379
2582:X 15 Mar 2026 21:14:52.561 * Sentinel new configuration saved on disk
2582:X 15 Mar 2026 21:14:59.495 * +sentinel sentinel 6c9e28a625b93afed0aadf11e57c7ef55abec4ec 172.25.254.80 26379 @ mymaster 172.25.254.60 6379
2582:X 15 Mar 2026 21:14:59.498 * Sentinel new configuration saved on disk
2582:signal-handler (1773580551) Received SIGINT scheduling shutdown...
2582:X 15 Mar 2026 21:15:51.662 * User requested shutdown...
2582:X 15 Mar 2026 21:15:51.662 * Removing the pid file.
2582:X 15 Mar 2026 21:15:51.663 # Sentinel is now ready to exit, bye bye...
#结果注释:
... * WARNING Memory overcommit must be enabled! ...
# [系统警告] 这是一个关于 Linux 内核内存管理的建议性警告,不影响 Sentinel 的核心功能,但最好按提示修复以提升稳定性。
2582:X 15 Mar 2026 ... * Redis version=7.4.8, bits=64, ..., pid=2582, just started
# [进程信息] Sentinel 进程启动,PID 为 2582,版本为 7.4.8。
2582:X 15 Mar 2026 ... * Configuration loaded
# [配置加载] 成功读取了我们刚刚修改并分发的配置文件。
2582:X 15 Mar 2026 ... * Increased maximum number of open files to 10032 ...
# [资源调整] Sentinel 自动调高了可打开文件数的限制,以应对高并发连接。
# [ASCII Art Logo]
# Redis 的启动图标,表示程序正常运行。
Redis Community Edition
7.4.8 (00000000/0) 64 bit
Running in sentinel mode
Port: 26379
PID: 2582
# [运行摘要] 确认 Sentinel 正在 26379 端口上运行。
2582:X 15 Mar 2026 ... * Sentinel new configuration saved on disk
# [保存配置] Sentinel 启动后,会立即将运行时信息保存到配置文件,所以配置文件内容会增加。
2582:X 15 Mar 2026 ... * Sentinel ID is 033a4111d25ab829645e8189e9ac82817119a77e
# [哨兵 ID] 生成了当前 Sentinel 实例的唯一标识符。
2582:X 15 Mar 2026 ... # +monitor master mymaster 172.25.254.60 6379 quorum 2
# [开始监控] Sentinel 开始监控名为 "mymaster" 的主节点,IP 为 172.25.254.60,法定人数为 2。**这次没有再报 +sdown 错误,说明 IP 地址正确,连接成功!**
2582:X 15 Mar 2026 ... * +slave slave 172.25.254.70:6379 172.25.254.70 6379 @ mymaster 172.25.254.60 6379
# [自动发现从节点 (1)] Sentinel 连接到主节点后,通过 `INFO REPLICATION` 命令自动发现了第一个从节点 (rd2, 172.25.254.70),并将其添加到监控列表。
2582:X 15 Mar 2026 ... * +slave slave 172.25.254.80:6379 172.25.254.80 6379 @ mymaster 172.25.254.60 6379
# [自动发现从节点 (2)] 同样地,Sentinel 也自动发现了第二个从节点 (rd3, 172.25.254.80)。
2582:X 15 Mar 2026 ... * +sentinel sentinel e28c0f0db6354edb4b3ad08e5e315003a6975ed3 172.25.254.70 26379 @ mymaster 172.25.254.60 6379
# [自动发现其他哨兵 (1)] Sentinel 通过 gossip 协议与其他哨兵通信,发现了正在运行的、位于 172.25.254.70 (rd2) 的另一个哨兵实例。
2582:X 15 Mar 2026 ... * +sentinel sentinel 6c9e28a625b93afed0aadf11e57c7ef55abec4ec 172.25.254.80 26379 @ mymaster 172.25.254.60 6379
# [自动发现其他哨兵 (2)] Sentinel 又发现了位于 172.25.254.80 (rd3) 的第三个哨兵实例。至此,三个哨兵已经互相认识,形成了哨兵集群。
2582:signal-handler (...) Received SIGINT scheduling shutdown...
# [接收中断信号] 用户按下了 Ctrl+C,向 Sentinel 进程发送了终止信号。
2582:X 15 Mar 2026 ... * User requested shutdown...
# [用户请求关闭] Sentinel 响应关闭请求。
2582:X 15 Mar 2026 ... # Sentinel is now ready to exit, bye bye...
# [正常退出] Sentinel 完成清理工作后,正常退出。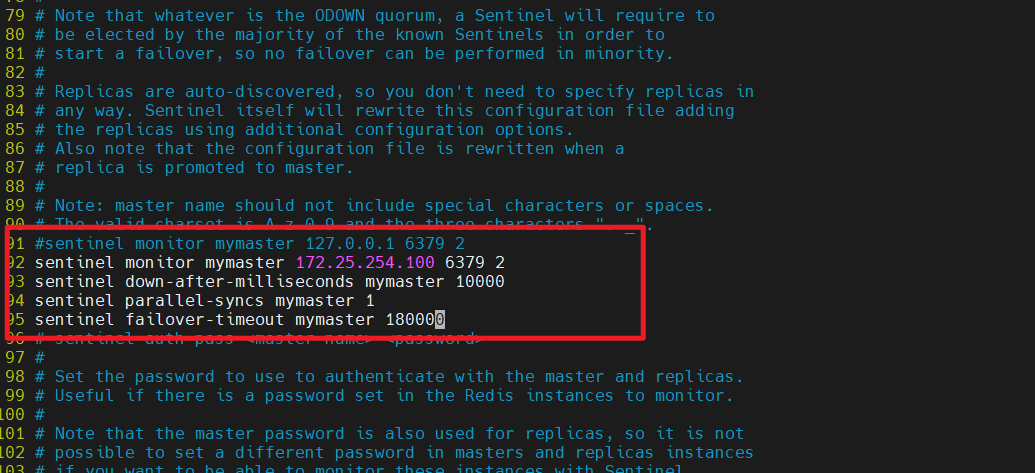
#这里的172.25.254.100应该是172.25.254.60;
bash
#故障检测
#1.故障制造
[root@rd1 ~]# redis-cli shutdown
# [关闭 Redis 主服务] 这条命令向本地运行的 Redis 服务器(即主节点)发送一个 SHUTDOWN 指令,使其正常停止。
# 这意味着 IP 为 172.25.254.60 的 Redis 主节点现在已下线。
[root@rd1 ~]# redis-sentinel /etc/redis/sentinel.conf
# [启动 Sentinel] 在主节点已经关闭的情况下,启动 Sentinel 服务。这将用于测试 Sentinel 的故障检测能力。
#以下是 redis-sentinel 命令的输出日志分析:
2593:X 15 Mar 2026 ... # WARNING Memory overcommit must be enabled! ...
# [系统警告] 关于 Linux 内核内存超分的建议性警告,与核心功能无关,但最好修复。
2593:X 15 Mar 2026 ... * Redis version=7.4.8, bits=64, ..., pid=2593, just started
# [进程信息] Sentinel 进程 (PID 2593) 已成功启动。
2593:X 15 Mar 2026 ... * Configuration loaded
# [配置加载] Sentinel 成功读取了配置文件。
2593:X 15 Mar 2026 ... * Increased maximum number of open files to 10032 ...
# [资源调整] Sentinel 自动增加了文件描述符限制。
# [ASCII Art Logo]
# Redis 启动成功的标志。
Redis Community Edition
7.4.8 (00000000/0) 64 bit
Running in sentinel mode
Port: 26379
PID: 2593
# [运行摘要] 确认 Sentinel 正在 26379 端口上以哨兵模式运行。
2593:X 15 Mar 2026 ... * Sentinel ID is 033a4111d25ab829645e8189e9ac82817119a7...
# [哨兵 ID] 显示当前 Sentinel 实例的唯一标识符。
2593:X 15 Mar 2026 ... # +monitor master mymaster 172.25.254.60 6379 quorum 2
# [开始监控] Sentinel 开始尝试监控名为 "mymaster" 的主节点 (172.25.254.60)。
2593:X 15 Mar 2026 ... # +sdown master mymaster 172.25.254.60 6379
# [主观下线 (Subjectively Down)] **关键日志!**
# 由于我们在启动 Sentinel 之前已经用 `redis-cli shutdown` 关闭了主节点,Sentinel 在配置的 `down-after-milliseconds` (10秒) 时间内无法连接到主节点。
# 因此,它根据自己的判断,将该主节点标记为"主观下线"(+sdown)。这是故障转移流程的第一步。
2593:X 15 Mar 2026 ... # +sdown sentinel e28c0f0db6354edb4b3ad08e5e315003a6975ed3 172.25.254.70 26379 @ mymaster ...
# [其他哨兵也下线?] 这条日志表示,这个 Sentinel 实例也认为位于 172.25.254.70 的另一个哨兵实例下线了。
# 这很可能是因为网络问题,或者那个哨兵实例本身也没有运行,导致它们之间无法通过 gossip 协议通信。
2593:X 15 Mar 2026 ... # +sdown sentinel 6c9e28a625b93afed0aadf11e57c7ef55abec4ec 172.25.254.80 26379 @ mymaster ...
# [其他哨兵也下线?] 同样地,它也认为位于 172.25.254.80 的第三个哨兵实例下线了。
# 【注意】要触发真正的故障转移(Failover),需要达到配置的法定人数(quorum 2)。目前只有一个 Sentinel 报告主节点下线,所以还不会发生主从切换。
2593:signal-handler (...) Received SIGINT scheduling shutdown...
# [接收中断信号] 用户按下了 Ctrl+C,向 Sentinel 进程发送了终止信号。
2593:X 15 Mar 2026 ... * User requested shutdown...
# [用户请求关闭] Sentinel 响应关闭请求。
2593:X 15 Mar 2026 ... * Removing the pid file.
# [清理工作] Sentinel 删除其 PID 文件。
2593:X 15 Mar 2026 ... # Sentinel is now ready to exit, bye bye...
# [正常退出] Sentinel 进程正常结束。
[root@rd3 ~]# redis-cli info replication
# [查询复制信息] 在 rd3 这台服务器上,使用 redis-cli 客户端连接到本地 Redis 服务,并执行 INFO REPLICATION 命令。
# 该命令用于查看当前实例在主从复制架构中的角色和状态。
# Replication
# [章节标题] 以下所有信息都属于"复制"这一类别。
role:slave
# [当前角色] 明确指出这个 Redis 实例是一个**从节点 (slave)**。
master_host:172.25.254.60
# [主节点地址] 这个从节点配置的主节点 IP 地址是 172.25.254.60 (即 rd1)。
master_port:6379
# [主节点端口] 主节点的监听端口是 6379。
master_link_status:down
# [连接状态 - 关键!] **这是最重要的信息之一。** 它表示这个从节点与主节点之间的网络连接已经断开 (down)。
# 这意味着数据同步已经停止,从节点无法接收来自主节点的新写入操作。
master_last_io_seconds_ago:-1
# [上次IO时间] 值为 -1 通常表示自从连接断开后,就没有再成功进行过任何 I/O 操作。
master_sync_in_progress:0
# [同步进行中] 值为 0 表示当前没有正在进行的全量或部分数据同步。因为连接都断了,自然无法同步。
slave_read_repl_offset:98596
# [读取偏移量] 这个从节点已经从主节点读取并处理了 98596 字节的数据。
slave_repl_offset:98596
# [自身偏移量] 这个从节点自身的复制偏移量也是 98596。这两个值相等是正常的,表示它已经应用了所有接收到的数据。
master_link_down_since_seconds:395
# [断开时长] 主从链接已经断开了 395 秒(约 6 分半钟)。这证实了连接中断不是刚刚发生的,而是一个持续性的问题。
slave_priority:100
# [从节点优先级] 这个从节点的优先级是 100。在 Sentinel 进行故障转移时,会优先选择优先级数值更小的从节点提升为新主节点。
slave_read_only:1
# [只读模式] 值为 1 表示这个从节点处于只读模式,不能接受写操作。这是从节点的标准行为。
replica_announced:1
# [已宣告] 值为 1 表示这个从节点已经向其他客户端和哨兵宣告了自己的存在。
connected_slaves:0
# [连接的从节点数] 值为 0。因为当前实例自己就是从节点 (slave),所以它下面没有连接其他的从节点。如果这是一个主节点,这里会显示有多少个从节点连着它。
master_failover_state:no-failover
# [故障转移状态] 当前没有发生故障转移。这个状态是由 Sentinel 管理的,但从节点也能看到这个信息。
master_replid:48d2d9023bd464a8155a8fe9828a79f0e3adcb9b
# [主节点复制ID] 这是主节点的第一个复制 ID。即使主从断开,从节点也会记住原主节点的 ID。
master_replid2:0000000000000000000000000000000000000000
# [第二个复制ID] 通常为全0,除非发生过故障转移且当前主节点是从之前的从节点升级上来的。
master_repl_offset:98596
# [主节点偏移量] 这是从节点所知道的、断开前主节点的复制偏移量,与 `slave_repl_offset` 一致。
second_repl_offset:-1
# [第二个偏移量] 通常为 -1。
repl_backlog_active:1
# [复制积压缓冲区激活] 值为 1 表示复制积压缓冲区 (replication backlog) 是激活的。这个缓冲区用于在主从短暂断开后进行部分重同步。
repl_backlog_size:1048576
# [缓冲区大小] 复制积压缓冲区的大小是 1048576 字节 (1MB)。
repl_backlog_first_byte_offset:20480
# [缓冲区起始偏移] 缓冲区中保存的数据的起始偏移量。
repl_backlog_histlen:78117
# [缓冲区历史长度] 缓冲区中当前保存的有效数据长度。
#2.故障恢复
[root@rd1 ~]# /etc/init.d/redis_6379 start
# [启动主节点服务] 使用传统的 init.d 脚本启动了位于 rd1 (172.25.254.60) 上的 Redis 服务。
# 这个服务就是之前被 `redis-cli shutdown` 命令关闭的那个主节点。
Starting Redis_server...
# [启动成功] 输出信息表明 Redis 服务器正在启动。执行完这条命令后,主节点就重新上线并开始监听 6379 端口了。
[root@rd3 ~]# redis-cli info replication
# [查询复制信息] 再次在从节点 rd3 上检查复制状态,以确认主节点恢复后的效果。
# Replication
role:slave
# [当前角色] 仍然是一个从节点。
master_host:172.25.254.60
# [主节点地址] 配置的主节点 IP 仍然是 172.25.254.60。
master_port:6379
# [主节点端口] 主节点端口仍然是 6379。
master_link_status:up
# [连接状态 - 关键变化!] **这是最重要的变化!** 状态从之前的 `down` 变为了 `up`。
# 这表明从节点 `rd3` 已经成功地与刚刚重启的主节点 `rd1` 重新建立了连接。
master_last_io_seconds_ago:3
# [上次IO时间] 值为 3,表示在 3 秒前刚与主节点有过一次成功的 I/O 通信。这进一步证实了连接是活跃且健康的。
master_sync_in_progress:0
# [同步进行中] 值为 0,表示没有进行耗时的全量同步。因为断开时间不长,数据差异在主节点的复制积压缓冲区 (backlog) 范围内,所以进行了快速的"部分重同步"。
slave_read_repl_offset:98638
# [读取偏移量] 从节点已处理的字节数。这个数字比断开前的 98596 增加了,说明它已经开始接收并处理来自主节点的新数据。
slave_repl_offset:98638
# [自身偏移量] 从节点自身的偏移量,与读取偏移量保持一致。
master_link_down_since_seconds:0 (此项在图中未显示,但逻辑上应为0或消失)
# [断开时长] 由于连接已经恢复,这项记录断开时长的信息通常会消失或被重置。
slave_priority:100
# [从节点优先级] 优先级保持不变。
slave_read_only:1
# [只读模式] 仍然处于只读模式。
replica_announced:1
# [已宣告] 仍然向集群宣告自己的存在。
connected_slaves:0
# [连接的从节点数] 作为从节点,其值为 0 是正常的。
master_failover_state:no-failover
# [故障转移状态] 没有发生故障转移,因为主节点已经被手动恢复了。
master_replid:ea141b60189519f17474c38344d309abd1c9cf68
# [主节点复制ID - 关键变化!] **注意,这个 ID 变了!**
# 这是因为主节点 `rd1` 重启后,生成了一个新的运行实例,因此拥有了一个新的复制 ID (replid)。
# 从节点通过比较新旧 ID 和数据偏移量,来判断是否可以进行部分重同步。
master_replid2:48d2d9023bd464a8155a8fe9828a79f0e3adcb9b
# [第二个复制ID - 关键变化!] **这个值不再是全0了!**
# 它变成了旧的 `master_replid`。这说明从节点记住了主节点的上一个 ID。
# 当主节点重启后,它会告知从节点自己的新 ID 和旧 ID。从节点发现自己的 `master_replid2` 与主节点的旧 ID 匹配,并且自己持有的数据偏移量 (`98596`) 在主节点的复制积压缓冲区内,于是成功进行了部分重同步,而不是耗时的全量同步。
master_repl_offset:98638
# [主节点偏移量] 从节点所知的主节点最新偏移量,已与自身同步。
second_repl_offset:98597
# [第二个偏移量] 记录了上一个主节点实例的偏移量信息,用于辅助判断部分重同步的可行性。
repl_backlog_active:1
# [复制积压缓冲区激活] 缓冲区依然激活。
repl_backlog_size:1048576
# [缓冲区大小] 大小不变。
repl_backlog_first_byte_offset:20480
# [缓冲区起始偏移] 缓冲区起始位置。
repl_backlog_histlen:78159
# [缓冲区历史长度] 缓冲区中的有效数据长度,略有增加,表明有新数据写入。
6.4 总结
(1)什么是 Redis 哨兵模式
⭐ 定义:Sentinel(哨兵)是 Redis 的高可用解决方案,用于监控主从集群中的 Master 节点状态,当 Master 发生故障时,自动完成故障转移(failover),将从节点提升为新的主节点。
🔴 核心作用:
-
监控:持续检查 Master 和 Slave 是否存活
-
通知:发现故障时通知管理员或其他应用
-
自动故障转移:Master 宕机时自动选举新 Master
-
配置提供者:客户端通过 Sentinel 获取当前主节点地址
生活例子 :想象一个演唱会现场的总控团队
Master 是台上的主唱 ,Slave 是替补歌手站在舞台两侧
Sentinel 就是导演组的监控人员(通常3人以上),他们戴着耳机盯着舞台
如果主唱突然晕倒(Master 宕机),监控人员立即通过对讲机通知:"主唱下线!3号替补顶上!",然后替补歌手立刻接过麦克风成为新的主唱,演唱会继续,观众几乎察觉不到中断。
(2)主观下线(SDOWN)与客观下线(ODOWN)
⭐⭐ 主观下线(Subjective Down, SDOWN):
-
单个 Sentinel 实例在配置的
down-after-milliseconds时间内(如10秒)无法联系到 Master -
这只是一个哨兵自己的判断,可能因网络抖动等误判
🔴🔴🔴 客观下线(Objective Down, ODOWN):
-
当** quorum(法定人数)** 个 Sentinel 都认为 Master 主观下线了,通过互相交流确认后,才判定 Master 真正下线
-
这是集体的、客观的事实
生活例子 :学校判断学生是否逃课
主观下线:数学老师点名,小明没回答,数学老师心想"小明可能逃课了"(只是数学老师一个人的猜测,小明可能在厕所或生病)
客观下线:数学老师、语文老师、英语老师都发现小明不在,三人碰头确认后,上报教务处:"小明确实逃课了,通知家长!"
🔴 关键点:必须多个老师(quorum=2)确认,才能避免冤枉学生(避免误判)
(3)哨兵的数量要求
⭐⭐ 必须 >= 3 个且最好为奇数
🔴🔴 原因:
-
偶数问题:如果是2个,各执一词时无法达成多数(1:1平局);如果是4个,2:2还是平局
-
奇数优势:3个可以2:1表决,5个可以3:2表决,总能形成多数决
-
高可用性:允许 (n-1)/2 个哨兵失效,集群仍能工作(3个允许挂1个,5个允许挂2个)
生活例子 :小区业主委员会投票
如果只有2个委员,一个说"换物业",一个说"不换",永远僵持不下(脑裂)
3个委员,2人同意就能决定,即使1人失联或弃权,事情也能推进
这就是为什么要"奇数"------避免平局,确保决策效率
(4)三个核心定时任务(Sentinel 的心跳机制)
⭐⭐⭐ 每10秒 :每个 Sentinel 对 Master 和 Slave 执行 INFO 命令
-
发现新的 Slave 节点
-
确认主从关系
⭐⭐ 每2秒 :每个 Sentinel 通过 Master 节点的 __sentinel__:hello 频道发布/订阅消息
-
交换对节点的"看法"(谁觉得 Master 下线了)
-
交换自身信息(IP、端口、运行ID等)
⭐ 每1秒 :每个 Sentinel 对其他 Sentinel 和 Redis 执行 PING
- 检测对方是否存活(心跳检测)
生活例子 :医院 ICU 病房的监护系统
每10秒 :护士查看病人的完整病历(INFO),记录血压、心率等所有指标,看看有没有新病人转进来
每2秒 :护士们在值班室的黑板(pub/sub频道)上写字交流:"3床病人情况稳定"、"5床需要关注",所有护士都能看到
每1秒 :监护仪**"滴"一声**(PING),如果连续几声没"滴",说明仪器或病人出问题了,立即报警
🔴 难点理解 :这三个频率是层层递进的------10秒是全面体检,2秒是交班沟通,1秒是生命线监测,缺一不可
(5)故障转移(Failover)流程
🔴🔴🔴🔴 完整流程:
(1)发现故障:多个 Sentinel 达成 ODOWN 共识
(2)选举领头 Sentinel:Sentinel 之间通过 Raft 算法选举出一个"领导者"来执行故障转移(避免多个 Sentinel 同时操作导致混乱)
(3)选择新 Master:从 Slave 中选出最优的一个
-
优先级(slave-priority)最小的
-
复制偏移量最大的(数据最新的)
-
Run ID 最小的
(4)提升新 Master :向选中的 Slave 发送 SLAVEOF NO ONE 命令
(5)重新配置从节点:让其他 Slave 改为复制新 Master
(6)更新配置:将旧 Master(如果恢复)标记为新 Master 的 Slave
生活例子 :公司 CEO 突然离职后的应急处理
(发现故障)董事会成员(Sentinel)发现 CEO(Master)联系不上,连续3个董事确认后,宣布"CEO 客观下线"
(选举领头)董事们投票选出一个临时董事长(领头 Sentinel)来主持大局,避免多人瞎指挥
(选择新 CEO)从 VP(Slave)中选:先看职级 (优先级),再看最近业绩 (复制偏移量,谁最了解公司现状),最后看入职时间(Run ID)
(上任)临时董事长宣布:"VP 张三升任 CEO!"
(重组团队)通知其他 VP:"以后向张三汇报,不再是前任 CEO"
(善后)前任 CEO 回来后,自动降为普通 VP,向新 CEO 汇报
(6)网络分区问题(脑裂)及解决方案
🔴🔴🔴🔴🔴 问题描述:
-
如果 Master 与 Slave 之间的网络中断,但 Master 本身没宕机
-
Sentinel 会认为 Master 下线,选举新 Master
-
网络恢复后,旧 Master 发现自己被降级为 Slave,会清空自己在这段时间写入的数据 (因为要以新 Master 为准同步),导致数据丢失!
⭐⭐⭐⭐⭐ 解决方案 :min-slaves-to-write
-
配置 Master:只有当至少 N 个 Slave 连接正常时,才允许写入
-
如果 Slave 数量不足,Master 拒绝写入,客户端报错
生活例子 :银行转账的安全机制
问题场景 :你在北京(Master)给同事转账,但北京到上海的专线断了,银行系统以为北京分行倒闭了,启用上海分行(新 Master)作为总部。你在北京转了一笔钱(写入旧 Master),同事在上海也操作了账户(写入新 Master)。后来网络恢复,北京分行发现自己不是总部了,为了和上海保持一致,把你转的那笔记录删了------钱没了!
解决方案:北京分行(Master)设置规则:"除非我至少能联系到2个其他分行(min-slaves-to-write=2),否则不接受任何转账请求"。这样网络断了,北京分行自动停止服务,不会有新数据写入,也就不会丢失数据。
(7)关键配置参数详解
⭐⭐ sentinel monitor mymaster <ip><port><quorum>
- 监控的主节点信息,
<quorum>是判定 ODOWN 所需的最少 Sentinel 票数
🔴🔴 sentinel down-after-milliseconds mymaster 10000
- 主观下线判断时间,10秒连不上即认为 SDOWN
⭐ sentinel parallel-syncs mymaster 1
-
故障转移后,同时向新 Master 同步数据的 Slave 数量
-
设置为1是避免所有 Slave 同时同步导致网络拥塞
🔴 sentinel failover-timeout mymaster 180000
- 整个故障转移过程的超时时间(3分钟)
生活例子 :消防应急响应配置
monitor:消防监控中心盯着哪个建筑(ip:port),需要几个烟雾报警器同时响(quorum=2)才确认火灾
down-after-milliseconds:烟雾报警器响多久(10秒)才确认不是误报
parallel-syncs:火灾后疏散时,一次开几个安全出口(1个),避免所有人挤向出口导致踩踏
failover-timeout:从发现火灾到完全控制火势的最长允许时间(3分钟),超过就算救援失败
(8)架构图解析
⭐⭐⭐ 图片核心要素:
-
客户端不直接连接 Redis:而是连接 Sentinel 集群获取当前 Master 地址
-
Sentinel 集群独立于 Redis 集群:通常部署在3台独立机器上,或与 Redis 节点混部
-
主从复制关系:Master 负责写,Slave 负责读,数据通过"复制"流向 Slave
-
Sentinel 监控所有节点:既监控 Master,也监控 Slave,还监控其他 Sentinel
plain
复制
┌─────────┐ ┌─────────┐
│ client │ │ client │
└────┬────┘ └────┬────┘
│ │
└───────┬───────┘
▼
┌─────────────────────┐
│ ┌─────┐┌─────┐┌─────┐ │ ◄── Sentinel 集群(3个,奇数)
│ │sentinel│sentinel│sentinel│ │
│ └─────┘└─────┘└─────┘ │
└───────┬─────────────┘
│ 监控 & 故障转移
┌───────┼───────┐
▼ ▼ ▼
┌──────┐ ┌──────┐ ┌──────┐
│Master│◄─┤ Slave│ │ Slave│ ◄── Redis 主从集群
│ (写) │ │ (读) │ │ (读) │
└──────┘ └──────┘ └──────┘
▲ │ │
└─────────┴─────────┘
复制(Replication)(9)生产环境注意事项
⭐⭐ 配置文件会被修改 :Sentinel 启动后会自动在 sentinel.conf 中追加运行时信息(如发现的 Slave、其他 Sentinel 的 ID 等),如果需要重新实验,必须删除配置文件重新编辑
🔴🔴🔴 必须关闭保护模式 :protected-mode no,否则 Sentinel 之间无法通信
⭐ 内存超分警告 :启动时可能会提示 vm.overcommit_memory = 1,建议按提示修改系统内核参数,避免后台保存失败
(10)总结记忆口诀
一主两从做基础,三哨奇数来监护
十秒info两秒聊,一秒ping下要知道
主观猜测客观定,投票选出领头人
网络分区会丢数,min-slaves来防护
客户端别直连库,先问哨兵找主库七 Redis Cluster(无中心化设计)
7.1 Redis Cluster 工作原理
在哨兵sentinel机制中,可以解决redis高可用问题,即当master故障后可以自动将slave提升为master,从而可以保证redis服务的正常使用,但是无法解决redis单机写入的瓶颈问题,即单机redis写入性能受限于单机的内存大小、并发数量、网卡速率等因素。
redis 3.0版本之后推出了无中心架构的redis cluster机制,在无中心的redis集群当中,其每个节点保存当前节点数据和整个集群状态,每个节点都和其他所有节点连接
Redis Cluster特点如下
-
所有Redis节点使用(PING机制)互联
-
集群中某个节点的是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效
-
客户端不需要proxy即可直接连接redis,应用程序中需要配置有全部的redis服务器IP
-
redis cluster把所有的redis node 平均映射到 0-16383个槽位(slot)上,读写需要到指定的redis node上进行操作,因此有多少个redis node相当于redis 并发扩展了多少倍,每个redis node 承担16384/N个槽位
-
Redis cluster预先分配16384个(slot)槽位,当需要在redis集群中写入一个key -value的时候,会使用CRC16(key) mod 16384之后的值,决定将key写入值哪一个槽位从而决定写入哪一个Redis节点上,从而有效解决单机瓶颈。
Redis cluster 架构
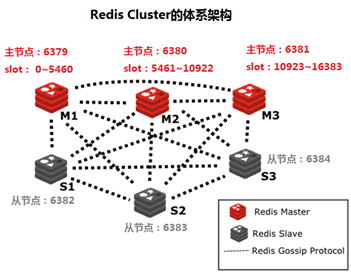
假如三个主节点分别是:A, B, C 三个节点,采用哈希槽 (hash slot)的方式来分配16384个slot 的话它们三个节点分别承担的slot 区间可以是:
节点A覆盖 0-5460
节点B覆盖 5461-10922
节点C覆盖 10923-16383!
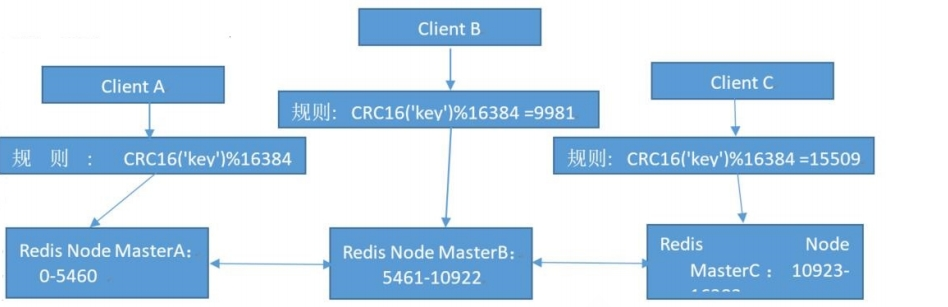
Redis cluster 主从架构
Redis cluster的架构虽然解决了并发的问题,但是又引入了一个新的问题,每个Redis master的高可用如何解决?
那就是对每个master 节点都实现主从复制,从而实现 redis 高可用性
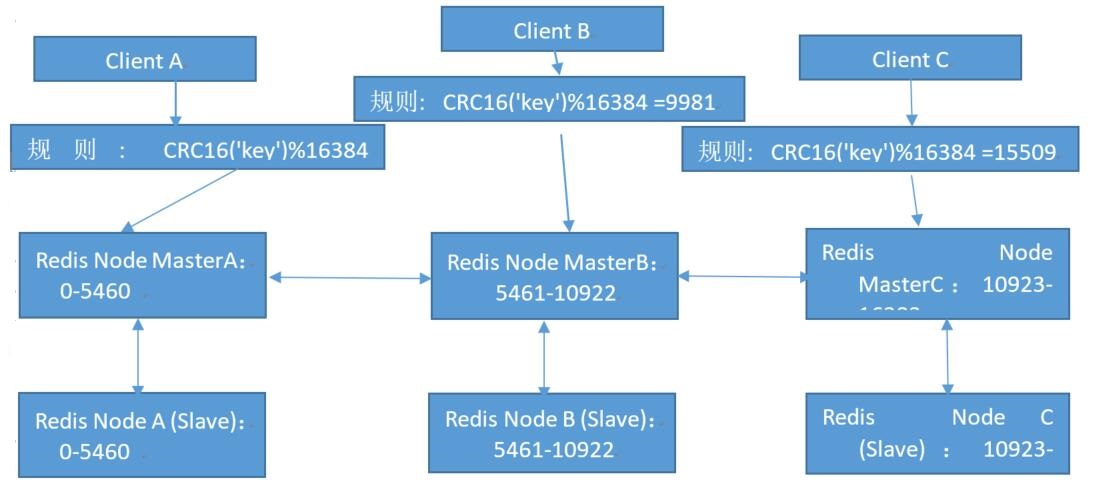
Redis Cluster 部署架构说明
7.2 创建redis cluster的前提
1.每个redis node节点采用相同的硬件配置、相同的密码、相同的redis版本。
2.每个节点必须开启的参数
-
cluster-enabled yes #必须开启集群状态,开启后redis进程会有cluster显示
-
cluster-config-file nodes-6380.conf #此文件有redis cluster集群自动创建和维护,不需要任何手动操作
3.所有redis服务器必须没有任何数据
4.先启动为单机redis且没有任何key value
7.3 部署redis cluster
在所有redis主机中
bash
[root@redis-masterx ~]# vim /etc/redis/redis.conf
masterauth "123456" #集群主从认证
requirepass "123456" #redis登陆密码 redis-cli 命令连接redis后要用"auth 密码"进行认证
cluster-enabled yes #开启cluster集群功能
cluster-config-file nodes-6379.conf #指定集群配置文件
cluster-node-timeout 15000 #节点加入集群的超时时间单位是ms
[root@redis-master1 ~]# systemctl restart redis.service
[root@redis-master1 ~]# redis-cli
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> info
# Cluster
cluster_enabled:17.4 redis-cli --cluster 参数说明
bash
[root@redis-master1 ~]# redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #指定master的副本数
check <host:port> or <host> <port> #检测集群信息
info <host:port> or <host> <port> #查看集群信息
fix <host:port> or <host> <port> #修复集群
reshard <host:port> or <host> <port> #在线热迁移集群指定主机的slots数据
rebalance <host:port> or <host> <port> #平衡各集群主机的slot数量
add-node new_host:new_port existing_host:existing_port #添加主机
del-node host:port node_id #删除主机
import host:port #导入外部redis服务器的数据到当前集群
-7.5. 创建redis-cluster
bash
[root@redis-master1 ~]# redis-cli --cluster create -a 123456 \
> 172.25.254.10:6379 172.25.254.20:6379 172.25.254.30:6379 \
> 172.25.254.110:6379 172.25.254.120:6379 172.25.254.130:6379 \
> --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460 #哈希槽分配
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.25.254.120:6379 to 172.25.254.10:6379 #主从分配情况
Adding replica 172.25.254.130:6379 to 172.25.254.20:6379
Adding replica 172.25.254.110:6379 to 172.25.254.30:6379
M: 5ab2e93f4f0783983676f7bd118efaacfb202bd1 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
M: ba504e78f14df5944280f9035543277a0cf5976b 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
M: 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
S: c20c9b5465b2e64868161c0e285d55bc81358ba4 172.25.254.110:6379
replicates 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
S: d458f34fa900d83212c021dc1e65396e490b5495 172.25.254.120:6379
replicates 5ab2e93f4f0783983676f7bd118efaacfb202bd1
S: 83d7a82fe896cf9f4d8212cb533058659bba16ce 172.25.254.130:6379
replicates ba504e78f14df5944280f9035543277a0cf5976b
Can I set the above configuration? (type 'yes' to accept): yes
>>> Performing Cluster Check (using node 172.25.254.10:6379)
M: 5ab2e93f4f0783983676f7bd118efaacfb202bd1 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: c20c9b5465b2e64868161c0e285d55bc81358ba4 172.25.254.110:6379
slots: (0 slots) slave
replicates 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
M: ba504e78f14df5944280f9035543277a0cf5976b 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 83d7a82fe896cf9f4d8212cb533058659bba16ce 172.25.254.130:6379
slots: (0 slots) slave
replicates ba504e78f14df5944280f9035543277a0cf5976b
M: 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: d458f34fa900d83212c021dc1e65396e490b5495 172.25.254.120:6379
slots: (0 slots) slave
replicates 5ab2e93f4f0783983676f7bd118efaacfb202bd1
[OK] All nodes agree about slots configuration.
>>> Check for open slots... #检查打开的哈希槽位
>>> Check slots coverage... #检查槽位覆盖范围
[OK] All 16384 slots covered. #所有槽位分配完成
#配置文件位置
[root@redis-master1 ~]# ll /var/lib/redis/nodes-6379.conf检测redis集群状态
bash
[root@redis-master1 ~]# redis-cli -a 123456 --cluster info 172.25.254.10:6379 #查看集群状态
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
172.25.254.10:6379 (5ab2e93f...) -> 0 keys | 5461 slots | 1 slaves.
172.25.254.20:6379 (ba504e78...) -> 0 keys | 5462 slots | 1 slaves.
172.25.254.30:6379 (1fcaeb1d...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
[root@redis-master1 ~]# redis-cli -a 123456 cluster info
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:821
cluster_stats_messages_pong_sent:801
cluster_stats_messages_sent:1622
cluster_stats_messages_ping_received:796
cluster_stats_messages_pong_received:821
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:1622
[root@redis-master1 ~]# redis-cli -a 123456 --cluster check 172.25.254.10:6379 #检测集群
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
172.25.254.10:6379 (5ab2e93f...) -> 0 keys | 5461 slots | 1 slaves.
172.25.254.20:6379 (ba504e78...) -> 0 keys | 5462 slots | 1 slaves.
172.25.254.30:6379 (1fcaeb1d...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 172.25.254.10:6379)
M: 5ab2e93f4f0783983676f7bd118efaacfb202bd1 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: c20c9b5465b2e64868161c0e285d55bc81358ba4 172.25.254.110:6379
slots: (0 slots) slave
replicates 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
M: ba504e78f14df5944280f9035543277a0cf5976b 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 83d7a82fe896cf9f4d8212cb533058659bba16ce 172.25.254.130:6379
slots: (0 slots) slave
replicates ba504e78f14df5944280f9035543277a0cf5976b
M: 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: d458f34fa900d83212c021dc1e65396e490b5495 172.25.254.120:6379
slots: (0 slots) slave
replicates 5ab2e93f4f0783983676f7bd118efaacfb202bd1
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.写入数据
bash
[root@redis-master1 ~]# redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> set key1 value1 #被分配到20的hash槽位上
(error) MOVED 9189 172.25.254.20:6379
[root@redis-master2 ~]# redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> set key1 value1
OK7.6 集群扩容
bash
#添加master
[root@redis-master1 ~]# redis-cli -a 123456 --cluster add-node 172.25.254.40:6379 172.25.254.10:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 172.25.254.40:6379 to cluster 172.25.254.10:6379
>>> Performing Cluster Check (using node 172.25.254.10:6379)
M: 5ab2e93f4f0783983676f7bd118efaacfb202bd1 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: c20c9b5465b2e64868161c0e285d55bc81358ba4 172.25.254.110:6379
slots: (0 slots) slave
replicates 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
M: ba504e78f14df5944280f9035543277a0cf5976b 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 83d7a82fe896cf9f4d8212cb533058659bba16ce 172.25.254.130:6379
slots: (0 slots) slave
replicates ba504e78f14df5944280f9035543277a0cf5976b
M: 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: d458f34fa900d83212c021dc1e65396e490b5495 172.25.254.120:6379
slots: (0 slots) slave
replicates 5ab2e93f4f0783983676f7bd118efaacfb202bd1
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Getting functions from cluster
>>> Failed retrieving Functions from the cluster, skip this step as Redis version do not support function command (error = 'ERR unknown command `FUNCTION`, with args beginning with: `DUMP`, ')
>>> Send CLUSTER MEET to node 172.25.254.40:6379 to make it join the cluster.
[OK] New node added correctly.
[root@redis-master1 ~]# redis-cli -a 123456 --cluster info 172.25.254.10:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
172.25.254.10:6379 (5ab2e93f...) -> 0 keys | 5461 slots | 1 slaves.
172.25.254.40:6379 (009571cb...) -> 0 keys | 0 slots | 0 slaves.
172.25.254.20:6379 (ba504e78...) -> 1 keys | 5462 slots | 1 slaves.
172.25.254.30:6379 (1fcaeb1d...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 1 keys in 4 masters.
0.00 keys per slot on average.
#分配槽位
[root@redis-master1 ~]# redis-cli -a 123456 --cluster reshard 172.25.254.10:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 172.25.254.10:6379)
M: 5ab2e93f4f0783983676f7bd118efaacfb202bd1 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: c20c9b5465b2e64868161c0e285d55bc81358ba4 172.25.254.110:6379
slots: (0 slots) slave
replicates 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
M: 009571cb206a89afa6658b60b2d403136056ac09 172.25.254.40:6379
slots: (0 slots) master
M: ba504e78f14df5944280f9035543277a0cf5976b 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 83d7a82fe896cf9f4d8212cb533058659bba16ce 172.25.254.130:6379
slots: (0 slots) slave
replicates ba504e78f14df5944280f9035543277a0cf5976b
M: 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: d458f34fa900d83212c021dc1e65396e490b5495 172.25.254.120:6379
slots: (0 slots) slave
replicates 5ab2e93f4f0783983676f7bd118efaacfb202bd1
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? 009571cb206a89afa6658b60b2d403136056ac09
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all
#添加salve
[root@redis-master1 ~]# redis-cli -a 123456 --cluster add-node 172.25.254.140:6379 172.25.254.10:6379 --cluster-slave --cluster-master-id 009571cb206a89afa6658b60b2d403136056ac09
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 172.25.254.140:6379 to cluster 172.25.254.10:6379
>>> Performing Cluster Check (using node 172.25.254.10:6379)
M: 5ab2e93f4f0783983676f7bd118efaacfb202bd1 172.25.254.10:6379
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: c20c9b5465b2e64868161c0e285d55bc81358ba4 172.25.254.110:6379
slots: (0 slots) slave
replicates 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
M: 009571cb206a89afa6658b60b2d403136056ac09 172.25.254.40:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
M: ba504e78f14df5944280f9035543277a0cf5976b 172.25.254.20:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
S: 83d7a82fe896cf9f4d8212cb533058659bba16ce 172.25.254.130:6379
slots: (0 slots) slave
replicates ba504e78f14df5944280f9035543277a0cf5976b
M: 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7 172.25.254.30:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
S: d458f34fa900d83212c021dc1e65396e490b5495 172.25.254.120:6379
slots: (0 slots) slave
replicates 5ab2e93f4f0783983676f7bd118efaacfb202bd1
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 172.25.254.140:6379 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 172.25.254.40:6379.
[OK] New node added correctly.7.7 clsuter集群维护
添加节点的时候是先添加node节点到集群,然后分配槽位,删除节点的操作与添加节点的操作正好相反,是先将被删除的Redis node上的槽位迁移到集群中的其他Redis node节点上,然后再将其删除,如果一个Redis node节点上的槽位没有被完全迁移,删除该node的时候会提示有数据且无法删除。
bash
#移除要下线主机的哈希槽位
[root@redis-master2 ~]# redis-cli -a 123456 --cluster reshard 172.25.254.20:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 172.25.254.20:6379)
M: ba504e78f14df5944280f9035543277a0cf5976b 172.25.254.20:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
M: 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7 172.25.254.30:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: 009571cb206a89afa6658b60b2d403136056ac09 172.25.254.40:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
1 additional replica(s)
S: c20c9b5465b2e64868161c0e285d55bc81358ba4 172.25.254.110:6379
slots: (0 slots) slave
replicates 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
S: d458f34fa900d83212c021dc1e65396e490b5495 172.25.254.120:6379
slots: (0 slots) slave
replicates 5ab2e93f4f0783983676f7bd118efaacfb202bd1
M: 5ab2e93f4f0783983676f7bd118efaacfb202bd1 172.25.254.10:6379
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: 83d7a82fe896cf9f4d8212cb533058659bba16ce 172.25.254.130:6379
slots: (0 slots) slave
replicates ba504e78f14df5944280f9035543277a0cf5976b
S: 86a4a8fb08e70e41b5a30f829deb983d23854ea7 172.25.254.140:6379
slots: (0 slots) slave
replicates 009571cb206a89afa6658b60b2d403136056ac09
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? 1fcaeb1dd936b46f4ea1efe4330c54195e66acf7
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 5ab2e93f4f0783983676f7bd118efaacfb202bd1
Source node #2: done
#删除master
[root@redis-master2 ~]# redis-cli -a 123456 --cluster del-node 172.25.254.120:6379 d458f34fa900d83212c021dc1e65396e490b5495
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node d458f34fa900d83212c021dc1e65396e490b5495 from cluster 172.25.254.120:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
[root@redis-master2 ~]# redis-cli -a 123456 --cluster del-node 172.25.254.10:6379 5ab2e93f4f0783983676f7bd118efaacfb202bd1
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node 5ab2e93f4f0783983676f7bd118efaacfb202bd1 from cluster 172.25.254.10:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.cluster部署及管理:
bash
#先将rd2/3移除,且rd1做以下动作:
# ==========================================
# 🟢 模板机 (rd1) 克隆前清理与重置操作
# 目标:确保克隆出的新机器 (rd2-rd7) 拥有独立的身份和干净的环境
# ==========================================
# 1. 停止 Redis 系统服务
# 作用:防止在清理文件时数据写入冲突,确保服务完全停止。
[root@rd1 ~]# systemctl stop redis
# 2. 强制杀死所有 Redis 进程
# 作用:双重保险。如果 systemctl 没停干净,这条命令会强制结束任何残留的 redis-server 进程。
[root@rd1 ~]# pkill -9 redis-server
# 3. 删除集群节点配置文件
# 作用:nodes-6379.conf 记录了集群拓扑和 Node ID。必须删除,否则新机器会沿用旧的 Node ID,导致集群冲突。
[root@rd1 ~]# rm -f /var/lib/redis/6379/nodes-6379.conf
# 4. 删除 RDB 快照文件
# 作用:清空持久化的数据快照,让新机器从空数据开始(避免测试数据污染)。
[root@rd1 ~]# rm -f /var/lib/redis/6379/dump.rdb
# 5. 删除 AOF 日志文件
# 作用:清空追加写日志,确保没有旧的事务记录。
[root@rd1 ~]# rm -f /var/lib/redis/6379/appendonly.aof
# 6. 删除 PID 文件
# 作用:清理进程号文件,防止新启动的 Redis 误认为旧进程还在运行而启动失败。
[root@rd1 ~]# rm -f /var/run/redis_6379.pid
# ---------------------------------------------------------
# ⚠️ 以下步骤是 Linux 虚拟机克隆的核心关键,不可跳过!
# ---------------------------------------------------------
# 7. 清空 Machine ID (第一步)
# 作用:/etc/machine-id 是系统的唯一身份证。克隆前必须清空,这样新机器首次启动时会自动生成新的唯一 ID。
# 如果不做,多台机器 ID 相同会导致 systemd 日志混乱、DHCP 获取 IP 失败等严重问题。
[root@rd1 ~]# > /etc/machine-id
# 8. 删除 D-Bus 链接的 Machine ID
# 作用:移除旧的软链接,为重新链接做准备。
[root@rd1 ~]# rm -f /var/lib/dbus/machine-id
# 9. 重建 D-Bus 软链接
# 作用:将 /var/lib/dbus/machine-id 重新指向 /etc/machine-id。
# 这样当新机器启动时,systemd 会检测到 /etc/machine-id 为空,从而自动生成新的 ID 并同步到这里。
[root@rd1 ~]# ln -s /etc/machine-id /var/lib/dbus/machine-id
# 10. 删除 SSH 主机密钥
# 作用:SSH Host Key 是服务器身份的指纹。如果不删除,所有克隆机的指纹都一样。
# 当你连接新机器时,SSH 客户端会报错 "WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED"。
# 删除后,新机器首次启动 sshd 服务时会自动生成全新的密钥对。
[root@rd1 ~]# rm -f /etc/ssh/ssh_host_*
# 11. 清理历史命令记录
# 作用:清空当前会话的历史记录 (.bash_history),避免克隆出来的机器里全是 rd1 的操作记录,保持环境整洁。
[root@rd1 ~]# history -c && > ~/.bash_history
# 12. 立即关机
# 作用:【最关键一步】必须在关机状态下进行克隆!
# 如果在开机状态下克隆,内存中的数据状态会被复制,可能导致文件系统损坏或网络状态异常。
# 执行此命令后,虚拟机将关闭,此时请去 VMware/VirtualBox 界面进行"克隆"操作。
[root@rd1 ~]# shutdown -h now
#现在将rd1关机后,进行克隆出rd2/3/4/5/6,再更改它们的IP为172.25.254.10/20/30/40/50/60即可;
[root@rd1 ~]# vmset.sh eth0 172.25.254.10 rd1
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:21:cf:ef brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.10/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe21:cfef/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd1
[root@rd2 ~]# vmset.sh eth0 172.25.254.20 rd2
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:75:4d:0e brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.20/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe75:4d0e/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd2
[root@rd3 ~]# vmset.sh eth0 172.25.254.30 rd3
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkMana ger/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group defaul t qlen 1000
link/ether 00:0c:29:62:4a:1e brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.30/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe62:4a1e/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd3
[root@rd4 ~]# vmset.sh eth0 172.25.254.40 rd4
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/6)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:1f:9a:35 brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.40/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe1f:9a35/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd4
[root@rd5 ~]# vmset.sh eth0 172.25.254.50 rd5
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:df:f2:e8 brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.50/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fedf:f2e8/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd5
[root@rd6 ~]# vmset.sh eth0 172.25.254.60 rd6
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:c8:f1:04 brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.60/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fec8:f104/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd6
#再克隆一台172.25.254.70的主机用于后续做集群扩容配置;
[root@rd7 ~]# vmset.sh eth0 172.25.254.70 rd7
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:45:b0:1e brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 172.25.254.70/24 brd 172.25.254.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe45:b01e/64 scope link tentative noprefixroute
valid_lft forever preferred_lft forever
rd7
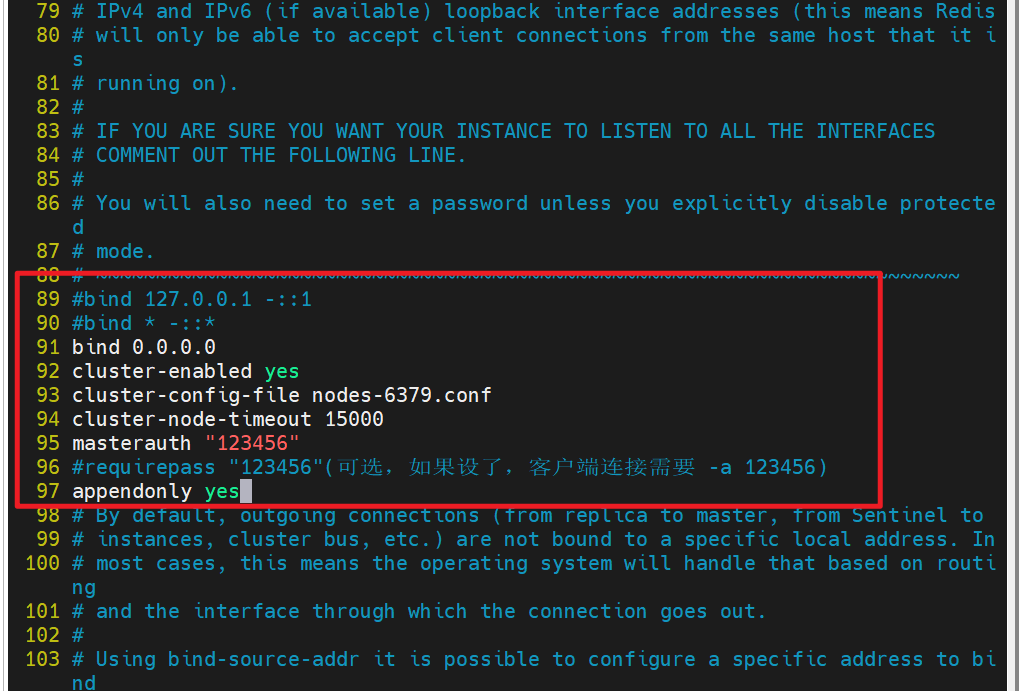
bash
#克隆后,执行检测脚本来保证环境的干净;
[root@rd1 ~]# vim redis_cluster_init.sh
#!/bin/bash
# ==========================================
# Redis Cluster 节点初始化与清理脚本
# 用途:克隆后批量清理旧数据、重置 Node ID、重启服务
# 适用:CentOS/RHEL/Ubuntu (源码编译或 yum 安装)
# ==========================================
echo "🚀 [开始] Redis 节点初始化清理..."
# 1. 停止 Redis 进程
echo "⏹️ 正在停止 Redis 进程..."
systemctl stop redis 2>/dev/null
systemctl stop redis-server 2>/dev/null
pkill -9 redis-server
sleep 2
# 2. 自动探测配置文件路径
# 优先检查常见路径,如果没有,尝试查找
CONF_FILE="/etc/redis/6379.conf"
if [ ! -f "$CONF_FILE" ]; then
CONF_FILE="/etc/redis.conf"
fi
if [ ! -f "$CONF_FILE" ]; then
# 尝试查找第一个 redis.conf
FOUND_CONF=$(find /etc -name "redis*.conf" 2>/dev/null | head -n 1)
if [ -n "$FOUND_CONF" ]; then
CONF_FILE=$FOUND_CONF
else
echo "❌ [错误] 未找到 Redis 配置文件!请手动检查。"
exit 1
fi
fi
echo "✅ 找到配置文件: $CONF_FILE"
# 3. 从配置文件中提取关键路径
# 提取 dir (数据目录)
DATA_DIR=$(grep "^dir " $CONF_FILE | awk '{print $2}' | sed 's/"//g')
if [ -z "$DATA_DIR" ]; then
DATA_DIR="/var/lib/redis" # 默认值
fi
# 提取 cluster-config-file (集群文件名)
CLUSTER_CONF=$(grep "^cluster-config-file " $CONF_FILE | awk '{print $2}')
if [ -z "$CLUSTER_CONF" ]; then
CLUSTER_CONF="nodes-6379.conf" # 默认值
fi
# 提取 pidfile
PID_FILE=$(grep "^pidfile " $CONF_FILE | awk '{print $2}' | sed 's/"//g')
if [ -z "$PID_FILE" ]; then
PID_FILE="/var/run/redis_6379.pid" # 默认值
fi
echo "📂 数据目录: $DATA_DIR"
echo "📄 集群文件: $CLUSTER_CONF"
echo "🔒 PID 文件: $PID_FILE"
# 4. 执行清理操作
echo "🧹 正在清理旧数据..."
# 构造完整路径并删除
TARGET_CLUSTER_FILE="$DATA_DIR/$CLUSTER_CONF"
# 处理相对路径情况 (如果 dir 是相对路径,通常相对于 conf 所在目录,但 redis 通常会转为绝对路径,这里做个保险)
if [[ "$DATA_DIR" != /* ]]; then
CONF_DIR=$(dirname $CONF_FILE)
TARGET_CLUSTER_FILE="$CONF_DIR/$DATA_DIR/$CLUSTER_CONF"
fi
# 删除文件列表
FILES_TO_DELETE=(
"$TARGET_CLUSTER_FILE"
"$DATA_DIR/dump.rdb"
"$DATA_DIR/appendonly.aof"
"$PID_FILE"
"/var/run/redis_6379.pid"
"/var/run/redis.pid"
)
for file in "${FILES_TO_DELETE[@]}"; do
if [ -f "$file" ]; then
rm -f "$file"
echo " ✅ 已删除: $file"
fi
done
# 额外保险:全局搜索并删除 nodes-*.conf (防止配置路径不一致)
find /var/lib/redis -name "nodes-*.conf" -delete 2>/dev/null
find /usr/local/var/db/redis -name "nodes-*.conf" -delete 2>/dev/null
# 5. 启动 Redis
echo "▶️ 正在启动 Redis..."
# 尝试 systemctl
if command -v systemctl &> /dev/null; then
systemctl start redis 2>/dev/null && echo " ✅ 通过 systemctl 启动 redis" && STARTED=1
if [ $? -ne 0 ]; then
systemctl start redis-server 2>/dev/null && echo " ✅ 通过 systemctl 启动 redis-server" && STARTED=1
fi
fi
# 如果 systemctl 失败或未找到,尝试直接后台启动
if [ "${STARTED:-0}" -eq 0 ]; then
echo " ⚠️ systemctl 未成功,尝试直接启动..."
# 确保以 daemon 方式启动,使用找到的配置文件
nohup redis-server $CONF_FILE --daemonize yes > /dev/null 2>&1
sleep 2
if pgrep -x "redis-server" > /dev/null; then
echo " ✅ 直接启动成功"
else
echo " ❌ 启动失败!请检查日志。"
exit 1
fi
fi
# 6. 最终验证
echo "🔍 验证状态..."
sleep 2
if pgrep -x "redis-server" > /dev/null; then
PORT=$(grep "^port " $CONF_FILE | awk '{print $2}')
PORT=${PORT:-6379}
if redis-cli -p $PORT ping | grep -q "PONG"; then
echo "✅ [成功] Redis 已启动并响应 PONG (端口: $PORT)"
echo "✅ [成功] 节点已清空,准备加入集群!"
# 显示当前 IP
MY_IP=$(hostname -I | awk '{print $1}')
echo "💡 本机 IP: $MY_IP"
else
echo "❌ [警告] 进程存在但无法 Ping 通,请检查防火墙或绑定地址。"
fi
else
echo "❌ [失败] Redis 进程未运行!"
exit 1
fi
echo "🏁 [结束] 初始化完成。"
#脚本作用:
#1.停止服务(无论是否有 systemd 服务)。
#2.彻底清理旧数据、集群配置文件、PID 文件。
#3.自动查找正确的 Redis 配置路径和数据目录(避免路径写死导致失败)。
#4.重启服务(优先尝试 systemctl,失败则尝试后台启动)。
#5.验证状态(检查进程和端口)。
[root@rd1 ~]# chmod +x redis_cluster_init.sh
[root@rd1 ~]# for ip in 10 20 30 40 50 60 70; do #本地运行这个循环检验环境;
echo "👉 正在处理 172.25.254.$ip ..."
scp redis_cluster_init.sh root@172.25.254.$ip:/root/
ssh root@172.25.254.$ip "bash /root/redis_cluster_init.sh"
echo "--------------------------"
done
#每个主机的执行结果相同,只是对应IP不同;
👉 正在处理 172.25.254.10 ...
Warning: Permanently added '172.25.254.10' (ED25519) to the list of known hosts.
redis_cluster_init.sh 100% 4146 3.7MB/s 00:00
🚀 [开始] Redis 节点初始化清理...
⏹️ 正在停止 Redis 进程...
✅ 找到配置文件: /etc/redis/6379.conf
📂 数据目录: /var/lib/redis/6379
📄 集群文件: nodes-6379.conf
🔒 PID 文件: /var/run/redis_6379.pid
🧹 正在清理旧数据...
✅ 已删除: /var/lib/redis/6379/nodes-6379.conf
✅ 已删除: /var/lib/redis/6379/dump.rdb
▶️ 正在启动 Redis...
⚠️ systemctl 未成功,尝试直接启动...
✅ 直接启动成功
🔍 验证状态...
✅ [成功] Redis 已启动并响应 PONG (端口: 6379)
✅ [成功] 节点已清空,准备加入集群!
💡 本机 IP: 172.25.254.10
🏁 [结束] 初始化完成。
#启动集群
# ==========================================
# 1. 发起集群创建命令
# ==========================================
# 命令解释:
# --cluster create : 告诉 redis-cli 我们要创建一个新集群
# 后面跟着6个 IP:端口 : 分别是 rd1(10) 到 rd6(60)
# --cluster-replicas 1 : 指定每个主节点配备 1 个从节点 (3主 + 3从 = 6台机器)
[root@rd1 ~]# redis-cli --cluster create \
172.25.254.10:6379 172.25.254.20:6379 172.25.254.30:6379 \
172.25.254.40:6379 172.25.254.50:6379 172.25.254.60:6379 \
--cluster-replicas 1
# ==========================================
# 2. 系统自动规划主从关系 (哈希槽分配)
# ==========================================
>>> Performing hash slots allocation on 6 nodes...
# Redis 共有 16384 个槽位,这里被平均分给了前3台机器作为 Master
Master[0] -> Slots 0 - 5460 # 第1台 (10号) 负责 0-5460 号槽
Master[1] -> Slots 5461 - 10922 # 第2台 (20号) 负责 5461-10922 号槽
Master[2] -> Slots 10923 - 16383 # 第3台 (30号) 负责 10923-16383 号槽
# 接下来自动分配从节点 (Replica)
# 注意:这里的分配是随机的,不一定按顺序对应,只要保证一主一从即可
Adding replica 172.25.254.50:6379 to 172.25.254.10:6379 # 50号 成为 10号 的从节点
Adding replica 172.25.254.60:6379 to 172.25.254.20:6379 # 60号 成为 20号 的从节点
Adding replica 172.25.254.40:6379 to 172.25.254.30:6379 # 40号 成为 30号 的从节点
# ==========================================
# 3. 打印最终拓扑方案 (等待确认)
# ==========================================
# M = Master (主节点), S = Slave/Replica (从节点)
# 每一行显示了节点的 ID、IP、以及它负责的槽位或跟随的主节点ID
M: bbfd4c35... 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
# 👆 10号是主节点,持有5461个槽
M: 8bcec549... 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
# 👆 20号是主节点
M: ce44f03f... 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
# 👆 30号是主节点
S: ad506c3a... 172.25.254.40:6379
replicates ce44f03f... (对应上面的30号节点ID)
# 👆 40号是从节点,跟随30号
S: c91e4490... 172.25.254.50:6379
replicates bbfd4c35... (对应上面的10号节点ID)
# 👆 50号是从节点,跟随10号
S: 7e2a7554... 172.25.254.60:6379
replicates 8bcec549... (对应上面的20号节点ID)
# 👆 60号是从节点,跟随20号
# 系统询问:是否接受这个配置?
Can I set the above configuration? (type 'yes' to accept): yes
# 👉 你输入了 'yes',开始执行
# ==========================================
# 4. 执行配置与节点加入
# ==========================================
>>> Nodes configuration updated
# 配置文件已写入各节点的 nodes-6379.conf
>>> Assign a different config epoch to each node
# 为每个节点分配不同的配置纪元 (用于解决集群元数据冲突的版本号)
>>> Sending CLUSTER MEET messages to join the cluster
# 发送握手消息,让所有节点互相认识 (Gossip 协议)
Waiting for the cluster to join
.
# 👉 等待几秒钟,直到所有节点状态变为 OK
# ==========================================
# 5. 最终集群健康检查 (Cluster Check)
# ==========================================
>>> Performing Cluster Check (using node 172.25.254.10:6379)
# 以 10号节点为入口,检查整个集群状态
# 以下是检查报告,格式为:角色 ID IP 信息
M: bbfd4c35... 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s) # ✅ 确认有1个从节点
S: c91e4490... 172.25.254.50:6379
slots: (0 slots) slave # 从节点不持有槽
replicates bbfd4c35... # ✅ 确认跟随正确的主节点
# ... (中间省略了其他节点的检查报告,结构同上) ...
# ==========================================
# 6. 最终结论
# ==========================================
[OK] All nodes agree about slots configuration.
# ✅ 所有节点对槽位的分配达成一致 (没有分歧)
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# ✅ 最关键的一句:0 到 16383 所有槽位都已覆盖,没有空缺!
# 这意味着集群已经完全可用,可以开始存数据了。
#检测集群信息:
#作用:快速查看集群中所有主节点的概览信息(键数量、槽位分配、从节点数)。
[root@rd1 ~]# redis-cli --cluster info 172.25.254.10:6379
# 每一行代表一个主节点 (Master) 的状态:
# 格式:IP:端口 (NodeID) -> 键数量 | 槽位数量 | 从节点数量
172.25.254.10:6379 (bbfd4c35...) -> 0 keys | 5461 slots | 1 slaves.
# 👉 10号是主节点,当前存了0个键,负责5461个槽,有1个从节点
172.25.254.30:6379 (ce44f03f...) -> 0 keys | 5461 slots | 1 slaves.
# 👉 30号是主节点,0键,5461槽,1个从节点
172.25.254.20:6379 (8bcec549...) -> 0 keys | 5462 slots | 1 slaves.
# 👉 20号是主节点,0键,5462槽(多1个是因为16384不能被3整除),1个从节点
[OK] 0 keys in 3 masters.
# ✅ 总结:3个主节点共存储0个键(刚初始化,正常)
0.00 keys per slot on average.
# ✅ 平均每个槽位0个键(因为总键数为0)
#作用:查看当前连接节点(这里是 rd1/10号)所知道的整个集群的全局统计信息。
[root@rd1 ~]# redis-cli cluster info
cluster_state:ok
# ✅ 集群整体状态正常!如果是 fail,说明集群不可用
cluster_slots_assigned:16384
# ✅ 总共16384个槽位已全部分配完毕
cluster_slots_ok:16384
# ✅ 所有槽位都处于"可用"状态(没有失败或迁移中的槽)
cluster_slots_pfail:0
# ✅ 没有"疑似失败"的槽(pfail = probably fail)
cluster_slots_fail:0
# ✅ 没有"确认失败"的槽
cluster_known_nodes:6
# ✅ 当前节点知道集群中有6个节点(3主+3从)
cluster_size:3
# ✅ 集群大小为3 ------ 指的是**主节点的数量**
cluster_current_epoch:6
# 🔄 集群配置版本号。每次拓扑变更(如主从切换)都会递增
cluster_my_epoch:1
# 🔄 当前节点自己的配置版本号
# 以下是通信统计数据(用于监控网络心跳)
cluster_stats_messages_ping_sent:1142
# 发送了多少次 PING 心跳包
cluster_stats_messages_pong_sent:1254
# 发送了多少次 PONG 响应包
cluster_stats_messages_sent:2396
# 总发送消息数 = ping + pong + 其他
cluster_stats_messages_ping_received:1249
# 收到多少次 PING
cluster_stats_messages_pong_received:1142
# 收到多少次 PONG
cluster_stats_messages_meet_received:5
# 收到多少次 CLUSTER MEET 握手请求(初始加入时产生)
cluster_stats_messages_received:2396
# 总接收消息数
total_cluster_links_buffer_limit_exceeded:0
# ✅ 没有限制超标的链接缓冲区(如果出现非零值,可能表示网络压力大)
#作用:对集群进行深度健康检查,包括主从关系、槽位覆盖、一致性等。
[root@rd1 ~]# redis-cli --cluster check 172.25.254.10:6379
# 再次列出主节点概要(同第一个命令)
172.25.254.10:6379 (bbfd4c35...) -> 0 keys | 5461 slots | 1 slaves.
172.25.254.30:6379 (ce44f03f...) -> 0 keys | 5461 slots | 1 slaves.
172.25.254.20:6379 (8bcec549...) -> 0 keys | 5462 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
# 开始详细拓扑检查
>>> Performing Cluster Check (using node 172.25.254.10:6379)
# M = Master, S = Slave
M: bbfd4c35... 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s) # ✅ 有1个从节点
S: c91e4490... 172.25.254.50:6379
slots: (0 slots) slave
replicates bbfd4c35... # ✅ 50号是从节点,跟随10号
M: ce44f03f... 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: ad506c3a... 172.25.254.40:6379
slots: (0 slots) slave
replicates ce44f03f... # ✅ 40号是从节点,跟随30号
M: 8bcec549... 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 7e2a7554... 172.25.254.60:6379
slots: (0 slots) slave
replicates 8bcec549... # ✅ 60号是从节点,跟随20号
# 最终一致性检查
[OK] All nodes agree about slots configuration.
# ✅ 所有节点对槽位分配达成一致(无分歧)
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# ✅ 最关键结论:所有槽位都被正确分配且可用!
#集群扩容
[root@rd1 ~]# redis-cli --cluster add-node 172.25.254.70:6379 172.25.254.10:6379
# 👉 把 70号节点 加入集群,通过 10号节点(已在集群中)作为入口进行引导
[root@rd1 ~]# redis-cli --cluster add-node 172.25.254.70:6379 172.25.254.10:6379
# 👉 将新节点 70 加入集群,通过已有节点 10 作为入口引导
>>> Adding node 172.25.254.70:6379 to cluster 172.25.254.10:6379
# 📌 开始执行添加操作
>>> Performing Cluster Check (using node 172.25.254.10:6379)
# 🔍 添加前后自动检查当前集群健康状态(以10号节点为视角)
M: bbfd4c35990fa9ffe77686f6e27a0808a519352e 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
# 🟦 主节点10号:负责0~5460槽,有1个从节点(50号)
S: c91e4490151cf4f28f29b4ba9a8215b16c289e91 172.25.254.50:6379
slots: (0 slots) slave
replicates bbfd4c35990fa9ffe77686f6e27a0808a519352e
# 🟩 从节点50号:无槽位,复制10号主节点
M: ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
# 🟦 主节点30号:负责10923~16383槽,有1个从节点(40号)
M: 8bcec54910dea2c00d5d29f6871052497ddfdac2 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
# 🟦 主节点20号:负责5461~10922槽(多1个因整除余数),有1个从节点(60号)
S: 7e2a755400363a587ffd87b03473f5ee53fa6ae5 172.25.254.60:6379
slots: (0 slots) slave
replicates 8bcec54910dea2c00d5d29f6871052497ddfdac2
# 🟩 从节点60号:无槽位,复制20号主节点
S: ad506c3a38500f7cdccf527ae617bcf30c84e39a 172.25.254.40:6379
slots: (0 slots) slave
replicates ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0
# 🟩 从节点40号:无槽位,复制30号主节点
[OK] All nodes agree about slots configuration.
# ✅ 所有节点对槽位分配达成一致(无分歧)
>>> Check for open slots...
# 🔎 检查是否有未分配的"空槽"
>>> Check slots coverage...
# 🔎 检查是否所有槽都被覆盖
[OK] All 16384 slots covered.
# ✅ 最关键结论:全部16384个槽都已分配完毕,集群完整可用
>>> Getting functions from cluster
# 🧩 获取集群中定义的 Lua 函数(如有),用于同步到新节点
>>> Send FUNCTION LIST to 172.25.254.70:6379 to verify there is no functions in it
# 📤 向新节点70发送请求,确认它当前没有自定义函数(避免冲突)
>>> Send FUNCTION RESTORE to 172.25.254.70:6379
# 📥 如果集群中有函数,则恢复到新节点(本例为空,实际无内容)
>>> Send CLUSTER MEET to node 172.25.254.70:6379 to make it join the cluster.
# 💥 核心动作!发送 `CLUSTER MEET` 命令,让70号主动与其他节点建立Gossip连接
[OK] New node added correctly.
# ✅ 成功!新节点已正式加入集群拓扑
[root@rd1 ~]# redis-cli --cluster check 172.25.254.10:6379
# 👉 对集群进行深度健康检查,入口节点为 10 号
172.25.254.10:6379 (bbfd4c35...) -> 0 keys | 5461 slots | 1 slaves.
# 🟦 主节点10号:0键,负责5461个槽,有1个从节点
172.25.254.70:6379 (eca36b15...) -> 0 keys | 0 slots | 0 slaves.
# ⚠️ 新节点70号:0键、0槽、无从节点 → 目前是"空主节点",未分配任何职责!
172.25.254.30:6379 (ce44f03f...) -> 0 keys | 5461 slots | 1 slaves.
# 🟦 主节点30号:0键,5461槽,1个从节点
172.25.254.20:6379 (8bcec549...) -> 0 keys | 5462 slots | 1 slaves.
# 🟦 主节点20号:0键,5462槽(多1个因整除余数),1个从节点
[OK] 0 keys in 4 masters.
# ✅ 总结:现在集群中有 **4个主节点**(包括刚加入的70号),但都还没存数据
0.00 keys per slot on average.
# ✅ 平均每个槽位0个键(因为总键数=0)
>>> Performing Cluster Check (using node 172.25.254.10:6379)
# 🔍 开始详细拓扑检查(以10号节点为视角)
M: bbfd4c35990fa9ffe77686f6e27a0808a519352e 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
# 🟦 主节点10号:槽位0~5460,有1个从节点(50号)
S: c91e4490151cf4f28f29b4ba9a8215b16c289e91 172.25.254.50:6379
slots: (0 slots) slave
replicates bbfd4c35990fa9ffe77686f6e27a0808a519352e
# 🟩 从节点50号:无槽位,复制10号主节点
M: eca36b15690909d3c65b37c67ee511711a61d3f8 172.25.254.70:6379
slots: (0 slots) master
# ⚠️ 新节点70号:被识别为主节点,但**没有分配任何槽位** → "光杆司令"
M: ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
# 🟦 主节点30号:槽位10923~16383,有1个从节点(40号)
M: 8bcec54910dea2c00d5d29f6871052497ddfdac2 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
# 🟦 主节点20号:槽位5461~10922,有1个从节点(60号)
S: 7e2a755400363a587ffd87b03473f5ee53fa6ae5 172.25.254.60:6379
slots: (0 slots) slave
replicates 8bcec54910dea2c00d5d29f6871052497ddfdac2
# 🟩 从节点60号:无槽位,复制20号主节点
S: ad506c3a38500f7cdccf527ae617bcf30c84e39a 172.25.254.40:6379
slots: (0 slots) slave
replicates ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0
# 🟩 从节点40号:无槽位,复制30号主节点
[OK] All nodes agree about slots configuration.
# ✅ 所有节点对当前槽位分配达成一致(无冲突或分歧)
>>> Check for open slots...
# 🔎 检查是否有未被分配的"空闲槽位"
>>> Check slots coverage...
# 🔎 检查是否所有16384个槽都被覆盖
[OK] All 16384 slots covered.
# ✅ 最关键结论:虽然70号没槽,但其他3个主节点已覆盖全部16384槽 → 集群仍可正常工作!
#给新主机添加slave
[root@rd1 ~]# redis-cli -h 172.25.254.70 -p 6379 CLUSTER REPLICATE bbfd4c35990fa9ffe77686f6e27a0808a519352e
OK
# ✅ [rd1上执行] 成功:将70号节点设置为10号主节点的从节点,开始同步数据
[root@rd1 ~]# redis-cli --cluster check 172.25.254.10:6379
172.25.254.10:6379 (bbfd4c35...) -> 0 keys | 5461 slots | 2 slaves.
172.25.254.30:6379 (ce44f03f...) -> 0 keys | 5461 slots | 1 slaves.
172.25.254.20:6379 (8bcec549...) -> 0 keys | 5462 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 172.25.254.10:6379)
M: bbfd4c35990fa9ffe77686f6e27a0808a519352e 172.25.254.10:6379
slots:[0-5460] (5461 slots) master
2 additional replica(s)
S: c91e4490151cf4f28f29b4ba9a8215b16c289e91 172.25.254.50:6379
slots: (0 slots) slave
replicates bbfd4c35990fa9ffe77686f6e27a0808a519352e
S: eca36b15690909d3c65b37c67ee511711a61d3f8 172.25.254.70:6379
slots: (0 slots) slave
replicates bbfd4c35990fa9ffe77686f6e27a0808a519352e
M: ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 8bcec54910dea2c00d5d29f6871052497ddfdac2 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 7e2a755400363a587ffd87b03473f5ee53fa6ae5 172.25.254.60:6379
slots: (0 slots) slave
replicates 8bcec54910dea2c00d5d29f6871052497ddfdac2
S: ad506c3a38500f7cdccf527ae617bcf30c84e39a 172.25.254.40:6379
slots: (0 slots) slave
replicates ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered. # ✅ [rd1上执行] 成功:验证集群状态正常,所有槽位已覆盖,节点角色正确(含新增从节点)
bash
[root@rd1 ~]# redis-cli -h 172.25.254.70 -p 6379 CLUSTER FAILOVER #把 70 号提升为 master(故障转移)
OK
[root@rd1 ~]# redis-cli --cluster reshard 172.25.254.10:6379
>>> Performing Cluster Check (using node 172.25.254.10:6379)
S: bbfd4c35990fa9ffe77686f6e27a0808a519352e 172.25.254.10:6379
slots: (0 slots) slave
replicates eca36b15690909d3c65b37c67ee511711a61d3f8
S: c91e4490151cf4f28f29b4ba9a8215b16c289e91 172.25.254.50:6379
slots: (0 slots) slave
replicates eca36b15690909d3c65b37c67ee511711a61d3f8
M: eca36b15690909d3c65b37c67ee511711a61d3f8 172.25.254.70:6379
slots:[0-5460] (5461 slots) master
2 additional replica(s)
M: ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 8bcec54910dea2c00d5d29f6871052497ddfdac2 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 7e2a755400363a587ffd87b03473f5ee53fa6ae5 172.25.254.60:6379
slots: (0 slots) slave
replicates 8bcec54910dea2c00d5d29f6871052497ddfdac2
S: ad506c3a38500f7cdccf527ae617bcf30c84e39a 172.25.254.40:6379
slots: (0 slots) slave
replicates ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 5461
What is the receiving node ID? 8bcec54910dea2c00d5d29f6871052497ddfdac2
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: eca36b15690909d3c65b37c67ee511711a61d3f8
Source node #2: done
Ready to move 5461 slots.
Source nodes:
M: eca36b15690909d3c65b37c67ee511711a61d3f8 172.25.254.70:6379
slots:[0-5460] (5461 slots) master
2 additional replica(s)
Destination node:
M: 8bcec54910dea2c00d5d29f6871052497ddfdac2 172.25.254.20:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
Resharding plan:
Moving slot 0 from eca36b15690909d3c65b37c67ee511711a61d3f8
...
Do you want to proceed with the proposed reshard plan (yes/no)? yes
Moving slot 0 from 172.25.254.70:6379 to 172.25.254.20:6379:
...
[root@rd1 ~]# redis-cli --cluster del-node 172.25.254.10:6379 eca36b15690909d3c65b37c67ee511711a61d3f8
>>> Removing node eca36b15690909d3c65b37c67ee511711a61d3f8 from cluster 172.25.254.10:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
[root@rd1 ~]# redis-cli --cluster check 172.25.254.10:6379
172.25.254.30:6379 (ce44f03f...) -> 0 keys | 5461 slots | 1 slaves.
172.25.254.20:6379 (8bcec549...) -> 0 keys | 10923 slots | 3 slaves.
[OK] 0 keys in 2 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 172.25.254.10:6379)
S: bbfd4c35990fa9ffe77686f6e27a0808a519352e 172.25.254.10:6379
slots: (0 slots) slave
replicates 8bcec54910dea2c00d5d29f6871052497ddfdac2
S: c91e4490151cf4f28f29b4ba9a8215b16c289e91 172.25.254.50:6379
slots: (0 slots) slave
replicates 8bcec54910dea2c00d5d29f6871052497ddfdac2
M: ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0 172.25.254.30:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 8bcec54910dea2c00d5d29f6871052497ddfdac2 172.25.254.20:6379
slots:[0-10922] (10923 slots) master
3 additional replica(s)
S: 7e2a755400363a587ffd87b03473f5ee53fa6ae5 172.25.254.60:6379
slots: (0 slots) slave
replicates 8bcec54910dea2c00d5d29f6871052497ddfdac2
S: ad506c3a38500f7cdccf527ae617bcf30c84e39a 172.25.254.40:6379
slots: (0 slots) slave
replicates ce44f03f481b47a4f8386ed0abc46b1f1ba38ff0
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
bash
#简洁解释:
# ✅ 第一步:reshard 迁移槽位(关键!)------ 在 rd1 上执行
[root@rd1 ~]# redis-cli --cluster reshard 172.25.254.10:6379
→ 输入 5461 → 接收者 8bcec5... → 来源 eca36b... → done → yes
→ 系统自动移动 0~5460 槽位从 70→20
# ✅ 第二步:直接删除节点(无需再 replicate!因为 reshared 后它已是"空壳")------ 在 rd1 上执行
[root@rd1 ~]# redis-cli --cluster del-node 172.25.254.10:6379 eca36b15690909d3c65b37c67ee511711a61d3f8
→ 成功移除,集群广播遗忘消息
# ✅ 第三步:验证集群状态 ------ 在 rd1 上执行
[root@rd1 ~]# redis-cli --cluster check 172.25.254.10:6379
→ 显示 2 masters, 4 slaves, 16384 slots covered → 完美!7.8 总结
(1)Redis Cluster 出现的背景与解决的问题
背景:哨兵模式(Sentinel)解决了高可用问题(master 故障自动切换),但无法解决单机写入的性能瓶颈。
Cluster 解决的两大核心问题:
-
⭐⭐ 高可用性:通过主从复制 + 故障转移实现
-
⭐⭐⭐ 水平扩展:通过数据分片(Sharding)突破单机性能限制
🔴🔴🔴 难点理解 :为什么单机有瓶颈? 单台服务器的内存、CPU、网卡是有限的。就像一个收银台 处理所有顾客,排队会越来越长。Cluster 就是开多个收银台并行处理。
(2)Redis Cluster 的核心架构特点
| 特点 | 说明 |
|---|---|
| ⭐⭐⭐ 无中心化设计 | 没有中心节点,每个节点都保存集群完整状态,所有节点平等 |
| ⭐⭐⭐ Gossip 协议通信 | 节点间通过 PING-PONG 机制互联,互相交换状态信息 |
| ⭐⭐⭐ 哈希槽(Hash Slot)分片 | 共 16384 个槽位(0-16383),数据分散存储 |
| ⭐⭐ 主从复制架构 | 每个 master 至少有一个 slave,保证高可用 |
架构图示(对应您的图片):
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Master1 │◄───────►│ Master2 │◄───────►│ Master3 │
│ 0-5460 │ │5461-10922│ │10923-16383│
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Slave1 │ │ Slave2 │ │ Slave3 │
└─────────┘ └─────────┘ └─────────┘
虚线 = Gossip 协议通信(所有节点互相连接)🔴🔴 难点理解:什么是"无中心化"?
生活例子 :传统公司有个总经理(中心节点),所有决策都要找他。如果总经理请假,公司瘫痪。
Redis Cluster 像合伙人制度:每个合伙人(节点)都知道公司全部业务,可以独立做决策,合伙人之间互相通气(Gossip)。一个合伙人休假,其他人照常运转。
(3)哈希槽(Hash Slot)机制 ⭐⭐⭐⭐⭐
核心公式:
CRC16(key) % 16384 = 槽位号 (0-16383)槽位分配示例(3 主节点):
| 节点 | 槽位范围 | 槽位数量 |
|---|---|---|
| Master A | 0 - 5460 | 5461 个 |
| Master B | 5461 - 10922 | 5462 个 |
| Master C | 10923 - 16383 | 5461 个 |
数据写入流程(对应的图片):
Client A 写 key="name"
↓
CRC16("name") % 16384 = 2580 ← 计算槽位
↓
2580 在 0-5460 范围内 → 发给 Master A
↓
Master A 存储数据,并同步给 Slave A🔴🔴🔴🔴🔴 最大难点:为什么用 16384 个槽?为什么不是直接哈希到节点?
生活例子 :快递分拣系统
直接哈希到节点 = 每个快递直接写上门牌号(如"张三收")。问题是:如果快递员离职(节点下线),所有写着"找张三"的快递都送不出去,必须全部重新贴标签。
哈希槽机制 = 先把全国划分为 16384 个固定区域编码 (槽位),再告诉快递员:"你负责编码 0-5460 的区域"。如果快递员 A 离职,只需要把"0-5460 区域"分配给新来的快递员,快递单上的编码不用改!
好处:扩容/缩容时,只需要迁移槽位映射关系,不需要改动数据本身的 key!
(4)节点失效判定机制 ⭐⭐⭐
判定条件:超过半数的 master 节点都认为某节点下线(主观下线 → 客观下线)
流程:
1. 节点 A 发现节点 B 超时未响应 PING → 标记 B 为 **PFAIL**(疑似失败)
2. A 通过 Gossip 广播 B 可能失败的消息
3. 其他节点也反馈 B 的状态
4. 如果超过半数 master 都认为 B 失败 → 标记为 **FAIL**(确认失败)
5. 触发故障转移:B 的 slave 提升为 master🔴🔴🔴 难点理解:为什么要"超过半数"?
生活例子 :医院会诊判定病人死亡
一个医生(节点)说"病人不行了"不算数(可能是误判)。必须多个科室专家会诊(超过半数节点),一致确认后才能宣布死亡证明(客观下线),启动后续流程(故障转移)。
这防止了"脑裂":避免网络分区时,两边各自选出一个 master,导致数据混乱。
(5)集群部署前提条件 ⭐⭐⭐
-
硬件一致:所有节点相同配置、相同 Redis 版本
-
配置开启:
-
cluster-enabled yes------ 开启集群模式 -
cluster-config-file nodes-6379.conf------ 集群配置文件(自动生成) -
cluster-node-timeout 15000------ 超时时间(毫秒)
-
-
数据为空:创建集群前,所有节点不能有任何数据
-
密码统一 :
masterauth和requirepass设置相同
(6)集群管理核心命令 ⭐⭐⭐⭐
| 命令 | 作用 |
|---|---|
redis-cli --cluster create |
创建集群,自动分配槽位和主从 |
redis-cli --cluster add-node |
添加新节点(扩容) |
redis-cli --cluster del-node |
删除节点(缩容) |
redis-cli --cluster reshard |
🔴🔴🔴 重新分配槽位(数据迁移) |
redis-cli --cluster rebalance |
平衡各节点槽位数量 |
redis-cli --cluster check |
检查集群健康状态 |
(7)集群扩容完整流程 ⭐⭐⭐⭐⭐
扩容步骤(以添加 1 主 1 从为例):
第 1 步:添加新 master 节点
redis-cli --cluster add-node 新IP:6379 现有集群任一IP:6379
第 2 步:分配槽位(🔴🔴🔴 关键!新节点默认 0 槽位)
redis-cli --cluster reshard 现有集群任一IP:6379
→ 输入要移动的槽位数(如 4096)
→ 输入接收者节点 ID(新节点)
→ 输入来源节点 ID(all 表示从所有节点平均取)
第 3 步:添加 slave 节点
redis-cli --cluster add-node 新SlaveIP:6379 现有集群任一IP:6379 \
--cluster-slave --cluster-master-id 新Master的ID🔴🔴🔴🔴 难点理解:为什么扩容要"先加节点,再移槽位"?
生活例子 :公司开新分店
add-node = 先租下新店面,装修好,挂牌子(加入集群拓扑)
reshard = 把老店的部分客户(数据)分配到新店(槽位迁移)
add slave = 给新店配个副店长(从节点),店长不在时能顶上
如果跳过第 2 步:新店开门了但没客户(0 槽位),顾客(请求)还是都去老店,新店闲置浪费!
(8)集群缩容完整流程 ⭐⭐⭐⭐⭐
缩容步骤(与扩容相反):
第 1 步:迁移槽位(🔴🔴🔴 必须先做!否则删不掉)
redis-cli --cluster reshard 现有集群任一IP:6379
→ 输入要移动的数量(该节点全部槽位)
→ 输入接收者(其他 master)
→ 输入来源(要删除的节点 ID)
第 2 步:删除节点
redis-cli --cluster del-node 现有集群任一IP:6379 要删的节点ID🔴🔴🔴🔴🔴 最大难点:为什么不能直接删节点?
生活例子 :撤掉一个快递站点
直接关门(直接 del-node)= 该站点负责的区域(槽位)所有快递都送不到了,系统崩溃!
正确做法:
先转移区域(reshard):把该站点负责的片区分配给附近其他站点
确认空壳后撤站(del-node):该站点没有任何片区负责了,才能安全撤掉
Redis 会检查:如果节点还有槽位,拒绝删除,防止数据丢失!
(9)数据写入的特殊现象 ⭐⭐⭐
MOVED 重定向:
# 连接到节点 10
redis-cli -h 172.25.254.10 -p 6379
127.0.0.1:6379> set key1 value1
(error) MOVED 9189 172.25.254.20:6379 ← 报错!key1 的槽位 9189 在 20 号节点解决方案:
-
使用
-c参数启动集群模式客户端,自动重定向:redis-cli -c -h 172.25.254.10 -p 6379 -a 123456 127.0.0.1:6379> set key1 value1 -> Redirected to slot 9189 located at 172.25.254.20:6379 OK
🔴🔴 难点理解:为什么需要重定向?
生活例子 :银行跨行取款
你去 A 银行(节点 10)取钱,但你的账户开在 B 银行(节点 20)。
A 银行告诉你:"您的账户不在这儿,请去 B 银行办理"(MOVED 错误)。
智能客户端(
redis-cli -c)就像全能银行 APP:你输入取钱指令,APP 自动识别账户所在银行,帮你完成转账,你不用自己跑(手动切换连接)。
(10)克隆虚拟机部署集群的注意事项 ⭐⭐⭐⭐
必须清理的"身份标识"(防止克隆机冲突):
| 文件/配置 | 作用 | 不清理的后果 |
|---|---|---|
nodes-6379.conf |
集群节点 ID 和拓扑 | 所有克隆机有相同 Node ID,集群混乱 |
dump.rdb / appendonly.aof |
持久化数据 | 数据污染,启动失败 |
/etc/machine-id |
系统唯一标识 | systemd 日志混乱,网络服务异常 |
/etc/ssh/ssh_host_* |
SSH 主机密钥 | SSH 连接报警告"身份已更改" |
自动化清理脚本(文档中提供):
# 核心逻辑:停止服务 → 删除身份文件 → 重启服务
systemctl stop redis
rm -f /var/lib/redis/6379/nodes-6379.conf
rm -f /var/lib/redis/6379/dump.rdb
rm -f /var/lib/redis/6379/appendonly.aof
> /etc/machine-id # 清空机器ID
systemctl start redis🔴🔴🔴🔴 难点理解:为什么机器 ID 会导致问题?
生活例子 :双胞胎身份证
克隆虚拟机就像复印身份证:原件和复印件(克隆机)身份证号(machine-id)完全一样!
如果两台电脑用同一个身份证上网:
DHCP 服务器(自动分配 IP)会 confused:"这身份证号刚才领过 IP 了,怎么又来?"
系统日志会混乱:"这台机器怎么同时在两个地方登录?"
必须清空身份证 (
> /etc/machine-id),让克隆机首次启动时去"公安局"(systemd)申请全新的身份证号!
(11)核心概念速查表
| 概念 | 一句话解释 | 重要性 |
|---|---|---|
| ⭐⭐⭐⭐⭐ 哈希槽 | 16384 个数据分区,实现水平扩展 | 必须掌握 |
| ⭐⭐⭐⭐⭐ Gossip 协议 | 节点间互相通信的"八卦网络" | 理解去中心化 |
| ⭐⭐⭐⭐ reshard | 槽位迁移,扩容缩容的核心操作 | 运维必会 |
| ⭐⭐⭐ MOVED 重定向 | 客户端连错节点时的自动纠正 | 开发必会 |
| ⭐⭐⭐ PFAIL/FAIL | 主观下线 → 客观下线的判定流程 | 故障排查 |
| ⭐⭐ cluster-enabled | 开启集群模式的配置开关 | 部署基础 |