
9.2.4 基于分布式神经网络架构的人形机器人算力分配
基于分布式神经网络架构的人形机器人算力分配,核心是通过"模块化硬件部署+分布式计算节点+实时通信总线",打破传统集中式算力架构的瓶颈,实现算力与任务需求的精准匹配,其技术范式在柏林洪堡大学Manfred Hild等人(2011)提出的DISTAL架构及MYON人形机器人中得到充分验证。该方案特别适用于需支持模块化重构、多任务并行的人形机器人,可兼顾实时性与灵活性。
- 技术原理
该算力分配架构以"分布式节点协同+总线化通信调度"为核心,整体结构如图9-11所示,主要包含算力节点层、通信总线层与任务调度层三大核心模块,实现算力的分布式部署与动态分配。
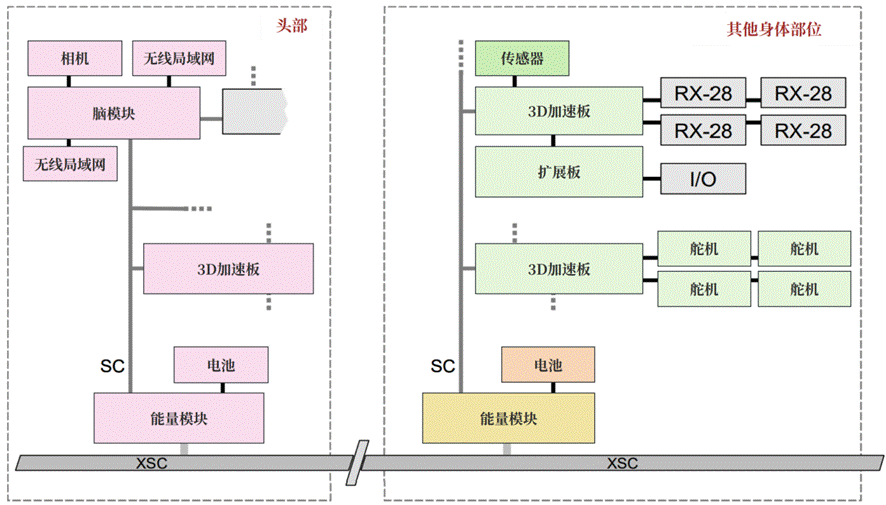
图9-11 算力分配系统
(1)算力节点层:分级部署与任务适配系统包含两类分布式算力节点,按需部署于机器人各模块化体块(头部、躯干、手臂、腿部):
- 基础算力节点(AccelBoard3D):共25个,每个搭载72MHz Cortex-M3 ARM RISC处理器与3轴加速度传感器,最多连接4个执行器(Robotis RX-28型),负责本地传感数据采集(关节角度、电机电流等)、低层级运动控制(如关节力矩调节)等实时性要求高的轻量级任务,实现"传感-计算-控制"本地闭环,减少数据传输延迟。
- 高级算力节点(BRAINMODULE):1个,部署于机器人头部,搭载XILINX Virtex-4 FPGA与16MB SDRAM,具备高强度并行计算能力,负责音视频处理(如Hough变换、目标识别)、全局行为决策等重算力任务,通过FPGA硬件加速保障复杂算法的实时性。
(2)通信总线层:SPINALCORD协同调度所有算力节点通过SPINALCORD总线互联,该总线兼具数据传输与能量传输功能,采用分时复用机制实现算力协同:
- 通信时序:10ms为一个周期,前3.36ms完成32个节点(含6个EnergyModule能量模块)的数据交互,剩余6.64ms供各节点执行本地计算与传感器数据采集;基础算力节点单次数据传输量为27个16位值(耗时125μs),能量模块仅传输电池状态(3个16位值,耗时18.33μs),确保总线带宽高效利用。
- 主从自适应:默认BRAINMODULE为总主节点(ID=0),同步相机50Hz信号实现数据时序一致性;当机器人模块化重构(如更换体块)时,新节点自动识别总线时序并加入,若新节点ID更低则自动成为主节点,保障算力分配无缝衔接。
(3)任务调度层:神经字节码(NBC)优化执行为降低算力损耗、提升执行效率,架构设计了神经字节码(NBC),将神经网络模型直接编译为ARM处理器的紧凑机器码:
-
模块化编译:每个神经网络计算单元(神经元/突触)对应独立的预处理代码(Preamble)与执行代码(Snippet),通过寄存器预分配减少上下文切换开销;
-
优先级调度:按代码前缀(如"200:"优先于"300:")定义计算顺序,初始化代码(前缀<100)仅执行一次,运动控制等实时任务优先调度,确保算力向高优先级任务倾斜。
-
核心特性
模块化算力适配:算力节点与机器人模块化体块一一对应,支持运行时体块拆卸与重组(runtime-metamorphosis),新体块接入后自动完成算力节点注册与任务分配,适配机器人形态重构需求。
-
实时性与并行性兼顾:本地轻量级任务由基础算力节点并行处理,重算力任务由高级节点集中加速,SPINALCORD总线的分时机制避免数据拥堵,整体计算延迟控制在10ms周期内,满足人形机器人运动控制的毫秒级响应需求。
-
算力利用率高:NBC编译机制减少代码冗余,本地闭环计算降低跨节点数据传输量,基础算力节点仅处理关联执行器的传感与控制任务,无无效算力消耗。
-
容错性强:无单一算力瓶颈,单个基础算力节点故障仅影响对应体块的局部功能,不导致整机瘫痪;总线主节点自适应切换机制保障重构或节点故障后的算力协同连续性。
-
人形机器人应用案例
MYON人形机器人(高1.25m、重15kg,32个自由度、48个执行器)基于该架构实现了手眼协调抓取任务,算力分配效果显著:
-
任务拆解与算力分配:目标识别任务(重算力)由BRAINMODULE的FPGA承担,通过相机图像实时检测物体位置(50Hz更新),消耗约60%高级节点算力;手臂运动控制任务(轻量级)由分布于手臂体块的AccelBoard3D节点并行处理,每个节点负责2-3个关节的力矩调节与位置闭环,单节点算力占用率约40%。
-
关键性能:无需预存世界模型,仅通过分布式算力协同,机器人可在桌面场景中自主定位物体、调整手臂姿态完成抓取,整个任务响应延迟≤100ms,位置控制精度达±0.5mm,验证了算力分配的合理性与实时性。
-
优势与局限性
(1)优势
- 适配模块化重构:算力节点随体块部署,支持机器人形态动态调整,解决传统集中式架构无法适配模块化机器人的痛点。
- 实时性与算力密度平衡:基础任务本地并行处理、复杂任务硬件加速,兼顾运动控制实时性与复杂算法算力需求。
- 开发门槛低:配套图形化软件BRAINDESIGNER,可通过拖拽节点生成神经网络模型并自动编译为NBC,无需手动编写底层算力调度代码。
(2)局限性
- 硬件成本较高:分布式算力节点(25个AccelBoard3D+1个BRAINMODULE)的硬件部署成本高于集中式架构,且FPGA开发需专业技术支持。
- 重算力任务扩展受限:高级算力节点仅1个,当新增多模态感知(如激光雷达点云处理)等重算力任务时,可能出现算力瓶颈。
- 跨节点协同复杂度高:虽通过总线时序保障协同,但多节点联合执行全局优化任务(如全身运动规划)时,数据同步与算力分配的调试难度较大。