1.进入官方仓库,手动下载代码(git拉取可能会有网络问题)
官方repo:https://github.com/haotian-liu/LLaVA
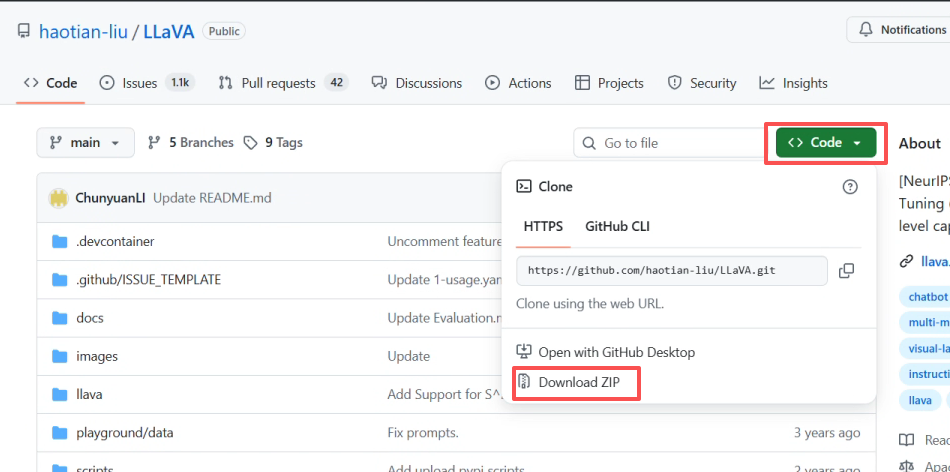
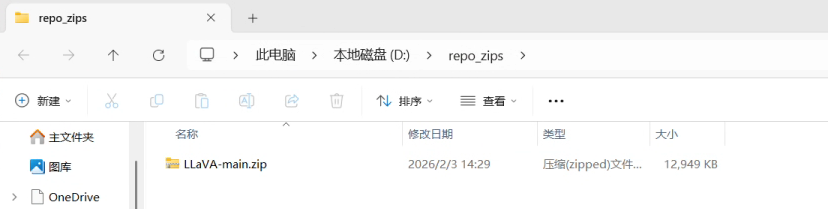
2.把压缩包放到WSL能看到的地方(这里放的是:D:\repo_zips)
3.在WSL创建新用户(避免污染),创建过程中需要设置密码,填完后全按回车即可。
bash
adduser llava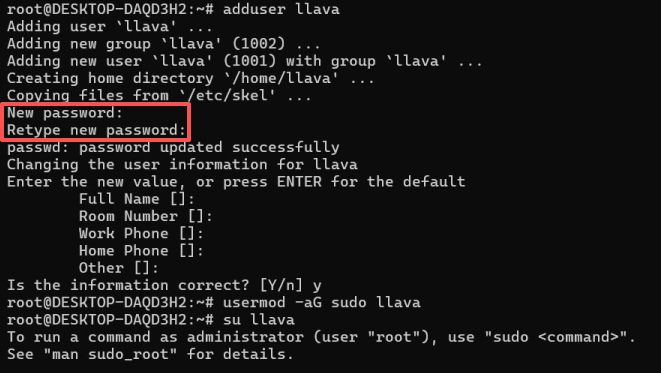
4.给用户权限,并转到用户,需要输入密码
bash
usermod -aG sudo llava
su - llava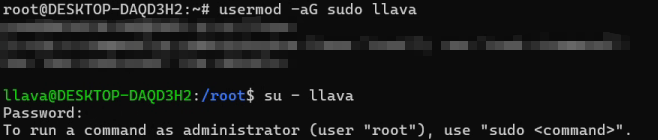
5.安装unzip工具包
bash
sudo apt-get update
sudo apt-get install -y unzip6.现在Linux文件home中创建work文件夹方便整理文件,解压官方库的压缩包(这里unzip 指令后跟着的是/mnt/ 加上本地存储路径)
bash
mkdir -p ~/work && cd ~/work
unzip /mnt/d/repo_zips/LLaVA-main.zip
ls -lh解压好后显示:
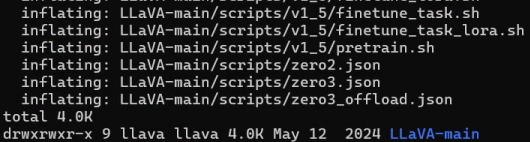
7.查看文件解压好后,拉wheel先装cuda,这里装的是50系显卡更适配的CUDA12.1,然后用清华镜像拉其他的包最大程度加快速度。
bash
ls
python3 -m venv ~/venvs/llava_dev
source ~/venvs/llava_dev/bin/activate
python -m pip install -U pip setuptools wheel
pip uninstall -y torch torchvision torchaudio
pip install -U torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/cu121 \
--extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple \
--timeout 120 --retries 20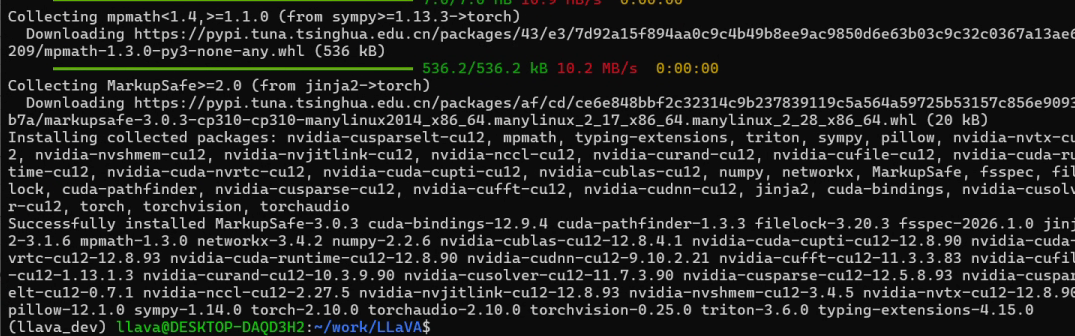
8.验证torch GPU可用
bash
python - <<'PY'
import torch
print("torch:", torch.__version__)
print("cuda available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("gpu:", torch.cuda.get_device_name(0))
print("cuda runtime:", torch.version.cuda)
PY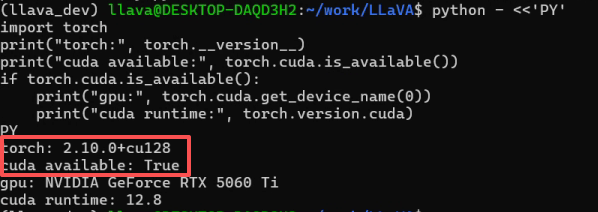
9.安装VLM依赖,并复查环境是否变化。因为-e可能会更改环境(有时候对于需求比较新的硬件是一个不好的现象)。
bash
pip install -U transformers accelerate bitsandbytes pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -e . --no-deps
pip install -U transformers accelerate bitsandbytes pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -U "protobuf<5" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -U \
einops==0.6.1 einops-exts==0.0.4 \
sentencepiece==0.1.99 shortuuid \
timm==0.6.13 \
pydantic \
-i https://pypi.tuna.tsinghua.edu.cn/simple
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)"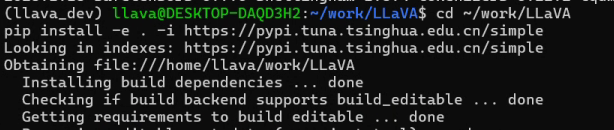
10.验证editable是否安装成功
bash
python -c "import llava; print('llava import OK:', llava.__file__)"
11.在D盘创建一个test文件夹,放入一个demo.jpg测试
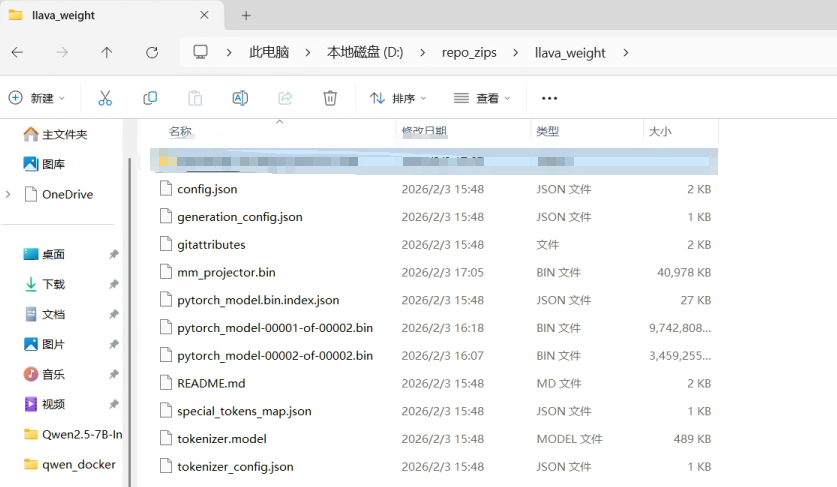
12.手动拉取权重:https://huggingface.co/liuhaotian/llava-v1.5-7b/tree/main,下载到本地文件夹(这里放的是D:\repo_zips\llava_weight)。
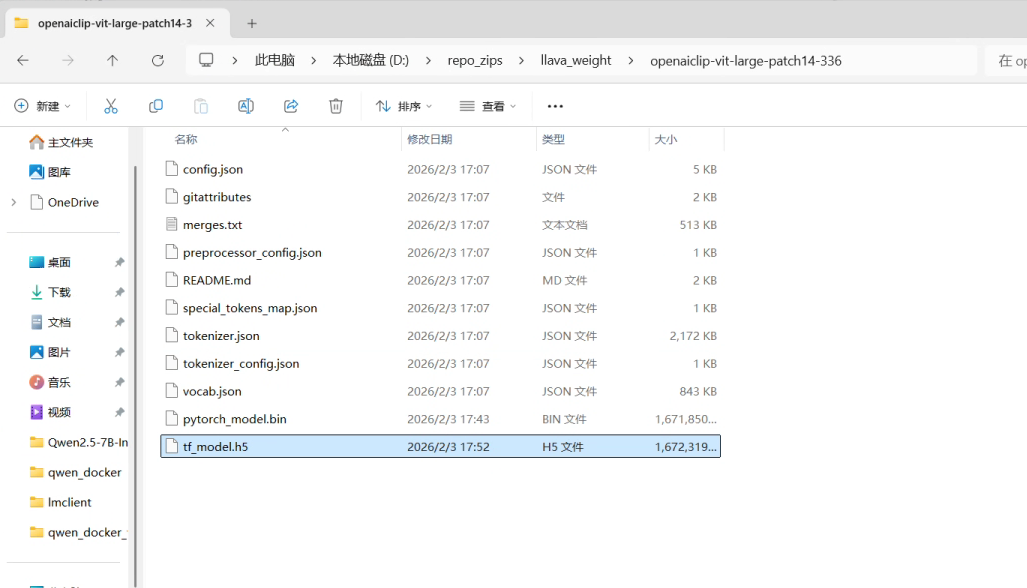
13.手动拉取视觉塔(clip)依赖,openai/clip-vit-large-patch14-336 at main,下载到本地文件夹(这里放的是D:\repo_zips\llava_weight\openaiclip-vit-large-patch14-336)
14.更改CLIP索引路径,本质上是到文件夹中找到config文件进行修正,修改local的赋值,可以手动改。
bash
python - <<'PY'
import json, shutil
p="/mnt/d/repo_zips/llava_weight/config.json"
bak=p+".bak"
shutil.copy2(p,bak)
cfg=json.load(open(p,"r",encoding="utf-8"))
local="/mnt/d/repo_zips\llava_weight\openaiclip-vit-large-patch14-336"
cfg["mm_vision_tower"]=local
json.dump(cfg, open(p,"w",encoding="utf-8"), ensure_ascii=False, indent=2)
print("updated mm_vision_tower ->", local)
print("backup saved ->", bak)
PY15.跑8bit量化测试
bash
export HF_HUB_OFFLINE=1
export TRANSFORMERS_OFFLINE=1
python -m llava.serve.cli \
--model-path /mnt/d/repo_zips/llava_weight \
--image-file /mnt/d/test/demo.jpg \
--load-8bit \
--max-new-tokens 128 \
--query "Describe the image in detail: objects, people, and background."