Qwen-2.5VL模型架构:
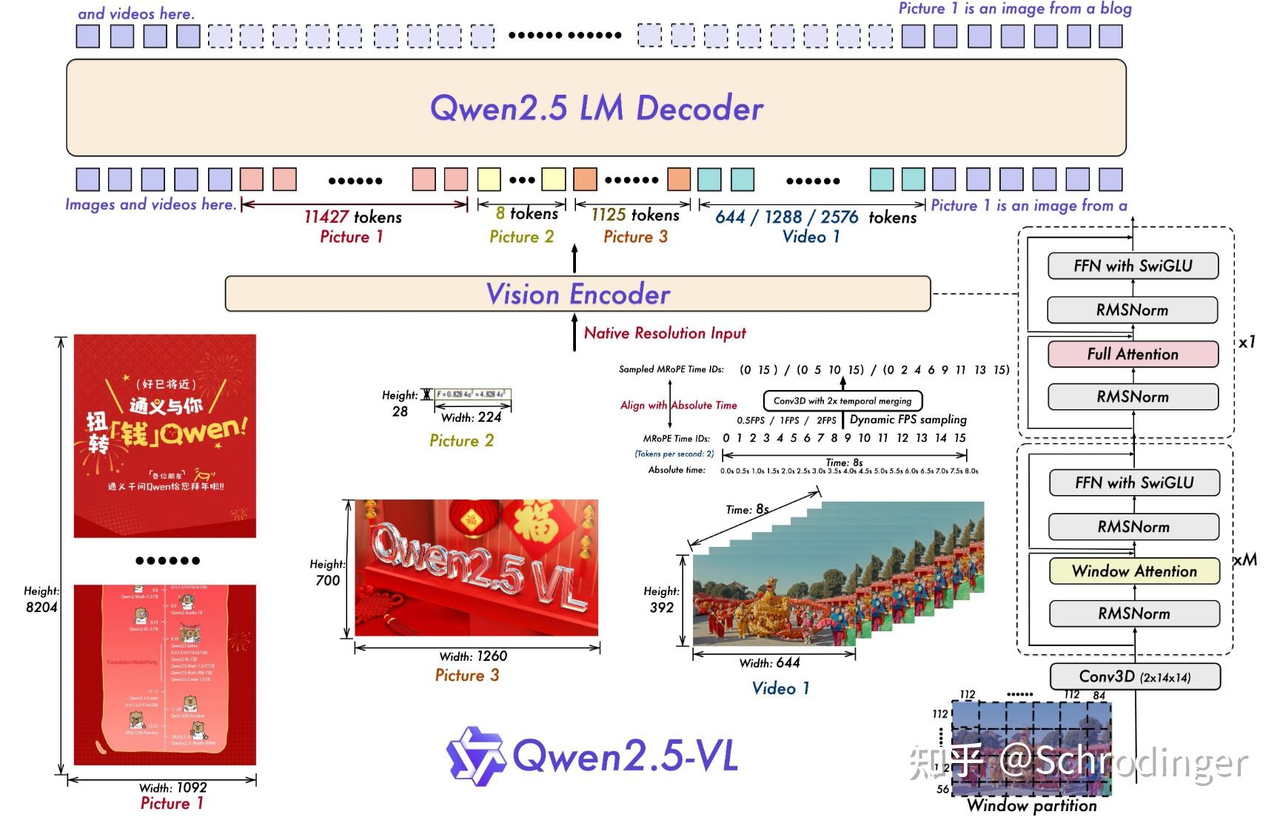
- Qwen2.5 LM Decoder: 主要以 Qwen2.5 LLM 为基础
- Vison Encoder: 重新设计的ViT -> 引入了 2D-ROPE 和 Window Attention 以支持原生分辨率输入并加速计算。在训练和推理时,输入图像的高度和宽度会被调整为 28 的倍数,然后通过 14 步幅的 Patch 分割来生成图像特征。
- 基于 MLP 的视觉-语言融合模块 :通过将空间上相邻的四个 Patch 特征进行分组,然后通过两层 MLP 将其投影到与 LLM 文本嵌入对齐的维度,实现特征序列的压缩
执行流程:实际推理时,往往会将文本和图像一起输入给Qwen-VL,并分开处理视觉和文本信息
ps:现在大模型的架构都放在Hugging Face Transformers库中,而不是在GitHub仓库中显式构建,这是现代深度学习模型的标准实践
- 视觉信息处理:
- Patch 分割:模型支持原生分辨率输入,图像首先被分割成 14x14 像素的 Patch块,会被一个线性投影层(通常是一个卷积核大小为 14x14、步长为 14 的卷积层)展平并映射为一个一维向量
- MROPE :模型采用了 2D Rotary Positional Embedding
- 在进行窗口注意力之前,batch, N, hidden_dim 必须先被"重新整形"(Reshape),把这个 1D 序列还原成它在 2D 图像上的空间结构,即 batch, H_patches, W_patches, hidden_dim
- Window Attention (窗口注意力机制):核心思想是将输入的特征图(或 Patch 序列)划分为若干个不重叠的局部窗口 (local windows)。然后,自注意力机制只在每个独立的窗口内部进行计算。模型需要把这个 H_patches 和 W_patches 的网格,进一步划分成一个个 8x8 的小窗口 -> batch*H_patches*W_patches/64, 64, hidden_dim自注意力在这个小空间中进行
- 文本信息处理:这部分由 Qwen2.5 系列的 Large Language Model (LLM)(大型语言模型)负责
- Tokenizer+Embedding bsz, seq_len, hidden_dim
- 融合模块:MLP-based Vison-Language Merger 模块对齐和融合
- 由于Vision Encoder 输出的原始视觉 Patch 特征序列可能很长,假设Vision Encoder 的输出为batch, H_patches, W_patches, hidden_dim_vision
- 关键操作------"相邻的四组 Patch 特征进行分组" -> batch, H_patches/2, W_patches/2, 2, 2, hidden_dim_vision -> 特征拼接 batch, H_patches/2, W_patches/2, 4 \* hidden_dim_vision
- 模态对齐--MLP投影:可以看到现在维度和形状都不匹配,先将2D 网格展平成序列 batch, N_visual_tokens, 4 \* hidden_dim_vision 然后通过两层MLP(5120, intermediate_dim+intermediate_dim, 2048)输出 -> batch, N_visual_tokens, hidden_dim_llm
- 最终将两个序列在 seq_len 维度上拼接
- Visual Tokens: batch, N_vis, H_llm
- Text Tokens: batch, N_txt, H_llm