一、使用cv2中自带的文件进行人脸识别
cv2库中就有人脸识别的文件,这里我们使用的是pycharm所以就用pycharm进行演示
左侧项目栏中展开外部库------>展开site-package------>展开cv2------>展开data
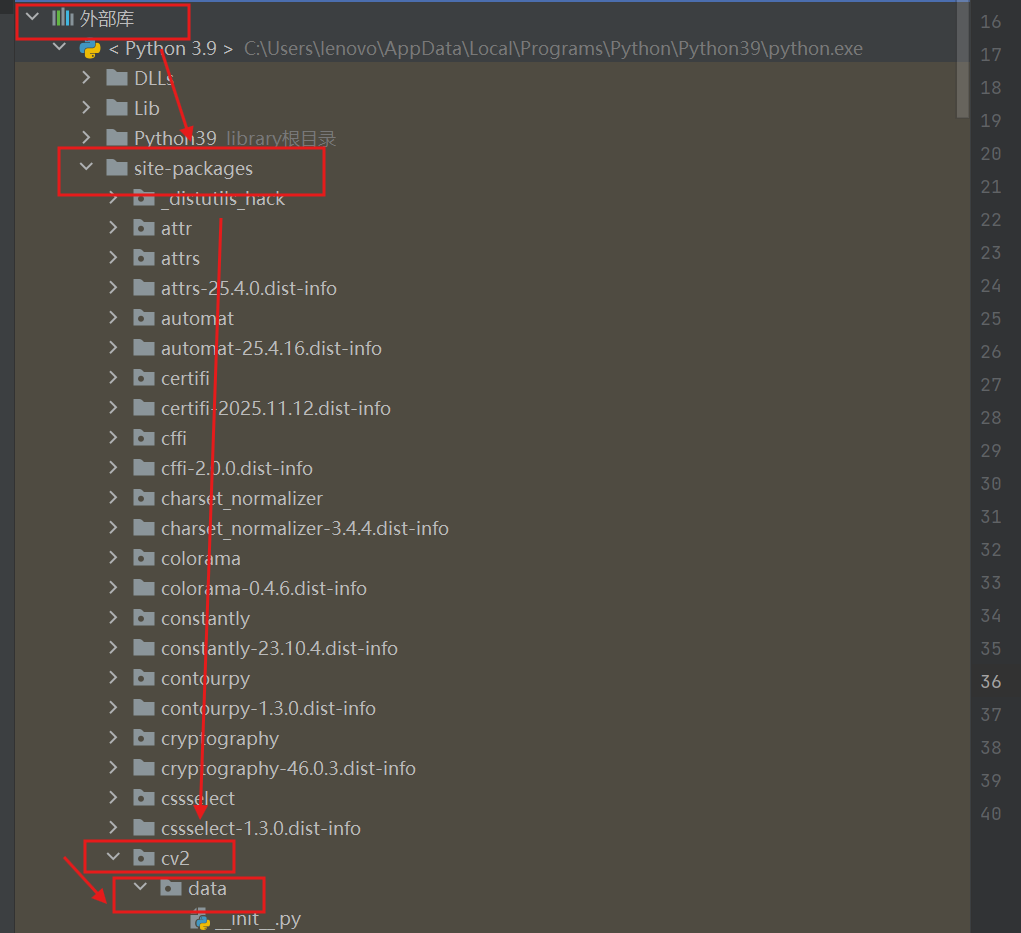
然后就会看到这些文件,这是cv2本身自带的
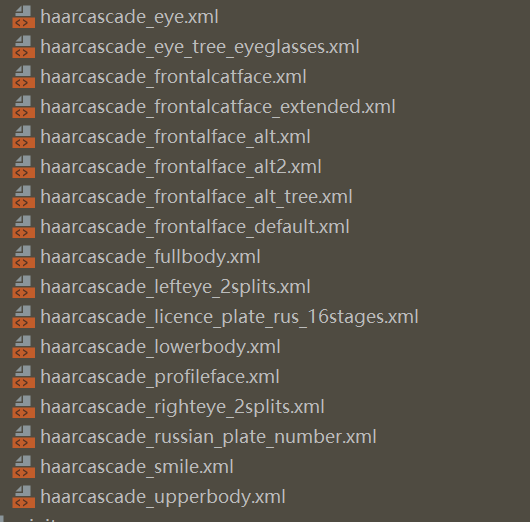
右击这个文件复制粘贴到我们要写的代码文件位置同目录下,以供我们后面的使用

其实意思就是
1.人脸识别
objects=cv2.CascadeClassifier.detectMultiScale(image,scaleFactor,minNeighbors,flags,minSize,maxSize )
其中,各个参数及返回值的含义如下。
- .image:待检测图像,通常为灰度图像。
- .scaLeFactor:表示在前后两次相继扫描中搜索窗口的缩放比例。识别,扫描,按照不同比例来进行扫描
- .minNeighbors:表示构成检测目标的相邻矩形的最小个数。在默认情况下,该参数的值为3, 表示有3个以上的检测标记存在时才认为存在人脸。如果希望提高检测的准确率可以将该参数的值设置得更大, 但这样做可能会让一些人脸无法被检测到。
- fLags:该参数通常被省略。在使用低版本OpenCV(OpenCV 1.X版本)时,该参数可能会被设置为 CV_HAAR_DO_CANNY_PRUNING,表示使用Canny边缘检测器拒绝一些区域。
- .minSize:目标的最小尺寸,小于这个尺寸的目标将被忽略。
- .maxSize:目标的最大尺寸,大于这个尺寸的目标将被忽略。通常情况下,将该可选参数省略即可。 若maxSize和minSize 大小一致,则表示仅在一个尺度上查找目标。
- .objects:返回值,目标对象的矩形框向量组。该值是一组矩形信息 包含每个检测到的人脸对应的矩形框的信息(x轴方向位置、y轴方向位置、宽度、高度)。
python
#对图片的人脸识别
import cv2
# 读取图片
image = cv2.imread(r"D:\project\x-other.jpg")
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 加载人脸识别分类器
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')#导入我们刚刚复制的文件
# 检测人脸
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.05, minNeighbors=5, minSize=(8, 8))
# 输出检测结果
print("发现{}张人脸!".format(len(faces)))
print("其位置分别是:", faces)
# 在图片上标注人脸
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示结果
cv2.imshow("result", image)
cv2.waitKey(0)
cv2.destroyAllWindows()注意,这里我们的文件要在同目录下,上面也有说过,意思就是 下面这样,我们在1人脸识别这个代码中使用到了这个文件,如果直接写这个cv2中人脸识别的文件名就要确保该文件也在这个文件目录下,这里两个文件都在人脸识别这个目录下。其实就是和我们读取图片一样道理。
结果

上面是对图片进行人脸识别,下面我们修改代码让他对摄像头或者视频进行人脸识别。
在之前opencv的学习中也有提到过图片和视屏的转换,最重要的一点就是while True的添加,对视频的处理实质上也是对图片的处理,搞懂一个那么后面图片转视频就会游刃有余。
python
import cv2
# 加载人脸识别分类器
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
cap=cv2.VideoCapture('tuanbo.mp4')
while True:
ret,frame=cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.05, minNeighbors=5, minSize=(8, 8))
# 输出检测结果
print("发现{}张人脸!".format(len(faces)))
print("其位置分别是:", faces)
# 在图片上标注人脸
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('re',frame)
key=cv2.waitKey(1) & 0xFF
if key==ord('q'):
break
cap.release()
cv2.destroyAllWindows()2.微笑检测
本质上也是对人脸的识别,在cv2库中找到下面文件,也复制粘贴到我们要写的代码文件同目录下

这里我们直接对视频进行微笑检测,也可以自己改代码改为图片微笑检测
这里我们设置镜像不是因为他能提高微笑检测的效果,而是一般情况下人脸识别是给用户自己是用户的,这样设置镜像能增加用户体验感。
python
import cv2
# 加载人脸和微笑检测分类器
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
smile = cv2.CascadeClassifier("haarcascade_smile.xml")
cap = cv2.VideoCapture('smile2.mp4') # 初始化摄像头
while True: # 处理每一帧
ret, image = cap.read() # 读取一帧
if not ret: # 没有读到,直接退出
break
image = cv2.flip(image, 1) # 图片翻转,水平翻转(镜像)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 灰度化
# 人脸检测
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=10, minSize=(5, 5))
for (x, y, w, h) in faces:
# 绘制人脸矩形框
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 提取人脸所在区域(灰度)
roi_grayscale = gray[y:y + h, x:x + w]
cv2.imshow('dongtai',roi_grayscale)#这里的显示是实时,人脸识别矩形框内单独裁剪出来
# 仅在人脸区域内检测微笑
smiles = smile.detectMultiScale(roi_grayscale, scaleFactor=1.5, minNeighbors=25, minSize=(50, 50))
for (sx, sy, sw, sh) in smiles:
# 绘制微笑区域(相对于原图坐标)
a = x + sx
b = y + sy
cv2.rectangle(image, (a, b), (a + sw, b + sh), (255, 0, 0), 2)
# 显示文字"smile"表示微笑了
cv2.putText(image, "smile", (x, y), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 255, 255), 2)
# 显示结果
cv2.imshow('Face and Smile Detection', image)
key = cv2.waitKey(30)
if key == 27: # ESC键退出
break
cap.release()
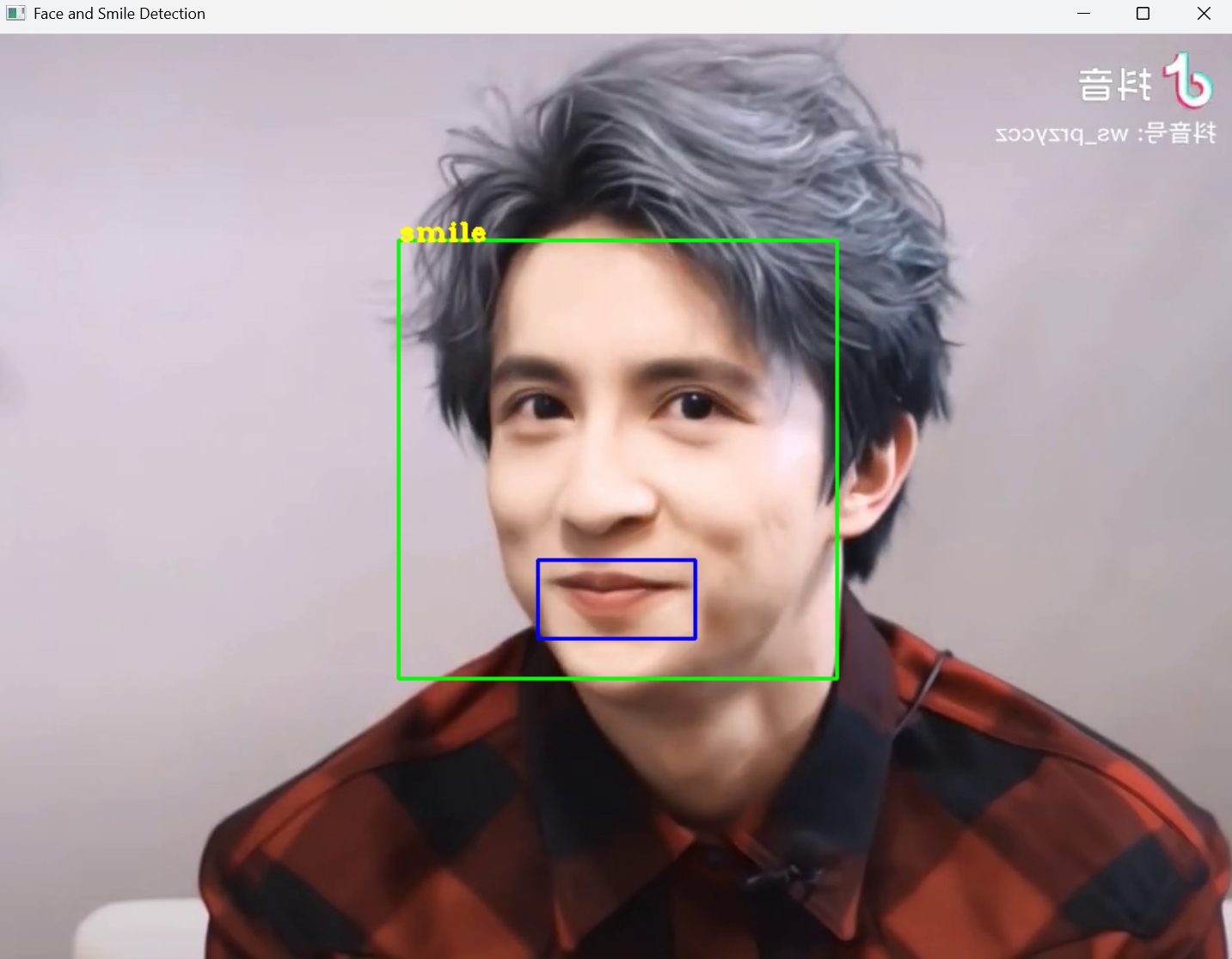
cv2.destroyAllWindows()这里有两个矩形框,一个是对人脸识别的,一个是对微笑识别,当检测到微笑的时候,左上角就会显示smile
二、LBPH人脸识别
这里我们传入五张图片其中前三张是一个人,我们设标签为0对应ss,后两张是另外一个人,我们设标签为1,对应是xzq。标签-1就是无法识别
传入一张新图对该图片进行识别人脸,并显示名字。
1.识别器
cv2. face. LBPHFaceRecognizer create(radius-None, neighbors-None, grid x=None, grid y-None, threshold-None) 是创建一个LBPH的人脸特征识别器:
- radius:可选参数 圆形局部二进制模式的半径,建议使用默认值
- neighbors:可选参数,圆形局部二进制模式的采样点数目,建议使用默认值
- grid_x:可选参数水平方向上的的单元格数,默认值为8,即将LBP特征图在水平方向上划分为8个单元。
- grid_y:可选参数垂直方向上的的单元格数,默认值为8,建议使用默认值,若grid_x和grid_y都为默认值 ,则表示特征图划分为8*8大小,统计8*8大小的直方图。
- threshold:可选参数 人脸识别时使用的阈值,建议使用默认值,也可以进行调节
2.训练模型
函数train用给定的数据和相关标签训练生成的实例模型。
该函数的语法格式为 :None = 识别器对象.train(src,Labels)
src:训练图像,用来学习的人脸图像;Labels:标签,人脸图像对应的标签
3.预测
函数predict()对一个待识别人脸图像进行判断,寻找与当前图像距离最近的人脸图像。与哪幅人脸图像距离最近,就将当前待测图像标注为该人脸图像对应的标签。若待识别人脸图像与所有人脸图像的距离都大于特定的距离值(阈值),则认为没有找到对应的结果,
参数与返回值的含义如下:
- src:需要识别的人脸图像
- Label:返回的识别结果标签,返回-1表示无法识别当前人脸。
- confidence:返回的置信度评分,用来衡量识别结果与原有模型之间的距离,
- 评分越小表示匹配越高,但是若高于80,则认为识别结果与原有模型差距大。
python
import cv2
import numpy as np
# 提前训练的人脸照片
images = []
images.append(cv2.imread(r"ss/1.jpg", cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(r"ss/4.jpg", cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(r"ss/3.jpg", cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(r"ss/7.jpg", cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(r"ss/8.jpg", cv2.IMREAD_GRAYSCALE))
labels = [0,0,0,1,1]
dic = {0: 'ss', 1: 'xzq', -1: '无法识别'}
# 待识别人脸
predict_image = cv2.imread(r"ss/9.jpg", cv2.IMREAD_GRAYSCALE)
# 创建LBPH人脸识别器
recognizer = cv2.face.LBPHFaceRecognizer_create(threshold=100)#可以进行调节,识别不出来就往大调
# 训练模型
recognizer.train(images, np.array(labels))
# 预测
label, confidence = recognizer.predict(predict_image)
print('这是:', dic[label])
print('置信度:', confidence)结果:
这里我们要介绍一下置信度的含义,置信度和准确率是不一样的。准确率高说明模型训练的很好。但是置信度高并不代码预测就是对的,置信度是模型训练之后,有一套自己的判断规则之后,进行预测一个新数据,他会有几个预测的结果,其中模型觉得哪个可能性最大就会输出哪个,所以置信度高只是模型自以为的可能性最大的结果。
三、EigenFace人脸识别
1.识别器
cv2.face.EigenFaceRecognizer_create (num_components=None, threshold=None)
- 作用:创建一个EigenFace的人脸特征识别器
- num_components:在PCA中要保留的分量个数。当然,该参数值通常要根据输入数据来具体确定,并没有一定取值。一般程序中,取80即可(降维成多少个特征)
- threshold:进行人脸识别所采用的阈值
2.训练
函数FaceRecognizertrain用给定的数据和相关标签训练生成的实例模型。
该函数的语法格式为 #None = cv2.faceFaceRecognizer.train(src, labels )
参数的含义如下:
- src:训练图像,用来学习的人脸图像
- LabeLs:标签,人脸图像对应的标签。
python
import cv2
import numpy as np
# 读取训练图像,注意:图片大小需要一致
images = []
a = cv2.imread(r".\ss\7.jpg", 0)
a = cv2.resize(a, (120, 180))
b = cv2.imread(r".\ss\9.jpg", 0)
b = cv2.resize(b, (120, 180))
c = cv2.imread(r".\ss\11.jpg", 0)
c = cv2.resize(c, (120, 180))
d = cv2.imread(r".\ss\12.jpg", 0)
d = cv2.resize(d, (120, 180))
images.append(a)
images.append(b)
images.append(c)
images.append(d)
labels = [0, 0, 1, 1]
# 待识别图像
pre_image = cv2.imread(r".\ss\8.jpg", 0)
pre_image = cv2.resize(pre_image, (120, 180))
# 创建Eigenfaces人脸识别器
recognizer = cv2.face.EigenFaceRecognizer_create(threshold=9000)#往大调
# 使用训练数据(images和labels)来训练识别器
recognizer.train(images, np.array(labels))
@预测
label, confidence = recognizer.predict(pre_image)
dic = {0: 'xzq', 1: 'yyp', -1: '无法识别'}
print('这是:', dic[label])
print('置信度为:', confidence)
# 在图片上显示识别结果
original_img = cv2.imread(r".\ss\8.jpg").copy()
original_img = cv2.resize(original_img, dsize=None,fx=0.5,fy=0.5)
aa = cv2.putText(original_img, dic[label], (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
cv2.imshow('Recognition Result', aa)
cv2.waitKey(0)
cv2.destroyAllWindows()结果:
