目录
[(2)CTC损失函数(CTC cost)来做语音识别](#(2)CTC损失函数(CTC cost)来做语音识别)
1.语音识别
- seq2seq模型 在**语音识别(speech recognition)**领域有很好的应用**
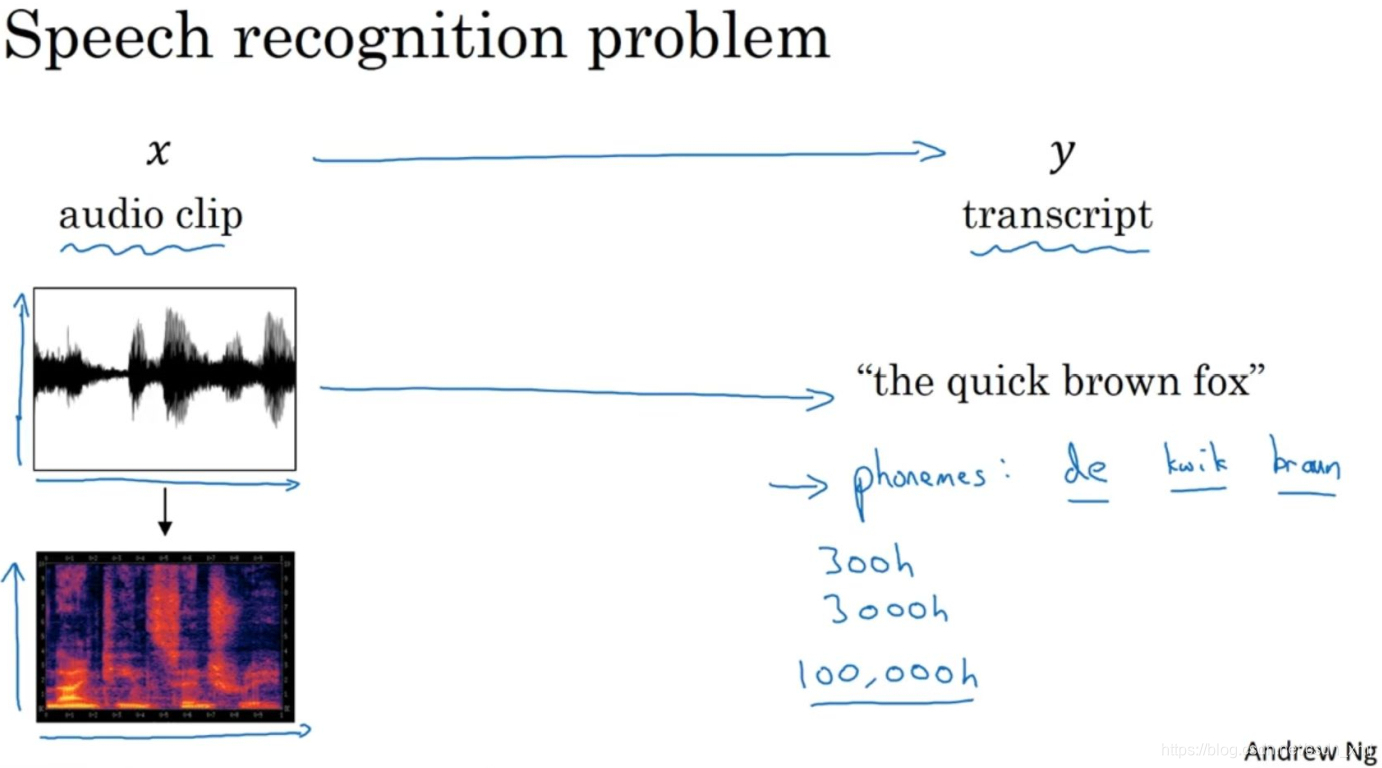
- 有一个音频片段x,任务是自动地生成文本 y。一个音频片段,画出来是这样(横轴是时间)。假如这个音频片段的内容是:"the quick brown fox",这时我们希望一个语音识别算法,通过输入这段音频,然后输出音频的文本内容。音频数据的常见预处理步骤,就是运行这个原始的音频片段,然后生成一个声谱图(右下方),横轴是时间,纵轴是声音的频率,图中不同的颜色,显示了声波能量的大小,也就是在不同的时间和频率上这些声音有多大。
(1)注意力模型构建语音识别
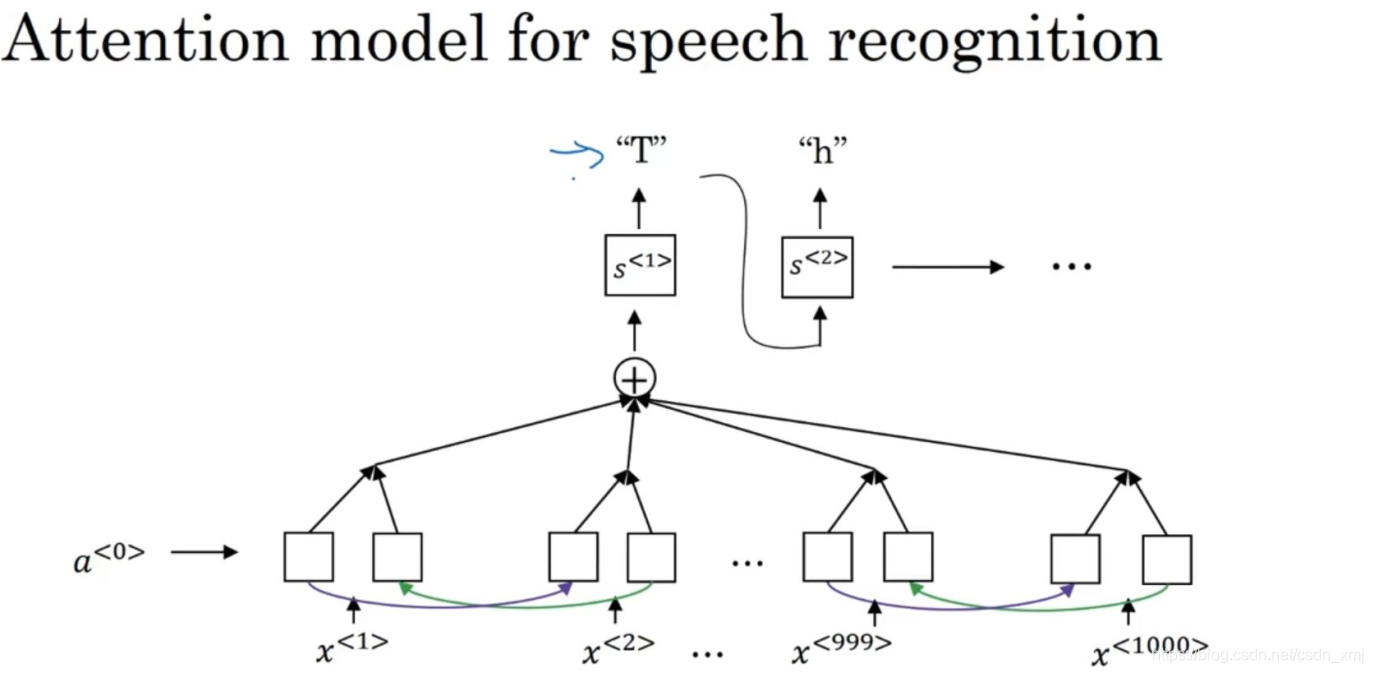
- 编码器获取输入音频的不同时间帧,解码器输出目标文本
(2)CTC损失函数(CTC cost)来做语音识别
- 还有一种效果也不错的方法,就是用CTC损失函数(CTC cost)来做语音识别
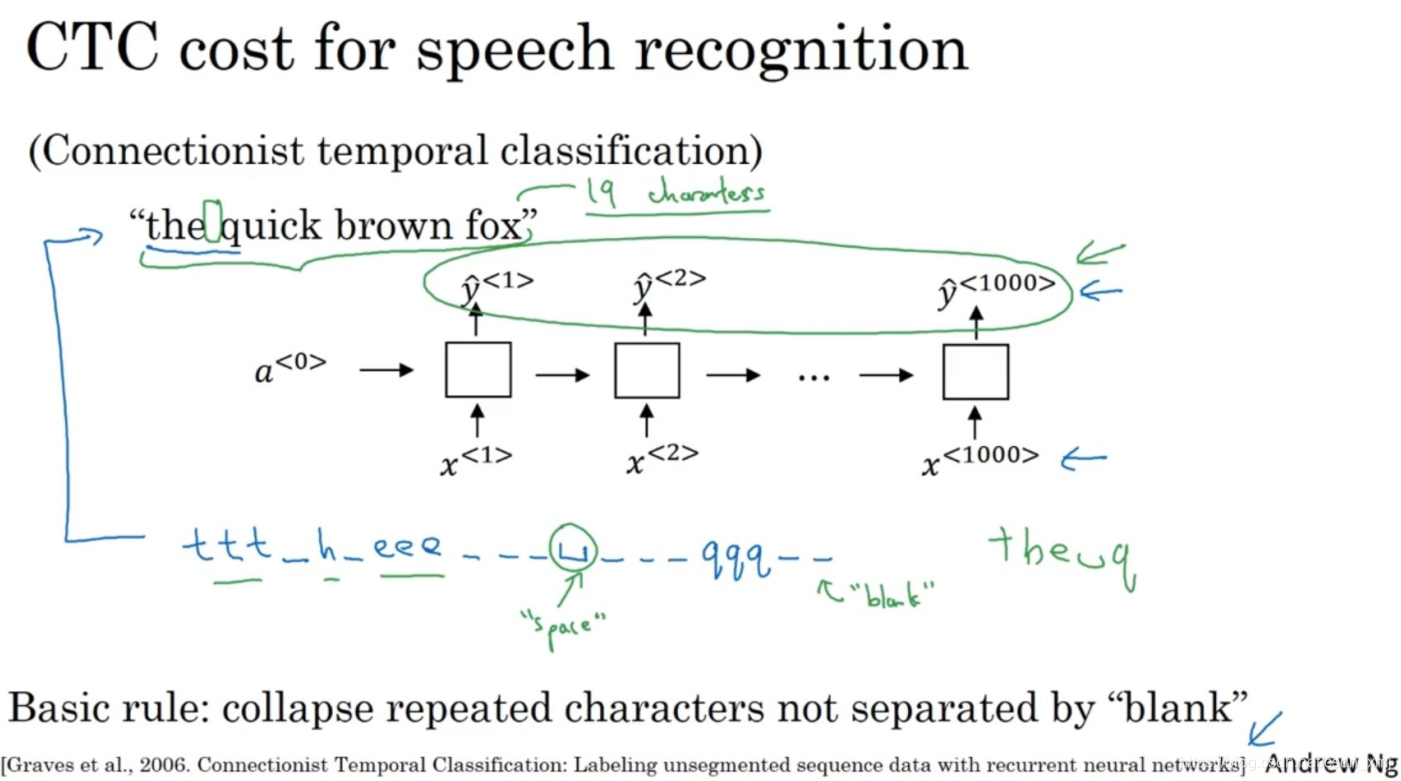
- 我们使用一个新的网络,结构像这个样子,这里输入x和输出y的数量一样,这里画的是一个简单的单向RNN结构,不过在实际中,它有可能是双向的LSTM结构,或者双向的GRU结构,并且通常是很深的模型。
- 在语音识别中,通常输入的时间步数量要比输出的时间步的数量多出很多。这时要怎么办呢?CTC损失函数允许RNN生成一个空白符(black character) ,用下划线表示。于是这句"the quick brown fox"包括空格一共有19个字符,在这样的情况下,通过允许神经网络有重复的字符和插入空白符使得它能强制输出1000个字符,甚至你可以输出1000个y值来表示这段19个字符长的输出。
2.触发词检测
(1)简介
- 随着语音识别的发展,越来越多的设备可以通过你的声音来唤醒,也叫做触发字检测系统(trigger word detection systems)。
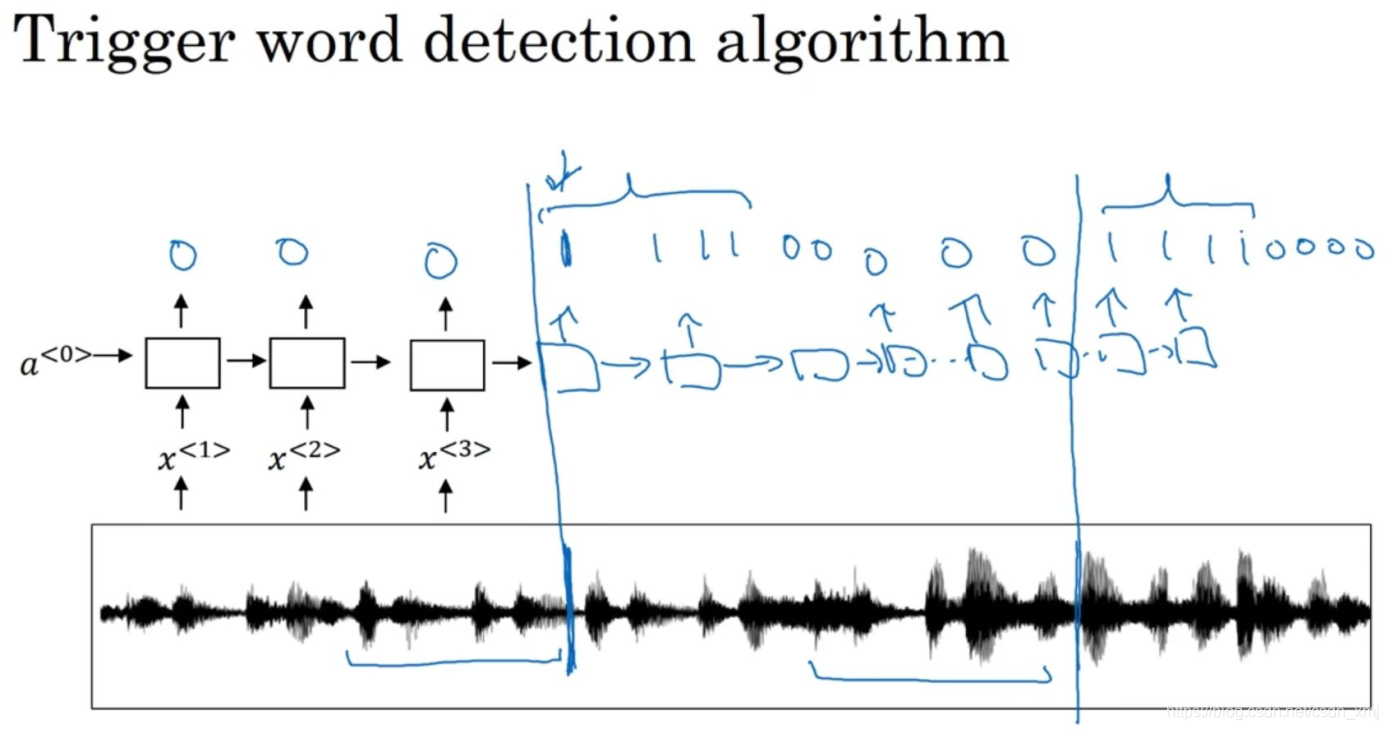
(2)构造触发词检测系统

- 如上图,有一个这样的RNN结构。
- 先把音频片段计算出它的声谱图特征,得到特征向量x^<1>, x^<2>, x^<3>...,然后把它放到RNN中。
- 然后定义我们的目标标签y。假如音频片段中的这一点是某人刚刚说完一个触发字,比如"小爱同学",或者"小度你好"等等,那么在这一点之前,你就可以在训练集中把目标标签都设为0,然后在这个点之后把目标标签设为1。这样的标签方案对于RNN来说是可行的,并且确实运行得非常不错。不过该算法一个明显的缺点是构建了一个很不平衡的训练集,因为0的数量比1多太多了。
- 有一个简单粗暴的解决办法,能使其变得更容易训练。如下图所示,比起只在一个时间步上去输出1,可以在输出变回0之前,多输出几个1,或说在固定的一段时间内输出多个1。这样就稍微提高了1与0的比例。