动画理解Pytorch 大模型分布式训练技术 DP,DDP,DeepSpeed ZeRO技术_哔哩哔哩_bilibili
单卡运行流程

DP(data parallel)
从硬盘读取数据,然后一个cpu进程将数据分成多份,给每个GPU训练,然后计算出梯度 进行网络更新(无效更新),然后再将各个GPU算出来的梯度,返回到gpu0进行梯度平均,再更新网络0,网络0再把更新后的网络参数广播到其他网络上。
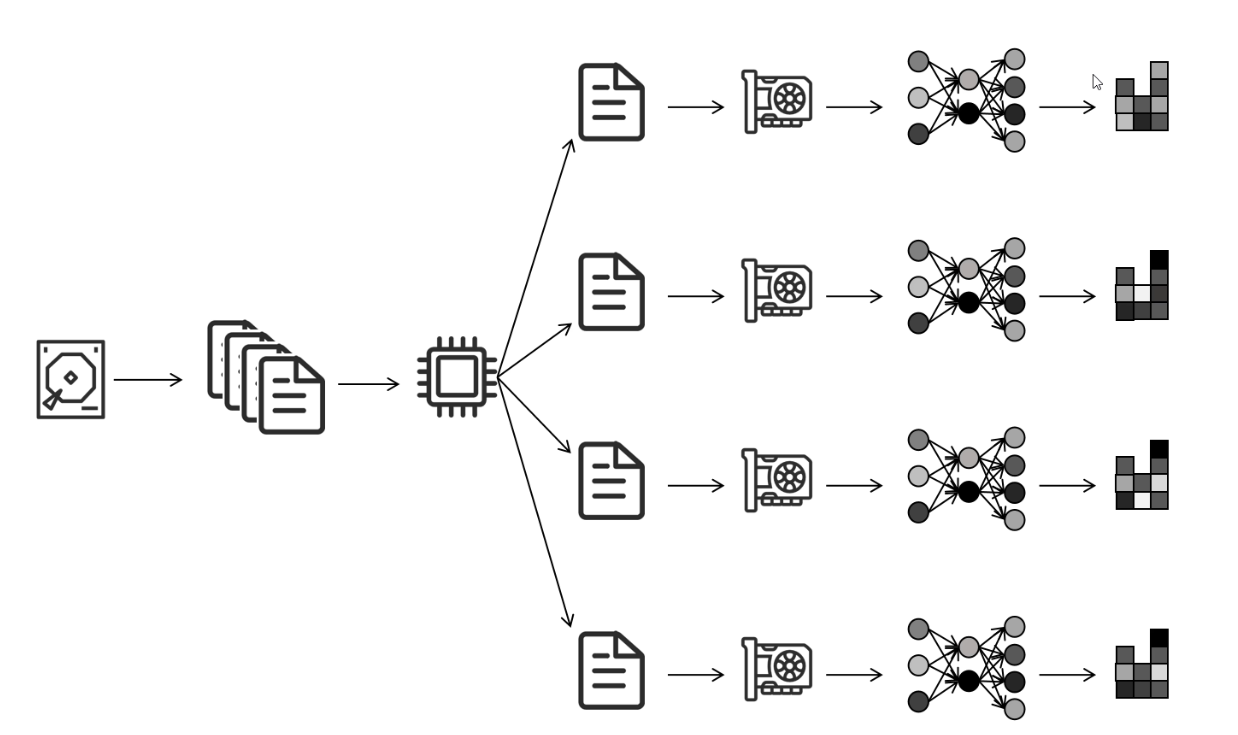
DP存在的问题: 单进程,多线程,Python GIL只能利用一个CPU核。
GPU0负责手机梯度,更新参数,同步参数,通信,计算压力大。(即卡间负载极不平衡)
DDP: 让每个GPU都能进行接收处理以及通讯。
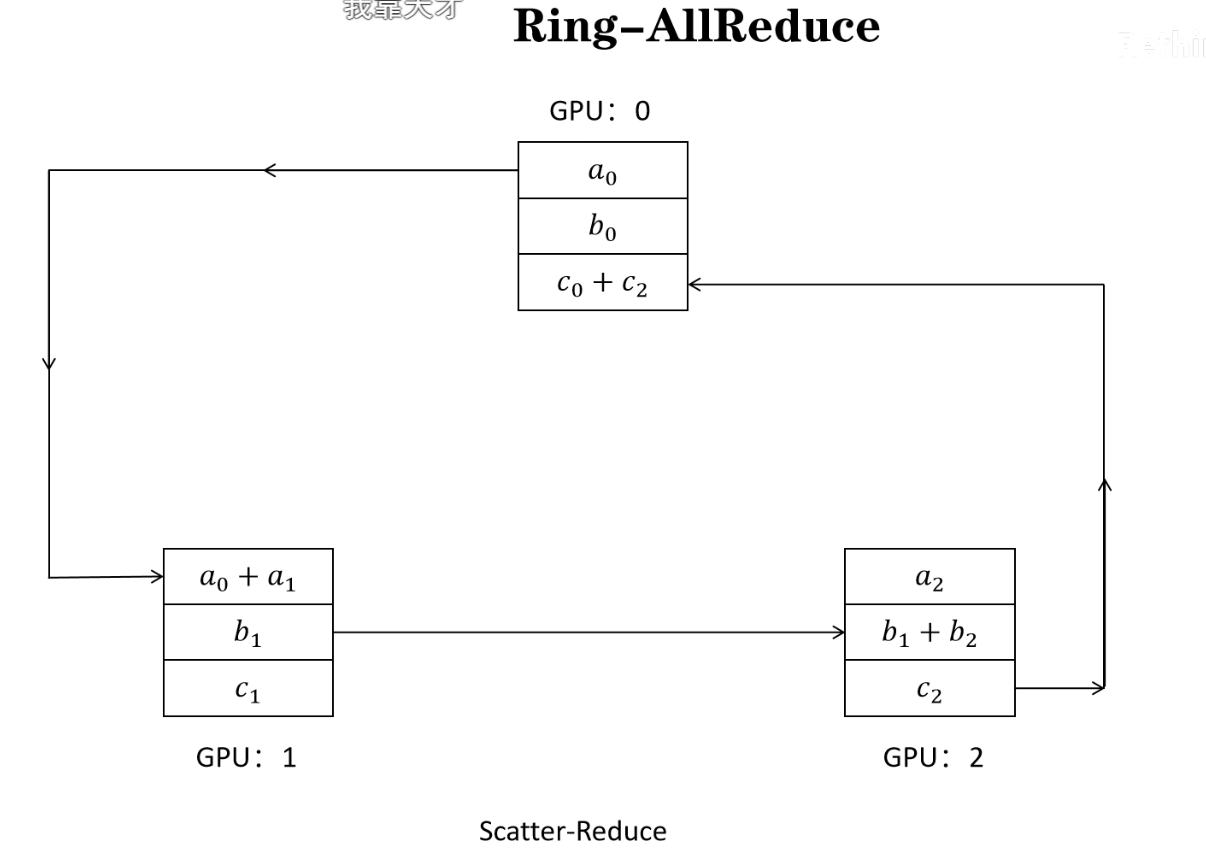
图中scatter的意思是,通过分发,让不同的节点有不同的值,reduce 的意思是 收集所有节点的值,并进行计算。
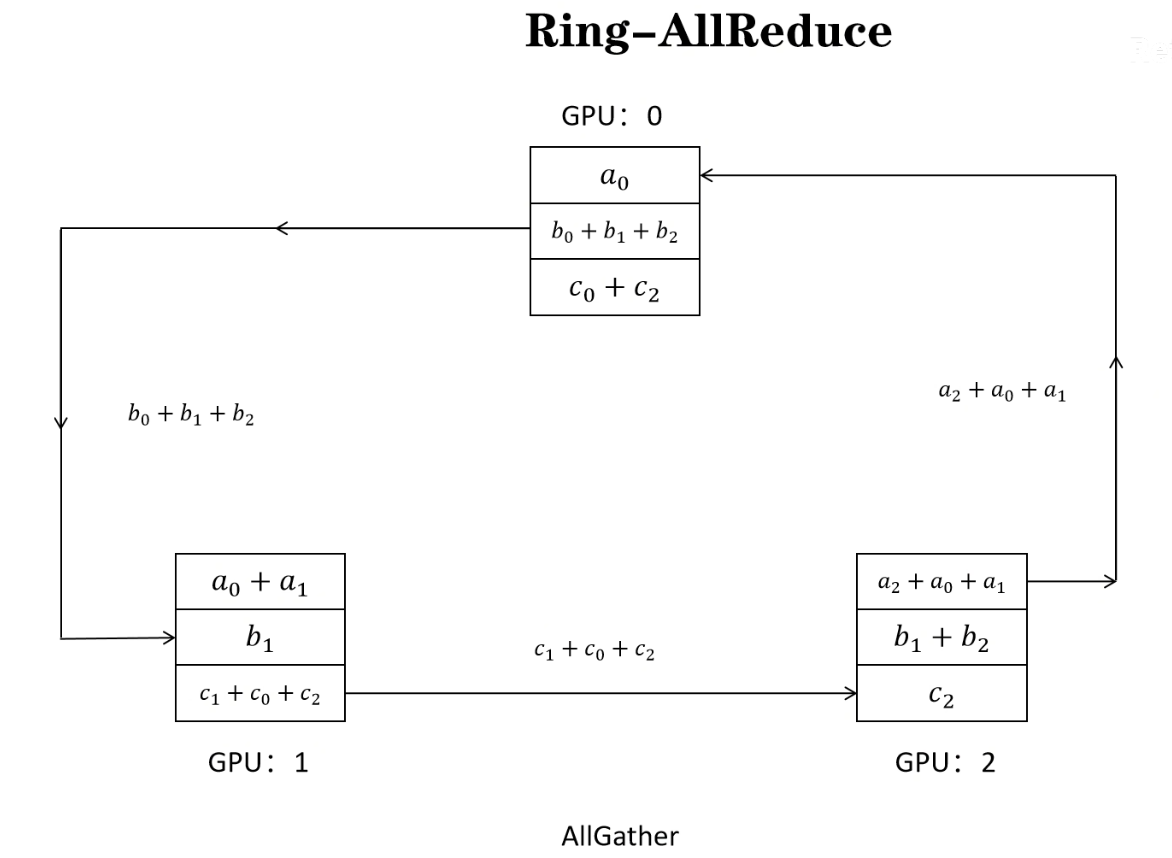
allgather 的意思是,把更新后的值,同步到 各个GPU,最后完成更新。充分利用各个GPU上下行的带宽。
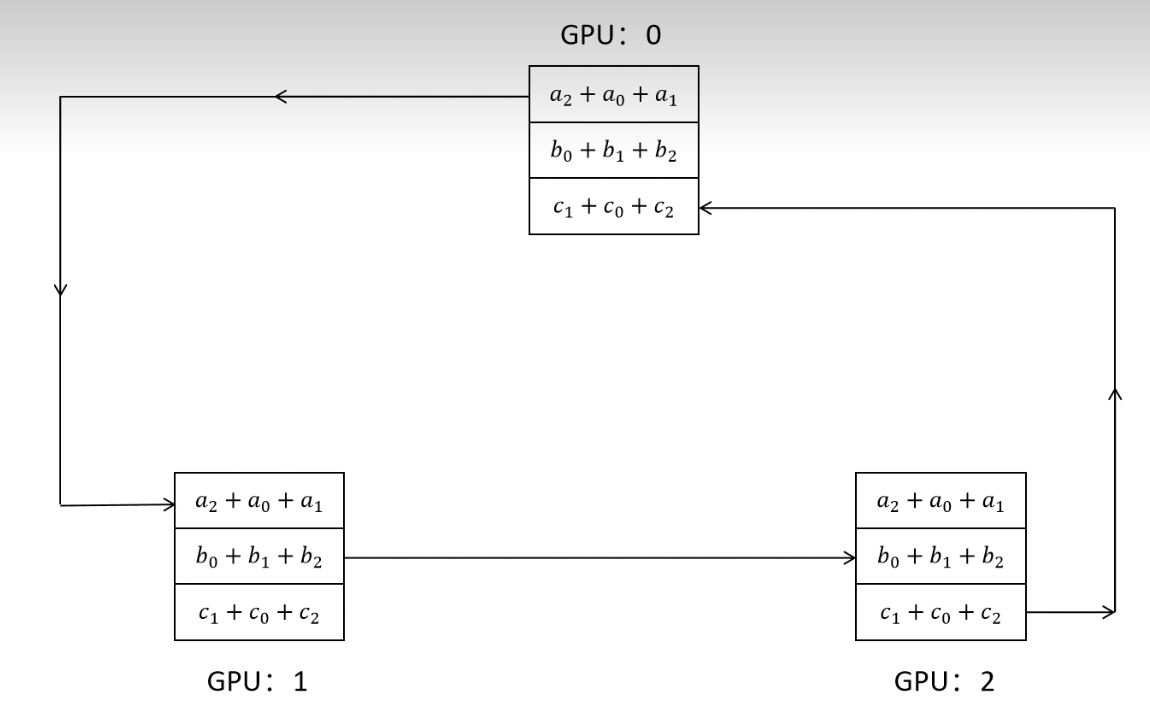
计算参数梯度的个数满一个'桶'的时候,就开始流水并行化更新同步。

(他会预先分配好,哪些参数该谁更新,这样就避免了一个参数连圈转的发送和接收(相当于原来是A给B给C给D,现在是,A,B,C直接给D了)
