Kubernetes 里看日志这件事,最常见的痛点不是"没工具",而是"工具太重、维护成本太高"。很多团队一开始用 EFK/ELK,索引能力强,但资源、运维复杂度和容量成本也跟着上来:集群一忙,日志平台先报警。
Loki 的思路更贴近运维日常:不做全文索引,只索引 标签(labels) ,日志原文压缩后存储。你用 LogQL 先按标签把范围缩小,再用 |= 之类的过滤在日志内容里做匹配。它换掉了一部分"随便搜"的自由度,换来更低的资源消耗和更容易长期跑稳。
这篇文章按我在生产里落地 Loki 的顺序来写:先把 Loki 用 Helm 在集群里跑起来,再把 Promtail 在不同场景(K8s 节点、虚拟机 nginx)接入,最后把 Grafana 查询和排障套路串起来。
1. 方案怎么选:Loki 到底省在哪
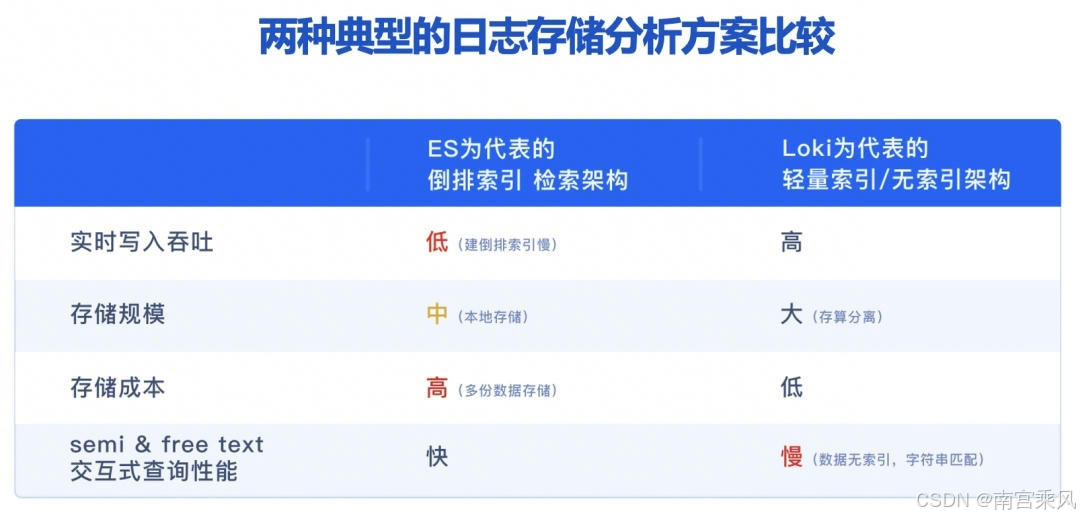
Loki 的核心取舍是:
- 索引只做标签 :比如
namespace、pod、app、host、job这类维度可控、基数不爆炸的字段 - 内容不建索引:日志行原文不进倒排索引,存储压力和索引构建开销都小很多
- 查询方式变了 :先用
{label="value"}缩范围,再用|=或|~过滤内容
经验上,Loki 适合这些场景:
- 你主要用"按服务/按命名空间/按主机"定位问题,然后在一个较小范围里搜索关键字
- 你更在意平台跑得稳、运维简单、成本可控
- 你愿意花点心思把标签体系设计好(这一步做对了,后面都省心)
不适合的场景也要提前说清楚:
- 你强依赖"任意字段全文检索"且日志结构化程度不高
- 你习惯把
trace_id、user_id、request_id这类高基数字段都当索引用
2. 组件与数据流:GLP(Grafana + Loki + Promtail)
整体链路很直白:
- Promtail 在节点/主机上"读日志文件"或"发现 Pod 日志路径"
- Promtail 把每一行日志打上标签,推送到 Loki
- Grafana 作为查询界面,通过 Loki API 拉取/查询日志
几个容易踩的点先放在这里:
- 标签基数(cardinality)决定生死:标签越"多且变化快",Loki stream 越多,内存和索引压力越大
- 路径与权限比配置更常出问题:Promtail 读不到文件、读到了但 positions 写不了、轮转后断档
- 网络连通性要优先验证:Promtail 推送是 HTTP,连不上就是"啥都没有"
3. 前置条件清单
以常见的"集群内 Loki + 节点/主机 Promtail"组合为例,部署前建议至少满足:
- Kubernetes 集群可用,kubectl/helm 可用
- 有合适的持久化存储(StorageClass),本地临时盘不建议长期存日志
- 能访问节点/Pod 日志目录(DaemonSet 通常需要 hostPath + 权限)
- 规划好暴露方式:NodePort / Ingress / 内网访问
- 如果用对象存储(S3/OSS/COS 等),Secret 先准备好(本文先按单机/本地 PV 讲)
4. Helm 单机模式部署 Loki(简单、够用、便于验证)
4.1 获取 Chart
bash
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
# 示例:拉取指定版本(按你环境固定版本,别"永远最新")
helm pull grafana/loki-stack --version 2.10.24.2 国内镜像与版本对齐
国内环境最常见的问题就是镜像拉不到。你的环境里如果已经有镜像加速或私有仓库,优先走统一镜像策略。
下面是一个"用国内镜像仓库替换"的示例(注意:Loki 与 Promtail 版本最好对齐同一大版本,避免奇怪的兼容问题):
bash
# 示例镜像(按你们实际仓库改)
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/grafana/loki:2.6.1
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/grafana/promtail:2.9.3我更推荐把这些写进 values.yaml,而不是堆一长串 --set。但如果你想快速验证,--set 也够用。
4.3 安装/升级
下面沿用"快速落地"的方式,启用持久化并用 NodePort 暴露 Loki:
bash
helm upgrade --install loki /root/loki-stack -n vke-system \
--set loki.image.repository=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/grafana/loki \
--set loki.service.type=NodePort \
--set loki.service.nodePort=31167 \
--set loki.persistence.enabled=true \
--set loki.persistence.storageClassName=nfs-csi \
--set loki.persistence.size=100Gi \
--set promtail.enabled=true落地经验:
- 单机模式适合先跑通链路、验证采集和查询;真正上生产要尽快做 存储后端、限流与保留策略 的规划
- NodePort 很方便,但别忘了 安全组/防火墙;Promtail 在别的网段推不上来时,Grafana 里就是"空"
5. Grafana 接入 Loki(把链路闭环)
Grafana 里接入 Loki,常见两种方式:
- 你自己已有 Grafana:在 Data sources 里新增 Loki
- Chart 里启用 Grafana:直接用内置 Grafana(适合验证,不建议长期当生产主 Grafana)
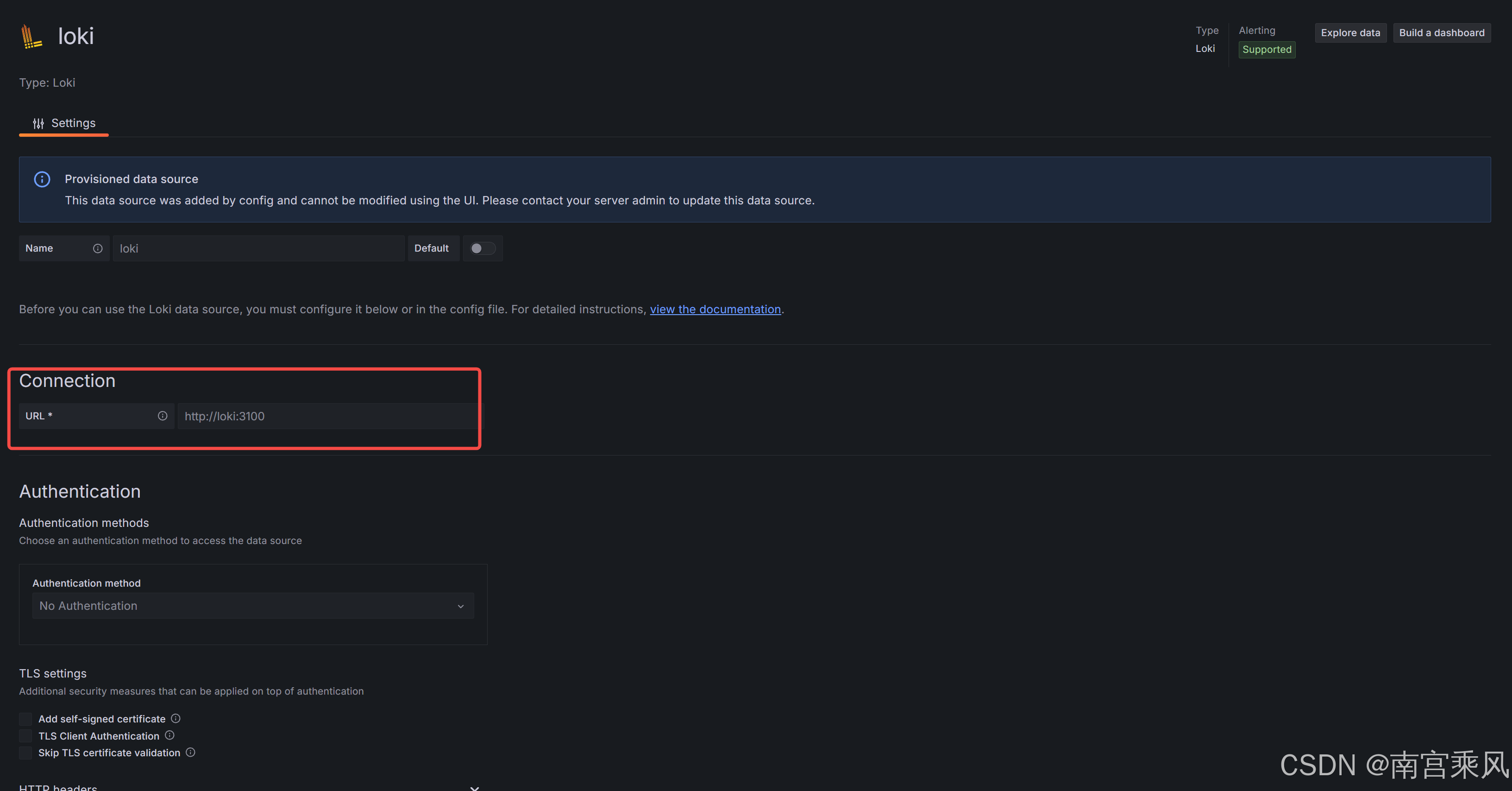
5.1 Data Source 配置要点
在 Grafana 里新增 Loki 数据源时,最常用的只需要:
- URL:
http://<loki-service>:3100或http://<node-ip>:<nodeport> - Save & Test 通过即可
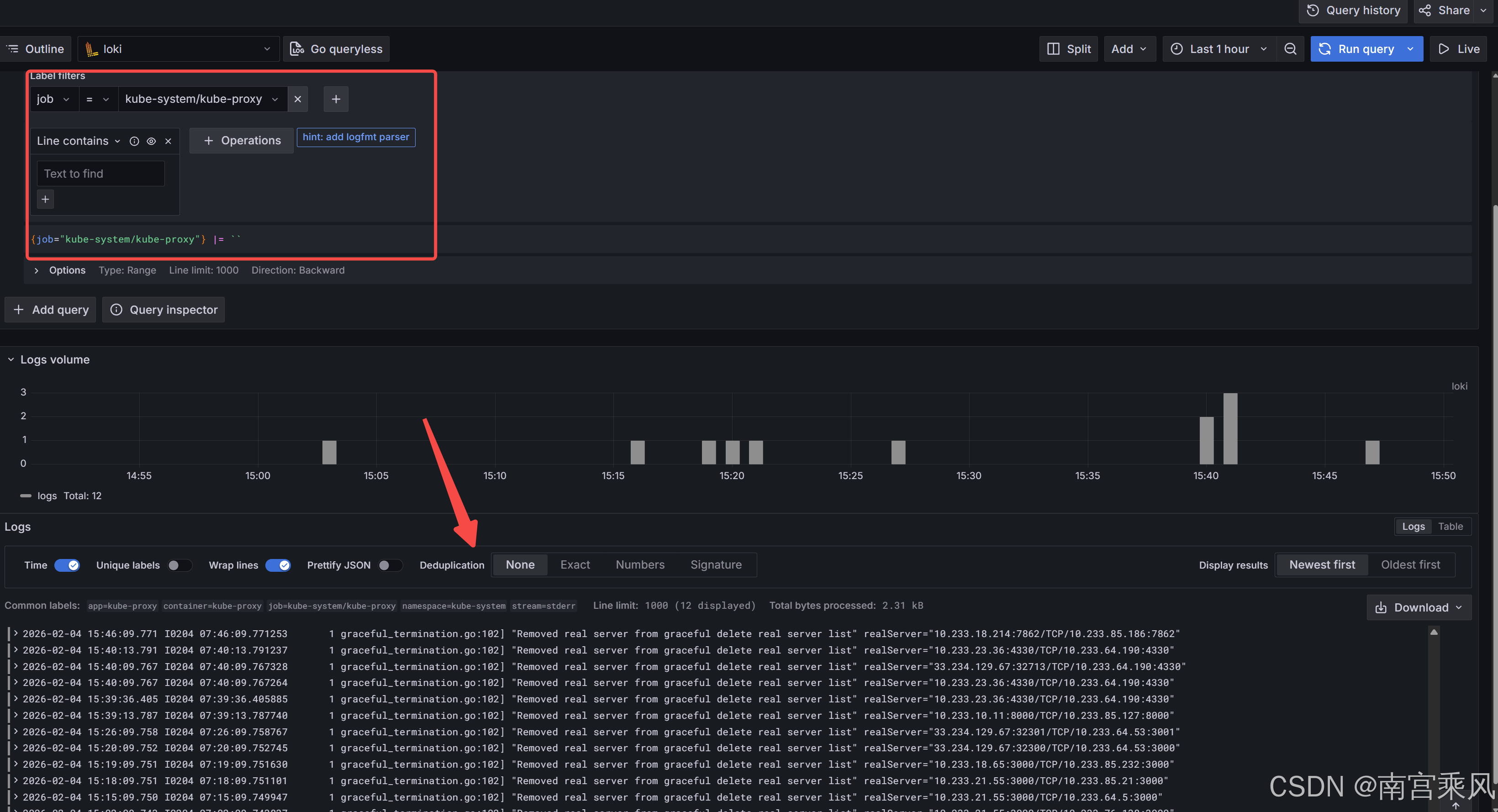
5.2 LogQL 查询习惯(先按标签,再筛内容)
几个我排障时常用的查询:
logql
{job="nginx"}
logql
{namespace="prod", app="api"} |= "error"
logql
{pod=~"api-.*"} |~ "timeout|context deadline exceeded"查询不出日志时,先别急着怀疑 Loki:
- 把时间范围拉大一点(Promtail 断过一段就很明显)
- 先用
{job="xxx"}这种最宽的条件看看有没有任何流 - 再逐步加标签与过滤条件
6. Promtail 部署:两类场景(K8s 节点与虚拟机)
Promtail 本质就是"读文件 + 打标签 + 推送"。部署形态主要两种:
- 集群里:DaemonSet(每个节点一个)
- 集群外:二进制/容器方式跑在虚拟机或物理机
6.1 虚拟机 nginx 采集:最小可用配置
下面这个配置和很多 nginx 场景一致:读 nginx 日志目录,打上 job/host 标签,推送到 Loki。
/etc/promtail-config.yaml 示例:
yaml
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://xxx.xxx.xxx.xxx:31167/loki/api/v1/push
scrape_configs:
- job_name: gateway-nginx
static_configs:
- targets:
- localhost
labels:
job: gateway-nginx
host: xxx.xxx.xxx.xxx
__path__: /vecps/nginx/common/nginx/logs/*.log启动方式(临时验证):
bash
nohup /bin/promtail-linux-amd64 -config.file=/etc/promtail-config.yaml 1>&2 > /var/log/promtail.log &生产里我通常会把它做成 systemd 服务,原因很现实:机器重启、进程被 OOM 杀掉、日志目录权限变化,这些都需要"自动拉起 + 有日志"。
创建专用用户(可选但推荐)
bash
sudo useradd --system --no-create-home --shell /sbin/nologin promtail
sudo chown promtail:promtail /var/log/promtail.log
sudo chmod 644 /etc/promtail-config.yaml编写服务
bash
sudo tee /etc/systemd/system/promtail.service << 'EOF'
[Unit]
Description=Promtail service for shipping logs to Loki
Documentation=https://grafana.com/docs/loki/latest/send-data/promtail/
After=network.target
[Service]
Type=simple
User=promtail
Group=promtail
ExecStart=/bin/promtail-linux-amd64 -config.file=/etc/promtail-config.yaml
Restart=on-failure
RestartSec=5
StandardOutput=append:/var/log/promtail.log
StandardError=append:/var/log/promtail.log
# 安全加固(可选)
NoNewPrivileges=true
ProtectSystem=strict
ProtectHome=true
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
bash
# 重载 systemd 配置
sudo systemctl daemon-reload
# 启动服务
sudo systemctl start promtail
# 设置开机自启
sudo systemctl enable promtail
# 查看状态
sudo systemctl status promtail这里也有几个常见坑:
positions.yaml写不了:目录没权限或磁盘满,会导致重启后重复采集或断档- 日志轮转后丢日志:
__path__写得太死、轮转策略不一致 - job/host 标签不统一:Grafana 查询时非常痛苦
6.2 K8s 采集:DaemonSet + Kubernetes 服务发现(推荐)
Kubernetes 环境下,Promtail 更推荐用 kubernetes_sd_configs 做服务发现,配合 relabel 把 namespace/pod/container/node 这些标签带上来。这样你在 Grafana 里按命名空间、按 Pod 查日志会顺手很多。
如果你要采集 容器 stdout/stderr,大部分 chart 默认就能跑通。
如果你要采集 容器内文件日志,要把"容器内路径"和"宿主机路径"打通(本质是 hostPath 共享目录),然后让 Promtail 知道该读哪个文件。
工作原理:
- 应用 Pod: 通过 hostPath 将宿主机上的一个目录挂载到容器内,应用将日志写入这个目录。同时,在该 Pod 的 metadata.annotations 中声明日志文件的路径。
- Promtail DaemonSet: 配置 kubernetes_sd_configs 来发现 Pod,并通过 relabel_configs 读取 Pod 的 annotation。如果 annotation 存在,就将其值作为 path ,告诉 Promtail 去宿主机的对应路径下抓取日志。
Promtail 配置示例 (relabel_configs):这个配置段的作用是:找到所有带有 loki.grafana.com/scrape: "true" 这个 annotation 的 Pod,并读取 loki.grafana.com/path 的值作为日志文件路径。
一个更好用的模式是用 annotation 控制哪些 Pod 需要采集文件日志:
编辑 Promtail ConfigMap,增加如下的配置
在Promtail 侧示例(重点是 __meta_kubernetes_pod_annotation_loki_io_logfile -> __path__):
yaml
server:
log_level: info
log_format: logfmt
http_listen_port: 3101
clients:
- url: http://loki:3100/loki/api/v1/push
positions:
filename: /run/promtail/positions.yaml
scrape_configs:
# See also https://github.com/grafana/loki/blob/master/production/ksonnet/promtail/scrape_config.libsonnet for reference
- job_name: kubernetes-pods
pipeline_stages:
- cri: {}
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_controller_name
regex: ([0-9a-z-.]+?)(-[0-9a-f]{8,10})?
action: replace
target_label: __tmp_controller_name
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_name
- __meta_kubernetes_pod_label_app
- __tmp_controller_name
- __meta_kubernetes_pod_name
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: app
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_instance
- __meta_kubernetes_pod_label_instance
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: instance
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_component
- __meta_kubernetes_pod_label_component
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: component
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node_name
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
replacement: $1
separator: /
source_labels:
- namespace
- app
target_label: job
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container
- action: replace
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_uid
- __meta_kubernetes_pod_container_name
target_label: __path__
- action: replace
regex: true/(.*)
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_annotationpresent_kubernetes_io_config_hash
- __meta_kubernetes_pod_annotation_kubernetes_io_config_hash
- __meta_kubernetes_pod_container_name
target_label: __path__
# === 新增:支持 loki.io/logfile 注解 ===
- source_labels: [__meta_kubernetes_pod_annotation_loki_io_logfile]
action: keep
regex: .+
- source_labels: [__meta_kubernetes_pod_annotation_loki_io_logfile]
target_label: __path__
# ===================================
limits_config:
tracing:
enabled: false应用 Pod 示例(用 annotation 指定宿主机上真实的日志文件路径):
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-log-test
annotations:
loki.io/logfile: '/mnt/log/busybox/*.log'
spec:
replicas: 2
selector:
matchLabels:
app: busybox-log
template:
metadata:
labels:
app: busybox-log
annotations:
loki.io/logfile: '/mnt/log/busybox/*.log'
spec:
volumes:
- name: log
hostPath:
path: /mnt/log/busybox
type: DirectoryOrCreate
containers:
- name: busybox
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:latest
command: ["/bin/sh"]
args: ["-c", "while true; do echo \"$(date): This is a log entry from busybox\" >> /var/log/busybox/busybox.log; sleep 5; done"]
volumeMounts:
- mountPath: /var/log/busybox
name: log
resources:
requests:
memory: "64Mi"
cpu: "50m"
limits:
memory: "128Mi"
cpu: "100m"这个模式我用下来最省心的点在于:
- 默认不采集文件日志,避免"全量把宿主机目录扫一遍"
- 哪些 Pod 需要采集、采集哪些文件,由应用自己声明,运维侧只管规则
7. 标签体系怎么定:别把 Loki 用成 ES
Loki 的体验好不好,80% 看标签体系。一个比较稳的经验组合是:
- K8s 相关:
cluster、namespace、app、pod、container、node - 机器相关:
job、host - 环境相关:
env(prod/staging/dev)
尽量别做这些事:
- 把
trace_id/request_id/user_id当标签(基数爆炸,stream 爆炸) - 把完整路径/URL 当标签(同样是基数炸弹)
- 标签命名不统一(同一个概念
host/node/instance混着来)
如果你确实要按 trace_id 查,建议把它当内容过滤:
logql
{namespace="prod", app="api"} |= "trace_id=abcd1234"8. 排障套路:从"链路"开始查
8.1 Promtail 推送失败
先在 Promtail 机器上确认 Loki 可达:
bash
curl -sS http://xxx.xxx.xxx.xxx:31167/ready再看 Promtail 自己的日志(你用 systemd 就 journalctl -u promtail -f,用 nohup 就看文件)。
常见原因:
- URL 写错、NodePort 不通、安全组没放行
- Loki 端限流或拒绝(通常能在 Loki 日志里看到)
- 证书/代理配置导致请求出不去
8.2 Grafana 里"查不到日志"
按这个顺序走,基本不会绕圈:
- 用最宽条件
{job="xxx"}或{namespace="xxx"}看有没有任何流 - 把时间范围拉到"最近 6h/24h"
- 再慢慢加过滤条件,定位是"没采到"还是"过滤太严"
8.3 Loki 内存突然涨、查询变慢
这通常不是"机器小",而是标签基数失控:
- 最近是不是加了新的标签(尤其是从日志内容里提取出来的)
pod是否频繁变化(短生命周期任务很多)- 有没有把 URL、path、request_id 这种东西做成标签
解决思路就是"收敛标签维度",并给 Loki 设置合理的 limits。