在 PyTorch 中,DataLoader 是训练流程中不可或缺的一环,它负责将数据集批量化并加载到模型中。在训练大型模型或处理图像、视频等大数据量任务时,数据加载速度往往会成为瓶颈。
num_workers 参数控制 DataLoader 使用的子进程数量,是优化数据加载性能的关键配置。本文将详细解析 num_workers 的取值意义、对训练性能的影响,以及在 Docker 环境下常见问题和解决方案。
1. num_workers 参数说明
决定了 DataLoader 在加载数据时使用的进程数:
| 值 | 说明 |
|---|---|
| 0 | 数据在主进程中加载(单线程) |
| >0 | 使用指定数量的子进程并行加载数据 |
⚠️ 注意:
num_workers=0时,数据加载简单可靠,但可能成为 GPU 的瓶颈;而num_workers>0可以加速数据加载,但可能占用大量内存。
2. 不同取值的影响
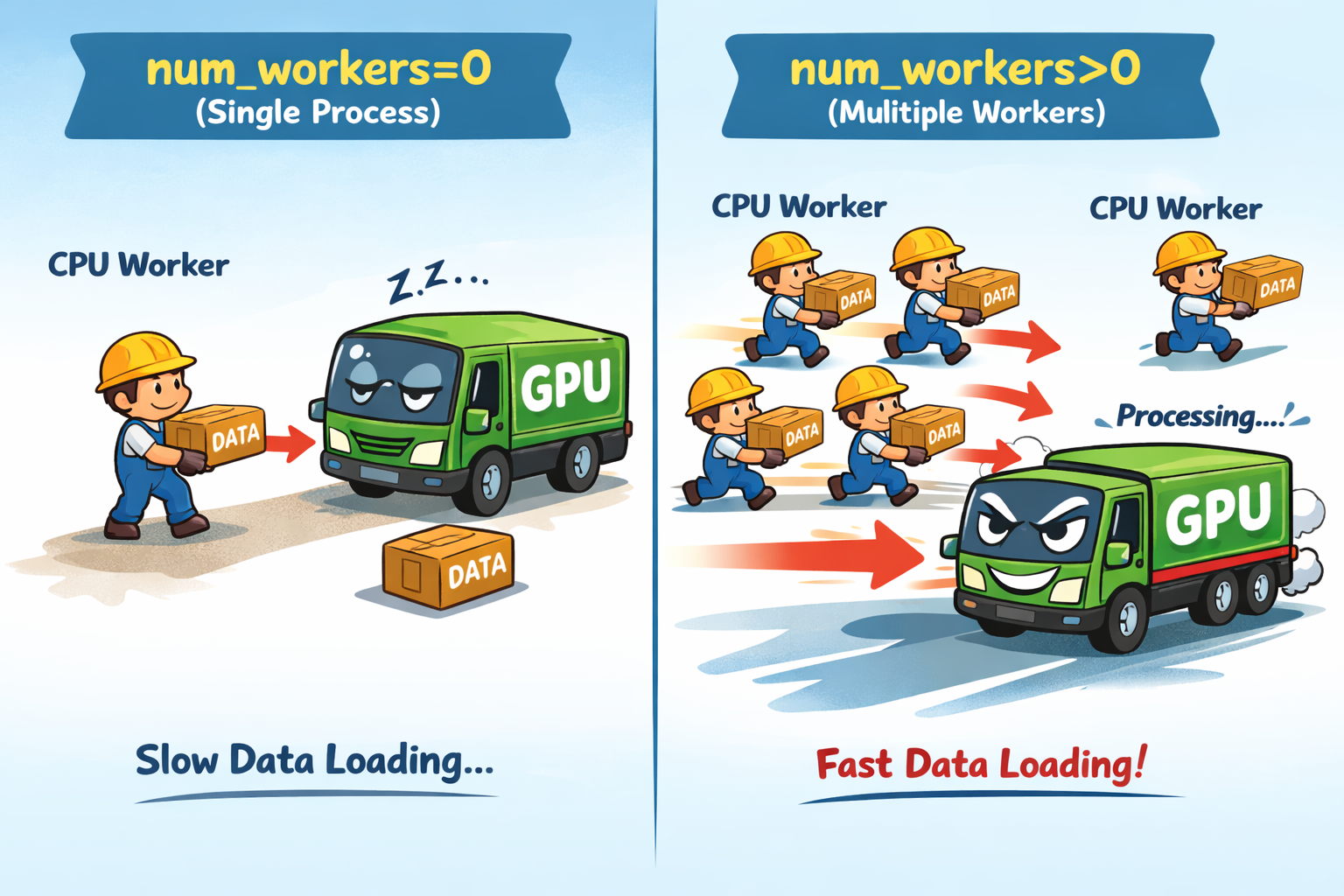
(1) num_workers=0
-
优点:无需额外内存,兼容性好,调试方便
-
缺点:数据加载速度慢,GPU 可能需要等待数据,对大数据集训练效率低
python
train_loader = DataLoader(dataset, batch_size=64, num_workers=0)(2) num_workers>0(如 4、8)
-
优点:并行加载数据,提高训练速度,减少 GPU 等待时间
-
缺点:占用更多内存和共享内存,可能导致内存问题
pythontrain_loader = DataLoader(dataset, batch_size=64, num_workers=4, pin_memory=True)
💡 Tip:结合 pin_memory=True 可以加速 GPU 数据传输,但需要系统内存充足。
3. 常见问题:共享内存不足错误
在 Docker 中使用 num_workers>0 时,可能出现如下错误:
python
RuntimeError: DataLoader worker (pid xxx) is killed by signal: Bus error.
It is possible that dataloader's workers are out of shared memory.
Please try to raise your shared memory limit. 原因:Docker 容器默认共享内存(/dev/shm)只有 64MB,多个 worker 进程需要使用共享内存进行数据传输,内存不足时会导致 Bus error。
4. 解决方案
方案一:增加 Docker 共享内存(推荐)
在 docker-compose.yml 中添加 shm_size 配置:
yaml
services:
your_service:
image: your_image
shm_size: 2g # 设置共享内存为 2GB
# ... 其他配置 或使用 docker run 命令时添加参数:
bash
docker run --shm-size=2g your_image-
运行后可以在容器中执行:
df -h /dev/shm验证 shm_size 配置是否生效。
bashFilesystem Size Used Avail Use% Mounted on shm 2.0G 0 2.0G 0% /dev/shm
方案二:减少 num_workers
当内存有限时,将 num_workers 调小或设为 0:
python
# 完全禁用多进程加载
DataLoader(dataset, batch_size=64, num_workers=0)
# 或使用较少的 worker
DataLoader(dataset, batch_size=64, num_workers=2)方案三:使用 pin_memory 优化
在 CPU 内存充足时,结合 pin_memory=True 可以提高 GPU 数据传输速度:
python
DataLoader(dataset, batch_size=64, num_workers=4, pin_memory=True)5. 推荐配置指南
| 环境 | num_workers | 备注 |
|---|---|---|
| Docker(默认 shm) | 0 | 避免共享内存不足问题 |
| Docker + shm_size=2g | 4-8 | 可根据 CPU 核心数调整 |
| 本地机器 | CPU 核心数 | 一般设置 4-8 |
| 调试阶段 | 0 | 方便排查问题 |
小技巧:在训练前用小批量数据跑一个 DataLoader 测试,观察 CPU、GPU 和内存占用,找到最适合的 num_workers 配置。
6. 总结
num_workers 对训练性能影响巨大:
- 0:安全、易调试,但速度慢
- >0:可加速数据加载,但需注意内存与 Docker 共享内存限制
在 Docker 中使用多进程 DataLoader 时,优先考虑增加 shm_size ,或降低 num_workers,结合 pin_memory 可以进一步优化 GPU 数据传输效率。