之前有群友问h5st,最近抽出时间来浅浅分析了一下。京东的h5st也是老朋友了,不管是不是搞电商业务的,肯定都多多少少有些了解,而且关于h5st的补环境文章很多,小破站上也有相关视频,这里我就不浪费时间了,咱们今天只分析算法。开干!

申明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!若有侵权,请添加(wx:ShawYbo)联系删除
目标网站
网站:
aHR0cHM6Ly9zZWFyY2guamQuY29tL1NlYXJjaD9rZXl3b3JkPeaJi+acug==
目标:
h5st
分析过程
随便搜索一个商品,查看请求,跟栈,先找到h5st的生成入口位置。
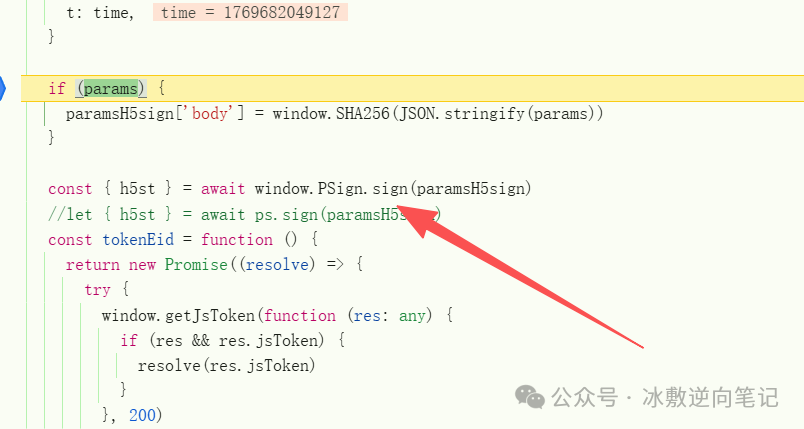

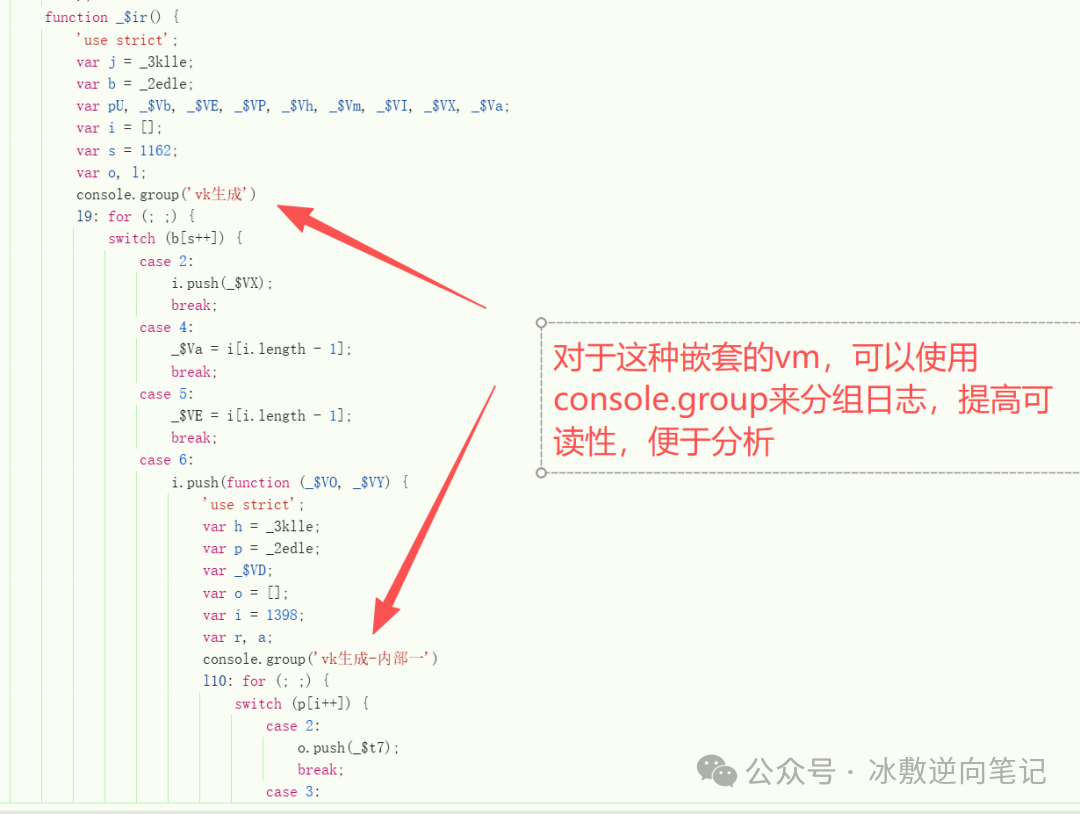
可以看到参数是通过js_security_v3_0.1.6.js 生成。粗看一边这个js,发现这个vm是通过for 循环加switch-case 控制,这种结构也很常见,比如阿里滑块,我们要做的依旧是找函数调用 和属性访问。与之前遇到的此种类型结构不同点是,js文件中有大量的函数是这种结构(for+switch),也就是说,每个函数都是一个小vm,而且对于函数调用来说,不同参数量的调用都有与之对应的case,这极大的增加了我们插桩的工作量,但是,我们依旧可以借助ai来帮我们插桩。
PS:直接告诉cursor对xx函数的所有call调用进行插桩即可。
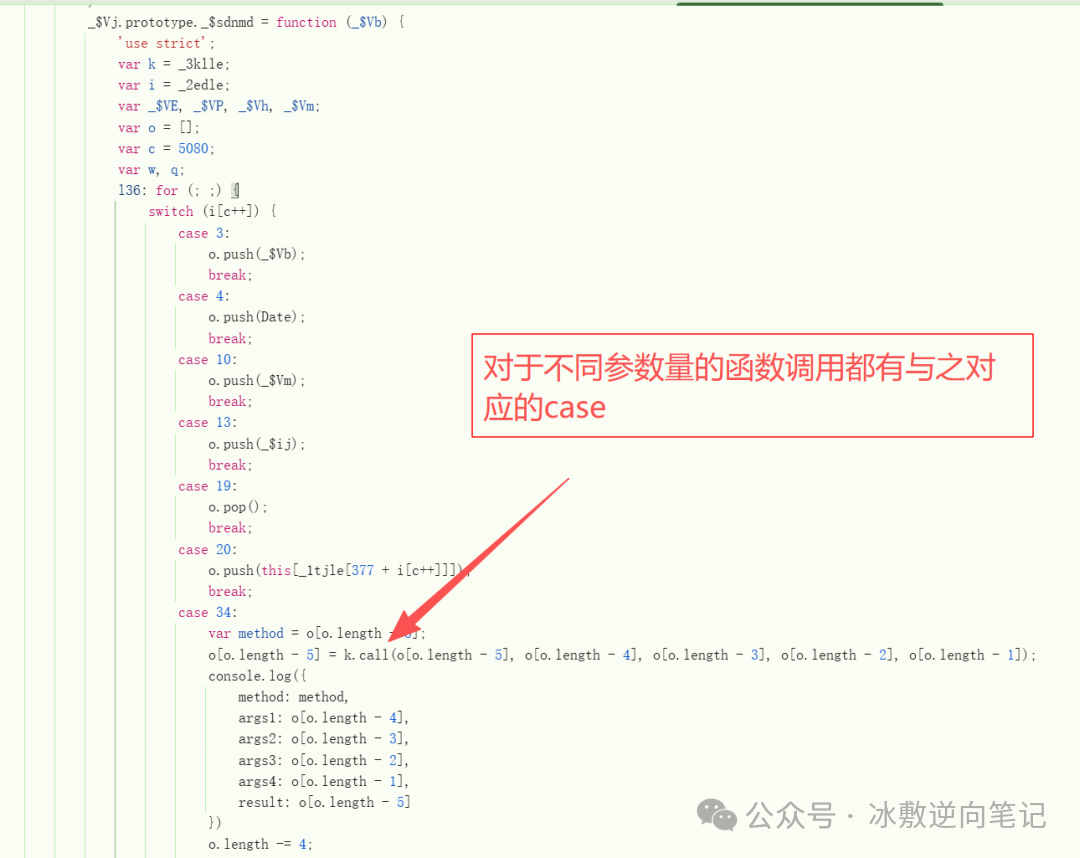
先来看一下h5st的构成。h5st由多个部分组成,且每个部分参数固定。
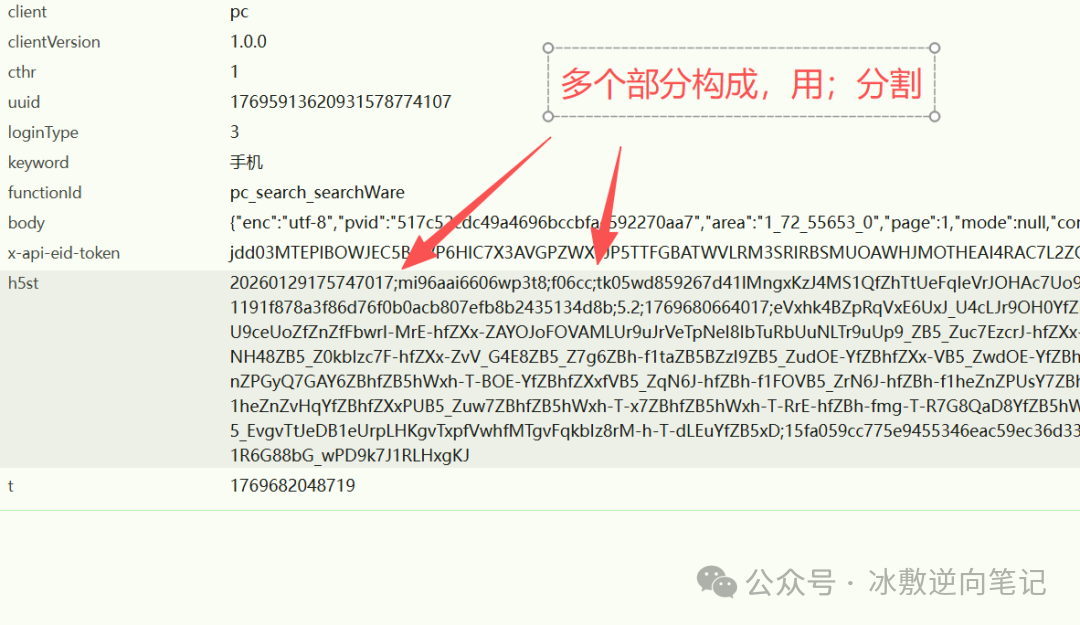
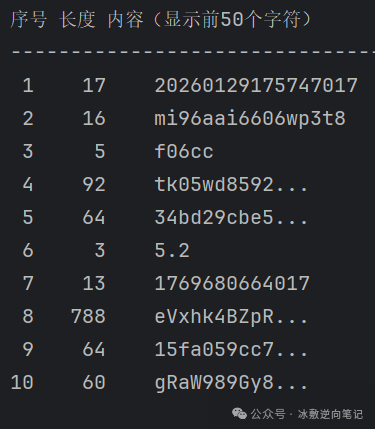
这里就不卖关子了,按照序号,我先依次说明一下各个参数作用,然后再分析是如何生成的。
-
20260129175747017:其实就是Date.now(),转换为yyyyMMddhhmmssSSS格式就行。
-
mi96aai6606wp3t8:一个根据固定字符串而生成的随机字符串。
-
f06cc:appid
-
tk05wd8592 ...:defaultToken,首次访问时,由mi96aai6606wp3t8等一系列参数生成。
-
34bd29cbe5...: 参数签名。
-
5.2:版本号。
-
1769680664017:这就是序号1参数的时间戳(20260129175747017)。
-
eVxhk4BZpR...:环境校验结果,这是重中之重。
-
15fa059cc7...:字符串'appid,body,client,.....'的签名。
-
gRaW989Gy8...:字符串'appid,body,client,.....'的自定义编码。
先看一下mi96aai6606wp3t8。mi96aai6606wp3t8被存储在浏览器的localStorage中,key为WQ_dy1_vk(WQ_dy1这个前缀会变),我们可以拿来直接用,但我这里是分析他的生成过程,所以我们需要删掉他,并且hook一下这个值的set,就可以找到具体的生成函数。
从日志中分析,可以得知一些逻辑。vk生成的第一部是获取一个4位的字符串,该字符串来源于一个固定字符串:t6d0jhqw3p。这像是一种伪随机筛选,通过 Math.random()和阈值比较(4)控制字符选择,小于4的被选中,最后按照特定的索引顺序(3,0,2,1)重新排列。
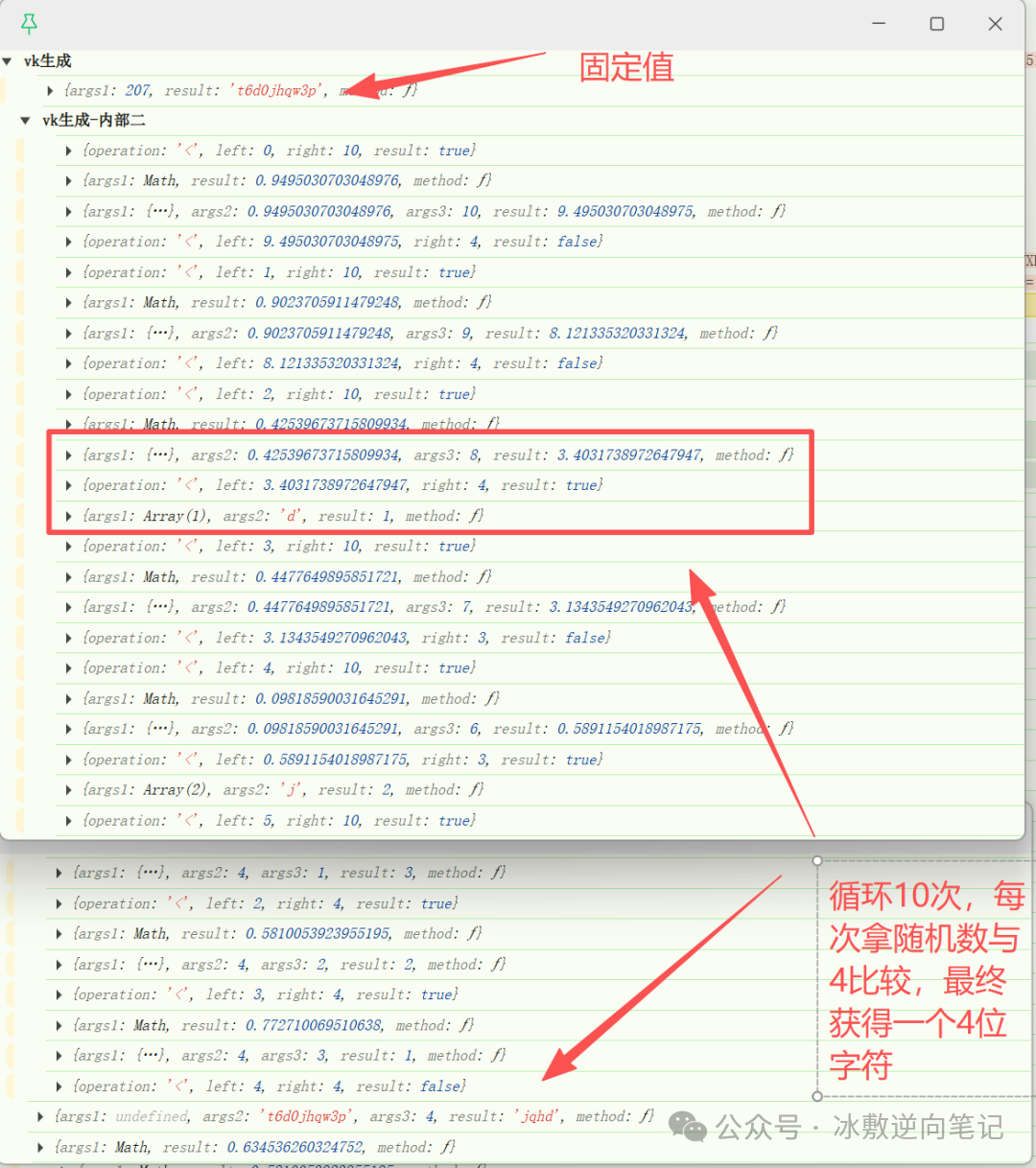
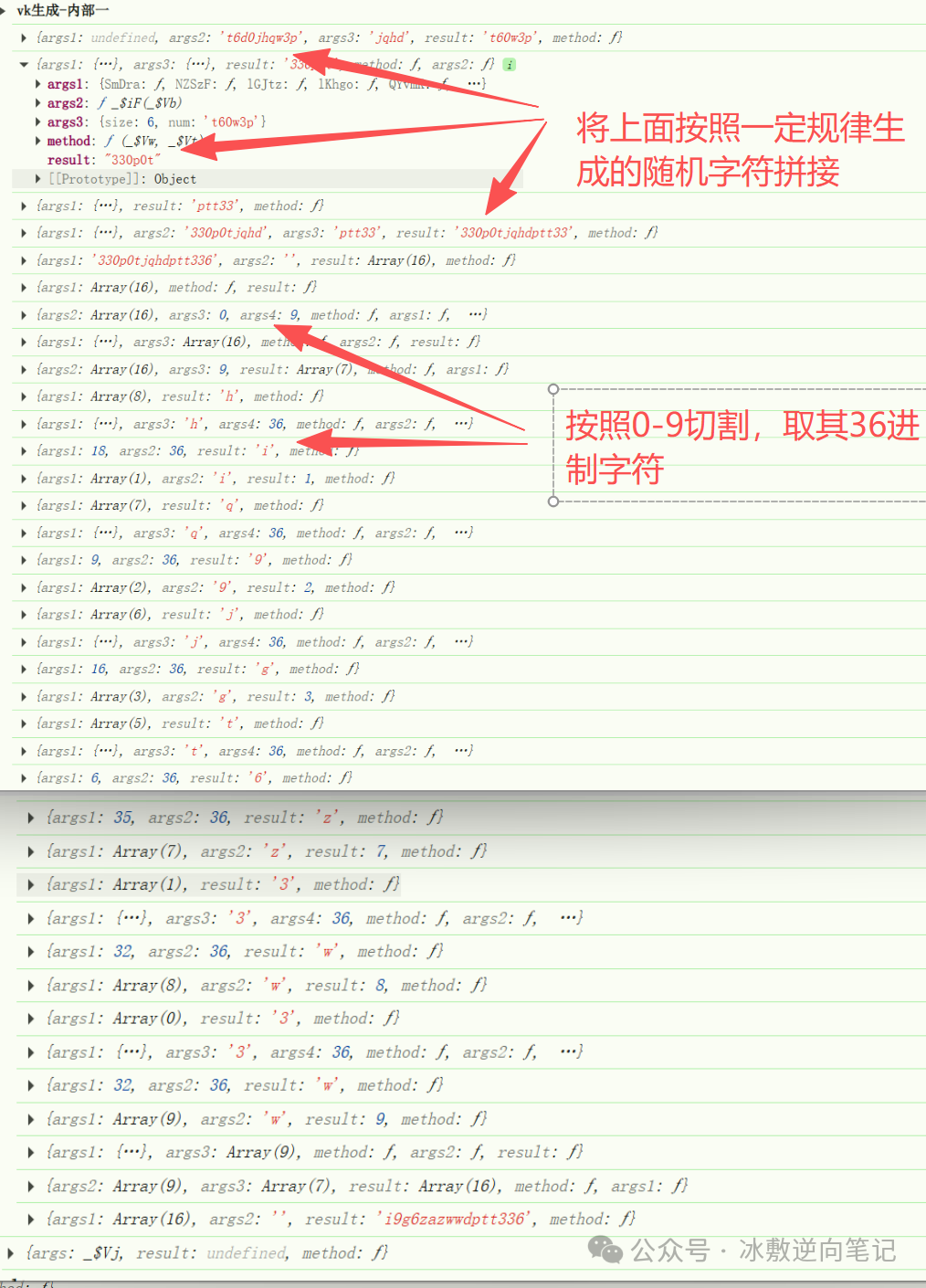
然后从原字符串中移除这些字符,从剩余字符集中随机生成 4 个和 7 个字符片段,将三者拼接后追加固定字符 "4",最后将前 9 个字符反转并按 36 进制补码规则(35-原值)进行字符映射转换,与后 7 个字符拼接得到最终结果。
python
def t6d0jhqw3p_to_result():
original = "t6d0jhqw3p"
selected_chars = []
remain_to_select = 4
for i, char in enumerate(original):
if remain_to_select == 0:
break
r = random.random() # 随机数决定是否选择
threshold = r * (len(original) - i)
if threshold < remain_to_select:
selected_chars.append(char)
remain_to_select -= 1
for i in range(len(selected_chars) - 1, 0, -1):
r_idx = random.random()
j = math.floor(r_idx * (i + 1))
selected_chars[i], selected_chars[j] = selected_chars[j], selected_chars[i]
q3hj = ''.join(selected_chars)[::-1]
temp_str = original
for char in q3hj:
temp_str = temp_str.replace(char, "", 1)
param = {
"size": 4,
"num": temp_str
}
part_060t = generate_random_string(param)
param = {
"size": 7,
"num": temp_str
}
part_3 = generate_random_string(param)
part_dwdpw0p = part_060t + q3hj + part_3
intermediate = part_dwdpw0p + "4"
char_to_num = {
'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5,
'6': 6, '7': 7, '8': 8, '9': 9, 'a': 10, 'b': 11,
'c': 12, 'd': 13, 'e': 14, 'f': 15, 'g': 16, 'h': 17,
'i': 18, 'j': 19, 'k': 20, 'l': 21, 'm': 22, 'n': 23,
'o': 24, 'p': 25, 'q': 26, 'r': 27, 's': 28, 't': 29,
'u': 30, 'v': 31, 'w': 32, 'x': 33, 'y': 34, 'z': 35
}
# 前9个字符
front_part = intermediate[:9]
back_part = intermediate[9:] # 后7个字符保持不变
# 转换前9个字符
converted_front = []
num_to_char = {v: k for k, v in char_to_num.items()}
reversed_front_part = front_part[::-1]
for char in reversed_front_part:
num = char_to_num.get(char, 0)
converted_front.append(num_to_char[(35-num)])
# 合并结果
result = ''.join(converted_front) + back_part
return result以上就是vk的生成逻辑,按照这个思路,我们继续分析eVxhk4BZpR环境校验结果,探究一下他是如何检验环境和加密的。
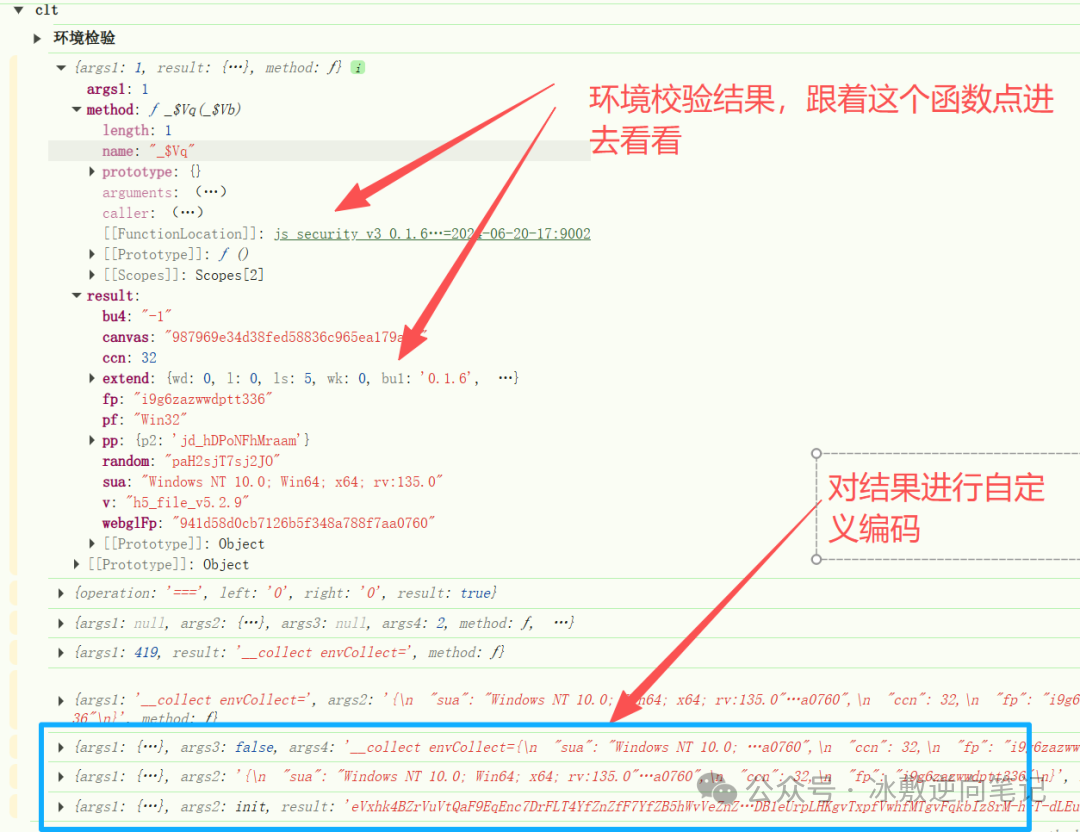
查看日志或者直接搜索clt。
python
{
"sua":"Windows NT 6.1; Win64; x64; rv:136.0",
"pp":{
"p2":"jd_7489ced5d8940"
},
"extend":{
"wd":0,
"l":0,
"ls":5,
"wk":0,
"bu1":"0.1.6",
"bu3":52,
"bu4":0,
"bu5":0,
"bu6":17,
"bu7":0,
"bu8":0,
"random":"3012d4o9jMQH",
"bu12":-8,
"bu10":14,
"bu11":2
},
"pf":"Win32",
"random":"Egn20XhHC47",
"v":"h5_file_v5.2.7",
"bu4":"0",
"canvas":"987969e34d38fed58836c965ea179a2a",
"webglFp":"941d58d0cb7126b5f348a788f7aa0760",
"ccn":32,
"fp":"igtz6wzwwqdw3tp7"
}先来解释一下各个参数含义:
sua就不说了;pp为账号名称;extend这是环境校验结果,稍后插桩分析各个值的含义;pf、random、v、canvas、webglFp、ccn这些都是见名知意,除了random(11为位随机字符)写死即可。fp可不是fingerprint,fp就是咱们上一步的vk,这里有点混淆视听。
关于extend的生成,因为京东的更新频率也很高,js会经常变化,所以很难用关键词搜索,这一块需要根据clt的日志,先进入环境校验的父函数,然后debug再找到具体的extend生成函数。
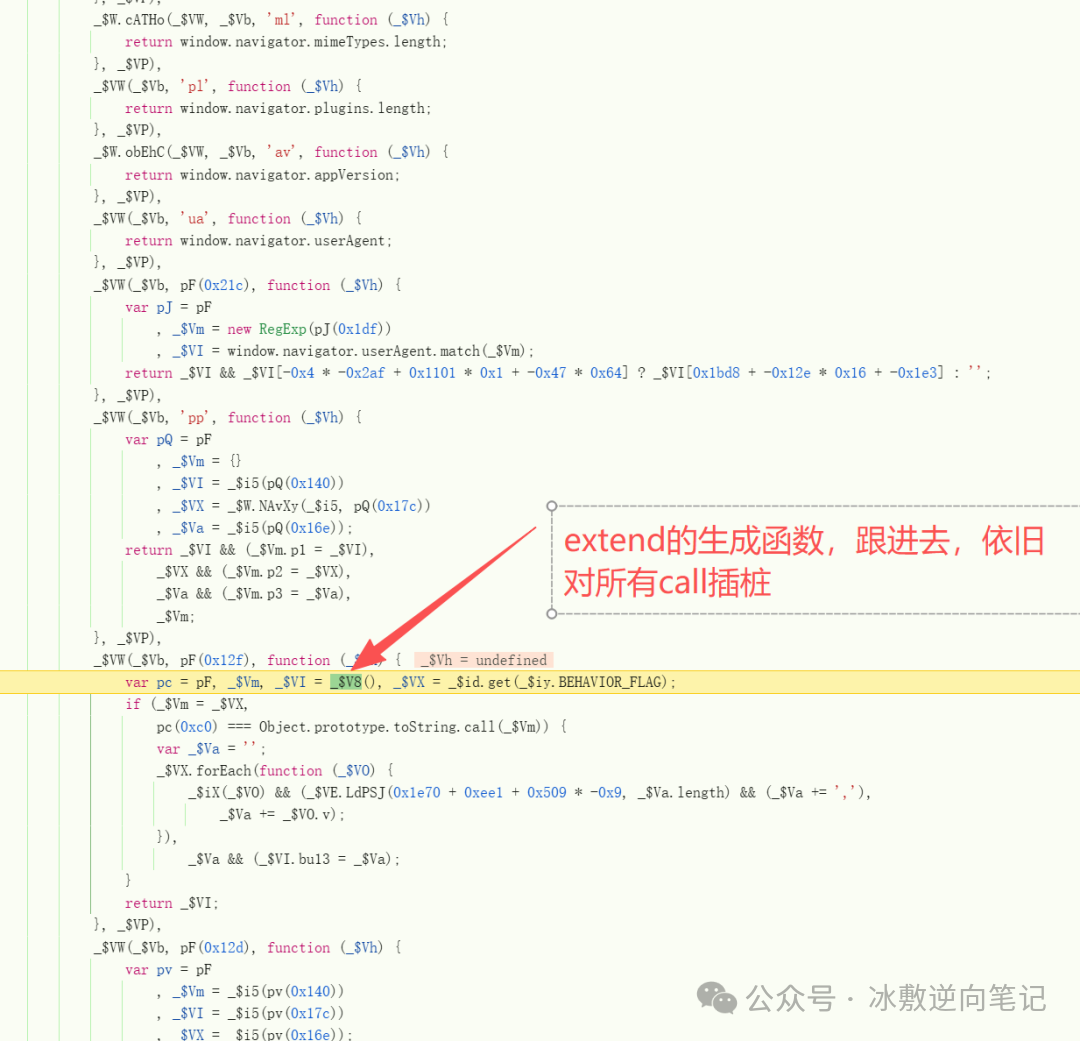
extend的检测点还是很多的。
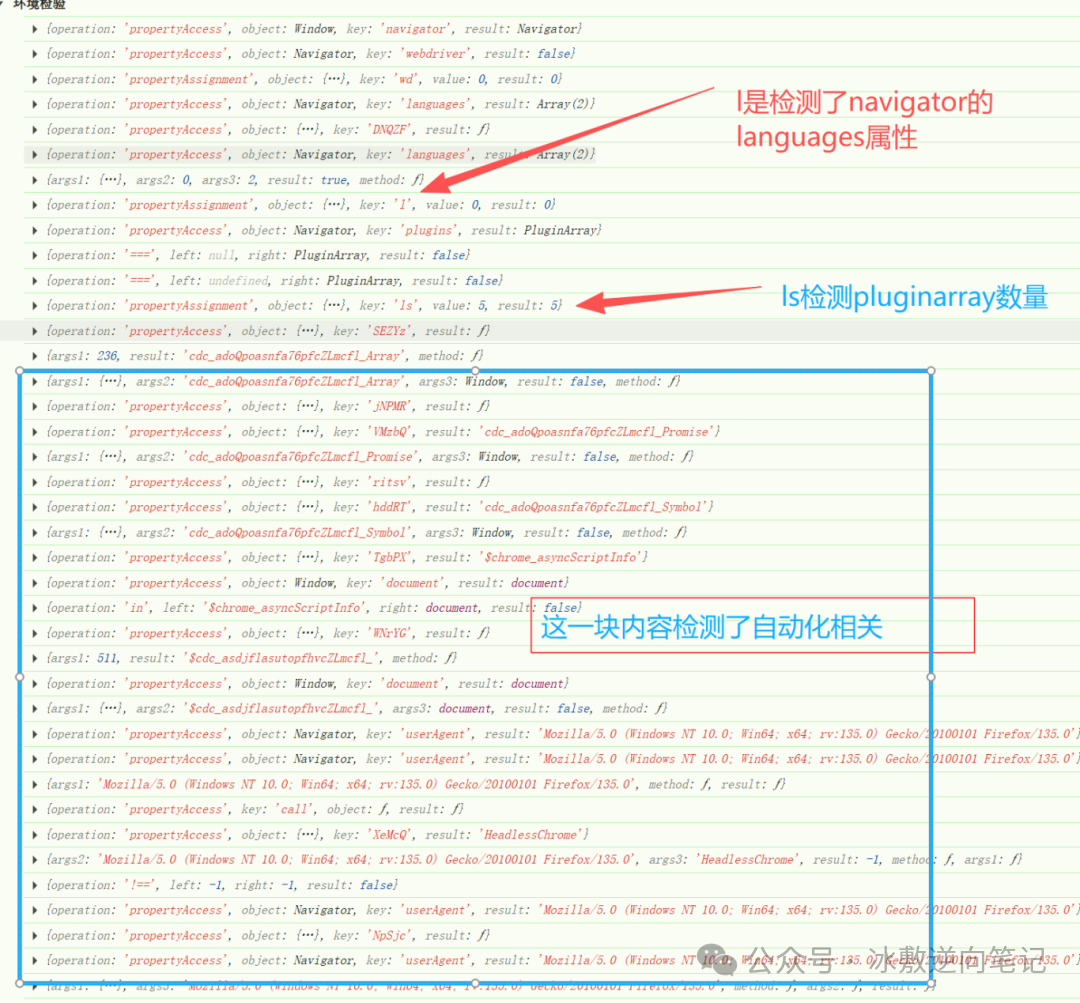
自动化工具检测类:
-
wd:检测是否存在WebDriver属性,用于识别自动化浏览器。
-
wk:检测User-Agent中是否包含headlessChrome,或是否为Selenium、PhantomJS、TestCafe等自动化工具运行环境。
-
bu5:通过调用堆栈信息判断是否包含playwright、node等关键字,用于识别自动化框架。
浏览器环境特征检测:
-
l:Navigator.languages,浏览器语言设置数组,检测语言偏好配置。
-
ls:Navigator.pluginArray.length,检测已安装的插件数量。
-
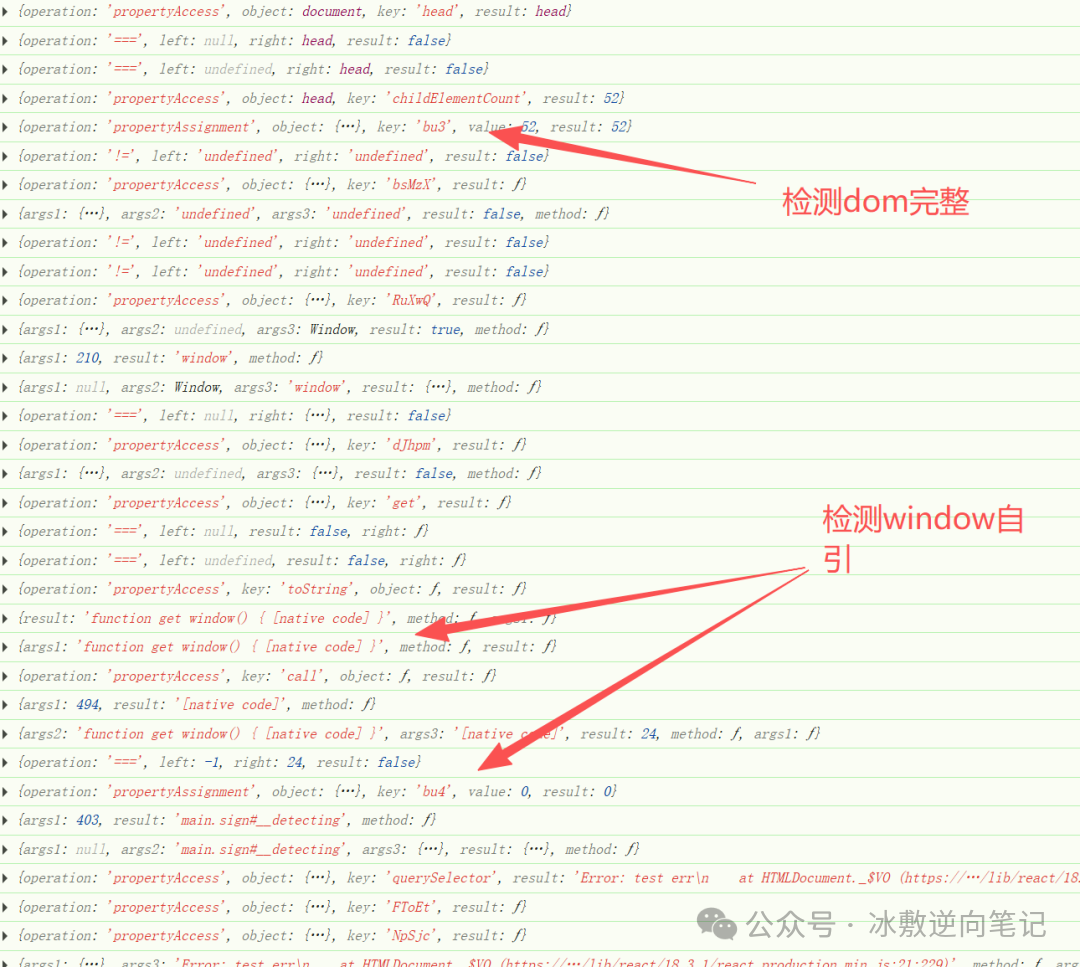
bu3:document.head.childElementCount,head元素的子元素数量,检测页面头部结构。
-
bu6:document.body.childElementCount,body元素的子元素数量,检测页面主体结构.
-
bu8:HTMLAllCollection,验证DOM完整性。
环境完整性检测:
- bu4:window.window === window,检测window对象的自引用完整性。主要针对node补环境。
函数保护检测:
- bu7:使用正则表达式判断函数的toString()方法,检测函数保护function toString(){native code}是否被篡改。
固定值:
-
bu1:固定值0.1.6,可以理解为检测版本号。
-
bu10:14。
-
bu11:2。
-
bu12:时区,偏移值-8,表示UTC+8(中国时区)。
ok,至此,关于环境校验的各个字段我们都已弄清他的含义,接下来就是要对其自定义编码。查找他的编码逻辑。
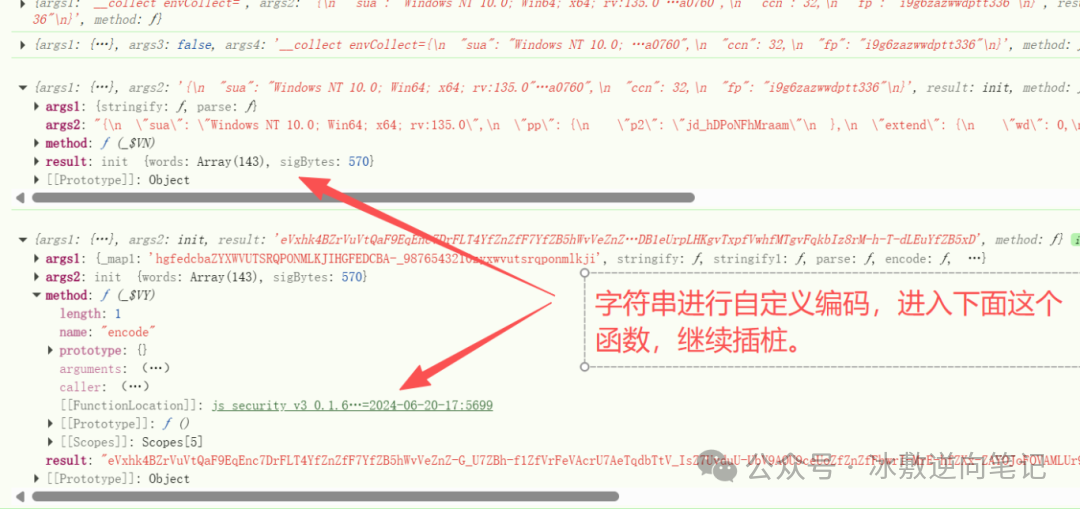
这一块逻辑分析起来确实耗时,日志粒度细一点,虽然日志很长,但大多是循环结果,所以分析循环内的一到两组日志便可推理出结果。整体逻辑就是采用base64自定义编码集,然后又进行了一系列的反转重组操作:
-
第一步:字节数组填充:将输入字符串转换为Uint8Array,按3的倍数填充(填充值为填充数量,若已为3的倍数则填充3个3),确保长度是3的倍数。
-
第二步:字节重排序:将字节数组按每3个字节为一组,从后往前倒序处理,每组内按 i-2, i-1, i 的顺序重新排列,打乱原始字节顺序。
-
第三步:自定义Base64编码:使用自定义字符集 'hgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA-_9876543210zyxwvutsrqponmlkji'(共64个字符,顺序与标准Base64不同),将重排序后的每3个字节组合成24位整数,按6位分段得到4个索引,映射到自定义字符集;对于不足3字节的组,用'='填充。
-
第四步:结果重组,将编码结果按每4个字符为一组,从后往前切片,每组内部字符反转,然后整体反转并拼接,形成最终编码字符串。
python
function encodeToCustomBase64(str) {
const chars = 'hgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA-_9876543210zyxwvutsrqponmlkji';
// 1. 将字符串转换为Uint8Array并进行填充
const bytes = new Uint8Array(str.length + (3 - str.length % 3) % 3);
for (let i = 0; i < str.length; i++) bytes[i] = str.charCodeAt(i) & 0xFF;
const fillCount = bytes.length - str.length || 3;
bytes.fill(fillCount, str.length);
// 2. 字节数组重新排序
const reordered = [];
for (let i = bytes.length - 1; i >= 0; i -= 3) {
reordered.push(bytes[i - 2], bytes[i - 1], bytes[i]);
}
// 3. 自定义Base64编码
let result = '';
for (let i = 0; i < reordered.length; i += 3) {
const triple = (reordered[i] << 16) | ((reordered[i + 1] || 0) << 8) | (reordered[i + 2] || 0);
result += chars[(triple >> 18) & 0x3F] +
chars[(triple >> 12) & 0x3F] +
(i + 1 < reordered.length ? chars[(triple >> 6) & 0x3F] : '=') +
(i + 2 < reordered.length ? chars[triple & 0x3F] : '=');
}
// 4. 最终字符串重组
return Array.from(
{ length: Math.ceil(result.length / 4) },
(_, i) => result
.slice(Math.max(0, result.length - (i + 1) * 4), result.length - i * 4)
.split('')
.reverse()
.join('')
)
.reverse()
.join('');
}

至此,关于环境校验这一块就算分析完了,剩下的其他参数,由于篇幅原因,且分析思路都大同小异,这里就不展开讨论了。
PS:
-
如果有补环境的,其实可以在本地运行,将所有日志保存至文件,然后交给ai,只需要日志打印粒度细一点即可,ai几乎能把整个生成逻辑的95%都挖掘出来,剩下的就是慢慢调试就好了。
-
京东的风控还是很严的,调试过程中,有概率会喜提七天封号套餐,望知悉。
总结
h5st还是有点点强度的,算是个中等级别的vmp。这个强度主要来源于他把各个功能都独立拆解为小的vm,而不是像其他vm一样,将所有操作码和操作数放入字节码中,这大大增加了我们插桩的工作量(这难道不就是人家反爬的意义?)。而且所有的算法,包括我们文章没有讲到的几个sign值的生成,用的全是自定义算法,并非标准的编码或者hash算法,所以这一块也比较考验日志分析的认真程度了。
了解最新逆向文章,可添加宫中号:冰敷逆向笔记