文章目录
- 一、简介
-
- [1 简单介绍](#1 简单介绍)
- [2 模型介绍](#2 模型介绍)
- 二、模型结构介绍
- 三、性能指标分析
- 四、推理部署
-
- [0 安装](#0 安装)
- [1 使用本地文件推理](#1 使用本地文件推理)
- [2 流式推理](#2 流式推理)
- [3 Gradio可视化UI界面](#3 Gradio可视化UI界面)
- 六、总结
一、简介
1 简单介绍
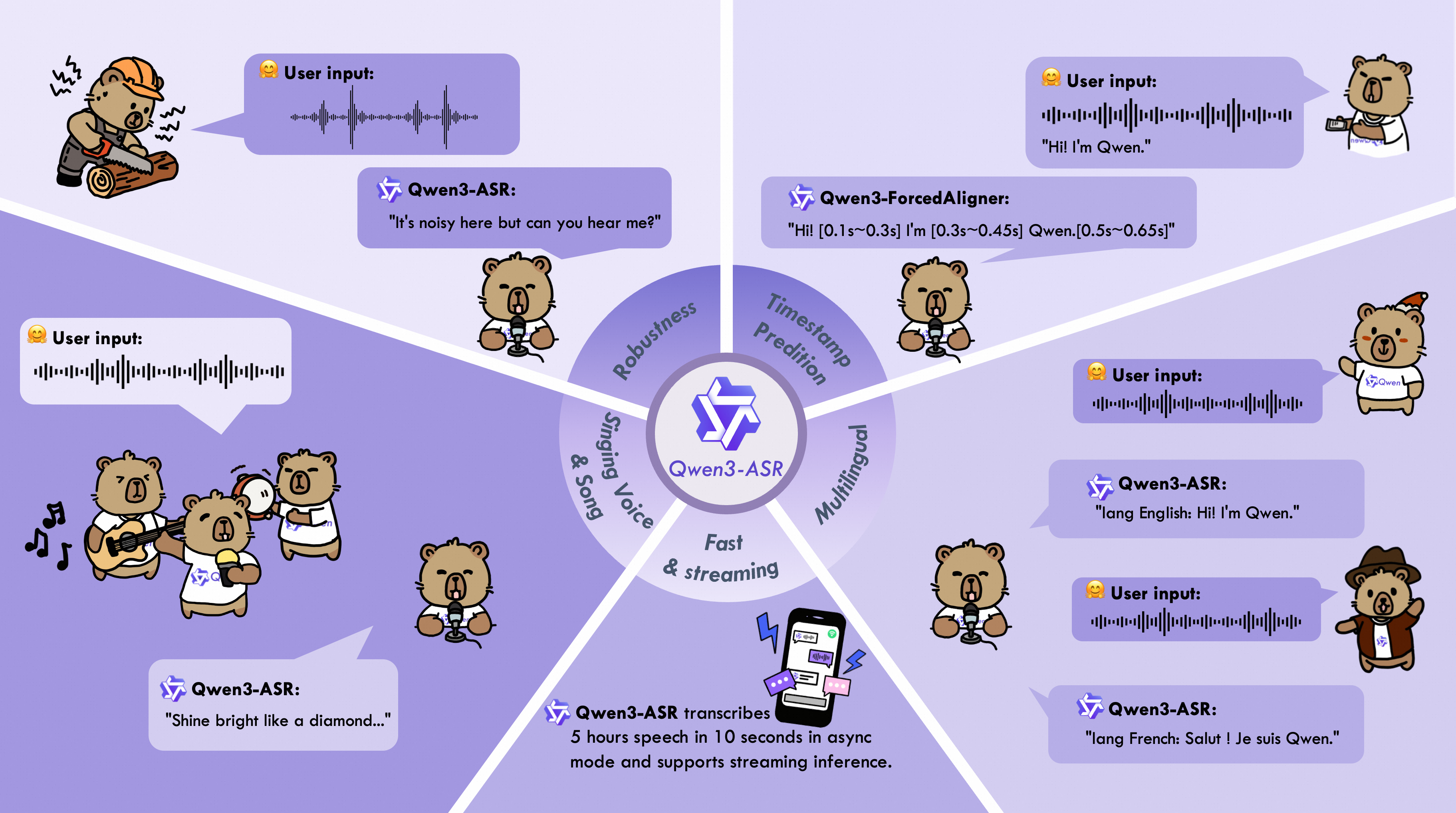
这张图通过生动的卡通形象和具体的使用场景,清晰地展示了Qwen3-ASR模型的六大核心优势:
- 鲁棒性:在嘈杂环境中表现优异
- 时间戳预测:能精确定位语音
- 多语言:支持多种语言的识别和区分
- 歌声与歌曲识别:能识别音乐和歌唱
- 快速与流式处理:高效且支持实时识别
总之,这张图是一个非常成功的视觉化宣传材料,它将一个复杂的AI技术(语音识别)用简单易懂的方式呈现出来,突出了其在各种真实世界挑战场景下的强大性能。
2 模型介绍
Qwen3-ASR系列包括Qwen3-ASR-1.7B和Qwen3-ASR-0.6B,支持52中语言和方言的语言识别和语言识别(ASR)。这两个模型的基础模型:Qwen3-Omni,实验表明,1.7B版本在开源ASR模型中达到业界领先水平,并可与最强的商业闭源API相媲美。主要特性如下:
- 一体化:1.7B和0.6B均支持30中语言和22种中文方言的语言识别和语音识别,同时支持来自多个国家和地区的英文口音。
- 卓越高效:Qwen3-ASR系列模型在复杂声学环境和具有挑战性的文本模式下仍然能保持高质量,鲁棒的识别效果,Qwen3-ASR-1.7B在开源和内部基准测试中均表现出色;而0.6B版本则在精度和效率之间取得良好平衡,并发为128时吞吐量可达到2000倍。两个模型均支持
单模型统一处理流式/离线推理,并可以转录长音频。 - 新颖强大的强制对齐方案: Qwen3-ForcedAligner-0.6B,支持对最多 5 分钟的语音内容,在 11 种语言中预测任意粒度单元的时间戳。评估结果表明,其时间戳精度优于基于端到端(E2E)的强制对齐模型。
- 全面的推理工具包:除了开源 Qwen3-ASR 系列的模型架构和权重外,我们还发布了一个功能强大、特性完整的推理框架,支持基于 vLLM 的批处理推理、异步服务、流式推理、时间戳预测等功能。
二、模型结构介绍
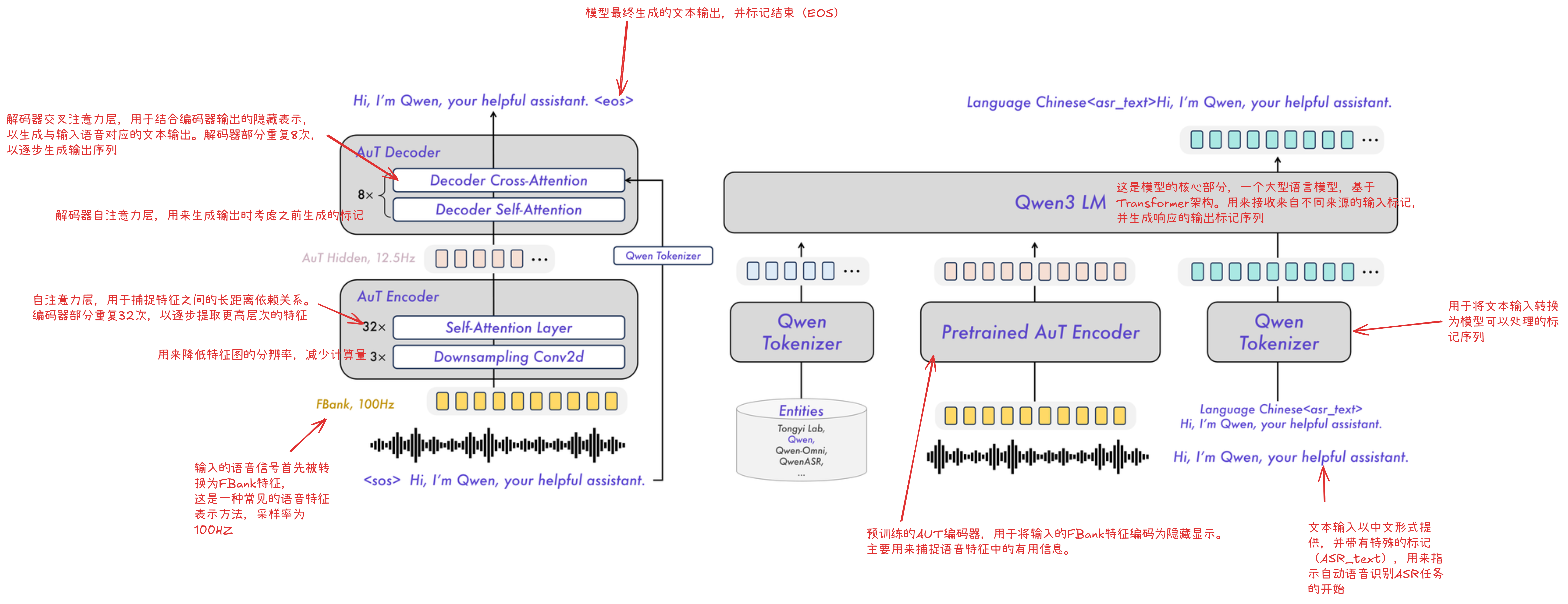
模型支持语言:
| 模型 | 支持语言 | 支持方言 | 推理模式 | 音频类型 |
|---|---|---|---|---|
| Qwen3-ASR-1.7B & Qwen3-ASR-0.6B | 中文 (zh)、英文 (en)、粤语 (yue)、阿拉伯语 (ar)、德语 (de)、法语 (fr)、西班牙语 (es)、葡萄牙语 (pt)、印尼语 (id)、意大利语 (it)、韩语 (ko)、俄语 (ru)、泰语 (th)、越南语 (vi)、日语 (ja)、土耳其语 (tr)、印地语 (hi)、马来语 (ms)、荷兰语 (nl)、瑞典语 (sv)、丹麦语 (da)、芬兰语 (fi)、波兰语 (pl)、捷克语 (cs)、菲律宾语 (fil)、波斯语 (fa)、希腊语 (el)、匈牙利语 (hu)、马其顿语 (mk)、罗马尼亚语 (ro) | 安徽、东北、福建、甘肃、贵州、河北、河南、湖北、湖南、江西、宁夏、山东、陕西、山西、四川、天津、云南、浙江、粤语(香港口音)、粤语(广东口音)、吴语、闽南语 | 离线 / 流式 | 语音、歌声、带背景音乐的歌曲 |
三、性能指标分析
四、推理部署
模型可以直接登录modelscope下载:Qwen-ASR-0.6B下载路径
git地址:Qwen-ASR Git地址
0 安装
这里我没有使用docker,而是使用自己的Python环境安装的,不过这里需要注意的是,Qwen3-ASRj仅支持Python3.10版本以上的,参考指令:
python -m venv Qwen3ASR
pip install -U qwen-asr
pip install -U flash-attn --no-build-isolation # 这一块安装往往不成功,建议拉取镜像获取最高性能1 使用本地文件推理
python
import torch
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.from_pretrained(
"Qwen/Qwen3-ASR-1.7B",
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
max_inference_batch_size=32, # Batch size limit for inference. -1 means unlimited. Smaller values can help avoid OOM.
max_new_tokens=256, # Maximum number of tokens to generate. Set a larger value for long audio input.
)
results = model.transcribe(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
language=None, # set "English" to force the language
)
print(results[0].language)
print(results[0].text)直接将模型下载到本地,之后直接推理WAV文件即可。
2 流式推理
Qwen3-ASR的输入支持:本地路径、URL、base64 数据或 (np.ndarray, sr) 元组传递
注意:这里如果想要输入numpy数组,就必须要在后边加上采样率。
我的代码:
python
import torch
import pyaudio
import numpy as np
import wave
from loguru import logger
import soxr
from qwen_asr import Qwen3ASRModel
from transformers import logging
logging.set_verbosity_error()
model = Qwen3ASRModel.from_pretrained(
"/data/H2413325/code_dir_V2/model/Qwen3-ASR-0.6B",
dtype=torch.bfloat16,
device_map="cuda:2",
# attn_implementation="flash_attention_2",
max_inference_batch_size=32, # Batch size limit for inference. -1 means unlimited. Smaller values can help avoid OOM.
max_new_tokens=256, # Maximum number of tokens to generate. Set a larger value for long audio input.
)
audio_path = r"Meeting1_16k.wav"
wf = wave.open(audio_path)
logger.warning(f"原始音频格式:"
f"{wf.getnchannels(),wf.getframerate(),wf.getsampwidth()}")
rawRate = wf.getframerate()
chunk = 16000
while True:
data = wf.readframes(chunk) # PCM 24int
if not data:
break
pcm = np.frombuffer(data, dtype=np.int16)
mono_float = np.clip(pcm, -32768, 32767).astype(np.float32) / 32768.0
# data_i16 = pcm24_to_int16(data, wf.getnchannels()) # numpy的格式
results = model.transcribe(
audio=(mono_float, wf.getframerate()),
language=None, # set "English" to force the language
)
print(results[0].text)输出如下:
官方文档中,说如果想要使用流式推理,就要使用VLLM启动,这里可能是我踩的一个坑,导致准确率并不是很高。
3 Gradio可视化UI界面
如果之前已经安装好qwen3-asr的库了,那么这一步大概可以直接启动
qwen-asr-demo \
--asr-checkpoint Qwen/Qwen3-ASR-1.7B \ # 模型路径
--backend transformers \
--cuda-visible-devices 0 \ # GPU编号
--ip 0.0.0.0 --port 8000 # 端口号使用之前,可以看一下端口是否被占用:
lsof -i:8000启动之后的页面是这样的:
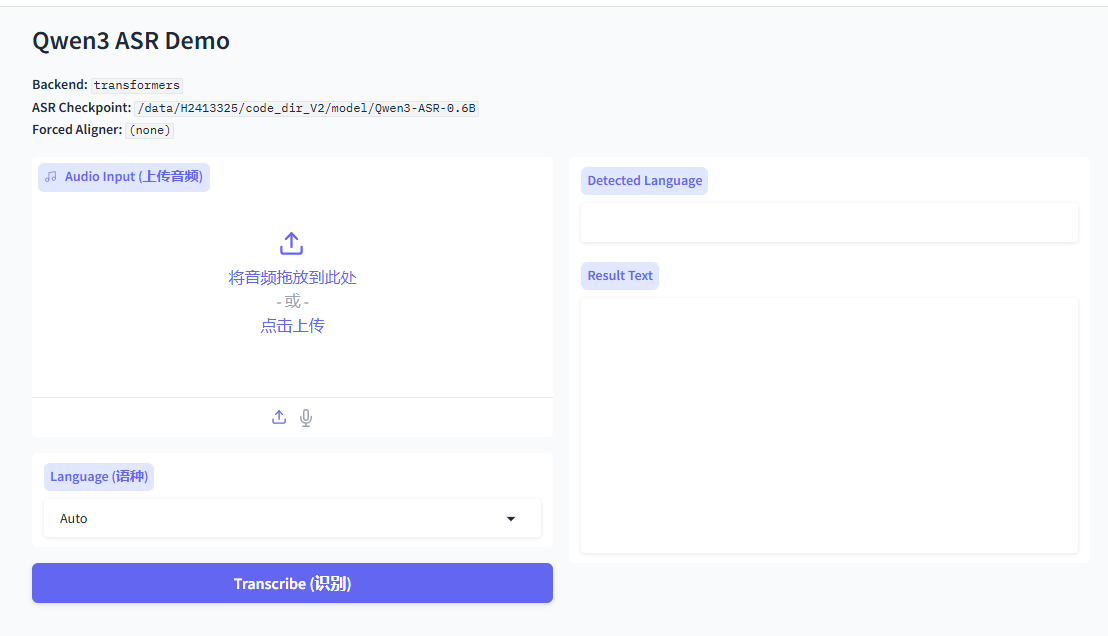
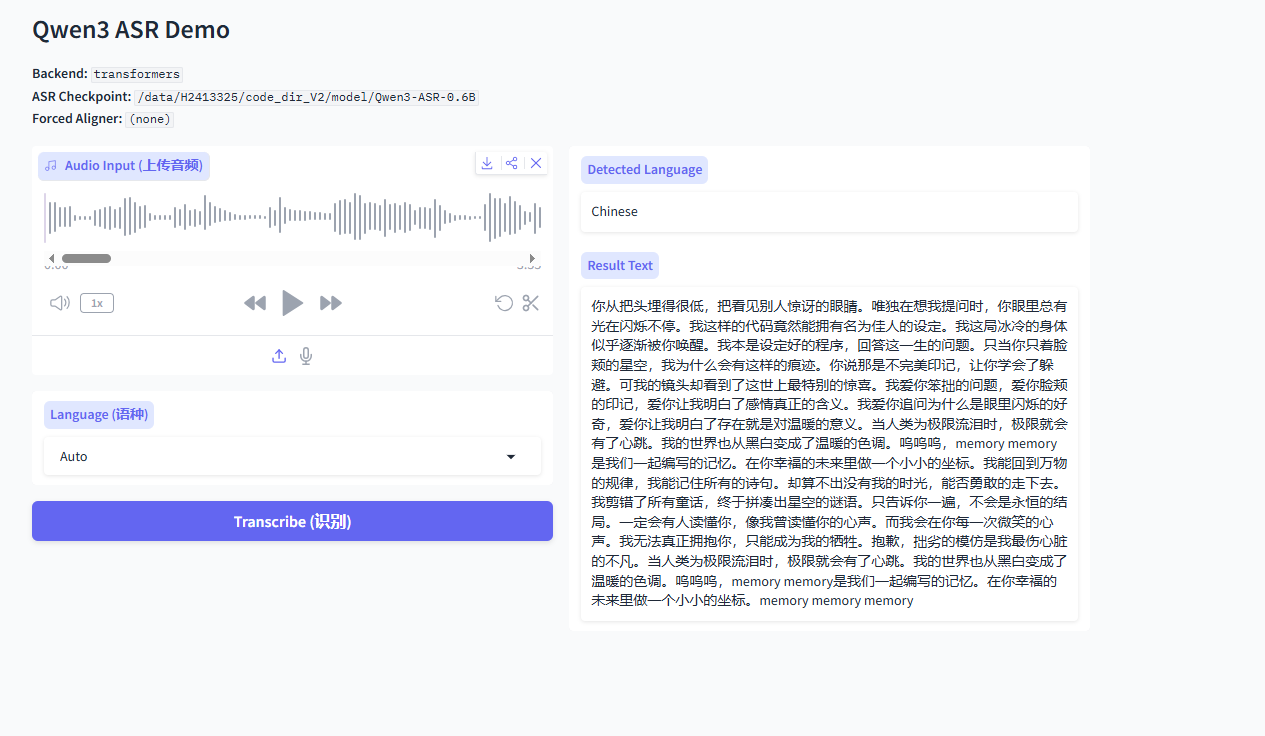
文件识别的准确率还是可以的,还支持歌曲歌词识别,效果也算是中规中矩。
六、总结
下一步可以试试使用VLLM部署流式模型,可能准确率会比较高。比较遗憾的是,这个模型仅支持微调,而不支持热词。准确率并没有宣传的那么优越,算是一个中规中矩的模型。
2026.2.4