从数据处理、计算loss的target、预测输出展示、模型与损失的顺序学习目标检测SSD项目。 前三者都是为了更好的理解数据流。适合有深度学习基础无目标检测经验的同学。
(项目代码待整理完上传github)
1、voc数据预处理
文件结构
xml
<!-- 典型Pascal VOC标注文件结构 -->
<annotation>
<folder>VOC2012</folder>
<filename>2007_000027.jpg</filename> <!-- ← 从这里提取 -->
<size>
<width>486</width>
<height>500</height>
<depth>3</depth>
</size>
<object> <!-- ← 每个object标签对应一个目标 -->
<name>person</name> <!-- ← 目标类别 -->
<pose>Left</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox> <!-- ← 边界框坐标(关键!) -->
<xmin>174</xmin> <!-- ← 提取 -->
<ymin>101</ymin> <!-- ← 提取 -->
<xmax>349</xmax> <!-- ← 提取 -->
<ymax>351</ymax> <!-- ← 提取 -->
</bndbox>
</object>
<object>
<!-- 可以有多个object -->
</object>
</annotation>标签提取
目标:类别、角坐标、困难目标

核心代码
python
def _get_annotation(self, image_id):
annotation_file = os.path.join(self.data_dir, "Annotations", "%s.xml" % image_id)
objects = ET.parse(annotation_file).findall("object")
boxes = []
labels = []
is_difficult = []
for obj in objects:
class_name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
# VOC dataset format follows Matlab, in which indexes start from 0
x1 = float(bbox.find('xmin').text) - 1
y1 = float(bbox.find('ymin').text) - 1
x2 = float(bbox.find('xmax').text) - 1
y2 = float(bbox.find('ymax').text) - 1
boxes.append([x1, y1, x2, y2])
labels.append(self.class_dict[class_name])
is_difficult_str = obj.find('difficult').text
is_difficult.append(int(is_difficult_str) if is_difficult_str else 0)
return (np.array(boxes, dtype=np.float32),
np.array(labels, dtype=np.int64),
np.array(is_difficult, dtype=np.uint8))返回的是角点格式的位置、类别以及是否为困难目标的元组,可能包含多个目标框、类别信息。
2、计算loss的target与处理方式
重点! 实际训练时计算loss并不是读取时的原数据。预设的网络预测是基于先验框中心的位置偏移量,并非实际的角坐标。作为真正的训练gt需进行一系列转变。目标是把绝对坐标数值 转换为相对先验框 的小范围偏移量
核心内容 :标签的三次转变
①维度层面 :单个场景的真实框(一个或多个)与先验框(场景size划分)的交并比(IOU),为每个先验框匹配对应的真实框(或标记为背景)。
假如预处理提取了3个目标框则维度为3,4,经过这一步变为8732,4。其中符合匹配阈值的框的实际存储值为目标框角坐标,不符合为0。
②格式层面 :维度不变,从角坐标变为中心坐标。
③数值层面:维度不变,中心坐标转变为归一化偏移量。
python
import numpy as np
import torch
from ssd.utils import box_utils
class SSDTargetTransform:
"""
SSD 模型的目标转换类:用于将原始的真实标签(gt_boxes、gt_labels)转换为 SSD 模型训练所需的目标数据(位置偏移量、匹配后的标签)。
核心作用:
1. 将原始真实边框(gt_boxes)与 SSD 模型预定义的先验框(priors)进行匹配。
2. 转换边框格式(从角点格式 ↔ 中心格式),适配模型训练需求。
3. 计算真实边框相对于匹配先验框的位置偏移量(而非直接使用原始边框坐标),作为模型位置回归的目标。
"""
def __init__(self, center_form_priors, center_variance, size_variance, iou_threshold):
"""
构造方法:初始化 SSD 目标转换所需的核心参数(先验框、方差、IOU 匹配阈值)
Args:
center_form_priors (torch.Tensor): 中心格式的先验框(default boxes),形状通常为 [num_priors, 4]。
每个先验框的格式为 (cx, cy, w, h):cx/cy 是框的中心坐标,w/h 是框的宽和高。
center_variance (float): 中心坐标(cx, cy)转换时使用的方差,用于归一化位置偏移量,提升训练稳定性。
size_variance (float): 尺寸(w, h)转换时使用的方差,作用同上(通常和 center_variance 取值相同,如 0.1)。
iou_threshold (float): IOU 匹配阈值,用于判断真实边框与先验框是否匹配(如 0.5)。
若两者 IOU 大于该阈值,认为先验框匹配到了真实目标,否则标记为背景。
"""
# 保存中心格式的先验框(后续用于计算位置偏移量)
self.center_form_priors = center_form_priors
# 将先验框从中心格式转换为角点格式,用于后续与真实边框(通常为角点格式)进行 IOU 匹配
# 角点格式:(xmin, ymin, xmax, ymax),分别对应框的左上角和右下角坐标
self.corner_form_priors = box_utils.center_form_to_corner_form(center_form_priors)
# 保存中心坐标对应的方差
self.center_variance = center_variance
# 保存尺寸对应的方差
self.size_variance = size_variance
# 保存 IOU 匹配阈值
self.iou_threshold = iou_threshold
def __call__(self, gt_boxes, gt_labels):
"""
可调用方法:核心逻辑实现,将原始真实标签转换为 SSD 模型训练所需的目标数据。
Args:
gt_boxes (np.ndarray / torch.Tensor): 原始真实边框,形状 [num_gt, 4],角点格式 (xmin, ymin, xmax, ymax)
gt_labels (np.ndarray / torch.Tensor): 原始真实类别标签,形状 [num_gt],非背景类别
Returns:
locations (torch.Tensor): 先验框对应的位置偏移量,形状 [num_priors, 4],中心格式偏移 (cx_off, cy_off, w_off, h_off)
labels (torch.Tensor): 先验框对应的类别标签,形状 [num_priors],背景标记为 0
"""
if type(gt_boxes) is np.ndarray:
gt_boxes = torch.from_numpy(gt_boxes)
if type(gt_labels) is np.ndarray:
gt_labels = torch.from_numpy(gt_labels)
# 维度层面:将真实边框/标签与先验框进行匹配,分配每个先验框对应的目标(计算交并比-角点模式)
# 输入:原始真实框、真实标签、角点格式先验框、IOU 匹配阈值
# 输出:boxes(每个先验框匹配后的真实框,角点格式,[num_priors, 4])、labels(每个先验框的类别,[num_priors])
boxes, labels = box_utils.assign_priors(gt_boxes, gt_labels,
self.corner_form_priors, self.iou_threshold)
# 格式层面:将匹配后的角点格式边框,转为中心格式(适配后续偏移量计算)
# 转换后格式:(cx, cy, w, h),形状仍为 [num_priors, 4]
boxes = box_utils.corner_form_to_center_form(boxes)
# 数值层面:计算真实框相对于先验框的位置偏移量(模型位置回归的训练目标)
# 输入:匹配后的中心格式框、原始中心格式先验框、中心/尺寸方差
# 输出:归一化后的位置偏移量,形状 [num_priors, 4]
locations = box_utils.convert_boxes_to_locations(boxes, self.center_form_priors, self.center_variance, self.size_variance)
return locations, labels3、模型预测输出与展示预测框
模型测试最终输出为以下格式(偏移量变化包含在模型结构中,在这儿不考虑流程)
python
boxes, labels, scores = result['boxes'], result['labels'], result['scores']
# boxes=[M, 4], 预测的边框角坐标
# labels=[M,], 边框的类别
# scores=[M,] 置信度直接调用vizer.draw_boxes即可
python
img_annotated_rgb = vizer.draw_boxes(
img=img_rgb, # 输入 RGB 格式图片
boxes=boxes, # 边框列表,格式 (xmin, ymin, xmax, ymax)
labels=labels, # 类别标签列表(可选)
scores=scores, # 置信度列表(可选)
box_color=(255, 0, 0), # 边框颜色(RGB),默认红色 (255,0,0)
text_color=(255, 255, 255), # 标签文字颜色(RGB),默认白色
line_width=2 # 边框线宽,默认 2
)4、模型结构与训练损失
结构
详细可看SSD模型详解
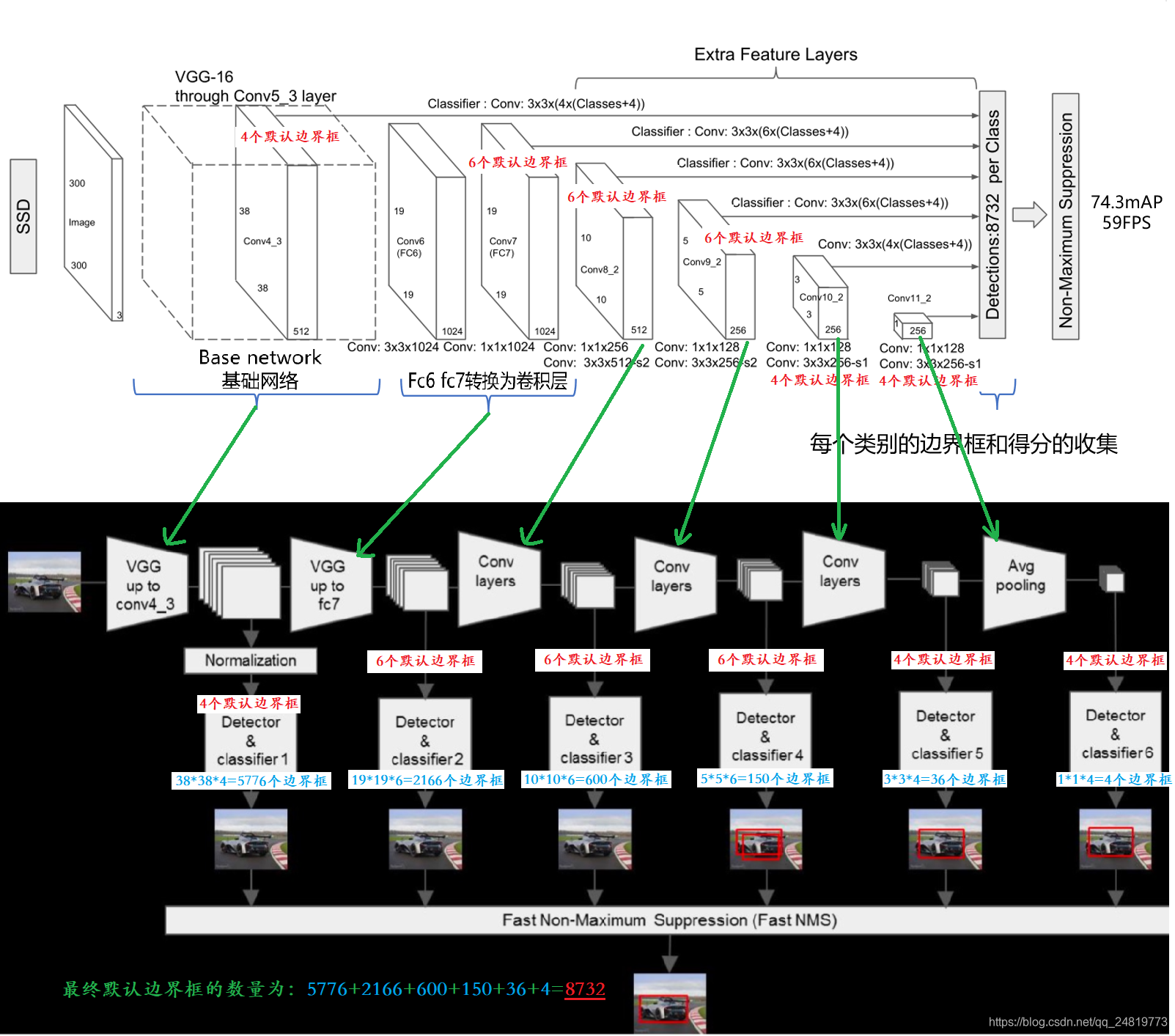
训练损失
SSD 核心的 MultiBoxLoss 类,整合了分类损失(交叉熵)和边框回归损失。
-
分类损失:采用交叉熵损失,针对先验框的类别预测(背景/各类目标)。采用「硬负样本挖掘(Hard Negative Mining)」,平衡正负样本比例(解决正负样本失衡问题)。
-
回归损失:采用 Smooth L1 损失,仅针对正样本先验框(匹配到真实框的先验框)。
python
class MultiBoxLoss(nn.Module):
def __init__(self, neg_pos_ratio):
"""
初始化 MultiBox 损失函数
Args:
neg_pos_ratio (int/float): 负样本与正样本的比例(通常设为3),用于硬负样本挖掘。
例如:neg_pos_ratio=3 表示每1个正样本,保留3个最难的负样本参与分类损失计算。
"""
super(MultiBoxLoss, self).__init__()
# 保存负正样本比例
self.neg_pos_ratio = neg_pos_ratio
def forward(self, confidence, predicted_locations, labels, gt_locations):
"""
前向传播:计算分类损失和边框回归损失(核心逻辑)。
Args:
confidence (torch.Tensor): 模型预测的类别置信度,形状 [batch_size, num_priors, num_classes]
- batch_size:批次大小(一次训练的图片数量)
- num_priors:先验框总数(如8732)
- num_classes:类别总数(包含背景,如VOC数据集为21类:背景+20类目标)
predicted_locations (torch.Tensor): 模型预测的边框偏移量,形状 [batch_size, num_priors, 4]
- 4:对应 cx/cy/w/h 四个维度的偏移量
labels (torch.Tensor): 每个先验框的真实类别标签,形状 [batch_size, num_priors]
- 数值含义:0=背景,>0=对应目标类别ID(如1=飞机,2=自行车)
gt_locations (torch.Tensor): 每个先验框对应的真实边框偏移量(正样本有效),形状 [batch_size, num_priors, 4]
Returns:
smooth_l1_loss (torch.Tensor): 归一化后的边框回归损失(仅正样本参与)
classification_loss (torch.Tensor): 归一化后的类别分类损失(正负样本按比例参与)
"""
num_classes = confidence.size(2)
with torch.no_grad():
# 步骤1:计算所有先验框的「背景类负样本损失」,用于后续硬负样本挖掘
# F.log_softmax(confidence, dim=2):对类别维度做log softmax,得到每个类别的对数概率
# [:, :, 0]:提取背景类(第0类)的对数概率
# 加负号:将对数概率转为「损失值」(损失越大,说明模型越认为这个先验框不是背景,即越可能是难分负样本)
loss = -F.log_softmax(confidence, dim=2)[:, :, 0]
# 步骤2:硬负样本挖掘(核心:平衡正负样本比例,只保留最难的负样本)
# 输入:背景类损失值、真实标签、负正样本比例
# 输出:一个布尔型掩码(mask),形状 [batch_size, num_priors],值为True表示该先验框被选中参与分类损失计算
# 逻辑:1. 筛选出所有正样本(labels>0),全部保留;2. 筛选出负样本中损失最大的部分,数量为正样本的neg_pos_ratio倍;3. 其余负样本丢弃
mask = box_utils.hard_negative_mining(loss, labels, self.neg_pos_ratio)
# 步骤3:计算类别分类损失(交叉熵损失)
# 1. 用掩码筛选出参与计算的先验框的置信度,形状变为 [selected_priors, num_classes]
confidence = confidence[mask, :]
# 2. 计算交叉熵损失:
# - confidence.view(-1, num_classes):将置信度展平为 [selected_priors_total, num_classes],适配交叉熵输入格式
# - labels[mask]:筛选出参与计算的先验框的真实标签,展平为 [selected_priors_total]
# - reduction='sum':损失结果求和(后续除以正样本数量归一化)
classification_loss = F.cross_entropy(confidence.view(-1, num_classes), labels[mask], reduction='sum')
# 步骤4:计算边框回归损失(Smooth L1 损失)
# 1. 构建正样本掩码:形状 [batch_size, num_priors],值为True表示该先验框是正样本(匹配到真实框)
pos_mask = labels > 0
# 2. 筛选出正样本的预测偏移量,展平为 [num_pos, 4](num_pos为正样本总数,仅正样本参与回归损失计算)
predicted_locations = predicted_locations[pos_mask, :].view(-1, 4)
# 3. 筛选出正样本的真实偏移量,展平为 [num_pos, 4]
gt_locations = gt_locations[pos_mask, :].view(-1, 4)
# 4. 计算Smooth L1损失:对离群值鲁棒(避免大误差样本主导损失),结果求和
smooth_l1_loss = F.smooth_l1_loss(predicted_locations, gt_locations, reduction='sum')
# 步骤5:损失归一化(除以正样本数量,消除批次中正样本数量差异的影响)
num_pos = gt_locations.size(0) # 获取正样本总数
# 返回归一化后的两个损失:边框回归损失、分类损失
return smooth_l1_loss / num_pos, classification_loss / num_pos