0. 写在前面
2026/3/17:
搜广推复习过程中,项目用到了树模型,但是一点不会,遂配合DeepSeek尽可能完整的整理八股
1. GBDT
训练出一棵树的基础上,再训练下一棵树,预测它和真实值之间的差距,累加预测结果
1.1 如何选择分裂特征
分离特征:决策树构建过程中,被选为内部节点分裂依据的输入特征
GBDT树是通过最小化损失函数来构建的,每个节点分裂时都会遍历所有特征,找到最大增益的分裂方式
对于回归问题:增益是基于方差减少或均方误差减少
对于分类问题:增益是基尼指数减少或交叉熵减少
**基尼指数:**从数据集中随机抽取两个样本,其类别标签不一致的概率
对于一个包含K个类别的数据集,基尼指数的计算公式如下:
p_i是数据集中第i个样本所占的比例
**交叉熵:**对于一个包含K个类别的数据集,信息熵的计算公式如下:
p_i是数据集中第i个样本所占的比例
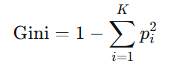
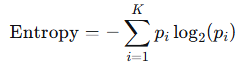
1.2 分裂特征的重要性
GBDT输出特征重要性评分,通常基于
-
分裂次数:该特征被选为分裂特征的次数
-
增益总和:该特征在所有分裂中带来的总增益
-
覆盖度:该特征分裂覆盖的样本数量
1.3 GBDT缺失值如何处理
GBDT(包括XGBoost和LightGBM)可以自动学习缺失值的分裂方向:在寻找最佳分裂特征时,算法会将缺失值分别放入左右子树计算损失,选择最优方向
**例如:**如果缺失值去左子树的增益是+10,去右子树是+5,直接规定所有收入缺失的样本默认走左子树
2. XGBoost
XGBoost在GBDT的基础上,对正则化 、损失函数 求解和工程实现等角度进行改进,兼顾运行效率和模型泛化性
2.1 算法优化
2.1.1 目标函数:引入正则化项
GBDT只优化损失函数(如平方误差、对数损失),不关心树本身的复杂度
XGBoost增加了正则项,包含 叶子节点数 和 叶子权重的L2模平方
2.1.2 损失函数:二阶泰勒展开
GBDT只使用损失函数的一阶导数(梯度)来近似残差
XGBoost对损失函数进行二阶泰勒展开,同时用一阶导和二阶导。
**XGBoost优势:**保留更多损失函数信息,梯度下降的方向更精准,收敛速度更快,能找到更优解
2.1.3 缺失值处理:自动学习缺失值分裂方向
XGBoost稀疏感知算法,训练时自动学习缺失值的最优分裂方向,免去预处理步骤,还可以捕捉缺失本身可能蕴含的信息(例如收入缺失的人可能没有工作,行为模式不同)
2.2 工程优化
2.2.1 并行化计算
GBDT: 串行生成树
XGBoost:特征并行。在构建单颗树时实现并行,先对特征值进行排序,以块结构存储在内存中。寻找分裂点时,可以并行计算所有特征的增益。
并行化决定了多个特征之间如何同时计算
2.2.2 近似分桶算法
GBDT:遍历所有特征值寻找最优切分点,数据量大时内存消耗大且慢
XGBoost:对于连续特征,不遍历所有值,而是根据二阶导数值作为权重,对特征值进行分桶,只在分位点上寻找分裂点
近似分桶决定了每个特征内部怎么找切分点
2.2.3 剪枝策略
GBDT:通常依赖预剪枝
XGBoost:引入最大深度参数限制(预剪枝),同时支持后剪枝。如果一次分裂带来的增益小于设定的最小损失下降值 γ,会剪掉这次分裂(预剪枝)。
**预剪枝:**在树生长过程中提前停止分裂,比如设置max_length=3,树深到3层就停,或者设置节点样本数小于某个阈值就停
**后剪枝:**先把树完全长成,然后自底向上考察非叶子节点,如果把某个子树砍掉能让验证集误差下降就执行
2.3 高频问题
2.3.1 XGBoost为什么要用二阶导而不是一阶导
二阶导数包含损失函数的曲率信息,只用一阶导相当于用直线去拟合残差,而用二阶导数相当于用抛物线去拟合,精度更高,梯度下降方向更准确。
2.3.2 XGBoost的并行化体现在哪里
XGBoost的并行不是树与树之间的并行,GBDT都是串行的,而是特征维度的并行。在训练同一颗树的同一层时,由于各个特征的分裂点搜索是独立的,XGBoost可以将数据预先排序存储为块,然后多线程同时计算所有特征的增益,选择最大增益的特征进行分裂
2.3.3 XGBoost如何处理类别特征
早期XGBoost默认将所有输入视为数值型,因此处理类别特征需要手动预处理
1)独热编码:将类别特征展开为多个01虚拟变量。缺点是维度爆炸、稀疏性、失去顺序信息
2)标签编码:将类别映射为整数(如红=1,蓝=2)。缺点是给类别强加不存在的关系
从XGBoost 1.6版本开始,官方引入对类别特征的原生实验性支持。通过指定`enable_categorical = True`参数,并将DataFrame中的类别列类型设未pandas.Categorical或使用feature_types指定。
启动原生支持后,XGBoost采用分区法:
1)统计:计算每个类别对应的一阶导和二阶导的统计量
2)排序:根据统计量对类别进行排序
3)寻找最优划分:在排序后的类别表上,寻找最优的切分点
3. LightGBM
LightGBM是一个基于直方图算法的梯度提升框架,针对XGBoost在大数据场景下的训练速度慢、内存消耗大的问题进行了系统性优化
3.1 决策树生长策略
|------|----------------|---------------|
| 维度 | XGBoost | LightGBM |
| 生长策略 | Level-Wise | Leaf-Wise |
| 示意图 | 每层所有节点同时分裂 | 每次只找增益最大的叶子分裂 |
| 特点 | 并行容易,控制深度防止过拟合 | 效率高,但可能过拟合 |
LightGBM的Wise-Level:
每次从当前所有叶子中,找到分裂增益最大的那个叶子进行分裂,其他叶子不动
优点:效率更高,误差更小,每次都在优化最需要分裂的位置
缺点:可能长出不平衡的树,容易过拟合,需要配合最大深度限制来控制
3.2 分裂点寻找算法
|----|----------|--------------------|
| | XGBoost | LightGBM |
| 算法 | 预排序算法 | 直方图算法 |
| 做法 | 遍历所有特征值 | 将连续特征离散化成k个桶,构建直方图 |
| 内存 | 大(存排序索引) | 小(存离散值) |
| 速度 | 慢(遍历所有值) | 快(只遍历k个桶) |
LightGBM将连续特征离散化成k(0-255)个整数,构建一个包含k个bin(桶)的直方图,分裂时只需要遍历k个bin(桶),而不是n个样本
3.3 GOSS和EFB
3.3.1 GOSS基于梯度的单边采样
问题:样本量太大,计算每个样本的梯度很耗时
做法:保留大梯度的样本(对计算信息增益贡献大),对小梯度的样本进行随机采样
3.3.2 EFB互斥特征捆绑
问题:特征维度太高
做法:将互斥(几乎不同时非零)特征捆绑成一个新特征
3.4 类别特征处理
XGBoost:传统版本需要独热编码,新版本虽然已支持但是成熟度不如LightGBM
LightGBM:使用直方图算法对类别进行按梯度统计量排序,然后寻找最优分裂
3.5 高频问题
3.5.1 LightGBM的leaf-wise生长为什么容易过拟合
每次只分裂增益最大的叶子,会导致树不平衡。
解决方案:设置最大深度限制、设置总叶子节点数
3.5.2 直方图算法的优缺点
优点:内存占用小;计算速度快;有利于差分计算;离散化本身是一种平滑,防止过拟合
缺点:丢失信息,损失精度
3.5.3 GOSS为什么有效,会不会丢信息
因为大梯度样本对计算信息增益贡献最大,小梯度样本贡献较小,采样一部分即可代表整体分布