封面来自于 midjourney

文章目录
- [Explainable Machine Learning](#Explainable Machine Learning)
- 参考
Explainable Machine Learning

不仅要给出正确答案,还是给出为什么

"神马汉斯"(Clever Hans,又译"聪明的汉斯")是一匹在20世纪初轰动德国的马,它的故事是心理学和科学方法论中的一个经典案例。
这匹名为汉斯的马由其主人冯·奥斯滕(Wilhelm von Osten)训练,据说它拥有惊人的智力。汉斯能通过蹄子敲击地面的次数来回答算术题(如"3加4等于几?")、识别颜色、甚至拼写单词。当时许多专家观察后都相信马真的学会了计算和思考。

这个案例揭示了著名的"观察者期望效应"(Observer-expectancy effect),即实验者的预期会无意识地影响实验对象的行为。从此,"神马汉斯"成为了科学实验中的警示符号,
提醒研究人员在进行动物认知研究或人类心理实验时,必须采用"双盲"等严格方法,以排除无意识暗示的干扰。

训练模型给客户放贷,需要解释为什么可以放
医疗诊断模型不仅给出结果,还需要解释原因
判案模型,要给出判决理由
自动驾驶模型突然刹车,需要给出刹车理由

A:"这是你的机器学习系统?"
B:"是的!你把数据倒入这一大堆线性代数中,然后从另一端收集答案。"
C:"如果答案错了怎么办?"
D:"只要不断搅拌,直到看起来正确为止。"
漫画的幽默之处在于它夸张地表现了某些机器学习实践中可能出现的盲目调整和缺乏真正理解的现象。
这种方法可能缺乏对模型内在逻辑的深入理解,仅仅依赖于反复试验来获得看似正确的结果。


linear model 有解释性,但是能力没有 non-linear model 强
因为 Deep Learning 没有解释性而不用它,有点削足适履
坚持用简单可解释的模型,就像坚持在路灯下找钥匙(因为有光)
现在要做的是,改变路灯的范围,改变照明的方向
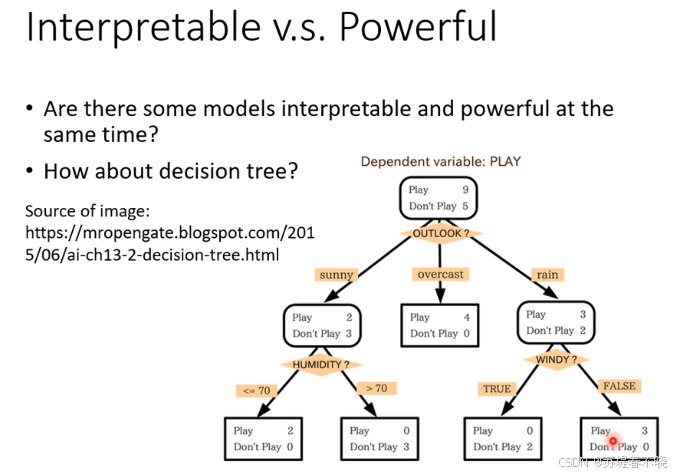
decision tree 既强大,又有解释性


decision tree 使用的时候往往以 random forest 的形式存在,并非单颗树
所以也是不太好解释的

explainable ML 的目标是什么
ML 是 black box,所以我们就不用它吗?
人脑目前对于我们来说也是 black box,但是我们可以完全相信另外一个人的决断
心理学史上非常著名的 "复印机实验"(The Copy Machine Study),由哈佛大学心理学家艾伦·兰格(Ellen Langer)于1978年进行

如果你想说服别人,给出一个理由(即便这个理由显而易见)比不给理由要有效得多。
什么是好的 explanation,让人高兴的 explanation
让谁高兴

这个是可解释的,给个 XXX 理由,也许别人就认可了,哈哈哈

local explanation


挡住某个区域,模型性能下降很多,说明该区域比较重要
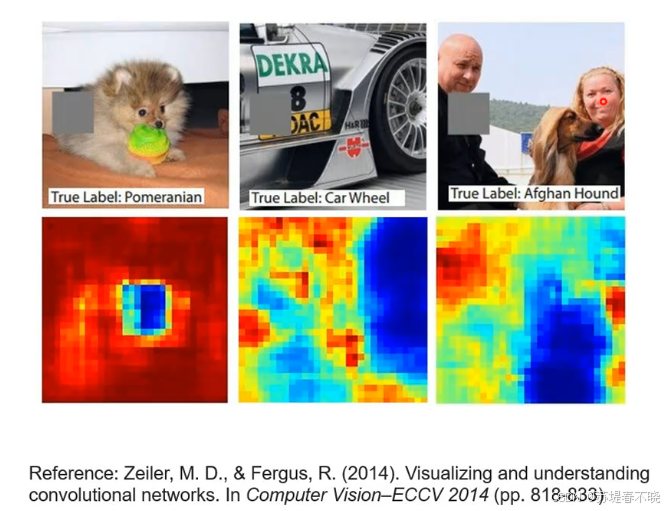
颜色约蓝,表示该区域遮挡后目标得分越低,进而可以看出哪些区域对最终分类的结果影响最大
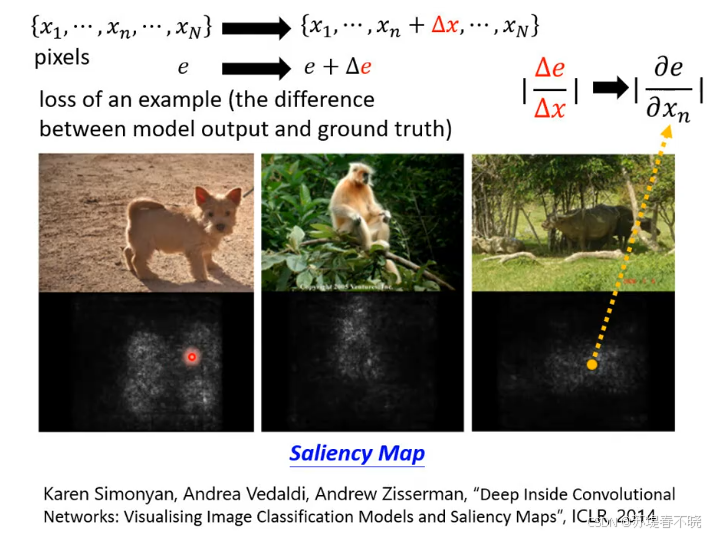
改变一个像素值, Δ x \Delta x Δx,看 loss 变化大不大 Δ e \Delta e Δe
如果比较大,就表示该处像素比较重要
利用这种机制可以画出 saliency map( Δ e \Delta e Δe 和 Δ x \Delta x Δx 的比值和 loss 对 x 求导一样),所以可以通过梯度来计算 saliency map


肉眼都搞不定,机器怎么精度这么高,画个热力图来分析一下
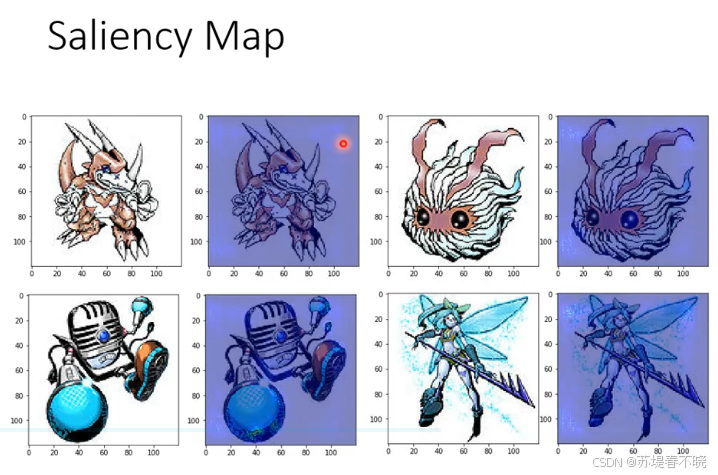
数码宝贝的热力图,重要的目标都分布在目标轮廓周边
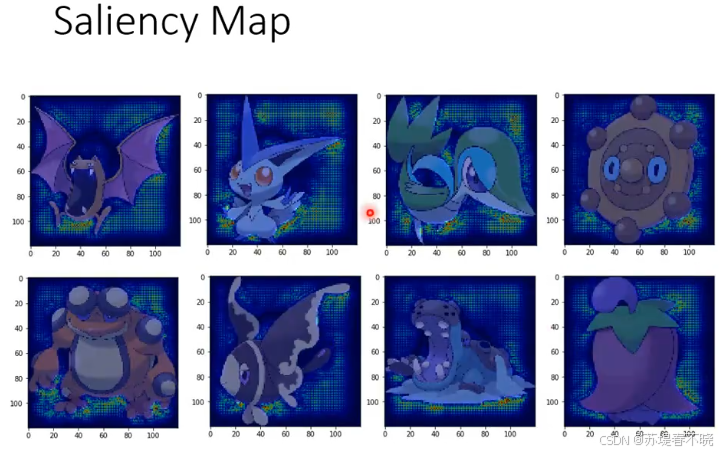
宝可梦更奇怪,比较重要的像素分布在背景处,避开了宝可梦本体



saliency map 方法画出来可能不美观,老板觉得模型不行(也许天空、草地对瞪羚的预测也很重要)
用 smoothGrad 方法,画出来的图更有说服力,哈哈哈
randomly add noises to the input image, get saliency maps of the noisy images, and average them.
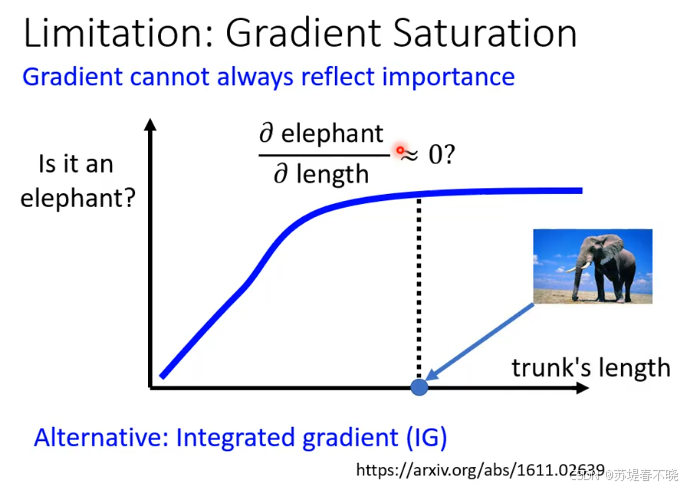
梯度饱和时,并不能精确反应对应区域的重要性了
eg:大象的特征是长鼻子,鼻子长到一定程度,模型对"它是大象"的预测概率已经接近 1.0 1.0 1.0(达到平台期)。

尽管象鼻这个特征对分类结果至关重要,但由于函数进入了饱和区(曲线变平),此时计算出的梯度趋近于 0 0 0。
如果你仅根据梯度画热力图,象鼻区域会是暗淡的,导致你错误地认为"象鼻不重要"。
当模型已经"确信"某个特征时,梯度会因为函数饱和而失效,导致热力图无法准确标记出真正的关键特征。
改进方法,integrated gradient,这里不展开讨论了
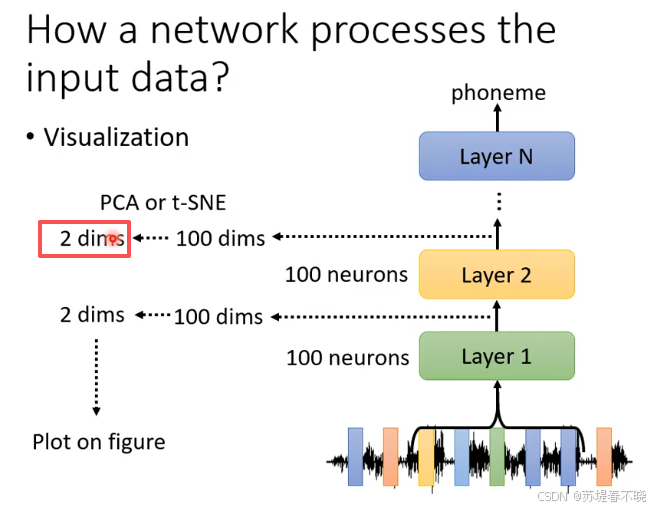

左图每种颜色表示每个人,每个位置表示一段语音
不同人说同样的话,看起来,也没有怎么重叠(好难做语音识别啊)
可视化第八个 hidden layer 的结果后,发现不同人同样的一句话的特征聚集在了一起
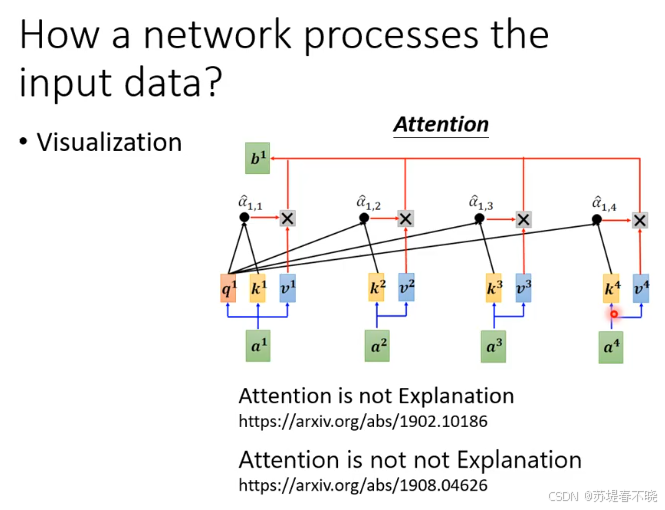
后面会不会再来一个 Attention is not not not Explanation,哈哈哈
attention 能不能被解释,什么状况下可以被解释,什么状况下不可以被解释,keep going
除了上面用人眼观察以外,还可以用 Probing 技能
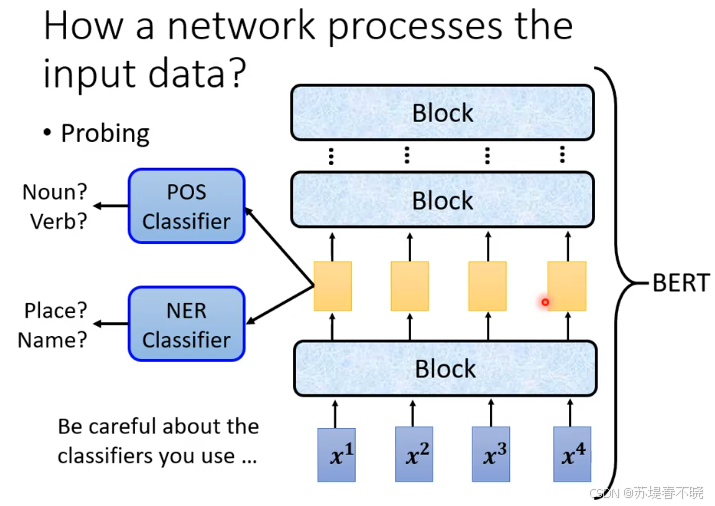
用 prob model,来探测中间层是否学到了对应的特征
POS Classifier (Part-of-Speech Classifier) 词性分类器。名词?动词?...
在 BERT 的中间层输出上接一个 POS 分类器,来观察模型的这一层是否已经学到了语法结构信息。
NER Classifier (Named Entity Recognition Classifier),命名实体识别分类器。它会判断一个词组是否代表地点(Place/Location)、人名(Name/Person)、组织机构(Organization)或时间等
小心 prob model 本身的正确性
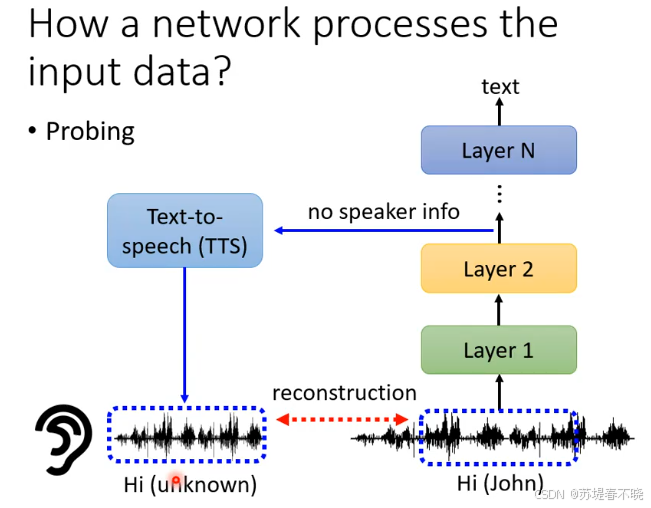
验证手段: 将 Layer N 的向量输入到一个预训练的 TTS(文字转语音) 系统中,尝试将其还原回声音。
如果 TTS 还原出来的声音不知道是谁说的,说明右边网络中间层已经学会了抹去 speaker 的能力
说话人无关化(Speaker-Invariant): 对模型来说,不论是 John 还是 Mary 说 "Hi",其语义是一样的。因此,Layer N 倾向于只保留文字内容(Text)的表征,而主动丢弃掉音色、口音、性别等个人特征
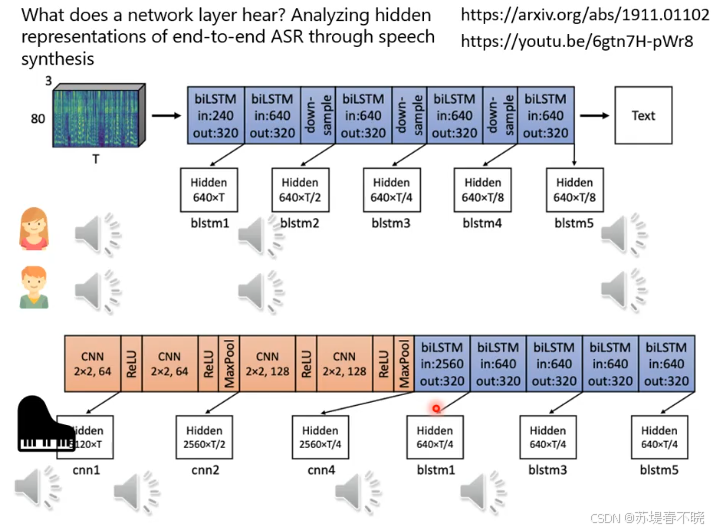
上面的声音一男一女,中间的输出还能听出来男生女生的差异,网络后面听不出来男生女生了。说明网络学到后面可以屏蔽掉 speakers
下面一个例子,输入有钢琴声+人声,前面的 CNN 处还是能听到钢琴声,第一个 biLSTM 后听不到了,说明网络学习到消除钢琴回音是在 LSTM 之后,CNN 不具备该能力
可以听 network 听到的声音